Green-VLA: Staged Vision-Language-Action Model for Generalist Robots























Abstract
Green-VLA is a five-stage vision-language-action framework for real-world robot deployment that achieves generalization across different robot embodiments through multimodal training and reinforcement learning.
We introduce Green-VLA, a staged Vision-Language-Action (VLA) framework for real-world deployment on the Green humanoid robot while maintaining generalization across diverse embodiments. Green-VLA follows a five stage curriculum: (L0) foundational VLMs, (L1) multimodal grounding, (R0) multi-embodiment pretraining, (R1) embodiment-specific adaptation, and (R2) reinforcement-learning (RL) policy alignment. We couple a scalable data-processing pipeline (3,000 hours of demonstrations) with temporal alignment and quality filtering, and use a unified, embodiment-aware action interface enabling a single policy to control humanoids, mobile manipulators, and fixed-base arms. At inference, the VLA controller is enhanced with episode-progress prediction, out-of-distribution detection, and joint-prediction-based guidance to improve safety and precise target selection. Experiments on Simpler BRIDGE WidowX and CALVIN ABC-D, as well as real-robot evaluations, show strong generalization and performance gains from RL alignment in success rate, robustness, and long-horizon efficiency.
Community
TL;DR: Scaling VLA isn’t enough—you need quality-aligned trajectories + a unified action interface + staged RL refinement to get reliable cross-robot generalization. This work (1) introduces a unified R64 action space with a fixed semantic layout plus embodiment/control-type prompts and a masked BC loss so unused DoFs don’t inject spurious gradients, (2) normalizes heterogeneous demonstration speeds via optical-flow–based temporal resampling to align motion statistics across datasets, and (3) follows a staged recipe R0 → R1 → R2, where R2 RL alignment explicitly targets long-horizon consistency and error recovery. On real bimanual table cleaning (ALOHA), it reaches 69.5% first-item success vs 35.6% for the baseline and is ~2× faster (1m35s vs 2m59s). On Simpler (Google Robot), performance improves from 60.2 (R0) to 71.8 (R2). A nice practical touch: an episode-end prediction head reduces “post-success fidgeting” that can flip successes into failures.
Project Page: https://greenvla.github.io/
Code: https://github.com/greenvla/GreenVLA

This is an automated message from the Librarian Bot. I found the following papers similar to this paper.
The following papers were recommended by the Semantic Scholar API
- Being-H0.5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization (2026)
- Clutter-Resistant Vision-Language-Action Models through Object-Centric and Geometry Grounding (2025)
- PALM: Progress-Aware Policy Learning via Affordance Reasoning for Long-Horizon Robotic Manipulation (2026)
- GR-Dexter Technical Report (2025)
- Mind to Hand: Purposeful Robotic Control via Embodied Reasoning (2025)
- CLAP: Contrastive Latent Action Pretraining for Learning Vision-Language-Action Models from Human Videos (2026)
- Robotic VLA Benefits from Joint Learning with Motion Image Diffusion (2025)
Please give a thumbs up to this comment if you found it helpful!
If you want recommendations for any Paper on Hugging Face checkout this Space
You can directly ask Librarian Bot for paper recommendations by tagging it in a comment:
@librarian-bot
recommend

Hello, colleagues! Cool job! I have a question for you: is it possible to put your approach in code on Unitree G1, or will it require a change in the codebase/pipeline logic?
Hi @thorin072 ,
Thanks for your kind words and interest in our work—glad you found it cool!
To answer your question: Our R0 dataset didn't include Unitree G1 data, so the current model isn’t directly trained on G1 embodiment. However, to adapt it for controlling a G1 robot, you'd minimally need to go through the R1 stage (or R1+R2 for best results). This is quite realistic and resource‑efficient, as it builds directly on our existing pipeline without major codebase changes.
We're actively expanding our pretraining datasets right now, so we'd be happy to discuss potential collaboration on integrating G1 data. If G1 trajectories are included in a future R0 release, the model should be able to operate with the G1 embodiment out of the box.



The main results of Green-VLA demonstrate that a staged training pipeline emphasizing quality alignment, unified action spaces, and RL refinement outperforms raw scaling approaches across diverse embodiments and benchmarks.
1. R0: General Robotics Pretraining
Green-VLA achieves strong zero-shot performance after the general robotics pretraining phase (R0), despite using only ~3,000 hours of unified data compared to >10,000 hours in competing models like π₀.
ALOHA Table-Cleaning (Bimanual Manipulation)
On the AgileX Magic Cobot platform (Figure 9), Green-VLA(R0) significantly outperforms foundation models including π₀, GR00T N1, WALL-OSS, and AgiBot GO-1 on instruction-following accuracy and execution speed:
| Policy | Tape SR (%) | Screwdrivers SR (%) | Pliers SR (%) | First Item SR (%) | Avg Time |
|---|---|---|---|---|---|
| π₀ | 46.3 | 29.7 | 31.8 | 35.6 | 2m 59s |
| GR00T N1 | 38.9 | 35.4 | 29.5 | 33.2 | >5m |
| Green-VLA(R0) | 83.1 | 52.1 | 63.7 | 69.5 | 1m 35s |



Simpler Benchmarks
On Google Robot tasks (Table 3), Green-VLA(R0) achieves 60.2% average success, outperforming OpenVLA (33.8%) and approaching π₀ fine-tuned (56.8%). On WidowX (Table 4), R0 achieves 75.0% pick success, exceeding Flower (42.4%) and OpenVLA (14.5%).
2. R1: Embodiment Specialization & Guidance
E-Commerce Shelf Picking with JPM
The Joint Prediction Module (JPM) with flow-matching guidance significantly improves precise target acquisition for fine-grained discrimination tasks (e.g., distinguishing specific SKUs on shelves). As shown in Figure 11, JPM guidance provides substantial gains particularly for Out-of-Distribution (OOD) items and exact SKU matching:


Humanoid Evaluation
On the Green humanoid robot (32 DoF upper body), the R1 policy successfully handles:
- Bimanual manipulation with dexterous hands
- Instruction-conditioned picking/placing with correct arm selection
- OOD scene layouts and fruit sorting tasks


3. R2: RL Alignment Gains
The RL alignment stage (R2) produces the largest performance improvements, particularly for long-horizon tasks and difficult dexterous manipulation.
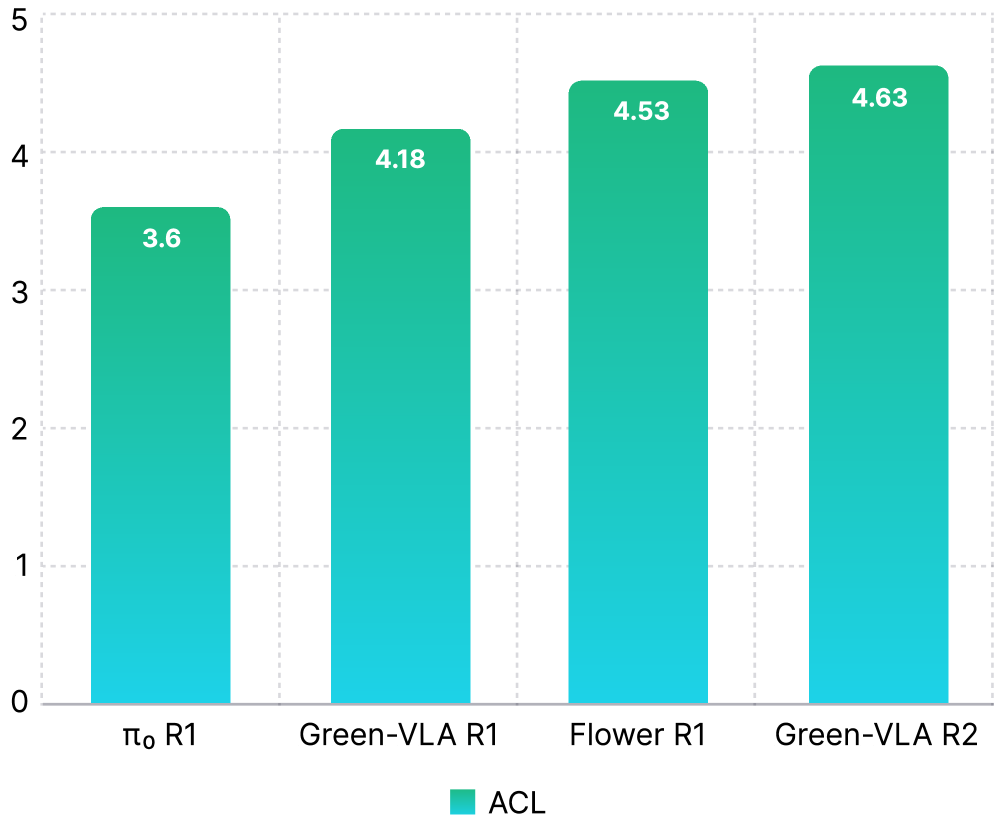
CALVIN ABC→D Benchmark
R2 improves the Average Chain Length (ACL)—measuring sequential task completion—from R1 levels to exceed π₀ and Flower, demonstrating superior long-horizon consistency and error recovery:
Simpler WidowX
R2 alignment improves success rates by an absolute 24% over R1 (Table 4), achieving 91.7% pick success compared to R1's 76.1% and R0's 75.0%.
| Model | Pick Success (%) | Grasp Success (%) |
|---|---|---|
| Green-VLA (R0) | 75.0 | 45.0 |
| Green-VLA (R1) | 76.1 | 55.2 |
| Green-VLA (R2) | 91.7 | 79.1 |
| π₀ (Fine-tune) | 53.1 | 27.1 |
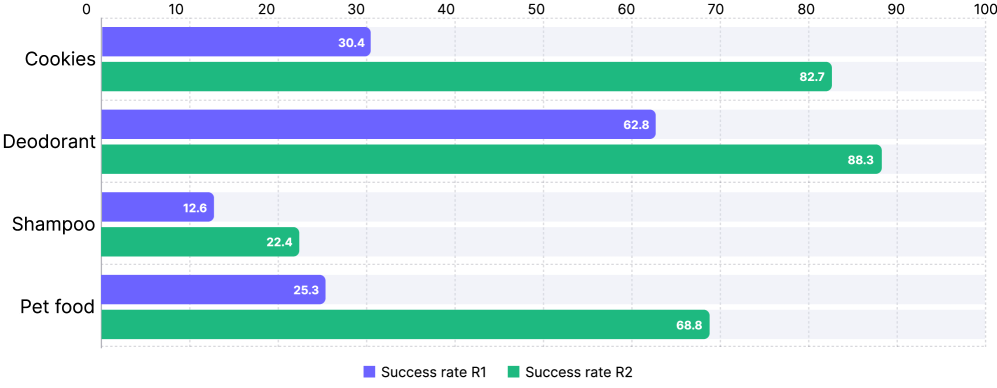
E-Commerce Physical Grasping
R2 optimization of success-conditioned rewards improves grasp reliability for challenging objects (deformable packaging, odd shapes), as shown in Figure 14a:
Key Architectural Contributions Validated
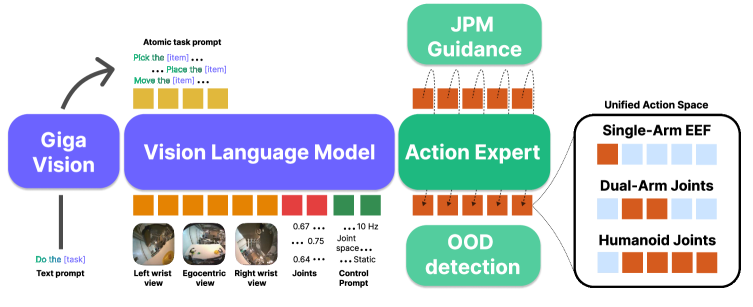
- Unified Action Space: The semantic slot layout (Figure 1) enables positive transfer across humanoids, dual-arm platforms, and single-arm manipulators without architectural changes.
DataQA Pipeline: Quality filtering using jitter (J), sharpness (S), diversity (D), and variance (σ²) metrics enables superior sample efficiency—achieving better results with 3,000 hours than competitors with 10,000+ hours.
Staged Training Recipe: The progression L0→L1→R0→R1→R2 provides clear performance gains at each phase, with R2 RL alignment delivering state-of-the-art results on Simpler BRIDGE WidowX and competitive performance on CALVIN ABC→D.


Models citing this paper 0
No model linking this paper
Datasets citing this paper 0
No dataset linking this paper
Spaces citing this paper 0
No Space linking this paper