---
base_model:
- google/siglip2-so400m-patch16-384
- google/siglip2-so400m-patch16-256
language:
- en
license: other
license_name: other
license_link: https://github.com/TencentARC/TokLIP/blob/main/LICENSE
pipeline_tag: image-text-to-text
tags:
- Tokenizer
- CLIP
- UnifiedMLLM
---
# TokLIP: Marry Visual Tokens to CLIP for Multimodal Comprehension and Generation
[](https://arxiv.org/abs/2505.05422)
[](https://github.com/TencentARC/TokLIP)
[](https://huggingface.co/TencentARC/TokLIP)
[](https://github.com/TencentARC/TokLIP/blob/main/LICENSE)
Welcome to the official code repository for "[**TokLIP: Marry Visual Tokens to CLIP for Multimodal Comprehension and Generation**](https://arxiv.org/abs/2505.05422)".
Your star means a lot to us in developing this project! ⭐⭐⭐
## 📰 News
* [2025/08/18] 🚀 Check our latest results on arXiv ([PDF](https://arxiv.org/pdf/2505.05422))!
* [2025/08/18] 🔥 We release TokLIP XL with 512 resolution [🤗 TokLIP_XL_512](https://huggingface.co/TencentARC/TokLIP/blob/main/TokLIP_XL_512.pt)!
* [2025/08/05] 🔥 We release the training code!
* [2025/06/05] 🔥 We release the code and models!
* [2025/05/09] 🚀 Our paper is available on arXiv!
## 👀 Introduction
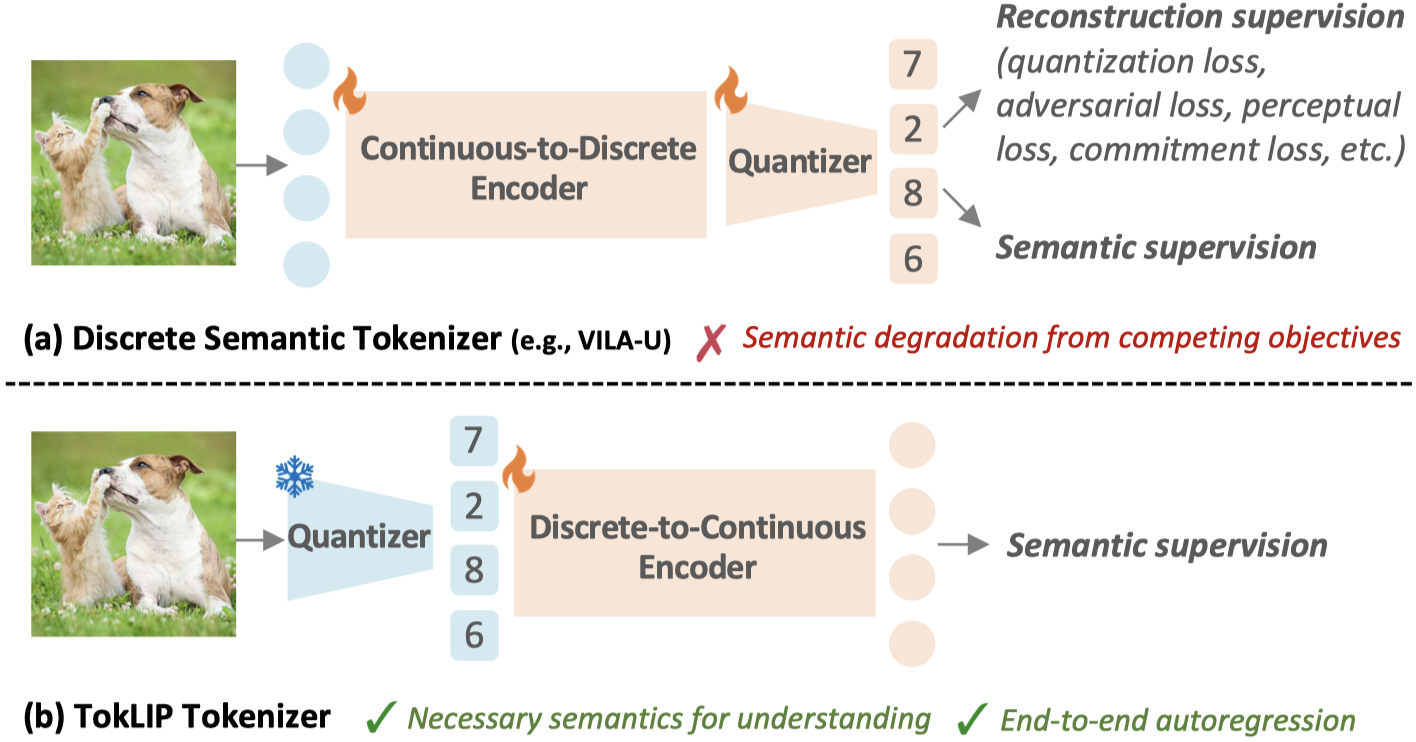 - We introduce TokLIP, a visual tokenizer that enhances comprehension by **semanticizing** vector-quantized (VQ) tokens and **incorporating CLIP-level semantics** while enabling end-to-end multimodal autoregressive training with standard VQ tokens.
- TokLIP integrates a low-level discrete VQ tokenizer with a ViT-based token encoder to capture high-level continuous semantics.
- Unlike previous approaches (e.g., VILA-U) that *discretize high-level features*, TokLIP **disentangles training objectives for comprehension and generation**, allowing the direct application of advanced VQ tokenizers without the need for tailored quantization operations.
## 🔧 Installation
```bash
conda create -n toklip python=3.10 -y
conda activate toklip
git clone https://github.com/TencentARC/TokLIP
pip install --upgrade pip
pip install -r requirements.txt
```
## ⚙️ Usage
### Model Weight
| Model | Resolution | VQGAN | IN Top1 | COCO TR@1 | COCO IR@1 | Weight |
| :-------: | :--------: | :----------------------------------------------------------: | :-----: | :-------: | :-------: | :----------------------------------------------------------: |
| TokLIP-S | 256 | [LlamaGen](https://huggingface.co/peizesun/llamagen_t2i/blob/main/vq_ds16_t2i.pt) | 76.4 | 64.06 | 48.46 | [🤗 TokLIP_S_256](https://huggingface.co/TencentARC/TokLIP/blob/main/TokLIP_S_256.pt) |
| TokLIP-L | 384 | [LlamaGen](https://huggingface.co/peizesun/llamagen_t2i/blob/main/vq_ds16_t2i.pt) | 80.0 | 68.00 | 52.87 | [🤗 TokLIP_L_384](https://huggingface.co/TencentARC/TokLIP/blob/main/TokLIP_L_384.pt) |
| TokLIP-XL | 512 | [IBQ](https://huggingface.co/TencentARC/IBQ-Tokenizer-262144/blob/main/imagenet256_262144.ckpt) | 80.8 | 69.40 | 53.77 | [🤗 TokLIP_XL_512](https://huggingface.co/TencentARC/TokLIP/blob/main/TokLIP_XL_512.pt) |
### Training
1. Please refer to [img2dataset](https://github.com/rom1504/img2dataset) to prepare the WebDataset required for training. You may choose datasets such as **CC3M**, **CC12M**, or **LAION**.
2. Prepare the teacher models using `src/covert.py`:
```bash
cd src
TIMM_MODEL='original' python covert.py --model_name 'ViT-SO400M-16-SigLIP2-256' --save_path './model/siglip2-so400m-vit-l16-256.pt'
TIMM_MODEL='original' python covert.py --model_name 'ViT-SO400M-16-SigLIP2-384' --save_path './model/siglip2-so400m-vit-l16-384.pt'
```
3. Train TokLIP using the scripts `src\train_toklip_256.sh` and `src\train_toklip_384.sh`. You need to set `--train-data` and `--train-num-samples` arguments accordingly.
### Evaluation
Please first download the TokLIP model weights.
We provide the evaluation scripts for ImageNet classification and MSCOCO Retrieval in `src\test_toklip_256.sh`, `src\test_toklip_384.sh`, and `src\test_toklip_512.sh`.
Please revise the `--pretrained`, `--imagenet-val`, and `--coco-dir` with your specific paths.
### Inference
We provide the inference example in `src/inference.py`.
```shell
cd src
python inference.py --model-config 'ViT-SO400M-16-SigLIP2-384-toklip' --pretrained 'YOUR_TOKLIP_PATH'
```
### Model Usage
We provide `build_toklip_encoder` function in `src/create_toklip.py`, you could directly load TokLIP with `model`, `image_size`, and `model_path` parameters.
## 🔜 TODOs
- [x] Release training codes.
- [x] Release TokLIP-XL with 512 resolution.
## 📂 Contact
If you have further questions, please open an issue or contact .
Discussions and potential collaborations are also welcome.
## 🙏 Acknowledgement
This repo is built upon the following projects:
* [OpenCLIP](https://github.com/mlfoundations/open_clip)
* [LlamaGen](https://github.com/FoundationVision/LlamaGen)
* [DeCLIP](https://github.com/Sense-GVT/DeCLIP)
* [SEED-Voken](https://github.com/TencentARC/SEED-Voken)
We thank the authors for their codes.
## 📝 Citation
Please cite our work if you use our code or discuss our findings in your own research:
```bibtex
@article{lin2025toklip,
title={Toklip: Marry visual tokens to clip for multimodal comprehension and generation},
author={Lin, Haokun and Wang, Teng and Ge, Yixiao and Ge, Yuying and Lu, Zhichao and Wei, Ying and Zhang, Qingfu and Sun, Zhenan and Shan, Ying},
journal={arXiv preprint arXiv:2505.05422},
year={2025}
}
```
- We introduce TokLIP, a visual tokenizer that enhances comprehension by **semanticizing** vector-quantized (VQ) tokens and **incorporating CLIP-level semantics** while enabling end-to-end multimodal autoregressive training with standard VQ tokens.
- TokLIP integrates a low-level discrete VQ tokenizer with a ViT-based token encoder to capture high-level continuous semantics.
- Unlike previous approaches (e.g., VILA-U) that *discretize high-level features*, TokLIP **disentangles training objectives for comprehension and generation**, allowing the direct application of advanced VQ tokenizers without the need for tailored quantization operations.
## 🔧 Installation
```bash
conda create -n toklip python=3.10 -y
conda activate toklip
git clone https://github.com/TencentARC/TokLIP
pip install --upgrade pip
pip install -r requirements.txt
```
## ⚙️ Usage
### Model Weight
| Model | Resolution | VQGAN | IN Top1 | COCO TR@1 | COCO IR@1 | Weight |
| :-------: | :--------: | :----------------------------------------------------------: | :-----: | :-------: | :-------: | :----------------------------------------------------------: |
| TokLIP-S | 256 | [LlamaGen](https://huggingface.co/peizesun/llamagen_t2i/blob/main/vq_ds16_t2i.pt) | 76.4 | 64.06 | 48.46 | [🤗 TokLIP_S_256](https://huggingface.co/TencentARC/TokLIP/blob/main/TokLIP_S_256.pt) |
| TokLIP-L | 384 | [LlamaGen](https://huggingface.co/peizesun/llamagen_t2i/blob/main/vq_ds16_t2i.pt) | 80.0 | 68.00 | 52.87 | [🤗 TokLIP_L_384](https://huggingface.co/TencentARC/TokLIP/blob/main/TokLIP_L_384.pt) |
| TokLIP-XL | 512 | [IBQ](https://huggingface.co/TencentARC/IBQ-Tokenizer-262144/blob/main/imagenet256_262144.ckpt) | 80.8 | 69.40 | 53.77 | [🤗 TokLIP_XL_512](https://huggingface.co/TencentARC/TokLIP/blob/main/TokLIP_XL_512.pt) |
### Training
1. Please refer to [img2dataset](https://github.com/rom1504/img2dataset) to prepare the WebDataset required for training. You may choose datasets such as **CC3M**, **CC12M**, or **LAION**.
2. Prepare the teacher models using `src/covert.py`:
```bash
cd src
TIMM_MODEL='original' python covert.py --model_name 'ViT-SO400M-16-SigLIP2-256' --save_path './model/siglip2-so400m-vit-l16-256.pt'
TIMM_MODEL='original' python covert.py --model_name 'ViT-SO400M-16-SigLIP2-384' --save_path './model/siglip2-so400m-vit-l16-384.pt'
```
3. Train TokLIP using the scripts `src\train_toklip_256.sh` and `src\train_toklip_384.sh`. You need to set `--train-data` and `--train-num-samples` arguments accordingly.
### Evaluation
Please first download the TokLIP model weights.
We provide the evaluation scripts for ImageNet classification and MSCOCO Retrieval in `src\test_toklip_256.sh`, `src\test_toklip_384.sh`, and `src\test_toklip_512.sh`.
Please revise the `--pretrained`, `--imagenet-val`, and `--coco-dir` with your specific paths.
### Inference
We provide the inference example in `src/inference.py`.
```shell
cd src
python inference.py --model-config 'ViT-SO400M-16-SigLIP2-384-toklip' --pretrained 'YOUR_TOKLIP_PATH'
```
### Model Usage
We provide `build_toklip_encoder` function in `src/create_toklip.py`, you could directly load TokLIP with `model`, `image_size`, and `model_path` parameters.
## 🔜 TODOs
- [x] Release training codes.
- [x] Release TokLIP-XL with 512 resolution.
## 📂 Contact
If you have further questions, please open an issue or contact .
Discussions and potential collaborations are also welcome.
## 🙏 Acknowledgement
This repo is built upon the following projects:
* [OpenCLIP](https://github.com/mlfoundations/open_clip)
* [LlamaGen](https://github.com/FoundationVision/LlamaGen)
* [DeCLIP](https://github.com/Sense-GVT/DeCLIP)
* [SEED-Voken](https://github.com/TencentARC/SEED-Voken)
We thank the authors for their codes.
## 📝 Citation
Please cite our work if you use our code or discuss our findings in your own research:
```bibtex
@article{lin2025toklip,
title={Toklip: Marry visual tokens to clip for multimodal comprehension and generation},
author={Lin, Haokun and Wang, Teng and Ge, Yixiao and Ge, Yuying and Lu, Zhichao and Wei, Ying and Zhang, Qingfu and Sun, Zhenan and Shan, Ying},
journal={arXiv preprint arXiv:2505.05422},
year={2025}
}
```