+
+
+
+
+ +Below is the original readme. + +---------------------------------------------------------- + + +# animatediff +[](https://results.pre-commit.ci/latest/github/neggles/animatediff-cli/main) + +animatediff refactor, ~~because I can.~~ with significantly lower VRAM usage. + +Also, **infinite generation length support!** yay! + +# LoRA loading is ABSOLUTELY NOT IMPLEMENTED YET! + +This can theoretically run on CPU, but it's not recommended. Should work fine on a GPU, nVidia or otherwise, +but I haven't tested on non-CUDA hardware. Uses PyTorch 2.0 Scaled-Dot-Product Attention (aka builtin xformers) +by default, but you can pass `--xformers` to force using xformers if you *really* want. + +### How To Use + +1. Lie down +2. Try not to cry +3. Cry a lot + +### but for real? + +Okay, fine. But it's still a little complicated and there's no webUI yet. + +```sh +git clone https://github.com/neggles/animatediff-cli +cd animatediff-cli +python3.10 -m venv .venv +source .venv/bin/activate +# install Torch. Use whatever your favourite torch version >= 2.0.0 is, but, good luck on non-nVidia... +python -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 +# install the rest of all the things (probably! I may have missed some deps.) +python -m pip install -e '.[dev]' +# you should now be able to +animatediff --help +# There's a nice pretty help screen with a bunch of info that'll print here. +``` + +From here you'll need to put whatever checkpoint you want to use into `data/models/sd`, copy +one of the prompt configs in `config/prompts`, edit it with your choices of prompt and model (model +paths in prompt .json files are **relative to `data/`**, e.g. `models/sd/vanilla.safetensors`), and +off you go. + +Then it's something like (for an 8GB card): +```sh +animatediff generate -c 'config/prompts/waifu.json' -W 576 -H 576 -L 128 -C 16 +``` +You may have to drop `-C` down to 8 on cards with less than 8GB VRAM, and you can raise it to 20-24 +on cards with more. 24 is max. + +N.B. generating 128 frames is _**slow...**_ + +## RiFE! + +I have added experimental support for [rife-ncnn-vulkan](https://github.com/nihui/rife-ncnn-vulkan) +using the `animatediff rife interpolate` command. It has fairly self-explanatory help, and it has +been tested on Linux, but I've **no idea** if it'll work on Windows. + +Either way, you'll need ffmpeg installed on your system and present in PATH, and you'll need to +download the rife-ncnn-vulkan release for your OS of choice from the GitHub repo (above). Unzip it, and +place the extracted folder at `data/rife/`. You should have a `data/rife/rife-ncnn-vulkan` executable, or `data\rife\rife-ncnn-vulkan.exe` on Windows. + +You'll also need to reinstall the repo/package with: +```py +python -m pip install -e '.[rife]' +``` +or just install `ffmpeg-python` manually yourself. + +Default is to multiply each frame by 8, turning an 8fps animation into a 64fps one, then encode +that to a 60fps WebM. (If you pick GIF mode, it'll be 50fps, because GIFs are cursed and encode +frame durations as 1/100ths of a second). + +Seems to work pretty well... + +## TODO: + +In no particular order: + +- [x] Infinite generation length support +- [x] RIFE support for motion interpolation (`rife-ncnn-vulkan` isn't the greatest implementation) +- [x] Export RIFE interpolated frames to a video file (webm, mp4, animated webp, hevc mp4, gif, etc.) +- [x] Generate infinite length animations on a 6-8GB card (at 512x512 with 8-frame context, but hey it'll do) +- [x] Torch SDP Attention (makes xformers optional) +- [x] Support for `clip_skip` in prompt config +- [x] Experimental support for `torch.compile()` (upstream Diffusers bugs slow this down a little but it's still zippy) +- [x] Batch your generations with `--repeat`! (e.g. `--repeat 10` will repeat all your prompts 10 times) +- [x] Call the `animatediff.cli.generate()` function from another Python program without reloading the model every time +- [x] Drag remaining old Diffusers code up to latest (mostly) +- [ ] Add a webUI (maybe, there are people wrapping this already so maybe not?) +- [ ] img2img support (start from an existing image and continue) +- [ ] Stop using custom modules where possible (should be able to use Diffusers for almost all of it) +- [ ] Automatic generate-then-interpolate-with-RIFE mode + +## Credits: + +see [guoyww/AnimateDiff](https://github.com/guoyww/AnimateDiff) (very little of this is my work) + +n.b. the copyright notice in `COPYING` is missing the original authors' names, solely because +the original repo (as of this writing) has no name attached to the license. I have, however, +used the same license they did (Apache 2.0). diff --git a/animate/config/.gitignore b/animate/config/.gitignore new file mode 100644 index 0000000000000000000000000000000000000000..c3dc93669d6beb75ff4e01ebb6fbec49547eb68b --- /dev/null +++ b/animate/config/.gitignore @@ -0,0 +1,4 @@ +/* +!.gitignore +!/inference/ +!/prompts/ diff --git a/animate/config/GroundingDINO/GroundingDINO_SwinB_cfg.py b/animate/config/GroundingDINO/GroundingDINO_SwinB_cfg.py new file mode 100644 index 0000000000000000000000000000000000000000..f490c4bbd598a35de43d36ceafcbd769e7ff21bf --- /dev/null +++ b/animate/config/GroundingDINO/GroundingDINO_SwinB_cfg.py @@ -0,0 +1,43 @@ +batch_size = 1 +modelname = "groundingdino" +backbone = "swin_B_384_22k" +position_embedding = "sine" +pe_temperatureH = 20 +pe_temperatureW = 20 +return_interm_indices = [1, 2, 3] +backbone_freeze_keywords = None +enc_layers = 6 +dec_layers = 6 +pre_norm = False +dim_feedforward = 2048 +hidden_dim = 256 +dropout = 0.0 +nheads = 8 +num_queries = 900 +query_dim = 4 +num_patterns = 0 +num_feature_levels = 4 +enc_n_points = 4 +dec_n_points = 4 +two_stage_type = "standard" +two_stage_bbox_embed_share = False +two_stage_class_embed_share = False +transformer_activation = "relu" +dec_pred_bbox_embed_share = True +dn_box_noise_scale = 1.0 +dn_label_noise_ratio = 0.5 +dn_label_coef = 1.0 +dn_bbox_coef = 1.0 +embed_init_tgt = True +dn_labelbook_size = 2000 +max_text_len = 256 +text_encoder_type = "bert-base-uncased" +use_text_enhancer = True +use_fusion_layer = True +use_checkpoint = True +use_transformer_ckpt = True +use_text_cross_attention = True +text_dropout = 0.0 +fusion_dropout = 0.0 +fusion_droppath = 0.1 +sub_sentence_present = True diff --git a/animate/config/GroundingDINO/GroundingDINO_SwinT_OGC.py b/animate/config/GroundingDINO/GroundingDINO_SwinT_OGC.py new file mode 100644 index 0000000000000000000000000000000000000000..9158d5f6260ec74bded95377d382387430d7cd70 --- /dev/null +++ b/animate/config/GroundingDINO/GroundingDINO_SwinT_OGC.py @@ -0,0 +1,43 @@ +batch_size = 1 +modelname = "groundingdino" +backbone = "swin_T_224_1k" +position_embedding = "sine" +pe_temperatureH = 20 +pe_temperatureW = 20 +return_interm_indices = [1, 2, 3] +backbone_freeze_keywords = None +enc_layers = 6 +dec_layers = 6 +pre_norm = False +dim_feedforward = 2048 +hidden_dim = 256 +dropout = 0.0 +nheads = 8 +num_queries = 900 +query_dim = 4 +num_patterns = 0 +num_feature_levels = 4 +enc_n_points = 4 +dec_n_points = 4 +two_stage_type = "standard" +two_stage_bbox_embed_share = False +two_stage_class_embed_share = False +transformer_activation = "relu" +dec_pred_bbox_embed_share = True +dn_box_noise_scale = 1.0 +dn_label_noise_ratio = 0.5 +dn_label_coef = 1.0 +dn_bbox_coef = 1.0 +embed_init_tgt = True +dn_labelbook_size = 2000 +max_text_len = 256 +text_encoder_type = "bert-base-uncased" +use_text_enhancer = True +use_fusion_layer = True +use_checkpoint = True +use_transformer_ckpt = True +use_text_cross_attention = True +text_dropout = 0.0 +fusion_dropout = 0.0 +fusion_droppath = 0.1 +sub_sentence_present = True diff --git a/animate/config/inference/default.json b/animate/config/inference/default.json new file mode 100644 index 0000000000000000000000000000000000000000..9c33560882502c6bf73f8eddd958da82ce97b969 --- /dev/null +++ b/animate/config/inference/default.json @@ -0,0 +1,27 @@ +{ + "unet_additional_kwargs": { + "unet_use_cross_frame_attention": false, + "unet_use_temporal_attention": false, + "use_motion_module": true, + "motion_module_resolutions": [1, 2, 4, 8], + "motion_module_mid_block": false, + "motion_module_decoder_only": false, + "motion_module_type": "Vanilla", + "motion_module_kwargs": { + "num_attention_heads": 8, + "num_transformer_block": 1, + "attention_block_types": ["Temporal_Self", "Temporal_Self"], + "temporal_position_encoding": true, + "temporal_position_encoding_max_len": 24, + "temporal_attention_dim_div": 1 + } + }, + "noise_scheduler_kwargs": { + "num_train_timesteps": 1000, + "beta_start": 0.00085, + "beta_end": 0.012, + "beta_schedule": "linear", + "steps_offset": 1, + "clip_sample": false + } +} diff --git a/animate/config/inference/motion_sdxl.json b/animate/config/inference/motion_sdxl.json new file mode 100644 index 0000000000000000000000000000000000000000..bf6158d41e382ce9e5cdbb0421369c2d599b1189 --- /dev/null +++ b/animate/config/inference/motion_sdxl.json @@ -0,0 +1,23 @@ +{ + "unet_additional_kwargs": { + "unet_use_temporal_attention": false, + "use_motion_module": true, + "motion_module_resolutions": [1, 2, 4, 8], + "motion_module_mid_block": false, + "motion_module_type": "Vanilla", + "motion_module_kwargs": { + "num_attention_heads": 8, + "num_transformer_block": 1, + "attention_block_types": ["Temporal_Self", "Temporal_Self"], + "temporal_position_encoding": true, + "temporal_position_encoding_max_len": 32, + "temporal_attention_dim_div": 1 + } + }, + "noise_scheduler_kwargs": { + "num_train_timesteps": 1000, + "beta_start": 0.00085, + "beta_end": 0.020, + "beta_schedule": "scaled_linear" + } +} diff --git a/animate/config/inference/motion_v2.json b/animate/config/inference/motion_v2.json new file mode 100644 index 0000000000000000000000000000000000000000..174a8fa36c12b9a645d91cb426076330e93c961c --- /dev/null +++ b/animate/config/inference/motion_v2.json @@ -0,0 +1,28 @@ +{ + "unet_additional_kwargs": { + "use_inflated_groupnorm": true, + "unet_use_cross_frame_attention": false, + "unet_use_temporal_attention": false, + "use_motion_module": true, + "motion_module_resolutions": [1, 2, 4, 8], + "motion_module_mid_block": true, + "motion_module_decoder_only": false, + "motion_module_type": "Vanilla", + "motion_module_kwargs": { + "num_attention_heads": 8, + "num_transformer_block": 1, + "attention_block_types": ["Temporal_Self", "Temporal_Self"], + "temporal_position_encoding": true, + "temporal_position_encoding_max_len": 32, + "temporal_attention_dim_div": 1 + } + }, + "noise_scheduler_kwargs": { + "num_train_timesteps": 1000, + "beta_start": 0.00085, + "beta_end": 0.012, + "beta_schedule": "linear", + "steps_offset": 1, + "clip_sample": false + } +} diff --git a/animate/config/inference/sd15-unet.json b/animate/config/inference/sd15-unet.json new file mode 100644 index 0000000000000000000000000000000000000000..6db217f3331db78e6daf0a8f46f12e4529de3fdf --- /dev/null +++ b/animate/config/inference/sd15-unet.json @@ -0,0 +1,89 @@ +{ + "sample_size": 64, + "in_channels": 4, + "out_channels": 4, + "center_input_sample": false, + "flip_sin_to_cos": true, + "freq_shift": 0, + "down_block_types": [ + "CrossAttnDownBlock2D", + "CrossAttnDownBlock2D", + "CrossAttnDownBlock2D", + "DownBlock2D" + ], + "mid_block_type": "UNetMidBlock2DCrossAttn", + "up_block_types": [ + "UpBlock2D", + "CrossAttnUpBlock2D", + "CrossAttnUpBlock2D", + "CrossAttnUpBlock2D" + ], + "only_cross_attention": false, + "block_out_channels": [320, 640, 1280, 1280], + "layers_per_block": 2, + "downsample_padding": 1, + "mid_block_scale_factor": 1, + "act_fn": "silu", + "norm_num_groups": 32, + "norm_eps": 1e-5, + "cross_attention_dim": 768, + "transformer_layers_per_block": 1, + "encoder_hid_dim": null, + "encoder_hid_dim_type": null, + "attention_head_dim": 8, + "num_attention_heads": null, + "dual_cross_attention": false, + "use_linear_projection": false, + "class_embed_type": null, + "addition_embed_type": null, + "addition_time_embed_dim": null, + "num_class_embeds": null, + "upcast_attention": false, + "resnet_time_scale_shift": "default", + "resnet_skip_time_act": false, + "resnet_out_scale_factor": 1.0, + "time_embedding_type": "positional", + "time_embedding_dim": null, + "time_embedding_act_fn": null, + "timestep_post_act": null, + "time_cond_proj_dim": null, + "conv_in_kernel": 3, + "conv_out_kernel": 3, + "projection_class_embeddings_input_dim": null, + "class_embeddings_concat": false, + "mid_block_only_cross_attention": null, + "cross_attention_norm": null, + "addition_embed_type_num_heads": 64, + "_use_default_values": [ + "transformer_layers_per_block", + "use_linear_projection", + "num_class_embeds", + "addition_embed_type", + "cross_attention_norm", + "conv_out_kernel", + "encoder_hid_dim_type", + "projection_class_embeddings_input_dim", + "num_attention_heads", + "only_cross_attention", + "class_embed_type", + "resnet_time_scale_shift", + "addition_embed_type_num_heads", + "timestep_post_act", + "mid_block_type", + "mid_block_only_cross_attention", + "time_embedding_type", + "addition_time_embed_dim", + "time_embedding_dim", + "encoder_hid_dim", + "resnet_skip_time_act", + "conv_in_kernel", + "upcast_attention", + "dual_cross_attention", + "resnet_out_scale_factor", + "time_cond_proj_dim", + "class_embeddings_concat", + "time_embedding_act_fn" + ], + "_class_name": "UNet2DConditionModel", + "_diffusers_version": "0.6.0" +} diff --git a/animate/config/inference/sd15-unet3d.json b/animate/config/inference/sd15-unet3d.json new file mode 100644 index 0000000000000000000000000000000000000000..bda0b03d27577e4384bdbc1b0d4e126a08b79f03 --- /dev/null +++ b/animate/config/inference/sd15-unet3d.json @@ -0,0 +1,64 @@ +{ + "sample_size": 64, + "in_channels": 4, + "out_channels": 4, + "center_input_sample": false, + "flip_sin_to_cos": true, + "freq_shift": 0, + "down_block_types": [ + "CrossAttnDownBlock3D", + "CrossAttnDownBlock3D", + "CrossAttnDownBlock3D", + "DownBlock3D" + ], + "mid_block_type": "UNetMidBlock3DCrossAttn", + "up_block_types": [ + "UpBlock3D", + "CrossAttnUpBlock3D", + "CrossAttnUpBlock3D", + "CrossAttnUpBlock3D" + ], + "only_cross_attention": false, + "block_out_channels": [320, 640, 1280, 1280], + "layers_per_block": 2, + "downsample_padding": 1, + "mid_block_scale_factor": 1, + "act_fn": "silu", + "norm_num_groups": 32, + "norm_eps": 1e-5, + "cross_attention_dim": 768, + "attention_head_dim": 8, + "dual_cross_attention": false, + "use_linear_projection": false, + "class_embed_type": null, + "num_class_embeds": null, + "upcast_attention": false, + "resnet_time_scale_shift": "default", + "use_motion_module": true, + "motion_module_resolutions": [1, 2, 4, 8], + "motion_module_mid_block": false, + "motion_module_decoder_only": false, + "motion_module_type": "Vanilla", + "motion_module_kwargs": { + "num_attention_heads": 8, + "num_transformer_block": 1, + "attention_block_types": ["Temporal_Self", "Temporal_Self"], + "temporal_position_encoding": true, + "temporal_position_encoding_max_len": 24, + "temporal_attention_dim_div": 1 + }, + "unet_use_cross_frame_attention": false, + "unet_use_temporal_attention": false, + "_use_default_values": [ + "use_linear_projection", + "mid_block_type", + "upcast_attention", + "dual_cross_attention", + "num_class_embeds", + "only_cross_attention", + "class_embed_type", + "resnet_time_scale_shift" + ], + "_class_name": "UNet3DConditionModel", + "_diffusers_version": "0.6.0" +} diff --git a/animate/config/prompts/.gitignore b/animate/config/prompts/.gitignore new file mode 100644 index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d --- /dev/null +++ b/animate/config/prompts/.gitignore @@ -0,0 +1,2 @@ +* +!.gitignore diff --git a/animate/config/prompts/01-ToonYou.json b/animate/config/prompts/01-ToonYou.json new file mode 100644 index 0000000000000000000000000000000000000000..033fdd951b1df1397952785094f665fcc4d4564d --- /dev/null +++ b/animate/config/prompts/01-ToonYou.json @@ -0,0 +1,24 @@ +{ + "name": "ToonYou", + "base": "", + "path": "models/sd/toonyou_beta3.safetensors", + "motion_module": "models/motion-module/mm_sd_v15.ckpt", + "compile": false, + "seed": [ + 10788741199826055000, 6520604954829637000, 6519455744612556000, + 16372571278361864000 + ], + "scheduler": "k_dpmpp", + "steps": 30, + "guidance_scale": 8.5, + "clip_skip": 2, + "prompt": [ + "1girl, solo, best quality, masterpiece, looking at viewer, purple hair, orange hair, gradient hair, blurry background, upper body, dress, flower print, spaghetti strap, bare shoulders", + "1girl, solo, masterpiece, best quality, cherry blossoms, hanami, pink flower, white flower, spring season, wisteria, petals, flower, plum blossoms, outdoors, falling petals, white hair, black eyes,", + "1girl, solo, best quality, masterpiece, looking at viewer, purple hair, orange hair, gradient hair, blurry background, upper body, dress, flower print, spaghetti strap, bare shoulders", + "1girl, solo, best quality, masterpiece, cloudy sky, dandelion, contrapposto, alternate hairstyle" + ], + "n_prompt": [ + "worst quality, low quality, cropped, lowres, text, jpeg artifacts, multiple view" + ] +} diff --git a/animate/config/prompts/02-Lyriel.json b/animate/config/prompts/02-Lyriel.json new file mode 100644 index 0000000000000000000000000000000000000000..9dc50afc96ae3d3d9b1d14b8caf0fc7630ab72a6 --- /dev/null +++ b/animate/config/prompts/02-Lyriel.json @@ -0,0 +1,25 @@ +{ + "name": "Lyriel", + "base": "", + "path": "models/sd/lyriel_v16.safetensors", + "motion_module": "models/motion-module/mm_sd_v15.ckpt", + "seed": [ + 10917152860782582000, 6399018107401806000, 15875751942533906000, + 6653196880059937000 + ], + "scheduler": "k_dpmpp", + "steps": 25, + "guidance_scale": 7.5, + "prompt": [ + "dark shot, epic realistic, portrait of halo, sunglasses, blue eyes, tartan scarf, white hair by atey ghailan, by greg rutkowski, by greg tocchini, by james gilleard, by joe fenton, by kaethe butcher, gradient yellow, black, brown and magenta color scheme, grunge aesthetic!!! graffiti tag wall background, art by greg rutkowski and artgerm, soft cinematic light, adobe lightroom, photolab, hdr, intricate, highly detailed, depth of field, faded, neutral colors, hdr, muted colors, hyperdetailed, artstation, cinematic, warm lights, dramatic light, intricate details, complex background, rutkowski, teal and orange", + "A forbidden castle high up in the mountains, pixel art, intricate details2, hdr, intricate details, hyperdetailed5, natural skin texture, hyperrealism, soft light, sharp, game art, key visual, surreal", + "dark theme, medieval portrait of a man sharp features, grim, cold stare, dark colors, Volumetric lighting, baroque oil painting by Greg Rutkowski, Artgerm, WLOP, Alphonse Mucha dynamic lighting hyperdetailed intricately detailed, hdr, muted colors, complex background, hyperrealism, hyperdetailed, amandine van ray", + "As I have gone alone in there and with my treasures bold, I can keep my secret where and hint of riches new and old. Begin it where warm waters halt and take it in a canyon down, not far but too far to walk, put in below the home of brown." + ], + "n_prompt": [ + "3d, cartoon, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name, young, loli, elf, 3d, illustration", + "3d, cartoon, anime, sketches, worst quality, low quality, normal quality, lowres, normal quality, monochrome, grayscale, skin spots, acnes, skin blemishes, bad anatomy, girl, loli, young, large breasts, red eyes, muscular", + "dof, grayscale, black and white, bw, 3d, cartoon, anime, sketches, worst quality, low quality, normal quality, lowres, normal quality, monochrome, grayscale, skin spots, acnes, skin blemishes, bad anatomy, girl, loli, young, large breasts, red eyes, muscular,badhandsv5-neg, By bad artist -neg 1, monochrome", + "holding an item, cowboy, hat, cartoon, 3d, disfigured, bad art, deformed,extra limbs,close up,b&w, wierd colors, blurry, duplicate, morbid, mutilated, [out of frame], extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, out of frame, ugly, extra limbs, bad anatomy, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, mutated hands, fused fingers, too many fingers, long neck, Photoshop, video game, ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, 3d render" + ] +} diff --git a/animate/config/prompts/03-RcnzCartoon.json b/animate/config/prompts/03-RcnzCartoon.json new file mode 100644 index 0000000000000000000000000000000000000000..fcf0bf0a4e2c9ec9f03843ea8b24cd1af061a897 --- /dev/null +++ b/animate/config/prompts/03-RcnzCartoon.json @@ -0,0 +1,25 @@ +{ + "name": "RcnzCartoon", + "base": "", + "path": "models/sd/rcnzCartoon3d_v10.safetensors", + "motion_module": "models/motion-module/mm_sd_v15.ckpt", + "seed": [ + 16931037867122268000, 2094308009433392000, 4292543217695451000, + 15572665120852310000 + ], + "scheduler": "k_dpmpp", + "steps": 25, + "guidance_scale": 7.5, + "prompt": [ + "Jane Eyre with headphones, natural skin texture,4mm,k textures, soft cinematic light, adobe lightroom, photolab, hdr, intricate, elegant, highly detailed, sharp focus, cinematic look, soothing tones, insane details, intricate details, hyperdetailed, low contrast, soft cinematic light, dim colors, exposure blend, hdr, faded", + "close up Portrait photo of muscular bearded guy in a worn mech suit, light bokeh, intricate, steel metal [rust], elegant, sharp focus, photo by greg rutkowski, soft lighting, vibrant colors, masterpiece, streets, detailed face", + "absurdres, photorealistic, masterpiece, a 30 year old man with gold framed, aviator reading glasses and a black hooded jacket and a beard, professional photo, a character portrait, altermodern, detailed eyes, detailed lips, detailed face, grey eyes", + "a golden labrador, warm vibrant colours, natural lighting, dappled lighting, diffused lighting, absurdres, highres,k, uhd, hdr, rtx, unreal, octane render, RAW photo, photorealistic, global illumination, subsurface scattering" + ], + "n_prompt": [ + "deformed, distorted, disfigured, poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, mutated hands and fingers, disconnected limbs, mutation, mutated, ugly, disgusting, blurry, amputation", + "nude, cross eyed, tongue, open mouth, inside, 3d, cartoon, anime, sketches, worst quality, low quality, normal quality, lowres, normal quality, monochrome, grayscale, skin spots, acnes, skin blemishes, bad anatomy, red eyes, muscular", + "easynegative, cartoon, anime, sketches, necklace, earrings worst quality, low quality, normal quality, bad anatomy, bad hands, shiny skin, error, missing fingers, extra digit, fewer digits, jpeg artifacts, signature, watermark, username, blurry, chubby, anorectic, bad eyes, old, wrinkled skin, red skin, photograph By bad artist -neg, big eyes, muscular face,", + "beard, EasyNegative, lowres, chromatic aberration, depth of field, motion blur, blurry, bokeh, bad quality, worst quality, multiple arms, badhand" + ] +} diff --git a/animate/config/prompts/04-MajicMix.json b/animate/config/prompts/04-MajicMix.json new file mode 100644 index 0000000000000000000000000000000000000000..b462b5f19cf8299fb6afd0f178afd708aae84325 --- /dev/null +++ b/animate/config/prompts/04-MajicMix.json @@ -0,0 +1,25 @@ +{ + "name": "MajicMix", + "base": "", + "path": "models/sd/majicmixRealistic_v5Preview.safetensors", + "motion_module": "models/motion-module/mm_sd_v15.ckpt", + "seed": [ + 1572448948722921000, 1099474677988590700, 6488833139725636000, + 18339859844376519000 + ], + "scheduler": "k_dpmpp", + "steps": 25, + "guidance_scale": 7.5, + "prompt": [ + "1girl, offshoulder, light smile, shiny skin best quality, masterpiece, photorealistic", + "best quality, masterpiece, photorealistic, 1boy, 50 years old beard, dramatic lighting", + "best quality, masterpiece, photorealistic, 1girl, light smile, shirt with collars, waist up, dramatic lighting, from below", + "male, man, beard, bodybuilder, skinhead,cold face, tough guy, cowboyshot, tattoo, french windows, luxury hotel masterpiece, best quality, photorealistic" + ], + "n_prompt": [ + "ng_deepnegative_v1_75t, badhandv4, worst quality, low quality, normal quality, lowres, bad anatomy, bad hands, watermark, moles", + "nsfw, ng_deepnegative_v1_75t,badhandv4, worst quality, low quality, normal quality, lowres,watermark, monochrome", + "nsfw, ng_deepnegative_v1_75t,badhandv4, worst quality, low quality, normal quality, lowres,watermark, monochrome", + "nude, nsfw, ng_deepnegative_v1_75t, badhandv4, worst quality, low quality, normal quality, lowres, bad anatomy, bad hands, monochrome, grayscale watermark, moles, people" + ] +} diff --git a/animate/config/prompts/05-RealisticVision.json b/animate/config/prompts/05-RealisticVision.json new file mode 100644 index 0000000000000000000000000000000000000000..ba93d964c342f5de995047b1cc38a6bb1fe34db0 --- /dev/null +++ b/animate/config/prompts/05-RealisticVision.json @@ -0,0 +1,25 @@ +{ + "name": "RealisticVision", + "base": "", + "path": "models/sd/realisticVisionV20_v20.safetensors", + "motion_module": "models/motion-module/mm_sd_v15.ckpt", + "seed": [ + 5658137986800322000, 12099779162349365000, 10499524853910854000, + 16768009035333712000 + ], + "scheduler": "k_dpmpp", + "steps": 25, + "guidance_scale": 7.5, + "prompt": [ + "b&w photo of 42 y.o man in black clothes, bald, face, half body, body, high detailed skin, skin pores, coastline, overcast weather, wind, waves, 8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3", + "close up photo of a rabbit, forest, haze, halation, bloom, dramatic atmosphere, centred, rule of thirds, 200mm 1.4f macro shot", + "photo of coastline, rocks, storm weather, wind, waves, lightning, 8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3", + "night, b&w photo of old house, post apocalypse, forest, storm weather, wind, rocks, 8k uhd, dslr, soft lighting, high quality, film grain" + ], + "n_prompt": [ + "semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime, text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck", + "semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime, text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck", + "blur, haze, deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime, mutated hands and fingers, deformed, distorted, disfigured, poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, disconnected limbs, mutation, mutated, ugly, disgusting, amputation", + "blur, haze, deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime, art, mutated hands and fingers, deformed, distorted, disfigured, poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, disconnected limbs, mutation, mutated, ugly, disgusting, amputation" + ] +} diff --git a/animate/config/prompts/06-Tusun.json b/animate/config/prompts/06-Tusun.json new file mode 100644 index 0000000000000000000000000000000000000000..95e400d6ff4f848228adebbc87c8d64481b34e27 --- /dev/null +++ b/animate/config/prompts/06-Tusun.json @@ -0,0 +1,23 @@ +{ + "name": "Tusun", + "base": "models/sd/moonfilm_reality20.safetensors", + "path": "models/sd/TUSUN.safetensors", + "motion_module": "models/motion-module/mm_sd_v15.ckpt", + "seed": [ + 10154078483724687000, 2664393535095473700, 4231566096207623000, + 1713349740448094500 + ], + "scheduler": "k_dpmpp", + "steps": 25, + "guidance_scale": 7.5, + "lora_alpha": 0.6, + "prompt": [ + "tusuncub with its mouth open, blurry, open mouth, fangs, photo background, looking at viewer, tongue, full body, solo, cute and lovely, Beautiful and realistic eye details, perfect anatomy, Nonsense, pure background, Centered-Shot, realistic photo, photograph, 4k, hyper detailed, DSLR, 24 Megapixels, 8mm Lens, Full Frame, film grain, Global Illumination, studio Lighting, Award Winning Photography, diffuse reflection, ray tracing", + "cute tusun with a blurry background, black background, simple background, signature, face, solo, cute and lovely, Beautiful and realistic eye details, perfect anatomy, Nonsense, pure background, Centered-Shot, realistic photo, photograph, 4k, hyper detailed, DSLR, 24 Megapixels, 8mm Lens, Full Frame, film grain, Global Illumination, studio Lighting, Award Winning Photography, diffuse reflection, ray tracing", + "cut tusuncub walking in the snow, blurry, looking at viewer, depth of field, blurry background, full body, solo, cute and lovely, Beautiful and realistic eye details, perfect anatomy, Nonsense, pure background, Centered-Shot, realistic photo, photograph, 4k, hyper detailed, DSLR, 24 Megapixels, 8mm Lens, Full Frame, film grain, Global Illumination, studio Lighting, Award Winning Photography, diffuse reflection, ray tracing", + "character design, cyberpunk tusun kitten wearing astronaut suit, sci-fic, realistic eye color and details, fluffy, big head, science fiction, communist ideology, Cyborg, fantasy, intense angle, soft lighting, photograph, 4k, hyper detailed, portrait wallpaper, realistic, photo-realistic, DSLR, 24 Megapixels, Full Frame, vibrant details, octane render, finely detail, best quality, incredibly absurdres, robotic parts, rim light, vibrant details, luxurious cyberpunk, hyperrealistic, cable electric wires, microchip, full body" + ], + "n_prompt": [ + "worst quality, low quality, deformed, distorted, disfigured, bad eyes, bad anatomy, disconnected limbs, wrong body proportions, low quality, worst quality, text, watermark, signatre, logo, illustration, painting, cartoons, ugly, easy_negative" + ] +} diff --git a/animate/config/prompts/07-FilmVelvia.json b/animate/config/prompts/07-FilmVelvia.json new file mode 100644 index 0000000000000000000000000000000000000000..cf53c4fd1eeac864ceeba88b0af17003485d214f --- /dev/null +++ b/animate/config/prompts/07-FilmVelvia.json @@ -0,0 +1,26 @@ +{ + "name": "FilmVelvia", + "base": "models/sd/majicmixRealistic_v4.safetensors", + "path": "models/sd/FilmVelvia2.safetensors", + "motion_module": "models/motion-module/mm_sd_v15.ckpt", + "seed": [ + 358675358833372800, 3519455280971924000, 11684545350557985000, + 8696855302100400000 + ], + "scheduler": "k_dpmpp", + "steps": 25, + "guidance_scale": 7.5, + "lora_alpha": 0.6, + "prompt": [ + "a woman standing on the side of a road at night,girl, long hair, motor vehicle, car, looking at viewer, ground vehicle, night, hands in pockets, blurry background, coat, black hair, parted lips, bokeh, jacket, brown hair, outdoors, red lips, upper body, artist name", + ", dark shot,0mm, portrait quality of a arab man worker,boy, wasteland that stands out vividly against the background of the desert, barren landscape, closeup, moles skin, soft light, sharp, exposure blend, medium shot, bokeh, hdr, high contrast, cinematic, teal and orange5, muted colors, dim colors, soothing tones, low saturation, hyperdetailed, noir", + "fashion photography portrait of 1girl, offshoulder, fluffy short hair, soft light, rim light, beautiful shadow, low key, photorealistic, raw photo, natural skin texture, realistic eye and face details, hyperrealism, ultra high res, 4K, Best quality, masterpiece, necklace, cleavage, in the dark", + "In this lighthearted portrait, a woman is dressed as a fierce warrior, armed with an arsenal of paintbrushes and palette knives. Her war paint is composed of thick, vibrant strokes of color, and her armor is made of paint tubes and paint-splattered canvases. She stands victoriously atop a mountain of conquered blank canvases, with a beautiful, colorful landscape behind her, symbolizing the power of art and creativity. bust Portrait, close-up, Bright and transparent scene lighting, " + ], + "n_prompt": [ + "cartoon, anime, sketches,worst quality, low quality, deformed, distorted, disfigured, bad eyes, wrong lips, weird mouth, bad teeth, mutated hands and fingers, bad anatomy, wrong anatomy, amputation, extra limb, missing limb, floating limbs, disconnected limbs, mutation, ugly, disgusting, bad_pictures, negative_hand-neg", + "cartoon, anime, sketches,worst quality, low quality, deformed, distorted, disfigured, bad eyes, wrong lips, weird mouth, bad teeth, mutated hands and fingers, bad anatomy, wrong anatomy, amputation, extra limb, missing limb, floating limbs, disconnected limbs, mutation, ugly, disgusting, bad_pictures, negative_hand-neg", + "wrong white balance, dark, cartoon, anime, sketches,worst quality, low quality, deformed, distorted, disfigured, bad eyes, wrong lips, weird mouth, bad teeth, mutated hands and fingers, bad anatomy, wrong anatomy, amputation, extra limb, missing limb, floating limbs, disconnected limbs, mutation, ugly, disgusting, bad_pictures, negative_hand-neg", + "wrong white balance, dark, cartoon, anime, sketches,worst quality, low quality, deformed, distorted, disfigured, bad eyes, wrong lips, weird mouth, bad teeth, mutated hands and fingers, bad anatomy, wrong anatomy, amputation, extra limb, missing limb, floating limbs, disconnected limbs, mutation, ugly, disgusting, bad_pictures, negative_hand-neg" + ] +} diff --git a/animate/config/prompts/08-GhibliBackground.json b/animate/config/prompts/08-GhibliBackground.json new file mode 100644 index 0000000000000000000000000000000000000000..fbe981aeed0a2a6d6f3ee15b5dd13c51c28cf553 --- /dev/null +++ b/animate/config/prompts/08-GhibliBackground.json @@ -0,0 +1,23 @@ +{ + "name": "GhibliBackground", + "base": "models/sd/CounterfeitV30_25.safetensors", + "path": "models/sd/lora_Ghibli_n3.safetensors", + "motion_module": "models/motion-module/mm_sd_v15.ckpt", + "seed": [ + 8775748474469046000, 5893874876080607000, 11911465742147697000, + 12437784838692000000 + ], + "scheduler": "k_dpmpp", + "steps": 25, + "guidance_scale": 7.5, + "lora_alpha": 1, + "prompt": [ + "best quality,single build,architecture, blue_sky, building,cloudy_sky, day, fantasy, fence, field, house, build,architecture,landscape, moss, outdoors, overgrown, path, river, road, rock, scenery, sky, sword, tower, tree, waterfall", + "black_border, building, city, day, fantasy, ice, landscape, letterboxed, mountain, ocean, outdoors, planet, scenery, ship, snow, snowing, water, watercraft, waterfall, winter", + ",mysterious sea area, fantasy,build,concept", + "Tomb Raider,Scenography,Old building" + ], + "n_prompt": [ + "easynegative,bad_construction,bad_structure,bad_wail,bad_windows,blurry,cloned_window,cropped,deformed,disfigured,error,extra_windows,extra_chimney,extra_door,extra_structure,extra_frame,fewer_digits,fused_structure,gross_proportions,jpeg_artifacts,long_roof,low_quality,structure_limbs,missing_windows,missing_doors,missing_roofs,mutated_structure,mutation,normal_quality,out_of_frame,owres,poorly_drawn_structure,poorly_drawn_house,signature,text,too_many_windows,ugly,username,uta,watermark,worst_quality" + ] +} diff --git a/animate/config/prompts/concat_2horizontal.bat b/animate/config/prompts/concat_2horizontal.bat new file mode 100644 index 0000000000000000000000000000000000000000..1c7663ca12ec0135bb0516c5e795ee2f960982b2 --- /dev/null +++ b/animate/config/prompts/concat_2horizontal.bat @@ -0,0 +1 @@ +ffmpeg -i %1 -i %2 -filter_complex "[0:v][1:v]hstack=inputs=2[v]" -map "[v]" -crf 15 2horizontal.mp4 \ No newline at end of file diff --git a/animate/config/prompts/copy_png.bat b/animate/config/prompts/copy_png.bat new file mode 100644 index 0000000000000000000000000000000000000000..4085b42bcc00d17a6ed4d65914be44373fae75b7 --- /dev/null +++ b/animate/config/prompts/copy_png.bat @@ -0,0 +1,11 @@ + +setlocal enableDelayedExpansion +FOR /l %%N in (1,1,%~n1) do ( + set "n=00000%%N" + set "TEST=!n:~-5! + echo !TEST! + copy /y %1 !TEST!.png +) + +ren %1 00000.png + diff --git a/animate/config/prompts/ignore_tokens.txt b/animate/config/prompts/ignore_tokens.txt new file mode 100644 index 0000000000000000000000000000000000000000..e9f87a6c4e6b03a33df48bf3afdf8e551625c34b --- /dev/null +++ b/animate/config/prompts/ignore_tokens.txt @@ -0,0 +1,4 @@ +motion_blur +blurry +realistic +depth_of_field diff --git a/animate/config/prompts/img2img_sample.json b/animate/config/prompts/img2img_sample.json new file mode 100644 index 0000000000000000000000000000000000000000..5aa4b976c8074a9fdbb4d331e421b768475585b2 --- /dev/null +++ b/animate/config/prompts/img2img_sample.json @@ -0,0 +1,272 @@ +{ + "name": "sample", + "path": "share/Stable-diffusion/mistoonAnime_v20.safetensors", + "motion_module": "models/motion-module/mm_sd_v15_v2.ckpt", + "compile": false, + "seed": [ + 12345 + ], + "scheduler": "k_dpmpp_sde", + "steps": 20, + "guidance_scale": 10, + "unet_batch_size": 1, + "clip_skip": 2, + "prompt_fixed_ratio": 0.5, + "head_prompt": "(style of studio ghibli:1.2), (masterpiece, best quality)", + "prompt_map": { + "0": "forest, water, river, outdoors," + }, + "tail_prompt": "", + "n_prompt": [ + "(worst quality:2), (bad quality:2), (normal quality:2), lowers, bad anatomy, bad hands, (multiple views)," + ], + "lora_map": { + "share/models/Lora/Ghibli_v6.safetensors": 1.0 + }, + "motion_lora_map": { + }, + "ip_adapter_map": { + "enable": false, + "input_image_dir": "", + "prompt_fixed_ratio": 0.5, + "save_input_image": true, + "resized_to_square": false, + "scale": 0.5, + "is_plus_face": false, + "is_plus": true, + "is_light": false + }, + "img2img_map":{ + "enable": true, + "init_img_dir" : "init_imgs/sample0", + "save_init_image": true, + "denoising_strength" : 0.85 + }, + "controlnet_map": { + "input_image_dir" : "", + "max_samples_on_vram": 0, + "max_models_on_vram" : 1, + "save_detectmap": true, + "preprocess_on_gpu": true, + "is_loop": true, + + "controlnet_tile":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "none", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_ip2p":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_lineart_anime":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_openpose":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_softedge":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "softedge_pidsafe", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_shuffle": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_depth": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_canny": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_inpaint": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_lineart": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_mlsd": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_normalbae": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_scribble": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_seg": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "qr_code_monster_v1": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "qr_code_monster_v2": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_mediapipe_face": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_ref": { + "enable": false, + "ref_image": "ref_image/ref_sample.png", + "attention_auto_machine_weight": 0.3, + "gn_auto_machine_weight": 0.3, + "style_fidelity": 0.5, + "reference_attn": true, + "reference_adain": false, + "scale_pattern":[1.0] + } + }, + "upscale_config": { + "scheduler": "k_dpmpp_sde", + "steps": 20, + "strength": 0.5, + "guidance_scale": 10, + "controlnet_tile": { + "enable": true, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_line_anime": { + "enable": false, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ip2p": { + "enable": false, + "controlnet_conditioning_scale": 0.5, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ref": { + "enable": false, + "use_frame_as_ref_image": false, + "use_1st_frame_as_ref_image": false, + "ref_image": "ref_image/path_to_your_ref_img.jpg", + "attention_auto_machine_weight": 1.0, + "gn_auto_machine_weight": 1.0, + "style_fidelity": 0.25, + "reference_attn": true, + "reference_adain": false + } + }, + "output":{ + "format" : "mp4", + "fps" : 8, + "encode_param":{ + "crf": 10 + } + } +} diff --git a/animate/config/prompts/inpaint_sample.json b/animate/config/prompts/inpaint_sample.json new file mode 100644 index 0000000000000000000000000000000000000000..e4bf2d49e58463024623709c82e1199b35a62600 --- /dev/null +++ b/animate/config/prompts/inpaint_sample.json @@ -0,0 +1,299 @@ +{ + "name": "sample", + "path": "share/Stable-diffusion/mistoonAnime_v20.safetensors", + "motion_module": "models/motion-module/mm_sd_v15_v2.ckpt", + "compile": false, + "seed": [ + 12345 + ], + "scheduler": "k_dpmpp_sde", + "steps": 20, + "guidance_scale": 10, + "unet_batch_size": 1, + "clip_skip": 2, + "prompt_fixed_ratio": 0.5, + "head_prompt": "(style of studio ghibli:1.2), (masterpiece, best quality)", + "prompt_map": { + "0": "cyberpunk,robot cat, robot" + }, + "tail_prompt": "", + "n_prompt": [ + "(worst quality:2), (bad quality:2), (normal quality:2), lowers, bad anatomy, bad hands, (multiple views)," + ], + "lora_map": { + "share/models/Lora/Ghibli_v6.safetensors": 1.0 + }, + "motion_lora_map": { + }, + "ip_adapter_map": { + "enable": true, + "input_image_dir": "ip_adapter_image/cyberpunk", + "prompt_fixed_ratio": 0.5, + "save_input_image": true, + "resized_to_square": false, + "scale": 0.5, + "is_plus_face": false, + "is_plus": true, + "is_light": false + }, + "img2img_map":{ + "enable": true, + "init_img_dir" : "init_imgs/sample1", + "save_init_image": true, + "denoising_strength" : 0.85 + }, + "region_map" : { + "0":{ + "enable": true, + "mask_dir" : "mask/sample1", + "save_mask": true, + "is_init_img" : true, + "condition":{ + "prompt_fixed_ratio": 0.5, + "head_prompt": "(masterpiece, best quality)", + "prompt_map": { + "0": "cyberpunk,robot cat, robot" + }, + "tail_prompt": "", + "ip_adapter_map": { + "enable": true, + "input_image_dir": "ip_adapter_image/cyberpunk", + "prompt_fixed_ratio": 0.5, + "save_input_image": true, + "resized_to_square": false + } + } + }, + "background":{ + "is_init_img" : false, + "hint" : "background's condition refers to the one in root" + } + }, + "controlnet_map": { + "input_image_dir" : "controlnet_image/cat", + "max_samples_on_vram": 0, + "max_models_on_vram" : 1, + "save_detectmap": true, + "preprocess_on_gpu": true, + "is_loop": true, + + "controlnet_tile":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "none", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_ip2p":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale":0.5, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[] + }, + "controlnet_lineart_anime":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_openpose":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_softedge":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "softedge_pidsafe", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_shuffle": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_depth": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_canny": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_inpaint": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_lineart": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_mlsd": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_normalbae": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 0.25, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[] + }, + "controlnet_scribble": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_seg": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "qr_code_monster_v1": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "qr_code_monster_v2": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_mediapipe_face": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_ref": { + "enable": false, + "ref_image": "ref_image/ref_sample.png", + "attention_auto_machine_weight": 0.3, + "gn_auto_machine_weight": 0.3, + "style_fidelity": 0.5, + "reference_attn": true, + "reference_adain": false, + "scale_pattern":[1.0] + } + }, + "upscale_config": { + "scheduler": "k_dpmpp_sde", + "steps": 20, + "strength": 0.5, + "guidance_scale": 10, + "controlnet_tile": { + "enable": true, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_line_anime": { + "enable": false, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ip2p": { + "enable": false, + "controlnet_conditioning_scale": 0.5, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ref": { + "enable": false, + "use_frame_as_ref_image": false, + "use_1st_frame_as_ref_image": false, + "ref_image": "ref_image/path_to_your_ref_img.jpg", + "attention_auto_machine_weight": 1.0, + "gn_auto_machine_weight": 1.0, + "style_fidelity": 0.25, + "reference_attn": true, + "reference_adain": false + } + }, + "output":{ + "format" : "mp4", + "fps" : 8, + "encode_param":{ + "crf": 10 + } + } +} diff --git a/animate/config/prompts/prompt_travel.json b/animate/config/prompts/prompt_travel.json new file mode 100644 index 0000000000000000000000000000000000000000..d301cab74dcbf5e33f690dbf4307a19dbf173204 --- /dev/null +++ b/animate/config/prompts/prompt_travel.json @@ -0,0 +1,322 @@ +{ + "name": "sample", + "path": "chilloutMix-Ni.safetensors", + "motion_module": "AnimateLCM_sd15_t2v.ckpt", + "context_schedule" : "composite", + "lcm_map":{ + "enable":true, + "start_scale":0.15, + "end_scale":0.75, + "gradient_start":0.2, + "gradient_end":0.75 + }, + "gradual_latent_hires_fix_map":{ + "enable": false, + "scale": { + "0": 0.5, + "0.7": 1.0 + }, + "reverse_steps": 5, + "noise_add_count":3 + }, + "compile": false, + "seed": [ + 0 + ], + "scheduler": "lcm", + "steps": 8, + "guidance_scale": 3, + "unet_batch_size": 1, + "clip_skip": 2, + "prompt_fixed_ratio": 0.8, + "head_prompt": "A full body gorgeous smiling slim young cleavage robust boob japanese girl, wearing white deep V bandeau pantie, two hands with five fingers, lying on back on white bed, two arms, front view", + "prompt_map": { + "0": "air kiss", + "32": "spread arms", + "64": "cross arms", + "96": "hand heart on chest", + "128": "hand heart on abdomen", + "160": "armpit", + "192": "waving hands, open palms", + "224": "one hand on hip", + "256": "both hands on hip", + "288": "twerking", + "320": "hula", + "352": "belly dance", + "384": "lap dance", + "416": "high kicks", + "448": "spread legs" + }, + "tail_prompt": "best quality, extremely detailed, HD, ultra-realistic, 8K, HQ, masterpiece, trending on artstation, art, smooth", + "n_prompt": [ + "nipple, dudou, shirt, skirt, glove, headgear, shawl, hat, sock, sleeve, monochrome, longbody, lowres, bad anatomy, bad hands, fused fingers, missing fingers, too many fingers, extra digit, fewer digits, cropped, worst quality, low quality, deformed body, bloated, ugly, unrealistic, extra hands and arms" + ], + "lora_map": {}, + "motion_lora_map": {}, + "ip_adapter_map": { + "enable": false, + "input_image_dir": "ip_adapter_image/test", + "prompt_fixed_ratio": 0.5, + "save_input_image": true, + "resized_to_square": false, + "scale": 0.5, + "is_full_face": false, + "is_plus_face": false, + "is_plus": true, + "is_light": false + }, + "controlnet_map": { + "input_image_dir" : "", + "max_samples_on_vram": 0, + "max_models_on_vram" : 0, + "save_detectmap": true, + "preprocess_on_gpu": true, + "is_loop": false, + + "controlnet_tile":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "none", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "controlnet_ip2p":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "controlnet_lineart_anime":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "controlnet_openpose":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "controlnet_softedge":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "softedge_pidsafe", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "controlnet_shuffle": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "controlnet_depth": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "controlnet_canny": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "controlnet_inpaint": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "controlnet_lineart": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "controlnet_mlsd": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "controlnet_normalbae": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "controlnet_scribble": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "controlnet_seg": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "qr_code_monster_v1": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "qr_code_monster_v2": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "controlnet_mediapipe_face": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "animatediff_controlnet": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1], + "control_region_list":[] + }, + "controlnet_ref": { + "enable": false, + "ref_image": "ref_image/ref_sample.png", + "attention_auto_machine_weight": 0.3, + "gn_auto_machine_weight": 0.3, + "style_fidelity": 0.5, + "reference_attn": true, + "reference_adain": false, + "scale_pattern":[1.0] + } + }, + "upscale_config": { + "scheduler": "k_dpmpp_sde", + "steps": 20, + "strength": 0.5, + "guidance_scale": 10, + "controlnet_tile": { + "enable": true, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_line_anime": { + "enable": false, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ip2p": { + "enable": false, + "controlnet_conditioning_scale": 0.5, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ref": { + "enable": false, + "use_frame_as_ref_image": false, + "use_1st_frame_as_ref_image": false, + "ref_image": "ref_image/path_to_your_ref_img.jpg", + "attention_auto_machine_weight": 1.0, + "gn_auto_machine_weight": 1.0, + "style_fidelity": 0.25, + "reference_attn": true, + "reference_adain": false + } + }, + "output":{ + "format" : "mp4", + "fps" : 8, + "encode_param":{ + "crf": 10 + } + } +} diff --git a/animate/config/prompts/prompt_travel_multi_controlnet.json b/animate/config/prompts/prompt_travel_multi_controlnet.json new file mode 100644 index 0000000000000000000000000000000000000000..107d02f7ec3e1820a0b0ad155c707e31a86afe36 --- /dev/null +++ b/animate/config/prompts/prompt_travel_multi_controlnet.json @@ -0,0 +1,238 @@ +{ + "name": "sample", + "path": "share/Stable-diffusion/mistoonAnime_v20.safetensors", + "motion_module": "models/motion-module/mm_sd_v14.ckpt", + "compile": false, + "seed": [ + 341774366206100 + ], + "scheduler": "k_dpmpp_sde", + "steps": 20, + "guidance_scale": 10, + "clip_skip": 2, + "head_prompt": "masterpiece, best quality, a beautiful and detailed portriat of muffet, monster girl,((purple body:1.3)),humanoid, arachnid, anthro,((fangs)),pigtails,hair bows,5 eyes,spider girl,6 arms,solo", + "prompt_map": { + "0": "smile standing,((spider webs:1.0))", + "32": "(((walking))),((spider webs:1.0))", + "64": "(((running))),((spider webs:2.0)),wide angle lens, fish eye effect", + "96": "(((sitting))),((spider webs:1.0))" + }, + "tail_prompt": "clothed, open mouth, awesome and detailed background, holding teapot, holding teacup, 6 hands,detailed hands,storefront that sells pastries and tea,bloomers,(red and black clothing),inside,pouring into teacup,muffetwear", + "n_prompt": [ + "(worst quality, low quality:1.4),nudity,simple background,border,mouth closed,text, patreon,bed,bedroom,white background,((monochrome)),sketch,(pink body:1.4),7 arms,8 arms,4 arms" + ], + "lora_map": { + "share/Lora/muffet_v2.safetensors" : 1.0, + "share/Lora/add_detail.safetensors" : 1.0 + }, + "ip_adapter_map": { + "enable": true, + "input_image_dir": "ip_adapter_image/test", + "save_input_image": true, + "resized_to_square": false, + "scale": 0.5, + "is_plus_face": true, + "is_plus": true + }, + "controlnet_map": { + "input_image_dir" : "controlnet_image/test", + "max_samples_on_vram": 200, + "max_models_on_vram" : 3, + "save_detectmap": true, + "preprocess_on_gpu": true, + "is_loop": true, + + "controlnet_tile":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "none", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_ip2p":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_lineart_anime":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_openpose":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_softedge":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "softedge_pidsafe", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_shuffle": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_depth": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_canny": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_inpaint": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_lineart": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_mlsd": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_normalbae": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_scribble": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_seg": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_ref": { + "enable": false, + "ref_image": "ref_image/ref_sample.png", + "attention_auto_machine_weight": 0.3, + "gn_auto_machine_weight": 0.3, + "style_fidelity": 0.5, + "reference_attn": true, + "reference_adain": false, + "scale_pattern":[1.0] + } + }, + "upscale_config": { + "scheduler": "k_dpmpp_sde", + "steps": 20, + "strength": 0.5, + "guidance_scale": 10, + "controlnet_tile": { + "enable": true, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_line_anime": { + "enable": false, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ip2p": { + "enable": true, + "controlnet_conditioning_scale": 0.5, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ref": { + "enable": false, + "use_frame_as_ref_image": false, + "use_1st_frame_as_ref_image": true, + "ref_image": "ref_image/path_to_your_ref_img.jpg", + "attention_auto_machine_weight": 1.0, + "gn_auto_machine_weight": 1.0, + "style_fidelity": 0.25, + "reference_attn": true, + "reference_adain": false + } + }, + "output":{ + "preview_steps": [10], + "format" : "gif", + "fps" : 8, + "encode_param":{ + "crf": 10 + } + } +} diff --git a/animate/config/prompts/region_sample.json b/animate/config/prompts/region_sample.json new file mode 100644 index 0000000000000000000000000000000000000000..4095981be6531c6f722ebe620458045130301c66 --- /dev/null +++ b/animate/config/prompts/region_sample.json @@ -0,0 +1,299 @@ +{ + "name": "sample", + "path": "share/Stable-diffusion/mistoonAnime_v20.safetensors", + "motion_module": "models/motion-module/mm_sd_v15_v2.ckpt", + "compile": false, + "seed": [ + 12345 + ], + "scheduler": "k_dpmpp_sde", + "steps": 20, + "guidance_scale": 10, + "unet_batch_size": 1, + "clip_skip": 2, + "prompt_fixed_ratio": 0.5, + "head_prompt": "(style of studio ghibli:1.2), (masterpiece, best quality)", + "prompt_map": { + "0": "forest, cute orange cat, outdoors," + }, + "tail_prompt": "", + "n_prompt": [ + "(worst quality:2), (bad quality:2), (normal quality:2), lowers, bad anatomy, bad hands, (multiple views)," + ], + "lora_map": { + "share/models/Lora/Ghibli_v6.safetensors": 1.0 + }, + "motion_lora_map": { + }, + "ip_adapter_map": { + "enable": true, + "input_image_dir": "ip_adapter_image/cat", + "prompt_fixed_ratio": 0.5, + "save_input_image": true, + "resized_to_square": false, + "scale": 0.5, + "is_plus_face": false, + "is_plus": true, + "is_light": false + }, + "img2img_map":{ + "enable": true, + "init_img_dir" : "init_imgs/sample1", + "save_init_image": true, + "denoising_strength" : 0.7 + }, + "region_map" : { + "0":{ + "enable": true, + "mask_dir" : "mask/sample0", + "save_mask": true, + "is_init_img" : false, + "condition":{ + "prompt_fixed_ratio": 0.5, + "head_prompt": "(style of studio ghibli:1.2), (masterpiece, best quality)", + "prompt_map": { + "0": "house, cute dog, rain, street, outdoors" + }, + "tail_prompt": "", + "ip_adapter_map": { + "enable": true, + "input_image_dir": "ip_adapter_image/cyberpunk", + "prompt_fixed_ratio": 0.5, + "save_input_image": true, + "resized_to_square": false + } + } + }, + "background":{ + "is_init_img" : false, + "hint" : "background's condition refers to the one in root" + } + }, + "controlnet_map": { + "input_image_dir" : "", + "max_samples_on_vram": 0, + "max_models_on_vram" : 1, + "save_detectmap": true, + "preprocess_on_gpu": true, + "is_loop": true, + + "controlnet_tile":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "none", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_ip2p":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_lineart_anime":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_openpose":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_softedge":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "softedge_pidsafe", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_shuffle": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_depth": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_canny": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_inpaint": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_lineart": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_mlsd": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_normalbae": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_scribble": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_seg": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "qr_code_monster_v1": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "qr_code_monster_v2": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_mediapipe_face": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_ref": { + "enable": false, + "ref_image": "ref_image/ref_sample.png", + "attention_auto_machine_weight": 0.3, + "gn_auto_machine_weight": 0.3, + "style_fidelity": 0.5, + "reference_attn": true, + "reference_adain": false, + "scale_pattern":[1.0] + } + }, + "upscale_config": { + "scheduler": "k_dpmpp_sde", + "steps": 20, + "strength": 0.5, + "guidance_scale": 10, + "controlnet_tile": { + "enable": true, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_line_anime": { + "enable": false, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ip2p": { + "enable": false, + "controlnet_conditioning_scale": 0.5, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ref": { + "enable": false, + "use_frame_as_ref_image": false, + "use_1st_frame_as_ref_image": false, + "ref_image": "ref_image/path_to_your_ref_img.jpg", + "attention_auto_machine_weight": 1.0, + "gn_auto_machine_weight": 1.0, + "style_fidelity": 0.25, + "reference_attn": true, + "reference_adain": false + } + }, + "output":{ + "format" : "mp4", + "fps" : 8, + "encode_param":{ + "crf": 10 + } + } +} diff --git a/animate/config/prompts/region_sample2.json b/animate/config/prompts/region_sample2.json new file mode 100644 index 0000000000000000000000000000000000000000..4d8d249d27749e6679d4523755e129772c2e2967 --- /dev/null +++ b/animate/config/prompts/region_sample2.json @@ -0,0 +1,299 @@ +{ + "name": "sample", + "path": "share/Stable-diffusion/mistoonAnime_v20.safetensors", + "motion_module": "models/motion-module/mm_sd_v15_v2.ckpt", + "compile": false, + "seed": [ + 12345 + ], + "scheduler": "k_dpmpp_sde", + "steps": 20, + "guidance_scale": 10, + "unet_batch_size": 1, + "clip_skip": 2, + "prompt_fixed_ratio": 0.5, + "head_prompt": "(style of studio ghibli:1.2), (masterpiece, best quality)", + "prompt_map": { + "0": "forest, outdoors," + }, + "tail_prompt": "", + "n_prompt": [ + "(worst quality:2), (bad quality:2), (normal quality:2), lowers, bad anatomy, bad hands, (multiple views)," + ], + "lora_map": { + "share/models/Lora/Ghibli_v6.safetensors": 1.0 + }, + "motion_lora_map": { + }, + "ip_adapter_map": { + "enable": true, + "input_image_dir": "ip_adapter_image/cat", + "prompt_fixed_ratio": 0.5, + "save_input_image": true, + "resized_to_square": false, + "scale": 0.5, + "is_plus_face": false, + "is_plus": true, + "is_light": false + }, + "img2img_map":{ + "enable": true, + "init_img_dir" : "init_imgs/sample1", + "save_init_image": true, + "denoising_strength" : 0.7 + }, + "region_map" : { + "0":{ + "enable": true, + "mask_dir" : "mask/sample1", + "save_mask": true, + "is_init_img" : false, + "condition":{ + "prompt_fixed_ratio": 0.5, + "head_prompt": "(masterpiece, best quality)", + "prompt_map": { + "0": "cyberpunk,robot cat, robot" + }, + "tail_prompt": "", + "ip_adapter_map": { + "enable": true, + "input_image_dir": "ip_adapter_image/cyberpunk", + "prompt_fixed_ratio": 0.5, + "save_input_image": true, + "resized_to_square": false + } + } + }, + "background":{ + "is_init_img" : false, + "hint" : "background's condition refers to the one in root" + } + }, + "controlnet_map": { + "input_image_dir" : "", + "max_samples_on_vram": 0, + "max_models_on_vram" : 1, + "save_detectmap": true, + "preprocess_on_gpu": true, + "is_loop": true, + + "controlnet_tile":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "none", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_ip2p":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_lineart_anime":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_openpose":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_softedge":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "softedge_pidsafe", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_shuffle": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_depth": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_canny": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_inpaint": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_lineart": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_mlsd": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_normalbae": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_scribble": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_seg": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "qr_code_monster_v1": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "qr_code_monster_v2": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_mediapipe_face": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_ref": { + "enable": false, + "ref_image": "ref_image/ref_sample.png", + "attention_auto_machine_weight": 0.3, + "gn_auto_machine_weight": 0.3, + "style_fidelity": 0.5, + "reference_attn": true, + "reference_adain": false, + "scale_pattern":[1.0] + } + }, + "upscale_config": { + "scheduler": "k_dpmpp_sde", + "steps": 20, + "strength": 0.5, + "guidance_scale": 10, + "controlnet_tile": { + "enable": true, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_line_anime": { + "enable": false, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ip2p": { + "enable": false, + "controlnet_conditioning_scale": 0.5, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ref": { + "enable": false, + "use_frame_as_ref_image": false, + "use_1st_frame_as_ref_image": false, + "ref_image": "ref_image/path_to_your_ref_img.jpg", + "attention_auto_machine_weight": 1.0, + "gn_auto_machine_weight": 1.0, + "style_fidelity": 0.25, + "reference_attn": true, + "reference_adain": false + } + }, + "output":{ + "format" : "mp4", + "fps" : 8, + "encode_param":{ + "crf": 10 + } + } +} diff --git a/animate/config/prompts/region_sample3.json b/animate/config/prompts/region_sample3.json new file mode 100644 index 0000000000000000000000000000000000000000..31e73d34d398ca6aae3c9644f2b921cd0c3fedf1 --- /dev/null +++ b/animate/config/prompts/region_sample3.json @@ -0,0 +1,299 @@ +{ + "name": "sample", + "path": "share/Stable-diffusion/mistoonAnime_v20.safetensors", + "motion_module": "models/motion-module/mm_sd_v15_v2.ckpt", + "compile": false, + "seed": [ + 12345 + ], + "scheduler": "k_dpmpp_sde", + "steps": 20, + "guidance_scale": 10, + "unet_batch_size": 1, + "clip_skip": 2, + "prompt_fixed_ratio": 0.5, + "head_prompt": "(style of studio ghibli:1.2), (masterpiece, best quality)", + "prompt_map": { + "0": "forest, outdoors," + }, + "tail_prompt": "", + "n_prompt": [ + "(worst quality:2), (bad quality:2), (normal quality:2), lowers, bad anatomy, bad hands, (multiple views)," + ], + "lora_map": { + "share/models/Lora/Ghibli_v6.safetensors": 1.0 + }, + "motion_lora_map": { + }, + "ip_adapter_map": { + "enable": true, + "input_image_dir": "ip_adapter_image/cat", + "prompt_fixed_ratio": 0.5, + "save_input_image": true, + "resized_to_square": false, + "scale": 0.5, + "is_plus_face": false, + "is_plus": true, + "is_light": false + }, + "img2img_map":{ + "enable": true, + "init_img_dir" : "init_imgs/sample1", + "save_init_image": true, + "denoising_strength" : 0.85 + }, + "region_map" : { + "0":{ + "enable": true, + "mask_dir" : "mask/sample1", + "save_mask": true, + "is_init_img" : false, + "condition":{ + "prompt_fixed_ratio": 0.5, + "head_prompt": "(masterpiece, best quality)", + "prompt_map": { + "0": "cyberpunk,robot cat, robot" + }, + "tail_prompt": "", + "ip_adapter_map": { + "enable": true, + "input_image_dir": "ip_adapter_image/cyberpunk", + "prompt_fixed_ratio": 0.5, + "save_input_image": true, + "resized_to_square": false + } + } + }, + "background":{ + "is_init_img" : false, + "hint" : "background's condition refers to the one in root" + } + }, + "controlnet_map": { + "input_image_dir" : "controlnet_image/cat", + "max_samples_on_vram": 0, + "max_models_on_vram" : 1, + "save_detectmap": true, + "preprocess_on_gpu": true, + "is_loop": true, + + "controlnet_tile":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "none", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_ip2p":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale":0.5, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[] + }, + "controlnet_lineart_anime":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_openpose":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_softedge":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "softedge_pidsafe", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_shuffle": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_depth": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_canny": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_inpaint": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_lineart": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_mlsd": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_normalbae": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 0.25, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[] + }, + "controlnet_scribble": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_seg": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "qr_code_monster_v1": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "qr_code_monster_v2": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_mediapipe_face": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_ref": { + "enable": false, + "ref_image": "ref_image/ref_sample.png", + "attention_auto_machine_weight": 0.3, + "gn_auto_machine_weight": 0.3, + "style_fidelity": 0.5, + "reference_attn": true, + "reference_adain": false, + "scale_pattern":[1.0] + } + }, + "upscale_config": { + "scheduler": "k_dpmpp_sde", + "steps": 20, + "strength": 0.5, + "guidance_scale": 10, + "controlnet_tile": { + "enable": true, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_line_anime": { + "enable": false, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ip2p": { + "enable": false, + "controlnet_conditioning_scale": 0.5, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ref": { + "enable": false, + "use_frame_as_ref_image": false, + "use_1st_frame_as_ref_image": false, + "ref_image": "ref_image/path_to_your_ref_img.jpg", + "attention_auto_machine_weight": 1.0, + "gn_auto_machine_weight": 1.0, + "style_fidelity": 0.25, + "reference_attn": true, + "reference_adain": false + } + }, + "output":{ + "format" : "mp4", + "fps" : 8, + "encode_param":{ + "crf": 10 + } + } +} diff --git a/animate/config/prompts/region_txt2img.json b/animate/config/prompts/region_txt2img.json new file mode 100644 index 0000000000000000000000000000000000000000..cbf738c6ae8111bb16ef166e93aca4548f812e15 --- /dev/null +++ b/animate/config/prompts/region_txt2img.json @@ -0,0 +1,324 @@ +{ + "name": "sample", + "path": "share/Stable-diffusion/mistoonAnime_v20.safetensors", + "motion_module": "models/motion-module/mm_sd_v15_v2.ckpt", + "compile": false, + "seed": [ + -1 + ], + "scheduler": "k_dpmpp_sde", + "steps": 20, + "guidance_scale": 10, + "unet_batch_size": 1, + "clip_skip": 2, + "prompt_fixed_ratio": 0.5, + "head_prompt": "(style of studio ghibli:1.2), (masterpiece, best quality)", + "prompt_map": { + "0": "town, outdoors," + }, + "tail_prompt": "", + "n_prompt": [ + "(worst quality:2), (bad quality:2), (normal quality:2), lowers, bad anatomy, bad hands, (multiple views)," + ], + "lora_map": { + }, + "motion_lora_map": { + }, + "ip_adapter_map": { + "enable": true, + "input_image_dir": "ip_adapter_image/cyberpunk", + "prompt_fixed_ratio": 0.5, + "save_input_image": true, + "resized_to_square": false, + "scale": 0.5, + "is_plus_face": false, + "is_plus": true, + "is_light": false + }, + "img2img_map":{ + "enable": false, + "init_img_dir" : "init_imgs/sample1", + "save_init_image": true, + "denoising_strength" : 0.7 + }, + "region_map" : { + "0":{ + "enable": true, + "crop_generation_rate": 0.1, + "mask_dir" : "mask/area0", + "save_mask": true, + "is_init_img" : false, + "condition":{ + "prompt_fixed_ratio": 1.0, + "head_prompt": "", + "prompt_map": { + "0": "((standing)),1girl, upper body,", + "8": "((smile)),1girl, upper body,", + "16": "(((arms_up))),1girl, upper body, ", + "24": "(((waving ))),1girl, upper body" + }, + "tail_prompt": "(style of studio ghibli:1.2), (masterpiece, best quality)", + "ip_adapter_map": { + "enable": true, + "input_image_dir": "ip_adapter_image/girl", + "prompt_fixed_ratio": 0.5, + "save_input_image": true, + "resized_to_square": false + } + } + }, + "1":{ + "enable": true, + "crop_generation_rate": 0.1, + "mask_dir" : "mask/area1", + "save_mask": true, + "is_init_img" : false, + "condition":{ + "prompt_fixed_ratio": 0.5, + "head_prompt": "((car)),(style of studio ghibli:1.2), (masterpiece, best quality)", + "prompt_map": { + "0": "street, road,no human" + }, + "tail_prompt": "", + "ip_adapter_map": { + "enable": true, + "input_image_dir": "ip_adapter_image/cyberpunk", + "prompt_fixed_ratio": 0.5, + "save_input_image": true, + "resized_to_square": false + } + } + }, + "background":{ + "is_init_img" : false, + "hint" : "background's condition refers to the one in root" + } + }, + "controlnet_map": { + "input_image_dir" : "", + "max_samples_on_vram": 0, + "max_models_on_vram" : 1, + "save_detectmap": true, + "preprocess_on_gpu": true, + "is_loop": true, + + "controlnet_tile":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "none", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_ip2p":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_lineart_anime":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_openpose":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_softedge":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "softedge_pidsafe", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_shuffle": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_depth": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_canny": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_inpaint": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_lineart": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_mlsd": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_normalbae": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_scribble": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_seg": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "qr_code_monster_v1": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "qr_code_monster_v2": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_mediapipe_face": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_ref": { + "enable": false, + "ref_image": "ref_image/ref_sample.png", + "attention_auto_machine_weight": 0.3, + "gn_auto_machine_weight": 0.3, + "style_fidelity": 0.5, + "reference_attn": true, + "reference_adain": false, + "scale_pattern":[1.0] + } + }, + "upscale_config": { + "scheduler": "k_dpmpp_sde", + "steps": 20, + "strength": 0.5, + "guidance_scale": 10, + "controlnet_tile": { + "enable": true, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_line_anime": { + "enable": false, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ip2p": { + "enable": false, + "controlnet_conditioning_scale": 0.5, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ref": { + "enable": false, + "use_frame_as_ref_image": false, + "use_1st_frame_as_ref_image": false, + "ref_image": "ref_image/path_to_your_ref_img.jpg", + "attention_auto_machine_weight": 1.0, + "gn_auto_machine_weight": 1.0, + "style_fidelity": 0.25, + "reference_attn": true, + "reference_adain": false + } + }, + "output":{ + "format" : "mp4", + "fps" : 8, + "encode_param":{ + "crf": 10 + } + } +} diff --git a/animate/config/prompts/sample_lcm.json b/animate/config/prompts/sample_lcm.json new file mode 100644 index 0000000000000000000000000000000000000000..af8c4d1b95f23279407cf52c628c475e95f58147 --- /dev/null +++ b/animate/config/prompts/sample_lcm.json @@ -0,0 +1,298 @@ +{ + "name": "simple", + "path": "share/Stable-diffusion/mistoonAnime_v20.safetensors", + "motion_module": "models/motion-module/mm_sd_v15_v2.ckpt", + "lcm_map":{ + "enable":true, + "start_scale":0.15, + "end_scale":0.75, + "gradient_start":0.2, + "gradient_end":0.75 + }, + "compile": false, + "seed": [ + 123456 + ], + "scheduler": "euler_a", + "steps": 8, + "guidance_scale": 3, + "clip_skip": 2, + "prompt_fixed_ratio": 1.0, + "head_prompt": "1girl, wizard, circlet, earrings, jewelry, purple hair,", + "prompt_map": { + "0": "", + "8": "((fire magic spell, fire background))", + "16": "((ice magic spell, ice background))", + "24": "((thunder magic spell, thunder background))", + "32": "((skull magic spell, skull background))", + "40": "((wind magic spell, wind background))", + "48": "((stone magic spell, stone background))", + "56": "((holy magic spell, holy background))", + "64": "((star magic spell, star background))", + "72": "((plant magic spell, plant background))", + "80": "((meteor magic spell, meteor background))" + }, + "tail_prompt": "", + "n_prompt": [ + "(worst quality, low quality:1.4),nudity,border,text, patreon, easynegative, negative_hand-neg" + ], + "is_single_prompt_mode":false, + "lora_map": { + "share/Lora/add_detail.safetensors":1.0 + }, + "ip_adapter_map": { + "enable": false, + "input_image_dir": "ip_adapter_image/test", + "save_input_image": true, + "resized_to_square": false, + "scale": 0.5, + "is_plus_face": false, + "is_plus": true + }, + "img2img_map":{ + "enable": false, + "init_img_dir" : "init_imgs/test", + "save_init_image": true, + "denoising_strength" : 0.8 + }, + "region_map" : { + "0":{ + "enable":false, + "mask_dir" : "mask/r0", + "save_mask": true, + "is_init_img" : false, + "condition":{ + "prompt_fixed_ratio": 0.5, + "head_prompt": "1girl, wizard, circlet, earrings, jewelry, purple hair,", + "prompt_map": { + "0": "", + "8": "((fire magic spell, fire background))", + "16": "((ice magic spell, ice background))", + "24": "((thunder magic spell, thunder background))", + "32": "((skull magic spell, skull background))", + "40": "((wind magic spell, wind background))", + "48": "((stone magic spell, stone background))", + "56": "((holy magic spell, holy background))", + "64": "((star magic spell, star background))", + "72": "((plant magic spell, plant background))", + "80": "((meteor magic spell, meteor background))" + }, + "tail_prompt": "", + "ip_adapter_map": { + "enable": false, + "input_image_dir": "ip_adapter_image/test", + "save_input_image": true, + "resized_to_square": false + } + } + }, + "background":{ + "is_init_img" : false, + "hint" : "background's condition refers to the one in root" + } + }, + "controlnet_map": { + "input_image_dir" : "controlnet_image/test9999", + "max_samples_on_vram": 200, + "max_models_on_vram" : 3, + "save_detectmap": true, + "preprocess_on_gpu": true, + "is_loop": true, + + "controlnet_tile":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "none", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5] + }, + "controlnet_ip2p":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_lineart_anime":{ + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_openpose":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "dwpose", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_softedge":{ + "enable": true, + "use_preprocessor":true, + "preprocessor":{ + "type" : "softedge_pidsafe", + "param":{ + } + }, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_shuffle": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_depth": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_canny": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_inpaint": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_lineart": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 0.5, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5] + }, + "controlnet_mlsd": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_normalbae": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_scribble": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_seg": { + "enable": true, + "use_preprocessor":true, + "guess_mode":false, + "controlnet_conditioning_scale": 1.0, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[0.5,0.4,0.3,0.2,0.1] + }, + "controlnet_ref": { + "enable": false, + "ref_image": "ref_image/naga.png", + "attention_auto_machine_weight": 0.5, + "gn_auto_machine_weight": 0.5, + "style_fidelity": 0.5, + "reference_attn": true, + "reference_adain": true, + "scale_pattern":[1.0] + } + }, + "upscale_config": { + "scheduler": "k_dpmpp_sde", + "steps": 20, + "strength": 0.5, + "guidance_scale": 10, + "controlnet_tile": { + "enable": true, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_line_anime": { + "enable": false, + "controlnet_conditioning_scale": 1.0, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ip2p": { + "enable": false, + "controlnet_conditioning_scale": 0.5, + "guess_mode": false, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0 + }, + "controlnet_ref": { + "enable": false, + "use_frame_as_ref_image": false, + "use_1st_frame_as_ref_image": false, + "ref_image": "ref_image/path_to_your_ref_img.jpg", + "attention_auto_machine_weight": 1.0, + "gn_auto_machine_weight": 1.0, + "style_fidelity": 0.25, + "reference_attn": true, + "reference_adain": false + } + }, + "output":{ + "format" : "mp4", + "fps" : 8, + "encode_param":{ + "crf": 10 + } + } +} diff --git a/animate/config/prompts/to_8fps_Frames.bat b/animate/config/prompts/to_8fps_Frames.bat new file mode 100644 index 0000000000000000000000000000000000000000..570efb39c33b988b7a912102469b520beabe79a0 --- /dev/null +++ b/animate/config/prompts/to_8fps_Frames.bat @@ -0,0 +1 @@ +ffmpeg -i %1 -start_number 0 -vf "scale=512:768,fps=8" %%04d.png \ No newline at end of file diff --git a/animate/data/.gitignore b/animate/data/.gitignore new file mode 100644 index 0000000000000000000000000000000000000000..bfbc95c50127ab5aea138ccd401536384d464860 --- /dev/null +++ b/animate/data/.gitignore @@ -0,0 +1,5 @@ +* +!.gitignore +!/models/ +!/embeddings/ +!/rife/ diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000000.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000000.png new file mode 100644 index 0000000000000000000000000000000000000000..abaf835c020ec32224dfeea6b78624e720d41701 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000000.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:2a9f75b633b2782e23fb72d6bccd72bfb6d7b9e208117e1c140d84c72b11d18b +size 708827 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000001.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000001.png new file mode 100644 index 0000000000000000000000000000000000000000..ea372436433c063b946ec02bbcd2c4ab3481c432 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000001.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:ccf1524c1cfc8a3201beb64d88916fafdb0d232e3ca73d90d0394acb1182576b +size 716497 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000002.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000002.png new file mode 100644 index 0000000000000000000000000000000000000000..2cdf26cf34f3913dedfe366a577b950987860292 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000002.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:91829b57b7c7fe953c065579b449d5343ed4bfa5f19afb47f558ca0f86920fd7 +size 717288 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000003.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000003.png new file mode 100644 index 0000000000000000000000000000000000000000..5619f6f4f217861aeba106f3a336b29ea8c892a7 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000003.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:f9315c95b78bd42cdb76022fe49d2f470045e6697e6bf589c17fad78d451e812 +size 710629 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000004.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000004.png new file mode 100644 index 0000000000000000000000000000000000000000..c7321b9ca254c24212ef0bb07e3ded581f17e8b0 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000004.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:0d223014da89119f6fd01b39b8298907f163522437b5e6f2fb4baf2f72b20e62 +size 706571 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000005.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000005.png new file mode 100644 index 0000000000000000000000000000000000000000..298bcc272cfe6be2ee8f3b937810059ee98a1735 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000005.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:96562f566944d566ab2ef2d76a9f5634017d13a7e8e3cb327c96e52b93e3d3ca +size 704015 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000006.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000006.png new file mode 100644 index 0000000000000000000000000000000000000000..bf67efa8e0c94032788df615af72b2a1a7369376 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000006.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:a4bf6767e4d854d4b84032e7e4520977f09b01c30c037d46b4cf1d56913d3d81 +size 705212 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000007.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000007.png new file mode 100644 index 0000000000000000000000000000000000000000..844ee82269f53811fdf8948fcd66e84348ea9d59 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000007.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:5000d11a22fba880a131be01686f05a26eed4140adf567c71c0f07938e6087b1 +size 699151 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000008.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000008.png new file mode 100644 index 0000000000000000000000000000000000000000..469c6f7caaf0130d6d7eaa995a5f848d8a43e5e3 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000008.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:d902208f4b1a4fac039d5a63cf476ff0bde3f47bbb59969637ea11f12ee10d0b +size 699404 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000009.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000009.png new file mode 100644 index 0000000000000000000000000000000000000000..b757e3579e1daf5930ffc02faea785c4b36a1274 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000009.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:f84488322a97130c3615ea8343669933868aa837f231942bb634abaa374b2875 +size 700013 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000010.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000010.png new file mode 100644 index 0000000000000000000000000000000000000000..63703deab245b8975c40c3dbfcefa6b3d7c83ba0 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000010.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:2678497ef445be3d6e6ed7b85104d996f4619662843e03a6fb00374971d3c767 +size 706960 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000011.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000011.png new file mode 100644 index 0000000000000000000000000000000000000000..42d291c498d094090b285960420913863e8e912b --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000011.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:84fd229aa9b804bf252424f7695ec50ac976ae5f90026cf795e19c305be23c9b +size 703776 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000012.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000012.png new file mode 100644 index 0000000000000000000000000000000000000000..10c3e42ea85ffbe13d0ba15cf9c1256290d49a43 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000012.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:4b78b3668549b3d234d15897867e6b86ff73bfd8561836692d9bc4e292ad77e4 +size 706140 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000013.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000013.png new file mode 100644 index 0000000000000000000000000000000000000000..b422652afc562309c2e4a749fa5953616bda8cca --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000013.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:9b82f4487df1606b5def7866de67cad9700f8604d91141080416e732b5e9c518 +size 712186 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000014.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000014.png new file mode 100644 index 0000000000000000000000000000000000000000..373f9abfabfb3b92ba437bb206c9e3d2a5ea5c7a --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000014.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:26d05101e1ae28b982e37d50ce6a68e42854fdd3a238d208fff44e55a9bb24e1 +size 710177 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000015.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000015.png new file mode 100644 index 0000000000000000000000000000000000000000..31052c89d0d06c16099eaf98fd3fead72d6f34a8 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000015.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:f738b02c0d01d22e0da251c11cb532b8ea833a83a93a0708e3e02da4cd151170 +size 710524 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000016.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000016.png new file mode 100644 index 0000000000000000000000000000000000000000..cb36aca4bb8816e19b24a3d6cfe41da0e2b97560 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000016.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:6c070728333b85ac7b5395435331cd17e88833b4f65878a280a4efb6d0186cd9 +size 710557 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000017.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000017.png new file mode 100644 index 0000000000000000000000000000000000000000..eaaf1514d07ba7418cc765f2d49856db950bd5b7 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000017.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:bb176f7b640c652c422799cc9fd5474e54aa4ce207c48dd788cb6078d25a8960 +size 711285 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000018.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000018.png new file mode 100644 index 0000000000000000000000000000000000000000..91aa0ae0c9cf0d91e67d432ca20bb268ae949a40 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000018.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:e96ad04e3ad065367862cf58d1a19a20c516912e53ea68c606424838d8ef53a0 +size 714555 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000019.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000019.png new file mode 100644 index 0000000000000000000000000000000000000000..91f3d492b1c20ec8bb155bd80f2083f8a4c75846 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000019.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:b9c8dbd40e243f8b7aaba20106284319775b510ddf36058406c54776a45226c7 +size 704520 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000020.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000020.png new file mode 100644 index 0000000000000000000000000000000000000000..8ca0b3b098df39aced8c7b86a72430e13739c5b7 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000020.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:5a6810cc34194fcbd29b7bc21e134d2b9f4c0d9149f5b74220e75495a18f8018 +size 708543 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000021.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000021.png new file mode 100644 index 0000000000000000000000000000000000000000..4bdc5be60f9da4eec49164cb41eab9a8d5657eb8 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000021.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:c4a398e48614bee4c0cff60536c9e62bd76e2a1815df0b6cd3b9c80ad5e4e5d1 +size 701650 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000022.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000022.png new file mode 100644 index 0000000000000000000000000000000000000000..3831ff4e5b340c8c7bb07c046e04efe07a1e47fb --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000022.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:a0a29cf5359e2a33b10ef68baced8e4eb625be9de3b6b545d5f28fd40b2f9d15 +size 696325 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000023.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000023.png new file mode 100644 index 0000000000000000000000000000000000000000..854c7f802d04817024287f5cac6342775417c10c --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000023.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:57df59eb11408fb6d68a7aa4dee0662bc922f13887fc1ff4019237b791368445 +size 701577 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000024.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000024.png new file mode 100644 index 0000000000000000000000000000000000000000..82da1e5f0a9ac42b00f3724edccf87e66cc808bc --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000024.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:a2d600f3780fccb9421fb9b01edc8aec1cc1b1d6eb4e68217b034b8606a46768 +size 687544 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000025.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000025.png new file mode 100644 index 0000000000000000000000000000000000000000..ffd5876cb5904bf1b35d38d1d07f4a981f4ea3ae --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000025.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:2a85ae78d565ac0dfe19d0a96abc90434d85fd4bbf0624c3d732ac90824e98e2 +size 688533 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000026.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000026.png new file mode 100644 index 0000000000000000000000000000000000000000..9e3abb4a886deab1d7c3b13b1cc4c44ad35dd99f --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000026.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:2085878ca22d55559dc4d628ef9fc426e10f7175b47deed5f4b47c48f124dca1 +size 678284 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000027.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000027.png new file mode 100644 index 0000000000000000000000000000000000000000..5d07ef9ea7528ddc0210c3b7c0044b623133d2a4 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000027.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:0e04d602ba7ce476a14b5c29d6355f8a41f74e89ccc06335dee91e4f9e2f1ee4 +size 676258 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000028.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000028.png new file mode 100644 index 0000000000000000000000000000000000000000..babc0804bcec7da485760df643590f1acf1b51ab --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000028.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:0b2bfb881016e65eb67662b585b8701fe6b91078494f68411789958c532a596f +size 673078 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000029.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000029.png new file mode 100644 index 0000000000000000000000000000000000000000..775237d9a4c03e0fabc4344c5f127bdaa7a0cd0e --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000029.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:0d28492b2536a8ff3b685a106cce1d4978f155b218aed6f5c5ab908b1ce9394b +size 676853 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000030.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000030.png new file mode 100644 index 0000000000000000000000000000000000000000..5bdaeba7de2a38eb90cfa5757a3c8033089db499 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000030.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:c96c12075e48770a246b099a14920736af81a6c58f73a6eedc0de6e10b1f433a +size 672478 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000031.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000031.png new file mode 100644 index 0000000000000000000000000000000000000000..c4bc91417c74571c828997bfb48af1d66d9c2667 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000031.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:da6b0f86da5bbe252ba2fc917032ea679a9c52a376ab3971271e82197a6bec0e +size 677109 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000032.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000032.png new file mode 100644 index 0000000000000000000000000000000000000000..5c10a88a2bbdd32a08ad784cd509dc77128e22bb --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000032.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:c16fd2011bb5665af924fa85a9a155784699a96e7f702a9673cf033d69dd3df0 +size 671831 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000033.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000033.png new file mode 100644 index 0000000000000000000000000000000000000000..2d27c0877ff1a50ac7f8000c516d01a340bac7a5 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000033.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:0779225f49ad3d62486bb6aff6f1cff5207464cfe7c9a27beacfe3b159457c1a +size 678263 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000034.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000034.png new file mode 100644 index 0000000000000000000000000000000000000000..97982bfe56c54503e6f49635d71cba549b566329 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000034.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:fe2cc155acf407245b6fbcacb9fcdbab67fb858a0a7e9748054885de127bceaa +size 673022 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000035.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000035.png new file mode 100644 index 0000000000000000000000000000000000000000..95fdb80437aa49ac8d3c50f3643e0e76cbd1e52f --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000035.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:8bdefdc67c2acd625df9ce07edba09521a42b036600264925ad7c71b9fa425ff +size 670384 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000036.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000036.png new file mode 100644 index 0000000000000000000000000000000000000000..77b0e2014ba68e860eb67a3f0e0fef8e721bb2f1 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000036.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:8f955138460c6fd57ca750843de59a43ea61bf530f8df2892067a73b1bf2468c +size 661212 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000037.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000037.png new file mode 100644 index 0000000000000000000000000000000000000000..ed5ef7deede4cf6814169b57ed51c743ce5197ac --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000037.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:cda54568d21d1e81e4554e874d018e02943a565fa5b9b1ad106e23adbe0e967e +size 658013 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000038.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000038.png new file mode 100644 index 0000000000000000000000000000000000000000..b13ba941706ef96cf31ca5a6dfe031cd806cd905 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000038.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:0e0f44f96538a76e471cf3513bb287a8a77257d0b61b3e9b0be98724cf1ffed0 +size 654774 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000039.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000039.png new file mode 100644 index 0000000000000000000000000000000000000000..b0c1bd682f0a621e0588e32d5f5d40e1c05b8d05 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000039.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:2b460896859ff190efbd2a8bfdd2d91288b00f2dfa2d73a6ea5ce7c1424bcfb2 +size 655336 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000040.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000040.png new file mode 100644 index 0000000000000000000000000000000000000000..82f6049238a5e9e0e07bb278095048cc15808de1 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000040.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:fadac0296a63231613853cfc96f79c058557fcf033060251b201cfe129bdab06 +size 652216 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000041.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000041.png new file mode 100644 index 0000000000000000000000000000000000000000..0a1aeb5778912b857cfc2ecdd380500fcfbea91a --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000041.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:0f026282529c3225ed039d578536fa3700b3f05acaa49137583dbc9cc2242e57 +size 650191 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000042.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000042.png new file mode 100644 index 0000000000000000000000000000000000000000..c17f294fa826afc1becc81a818266c27e1c67999 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000042.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:8f0ecde382d65149eec50aa26840c2467c5c772b4627a7b80e0cc5a6dbe3d166 +size 648262 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000043.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000043.png new file mode 100644 index 0000000000000000000000000000000000000000..f046afa32faf40c77e46dff8c9fc5f76d46d0204 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000043.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:b1358383a6274c58b0a4ab23f87a8b8aa52111cfb6336a4ab70474c20be7af54 +size 650978 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000044.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000044.png new file mode 100644 index 0000000000000000000000000000000000000000..e51e264523d95b8d92c129f551427c0114559232 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000044.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:af63c78e06137cd945411c60fe388b1b2a90f6d2b89006c6fd605f9663bfb253 +size 636184 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000045.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000045.png new file mode 100644 index 0000000000000000000000000000000000000000..4ac962d8c97f9e4e41d0418b9ad924e00e930544 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000045.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:0c1713f55a80bfc42074fd06251c15be6fbb33702c8ae499fbce72f84a5cc0bd +size 636189 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000046.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000046.png new file mode 100644 index 0000000000000000000000000000000000000000..72ff90493097c0ae73214b9bbf62a9e6b7858a3d --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000046.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:ace92dd54e3febf163da6f807b5887cbf6ef289af754e621416541951495d242 +size 643142 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000047.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000047.png new file mode 100644 index 0000000000000000000000000000000000000000..63fe93a9f6aa86757a8a8ac4096cbb4d5590397f --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000047.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:5b618da6418bedf45fda761cfb9c7df4bd2e03926ce9c59a7425e3994f250d3b +size 638713 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000048.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000048.png new file mode 100644 index 0000000000000000000000000000000000000000..601e1cd56f5cdf4da16224f6f01250413b6fb74f --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000048.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:77c246d511dc8043f02a2eb9844421a4198178eefbbe89c1ab0955c8fb24b328 +size 636056 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000049.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000049.png new file mode 100644 index 0000000000000000000000000000000000000000..56f1e0a86d6f08a4f509d7b44f00d352d8c36711 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000049.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:d30a6dc328a8d4a392219262fe161e2d390359d29276718c67183821c3b8ff96 +size 641086 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000050.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000050.png new file mode 100644 index 0000000000000000000000000000000000000000..afbd8c907b2f7de362d0d83b8bb4165541f777fa --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000050.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:159a8ffc2b84d4769cb10091839f80b547fb6c420a6ef3b16b7099f9f2aa404c +size 638778 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000051.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000051.png new file mode 100644 index 0000000000000000000000000000000000000000..6601f5fe14de5c1eea72e27fa69f28775781bfa7 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000051.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:0fb41d385288e2bbb8cde6ed5fb7e80b22e4c67621adc766a84a9ce292372169 +size 640519 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000052.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000052.png new file mode 100644 index 0000000000000000000000000000000000000000..d9bd2b0c8de7b9a585df0dc33a820b67f4eebf46 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000052.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:0bfb9f9655659c370ac55a34caee9ff0bdfa19d480b9cc9a643725f10fed771e +size 640542 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000053.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000053.png new file mode 100644 index 0000000000000000000000000000000000000000..0b849bc23545578592581a10fe2dc2f00ab2139a --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000053.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:26d51d19f8d93301c5a07cc773ebafac6c3ed6b25027ee739fcca0b50b797faa +size 641297 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000054.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000054.png new file mode 100644 index 0000000000000000000000000000000000000000..27d89022fa5859ed7d6e2206070d22513024fc36 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000054.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:d0e3e6b41aab3038d0a8ef9e1bf03626224f0b98df9f7c6fbdc27f9c177c9de2 +size 637305 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000055.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000055.png new file mode 100644 index 0000000000000000000000000000000000000000..f720e187ec012a420d4b07d6fda9665a275eb595 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000055.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:66c476eeb5da15c8b6ae5dd3001dc6ca84bef47d7df69e7e8dff7d00cc5f9fbc +size 643360 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000056.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000056.png new file mode 100644 index 0000000000000000000000000000000000000000..792ee2c0c0ff95bd4e149143ca8aeee243bd343d --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000056.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:7f18a73ed55ae906fb458fc7d105970faf988dffc6edc0d57a6adec5bb71e761 +size 628374 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000057.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000057.png new file mode 100644 index 0000000000000000000000000000000000000000..032c57d8f53bd03820521a3b68c38eb0f9c56c05 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000057.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:52baa96ed44071a84dafda3411c2c5a210bd82e126422bb08acf4176d417111b +size 624900 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000058.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000058.png new file mode 100644 index 0000000000000000000000000000000000000000..2b7db99f84ff100bad1bfbdc7f5eaa51b393360a --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000058.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:1cdc4c101bbacc8c17a7fbfeac9dc44000911de8d1f8509698042d209e2e18f1 +size 616220 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000059.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000059.png new file mode 100644 index 0000000000000000000000000000000000000000..bbff557c2116511b6470d746b755e4f058e3aa84 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000059.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:ddb7705909b6fa7f3778f9015b513e3d9faee6160b5062ed5821f8a9f460af5d +size 626778 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000060.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000060.png new file mode 100644 index 0000000000000000000000000000000000000000..8315f97084837209cc0f28f28e6264a6d29dcc3f --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000060.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:6e61f33b2bff765b92f15705c51fa9fe8d6db2c4fff3bafd194799b35953f198 +size 615110 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000061.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000061.png new file mode 100644 index 0000000000000000000000000000000000000000..db3b4fef0a2f82623c132f86bb6ca6516b379888 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000061.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:ab6cf7abd8e859a627d53fb9fbef04dbc9685dba601cf441386b83e1bb7fde4c +size 619490 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000062.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000062.png new file mode 100644 index 0000000000000000000000000000000000000000..2cf721b64570e36bc7ddd765d9ccfa53e616d13c --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000062.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:da436b909cd5a650f4310fa63fe571670c9216319018a94d4b7668f69ca9379a +size 618211 diff --git a/animate/data/controlnet_image/cat/controlnet_ip2p/00000063.png b/animate/data/controlnet_image/cat/controlnet_ip2p/00000063.png new file mode 100644 index 0000000000000000000000000000000000000000..5a0dccfa9b7569492b0eb462634f4365fc3996a9 --- /dev/null +++ b/animate/data/controlnet_image/cat/controlnet_ip2p/00000063.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:1e6a6a3f94d667ba5e502199d61203a2d92e6b5cb1186f6bfbc0b6e2220556dd +size 625231 diff --git a/animate/data/controlnet_image/test/controlnet_canny/put_pngs_here.txt b/animate/data/controlnet_image/test/controlnet_canny/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/controlnet_image/test/controlnet_depth/put_pngs_here.txt b/animate/data/controlnet_image/test/controlnet_depth/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/controlnet_image/test/controlnet_inpaint/put_pngs_here.txt b/animate/data/controlnet_image/test/controlnet_inpaint/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/controlnet_image/test/controlnet_ip2p/put_pngs_here.txt b/animate/data/controlnet_image/test/controlnet_ip2p/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/controlnet_image/test/controlnet_lineart/put_pngs_here.txt b/animate/data/controlnet_image/test/controlnet_lineart/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/controlnet_image/test/controlnet_lineart_anime/put_pngs_here.txt b/animate/data/controlnet_image/test/controlnet_lineart_anime/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/controlnet_image/test/controlnet_mlsd/put_pngs_here.txt b/animate/data/controlnet_image/test/controlnet_mlsd/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/controlnet_image/test/controlnet_normalbae/put_pngs_here.txt b/animate/data/controlnet_image/test/controlnet_normalbae/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/controlnet_image/test/controlnet_openpose/0000.png b/animate/data/controlnet_image/test/controlnet_openpose/0000.png new file mode 100644 index 0000000000000000000000000000000000000000..0edf0ff98169c96868cb0af9c9aaafe27eb1eba1 --- /dev/null +++ b/animate/data/controlnet_image/test/controlnet_openpose/0000.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:02eb4bc9c7cef99e9b48cb194d93d741da325035db351e2a3bbd2a6d8e482e63 +size 579896 diff --git a/animate/data/controlnet_image/test/controlnet_openpose/0016.png b/animate/data/controlnet_image/test/controlnet_openpose/0016.png new file mode 100644 index 0000000000000000000000000000000000000000..505de357692e46c37b6b2889e863fd021faee093 --- /dev/null +++ b/animate/data/controlnet_image/test/controlnet_openpose/0016.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:51ad874d1186c4ebdf88c8aff44bce3dc75c7046bc567fb01ad9653c8b213f42 +size 584145 diff --git a/animate/data/controlnet_image/test/controlnet_openpose/0032.png b/animate/data/controlnet_image/test/controlnet_openpose/0032.png new file mode 100644 index 0000000000000000000000000000000000000000..79622a9278650f35e437c8f918a58acfc73f7780 --- /dev/null +++ b/animate/data/controlnet_image/test/controlnet_openpose/0032.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:ee5b1e6937646d08783eaddc3718874acfab976307afbb39a4461461b7caa1c2 +size 497193 diff --git a/animate/data/controlnet_image/test/controlnet_openpose/put_pngs_here.txt b/animate/data/controlnet_image/test/controlnet_openpose/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/controlnet_image/test/controlnet_scribble/put_pngs_here.txt b/animate/data/controlnet_image/test/controlnet_scribble/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/controlnet_image/test/controlnet_seg/put_pngs_here.txt b/animate/data/controlnet_image/test/controlnet_seg/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/controlnet_image/test/controlnet_shuffle/put_pngs_here.txt b/animate/data/controlnet_image/test/controlnet_shuffle/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/controlnet_image/test/controlnet_softedge/0000.png b/animate/data/controlnet_image/test/controlnet_softedge/0000.png new file mode 100644 index 0000000000000000000000000000000000000000..0edf0ff98169c96868cb0af9c9aaafe27eb1eba1 --- /dev/null +++ b/animate/data/controlnet_image/test/controlnet_softedge/0000.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:02eb4bc9c7cef99e9b48cb194d93d741da325035db351e2a3bbd2a6d8e482e63 +size 579896 diff --git a/animate/data/controlnet_image/test/controlnet_softedge/0016.png b/animate/data/controlnet_image/test/controlnet_softedge/0016.png new file mode 100644 index 0000000000000000000000000000000000000000..505de357692e46c37b6b2889e863fd021faee093 --- /dev/null +++ b/animate/data/controlnet_image/test/controlnet_softedge/0016.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:51ad874d1186c4ebdf88c8aff44bce3dc75c7046bc567fb01ad9653c8b213f42 +size 584145 diff --git a/animate/data/controlnet_image/test/controlnet_softedge/0032.png b/animate/data/controlnet_image/test/controlnet_softedge/0032.png new file mode 100644 index 0000000000000000000000000000000000000000..79622a9278650f35e437c8f918a58acfc73f7780 --- /dev/null +++ b/animate/data/controlnet_image/test/controlnet_softedge/0032.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:ee5b1e6937646d08783eaddc3718874acfab976307afbb39a4461461b7caa1c2 +size 497193 diff --git a/animate/data/controlnet_image/test/controlnet_softedge/put_pngs_here.txt b/animate/data/controlnet_image/test/controlnet_softedge/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/controlnet_image/test/controlnet_tile/put_pngs_here.txt b/animate/data/controlnet_image/test/controlnet_tile/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/controlnet_image/test/qr_code_monster_v1/put_pngs_here.txt b/animate/data/controlnet_image/test/qr_code_monster_v1/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/controlnet_image/test/qr_code_monster_v2/put_pngs_here.txt b/animate/data/controlnet_image/test/qr_code_monster_v2/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/embeddings/.gitignore b/animate/data/embeddings/.gitignore new file mode 100644 index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d --- /dev/null +++ b/animate/data/embeddings/.gitignore @@ -0,0 +1,2 @@ +* +!.gitignore diff --git a/animate/data/init_imgs/sample0/00000000.png b/animate/data/init_imgs/sample0/00000000.png new file mode 100644 index 0000000000000000000000000000000000000000..9cd81d4241f6209c0dee87b3e8b6207ea2b28f2d --- /dev/null +++ b/animate/data/init_imgs/sample0/00000000.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:e15ef3b0b55bcff3d39bd885904e24630fed5bec5db40187f0ea1cb51c46bd07 +size 931695 diff --git a/animate/data/init_imgs/sample0/00000001.png b/animate/data/init_imgs/sample0/00000001.png new file mode 100644 index 0000000000000000000000000000000000000000..b53ba07bcf2eb942837bb19cca2fca99b3d8c61d --- /dev/null +++ b/animate/data/init_imgs/sample0/00000001.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:43bce27ea2bbae1dbaeb670764b2ca151a0e150e32a807400082369ddbe369ff +size 933870 diff --git a/animate/data/init_imgs/sample0/00000002.png b/animate/data/init_imgs/sample0/00000002.png new file mode 100644 index 0000000000000000000000000000000000000000..1012fd35100ce457c23930dbffb9f0a46ae6dcac --- /dev/null +++ b/animate/data/init_imgs/sample0/00000002.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:c80c8e22d04304d30edd26547bfc0718d6e66189ecd7799e4918453cafe83d9d +size 933434 diff --git a/animate/data/init_imgs/sample0/00000003.png b/animate/data/init_imgs/sample0/00000003.png new file mode 100644 index 0000000000000000000000000000000000000000..5a4411450d91a2b43fad859cb08e158f36b8b034 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000003.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:6086804f674d7395cf3728479931f9650895ced2cc5ca6cad664675ede98a9b9 +size 936635 diff --git a/animate/data/init_imgs/sample0/00000004.png b/animate/data/init_imgs/sample0/00000004.png new file mode 100644 index 0000000000000000000000000000000000000000..230628aab14353851bb6203f43a30d895d73b41e --- /dev/null +++ b/animate/data/init_imgs/sample0/00000004.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:cfe708e0b368a55b2f1e66096f1bf7f1b0f6940a324272c5124650ac0bc1c5d7 +size 938842 diff --git a/animate/data/init_imgs/sample0/00000005.png b/animate/data/init_imgs/sample0/00000005.png new file mode 100644 index 0000000000000000000000000000000000000000..40b2a865dae8c0a709840d2743081a4dc2ce9cb8 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000005.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:575a89363d0cb46a659f567782d592804ae00933aa7d2edcd8ef3eeaa943645d +size 938980 diff --git a/animate/data/init_imgs/sample0/00000006.png b/animate/data/init_imgs/sample0/00000006.png new file mode 100644 index 0000000000000000000000000000000000000000..03961658cc74eaf01fb7237e71e162c0840b8619 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000006.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:be70e598d9f453bc692e6e3889e04c7d044b24f15be35ca363fc1d6b19008d18 +size 939765 diff --git a/animate/data/init_imgs/sample0/00000007.png b/animate/data/init_imgs/sample0/00000007.png new file mode 100644 index 0000000000000000000000000000000000000000..dee756d49dc64fb2dc9e2e965b8bafa6d27f9479 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000007.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:594199d24d431428cc36112717b498ab3a37579f20b01d380a9e8b1aa3ddcdea +size 940101 diff --git a/animate/data/init_imgs/sample0/00000008.png b/animate/data/init_imgs/sample0/00000008.png new file mode 100644 index 0000000000000000000000000000000000000000..42c6a5f294407a779225d5cbcd4ea787d7d4b67b --- /dev/null +++ b/animate/data/init_imgs/sample0/00000008.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:229e8c63874047a0cbc3bc1812816e0c07b9bd5a36a522ca89bbc3d9029e95a4 +size 939038 diff --git a/animate/data/init_imgs/sample0/00000009.png b/animate/data/init_imgs/sample0/00000009.png new file mode 100644 index 0000000000000000000000000000000000000000..37251df3e5fe493bb443086d07ddc5b5ff8a3a01 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000009.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:3e9e6600a0e017146e18927c62469538ba5ca88a718211d21473af2d2b36dc55 +size 935685 diff --git a/animate/data/init_imgs/sample0/00000010.png b/animate/data/init_imgs/sample0/00000010.png new file mode 100644 index 0000000000000000000000000000000000000000..41ac212df1fa15bbadd09be2116a5fe7f55106c7 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000010.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:1930aeff736e3ab8ba076f3aa4b7a12945c511f6334daff594e6d4ffba9d9cf8 +size 934209 diff --git a/animate/data/init_imgs/sample0/00000011.png b/animate/data/init_imgs/sample0/00000011.png new file mode 100644 index 0000000000000000000000000000000000000000..4e260fb873d38f3044edfef895dae11ba85f5eee --- /dev/null +++ b/animate/data/init_imgs/sample0/00000011.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:5f33ba0eb6653646300e95b005c0d366e135547d80bcb702afb5db1cedf2ef49 +size 931270 diff --git a/animate/data/init_imgs/sample0/00000012.png b/animate/data/init_imgs/sample0/00000012.png new file mode 100644 index 0000000000000000000000000000000000000000..ce5872ddedb9e58f30e60cd87b3c665e37484671 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000012.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:2a5e0b6b044b520bf47c39ea51746cfd38c0e122218d311eb010bf615b5a7fb8 +size 931510 diff --git a/animate/data/init_imgs/sample0/00000013.png b/animate/data/init_imgs/sample0/00000013.png new file mode 100644 index 0000000000000000000000000000000000000000..1c7cf20f87a2e6b06c36c191d63c2be89458b859 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000013.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:de8353d166201f5cbbd9c28a9ce61b1899fa2108e735ca8f06e3e8078262e5af +size 928893 diff --git a/animate/data/init_imgs/sample0/00000014.png b/animate/data/init_imgs/sample0/00000014.png new file mode 100644 index 0000000000000000000000000000000000000000..e7215ac4278c7afe359c786f6404dc8af76c3463 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000014.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:83e6a09da37b1afec3e4f734f50fcf4ec5e63944e2b2eae46b24bdc73a62ce46 +size 927344 diff --git a/animate/data/init_imgs/sample0/00000015.png b/animate/data/init_imgs/sample0/00000015.png new file mode 100644 index 0000000000000000000000000000000000000000..56df234854208852ef307b4926598ec74ca36cbb --- /dev/null +++ b/animate/data/init_imgs/sample0/00000015.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:968763dcbd725710ef6364d5cd2ef3e24b1ab61cce2fa23bc18fedc4740cec22 +size 928411 diff --git a/animate/data/init_imgs/sample0/00000016.png b/animate/data/init_imgs/sample0/00000016.png new file mode 100644 index 0000000000000000000000000000000000000000..f9a9e63b9124f683cce195bdc97e8f7f470af464 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000016.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:5dd2cb590adc6d4ece5d7f51d308181a3a1d226d5df2d496e00ae399ceb7804a +size 929289 diff --git a/animate/data/init_imgs/sample0/00000017.png b/animate/data/init_imgs/sample0/00000017.png new file mode 100644 index 0000000000000000000000000000000000000000..3d6365ac43c080dc6f7599bc186c48612642a838 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000017.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:7b0faacd0555d1eaf62d25546f3ed524a6009617282aa1d4de2448307320909e +size 925595 diff --git a/animate/data/init_imgs/sample0/00000018.png b/animate/data/init_imgs/sample0/00000018.png new file mode 100644 index 0000000000000000000000000000000000000000..e01fc775fff8e09b4469d425c04f4284b0ef74f0 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000018.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:56a8c8ff6061b09129b03c6f8b48ba637f96074bd92a36891f933af416b0b491 +size 925952 diff --git a/animate/data/init_imgs/sample0/00000019.png b/animate/data/init_imgs/sample0/00000019.png new file mode 100644 index 0000000000000000000000000000000000000000..8c616c2bb3599a46b36319d66d0a896dca9e2846 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000019.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:70bfe3e9c4e17d7ac39908ea0305f9ca52d7b17324314e9a8ba822911db8b65a +size 925620 diff --git a/animate/data/init_imgs/sample0/00000020.png b/animate/data/init_imgs/sample0/00000020.png new file mode 100644 index 0000000000000000000000000000000000000000..1641b94bb582c2339e56480408c80edc3b1f620a --- /dev/null +++ b/animate/data/init_imgs/sample0/00000020.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:8fa0660abcf51e18e1092dbcaa87a5988dd55c37d4982a9c432882b176474641 +size 921763 diff --git a/animate/data/init_imgs/sample0/00000021.png b/animate/data/init_imgs/sample0/00000021.png new file mode 100644 index 0000000000000000000000000000000000000000..95a662966eb4158cb0003a607764aa8ab8c31d7d --- /dev/null +++ b/animate/data/init_imgs/sample0/00000021.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:d7765c07d5ee42ea561c63e5dfd25135ccdbffa5e339e20f325accafaca316b0 +size 922070 diff --git a/animate/data/init_imgs/sample0/00000022.png b/animate/data/init_imgs/sample0/00000022.png new file mode 100644 index 0000000000000000000000000000000000000000..975fb4c937bbee188ad41df90b6f2496d2680908 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000022.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:9e808a5bacd280871dff8d1930445eab92b30513d6df7e5a0e3c5954e63f01d7 +size 921524 diff --git a/animate/data/init_imgs/sample0/00000023.png b/animate/data/init_imgs/sample0/00000023.png new file mode 100644 index 0000000000000000000000000000000000000000..065b3bfbf9c1c3f95aecc77be1da1c0e8ac7a7da --- /dev/null +++ b/animate/data/init_imgs/sample0/00000023.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:df9f985230a957ad9571aae2dc9d4a176c4390ad8de95513bd4ed9452ab90965 +size 923456 diff --git a/animate/data/init_imgs/sample0/00000024.png b/animate/data/init_imgs/sample0/00000024.png new file mode 100644 index 0000000000000000000000000000000000000000..fa91b36b697e4fbe817ca8e6f5260a7682c15d70 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000024.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:721e42476ee068fbf0d4bce8023d99325381306bb442d664908886145a4ed7c0 +size 917420 diff --git a/animate/data/init_imgs/sample0/00000025.png b/animate/data/init_imgs/sample0/00000025.png new file mode 100644 index 0000000000000000000000000000000000000000..7fc78815ac65c602d8dc86242919ee769e512dda --- /dev/null +++ b/animate/data/init_imgs/sample0/00000025.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:050693f1257cfa50ab82152fe73a41a29e125ac87b69dbd67ff1f2df8f3e6eda +size 921543 diff --git a/animate/data/init_imgs/sample0/00000026.png b/animate/data/init_imgs/sample0/00000026.png new file mode 100644 index 0000000000000000000000000000000000000000..f2df3a1b23a309a7bdb34e7a803eb4dda4a1d585 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000026.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:96df4b62522d527945d458f90e3e65fc601d9ccffc032c9fc1be369dca76325b +size 923419 diff --git a/animate/data/init_imgs/sample0/00000027.png b/animate/data/init_imgs/sample0/00000027.png new file mode 100644 index 0000000000000000000000000000000000000000..ddb9698f8490f6593a49116a9f8a909370aee7b7 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000027.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:071a6faaa7149b88e71846735e5457029c3f2456311f874c796cdbf1581bca48 +size 926506 diff --git a/animate/data/init_imgs/sample0/00000028.png b/animate/data/init_imgs/sample0/00000028.png new file mode 100644 index 0000000000000000000000000000000000000000..1558542501a27dd36e151543aa5507f722209fbe --- /dev/null +++ b/animate/data/init_imgs/sample0/00000028.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:27e72d0a409167fdc2b624eac5c1b32062ed632b63c88f4aeccd83cc5a96fe80 +size 929356 diff --git a/animate/data/init_imgs/sample0/00000029.png b/animate/data/init_imgs/sample0/00000029.png new file mode 100644 index 0000000000000000000000000000000000000000..0e718eb7089dd40b1b48a726a90bc6323c799f25 --- /dev/null +++ b/animate/data/init_imgs/sample0/00000029.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:a82a18676ba11921c639a56493df9b76c0431cfa29d6e2fdba3973fefa4327ef +size 930877 diff --git a/animate/data/init_imgs/sample0/00000030.png b/animate/data/init_imgs/sample0/00000030.png new file mode 100644 index 0000000000000000000000000000000000000000..0b3699f47c65126b4af40f576b8178b042aecb4d --- /dev/null +++ b/animate/data/init_imgs/sample0/00000030.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:86ced26f979a5f1ed376da336d83c921ac10f84733e8fbabe269e200ed2fbeb4 +size 931406 diff --git a/animate/data/init_imgs/sample0/00000031.png b/animate/data/init_imgs/sample0/00000031.png new file mode 100644 index 0000000000000000000000000000000000000000..45aec9f0632983aa4fd3b2ae8d7a515f407d77ff --- /dev/null +++ b/animate/data/init_imgs/sample0/00000031.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:fdf327f88141ff8d34b221d12bc4393f3b75a17d6820209a6b6e924128b4e84c +size 928986 diff --git a/animate/data/init_imgs/sample1/00000000.png b/animate/data/init_imgs/sample1/00000000.png new file mode 100644 index 0000000000000000000000000000000000000000..cf7325b216f3a21024830b3d5924b2576e725869 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000000.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:278e7241da76978972e7b77663770db27e6445a11a574e6fd36786e14580e73e +size 980761 diff --git a/animate/data/init_imgs/sample1/00000001.png b/animate/data/init_imgs/sample1/00000001.png new file mode 100644 index 0000000000000000000000000000000000000000..58fcf90cd3e01462c703fc997ad1fd7834b45b7d --- /dev/null +++ b/animate/data/init_imgs/sample1/00000001.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:9a0c2089e51232dc6a0ab14c4a6a854406e33e21d4bbc7b2b18002967f241594 +size 985340 diff --git a/animate/data/init_imgs/sample1/00000002.png b/animate/data/init_imgs/sample1/00000002.png new file mode 100644 index 0000000000000000000000000000000000000000..250f6473b6295a1c27014c7c55ad0fb7611da2e4 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000002.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:f659855f8863fa73f08f31bb54c0bbca44ff2f48a2f4f9d3c1fdf889474bea1d +size 989746 diff --git a/animate/data/init_imgs/sample1/00000003.png b/animate/data/init_imgs/sample1/00000003.png new file mode 100644 index 0000000000000000000000000000000000000000..03aa0d05a411e5bd050abd209ed716de6c14a43c --- /dev/null +++ b/animate/data/init_imgs/sample1/00000003.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:ea085ef078593d3942a3b7f0443a42852cbc7ab340964389ad51c6dff091f513 +size 988683 diff --git a/animate/data/init_imgs/sample1/00000004.png b/animate/data/init_imgs/sample1/00000004.png new file mode 100644 index 0000000000000000000000000000000000000000..78d6d70373ae498884a306e5c2d13a4dff56db77 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000004.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:bdbc0cbfbfceaf85acb705abd0b599f841473bba77585548a3745733d4b2baf2 +size 984843 diff --git a/animate/data/init_imgs/sample1/00000005.png b/animate/data/init_imgs/sample1/00000005.png new file mode 100644 index 0000000000000000000000000000000000000000..350ba3baccc862c1810a4f5611e6ec46c15fcd8e --- /dev/null +++ b/animate/data/init_imgs/sample1/00000005.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:9f37441cba5941a44d6d03676f60f0a01a938b056f159654a003f3c94100041e +size 982764 diff --git a/animate/data/init_imgs/sample1/00000006.png b/animate/data/init_imgs/sample1/00000006.png new file mode 100644 index 0000000000000000000000000000000000000000..478d77f07706aa566e6ef58c07741f1fc10bc12b --- /dev/null +++ b/animate/data/init_imgs/sample1/00000006.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:bd507ae37d544407b9ae1cd1a0b08354940232c5a188d6ead5dbf3d5c6043a45 +size 984485 diff --git a/animate/data/init_imgs/sample1/00000007.png b/animate/data/init_imgs/sample1/00000007.png new file mode 100644 index 0000000000000000000000000000000000000000..d9478b221d11226bfa154a6d26ce077176907542 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000007.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:2884f94e7c777c80538a60e1c95acf378251377e5c44ddb3f58e0b8bb534c783 +size 981765 diff --git a/animate/data/init_imgs/sample1/00000008.png b/animate/data/init_imgs/sample1/00000008.png new file mode 100644 index 0000000000000000000000000000000000000000..3f9d26c6469cdfc6a0999ffadc41fd29f44e0faf --- /dev/null +++ b/animate/data/init_imgs/sample1/00000008.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:617f60b43f36226fb9508a6e1a7b67aa7dca1708490aa3f541cda4c92aad55b0 +size 980562 diff --git a/animate/data/init_imgs/sample1/00000009.png b/animate/data/init_imgs/sample1/00000009.png new file mode 100644 index 0000000000000000000000000000000000000000..34859025f4e5492c298fe6290beb829bc0368440 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000009.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:d30a399e4e4720c7e93742ef1ac5815a8d8fcf0b7906cdf195a6256ac670ed70 +size 981234 diff --git a/animate/data/init_imgs/sample1/00000010.png b/animate/data/init_imgs/sample1/00000010.png new file mode 100644 index 0000000000000000000000000000000000000000..339377ffd8d5556119b0acefd9700bccb1cd1069 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000010.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:f740999cce6c1704186610b01aadde171ea7ca47caa05b76928b60d1c0ced2ae +size 987402 diff --git a/animate/data/init_imgs/sample1/00000011.png b/animate/data/init_imgs/sample1/00000011.png new file mode 100644 index 0000000000000000000000000000000000000000..5b615b420a9e4281fae055484450c0a76f8ac3b6 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000011.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:1c43e1c1049c4a6d1abbb967f0a7d151bb359793ae2c8c459b11d24eef02f6be +size 984674 diff --git a/animate/data/init_imgs/sample1/00000012.png b/animate/data/init_imgs/sample1/00000012.png new file mode 100644 index 0000000000000000000000000000000000000000..269cf9d5cde33fff5be9c9bfeaa52bd98880a015 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000012.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:e90434de225cb81855c55e117f4b6b87841d553d36f8d83baf774025d2bd86e5 +size 984626 diff --git a/animate/data/init_imgs/sample1/00000013.png b/animate/data/init_imgs/sample1/00000013.png new file mode 100644 index 0000000000000000000000000000000000000000..62662f5df9212588e978c076091c2e8b78da5fbf --- /dev/null +++ b/animate/data/init_imgs/sample1/00000013.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:551ce254d598217ba9a5d8cbfb0fe88df98b8bf07a39a6d32099f8d1ed909fc2 +size 991803 diff --git a/animate/data/init_imgs/sample1/00000014.png b/animate/data/init_imgs/sample1/00000014.png new file mode 100644 index 0000000000000000000000000000000000000000..8f11a6ea5ee83a1ed433985a371af7dbf58ea3df --- /dev/null +++ b/animate/data/init_imgs/sample1/00000014.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:7e064ecc4dfd661786118a875000540cc9f4ff83856a4ccce51aa1fbd8e9b778 +size 991103 diff --git a/animate/data/init_imgs/sample1/00000015.png b/animate/data/init_imgs/sample1/00000015.png new file mode 100644 index 0000000000000000000000000000000000000000..6f37097d4d38497749561f3cada194ebb6515c9d --- /dev/null +++ b/animate/data/init_imgs/sample1/00000015.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:ea27a917862e77dfd44b7c4fed61d5a12cebf3a12aa1172aa1b0df8b2de82320 +size 993828 diff --git a/animate/data/init_imgs/sample1/00000016.png b/animate/data/init_imgs/sample1/00000016.png new file mode 100644 index 0000000000000000000000000000000000000000..d7f6254ed9bc89058cedf26da82f14c9afe7331f --- /dev/null +++ b/animate/data/init_imgs/sample1/00000016.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:ee87424f42a7b51a1e28f9a0857f63b38ce0e4c4383266ec5f820a4ac84a1e9f +size 994877 diff --git a/animate/data/init_imgs/sample1/00000017.png b/animate/data/init_imgs/sample1/00000017.png new file mode 100644 index 0000000000000000000000000000000000000000..96e8522db601784725a075c4865dc6e48863cc62 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000017.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:42eeeb1ed62b11d6950bdf9b14d3fd4155dc24a12766fd5877d07273260f0be0 +size 994819 diff --git a/animate/data/init_imgs/sample1/00000018.png b/animate/data/init_imgs/sample1/00000018.png new file mode 100644 index 0000000000000000000000000000000000000000..55fc7cf504c6b6a44b0e286cadf21b5282d56a56 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000018.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:3f7707568e1f27d673655e19d4095d1e610d38d077839b3fdeba84324e04c896 +size 994423 diff --git a/animate/data/init_imgs/sample1/00000019.png b/animate/data/init_imgs/sample1/00000019.png new file mode 100644 index 0000000000000000000000000000000000000000..5463d7a3053312db93c9e0b0df42c376dd04510d --- /dev/null +++ b/animate/data/init_imgs/sample1/00000019.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:06400146e01f354584473a20ac3527295c6b2866b0e4d1f3ab226a40df7847bc +size 990971 diff --git a/animate/data/init_imgs/sample1/00000020.png b/animate/data/init_imgs/sample1/00000020.png new file mode 100644 index 0000000000000000000000000000000000000000..46ea979371a3e84131ff79e1a3f69593926703e7 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000020.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:a8c02b3a2accbe47824f1e1a1ce2938ff60a4819d6b2bf1f4631761d970152eb +size 992188 diff --git a/animate/data/init_imgs/sample1/00000021.png b/animate/data/init_imgs/sample1/00000021.png new file mode 100644 index 0000000000000000000000000000000000000000..a424383b88270f56907253c085e1738fb7513a29 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000021.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:3fdba72999bce889844e523fee276fd664a5f5b3152faffb1f41a6447e96d4de +size 989605 diff --git a/animate/data/init_imgs/sample1/00000022.png b/animate/data/init_imgs/sample1/00000022.png new file mode 100644 index 0000000000000000000000000000000000000000..1e2025d2694b8ae21c0d56c177cd952b91717654 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000022.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:215e7af51a50221fb7c2bdb626a17f4fc1223b7964480c1e8c80f923b65fd129 +size 986349 diff --git a/animate/data/init_imgs/sample1/00000023.png b/animate/data/init_imgs/sample1/00000023.png new file mode 100644 index 0000000000000000000000000000000000000000..218e9ae7427060a31669d304f10a5b3ab21d55a0 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000023.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:f643fd204c05c7d0664930182353985c8b4b2432610a01e38ba5a67ed49ab2a7 +size 988400 diff --git a/animate/data/init_imgs/sample1/00000024.png b/animate/data/init_imgs/sample1/00000024.png new file mode 100644 index 0000000000000000000000000000000000000000..7cc769b218a01127d6795ec180a5648131a29e71 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000024.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:9685887c525f96f3328f8c39695d39df546f561960e1bc1571c008e2676438d8 +size 974030 diff --git a/animate/data/init_imgs/sample1/00000025.png b/animate/data/init_imgs/sample1/00000025.png new file mode 100644 index 0000000000000000000000000000000000000000..73828aa243c82f4fdea50e2e6978127741162be8 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000025.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:42f80231e052db4db840c8a6b68a6cea63d8a277bedd6c18f42e16a795e5fae1 +size 975810 diff --git a/animate/data/init_imgs/sample1/00000026.png b/animate/data/init_imgs/sample1/00000026.png new file mode 100644 index 0000000000000000000000000000000000000000..a51436658ead28ab93eb2e57e43e2fd03858d900 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000026.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:394a222ea6bd631a7975761ab5bab3f0445f1f3c20897429c8a11f39299165fd +size 970417 diff --git a/animate/data/init_imgs/sample1/00000027.png b/animate/data/init_imgs/sample1/00000027.png new file mode 100644 index 0000000000000000000000000000000000000000..bbd047fbc49a2029e2e85a547d14aacd08e44a7b --- /dev/null +++ b/animate/data/init_imgs/sample1/00000027.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:6a9bb1938c27a65565b8cbc17fec02736ca642f621b20266c41c7dd8ff16406e +size 968389 diff --git a/animate/data/init_imgs/sample1/00000028.png b/animate/data/init_imgs/sample1/00000028.png new file mode 100644 index 0000000000000000000000000000000000000000..cb7417ab568ec4abf51397bc8973d03dae385dbe --- /dev/null +++ b/animate/data/init_imgs/sample1/00000028.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:e33d119109c51c2b624abd36e689972875d13de3133e3ae48ed71a2276566619 +size 967385 diff --git a/animate/data/init_imgs/sample1/00000029.png b/animate/data/init_imgs/sample1/00000029.png new file mode 100644 index 0000000000000000000000000000000000000000..9a423f6aa67bbe7d9bec6759ba17166b9e1c248c --- /dev/null +++ b/animate/data/init_imgs/sample1/00000029.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:a74672bee967136db421354d126bccc81b21cae4ad147f9f86bceb25cee636d8 +size 971867 diff --git a/animate/data/init_imgs/sample1/00000030.png b/animate/data/init_imgs/sample1/00000030.png new file mode 100644 index 0000000000000000000000000000000000000000..69492465d4fb043ec43dd2707f963e503de2470e --- /dev/null +++ b/animate/data/init_imgs/sample1/00000030.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:1de753b0b79e58bd16c2eb9d66786e50d8ff07dded2475500964a1c205bc0b17 +size 970048 diff --git a/animate/data/init_imgs/sample1/00000031.png b/animate/data/init_imgs/sample1/00000031.png new file mode 100644 index 0000000000000000000000000000000000000000..f894fab427a4f16561018d0563219dfd2462aa5f --- /dev/null +++ b/animate/data/init_imgs/sample1/00000031.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:65f28ff1cc22e374682cf50922e932bfa558b4bc01b92cf14c41116d6fe73509 +size 971464 diff --git a/animate/data/init_imgs/sample1/00000032.png b/animate/data/init_imgs/sample1/00000032.png new file mode 100644 index 0000000000000000000000000000000000000000..0f5da62b217ea3d8f36982c8b070651655977f3f --- /dev/null +++ b/animate/data/init_imgs/sample1/00000032.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:61565fb5ec4c94b525c07fbf88974b4d8f617bfb1fa369bedc10775ded66fe01 +size 969711 diff --git a/animate/data/init_imgs/sample1/00000033.png b/animate/data/init_imgs/sample1/00000033.png new file mode 100644 index 0000000000000000000000000000000000000000..3d12e63f18474365e82518ab65d582eeafb805db --- /dev/null +++ b/animate/data/init_imgs/sample1/00000033.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:3ba75d6906828c03e16d05a8541a5052bc90f486be69fe8d946b8cbed14cc794 +size 972983 diff --git a/animate/data/init_imgs/sample1/00000034.png b/animate/data/init_imgs/sample1/00000034.png new file mode 100644 index 0000000000000000000000000000000000000000..26cd76b584baf1552f51b619ba2042a884a01a08 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000034.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:fad4b2c51f4fc500a9cbd49edc5364a2090c27bd96db53248e265a2b99e7ce80 +size 970505 diff --git a/animate/data/init_imgs/sample1/00000035.png b/animate/data/init_imgs/sample1/00000035.png new file mode 100644 index 0000000000000000000000000000000000000000..f69eab48462ae1a81406b589f5bbd0217d9e4bac --- /dev/null +++ b/animate/data/init_imgs/sample1/00000035.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:9b9d58637d8586ae89dc1fcfc665e3b466f505c6c381f81ff411e6a1222a6742 +size 970474 diff --git a/animate/data/init_imgs/sample1/00000036.png b/animate/data/init_imgs/sample1/00000036.png new file mode 100644 index 0000000000000000000000000000000000000000..5aa3c6619a2cccef3b593f36f2ac06bceddf7d96 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000036.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:6ea4d85d99147d5f7d86c527dd30acc9e9237469a18a0a773e49bd61db0cb3ba +size 966197 diff --git a/animate/data/init_imgs/sample1/00000037.png b/animate/data/init_imgs/sample1/00000037.png new file mode 100644 index 0000000000000000000000000000000000000000..4514a24dc8eb796dd4d4e3c09361956db70d6505 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000037.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:cbb29b1d4e87cbdb566919e7d9ff4f7bc0b272014a526f4be39ed08cc47e7044 +size 964481 diff --git a/animate/data/init_imgs/sample1/00000038.png b/animate/data/init_imgs/sample1/00000038.png new file mode 100644 index 0000000000000000000000000000000000000000..579007ab98bff8e2baee640d886028a69ec3d439 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000038.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:936d5104ad379772f5c10fe780ed54c12c3b3f205a910a87cd2567862640dd00 +size 962344 diff --git a/animate/data/init_imgs/sample1/00000039.png b/animate/data/init_imgs/sample1/00000039.png new file mode 100644 index 0000000000000000000000000000000000000000..77a0efe1c2787064eb8ebb976044099fca285537 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000039.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:034bfd8f4c50a3f947f9db430a490c85c0c46e75c1ab980fd8d041ccf883ae39 +size 963148 diff --git a/animate/data/init_imgs/sample1/00000040.png b/animate/data/init_imgs/sample1/00000040.png new file mode 100644 index 0000000000000000000000000000000000000000..7baf01964052c98a6be5eeb852a357362d3039ba --- /dev/null +++ b/animate/data/init_imgs/sample1/00000040.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:73e786c1cc7c3bc67b9a7a1d8b29129c1187cee4e3dfb1538a4d015d1f528d74 +size 962817 diff --git a/animate/data/init_imgs/sample1/00000041.png b/animate/data/init_imgs/sample1/00000041.png new file mode 100644 index 0000000000000000000000000000000000000000..ff77e9eef7736f3ed44538fb60d9bed7625cbc8b --- /dev/null +++ b/animate/data/init_imgs/sample1/00000041.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:6a8a98f5b7a867de631e211a122dc2374587c08d2dda56360c76ad143536d81b +size 961602 diff --git a/animate/data/init_imgs/sample1/00000042.png b/animate/data/init_imgs/sample1/00000042.png new file mode 100644 index 0000000000000000000000000000000000000000..1e3ec7e332b46f33b055c230d45371253fa56b16 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000042.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:cd91ba92ffcc979398431667f308089978909cc1fca4ff55f4946aea86502210 +size 962245 diff --git a/animate/data/init_imgs/sample1/00000043.png b/animate/data/init_imgs/sample1/00000043.png new file mode 100644 index 0000000000000000000000000000000000000000..74a163d79908f2105702be1bf8f1663f110432dd --- /dev/null +++ b/animate/data/init_imgs/sample1/00000043.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:9164ffcb03d46937b97a38fcac1af26a9511741913561c5ee9b7a302a119a1fe +size 966476 diff --git a/animate/data/init_imgs/sample1/00000044.png b/animate/data/init_imgs/sample1/00000044.png new file mode 100644 index 0000000000000000000000000000000000000000..8f5b087991cee27756099accd1a9352f52a4ef3b --- /dev/null +++ b/animate/data/init_imgs/sample1/00000044.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:651846ec617b2ca4f4a725eef2c1bb7bee34d19eb79c96524cee0fee7d245121 +size 959837 diff --git a/animate/data/init_imgs/sample1/00000045.png b/animate/data/init_imgs/sample1/00000045.png new file mode 100644 index 0000000000000000000000000000000000000000..e16a13f74f77c2fc5ce109d33000477ea5f46658 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000045.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:ad65719b4de234290b0f8117674a9e5d694315cbe7d1851329d245d74acbe00f +size 959114 diff --git a/animate/data/init_imgs/sample1/00000046.png b/animate/data/init_imgs/sample1/00000046.png new file mode 100644 index 0000000000000000000000000000000000000000..7f79102f19117a67f4b0cf402f51870d23920329 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000046.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:b8aa9e824a10dc6424f7cf1eb46426ca23b1f151a7730b11444cf7028a5bd6ce +size 966404 diff --git a/animate/data/init_imgs/sample1/00000047.png b/animate/data/init_imgs/sample1/00000047.png new file mode 100644 index 0000000000000000000000000000000000000000..bb598991479964d0cf5a78c824870688c31c301a --- /dev/null +++ b/animate/data/init_imgs/sample1/00000047.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:e4f758f1b8a223f3aa4c397c789ecde33e9ecef606707e93cce70a7b0d082280 +size 962164 diff --git a/animate/data/init_imgs/sample1/00000048.png b/animate/data/init_imgs/sample1/00000048.png new file mode 100644 index 0000000000000000000000000000000000000000..4d11994c014e094a377f9c1227a5a7259d56537f --- /dev/null +++ b/animate/data/init_imgs/sample1/00000048.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:f717f42b71b38597230a65e87932409c43610037995192d3573d6f41e931e0aa +size 950754 diff --git a/animate/data/init_imgs/sample1/00000049.png b/animate/data/init_imgs/sample1/00000049.png new file mode 100644 index 0000000000000000000000000000000000000000..189fefec3df2239bb6fa3d48e3f5c60c965310e6 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000049.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:81dddfeed7303f32ea30e5938b12bf5881a5ac77e61273ea12f70f29c64f3968 +size 956857 diff --git a/animate/data/init_imgs/sample1/00000050.png b/animate/data/init_imgs/sample1/00000050.png new file mode 100644 index 0000000000000000000000000000000000000000..d7e25f984ed83e3291560d0373c883d08a72b972 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000050.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:d51d1466a017cc49ed0f065e26e11055612a3c7b8809775e4aa55d691e988d68 +size 956332 diff --git a/animate/data/init_imgs/sample1/00000051.png b/animate/data/init_imgs/sample1/00000051.png new file mode 100644 index 0000000000000000000000000000000000000000..503b1ad500e2c740afd1f190722f9d14319001e7 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000051.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:355eac2f8d229ffae5a245a6435330ef3999c22bdabec72489c8b68ed1f40830 +size 958491 diff --git a/animate/data/init_imgs/sample1/00000052.png b/animate/data/init_imgs/sample1/00000052.png new file mode 100644 index 0000000000000000000000000000000000000000..a1eb3ffd1226bc156df11c3972f060200ea2563f --- /dev/null +++ b/animate/data/init_imgs/sample1/00000052.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:8a23cc52e25b862d4cdb744827988aa718628690c003f6ab1729fe5135760518 +size 958844 diff --git a/animate/data/init_imgs/sample1/00000053.png b/animate/data/init_imgs/sample1/00000053.png new file mode 100644 index 0000000000000000000000000000000000000000..bda5207151b7cde2881a04d192b5e6c1117a6dda --- /dev/null +++ b/animate/data/init_imgs/sample1/00000053.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:f5bd120301c456c45ec2a4cc1b852f0a4d00d7fb98a6ac826aa125d9b8cb4748 +size 959915 diff --git a/animate/data/init_imgs/sample1/00000054.png b/animate/data/init_imgs/sample1/00000054.png new file mode 100644 index 0000000000000000000000000000000000000000..fb10d166e0336b02d94ce3b929d7802c233a2243 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000054.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:1651526f04fc21e7e7b0b541336f6483f14ed908cfe2c07d99eeab263b87a9a3 +size 959336 diff --git a/animate/data/init_imgs/sample1/00000055.png b/animate/data/init_imgs/sample1/00000055.png new file mode 100644 index 0000000000000000000000000000000000000000..4d5d53de52ab472fbb0afb68e08c96bc63ad0065 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000055.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:814c2a75dcb717ec4113708005dbec01268c348c500bf3d5a131da6fae67a655 +size 963567 diff --git a/animate/data/init_imgs/sample1/00000056.png b/animate/data/init_imgs/sample1/00000056.png new file mode 100644 index 0000000000000000000000000000000000000000..abd7a537e3e1f91cdc8ea1db0c9463abef4e0a79 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000056.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:e2909ac39c6ff6e58f1acd3a0238f5edb6234911dcf752abc207dda517ef184c +size 955475 diff --git a/animate/data/init_imgs/sample1/00000057.png b/animate/data/init_imgs/sample1/00000057.png new file mode 100644 index 0000000000000000000000000000000000000000..572182eaf4c918918815271dcf019b21d4de91eb --- /dev/null +++ b/animate/data/init_imgs/sample1/00000057.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:fa5813af5dbbb062597b5b5d80c6fa4b77075afda33588067d962693df0d74d5 +size 953150 diff --git a/animate/data/init_imgs/sample1/00000058.png b/animate/data/init_imgs/sample1/00000058.png new file mode 100644 index 0000000000000000000000000000000000000000..c70323e9f1bc853b198d6116af68b74d90e37e0f --- /dev/null +++ b/animate/data/init_imgs/sample1/00000058.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:cbe57c7686e6b5ca1a838b77103251d98b3015b8dafcd0199ddfd75ff3c5afdb +size 948059 diff --git a/animate/data/init_imgs/sample1/00000059.png b/animate/data/init_imgs/sample1/00000059.png new file mode 100644 index 0000000000000000000000000000000000000000..eed765ea872258dd86b13931c6cb70f728828e02 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000059.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:ec11d742aa004616388eb69b7a8e4568752b8f6e5446df28368fef2fe4e3657d +size 953801 diff --git a/animate/data/init_imgs/sample1/00000060.png b/animate/data/init_imgs/sample1/00000060.png new file mode 100644 index 0000000000000000000000000000000000000000..b83800ebc349cf2c1997627d356058e887229d7e --- /dev/null +++ b/animate/data/init_imgs/sample1/00000060.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:055213efbfdd18af75732039962edaec7862049ca31b96bf8366deec19c68467 +size 948161 diff --git a/animate/data/init_imgs/sample1/00000061.png b/animate/data/init_imgs/sample1/00000061.png new file mode 100644 index 0000000000000000000000000000000000000000..4a62be83d94b275bcdff674f99d50f2aebfe20ed --- /dev/null +++ b/animate/data/init_imgs/sample1/00000061.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:abef68884ec4a0d9a60c8af6c4f02f4ce41f07d5b110459d49907f117208fa6c +size 951319 diff --git a/animate/data/init_imgs/sample1/00000062.png b/animate/data/init_imgs/sample1/00000062.png new file mode 100644 index 0000000000000000000000000000000000000000..74cf7ae9193dbb1ac0b3e6783ae149fbbc49ab6a --- /dev/null +++ b/animate/data/init_imgs/sample1/00000062.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:40fb5d4b6505f936686960a8a1efb08f4692c1733b8c4adabb3b99e9b17fe3cc +size 950596 diff --git a/animate/data/init_imgs/sample1/00000063.png b/animate/data/init_imgs/sample1/00000063.png new file mode 100644 index 0000000000000000000000000000000000000000..ac8522368986ce4dc3f46a02fad56c0bd1761153 --- /dev/null +++ b/animate/data/init_imgs/sample1/00000063.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:39d2088988a75917b2436d182e0ebadc02afc22c73ba1f0c6869e7d8f01c7676 +size 954336 diff --git a/animate/data/ip_adapter_image/cat/0000.png b/animate/data/ip_adapter_image/cat/0000.png new file mode 100644 index 0000000000000000000000000000000000000000..92fe49467eab65e7665361503e7b45bac05723c8 --- /dev/null +++ b/animate/data/ip_adapter_image/cat/0000.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:343e283442a0d843221fa0cd21e130300c065fe09b739be93bfd7cb7c8bd4776 +size 304456 diff --git a/animate/data/ip_adapter_image/cyberpunk/0000.png b/animate/data/ip_adapter_image/cyberpunk/0000.png new file mode 100644 index 0000000000000000000000000000000000000000..6cfc64bb46be81252df7353a9df387fee64acabc --- /dev/null +++ b/animate/data/ip_adapter_image/cyberpunk/0000.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:3a2d1442c2449e721b42b28066390365a658e46f451b9669fd489810a92d730c +size 668146 diff --git a/animate/data/ip_adapter_image/dungeon/0000.png b/animate/data/ip_adapter_image/dungeon/0000.png new file mode 100644 index 0000000000000000000000000000000000000000..afa691f24c6dd48c0a5ad6f48f59a9ce6ea92e9e --- /dev/null +++ b/animate/data/ip_adapter_image/dungeon/0000.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:80504e6c88bdc1171a13dc6413a82ec09fbc07ada1c71d2d00fed8c5a39b95a9 +size 151950 diff --git a/animate/data/ip_adapter_image/girl/0000.png b/animate/data/ip_adapter_image/girl/0000.png new file mode 100644 index 0000000000000000000000000000000000000000..fc7290718783faf537a790a3a76b53b60d4dd87c --- /dev/null +++ b/animate/data/ip_adapter_image/girl/0000.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:dd409402a4faab882ddc17d053febd52ea8309623e9c2603069d896ae000919b +size 705526 diff --git a/animate/data/ip_adapter_image/test/put_pngs_here.txt b/animate/data/ip_adapter_image/test/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/mask/area0/00000.png b/animate/data/mask/area0/00000.png new file mode 100644 index 0000000000000000000000000000000000000000..5d8c079ce38039810ad4502645d3f712ceddfa75 Binary files /dev/null and b/animate/data/mask/area0/00000.png differ diff --git a/animate/data/mask/area1/00000.png b/animate/data/mask/area1/00000.png new file mode 100644 index 0000000000000000000000000000000000000000..0b40f35bb7bc8f06afe7ad763272e9a18183f7e3 Binary files /dev/null and b/animate/data/mask/area1/00000.png differ diff --git a/animate/data/mask/etc/00000.png b/animate/data/mask/etc/00000.png new file mode 100644 index 0000000000000000000000000000000000000000..cd2db4baa1c8c2a89b645d0e67189a13084e13b3 Binary files /dev/null and b/animate/data/mask/etc/00000.png differ diff --git a/animate/data/mask/etc/100000.png b/animate/data/mask/etc/100000.png new file mode 100644 index 0000000000000000000000000000000000000000..af465fafcd417f3615c1ad51d23736a704aa9642 Binary files /dev/null and b/animate/data/mask/etc/100000.png differ diff --git a/animate/data/mask/etc/200000.png b/animate/data/mask/etc/200000.png new file mode 100644 index 0000000000000000000000000000000000000000..a047c4c87d6b1470508ae78f400efdedeab4b3d3 Binary files /dev/null and b/animate/data/mask/etc/200000.png differ diff --git a/animate/data/mask/sample0/00000.png b/animate/data/mask/sample0/00000.png new file mode 100644 index 0000000000000000000000000000000000000000..0d8406d3a47ad2d485d72242002b2fabfe752d88 Binary files /dev/null and b/animate/data/mask/sample0/00000.png differ diff --git a/animate/data/mask/sample1/00000000.png b/animate/data/mask/sample1/00000000.png new file mode 100644 index 0000000000000000000000000000000000000000..2286febee873fd8a9955ef5c95fd55bb6031fcf6 Binary files /dev/null and b/animate/data/mask/sample1/00000000.png differ diff --git a/animate/data/mask/sample1/00000001.png b/animate/data/mask/sample1/00000001.png new file mode 100644 index 0000000000000000000000000000000000000000..8faa35a7eced632a5c96d8b28b38169961917500 Binary files /dev/null and b/animate/data/mask/sample1/00000001.png differ diff --git a/animate/data/mask/sample1/00000002.png b/animate/data/mask/sample1/00000002.png new file mode 100644 index 0000000000000000000000000000000000000000..a7c8d05054874816e08251b29465d3c5571005fd Binary files /dev/null and b/animate/data/mask/sample1/00000002.png differ diff --git a/animate/data/mask/sample1/00000003.png b/animate/data/mask/sample1/00000003.png new file mode 100644 index 0000000000000000000000000000000000000000..e11862a375d94d1845922cf014c3d6525dec8bcf Binary files /dev/null and b/animate/data/mask/sample1/00000003.png differ diff --git a/animate/data/mask/sample1/00000004.png b/animate/data/mask/sample1/00000004.png new file mode 100644 index 0000000000000000000000000000000000000000..41f8cc0a45bd3b04accd4d14c9d6d7e3c74d1d76 Binary files /dev/null and b/animate/data/mask/sample1/00000004.png differ diff --git a/animate/data/mask/sample1/00000005.png b/animate/data/mask/sample1/00000005.png new file mode 100644 index 0000000000000000000000000000000000000000..9426d2bcf9c1b15f855f1ae5957a7e1e7b4facd5 Binary files /dev/null and b/animate/data/mask/sample1/00000005.png differ diff --git a/animate/data/mask/sample1/00000006.png b/animate/data/mask/sample1/00000006.png new file mode 100644 index 0000000000000000000000000000000000000000..7e5923f325050528b750fca10a808e8f554e585a Binary files /dev/null and b/animate/data/mask/sample1/00000006.png differ diff --git a/animate/data/mask/sample1/00000007.png b/animate/data/mask/sample1/00000007.png new file mode 100644 index 0000000000000000000000000000000000000000..318f4d951b5dd788eb838112e07f10f9a865afc3 Binary files /dev/null and b/animate/data/mask/sample1/00000007.png differ diff --git a/animate/data/mask/sample1/00000008.png b/animate/data/mask/sample1/00000008.png new file mode 100644 index 0000000000000000000000000000000000000000..eeaba87f32495c3f8886f71b5439a6e2d0666e41 Binary files /dev/null and b/animate/data/mask/sample1/00000008.png differ diff --git a/animate/data/mask/sample1/00000009.png b/animate/data/mask/sample1/00000009.png new file mode 100644 index 0000000000000000000000000000000000000000..a95a35f29294324335cfbd1c1e92dcba458661a1 Binary files /dev/null and b/animate/data/mask/sample1/00000009.png differ diff --git a/animate/data/mask/sample1/00000010.png b/animate/data/mask/sample1/00000010.png new file mode 100644 index 0000000000000000000000000000000000000000..28bc91c4a78cbaf0e75f9cc6f26daa377afab08a Binary files /dev/null and b/animate/data/mask/sample1/00000010.png differ diff --git a/animate/data/mask/sample1/00000011.png b/animate/data/mask/sample1/00000011.png new file mode 100644 index 0000000000000000000000000000000000000000..c0b2f1bc0b248d25bf0aeff11c14194bde6b871c Binary files /dev/null and b/animate/data/mask/sample1/00000011.png differ diff --git a/animate/data/mask/sample1/00000012.png b/animate/data/mask/sample1/00000012.png new file mode 100644 index 0000000000000000000000000000000000000000..3c63196434f88430324a7149af85b82a619a2f11 Binary files /dev/null and b/animate/data/mask/sample1/00000012.png differ diff --git a/animate/data/mask/sample1/00000013.png b/animate/data/mask/sample1/00000013.png new file mode 100644 index 0000000000000000000000000000000000000000..d87e73b5658de274667134e04070d905f3a4242b Binary files /dev/null and b/animate/data/mask/sample1/00000013.png differ diff --git a/animate/data/mask/sample1/00000014.png b/animate/data/mask/sample1/00000014.png new file mode 100644 index 0000000000000000000000000000000000000000..3a3c29c353f6e9388300ca79fb5212836ecea7a3 Binary files /dev/null and b/animate/data/mask/sample1/00000014.png differ diff --git a/animate/data/mask/sample1/00000015.png b/animate/data/mask/sample1/00000015.png new file mode 100644 index 0000000000000000000000000000000000000000..65e7035195b5f62c5c25677ad35e7244da7da1f7 Binary files /dev/null and b/animate/data/mask/sample1/00000015.png differ diff --git a/animate/data/mask/sample1/00000016.png b/animate/data/mask/sample1/00000016.png new file mode 100644 index 0000000000000000000000000000000000000000..021d650a8758ac5613b717b42bde37bc2757bcc3 Binary files /dev/null and b/animate/data/mask/sample1/00000016.png differ diff --git a/animate/data/mask/sample1/00000017.png b/animate/data/mask/sample1/00000017.png new file mode 100644 index 0000000000000000000000000000000000000000..2510a671b9a1c4bc051038503a2f81ad9fa37588 Binary files /dev/null and b/animate/data/mask/sample1/00000017.png differ diff --git a/animate/data/mask/sample1/00000018.png b/animate/data/mask/sample1/00000018.png new file mode 100644 index 0000000000000000000000000000000000000000..586a37737079f975b582f1cb3950871804fe7acd Binary files /dev/null and b/animate/data/mask/sample1/00000018.png differ diff --git a/animate/data/mask/sample1/00000019.png b/animate/data/mask/sample1/00000019.png new file mode 100644 index 0000000000000000000000000000000000000000..fd36ee2ea4bd1d4ad07f198e471bcee7070de900 Binary files /dev/null and b/animate/data/mask/sample1/00000019.png differ diff --git a/animate/data/mask/sample1/00000020.png b/animate/data/mask/sample1/00000020.png new file mode 100644 index 0000000000000000000000000000000000000000..0b1237f2d94a78cdbc57103431357a716a770727 Binary files /dev/null and b/animate/data/mask/sample1/00000020.png differ diff --git a/animate/data/mask/sample1/00000021.png b/animate/data/mask/sample1/00000021.png new file mode 100644 index 0000000000000000000000000000000000000000..d249f46b31c960e9f80a21930488452f1355c680 Binary files /dev/null and b/animate/data/mask/sample1/00000021.png differ diff --git a/animate/data/mask/sample1/00000022.png b/animate/data/mask/sample1/00000022.png new file mode 100644 index 0000000000000000000000000000000000000000..4dc3715f5ed72e8ff3a141852207a83d4a74eac8 Binary files /dev/null and b/animate/data/mask/sample1/00000022.png differ diff --git a/animate/data/mask/sample1/00000023.png b/animate/data/mask/sample1/00000023.png new file mode 100644 index 0000000000000000000000000000000000000000..9e51afa1eb8cd5b432f424cae563a5d6644fa966 Binary files /dev/null and b/animate/data/mask/sample1/00000023.png differ diff --git a/animate/data/mask/sample1/00000024.png b/animate/data/mask/sample1/00000024.png new file mode 100644 index 0000000000000000000000000000000000000000..5894b5ab30bdc1a33fc0c599d746692ee4e7c38d Binary files /dev/null and b/animate/data/mask/sample1/00000024.png differ diff --git a/animate/data/mask/sample1/00000025.png b/animate/data/mask/sample1/00000025.png new file mode 100644 index 0000000000000000000000000000000000000000..154a478231dc03125cb944d2d2eb6dbd8c494df7 Binary files /dev/null and b/animate/data/mask/sample1/00000025.png differ diff --git a/animate/data/mask/sample1/00000026.png b/animate/data/mask/sample1/00000026.png new file mode 100644 index 0000000000000000000000000000000000000000..342c5a3619ec4fd38ace9efb3071f4d858681ad6 Binary files /dev/null and b/animate/data/mask/sample1/00000026.png differ diff --git a/animate/data/mask/sample1/00000027.png b/animate/data/mask/sample1/00000027.png new file mode 100644 index 0000000000000000000000000000000000000000..69632e291901e7027470709c2addee114ee92404 Binary files /dev/null and b/animate/data/mask/sample1/00000027.png differ diff --git a/animate/data/mask/sample1/00000028.png b/animate/data/mask/sample1/00000028.png new file mode 100644 index 0000000000000000000000000000000000000000..55e979b7e94ab8d1938257375e65f491560f5f36 Binary files /dev/null and b/animate/data/mask/sample1/00000028.png differ diff --git a/animate/data/mask/sample1/00000029.png b/animate/data/mask/sample1/00000029.png new file mode 100644 index 0000000000000000000000000000000000000000..02b77da0b070e6cbcaafedd2a1354d627d7c8946 Binary files /dev/null and b/animate/data/mask/sample1/00000029.png differ diff --git a/animate/data/mask/sample1/00000030.png b/animate/data/mask/sample1/00000030.png new file mode 100644 index 0000000000000000000000000000000000000000..f8c801dc61ef425343f73d71c2d8618682262df6 Binary files /dev/null and b/animate/data/mask/sample1/00000030.png differ diff --git a/animate/data/mask/sample1/00000031.png b/animate/data/mask/sample1/00000031.png new file mode 100644 index 0000000000000000000000000000000000000000..5350fe7fe76c757e63c9e9bdf898c1d13185d9c5 Binary files /dev/null and b/animate/data/mask/sample1/00000031.png differ diff --git a/animate/data/mask/sample1/00000032.png b/animate/data/mask/sample1/00000032.png new file mode 100644 index 0000000000000000000000000000000000000000..68bff14cd5c92959f3c837ca439cff22edbefc6b Binary files /dev/null and b/animate/data/mask/sample1/00000032.png differ diff --git a/animate/data/mask/sample1/00000033.png b/animate/data/mask/sample1/00000033.png new file mode 100644 index 0000000000000000000000000000000000000000..8c9920b897d1be73a8e260dfc910521a150bd8db Binary files /dev/null and b/animate/data/mask/sample1/00000033.png differ diff --git a/animate/data/mask/sample1/00000034.png b/animate/data/mask/sample1/00000034.png new file mode 100644 index 0000000000000000000000000000000000000000..f8450442d7eb877416b7c3b6486bec05d4d85277 Binary files /dev/null and b/animate/data/mask/sample1/00000034.png differ diff --git a/animate/data/mask/sample1/00000035.png b/animate/data/mask/sample1/00000035.png new file mode 100644 index 0000000000000000000000000000000000000000..49704665e58f9322722af9b025a93c93b9e7e102 Binary files /dev/null and b/animate/data/mask/sample1/00000035.png differ diff --git a/animate/data/mask/sample1/00000036.png b/animate/data/mask/sample1/00000036.png new file mode 100644 index 0000000000000000000000000000000000000000..495eea30d3d0fa2d345e9be13ee90fb4090d6964 Binary files /dev/null and b/animate/data/mask/sample1/00000036.png differ diff --git a/animate/data/mask/sample1/00000037.png b/animate/data/mask/sample1/00000037.png new file mode 100644 index 0000000000000000000000000000000000000000..6065d467449ae0b7a89e1440c0d2102b042ecf2f Binary files /dev/null and b/animate/data/mask/sample1/00000037.png differ diff --git a/animate/data/mask/sample1/00000038.png b/animate/data/mask/sample1/00000038.png new file mode 100644 index 0000000000000000000000000000000000000000..27ea24f5ef2ed2379222c4dc72b96e42fbc1831d Binary files /dev/null and b/animate/data/mask/sample1/00000038.png differ diff --git a/animate/data/mask/sample1/00000039.png b/animate/data/mask/sample1/00000039.png new file mode 100644 index 0000000000000000000000000000000000000000..b1018460c04bbb67715251f2e1b6d1274b6d5aa3 Binary files /dev/null and b/animate/data/mask/sample1/00000039.png differ diff --git a/animate/data/mask/sample1/00000040.png b/animate/data/mask/sample1/00000040.png new file mode 100644 index 0000000000000000000000000000000000000000..10b7814b3dbbc913b8fe40f97264aa9f313cdc4a Binary files /dev/null and b/animate/data/mask/sample1/00000040.png differ diff --git a/animate/data/mask/sample1/00000041.png b/animate/data/mask/sample1/00000041.png new file mode 100644 index 0000000000000000000000000000000000000000..64c9687ba0a7496678ae6e63ef664ac5d2886b30 Binary files /dev/null and b/animate/data/mask/sample1/00000041.png differ diff --git a/animate/data/mask/sample1/00000042.png b/animate/data/mask/sample1/00000042.png new file mode 100644 index 0000000000000000000000000000000000000000..09496c515221362a2b3f91652fd546800480f42f Binary files /dev/null and b/animate/data/mask/sample1/00000042.png differ diff --git a/animate/data/mask/sample1/00000043.png b/animate/data/mask/sample1/00000043.png new file mode 100644 index 0000000000000000000000000000000000000000..9b62caebfd9d24fb1b06a293b126aa95bca2a570 Binary files /dev/null and b/animate/data/mask/sample1/00000043.png differ diff --git a/animate/data/mask/sample1/00000044.png b/animate/data/mask/sample1/00000044.png new file mode 100644 index 0000000000000000000000000000000000000000..5ed2363f133d2ccf5be1433afac14ab77e8ba9a6 Binary files /dev/null and b/animate/data/mask/sample1/00000044.png differ diff --git a/animate/data/mask/sample1/00000045.png b/animate/data/mask/sample1/00000045.png new file mode 100644 index 0000000000000000000000000000000000000000..81e402722fe71c2a38038e9fe964267c608f0c13 Binary files /dev/null and b/animate/data/mask/sample1/00000045.png differ diff --git a/animate/data/mask/sample1/00000046.png b/animate/data/mask/sample1/00000046.png new file mode 100644 index 0000000000000000000000000000000000000000..bd4bb7ac9511ec601843832965843e0e9e71a156 Binary files /dev/null and b/animate/data/mask/sample1/00000046.png differ diff --git a/animate/data/mask/sample1/00000047.png b/animate/data/mask/sample1/00000047.png new file mode 100644 index 0000000000000000000000000000000000000000..716b9f28eb1cb8bba0dce07c27b36d46736a98f5 Binary files /dev/null and b/animate/data/mask/sample1/00000047.png differ diff --git a/animate/data/mask/sample1/00000048.png b/animate/data/mask/sample1/00000048.png new file mode 100644 index 0000000000000000000000000000000000000000..a29977eece0c1b1f0bce137c646e20eebfbf0556 Binary files /dev/null and b/animate/data/mask/sample1/00000048.png differ diff --git a/animate/data/mask/sample1/00000049.png b/animate/data/mask/sample1/00000049.png new file mode 100644 index 0000000000000000000000000000000000000000..b97cbd365fd69ceb9a588ad2009e0cde6b5965ca Binary files /dev/null and b/animate/data/mask/sample1/00000049.png differ diff --git a/animate/data/mask/sample1/00000050.png b/animate/data/mask/sample1/00000050.png new file mode 100644 index 0000000000000000000000000000000000000000..80539d186dce79525002f3935f87df3ef32e02cd Binary files /dev/null and b/animate/data/mask/sample1/00000050.png differ diff --git a/animate/data/mask/sample1/00000051.png b/animate/data/mask/sample1/00000051.png new file mode 100644 index 0000000000000000000000000000000000000000..eff11aa95d5f565522d9e9c613de3fa99768961d Binary files /dev/null and b/animate/data/mask/sample1/00000051.png differ diff --git a/animate/data/mask/sample1/00000052.png b/animate/data/mask/sample1/00000052.png new file mode 100644 index 0000000000000000000000000000000000000000..a19c5a910f4ac221e31b8504bd267d156e5066df Binary files /dev/null and b/animate/data/mask/sample1/00000052.png differ diff --git a/animate/data/mask/sample1/00000053.png b/animate/data/mask/sample1/00000053.png new file mode 100644 index 0000000000000000000000000000000000000000..a91c1c7be99020f13f09e5b7ac37de809d2ee6b9 Binary files /dev/null and b/animate/data/mask/sample1/00000053.png differ diff --git a/animate/data/mask/sample1/00000054.png b/animate/data/mask/sample1/00000054.png new file mode 100644 index 0000000000000000000000000000000000000000..1e0cae16e6450d043da2e9a73aa2a7b7b3858d62 Binary files /dev/null and b/animate/data/mask/sample1/00000054.png differ diff --git a/animate/data/mask/sample1/00000055.png b/animate/data/mask/sample1/00000055.png new file mode 100644 index 0000000000000000000000000000000000000000..604a97d979c57c766695a204c7e2f6da4632c394 Binary files /dev/null and b/animate/data/mask/sample1/00000055.png differ diff --git a/animate/data/mask/sample1/00000056.png b/animate/data/mask/sample1/00000056.png new file mode 100644 index 0000000000000000000000000000000000000000..0de477df6afb16ba3e6bcb0791aa3b9af7020a9b Binary files /dev/null and b/animate/data/mask/sample1/00000056.png differ diff --git a/animate/data/mask/sample1/00000057.png b/animate/data/mask/sample1/00000057.png new file mode 100644 index 0000000000000000000000000000000000000000..9643e80cc6aee1ff8b33b48eefec1ca2fe8f575e Binary files /dev/null and b/animate/data/mask/sample1/00000057.png differ diff --git a/animate/data/mask/sample1/00000058.png b/animate/data/mask/sample1/00000058.png new file mode 100644 index 0000000000000000000000000000000000000000..bbe34c48baee666048b3690a2eb54a90503d8873 Binary files /dev/null and b/animate/data/mask/sample1/00000058.png differ diff --git a/animate/data/mask/sample1/00000059.png b/animate/data/mask/sample1/00000059.png new file mode 100644 index 0000000000000000000000000000000000000000..ed49031be3926be512825b983602550daba9bb16 Binary files /dev/null and b/animate/data/mask/sample1/00000059.png differ diff --git a/animate/data/mask/sample1/00000060.png b/animate/data/mask/sample1/00000060.png new file mode 100644 index 0000000000000000000000000000000000000000..979859bd3535180ae7c0849fb2adac52a0ebe45c Binary files /dev/null and b/animate/data/mask/sample1/00000060.png differ diff --git a/animate/data/mask/sample1/00000061.png b/animate/data/mask/sample1/00000061.png new file mode 100644 index 0000000000000000000000000000000000000000..3f6c30e1d6002705861796a79be024c00d3dcf8b Binary files /dev/null and b/animate/data/mask/sample1/00000061.png differ diff --git a/animate/data/mask/sample1/00000062.png b/animate/data/mask/sample1/00000062.png new file mode 100644 index 0000000000000000000000000000000000000000..bdab96d7aecc87527f2ec7e14faccf533e0e4880 Binary files /dev/null and b/animate/data/mask/sample1/00000062.png differ diff --git a/animate/data/mask/sample1/00000063.png b/animate/data/mask/sample1/00000063.png new file mode 100644 index 0000000000000000000000000000000000000000..89de289143f792ac31e76c1e3dbe3f5baf55f6ce Binary files /dev/null and b/animate/data/mask/sample1/00000063.png differ diff --git a/animate/data/models/.gitignore b/animate/data/models/.gitignore new file mode 100644 index 0000000000000000000000000000000000000000..32d2c400841c9c1e441e1a508059a308205b8442 --- /dev/null +++ b/animate/data/models/.gitignore @@ -0,0 +1,5 @@ +* +!.gitignore +!/huggingface/ +!/sd/ +!/motion-module/ diff --git a/animate/data/models/huggingface/.gitignore b/animate/data/models/huggingface/.gitignore new file mode 100644 index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d --- /dev/null +++ b/animate/data/models/huggingface/.gitignore @@ -0,0 +1,2 @@ +* +!.gitignore diff --git a/animate/data/models/motion-module/.gitignore b/animate/data/models/motion-module/.gitignore new file mode 100644 index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d --- /dev/null +++ b/animate/data/models/motion-module/.gitignore @@ -0,0 +1,2 @@ +* +!.gitignore diff --git a/animate/data/models/sd/.gitignore b/animate/data/models/sd/.gitignore new file mode 100644 index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d --- /dev/null +++ b/animate/data/models/sd/.gitignore @@ -0,0 +1,2 @@ +* +!.gitignore diff --git a/animate/data/ref_image/put_pngs_here.txt b/animate/data/ref_image/put_pngs_here.txt new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/data/ref_image/ref_sample.png b/animate/data/ref_image/ref_sample.png new file mode 100644 index 0000000000000000000000000000000000000000..4702fb6913940b9cc8e64da2f16b643e2b4d0147 --- /dev/null +++ b/animate/data/ref_image/ref_sample.png @@ -0,0 +1,3 @@ +version https://git-lfs.github.com/spec/v1 +oid sha256:477e1cd397869b1166a5d277b7b69c0438c7036542405b01123eda0756cf5ed4 +size 1043522 diff --git a/animate/data/rife/.gitignore b/animate/data/rife/.gitignore new file mode 100644 index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d --- /dev/null +++ b/animate/data/rife/.gitignore @@ -0,0 +1,2 @@ +* +!.gitignore diff --git a/animate/data/sdxl_embeddings/.gitignore b/animate/data/sdxl_embeddings/.gitignore new file mode 100644 index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d --- /dev/null +++ b/animate/data/sdxl_embeddings/.gitignore @@ -0,0 +1,2 @@ +* +!.gitignore diff --git a/animate/example.md b/animate/example.md new file mode 100644 index 0000000000000000000000000000000000000000..b37ca780cc8a8924a91f82f66f0e3ecb2e8b307a --- /dev/null +++ b/animate/example.md @@ -0,0 +1,144 @@ +### Example + +- region prompt(txt2img / no controlnet) +- region 0 ... 1girl, upper body etc +- region 1 ... ((car)), street, road,no human etc +- background ... town, outdoors etc +- ip adapter input for background / region 0 / region 1 +
+ +- apply different lora for each region. +- [abdiel](https://civitai.com/models/159943/abdiel-shin-megami-tensei-v-v) for region 0 +- [amanozoko](https://civitai.com/models/159933/amanozoko-shin-megami-tensei-v-v) for region 1 +- no lora for background + + +```json + # new lora_map format + "lora_map": { + # Specify lora as a path relative to /animatediff-cli/data + "share/Lora/zs_Abdiel.safetensors": { # setting for abdiel lora + "region" : ["0"], # target region. Multiple designations possible + "scale" : { + # "frame_no" : scale format + "0": 0.75 # lora scale. same as prompt_map format. For example, it is possible to set the lora to be used from the 30th frame. + } + }, + "share/Lora/zs_Amanazoko.safetensors": { # setting for amanozako lora + "region" : ["1"], # target region + "scale" : { + "0": 0.75 + } + } + }, +``` +- more example [here](https://github.com/s9roll7/animatediff-cli-prompt-travel/issues/147) +
+ + + +- img2img +- This can be improved using controlnet, but this sample does not use it. +- source / denoising_strength 0.7 / denoising_strength 0.85 + +
+
+ +- [A command to stylization with region has been added](https://github.com/s9roll7/animatediff-cli-prompt-travel#video-stylization-with-region). +- (You can also create json manually without using the stylize command.) +- region prompt +- Region division into person shapes +- source / img2img / txt2img + +
+ +- source / Region division into person shapes / inpaint + +
+
+ + + + +- [A command to stylization with mask has been added](https://github.com/s9roll7/animatediff-cli-prompt-travel#video-stylization-with-mask). +- more example [here](https://github.com/s9roll7/animatediff-cli-prompt-travel/issues/111) + + +
+ + +- [A command to automate video stylization has been added](https://github.com/s9roll7/animatediff-cli-prompt-travel#video-stylization). +- Original / First generation result / Second generation(for upscaling) result +- It took 4 minutes to generate the first one and about 5 minutes to generate the second one (on rtx 4090). +- more example [here](https://github.com/s9roll7/animatediff-cli-prompt-travel/issues/29) + + +
+ + +- controlnet_openpose + controlnet_softedge +- input frames for controlnet(0,16,32 frames) +
+ +- In the latest version, generation can now be controlled more precisely through prompts. +- sample 1 +```json + "prompt_fixed_ratio": 0.8, + "head_prompt": "1girl, wizard, circlet, earrings, jewelry, purple hair,", + "prompt_map": { + "0": "(standing,full_body),blue_sky, town", + "8": "(sitting,full_body),rain, town", + "16": "(standing,full_body),blue_sky, woods", + "24": "(upper_body), beach", + "32": "(upper_body, smile)", + "40": "(upper_body, angry)", + "48": "(upper_body, smile, from_above)", + "56": "(upper_body, angry, from_side)", + "64": "(upper_body, smile, from_below)", + "72": "(upper_body, angry, from_behind, looking at viewer)", + "80": "face,looking at viewer", + "88": "face,looking at viewer, closed_eyes", + "96": "face,looking at viewer, open eyes, open_mouth", + "104": "face,looking at viewer, closed_eyes, closed_mouth", + "112": "face,looking at viewer, open eyes,eyes, open_mouth, tongue, smile, laughing", + "120": "face,looking at viewer, eating, bowl,chopsticks,holding,food" + }, +``` + +
+ +- sample 2 +```json + "prompt_fixed_ratio": 1.0, + "head_prompt": "1girl, wizard, circlet, earrings, jewelry, purple hair,", + "prompt_map": { + "0": "", + "8": "((fire magic spell, fire background))", + "16": "((ice magic spell, ice background))", + "24": "((thunder magic spell, thunder background))", + "32": "((skull magic spell, skull background))", + "40": "((wind magic spell, wind background))", + "48": "((stone magic spell, stone background))", + "56": "((holy magic spell, holy background))", + "64": "((star magic spell, star background))", + "72": "((plant magic spell, plant background))", + "80": "((meteor magic spell, meteor background))" + }, +``` + +
+ diff --git a/animate/output/.gitignore b/animate/output/.gitignore new file mode 100644 index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d --- /dev/null +++ b/animate/output/.gitignore @@ -0,0 +1,2 @@ +* +!.gitignore diff --git a/animate/pyproject.toml b/animate/pyproject.toml new file mode 100644 index 0000000000000000000000000000000000000000..cb30c7d3d50411723ad2b3d7b302f8d9ccb8e4a5 --- /dev/null +++ b/animate/pyproject.toml @@ -0,0 +1,27 @@ +[build-system] +build-backend = "setuptools.build_meta" +requires = ["setuptools>=46.4.0", "wheel", "setuptools_scm[toml]>=6.2"] + +[tool.setuptools_scm] +write_to = "src/animatediff/_version.py" + +[tool.black] +line-length = 110 +target-version = ['py310'] +ignore = ['F841', 'F401', 'E501'] +preview = true + +[tool.ruff] +line-length = 110 +target-version = 'py310' +ignore = ['F841', 'F401', 'E501'] + +[tool.ruff.isort] +combine-as-imports = true +force-wrap-aliases = true +known-local-folder = ["src"] +known-first-party = ["animatediff"] + +[tool.pyright] +include = ['src/**'] +exclude = ['/usr/lib/**'] diff --git a/animate/refine/.gitignore b/animate/refine/.gitignore new file mode 100644 index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d --- /dev/null +++ b/animate/refine/.gitignore @@ -0,0 +1,2 @@ +* +!.gitignore diff --git a/animate/scripts/download/01-Motion-Modules.sh b/animate/scripts/download/01-Motion-Modules.sh new file mode 100644 index 0000000000000000000000000000000000000000..4b1404252806386bc59bdcd767213c6d6924ae02 --- /dev/null +++ b/animate/scripts/download/01-Motion-Modules.sh @@ -0,0 +1,11 @@ +#!/usr/bin/env bash + +echo "Attempting download of Motion Module models from Google Drive." +echo "If this fails, please download them manually from the links in the error messages/README." + +gdown 1RqkQuGPaCO5sGZ6V6KZ-jUWmsRu48Kdq -O models/motion-module/ || true +gdown 1ql0g_Ys4UCz2RnokYlBjyOYPbttbIpbu -O models/motion-module/ || true + +echo "Motion module download script complete." +echo "If you see errors above, please download the models manually from the links in the error messages/README." +exit 0 diff --git a/animate/scripts/download/02-All-SD-Models.sh b/animate/scripts/download/02-All-SD-Models.sh new file mode 100644 index 0000000000000000000000000000000000000000..7226b028ad85fc85ccb7c561a4aad09f3ecd8d9f --- /dev/null +++ b/animate/scripts/download/02-All-SD-Models.sh @@ -0,0 +1,39 @@ +#!/usr/bin/env bash +set -euo pipefail + +repo_dir=$(git rev-parse --show-toplevel) +if [[ ! -d "${repo_dir}" ]]; then + echo "Could not find the repo root. Checking for ./data/models/sd" + repo_dir="." +fi + +models_dir=$(realpath "${repo_dir}/data/models/sd") +if [[ ! -d "${models_dir}" ]]; then + echo "Could not find repo root or models directory." + echo "Either create ./data/models/sd or run this script from a checked-out git repo." + exit 1 +fi + +model_urls=( + https://civitai.com/api/download/models/78775 # ToonYou + https://civitai.com/api/download/models/72396 # Lyriel + https://civitai.com/api/download/models/71009 # RcnzCartoon + https://civitai.com/api/download/models/79068 # MajicMix + https://civitai.com/api/download/models/29460 # RealisticVision + https://civitai.com/api/download/models/97261 # Tusun (1/2) + https://civitai.com/api/download/models/50705 # Tusun (2/2) + https://civitai.com/api/download/models/90115 # FilmVelvia (1/2) + https://civitai.com/api/download/models/92475 # FilmVelvia (2/2) + https://civitai.com/api/download/models/102828 # GhibliBackground (1/2) + https://civitai.com/api/download/models/57618 # GhibliBackground (2/2) +) + +echo "Downloading model files to ${models_dir}..." + +# Create the models directory if it doesn't exist +mkdir -p "${models_dir}" + +# Download the models +for url in ${model_urls[@]}; do + curl -JLO --output-dir "${models_dir}" "${url}" || true +done diff --git a/animate/scripts/download/03-BaseSD.py b/animate/scripts/download/03-BaseSD.py new file mode 100644 index 0000000000000000000000000000000000000000..26c9fcd4b611c731c3b766e1a06b2e9cda0e5c9e --- /dev/null +++ b/animate/scripts/download/03-BaseSD.py @@ -0,0 +1,16 @@ +#!/usr/bin/env python3 +from diffusers.pipelines import StableDiffusionPipeline + +from animatediff import get_dir + +out_dir = get_dir("data/models/huggingface/stable-diffusion-v1-5") + +pipeline = StableDiffusionPipeline.from_pretrained( + "runwayml/stable-diffusion-v1-5", + use_safetensors=True, + kwargs=dict(safety_checker=None, requires_safety_checker=False), +) +pipeline.save_pretrained( + save_directory=str(out_dir), + safe_serialization=True, +) diff --git a/animate/scripts/download/11-ToonYou.sh b/animate/scripts/download/11-ToonYou.sh new file mode 100644 index 0000000000000000000000000000000000000000..43ad97fd438037cf54c6b0a8fc1f9a2fb711c263 --- /dev/null +++ b/animate/scripts/download/11-ToonYou.sh @@ -0,0 +1,2 @@ +#!/usr/bin/env bash +wget https://civitai.com/api/download/models/78775 -P models/DreamBooth_LoRA/ --content-disposition --no-check-certificate diff --git a/animate/scripts/download/12-Lyriel.sh b/animate/scripts/download/12-Lyriel.sh new file mode 100644 index 0000000000000000000000000000000000000000..8c5f53dc13835b2a72cd63cad6d82cf8ea6492af --- /dev/null +++ b/animate/scripts/download/12-Lyriel.sh @@ -0,0 +1,2 @@ +#!/usr/bin/env bash +wget https://civitai.com/api/download/models/72396 -P models/DreamBooth_LoRA/ --content-disposition --no-check-certificate diff --git a/animate/scripts/download/13-RcnzCartoon.sh b/animate/scripts/download/13-RcnzCartoon.sh new file mode 100644 index 0000000000000000000000000000000000000000..b0529dceda610b111f06fe3e2bc3cb0686fa6782 --- /dev/null +++ b/animate/scripts/download/13-RcnzCartoon.sh @@ -0,0 +1,2 @@ +#!/usr/bin/env bash +wget https://civitai.com/api/download/models/71009 -P models/DreamBooth_LoRA/ --content-disposition --no-check-certificate diff --git a/animate/scripts/download/14-MajicMix.sh b/animate/scripts/download/14-MajicMix.sh new file mode 100644 index 0000000000000000000000000000000000000000..794afc28243da7220896945558f5071837e0a120 --- /dev/null +++ b/animate/scripts/download/14-MajicMix.sh @@ -0,0 +1,2 @@ +#!/usr/bin/env bash +wget https://civitai.com/api/download/models/79068 -P models/DreamBooth_LoRA/ --content-disposition --no-check-certificate diff --git a/animate/scripts/download/15-RealisticVision.sh b/animate/scripts/download/15-RealisticVision.sh new file mode 100644 index 0000000000000000000000000000000000000000..da1729af6844e780958e8851146d74fa81d83e89 --- /dev/null +++ b/animate/scripts/download/15-RealisticVision.sh @@ -0,0 +1,2 @@ +#!/usr/bin/env bash +wget https://civitai.com/api/download/models/29460 -P models/DreamBooth_LoRA/ --content-disposition --no-check-certificate diff --git a/animate/scripts/download/16-Tusun.sh b/animate/scripts/download/16-Tusun.sh new file mode 100644 index 0000000000000000000000000000000000000000..3874a94b78d23d85fb2a26200d20274f962cc4db --- /dev/null +++ b/animate/scripts/download/16-Tusun.sh @@ -0,0 +1,3 @@ +#!/usr/bin/env bash +wget https://civitai.com/api/download/models/97261 -P models/DreamBooth_LoRA/ --content-disposition --no-check-certificate +wget https://civitai.com/api/download/models/50705 -P models/DreamBooth_LoRA/ --content-disposition --no-check-certificate diff --git a/animate/scripts/download/17-FilmVelvia.sh b/animate/scripts/download/17-FilmVelvia.sh new file mode 100644 index 0000000000000000000000000000000000000000..1bca1c6e6e67868d83d6718add275e82734f4dc0 --- /dev/null +++ b/animate/scripts/download/17-FilmVelvia.sh @@ -0,0 +1,3 @@ +#!/usr/bin/env bash +wget https://civitai.com/api/download/models/90115 -P models/DreamBooth_LoRA/ --content-disposition --no-check-certificate +wget https://civitai.com/api/download/models/92475 -P models/DreamBooth_LoRA/ --content-disposition --no-check-certificate diff --git a/animate/scripts/download/18-GhibliBackground.sh b/animate/scripts/download/18-GhibliBackground.sh new file mode 100644 index 0000000000000000000000000000000000000000..131d0aec1e4e6101bb32b62f0493e342b9ba1a35 --- /dev/null +++ b/animate/scripts/download/18-GhibliBackground.sh @@ -0,0 +1,3 @@ +#!/usr/bin/env bash +wget https://civitai.com/api/download/models/102828 -P models/DreamBooth_LoRA/ --content-disposition --no-check-certificate +wget https://civitai.com/api/download/models/57618 -P models/DreamBooth_LoRA/ --content-disposition --no-check-certificate diff --git a/animate/scripts/download/sd-models.aria2 b/animate/scripts/download/sd-models.aria2 new file mode 100644 index 0000000000000000000000000000000000000000..161e19245677a35cba990deb76fe8339ff9512b7 --- /dev/null +++ b/animate/scripts/download/sd-models.aria2 @@ -0,0 +1,22 @@ +https://civitai.com/api/download/models/78775 + out=models/sd/toonyou_beta3.safetensors +https://civitai.com/api/download/models/72396 + out=models/sd/lyriel_v16.safetensors +https://civitai.com/api/download/models/71009 + out=models/sd/rcnzCartoon3d_v10.safetensors +https://civitai.com/api/download/models/79068 + out=majicmixRealistic_v5Preview.safetensors +https://civitai.com/api/download/models/29460 + out=models/sd/realisticVisionV40_v20Novae.safetensors +https://civitai.com/api/download/models/97261 + out=models/sd/TUSUN.safetensors +https://civitai.com/api/download/models/50705 + out=models/sd/leosamsMoonfilm_reality20.safetensors +https://civitai.com/api/download/models/90115 + out=models/sd/FilmVelvia2.safetensors +https://civitai.com/api/download/models/92475 + out=models/sd/leosamsMoonfilm_filmGrain10.safetensors +https://civitai.com/api/download/models/102828 + out=models/sd/Pyramid\ lora_Ghibli_n3.safetensors +https://civitai.com/api/download/models/57618 + out=models/sd/CounterfeitV30_v30.safetensors diff --git a/animate/scripts/test_persistent.py b/animate/scripts/test_persistent.py new file mode 100644 index 0000000000000000000000000000000000000000..9b49d091934957ffba08e986e864fa407e9295dc --- /dev/null +++ b/animate/scripts/test_persistent.py @@ -0,0 +1,37 @@ +from rich import print + +from animatediff import get_dir +from animatediff.cli import generate, logger + +config_dir = get_dir("config") + +config_path = config_dir.joinpath("prompts/test.json") +width = 512 +height = 512 +length = 32 +context = 16 +stride = 4 + +logger.warn("Running first-round generation test, this should load the full model.\n\n") +out_dir = generate( + config_path=config_path, + width=width, + height=height, + length=length, + context=context, + stride=stride, +) +logger.warn(f"Generated animation to {out_dir}") + +logger.warn("\n\nRunning second-round generation test, this should reuse the already loaded model.\n\n") +out_dir = generate( + config_path=config_path, + width=width, + height=height, + length=length, + context=context, + stride=stride, +) +logger.warn(f"Generated animation to {out_dir}") + +logger.error("If the second round didn't talk about reloading the model, it worked! yay!") diff --git a/animate/setup.cfg b/animate/setup.cfg new file mode 100644 index 0000000000000000000000000000000000000000..2e0b99d0df696ed14c53598a4d03eeca193d2b55 --- /dev/null +++ b/animate/setup.cfg @@ -0,0 +1,91 @@ +[metadata] +name = animatediff +author = Andi Powers-Holmes +email = aholmes@omnom.net +maintainer = Andi Powers-Holmes +maintainer_email = aholmes@omnom.net +license_files = LICENSE.md + +[options] +python_requires = >=3.10 +packages = find: +package_dir = + =src +py_modules = + animatediff +include_package_data = True +install_requires = + accelerate + colorama >= 0.4.3, < 0.5.0 + cmake + diffusers + einops + gdown + ninja + numpy + omegaconf + pillow + pydantic >= 1.10.0, < 2.0.0 + rich >= 13.0.0, < 14.0.0 + safetensors + sentencepiece + shellingham >= 1.5.0, < 2.0.0 + torch + torchaudio + torchvision + transformers + typer + controlnet_aux + matplotlib + ffmpeg-python + mediapipe + xformers + onnxruntime-gpu + +[options.packages.find] +where = src + +[options.package_data] + * = *.txt, *.md + +[options.extras_require] +dev = + black >= 22.3.0 + ruff >= 0.0.234 + setuptools-scm >= 7.0.0 + pre-commit >= 3.3.0 + ipython +rife = + ffmpeg-python >= 0.2.0 +stylize = + ffmpeg-python >= 0.2.0 + onnxruntime-gpu + pandas +dwpose = + onnxruntime-gpu +stylize_mask = + ffmpeg-python >= 0.2.0 + pandas + segment-anything-hq == 0.3 + groundingdino-py == 0.4.0 + gitpython + rembg[gpu] + onnxruntime-gpu + +[options.entry_points] +console_scripts = + animatediff = animatediff.cli:cli + +[flake8] +max-line-length = 110 +ignore = + # these are annoying during development but should be enabled later + F401 # module imported but unused + F841 # local variable is assigned to but never used + # black automatically fixes this + E501 # line too long + # black breaks these two rules: + E203 # whitespace before : + W503 # line break before binary operator +extend-exclude = + .venv \ No newline at end of file diff --git a/animate/setup.py b/animate/setup.py new file mode 100644 index 0000000000000000000000000000000000000000..b908cbe55cb344569d32de1dfc10ca7323828dc5 --- /dev/null +++ b/animate/setup.py @@ -0,0 +1,3 @@ +import setuptools + +setuptools.setup() diff --git a/animate/src/animatediff/__init__.py b/animate/src/animatediff/__init__.py new file mode 100644 index 0000000000000000000000000000000000000000..042e97a682db80c56e479d108c284c496d0bf6af --- /dev/null +++ b/animate/src/animatediff/__init__.py @@ -0,0 +1,67 @@ +try: + from ._version import ( + version as __version__, + version_tuple, + ) +except ImportError: + __version__ = "unknown (no version information available)" + version_tuple = (0, 0, "unknown", "noinfo") + +from functools import lru_cache +from os import getenv +from pathlib import Path +from warnings import filterwarnings + +from rich.console import Console +from tqdm import TqdmExperimentalWarning + +PACKAGE = __package__.replace("_", "-") +PACKAGE_ROOT = Path(__file__).parent.parent + +HF_HOME = Path(getenv("HF_HOME", Path.home() / ".cache" / "huggingface")) +HF_HUB_CACHE = Path(getenv("HUGGINGFACE_HUB_CACHE", HF_HOME.joinpath("hub"))) + +HF_LIB_NAME = "animatediff-cli" +HF_LIB_VER = __version__ +HF_MODULE_REPO = "neggles/animatediff-modules" + +console = Console(highlight=True) +err_console = Console(stderr=True) + +# shhh torch, don't worry about it it's fine +filterwarnings("ignore", category=UserWarning, message="TypedStorage is deprecated") +# you too tqdm +filterwarnings("ignore", category=TqdmExperimentalWarning) + + +@lru_cache(maxsize=4) +def get_dir(dirname: str = "data") -> Path: + if PACKAGE_ROOT.name == "src": + # we're installed in editable mode from within the repo + dirpath = PACKAGE_ROOT.parent.joinpath(dirname) + else: + # we're installed normally, so we just use the current working directory + dirpath = Path.cwd().joinpath(dirname) + dirpath.mkdir(parents=True, exist_ok=True) + return dirpath.absolute() + + +__all__ = [ + "__version__", + "version_tuple", + "PACKAGE", + "PACKAGE_ROOT", + "HF_HOME", + "HF_HUB_CACHE", + "console", + "err_console", + "get_dir", + "models", + "pipelines", + "rife", + "utils", + "cli", + "generate", + "schedulers", + "settings", +] diff --git a/animate/src/animatediff/__main__.py b/animate/src/animatediff/__main__.py new file mode 100644 index 0000000000000000000000000000000000000000..bf4d0abdb53959b6f3b62562c2ecf0a4dbbb3d45 --- /dev/null +++ b/animate/src/animatediff/__main__.py @@ -0,0 +1,4 @@ +from animatediff.cli import cli + +if __name__ == "__main__": + cli() diff --git a/animate/src/animatediff/cli.py b/animate/src/animatediff/cli.py new file mode 100644 index 0000000000000000000000000000000000000000..eaf9ce9f9a7a2882a09412bcad73d88ede5a8f1c --- /dev/null +++ b/animate/src/animatediff/cli.py @@ -0,0 +1,1186 @@ +import glob +import logging +import os.path +from datetime import datetime +from pathlib import Path +from typing import Annotated, Optional + +if False: + if 'PYTORCH_CUDA_ALLOC_CONF' in os.environ: + os.environ['PYTORCH_CUDA_ALLOC_CONF'] = ",backend:cudaMallocAsync" + else: + os.environ['PYTORCH_CUDA_ALLOC_CONF'] = "backend:cudaMallocAsync" + + #"garbage_collection_threshold:0.6" + # max_split_size_mb:1024" + # "backend:cudaMallocAsync" + # roundup_power2_divisions:4 + print(f"{os.environ['PYTORCH_CUDA_ALLOC_CONF']=}") + +if False: + os.environ['PYTORCH_NO_CUDA_MEMORY_CACHING']="1" + + +import torch +import typer +from diffusers import DiffusionPipeline +from diffusers.utils.logging import \ + set_verbosity_error as set_diffusers_verbosity_error +from rich.logging import RichHandler + +from animatediff import __version__, console, get_dir +from animatediff.generate import (controlnet_preprocess, create_pipeline, + create_us_pipeline, img2img_preprocess, + ip_adapter_preprocess, + load_controlnet_models, prompt_preprocess, + region_preprocess, run_inference, + run_upscale, save_output, + unload_controlnet_models, + wild_card_conversion) +from animatediff.pipelines import AnimationPipeline, load_text_embeddings +from animatediff.settings import (CKPT_EXTENSIONS, InferenceConfig, + ModelConfig, get_infer_config, + get_model_config) +from animatediff.utils.civitai2config import generate_config_from_civitai_info +from animatediff.utils.model import (checkpoint_to_pipeline, + fix_checkpoint_if_needed, get_base_model) +from animatediff.utils.pipeline import get_context_params, send_to_device +from animatediff.utils.util import (extract_frames, is_sdxl_checkpoint, + is_v2_motion_module, path_from_cwd, + save_frames, save_imgs, save_video, + set_tensor_interpolation_method, show_gpu) +from animatediff.utils.wild_card import replace_wild_card + +cli: typer.Typer = typer.Typer( + context_settings=dict(help_option_names=["-h", "--help"]), + rich_markup_mode="rich", + no_args_is_help=True, + pretty_exceptions_show_locals=False, +) +data_dir = get_dir("data") +checkpoint_dir = data_dir.joinpath("models/sd") +pipeline_dir = data_dir.joinpath("models/huggingface") + + +try: + import google.colab + IN_COLAB = True +except: + IN_COLAB = False + +if IN_COLAB: + import sys + logging.basicConfig( + level=logging.INFO, + stream=sys.stdout, + format="%(message)s", + datefmt="%H:%M:%S", + force=True, + ) +else: + logging.basicConfig( + level=logging.INFO, + format="%(message)s", + handlers=[ + RichHandler(console=console, rich_tracebacks=True), + ], + datefmt="%H:%M:%S", + force=True, + ) + +logger = logging.getLogger(__name__) + + +from importlib.metadata import version as meta_version + +from packaging import version + +diffuser_ver = meta_version('diffusers') + +logger.info(f"{diffuser_ver=}") + +if version.parse(diffuser_ver) < version.parse('0.23.0'): + logger.error(f"The version of diffusers is out of date") + logger.error(f"python -m pip install diffusers==0.23.0") + raise ImportError("Please update diffusers to 0.23.0") + +try: + from animatediff.rife import app as rife_app + + cli.add_typer(rife_app, name="rife") +except ImportError: + logger.debug("RIFE not available, skipping...", exc_info=True) + rife_app = None + + +from animatediff.stylize import stylize + +cli.add_typer(stylize, name="stylize") + + + + +# mildly cursed globals to allow for reuse of the pipeline if we're being called as a module +g_pipeline: Optional[DiffusionPipeline] = None +last_model_path: Optional[Path] = None + + +def version_callback(value: bool): + if value: + console.print(f"AnimateDiff v{__version__}") + raise typer.Exit() + +def get_random(): + import sys + + import numpy as np + return int(np.random.randint(sys.maxsize, dtype=np.int64)) + + +@cli.command() +def generate( + config_path: Annotated[ + Path, + typer.Option( + "--config-path", + "-c", + path_type=Path, + exists=True, + readable=True, + dir_okay=False, + help="Path to a prompt configuration JSON file", + ), + ] = Path("config/prompts/01-ToonYou.json"), + width: Annotated[ + int, + typer.Option( + "--width", + "-W", + min=64, + max=3840, + help="Width of generated frames", + rich_help_panel="Generation", + ), + ] = 512, + height: Annotated[ + int, + typer.Option( + "--height", + "-H", + min=64, + max=2160, + help="Height of generated frames", + rich_help_panel="Generation", + ), + ] = 512, + length: Annotated[ + int, + typer.Option( + "--length", + "-L", + min=1, + max=9999, + help="Number of frames to generate", + rich_help_panel="Generation", + ), + ] = 16, + context: Annotated[ + Optional[int], + typer.Option( + "--context", + "-C", + min=1, + max=32, + help="Number of frames to condition on (default: 16)", + show_default=False, + rich_help_panel="Generation", + ), + ] = 16, + overlap: Annotated[ + Optional[int], + typer.Option( + "--overlap", + "-O", + min=0, + max=12, + help="Number of frames to overlap in context (default: context//4)", + show_default=False, + rich_help_panel="Generation", + ), + ] = None, + stride: Annotated[ + Optional[int], + typer.Option( + "--stride", + "-S", + min=0, + max=8, + help="Max motion stride as a power of 2 (default: 0)", + show_default=False, + rich_help_panel="Generation", + ), + ] = None, + repeats: Annotated[ + int, + typer.Option( + "--repeats", + "-r", + min=1, + max=99, + help="Number of times to repeat the prompt (default: 1)", + show_default=False, + rich_help_panel="Generation", + ), + ] = 1, + device: Annotated[ + str, + typer.Option( + "--device", "-d", help="Device to run on (cpu, cuda, cuda:id)", rich_help_panel="Advanced" + ), + ] = "cuda", + use_xformers: Annotated[ + bool, + typer.Option( + "--xformers", + "-x", + is_flag=True, + help="Use XFormers instead of SDP Attention", + rich_help_panel="Advanced", + ), + ] = False, + force_half_vae: Annotated[ + bool, + typer.Option( + "--half-vae", + is_flag=True, + help="Force VAE to use fp16 (not recommended)", + rich_help_panel="Advanced", + ), + ] = False, + out_dir: Annotated[ + Path, + typer.Option( + "--out-dir", + "-o", + path_type=Path, + file_okay=False, + help="Directory for output folders (frames, gifs, etc)", + rich_help_panel="Output", + ), + ] = Path("output/"), + no_frames: Annotated[ + bool, + typer.Option( + "--no-frames", + "-N", + is_flag=True, + help="Don't save frames, only the animation", + rich_help_panel="Output", + ), + ] = False, + save_merged: Annotated[ + bool, + typer.Option( + "--save-merged", + "-m", + is_flag=True, + help="Save a merged animation of all prompts", + rich_help_panel="Output", + ), + ] = False, + version: Annotated[ + Optional[bool], + typer.Option( + "--version", + "-v", + callback=version_callback, + is_eager=True, + is_flag=True, + help="Show version", + ), + ] = None, +): + """ + Do the thing. Make the animation happen. Waow. + """ + + # be quiet, diffusers. we care not for your safety checker + set_diffusers_verbosity_error() + + #torch.set_flush_denormal(True) + + config_path = config_path.absolute() + logger.info(f"Using generation config: {path_from_cwd(config_path)}") + model_config: ModelConfig = get_model_config(config_path) + + is_sdxl = is_sdxl_checkpoint(data_dir.joinpath(model_config.path)) + + if is_sdxl: + is_v2 = False + else: + is_v2 = is_v2_motion_module(data_dir.joinpath(model_config.motion_module)) + + infer_config: InferenceConfig = get_infer_config(is_v2, is_sdxl) + + set_tensor_interpolation_method( model_config.tensor_interpolation_slerp ) + + # set sane defaults for context, overlap, and stride if not supplied + context, overlap, stride = get_context_params(length, context, overlap, stride) + + if (not is_v2) and (not is_sdxl) and (context > 24): + logger.warning( "For motion module v1, the maximum value of context is 24. Set to 24" ) + context = 24 + + # turn the device string into a torch.device + device: torch.device = torch.device(device) + + model_name_or_path = Path("chaowenguo/stable-diffusion-v1-5") if not is_sdxl else Path("stabilityai/stable-diffusion-xl-base-1.0") + + # Get the base model if we don't have it already + logger.info(f"Using base model: {model_name_or_path}") + base_model_path: Path = get_base_model(model_name_or_path, local_dir=get_dir("data/models/huggingface"), is_sdxl=is_sdxl) + + # get a timestamp for the output directory + time_str = datetime.now().strftime("%Y-%m-%dT%H-%M-%S") + # make the output directory + save_dir = out_dir.joinpath(f"{time_str}-{model_config.save_name}") + save_dir.mkdir(parents=True, exist_ok=True) + logger.info(f"Will save outputs to ./{path_from_cwd(save_dir)}") + + controlnet_image_map, controlnet_type_map, controlnet_ref_map, controlnet_no_shrink = controlnet_preprocess(model_config.controlnet_map, width, height, length, save_dir, device, is_sdxl) + img2img_map = img2img_preprocess(model_config.img2img_map, width, height, length, save_dir) + + # beware the pipeline + global g_pipeline + global last_model_path + pipeline_already_loaded = False + if g_pipeline is None or last_model_path != model_config.path.resolve(): + g_pipeline = create_pipeline( + base_model=base_model_path, + model_config=model_config, + infer_config=infer_config, + use_xformers=use_xformers, + video_length=length, + is_sdxl=is_sdxl + ) + last_model_path = model_config.path.resolve() + else: + logger.info("Pipeline already loaded, skipping initialization") + # reload TIs; create_pipeline does this for us, but they may have changed + # since load time if we're being called from another package + #load_text_embeddings(g_pipeline, is_sdxl=is_sdxl) + pipeline_already_loaded = True + + load_controlnet_models(pipe=g_pipeline, model_config=model_config, is_sdxl=is_sdxl) + +# if g_pipeline.device == device: + if pipeline_already_loaded: + logger.info("Pipeline already on the correct device, skipping device transfer") + else: + + g_pipeline = send_to_device( + g_pipeline, device, freeze=True, force_half=force_half_vae, compile=model_config.compile, is_sdxl=is_sdxl + ) + + torch.cuda.empty_cache() + + apply_lcm_lora = False + if model_config.lcm_map: + if "enable" in model_config.lcm_map: + apply_lcm_lora = model_config.lcm_map["enable"] + + # save raw config to output directory + save_config_path = save_dir.joinpath("raw_prompt.json") + save_config_path.write_text(model_config.json(indent=4), encoding="utf-8") + + # fix seed + for i, s in enumerate(model_config.seed): + if s == -1: + model_config.seed[i] = get_random() + + # wildcard conversion + wild_card_conversion(model_config) + + is_init_img_exist = img2img_map != None + region_condi_list, region_list, ip_adapter_config_map, region2index = region_preprocess(model_config, width, height, length, save_dir, is_init_img_exist, is_sdxl) + + if controlnet_type_map: + for c in controlnet_type_map: + tmp_r = [region2index[r] for r in controlnet_type_map[c]["control_region_list"]] + controlnet_type_map[c]["control_region_list"] = [r for r in tmp_r if r != -1] + logger.info(f"{c=} / {controlnet_type_map[c]['control_region_list']}") + + # save config to output directory + logger.info("Saving prompt config to output directory") + save_config_path = save_dir.joinpath("prompt.json") + save_config_path.write_text(model_config.json(indent=4), encoding="utf-8") + + num_negatives = len(model_config.n_prompt) + num_seeds = len(model_config.seed) + gen_total = repeats # total number of generations + + logger.info("Initialization complete!") + logger.info(f"Generating {gen_total} animations") + outputs = [] + + gen_num = 0 # global generation index + + # repeat the prompts if we're doing multiple runs + for _ in range(repeats): + if model_config.prompt_map: + # get the index of the prompt, negative, and seed + idx = gen_num + logger.info(f"Running generation {gen_num + 1} of {gen_total}") + + # allow for reusing the same negative prompt(s) and seed(s) for multiple prompts + n_prompt = model_config.n_prompt[idx % num_negatives] + seed = model_config.seed[idx % num_seeds] + + logger.info(f"Generation seed: {seed}") + + + output = run_inference( + pipeline=g_pipeline, + n_prompt=n_prompt, + seed=seed, + steps=model_config.steps, + guidance_scale=model_config.guidance_scale, + unet_batch_size=model_config.unet_batch_size, + width=width, + height=height, + duration=length, + idx=gen_num, + out_dir=save_dir, + context_schedule=model_config.context_schedule, + context_frames=context, + context_overlap=overlap, + context_stride=stride, + clip_skip=model_config.clip_skip, + controlnet_map=model_config.controlnet_map, + controlnet_image_map=controlnet_image_map, + controlnet_type_map=controlnet_type_map, + controlnet_ref_map=controlnet_ref_map, + controlnet_no_shrink=controlnet_no_shrink, + no_frames=no_frames, + img2img_map=img2img_map, + ip_adapter_config_map=ip_adapter_config_map, + region_list=region_list, + region_condi_list=region_condi_list, + output_map = model_config.output, + is_single_prompt_mode=model_config.is_single_prompt_mode, + is_sdxl=is_sdxl, + apply_lcm_lora=apply_lcm_lora, + gradual_latent_map=model_config.gradual_latent_hires_fix_map + ) + outputs.append(output) + torch.cuda.empty_cache() + + # increment the generation number + gen_num += 1 + + unload_controlnet_models(pipe=g_pipeline) + + + logger.info("Generation complete!") + if save_merged: + logger.info("Output merged output video...") + merged_output = torch.concat(outputs, dim=0) + save_video(merged_output, save_dir.joinpath("final.gif")) + + logger.info("Done, exiting...") + cli.info + + return save_dir + +@cli.command() +def tile_upscale( + frames_dir: Annotated[ + Path, + typer.Argument(path_type=Path, file_okay=False, exists=True, help="Path to source frames directory"), + ] = ..., + model_name_or_path: Annotated[ + Path, + typer.Option( + ..., + "--model-path", + "-m", + path_type=Path, + help="Base model to use (path or HF repo ID). You probably don't need to change this.", + ), + ] = Path("chaowenguo/stable-diffusion-v1-5"), + config_path: Annotated[ + Path, + typer.Option( + "--config-path", + "-c", + path_type=Path, + exists=True, + readable=True, + dir_okay=False, + help="Path to a prompt configuration JSON file. default is frames_dir/../prompt.json", + ), + ] = None, + width: Annotated[ + int, + typer.Option( + "--width", + "-W", + min=-1, + max=3840, + help="Width of generated frames", + rich_help_panel="Generation", + ), + ] = -1, + height: Annotated[ + int, + typer.Option( + "--height", + "-H", + min=-1, + max=2160, + help="Height of generated frames", + rich_help_panel="Generation", + ), + ] = -1, + device: Annotated[ + str, + typer.Option( + "--device", "-d", help="Device to run on (cpu, cuda, cuda:id)", rich_help_panel="Advanced" + ), + ] = "cuda", + use_xformers: Annotated[ + bool, + typer.Option( + "--xformers", + "-x", + is_flag=True, + help="Use XFormers instead of SDP Attention", + rich_help_panel="Advanced", + ), + ] = False, + force_half_vae: Annotated[ + bool, + typer.Option( + "--half-vae", + is_flag=True, + help="Force VAE to use fp16 (not recommended)", + rich_help_panel="Advanced", + ), + ] = False, + out_dir: Annotated[ + Path, + typer.Option( + "--out-dir", + "-o", + path_type=Path, + file_okay=False, + help="Directory for output folders (frames, gifs, etc)", + rich_help_panel="Output", + ), + ] = Path("upscaled/"), + no_frames: Annotated[ + bool, + typer.Option( + "--no-frames", + "-N", + is_flag=True, + help="Don't save frames, only the animation", + rich_help_panel="Output", + ), + ] = False, +): + """Upscale frames using controlnet tile""" + # be quiet, diffusers. we care not for your safety checker + set_diffusers_verbosity_error() + + if width < 0 and height < 0: + raise ValueError(f"invalid width,height: {width},{height} \n At least one of them must be specified.") + + if not config_path: + tmp = frames_dir.parent.joinpath("prompt.json") + if tmp.is_file(): + config_path = tmp + + config_path = config_path.absolute() + logger.info(f"Using generation config: {path_from_cwd(config_path)}") + model_config: ModelConfig = get_model_config(config_path) + + is_sdxl = is_sdxl_checkpoint(data_dir.joinpath(model_config.path)) + if is_sdxl: + raise ValueError("Currently SDXL model is not available for this command.") + + infer_config: InferenceConfig = get_infer_config(is_v2_motion_module(data_dir.joinpath(model_config.motion_module)), is_sdxl) + frames_dir = frames_dir.absolute() + + set_tensor_interpolation_method( model_config.tensor_interpolation_slerp ) + + # turn the device string into a torch.device + device: torch.device = torch.device(device) + + # get a timestamp for the output directory + time_str = datetime.now().strftime("%Y-%m-%dT%H-%M-%S") + # make the output directory + save_dir = out_dir.joinpath(f"{time_str}-{model_config.save_name}") + save_dir.mkdir(parents=True, exist_ok=True) + logger.info(f"Will save outputs to ./{path_from_cwd(save_dir)}") + + + if "controlnet_tile" not in model_config.upscale_config: + model_config.upscale_config["controlnet_tile"] = { + "enable": True, + "controlnet_conditioning_scale": 1.0, + "guess_mode": False, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + } + + use_controlnet_ref = False + use_controlnet_tile = False + use_controlnet_line_anime = False + use_controlnet_ip2p = False + + if model_config.upscale_config: + use_controlnet_ref = model_config.upscale_config["controlnet_ref"]["enable"] if "controlnet_ref" in model_config.upscale_config else False + use_controlnet_tile = model_config.upscale_config["controlnet_tile"]["enable"] if "controlnet_tile" in model_config.upscale_config else False + use_controlnet_line_anime = model_config.upscale_config["controlnet_line_anime"]["enable"] if "controlnet_line_anime" in model_config.upscale_config else False + use_controlnet_ip2p = model_config.upscale_config["controlnet_ip2p"]["enable"] if "controlnet_ip2p" in model_config.upscale_config else False + + if use_controlnet_tile == False: + if use_controlnet_line_anime==False: + if use_controlnet_ip2p == False: + raise ValueError(f"At least one of them should be enabled. {use_controlnet_tile=}, {use_controlnet_line_anime=}, {use_controlnet_ip2p=}") + + # beware the pipeline + us_pipeline = create_us_pipeline( + model_config=model_config, + infer_config=infer_config, + use_xformers=use_xformers, + use_controlnet_ref=use_controlnet_ref, + use_controlnet_tile=use_controlnet_tile, + use_controlnet_line_anime=use_controlnet_line_anime, + use_controlnet_ip2p=use_controlnet_ip2p, + ) + + + if us_pipeline.device == device: + logger.info("Pipeline already on the correct device, skipping device transfer") + else: + us_pipeline = send_to_device( + us_pipeline, device, freeze=True, force_half=force_half_vae, compile=model_config.compile + ) + + + model_config.result = { "original_frames": str(frames_dir) } + + + # save config to output directory + logger.info("Saving prompt config to output directory") + save_config_path = save_dir.joinpath("prompt.json") + save_config_path.write_text(model_config.json(indent=4), encoding="utf-8") + + num_prompts = 1 + num_negatives = len(model_config.n_prompt) + num_seeds = len(model_config.seed) + + logger.info("Initialization complete!") + + gen_num = 0 # global generation index + + org_images = sorted(glob.glob( os.path.join(frames_dir, "[0-9]*.png"), recursive=False)) + length = len(org_images) + + if model_config.prompt_map: + # get the index of the prompt, negative, and seed + idx = gen_num % num_prompts + logger.info(f"Running generation {gen_num + 1} of {1} (prompt {idx + 1})") + + # allow for reusing the same negative prompt(s) and seed(s) for multiple prompts + n_prompt = model_config.n_prompt[idx % num_negatives] + seed = seed = model_config.seed[idx % num_seeds] + + if seed == -1: + seed = get_random() + logger.info(f"Generation seed: {seed}") + + prompt_map = {} + for k in model_config.prompt_map.keys(): + if int(k) < length: + pr = model_config.prompt_map[k] + if model_config.head_prompt: + pr = model_config.head_prompt + "," + pr + if model_config.tail_prompt: + pr = pr + "," + model_config.tail_prompt + + prompt_map[int(k)]=pr + + if model_config.upscale_config: + + upscaled_output = run_upscale( + org_imgs=org_images, + pipeline=us_pipeline, + prompt_map=prompt_map, + n_prompt=n_prompt, + seed=seed, + steps=model_config.steps, + guidance_scale=model_config.guidance_scale, + clip_skip=model_config.clip_skip, + us_width=width, + us_height=height, + idx=gen_num, + out_dir=save_dir, + upscale_config=model_config.upscale_config, + use_controlnet_ref=use_controlnet_ref, + use_controlnet_tile=use_controlnet_tile, + use_controlnet_line_anime=use_controlnet_line_anime, + use_controlnet_ip2p=use_controlnet_ip2p, + no_frames = no_frames, + output_map = model_config.output, + ) + torch.cuda.empty_cache() + + # increment the generation number + gen_num += 1 + + logger.info("Generation complete!") + + logger.info("Done, exiting...") + cli.info + + return save_dir + +@cli.command() +def civitai2config( + lora_dir: Annotated[ + Path, + typer.Argument(path_type=Path, file_okay=False, exists=True, help="Path to loras directory"), + ] = ..., + config_org: Annotated[ + Path, + typer.Option( + "--config-org", + "-c", + path_type=Path, + dir_okay=False, + exists=True, + help="Path to original config file", + ), + ] = Path("config/prompts/prompt_travel.json"), + out_dir: Annotated[ + Optional[Path], + typer.Option( + "--out-dir", + "-o", + path_type=Path, + file_okay=False, + help="Target directory for generated configs", + ), + ] = Path("config/prompts/converted/"), + lora_weight: Annotated[ + float, + typer.Option( + "--lora_weight", + "-l", + min=0.0, + max=3.0, + help="Lora weight", + ), + ] = 0.75, +): + """Generate config file from *.civitai.info""" + + out_dir.mkdir(parents=True, exist_ok=True) + + logger.info(f"Generate config files from: {lora_dir}") + generate_config_from_civitai_info(lora_dir,config_org,out_dir, lora_weight) + logger.info(f"saved at: {out_dir.absolute()}") + + +@cli.command() +def convert( + checkpoint: Annotated[ + Path, + typer.Option( + "--checkpoint", + "-i", + path_type=Path, + dir_okay=False, + exists=True, + help="Path to a model checkpoint file", + ), + ] = ..., + out_dir: Annotated[ + Optional[Path], + typer.Option( + "--out-dir", + "-o", + path_type=Path, + file_okay=False, + help="Target directory for converted model", + ), + ] = None, +): + """Convert a StableDiffusion checkpoint into a Diffusers pipeline""" + logger.info(f"Converting checkpoint: {checkpoint}") + _, pipeline_dir = checkpoint_to_pipeline(checkpoint, target_dir=out_dir) + logger.info(f"Converted to HuggingFace pipeline at {pipeline_dir}") + + +@cli.command() +def fix_checkpoint( + checkpoint: Annotated[ + Path, + typer.Argument(path_type=Path, dir_okay=False, exists=True, help="Path to a model checkpoint file"), + ] = ..., + debug: Annotated[ + bool, + typer.Option( + "--debug", + "-d", + is_flag=True, + rich_help_panel="Debug", + ), + ] = False, +): + """Fix checkpoint with error "AttributeError: 'Attention' object has no attribute 'to_to_k'" on loading""" + set_diffusers_verbosity_error() + + logger.info(f"Converting checkpoint: {checkpoint}") + fix_checkpoint_if_needed(checkpoint, debug) + + + +@cli.command() +def merge( + checkpoint: Annotated[ + Path, + typer.Option( + "--checkpoint", + "-i", + path_type=Path, + dir_okay=False, + exists=True, + help="Path to a model checkpoint file", + ), + ] = ..., + out_dir: Annotated[ + Optional[Path], + typer.Option( + "--out-dir", + "-o", + path_type=Path, + file_okay=False, + help="Target directory for converted model", + ), + ] = None, +): + """Convert a StableDiffusion checkpoint into an AnimationPipeline""" + raise NotImplementedError("Sorry, haven't implemented this yet!") + + # if we have a checkpoint, convert it to HF automagically + if checkpoint.is_file() and checkpoint.suffix in CKPT_EXTENSIONS: + logger.info(f"Loading model from checkpoint: {checkpoint}") + # check if we've already converted this model + model_dir = pipeline_dir.joinpath(checkpoint.stem) + if model_dir.joinpath("model_index.json").exists(): + # we have, so just use that + logger.info("Found converted model in {model_dir}, will not convert") + logger.info("Delete the output directory to re-run conversion.") + else: + # we haven't, so convert it + logger.info("Converting checkpoint to HuggingFace pipeline...") + g_pipeline, model_dir = checkpoint_to_pipeline(checkpoint) + logger.info("Done!") + + + +@cli.command(no_args_is_help=True) +def refine( + frames_dir: Annotated[ + Path, + typer.Argument(path_type=Path, file_okay=False, exists=True, help="Path to source frames directory"), + ] = ..., + config_path: Annotated[ + Path, + typer.Option( + "--config-path", + "-c", + path_type=Path, + exists=True, + readable=True, + dir_okay=False, + help="Path to a prompt configuration JSON file. default is frames_dir/../prompt.json", + ), + ] = None, + interpolation_multiplier: Annotated[ + int, + typer.Option( + "--interpolation-multiplier", + "-M", + min=1, + max=10, + help="Interpolate with RIFE before generation. (I'll leave it as is, but I think interpolation after generation is sufficient).", + rich_help_panel="Generation", + ), + ] = 1, + tile_conditioning_scale: Annotated[ + float, + typer.Option( + "--tile", + "-t", + min= 0, + max= 1.0, + help="controlnet_tile conditioning scale", + rich_help_panel="Generation", + ), + ] = 0.75, + width: Annotated[ + int, + typer.Option( + "--width", + "-W", + min=-1, + max=3840, + help="Width of generated frames", + rich_help_panel="Generation", + ), + ] = -1, + height: Annotated[ + int, + typer.Option( + "--height", + "-H", + min=-1, + max=2160, + help="Height of generated frames", + rich_help_panel="Generation", + ), + ] = -1, + length: Annotated[ + int, + typer.Option( + "--length", + "-L", + min=-1, + max=9999, + help="Number of frames to generate. -1 means using all frames in frames_dir.", + rich_help_panel="Generation", + ), + ] = -1, + context: Annotated[ + Optional[int], + typer.Option( + "--context", + "-C", + min=1, + max=32, + help="Number of frames to condition on (default: 16)", + show_default=False, + rich_help_panel="Generation", + ), + ] = 16, + overlap: Annotated[ + Optional[int], + typer.Option( + "--overlap", + "-O", + min=1, + max=12, + help="Number of frames to overlap in context (default: context//4)", + show_default=False, + rich_help_panel="Generation", + ), + ] = None, + stride: Annotated[ + Optional[int], + typer.Option( + "--stride", + "-S", + min=0, + max=8, + help="Max motion stride as a power of 2 (default: 0)", + show_default=False, + rich_help_panel="Generation", + ), + ] = None, + repeats: Annotated[ + int, + typer.Option( + "--repeats", + "-r", + min=1, + max=99, + help="Number of times to repeat the refine (default: 1)", + show_default=False, + rich_help_panel="Generation", + ), + ] = 1, + device: Annotated[ + str, + typer.Option( + "--device", "-d", help="Device to run on (cpu, cuda, cuda:id)", rich_help_panel="Advanced" + ), + ] = "cuda", + use_xformers: Annotated[ + bool, + typer.Option( + "--xformers", + "-x", + is_flag=True, + help="Use XFormers instead of SDP Attention", + rich_help_panel="Advanced", + ), + ] = False, + force_half_vae: Annotated[ + bool, + typer.Option( + "--half-vae", + is_flag=True, + help="Force VAE to use fp16 (not recommended)", + rich_help_panel="Advanced", + ), + ] = False, + out_dir: Annotated[ + Path, + typer.Option( + "--out-dir", + "-o", + path_type=Path, + file_okay=False, + help="Directory for output folders (frames, gifs, etc)", + rich_help_panel="Output", + ), + ] = Path("refine/"), +): + """Create upscaled or improved video using pre-generated frames""" + import shutil + + from PIL import Image + + from animatediff.rife.rife import rife_interpolate + + if not config_path: + tmp = frames_dir.parent.joinpath("prompt.json") + if tmp.is_file(): + config_path = tmp + else: + raise ValueError(f"config_path invalid.") + + org_frames = sorted(glob.glob( os.path.join(frames_dir, "[0-9]*.png"), recursive=False)) + W,H = Image.open(org_frames[0]).size + + if width == -1 and height == -1: + width = W + height = H + elif width == -1: + width = int(height * W / H) //8 * 8 + elif height == -1: + height = int(width * H / W) //8 * 8 + else: + pass + + if length == -1: + length = len(org_frames) + else: + length = min(length, len(org_frames)) + + config_path = config_path.absolute() + logger.info(f"Using generation config: {path_from_cwd(config_path)}") + model_config: ModelConfig = get_model_config(config_path) + + # get a timestamp for the output directory + time_str = datetime.now().strftime("%Y-%m-%dT%H-%M-%S") + # make the output directory + save_dir = out_dir.joinpath(f"{time_str}-{model_config.save_name}") + save_dir.mkdir(parents=True, exist_ok=True) + logger.info(f"Will save outputs to ./{path_from_cwd(save_dir)}") + + seeds = [get_random() for i in range(repeats)] + + rife_img_dir = None + + for repeat_count in range(repeats): + + if interpolation_multiplier > 1: + rife_img_dir = save_dir.joinpath(f"{repeat_count:02d}_rife_frame") + rife_img_dir.mkdir(parents=True, exist_ok=True) + + rife_interpolate(frames_dir, rife_img_dir, interpolation_multiplier) + length *= interpolation_multiplier + + if model_config.output: + model_config.output["fps"] *= interpolation_multiplier + if model_config.prompt_map: + model_config.prompt_map = { str(int(i)*interpolation_multiplier): model_config.prompt_map[i] for i in model_config.prompt_map } + + frames_dir = rife_img_dir + + + controlnet_img_dir = save_dir.joinpath(f"{repeat_count:02d}_controlnet_image") + + for c in ["controlnet_canny","controlnet_depth","controlnet_inpaint","controlnet_ip2p","controlnet_lineart","controlnet_lineart_anime","controlnet_mlsd","controlnet_normalbae","controlnet_openpose","controlnet_scribble","controlnet_seg","controlnet_shuffle","controlnet_softedge","controlnet_tile"]: + c_dir = controlnet_img_dir.joinpath(c) + c_dir.mkdir(parents=True, exist_ok=True) + + shutil.copytree(frames_dir, controlnet_img_dir.joinpath("controlnet_tile"), dirs_exist_ok=True) + + model_config.controlnet_map["input_image_dir"] = os.path.relpath(controlnet_img_dir.absolute(), data_dir) + model_config.controlnet_map["is_loop"] = False + + if "controlnet_tile" in model_config.controlnet_map: + model_config.controlnet_map["controlnet_tile"]["enable"] = True + model_config.controlnet_map["controlnet_tile"]["control_scale_list"] = [] + model_config.controlnet_map["controlnet_tile"]["controlnet_conditioning_scale"] = tile_conditioning_scale + + else: + model_config.controlnet_map["controlnet_tile"] = { + "enable": True, + "use_preprocessor":True, + "guess_mode":False, + "controlnet_conditioning_scale": tile_conditioning_scale, + "control_guidance_start": 0.0, + "control_guidance_end": 1.0, + "control_scale_list":[] + } + + model_config.seed = [seeds[repeat_count]] + + config_path = save_dir.joinpath(f"{repeat_count:02d}_prompt.json") + config_path.write_text(model_config.json(indent=4), encoding="utf-8") + + + generated_dir = generate( + config_path=config_path, + width=width, + height=height, + length=length, + context=context, + overlap=overlap, + stride=stride, + device=device, + use_xformers=use_xformers, + force_half_vae=force_half_vae, + out_dir=save_dir, + ) + + interpolation_multiplier = 1 + + torch.cuda.empty_cache() + + generated_dir = generated_dir.rename(generated_dir.parent / f"{time_str}_{repeat_count:02d}") + + + frames_dir = glob.glob( os.path.join(generated_dir, "00-[0-9]*"), recursive=False)[0] + + + if rife_img_dir: + frames = sorted(glob.glob( os.path.join(rife_img_dir, "[0-9]*.png"), recursive=False)) + out_images = [] + for f in frames: + out_images.append(Image.open(f)) + + out_file = save_dir.joinpath(f"rife_only_for_comparison") + save_output(out_images,rife_img_dir,out_file,model_config.output,True,save_frames=None,save_video=None) + + + logger.info(f"Refined results are output to {generated_dir}") + diff --git a/animate/src/animatediff/dwpose/__init__.py b/animate/src/animatediff/dwpose/__init__.py new file mode 100644 index 0000000000000000000000000000000000000000..28df14c4fcb615c3df72d3212405e8cc7a913eb0 --- /dev/null +++ b/animate/src/animatediff/dwpose/__init__.py @@ -0,0 +1,91 @@ +# https://github.com/IDEA-Research/DWPose +# Openpose +# Original from CMU https://github.com/CMU-Perceptual-Computing-Lab/openpose +# 2nd Edited by https://github.com/Hzzone/pytorch-openpose +# 3rd Edited by ControlNet +# 4th Edited by ControlNet (added face and correct hands) + +import os + +os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" +import cv2 +import numpy as np +import torch +from controlnet_aux.util import HWC3, resize_image +from PIL import Image + +from . import util +from .wholebody import Wholebody + + +def draw_pose(pose, H, W): + bodies = pose['bodies'] + faces = pose['faces'] + hands = pose['hands'] + candidate = bodies['candidate'] + subset = bodies['subset'] + canvas = np.zeros(shape=(H, W, 3), dtype=np.uint8) + + canvas = util.draw_bodypose(canvas, candidate, subset) + + canvas = util.draw_handpose(canvas, hands) + + canvas = util.draw_facepose(canvas, faces) + + return canvas + + +class DWposeDetector: + def __init__(self): + pass + + def to(self, device): + self.pose_estimation = Wholebody(device) + return self + + def __call__(self, input_image, detect_resolution=512, image_resolution=512, output_type="pil", **kwargs): + input_image = cv2.cvtColor(np.array(input_image, dtype=np.uint8), cv2.COLOR_RGB2BGR) + + input_image = HWC3(input_image) + input_image = resize_image(input_image, detect_resolution) + H, W, C = input_image.shape + with torch.no_grad(): + candidate, subset = self.pose_estimation(input_image) + nums, keys, locs = candidate.shape + candidate[..., 0] /= float(W) + candidate[..., 1] /= float(H) + body = candidate[:,:18].copy() + body = body.reshape(nums*18, locs) + score = subset[:,:18] + for i in range(len(score)): + for j in range(len(score[i])): + if score[i][j] > 0.3: + score[i][j] = int(18*i+j) + else: + score[i][j] = -1 + + un_visible = subset<0.3 + candidate[un_visible] = -1 + + foot = candidate[:,18:24] + + faces = candidate[:,24:92] + + hands = candidate[:,92:113] + hands = np.vstack([hands, candidate[:,113:]]) + + bodies = dict(candidate=body, subset=score) + pose = dict(bodies=bodies, hands=hands, faces=faces) + + detected_map = draw_pose(pose, H, W) + detected_map = HWC3(detected_map) + + img = resize_image(input_image, image_resolution) + H, W, C = img.shape + + detected_map = cv2.resize(detected_map, (W, H), interpolation=cv2.INTER_LINEAR) + + if output_type == "pil": + detected_map = Image.fromarray(detected_map) + + return detected_map diff --git a/animate/src/animatediff/dwpose/onnxdet.py b/animate/src/animatediff/dwpose/onnxdet.py new file mode 100644 index 0000000000000000000000000000000000000000..f755e374b43d181111c9ff3151ead62153981cfd --- /dev/null +++ b/animate/src/animatediff/dwpose/onnxdet.py @@ -0,0 +1,126 @@ +# https://github.com/IDEA-Research/DWPose +import cv2 +import numpy as np +import onnxruntime + + +def nms(boxes, scores, nms_thr): + """Single class NMS implemented in Numpy.""" + x1 = boxes[:, 0] + y1 = boxes[:, 1] + x2 = boxes[:, 2] + y2 = boxes[:, 3] + + areas = (x2 - x1 + 1) * (y2 - y1 + 1) + order = scores.argsort()[::-1] + + keep = [] + while order.size > 0: + i = order[0] + keep.append(i) + xx1 = np.maximum(x1[i], x1[order[1:]]) + yy1 = np.maximum(y1[i], y1[order[1:]]) + xx2 = np.minimum(x2[i], x2[order[1:]]) + yy2 = np.minimum(y2[i], y2[order[1:]]) + + w = np.maximum(0.0, xx2 - xx1 + 1) + h = np.maximum(0.0, yy2 - yy1 + 1) + inter = w * h + ovr = inter / (areas[i] + areas[order[1:]] - inter) + + inds = np.where(ovr <= nms_thr)[0] + order = order[inds + 1] + + return keep + +def multiclass_nms(boxes, scores, nms_thr, score_thr): + """Multiclass NMS implemented in Numpy. Class-aware version.""" + final_dets = [] + num_classes = scores.shape[1] + for cls_ind in range(num_classes): + cls_scores = scores[:, cls_ind] + valid_score_mask = cls_scores > score_thr + if valid_score_mask.sum() == 0: + continue + else: + valid_scores = cls_scores[valid_score_mask] + valid_boxes = boxes[valid_score_mask] + keep = nms(valid_boxes, valid_scores, nms_thr) + if len(keep) > 0: + cls_inds = np.ones((len(keep), 1)) * cls_ind + dets = np.concatenate( + [valid_boxes[keep], valid_scores[keep, None], cls_inds], 1 + ) + final_dets.append(dets) + if len(final_dets) == 0: + return None + return np.concatenate(final_dets, 0) + +def demo_postprocess(outputs, img_size, p6=False): + grids = [] + expanded_strides = [] + strides = [8, 16, 32] if not p6 else [8, 16, 32, 64] + + hsizes = [img_size[0] // stride for stride in strides] + wsizes = [img_size[1] // stride for stride in strides] + + for hsize, wsize, stride in zip(hsizes, wsizes, strides): + xv, yv = np.meshgrid(np.arange(wsize), np.arange(hsize)) + grid = np.stack((xv, yv), 2).reshape(1, -1, 2) + grids.append(grid) + shape = grid.shape[:2] + expanded_strides.append(np.full((*shape, 1), stride)) + + grids = np.concatenate(grids, 1) + expanded_strides = np.concatenate(expanded_strides, 1) + outputs[..., :2] = (outputs[..., :2] + grids) * expanded_strides + outputs[..., 2:4] = np.exp(outputs[..., 2:4]) * expanded_strides + + return outputs + +def preprocess(img, input_size, swap=(2, 0, 1)): + if len(img.shape) == 3: + padded_img = np.ones((input_size[0], input_size[1], 3), dtype=np.uint8) * 114 + else: + padded_img = np.ones(input_size, dtype=np.uint8) * 114 + + r = min(input_size[0] / img.shape[0], input_size[1] / img.shape[1]) + resized_img = cv2.resize( + img, + (int(img.shape[1] * r), int(img.shape[0] * r)), + interpolation=cv2.INTER_LINEAR, + ).astype(np.uint8) + padded_img[: int(img.shape[0] * r), : int(img.shape[1] * r)] = resized_img + + padded_img = padded_img.transpose(swap) + padded_img = np.ascontiguousarray(padded_img, dtype=np.float32) + return padded_img, r + +def inference_detector(session, oriImg): + input_shape = (640,640) + img, ratio = preprocess(oriImg, input_shape) + + ort_inputs = {session.get_inputs()[0].name: img[None, :, :, :]} + output = session.run(None, ort_inputs) + predictions = demo_postprocess(output[0], input_shape)[0] + + boxes = predictions[:, :4] + scores = predictions[:, 4:5] * predictions[:, 5:] + + boxes_xyxy = np.ones_like(boxes) + boxes_xyxy[:, 0] = boxes[:, 0] - boxes[:, 2]/2. + boxes_xyxy[:, 1] = boxes[:, 1] - boxes[:, 3]/2. + boxes_xyxy[:, 2] = boxes[:, 0] + boxes[:, 2]/2. + boxes_xyxy[:, 3] = boxes[:, 1] + boxes[:, 3]/2. + boxes_xyxy /= ratio + dets = multiclass_nms(boxes_xyxy, scores, nms_thr=0.45, score_thr=0.1) + if dets is not None: + final_boxes, final_scores, final_cls_inds = dets[:, :4], dets[:, 4], dets[:, 5] + isscore = final_scores>0.3 + iscat = final_cls_inds == 0 + isbbox = [ i and j for (i, j) in zip(isscore, iscat)] + final_boxes = final_boxes[isbbox] + else: + return [] + + return final_boxes diff --git a/animate/src/animatediff/dwpose/onnxpose.py b/animate/src/animatediff/dwpose/onnxpose.py new file mode 100644 index 0000000000000000000000000000000000000000..cb080e75e8d6beba5e74b843a1e475e8152ed01e --- /dev/null +++ b/animate/src/animatediff/dwpose/onnxpose.py @@ -0,0 +1,361 @@ +# https://github.com/IDEA-Research/DWPose +from typing import List, Tuple + +import cv2 +import numpy as np +import onnxruntime as ort + +def preprocess( + img: np.ndarray, out_bbox, input_size: Tuple[int, int] = (192, 256) +) -> Tuple[np.ndarray, np.ndarray, np.ndarray]: + """Do preprocessing for RTMPose model inference. + + Args: + img (np.ndarray): Input image in shape. + input_size (tuple): Input image size in shape (w, h). + + Returns: + tuple: + - resized_img (np.ndarray): Preprocessed image. + - center (np.ndarray): Center of image. + - scale (np.ndarray): Scale of image. + """ + # get shape of image + img_shape = img.shape[:2] + out_img, out_center, out_scale = [], [], [] + if len(out_bbox) == 0: + out_bbox = [[0, 0, img_shape[1], img_shape[0]]] + for i in range(len(out_bbox)): + x0 = out_bbox[i][0] + y0 = out_bbox[i][1] + x1 = out_bbox[i][2] + y1 = out_bbox[i][3] + bbox = np.array([x0, y0, x1, y1]) + + # get center and scale + center, scale = bbox_xyxy2cs(bbox, padding=1.25) + + # do affine transformation + resized_img, scale = top_down_affine(input_size, scale, center, img) + + # normalize image + mean = np.array([123.675, 116.28, 103.53]) + std = np.array([58.395, 57.12, 57.375]) + resized_img = (resized_img - mean) / std + + out_img.append(resized_img) + out_center.append(center) + out_scale.append(scale) + + return out_img, out_center, out_scale + + +def inference(sess: ort.InferenceSession, img: np.ndarray) -> np.ndarray: + """Inference RTMPose model. + + Args: + sess (ort.InferenceSession): ONNXRuntime session. + img (np.ndarray): Input image in shape. + + Returns: + outputs (np.ndarray): Output of RTMPose model. + """ + all_out = [] + # build input + for i in range(len(img)): + input = [img[i].transpose(2, 0, 1)] + + # build output + sess_input = {sess.get_inputs()[0].name: input} + sess_output = [] + for out in sess.get_outputs(): + sess_output.append(out.name) + + # run model + outputs = sess.run(sess_output, sess_input) + all_out.append(outputs) + + return all_out + + +def postprocess(outputs: List[np.ndarray], + model_input_size: Tuple[int, int], + center: Tuple[int, int], + scale: Tuple[int, int], + simcc_split_ratio: float = 2.0 + ) -> Tuple[np.ndarray, np.ndarray]: + """Postprocess for RTMPose model output. + + Args: + outputs (np.ndarray): Output of RTMPose model. + model_input_size (tuple): RTMPose model Input image size. + center (tuple): Center of bbox in shape (x, y). + scale (tuple): Scale of bbox in shape (w, h). + simcc_split_ratio (float): Split ratio of simcc. + + Returns: + tuple: + - keypoints (np.ndarray): Rescaled keypoints. + - scores (np.ndarray): Model predict scores. + """ + all_key = [] + all_score = [] + for i in range(len(outputs)): + # use simcc to decode + simcc_x, simcc_y = outputs[i] + keypoints, scores = decode(simcc_x, simcc_y, simcc_split_ratio) + + # rescale keypoints + keypoints = keypoints / model_input_size * scale[i] + center[i] - scale[i] / 2 + all_key.append(keypoints[0]) + all_score.append(scores[0]) + + return np.array(all_key), np.array(all_score) + + +def bbox_xyxy2cs(bbox: np.ndarray, + padding: float = 1.) -> Tuple[np.ndarray, np.ndarray]: + """Transform the bbox format from (x,y,w,h) into (center, scale) + + Args: + bbox (ndarray): Bounding box(es) in shape (4,) or (n, 4), formatted + as (left, top, right, bottom) + padding (float): BBox padding factor that will be multilied to scale. + Default: 1.0 + + Returns: + tuple: A tuple containing center and scale. + - np.ndarray[float32]: Center (x, y) of the bbox in shape (2,) or + (n, 2) + - np.ndarray[float32]: Scale (w, h) of the bbox in shape (2,) or + (n, 2) + """ + # convert single bbox from (4, ) to (1, 4) + dim = bbox.ndim + if dim == 1: + bbox = bbox[None, :] + + # get bbox center and scale + x1, y1, x2, y2 = np.hsplit(bbox, [1, 2, 3]) + center = np.hstack([x1 + x2, y1 + y2]) * 0.5 + scale = np.hstack([x2 - x1, y2 - y1]) * padding + + if dim == 1: + center = center[0] + scale = scale[0] + + return center, scale + + +def _fix_aspect_ratio(bbox_scale: np.ndarray, + aspect_ratio: float) -> np.ndarray: + """Extend the scale to match the given aspect ratio. + + Args: + scale (np.ndarray): The image scale (w, h) in shape (2, ) + aspect_ratio (float): The ratio of ``w/h`` + + Returns: + np.ndarray: The reshaped image scale in (2, ) + """ + w, h = np.hsplit(bbox_scale, [1]) + bbox_scale = np.where(w > h * aspect_ratio, + np.hstack([w, w / aspect_ratio]), + np.hstack([h * aspect_ratio, h])) + return bbox_scale + + +def _rotate_point(pt: np.ndarray, angle_rad: float) -> np.ndarray: + """Rotate a point by an angle. + + Args: + pt (np.ndarray): 2D point coordinates (x, y) in shape (2, ) + angle_rad (float): rotation angle in radian + + Returns: + np.ndarray: Rotated point in shape (2, ) + """ + sn, cs = np.sin(angle_rad), np.cos(angle_rad) + rot_mat = np.array([[cs, -sn], [sn, cs]]) + return rot_mat @ pt + + +def _get_3rd_point(a: np.ndarray, b: np.ndarray) -> np.ndarray: + """To calculate the affine matrix, three pairs of points are required. This + function is used to get the 3rd point, given 2D points a & b. + + The 3rd point is defined by rotating vector `a - b` by 90 degrees + anticlockwise, using b as the rotation center. + + Args: + a (np.ndarray): The 1st point (x,y) in shape (2, ) + b (np.ndarray): The 2nd point (x,y) in shape (2, ) + + Returns: + np.ndarray: The 3rd point. + """ + direction = a - b + c = b + np.r_[-direction[1], direction[0]] + return c + + +def get_warp_matrix(center: np.ndarray, + scale: np.ndarray, + rot: float, + output_size: Tuple[int, int], + shift: Tuple[float, float] = (0., 0.), + inv: bool = False) -> np.ndarray: + """Calculate the affine transformation matrix that can warp the bbox area + in the input image to the output size. + + Args: + center (np.ndarray[2, ]): Center of the bounding box (x, y). + scale (np.ndarray[2, ]): Scale of the bounding box + wrt [width, height]. + rot (float): Rotation angle (degree). + output_size (np.ndarray[2, ] | list(2,)): Size of the + destination heatmaps. + shift (0-100%): Shift translation ratio wrt the width/height. + Default (0., 0.). + inv (bool): Option to inverse the affine transform direction. + (inv=False: src->dst or inv=True: dst->src) + + Returns: + np.ndarray: A 2x3 transformation matrix + """ + shift = np.array(shift) + src_w = scale[0] + dst_w = output_size[0] + dst_h = output_size[1] + + # compute transformation matrix + rot_rad = np.deg2rad(rot) + src_dir = _rotate_point(np.array([0., src_w * -0.5]), rot_rad) + dst_dir = np.array([0., dst_w * -0.5]) + + # get four corners of the src rectangle in the original image + src = np.zeros((3, 2), dtype=np.float32) + src[0, :] = center + scale * shift + src[1, :] = center + src_dir + scale * shift + src[2, :] = _get_3rd_point(src[0, :], src[1, :]) + + # get four corners of the dst rectangle in the input image + dst = np.zeros((3, 2), dtype=np.float32) + dst[0, :] = [dst_w * 0.5, dst_h * 0.5] + dst[1, :] = np.array([dst_w * 0.5, dst_h * 0.5]) + dst_dir + dst[2, :] = _get_3rd_point(dst[0, :], dst[1, :]) + + if inv: + warp_mat = cv2.getAffineTransform(np.float32(dst), np.float32(src)) + else: + warp_mat = cv2.getAffineTransform(np.float32(src), np.float32(dst)) + + return warp_mat + + +def top_down_affine(input_size: dict, bbox_scale: dict, bbox_center: dict, + img: np.ndarray) -> Tuple[np.ndarray, np.ndarray]: + """Get the bbox image as the model input by affine transform. + + Args: + input_size (dict): The input size of the model. + bbox_scale (dict): The bbox scale of the img. + bbox_center (dict): The bbox center of the img. + img (np.ndarray): The original image. + + Returns: + tuple: A tuple containing center and scale. + - np.ndarray[float32]: img after affine transform. + - np.ndarray[float32]: bbox scale after affine transform. + """ + w, h = input_size + warp_size = (int(w), int(h)) + + # reshape bbox to fixed aspect ratio + bbox_scale = _fix_aspect_ratio(bbox_scale, aspect_ratio=w / h) + + # get the affine matrix + center = bbox_center + scale = bbox_scale + rot = 0 + warp_mat = get_warp_matrix(center, scale, rot, output_size=(w, h)) + + # do affine transform + img = cv2.warpAffine(img, warp_mat, warp_size, flags=cv2.INTER_LINEAR) + + return img, bbox_scale + + +def get_simcc_maximum(simcc_x: np.ndarray, + simcc_y: np.ndarray) -> Tuple[np.ndarray, np.ndarray]: + """Get maximum response location and value from simcc representations. + + Note: + instance number: N + num_keypoints: K + heatmap height: H + heatmap width: W + + Args: + simcc_x (np.ndarray): x-axis SimCC in shape (K, Wx) or (N, K, Wx) + simcc_y (np.ndarray): y-axis SimCC in shape (K, Wy) or (N, K, Wy) + + Returns: + tuple: + - locs (np.ndarray): locations of maximum heatmap responses in shape + (K, 2) or (N, K, 2) + - vals (np.ndarray): values of maximum heatmap responses in shape + (K,) or (N, K) + """ + N, K, Wx = simcc_x.shape + simcc_x = simcc_x.reshape(N * K, -1) + simcc_y = simcc_y.reshape(N * K, -1) + + # get maximum value locations + x_locs = np.argmax(simcc_x, axis=1) + y_locs = np.argmax(simcc_y, axis=1) + locs = np.stack((x_locs, y_locs), axis=-1).astype(np.float32) + max_val_x = np.amax(simcc_x, axis=1) + max_val_y = np.amax(simcc_y, axis=1) + + # get maximum value across x and y axis + mask = max_val_x > max_val_y + max_val_x[mask] = max_val_y[mask] + vals = max_val_x + locs[vals <= 0.] = -1 + + # reshape + locs = locs.reshape(N, K, 2) + vals = vals.reshape(N, K) + + return locs, vals + + +def decode(simcc_x: np.ndarray, simcc_y: np.ndarray, + simcc_split_ratio) -> Tuple[np.ndarray, np.ndarray]: + """Modulate simcc distribution with Gaussian. + + Args: + simcc_x (np.ndarray[K, Wx]): model predicted simcc in x. + simcc_y (np.ndarray[K, Wy]): model predicted simcc in y. + simcc_split_ratio (int): The split ratio of simcc. + + Returns: + tuple: A tuple containing center and scale. + - np.ndarray[float32]: keypoints in shape (K, 2) or (n, K, 2) + - np.ndarray[float32]: scores in shape (K,) or (n, K) + """ + keypoints, scores = get_simcc_maximum(simcc_x, simcc_y) + keypoints /= simcc_split_ratio + + return keypoints, scores + + +def inference_pose(session, out_bbox, oriImg): + h, w = session.get_inputs()[0].shape[2:] + model_input_size = (w, h) + resized_img, center, scale = preprocess(oriImg, out_bbox, model_input_size) + outputs = inference(session, resized_img) + keypoints, scores = postprocess(outputs, model_input_size, center, scale) + + return keypoints, scores \ No newline at end of file diff --git a/animate/src/animatediff/dwpose/util.py b/animate/src/animatediff/dwpose/util.py new file mode 100644 index 0000000000000000000000000000000000000000..21e37d609b08591dfa15dd81b3c35839256267fe --- /dev/null +++ b/animate/src/animatediff/dwpose/util.py @@ -0,0 +1,298 @@ +# https://github.com/IDEA-Research/DWPose +import math +import numpy as np +import matplotlib +import cv2 + + +eps = 0.01 + + +def smart_resize(x, s): + Ht, Wt = s + if x.ndim == 2: + Ho, Wo = x.shape + Co = 1 + else: + Ho, Wo, Co = x.shape + if Co == 3 or Co == 1: + k = float(Ht + Wt) / float(Ho + Wo) + return cv2.resize(x, (int(Wt), int(Ht)), interpolation=cv2.INTER_AREA if k < 1 else cv2.INTER_LANCZOS4) + else: + return np.stack([smart_resize(x[:, :, i], s) for i in range(Co)], axis=2) + + +def smart_resize_k(x, fx, fy): + if x.ndim == 2: + Ho, Wo = x.shape + Co = 1 + else: + Ho, Wo, Co = x.shape + Ht, Wt = Ho * fy, Wo * fx + if Co == 3 or Co == 1: + k = float(Ht + Wt) / float(Ho + Wo) + return cv2.resize(x, (int(Wt), int(Ht)), interpolation=cv2.INTER_AREA if k < 1 else cv2.INTER_LANCZOS4) + else: + return np.stack([smart_resize_k(x[:, :, i], fx, fy) for i in range(Co)], axis=2) + + +def padRightDownCorner(img, stride, padValue): + h = img.shape[0] + w = img.shape[1] + + pad = 4 * [None] + pad[0] = 0 # up + pad[1] = 0 # left + pad[2] = 0 if (h % stride == 0) else stride - (h % stride) # down + pad[3] = 0 if (w % stride == 0) else stride - (w % stride) # right + + img_padded = img + pad_up = np.tile(img_padded[0:1, :, :]*0 + padValue, (pad[0], 1, 1)) + img_padded = np.concatenate((pad_up, img_padded), axis=0) + pad_left = np.tile(img_padded[:, 0:1, :]*0 + padValue, (1, pad[1], 1)) + img_padded = np.concatenate((pad_left, img_padded), axis=1) + pad_down = np.tile(img_padded[-2:-1, :, :]*0 + padValue, (pad[2], 1, 1)) + img_padded = np.concatenate((img_padded, pad_down), axis=0) + pad_right = np.tile(img_padded[:, -2:-1, :]*0 + padValue, (1, pad[3], 1)) + img_padded = np.concatenate((img_padded, pad_right), axis=1) + + return img_padded, pad + + +def transfer(model, model_weights): + transfered_model_weights = {} + for weights_name in model.state_dict().keys(): + transfered_model_weights[weights_name] = model_weights['.'.join(weights_name.split('.')[1:])] + return transfered_model_weights + + +def draw_bodypose(canvas, candidate, subset): + H, W, C = canvas.shape + candidate = np.array(candidate) + subset = np.array(subset) + + stickwidth = 4 + + limbSeq = [[2, 3], [2, 6], [3, 4], [4, 5], [6, 7], [7, 8], [2, 9], [9, 10], \ + [10, 11], [2, 12], [12, 13], [13, 14], [2, 1], [1, 15], [15, 17], \ + [1, 16], [16, 18], [3, 17], [6, 18]] + + colors = [[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0], \ + [0, 255, 85], [0, 255, 170], [0, 255, 255], [0, 170, 255], [0, 85, 255], [0, 0, 255], [85, 0, 255], \ + [170, 0, 255], [255, 0, 255], [255, 0, 170], [255, 0, 85]] + + for i in range(17): + for n in range(len(subset)): + index = subset[n][np.array(limbSeq[i]) - 1] + if -1 in index: + continue + Y = candidate[index.astype(int), 0] * float(W) + X = candidate[index.astype(int), 1] * float(H) + mX = np.mean(X) + mY = np.mean(Y) + length = ((X[0] - X[1]) ** 2 + (Y[0] - Y[1]) ** 2) ** 0.5 + angle = math.degrees(math.atan2(X[0] - X[1], Y[0] - Y[1])) + polygon = cv2.ellipse2Poly((int(mY), int(mX)), (int(length / 2), stickwidth), int(angle), 0, 360, 1) + cv2.fillConvexPoly(canvas, polygon, colors[i]) + + canvas = (canvas * 0.6).astype(np.uint8) + + for i in range(18): + for n in range(len(subset)): + index = int(subset[n][i]) + if index == -1: + continue + x, y = candidate[index][0:2] + x = int(x * W) + y = int(y * H) + cv2.circle(canvas, (int(x), int(y)), 4, colors[i], thickness=-1) + + return canvas + + +def draw_handpose(canvas, all_hand_peaks): + H, W, C = canvas.shape + + edges = [[0, 1], [1, 2], [2, 3], [3, 4], [0, 5], [5, 6], [6, 7], [7, 8], [0, 9], [9, 10], \ + [10, 11], [11, 12], [0, 13], [13, 14], [14, 15], [15, 16], [0, 17], [17, 18], [18, 19], [19, 20]] + + for peaks in all_hand_peaks: + peaks = np.array(peaks) + + for ie, e in enumerate(edges): + x1, y1 = peaks[e[0]] + x2, y2 = peaks[e[1]] + x1 = int(x1 * W) + y1 = int(y1 * H) + x2 = int(x2 * W) + y2 = int(y2 * H) + if x1 > eps and y1 > eps and x2 > eps and y2 > eps: + cv2.line(canvas, (x1, y1), (x2, y2), matplotlib.colors.hsv_to_rgb([ie / float(len(edges)), 1.0, 1.0]) * 255, thickness=2) + + for i, keyponit in enumerate(peaks): + x, y = keyponit + x = int(x * W) + y = int(y * H) + if x > eps and y > eps: + cv2.circle(canvas, (x, y), 4, (0, 0, 255), thickness=-1) + return canvas + + +def draw_facepose(canvas, all_lmks): + H, W, C = canvas.shape + for lmks in all_lmks: + lmks = np.array(lmks) + for lmk in lmks: + x, y = lmk + x = int(x * W) + y = int(y * H) + if x > eps and y > eps: + cv2.circle(canvas, (x, y), 3, (255, 255, 255), thickness=-1) + return canvas + + +# detect hand according to body pose keypoints +# please refer to https://github.com/CMU-Perceptual-Computing-Lab/openpose/blob/master/src/openpose/hand/handDetector.cpp +def handDetect(candidate, subset, oriImg): + # right hand: wrist 4, elbow 3, shoulder 2 + # left hand: wrist 7, elbow 6, shoulder 5 + ratioWristElbow = 0.33 + detect_result = [] + image_height, image_width = oriImg.shape[0:2] + for person in subset.astype(int): + # if any of three not detected + has_left = np.sum(person[[5, 6, 7]] == -1) == 0 + has_right = np.sum(person[[2, 3, 4]] == -1) == 0 + if not (has_left or has_right): + continue + hands = [] + #left hand + if has_left: + left_shoulder_index, left_elbow_index, left_wrist_index = person[[5, 6, 7]] + x1, y1 = candidate[left_shoulder_index][:2] + x2, y2 = candidate[left_elbow_index][:2] + x3, y3 = candidate[left_wrist_index][:2] + hands.append([x1, y1, x2, y2, x3, y3, True]) + # right hand + if has_right: + right_shoulder_index, right_elbow_index, right_wrist_index = person[[2, 3, 4]] + x1, y1 = candidate[right_shoulder_index][:2] + x2, y2 = candidate[right_elbow_index][:2] + x3, y3 = candidate[right_wrist_index][:2] + hands.append([x1, y1, x2, y2, x3, y3, False]) + + for x1, y1, x2, y2, x3, y3, is_left in hands: + # pos_hand = pos_wrist + ratio * (pos_wrist - pos_elbox) = (1 + ratio) * pos_wrist - ratio * pos_elbox + # handRectangle.x = posePtr[wrist*3] + ratioWristElbow * (posePtr[wrist*3] - posePtr[elbow*3]); + # handRectangle.y = posePtr[wrist*3+1] + ratioWristElbow * (posePtr[wrist*3+1] - posePtr[elbow*3+1]); + # const auto distanceWristElbow = getDistance(poseKeypoints, person, wrist, elbow); + # const auto distanceElbowShoulder = getDistance(poseKeypoints, person, elbow, shoulder); + # handRectangle.width = 1.5f * fastMax(distanceWristElbow, 0.9f * distanceElbowShoulder); + x = x3 + ratioWristElbow * (x3 - x2) + y = y3 + ratioWristElbow * (y3 - y2) + distanceWristElbow = math.sqrt((x3 - x2) ** 2 + (y3 - y2) ** 2) + distanceElbowShoulder = math.sqrt((x2 - x1) ** 2 + (y2 - y1) ** 2) + width = 1.5 * max(distanceWristElbow, 0.9 * distanceElbowShoulder) + # x-y refers to the center --> offset to topLeft point + # handRectangle.x -= handRectangle.width / 2.f; + # handRectangle.y -= handRectangle.height / 2.f; + x -= width / 2 + y -= width / 2 # width = height + # overflow the image + if x < 0: x = 0 + if y < 0: y = 0 + width1 = width + width2 = width + if x + width > image_width: width1 = image_width - x + if y + width > image_height: width2 = image_height - y + width = min(width1, width2) + # the max hand box value is 20 pixels + if width >= 20: + detect_result.append([int(x), int(y), int(width), is_left]) + + ''' + return value: [[x, y, w, True if left hand else False]]. + width=height since the network require squared input. + x, y is the coordinate of top left + ''' + return detect_result + + +# Written by Lvmin +def faceDetect(candidate, subset, oriImg): + # left right eye ear 14 15 16 17 + detect_result = [] + image_height, image_width = oriImg.shape[0:2] + for person in subset.astype(int): + has_head = person[0] > -1 + if not has_head: + continue + + has_left_eye = person[14] > -1 + has_right_eye = person[15] > -1 + has_left_ear = person[16] > -1 + has_right_ear = person[17] > -1 + + if not (has_left_eye or has_right_eye or has_left_ear or has_right_ear): + continue + + head, left_eye, right_eye, left_ear, right_ear = person[[0, 14, 15, 16, 17]] + + width = 0.0 + x0, y0 = candidate[head][:2] + + if has_left_eye: + x1, y1 = candidate[left_eye][:2] + d = max(abs(x0 - x1), abs(y0 - y1)) + width = max(width, d * 3.0) + + if has_right_eye: + x1, y1 = candidate[right_eye][:2] + d = max(abs(x0 - x1), abs(y0 - y1)) + width = max(width, d * 3.0) + + if has_left_ear: + x1, y1 = candidate[left_ear][:2] + d = max(abs(x0 - x1), abs(y0 - y1)) + width = max(width, d * 1.5) + + if has_right_ear: + x1, y1 = candidate[right_ear][:2] + d = max(abs(x0 - x1), abs(y0 - y1)) + width = max(width, d * 1.5) + + x, y = x0, y0 + + x -= width + y -= width + + if x < 0: + x = 0 + + if y < 0: + y = 0 + + width1 = width * 2 + width2 = width * 2 + + if x + width > image_width: + width1 = image_width - x + + if y + width > image_height: + width2 = image_height - y + + width = min(width1, width2) + + if width >= 20: + detect_result.append([int(x), int(y), int(width)]) + + return detect_result + + +# get max index of 2d array +def npmax(array): + arrayindex = array.argmax(1) + arrayvalue = array.max(1) + i = arrayvalue.argmax() + j = arrayindex[i] + return i, j diff --git a/animate/src/animatediff/dwpose/wholebody.py b/animate/src/animatediff/dwpose/wholebody.py new file mode 100644 index 0000000000000000000000000000000000000000..4de6d10e3cff9634b80063e0d6862606731f75c4 --- /dev/null +++ b/animate/src/animatediff/dwpose/wholebody.py @@ -0,0 +1,49 @@ +# https://github.com/IDEA-Research/DWPose +import cv2 +import numpy as np +import onnxruntime as ort + +from .onnxdet import inference_detector +from .onnxpose import inference_pose + + +class Wholebody: + def __init__(self, device='cuda:0'): + providers = ['CPUExecutionProvider' + ] if device == 'cpu' else ['CUDAExecutionProvider'] + onnx_det = 'data/models/DWPose/yolox_l.onnx' + onnx_pose = 'data/models/DWPose/dw-ll_ucoco_384.onnx' + + self.session_det = ort.InferenceSession(path_or_bytes=onnx_det, providers=providers) + self.session_pose = ort.InferenceSession(path_or_bytes=onnx_pose, providers=providers) + + def __call__(self, oriImg): + det_result = inference_detector(self.session_det, oriImg) + keypoints, scores = inference_pose(self.session_pose, det_result, oriImg) + + keypoints_info = np.concatenate( + (keypoints, scores[..., None]), axis=-1) + # compute neck joint + neck = np.mean(keypoints_info[:, [5, 6]], axis=1) + # neck score when visualizing pred + neck[:, 2:4] = np.logical_and( + keypoints_info[:, 5, 2:4] > 0.3, + keypoints_info[:, 6, 2:4] > 0.3).astype(int) + new_keypoints_info = np.insert( + keypoints_info, 17, neck, axis=1) + mmpose_idx = [ + 17, 6, 8, 10, 7, 9, 12, 14, 16, 13, 15, 2, 1, 4, 3 + ] + openpose_idx = [ + 1, 2, 3, 4, 6, 7, 8, 9, 10, 12, 13, 14, 15, 16, 17 + ] + new_keypoints_info[:, openpose_idx] = \ + new_keypoints_info[:, mmpose_idx] + keypoints_info = new_keypoints_info + + keypoints, scores = keypoints_info[ + ..., :2], keypoints_info[..., 2] + + return keypoints, scores + + diff --git a/animate/src/animatediff/generate.py b/animate/src/animatediff/generate.py new file mode 100644 index 0000000000000000000000000000000000000000..2eae736418b4e7bad24860a82f86ceeee09a1d1b --- /dev/null +++ b/animate/src/animatediff/generate.py @@ -0,0 +1,1763 @@ +import glob +import logging +import os +import re +from functools import partial +from itertools import chain +from os import PathLike +from pathlib import Path +from typing import Any, Callable, Dict, List, Union + +import numpy as np +import torch +from controlnet_aux import LineartAnimeDetector +from controlnet_aux.processor import MODELS +from controlnet_aux.processor import Processor as ControlnetPreProcessor +from controlnet_aux.util import HWC3, ade_palette +from controlnet_aux.util import resize_image as aux_resize_image +from diffusers import (AutoencoderKL, ControlNetModel, DiffusionPipeline, + EulerDiscreteScheduler, + StableDiffusionControlNetImg2ImgPipeline, + StableDiffusionPipeline, StableDiffusionXLPipeline) +from PIL import Image +from torchvision.datasets.folder import IMG_EXTENSIONS +from tqdm.rich import tqdm +from transformers import (AutoImageProcessor, CLIPImageProcessor, + CLIPTextConfig, CLIPTextModel, + CLIPTextModelWithProjection, CLIPTokenizer, + UperNetForSemanticSegmentation) + +from animatediff import get_dir +from animatediff.dwpose import DWposeDetector +from animatediff.models.unet import UNet2DConditionModel +from animatediff.pipelines import AnimationPipeline, load_text_embeddings +from animatediff.pipelines.lora import load_lcm_lora, load_lora_map +from animatediff.pipelines.pipeline_controlnet_img2img_reference import \ + StableDiffusionControlNetImg2ImgReferencePipeline +from animatediff.schedulers import DiffusionScheduler, get_scheduler +from animatediff.settings import InferenceConfig, ModelConfig +from animatediff.utils.control_net_lllite import (ControlNetLLLite, + load_controlnet_lllite) +from animatediff.utils.convert_from_ckpt import convert_ldm_vae_checkpoint +from animatediff.utils.convert_lora_safetensor_to_diffusers import convert_lora +from animatediff.utils.model import (ensure_motion_modules, + get_checkpoint_weights, + get_checkpoint_weights_sdxl) +from animatediff.utils.util import (get_resized_image, get_resized_image2, + get_resized_images, + get_tensor_interpolation_method, + prepare_dwpose, prepare_extra_controlnet, + prepare_ip_adapter, + prepare_ip_adapter_sdxl, prepare_lcm_lora, + prepare_lllite, prepare_motion_module, + save_frames, save_imgs, save_video) + +controlnet_address_table={ + "controlnet_tile" : ['lllyasviel/control_v11f1e_sd15_tile'], + "controlnet_lineart_anime" : ['lllyasviel/control_v11p_sd15s2_lineart_anime'], + "controlnet_ip2p" : ['lllyasviel/control_v11e_sd15_ip2p'], + "controlnet_openpose" : ['lllyasviel/control_v11p_sd15_openpose'], + "controlnet_softedge" : ['lllyasviel/control_v11p_sd15_softedge'], + "controlnet_shuffle" : ['lllyasviel/control_v11e_sd15_shuffle'], + "controlnet_depth" : ['lllyasviel/control_v11f1p_sd15_depth'], + "controlnet_canny" : ['lllyasviel/control_v11p_sd15_canny'], + "controlnet_inpaint" : ['lllyasviel/control_v11p_sd15_inpaint'], + "controlnet_lineart" : ['lllyasviel/control_v11p_sd15_lineart'], + "controlnet_mlsd" : ['lllyasviel/control_v11p_sd15_mlsd'], + "controlnet_normalbae" : ['lllyasviel/control_v11p_sd15_normalbae'], + "controlnet_scribble" : ['lllyasviel/control_v11p_sd15_scribble'], + "controlnet_seg" : ['lllyasviel/control_v11p_sd15_seg'], + "qr_code_monster_v1" : ['monster-labs/control_v1p_sd15_qrcode_monster'], + "qr_code_monster_v2" : ['monster-labs/control_v1p_sd15_qrcode_monster', 'v2'], + "controlnet_mediapipe_face" : ['CrucibleAI/ControlNetMediaPipeFace', "diffusion_sd15"], + "animatediff_controlnet" : [None, "data/models/controlnet/animatediff_controlnet/controlnet_checkpoint.ckpt"] +} + +# Edit this table if you want to change to another controlnet checkpoint +controlnet_address_table_sdxl={ +# "controlnet_openpose" : ['thibaud/controlnet-openpose-sdxl-1.0'], +# "controlnet_softedge" : ['SargeZT/controlnet-sd-xl-1.0-softedge-dexined'], +# "controlnet_depth" : ['diffusers/controlnet-depth-sdxl-1.0-small'], +# "controlnet_canny" : ['diffusers/controlnet-canny-sdxl-1.0-small'], +# "controlnet_seg" : ['SargeZT/sdxl-controlnet-seg'], + "qr_code_monster_v1" : ['monster-labs/control_v1p_sdxl_qrcode_monster'], +} + +# Edit this table if you want to change to another lllite checkpoint +lllite_address_table_sdxl={ + "controlnet_tile" : ['models/lllite/bdsqlsz_controlllite_xl_tile_anime_β.safetensors'], + "controlnet_lineart_anime" : ['models/lllite/bdsqlsz_controlllite_xl_lineart_anime_denoise.safetensors'], +# "controlnet_ip2p" : ('lllyasviel/control_v11e_sd15_ip2p'), + "controlnet_openpose" : ['models/lllite/bdsqlsz_controlllite_xl_dw_openpose.safetensors'], +# "controlnet_openpose" : ['models/lllite/controllllite_v01032064e_sdxl_pose_anime.safetensors'], + "controlnet_softedge" : ['models/lllite/bdsqlsz_controlllite_xl_softedge.safetensors'], + "controlnet_shuffle" : ['models/lllite/bdsqlsz_controlllite_xl_t2i-adapter_color_shuffle.safetensors'], + "controlnet_depth" : ['models/lllite/bdsqlsz_controlllite_xl_depth.safetensors'], + "controlnet_canny" : ['models/lllite/bdsqlsz_controlllite_xl_canny.safetensors'], +# "controlnet_canny" : ['models/lllite/controllllite_v01032064e_sdxl_canny.safetensors'], +# "controlnet_inpaint" : ('lllyasviel/control_v11p_sd15_inpaint'), +# "controlnet_lineart" : ('lllyasviel/control_v11p_sd15_lineart'), + "controlnet_mlsd" : ['models/lllite/bdsqlsz_controlllite_xl_mlsd_V2.safetensors'], + "controlnet_normalbae" : ['models/lllite/bdsqlsz_controlllite_xl_normal.safetensors'], + "controlnet_scribble" : ['models/lllite/bdsqlsz_controlllite_xl_sketch.safetensors'], + "controlnet_seg" : ['models/lllite/bdsqlsz_controlllite_xl_segment_animeface_V2.safetensors'], +# "qr_code_monster_v1" : ['monster-labs/control_v1p_sdxl_qrcode_monster'], +# "qr_code_monster_v2" : ('monster-labs/control_v1p_sd15_qrcode_monster', 'v2'), +# "controlnet_mediapipe_face" : ('CrucibleAI/ControlNetMediaPipeFace', "diffusion_sd15"), +} + + + + + +try: + import onnxruntime + onnxruntime_installed = True +except: + onnxruntime_installed = False + + + + +logger = logging.getLogger(__name__) + +data_dir = get_dir("data") +default_base_path = data_dir.joinpath("models/huggingface/stable-diffusion-v1-5") + +re_clean_prompt = re.compile(r"[^\w\-, ]") + +controlnet_preprocessor = {} + +def load_safetensors_lora(text_encoder, unet, lora_path, alpha=0.75, is_animatediff=True): + from safetensors.torch import load_file + + from animatediff.utils.lora_diffusers import (LoRANetwork, + create_network_from_weights) + + sd = load_file(lora_path) + + print(f"create LoRA network") + lora_network: LoRANetwork = create_network_from_weights(text_encoder, unet, sd, multiplier=alpha, is_animatediff=is_animatediff) + print(f"load LoRA network weights") + lora_network.load_state_dict(sd, False) + #lora_network.merge_to(alpha) + lora_network.apply_to(alpha) + return lora_network + +def load_safetensors_lora2(text_encoder, unet, lora_path, alpha=0.75, is_animatediff=True): + from safetensors.torch import load_file + + from animatediff.utils.lora_diffusers import (LoRANetwork, + create_network_from_weights) + + sd = load_file(lora_path) + + print(f"create LoRA network") + lora_network: LoRANetwork = create_network_from_weights(text_encoder, unet, sd, multiplier=alpha, is_animatediff=is_animatediff) + print(f"load LoRA network weights") + lora_network.load_state_dict(sd, False) + lora_network.merge_to(alpha) + + +def load_tensors(path:Path,framework="pt",device="cpu"): + tensors = {} + if path.suffix == ".safetensors": + from safetensors import safe_open + with safe_open(path, framework=framework, device=device) as f: + for k in f.keys(): + tensors[k] = f.get_tensor(k) # loads the full tensor given a key + else: + from torch import load + tensors = load(path, device) + if "state_dict" in tensors: + tensors = tensors["state_dict"] + return tensors + +def load_motion_lora(unet, lora_path:Path, alpha=1.0): + state_dict = load_tensors(lora_path) + + # directly update weight in diffusers model + for key in state_dict: + # only process lora down key + if "up." in key: continue + + up_key = key.replace(".down.", ".up.") + model_key = key.replace("processor.", "").replace("_lora", "").replace("down.", "").replace("up.", "") + model_key = model_key.replace("to_out.", "to_out.0.") + layer_infos = model_key.split(".")[:-1] + + curr_layer = unet + try: + while len(layer_infos) > 0: + temp_name = layer_infos.pop(0) + curr_layer = curr_layer.__getattr__(temp_name) + except: + logger.info(f"{model_key} not found") + continue + + + weight_down = state_dict[key] + weight_up = state_dict[up_key] + curr_layer.weight.data += alpha * torch.mm(weight_up, weight_down).to(curr_layer.weight.data.device) + + +class SegPreProcessor: + + def __init__(self): + self.image_processor = AutoImageProcessor.from_pretrained("openmmlab/upernet-convnext-small") + self.processor = UperNetForSemanticSegmentation.from_pretrained("openmmlab/upernet-convnext-small") + + def __call__(self, input_image, detect_resolution=512, image_resolution=512, output_type="pil", **kwargs): + + input_array = np.array(input_image, dtype=np.uint8) + input_array = HWC3(input_array) + input_array = aux_resize_image(input_array, detect_resolution) + + pixel_values = self.image_processor(input_array, return_tensors="pt").pixel_values + + with torch.no_grad(): + outputs = self.processor(pixel_values.to(self.processor.device)) + + outputs.loss = outputs.loss.to("cpu") if outputs.loss is not None else outputs.loss + outputs.logits = outputs.logits.to("cpu") if outputs.logits is not None else outputs.logits + outputs.hidden_states = outputs.hidden_states.to("cpu") if outputs.hidden_states is not None else outputs.hidden_states + outputs.attentions = outputs.attentions.to("cpu") if outputs.attentions is not None else outputs.attentions + + seg = self.image_processor.post_process_semantic_segmentation(outputs, target_sizes=[input_image.size[::-1]])[0] + color_seg = np.zeros((seg.shape[0], seg.shape[1], 3), dtype=np.uint8) # height, width, 3 + + for label, color in enumerate(ade_palette()): + color_seg[seg == label, :] = color + + color_seg = color_seg.astype(np.uint8) + color_seg = aux_resize_image(color_seg, image_resolution) + color_seg = Image.fromarray(color_seg) + + return color_seg + +class NullPreProcessor: + def __call__(self, input_image, **kwargs): + return input_image + +class BlurPreProcessor: + def __call__(self, input_image, sigma=5.0, **kwargs): + import cv2 + + input_array = np.array(input_image, dtype=np.uint8) + input_array = HWC3(input_array) + + dst = cv2.GaussianBlur(input_array, (0, 0), sigma) + + return Image.fromarray(dst) + +class TileResamplePreProcessor: + + def resize(self, input_image, resolution): + import cv2 + + H, W, C = input_image.shape + H = float(H) + W = float(W) + k = float(resolution) / min(H, W) + H *= k + W *= k + img = cv2.resize(input_image, (int(W), int(H)), interpolation=cv2.INTER_LANCZOS4 if k > 1 else cv2.INTER_AREA) + return img + + def __call__(self, input_image, down_sampling_rate = 1.0, **kwargs): + + input_array = np.array(input_image, dtype=np.uint8) + input_array = HWC3(input_array) + + H, W, C = input_array.shape + + target_res = min(H,W) / down_sampling_rate + + dst = self.resize(input_array, target_res) + + return Image.fromarray(dst) + + + +def is_valid_controlnet_type(type_str, is_sdxl): + if not is_sdxl: + return type_str in controlnet_address_table + else: + return (type_str in controlnet_address_table_sdxl) or (type_str in lllite_address_table_sdxl) + +def load_controlnet_from_file(file_path, torch_dtype): + from safetensors.torch import load_file + + prepare_extra_controlnet() + + file_path = Path(file_path) + + if file_path.exists() and file_path.is_file(): + if file_path.suffix.lower() in [".pth", ".pt", ".ckpt"]: + controlnet_state_dict = torch.load(file_path, map_location="cpu", weights_only=True) + elif file_path.suffix.lower() == ".safetensors": + controlnet_state_dict = load_file(file_path, device="cpu") + else: + raise RuntimeError( + f"unknown file format for controlnet weights: {file_path.suffix}" + ) + else: + raise FileNotFoundError(f"no controlnet weights found in {file_path}") + + if file_path.parent.name == "animatediff_controlnet": + model = ControlNetModel(cross_attention_dim=768) + else: + model = ControlNetModel() + + missing, _ = model.load_state_dict(controlnet_state_dict["state_dict"], strict=False) + if len(missing) > 0: + logger.info(f"ControlNetModel has missing keys: {missing}") + + return model.to(dtype=torch_dtype) + +def create_controlnet_model(pipe, type_str, is_sdxl): + if not is_sdxl: + if type_str in controlnet_address_table: + addr = controlnet_address_table[type_str] + if addr[0] != None: + if len(addr) == 1: + return ControlNetModel.from_pretrained(addr[0], torch_dtype=torch.float16) + else: + return ControlNetModel.from_pretrained(addr[0], subfolder=addr[1], torch_dtype=torch.float16) + else: + return load_controlnet_from_file(addr[1],torch_dtype=torch.float16) + else: + raise ValueError(f"unknown controlnet type {type_str}") + else: + + if type_str in controlnet_address_table_sdxl: + addr = controlnet_address_table_sdxl[type_str] + if len(addr) == 1: + return ControlNetModel.from_pretrained(addr[0], torch_dtype=torch.float16) + else: + return ControlNetModel.from_pretrained(addr[0], subfolder=addr[1], torch_dtype=torch.float16) + elif type_str in lllite_address_table_sdxl: + addr = lllite_address_table_sdxl[type_str] + model_path = data_dir.joinpath(addr[0]) + return load_controlnet_lllite(model_path, pipe, torch_dtype=torch.float16) + else: + raise ValueError(f"unknown controlnet type {type_str}") + + + +default_preprocessor_table={ + "controlnet_lineart_anime":"lineart_anime", + "controlnet_openpose": "openpose_full" if onnxruntime_installed==False else "dwpose", + "controlnet_softedge":"softedge_hedsafe", + "controlnet_shuffle":"shuffle", + "controlnet_depth":"depth_midas", + "controlnet_canny":"canny", + "controlnet_lineart":"lineart_realistic", + "controlnet_mlsd":"mlsd", + "controlnet_normalbae":"normal_bae", + "controlnet_scribble":"scribble_pidsafe", + "controlnet_seg":"upernet_seg", + "controlnet_mediapipe_face":"mediapipe_face", + "qr_code_monster_v1":"depth_midas", + "qr_code_monster_v2":"depth_midas", +} + +def create_preprocessor_from_name(pre_type): + if pre_type == "dwpose": + prepare_dwpose() + return DWposeDetector() + elif pre_type == "upernet_seg": + return SegPreProcessor() + elif pre_type == "blur": + return BlurPreProcessor() + elif pre_type == "tile_resample": + return TileResamplePreProcessor() + elif pre_type == "none": + return NullPreProcessor() + elif pre_type in MODELS: + return ControlnetPreProcessor(pre_type) + else: + raise ValueError(f"unknown controlnet preprocessor type {pre_type}") + + +def create_default_preprocessor(type_str): + if type_str in default_preprocessor_table: + pre_type = default_preprocessor_table[type_str] + else: + pre_type = "none" + + return create_preprocessor_from_name(pre_type) + + +def get_preprocessor(type_str, device_str, preprocessor_map): + if type_str not in controlnet_preprocessor: + if preprocessor_map: + controlnet_preprocessor[type_str] = create_preprocessor_from_name(preprocessor_map["type"]) + + if type_str not in controlnet_preprocessor: + controlnet_preprocessor[type_str] = create_default_preprocessor(type_str) + + if hasattr(controlnet_preprocessor[type_str], "processor"): + if hasattr(controlnet_preprocessor[type_str].processor, "to"): + if device_str: + controlnet_preprocessor[type_str].processor.to(device_str) + elif hasattr(controlnet_preprocessor[type_str], "to"): + if device_str: + controlnet_preprocessor[type_str].to(device_str) + + + return controlnet_preprocessor[type_str] + +def clear_controlnet_preprocessor(type_str = None): + global controlnet_preprocessor + if type_str == None: + for t in controlnet_preprocessor: + controlnet_preprocessor[t] = None + controlnet_preprocessor={} + torch.cuda.empty_cache() + else: + controlnet_preprocessor[type_str] = None + torch.cuda.empty_cache() + + +def get_preprocessed_img(type_str, img, use_preprocessor, device_str, preprocessor_map): + if use_preprocessor: + param = {} + if preprocessor_map: + param = preprocessor_map["param"] if "param" in preprocessor_map else {} + return get_preprocessor(type_str, device_str, preprocessor_map)(img, **param) + else: + return img + + +def create_pipeline_sdxl( + base_model: Union[str, PathLike] = default_base_path, + model_config: ModelConfig = ..., + infer_config: InferenceConfig = ..., + use_xformers: bool = True, + video_length: int = 16, + motion_module_path = ..., +): + from animatediff.pipelines.sdxl_animation import AnimationPipeline + from animatediff.sdxl_models.unet import UNet2DConditionModel + + logger.info("Loading tokenizer...") + tokenizer: CLIPTokenizer = CLIPTokenizer.from_pretrained(base_model, subfolder="tokenizer") + logger.info("Loading text encoder...") + text_encoder: CLIPTextModel = CLIPTextModel.from_pretrained(base_model, subfolder="text_encoder", torch_dtype=torch.float16) + logger.info("Loading VAE...") + vae: AutoencoderKL = AutoencoderKL.from_single_file('https://huggingface.co/chaowenguo/pal/blob/main/vae-ft-mse-840000-ema-pruned.safetensors') + logger.info("Loading tokenizer two...") + tokenizer_two = CLIPTokenizer.from_pretrained(base_model, subfolder="tokenizer_2") + logger.info("Loading text encoder two...") + text_encoder_two = CLIPTextModelWithProjection.from_pretrained(base_model, subfolder="text_encoder_2", torch_dtype=torch.float16) + + + logger.info("Loading UNet...") + unet: UNet2DConditionModel = UNet2DConditionModel.from_pretrained_2d( + pretrained_model_path=base_model, + motion_module_path=motion_module_path, + subfolder="unet", + unet_additional_kwargs=infer_config.unet_additional_kwargs, + ) + + # set up scheduler + sched_kwargs = infer_config.noise_scheduler_kwargs + scheduler = get_scheduler(model_config.scheduler, sched_kwargs) + logger.info(f'Using scheduler "{model_config.scheduler}" ({scheduler.__class__.__name__})') + + if model_config.gradual_latent_hires_fix_map: + if "enable" in model_config.gradual_latent_hires_fix_map: + if model_config.gradual_latent_hires_fix_map["enable"]: + if model_config.scheduler not in (DiffusionScheduler.euler_a, DiffusionScheduler.lcm): + logger.warn("gradual_latent_hires_fix enable") + logger.warn(f"{model_config.scheduler=}") + logger.warn("If you are forced to exit with an error, change to euler_a or lcm") + + + + # Load the checkpoint weights into the pipeline + if model_config.path is not None: + model_path = data_dir.joinpath(model_config.path) + logger.info(f"Loading weights from {model_path}") + if model_path.is_file(): + logger.debug("Loading from single checkpoint file") + unet_state_dict, tenc_state_dict, tenc2_state_dict, vae_state_dict = get_checkpoint_weights_sdxl(model_path) + elif model_path.is_dir(): + logger.debug("Loading from Diffusers model directory") + temp_pipeline = StableDiffusionXLPipeline.from_pretrained(model_path) + unet_state_dict, tenc_state_dict, tenc2_state_dict, vae_state_dict = ( + temp_pipeline.unet.state_dict(), + temp_pipeline.text_encoder.state_dict(), + temp_pipeline.text_encoder_2.state_dict(), + temp_pipeline.vae.state_dict(), + ) + del temp_pipeline + else: + raise FileNotFoundError(f"model_path {model_path} is not a file or directory") + + # Load into the unet, TE, and VAE + logger.info("Merging weights into UNet...") + _, unet_unex = unet.load_state_dict(unet_state_dict, strict=False) + if len(unet_unex) > 0: + raise ValueError(f"UNet has unexpected keys: {unet_unex}") + tenc_missing, _ = text_encoder.load_state_dict(tenc_state_dict, strict=False) + if len(tenc_missing) > 0: + raise ValueError(f"TextEncoder has missing keys: {tenc_missing}") + tenc2_missing, _ = text_encoder_two.load_state_dict(tenc2_state_dict, strict=False) + if len(tenc2_missing) > 0: + raise ValueError(f"TextEncoder2 has missing keys: {tenc2_missing}") + vae_missing, _ = vae.load_state_dict(vae_state_dict, strict=False) + if len(vae_missing) > 0: + raise ValueError(f"VAE has missing keys: {vae_missing}") + else: + logger.info("Using base model weights (no checkpoint/LoRA)") + + unet.to(torch.float16) + text_encoder.to(torch.float16) + text_encoder_two.to(torch.float16) + + del unet_state_dict + del tenc_state_dict + del tenc2_state_dict + del vae_state_dict + + # enable xformers if available + if use_xformers: + logger.info("Enabling xformers memory-efficient attention") + unet.enable_xformers_memory_efficient_attention() + + # motion lora + for l in model_config.motion_lora_map: + lora_path = data_dir.joinpath(l) + logger.info(f"loading motion lora {lora_path=}") + if lora_path.is_file(): + logger.info(f"Loading motion lora {lora_path}") + logger.info(f"alpha = {model_config.motion_lora_map[l]}") + load_motion_lora(unet, lora_path, alpha=model_config.motion_lora_map[l]) + else: + raise ValueError(f"{lora_path=} not found") + + logger.info("Creating AnimationPipeline...") + pipeline = AnimationPipeline( + vae=vae, + text_encoder=text_encoder, + text_encoder_2=text_encoder_two, + tokenizer=tokenizer, + tokenizer_2=tokenizer_two, + unet=unet, + scheduler=scheduler, + controlnet_map=None, + ) + + del vae + del text_encoder + del text_encoder_two + del tokenizer + del tokenizer_two + del unet + + torch.cuda.empty_cache() + + pipeline.lcm = None + if model_config.lcm_map: + if model_config.lcm_map["enable"]: + prepare_lcm_lora() + load_lcm_lora(pipeline, model_config.lcm_map, is_sdxl=True) + + load_lora_map(pipeline, model_config.lora_map, video_length, is_sdxl=True) + + pipeline.unet = pipeline.unet.half() + pipeline.text_encoder = pipeline.text_encoder.half() + pipeline.text_encoder_2 = pipeline.text_encoder_2.half() + + # Load TI embeddings + pipeline.text_encoder = pipeline.text_encoder.to("cuda") + pipeline.text_encoder_2 = pipeline.text_encoder_2.to("cuda") + + load_text_embeddings(pipeline, is_sdxl=True) + + pipeline.text_encoder = pipeline.text_encoder.to("cpu") + pipeline.text_encoder_2 = pipeline.text_encoder_2.to("cpu") + + return pipeline + + +def create_pipeline( + base_model: Union[str, PathLike] = default_base_path, + model_config: ModelConfig = ..., + infer_config: InferenceConfig = ..., + use_xformers: bool = True, + video_length: int = 16, + is_sdxl:bool = False, +) -> DiffusionPipeline: + """Create an AnimationPipeline from a pretrained model. + Uses the base_model argument to load or download the pretrained reference pipeline model.""" + + # make sure motion_module is a Path and exists + logger.info("Checking motion module...") + motion_module = data_dir.joinpath(model_config.motion_module) + if not (motion_module.exists() and motion_module.is_file()): + prepare_motion_module() + if not (motion_module.exists() and motion_module.is_file()): + # check for safetensors version + motion_module = motion_module.with_suffix(".safetensors") + if not (motion_module.exists() and motion_module.is_file()): + # download from HuggingFace Hub if not found + ensure_motion_modules() + if not (motion_module.exists() and motion_module.is_file()): + # this should never happen, but just in case... + raise FileNotFoundError(f"Motion module {motion_module} does not exist or is not a file!") + + if is_sdxl: + return create_pipeline_sdxl( + base_model=base_model, + model_config=model_config, + infer_config=infer_config, + use_xformers=use_xformers, + video_length=video_length, + motion_module_path=motion_module, + ) + + logger.info("Loading tokenizer...") + tokenizer: CLIPTokenizer = CLIPTokenizer.from_pretrained(base_model, subfolder="tokenizer") + logger.info("Loading text encoder...") + text_encoder: CLIPSkipTextModel = CLIPSkipTextModel.from_pretrained(base_model, subfolder="text_encoder") + logger.info("Loading VAE...") + vae: AutoencoderKL = AutoencoderKL.from_single_file('https://huggingface.co/chaowenguo/pal/blob/main/vae-ft-mse-840000-ema-pruned.safetensors') + logger.info("Loading UNet...") + unet: UNet3DConditionModel = UNet3DConditionModel.from_pretrained_2d( + pretrained_model_path=base_model, + motion_module_path=motion_module, + subfolder="unet", + unet_additional_kwargs=infer_config.unet_additional_kwargs, + ) + feature_extractor = CLIPImageProcessor.from_pretrained(base_model, subfolder="feature_extractor") + + # set up scheduler + if model_config.gradual_latent_hires_fix_map: + if "enable" in model_config.gradual_latent_hires_fix_map: + if model_config.gradual_latent_hires_fix_map["enable"]: + if model_config.scheduler not in (DiffusionScheduler.euler_a, DiffusionScheduler.lcm): + logger.warn("gradual_latent_hires_fix enable") + logger.warn(f"{model_config.scheduler=}") + logger.warn("If you are forced to exit with an error, change to euler_a or lcm") + + sched_kwargs = infer_config.noise_scheduler_kwargs + scheduler = get_scheduler(model_config.scheduler, sched_kwargs) + logger.info(f'Using scheduler "{model_config.scheduler}" ({scheduler.__class__.__name__})') + + # Load the checkpoint weights into the pipeline + if model_config.path is not None: + model_path = data_dir.joinpath(model_config.path) + logger.info(f"Loading weights from {model_path}") + if model_path.is_file(): + logger.debug("Loading from single checkpoint file") + unet_state_dict, tenc_state_dict, vae_state_dict = get_checkpoint_weights(model_path) + elif model_path.is_dir(): + logger.debug("Loading from Diffusers model directory") + temp_pipeline = StableDiffusionPipeline.from_pretrained(model_path) + unet_state_dict, tenc_state_dict, vae_state_dict = ( + temp_pipeline.unet.state_dict(), + temp_pipeline.text_encoder.state_dict(), + temp_pipeline.vae.state_dict(), + ) + del temp_pipeline + else: + raise FileNotFoundError(f"model_path {model_path} is not a file or directory") + + # Load into the unet, TE, and VAE + logger.info("Merging weights into UNet...") + _, unet_unex = unet.load_state_dict(unet_state_dict, strict=False) + if len(unet_unex) > 0: + raise ValueError(f"UNet has unexpected keys: {unet_unex}") + tenc_missing, _ = text_encoder.load_state_dict(tenc_state_dict, strict=False) + if len(tenc_missing) > 0: + raise ValueError(f"TextEncoder has missing keys: {tenc_missing}") + vae_missing, _ = vae.load_state_dict(vae_state_dict, strict=False) + if len(vae_missing) > 0: + raise ValueError(f"VAE has missing keys: {vae_missing}") + else: + logger.info("Using base model weights (no checkpoint/LoRA)") + + + # enable xformers if available + if use_xformers: + logger.info("Enabling xformers memory-efficient attention") + unet.enable_xformers_memory_efficient_attention() + + if False: + # lora + for l in model_config.lora_map: + lora_path = data_dir.joinpath(l) + if lora_path.is_file(): + logger.info(f"Loading lora {lora_path}") + logger.info(f"alpha = {model_config.lora_map[l]}") + load_safetensors_lora(text_encoder, unet, lora_path, alpha=model_config.lora_map[l]) + + # motion lora + for l in model_config.motion_lora_map: + lora_path = data_dir.joinpath(l) + logger.info(f"loading motion lora {lora_path=}") + if lora_path.is_file(): + logger.info(f"Loading motion lora {lora_path}") + logger.info(f"alpha = {model_config.motion_lora_map[l]}") + load_motion_lora(unet, lora_path, alpha=model_config.motion_lora_map[l]) + else: + raise ValueError(f"{lora_path=} not found") + + logger.info("Creating AnimationPipeline...") + pipeline = AnimationPipeline( + vae=vae, + text_encoder=text_encoder, + tokenizer=tokenizer, + unet=unet, + scheduler=scheduler, + feature_extractor=feature_extractor, + controlnet_map=None, + ) + + pipeline.lcm = None + if model_config.lcm_map: + if model_config.lcm_map["enable"]: + prepare_lcm_lora() + load_lcm_lora(pipeline, model_config.lcm_map, is_sdxl=False) + + load_lora_map(pipeline, model_config.lora_map, video_length) + + # Load TI embeddings + pipeline.unet = pipeline.unet.half() + pipeline.text_encoder = pipeline.text_encoder.half() + + pipeline.text_encoder = pipeline.text_encoder.to("cuda") + + load_text_embeddings(pipeline) + + pipeline.text_encoder = pipeline.text_encoder.to("cpu") + + return pipeline + +def load_controlnet_models(pipe: DiffusionPipeline, model_config: ModelConfig = ..., is_sdxl:bool = False): + # controlnet + + if is_sdxl: + prepare_lllite() + + controlnet_map={} + if model_config.controlnet_map: + c_image_dir = data_dir.joinpath( model_config.controlnet_map["input_image_dir"] ) + + for c in model_config.controlnet_map: + item = model_config.controlnet_map[c] + if type(item) is dict: + if item["enable"] == True: + if is_valid_controlnet_type(c, is_sdxl): + img_dir = c_image_dir.joinpath( c ) + cond_imgs = sorted(glob.glob( os.path.join(img_dir, "[0-9]*.png"), recursive=False)) + if len(cond_imgs) > 0: + logger.info(f"loading {c=} model") + controlnet_map[c] = create_controlnet_model(pipe, c , is_sdxl) + else: + logger.info(f"invalid controlnet type for {'sdxl' if is_sdxl else 'sd15'} : {c}") + + if not controlnet_map: + controlnet_map = None + + pipe.controlnet_map = controlnet_map + +def unload_controlnet_models(pipe: AnimationPipeline): + from animatediff.utils.util import show_gpu + + if pipe.controlnet_map: + for c in pipe.controlnet_map: + controlnet = pipe.controlnet_map[c] + if isinstance(controlnet, ControlNetLLLite): + controlnet.unapply_to() + del controlnet + + #show_gpu("before uload controlnet") + pipe.controlnet_map = None + torch.cuda.empty_cache() + #show_gpu("after unload controlnet") + + +def create_us_pipeline( + model_config: ModelConfig = ..., + infer_config: InferenceConfig = ..., + use_xformers: bool = True, + use_controlnet_ref: bool = False, + use_controlnet_tile: bool = False, + use_controlnet_line_anime: bool = False, + use_controlnet_ip2p: bool = False, +) -> DiffusionPipeline: + + # set up scheduler + sched_kwargs = infer_config.noise_scheduler_kwargs + scheduler = get_scheduler(model_config.scheduler, sched_kwargs) + logger.info(f'Using scheduler "{model_config.scheduler}" ({scheduler.__class__.__name__})') + + controlnet = [] + if use_controlnet_tile: + controlnet.append( ControlNetModel.from_pretrained('lllyasviel/control_v11f1e_sd15_tile') ) + if use_controlnet_line_anime: + controlnet.append( ControlNetModel.from_pretrained('lllyasviel/control_v11p_sd15s2_lineart_anime') ) + if use_controlnet_ip2p: + controlnet.append( ControlNetModel.from_pretrained('lllyasviel/control_v11e_sd15_ip2p') ) + + if len(controlnet) == 1: + controlnet = controlnet[0] + elif len(controlnet) == 0: + controlnet = None + + # Load the checkpoint weights into the pipeline + pipeline:DiffusionPipeline + + if model_config.path is not None: + model_path = data_dir.joinpath(model_config.path) + logger.info(f"Loading weights from {model_path}") + if model_path.is_file(): + + def is_empty_dir(path): + import os + return len(os.listdir(path)) == 0 + + save_path = data_dir.joinpath("models/huggingface/" + model_path.stem + "_" + str(model_path.stat().st_size)) + save_path.mkdir(exist_ok=True) + if save_path.is_dir() and is_empty_dir(save_path): + # StableDiffusionControlNetImg2ImgPipeline.from_single_file does not exist in version 18.2 + logger.debug("Loading from single checkpoint file") + tmp_pipeline = StableDiffusionPipeline.from_single_file( + pretrained_model_link_or_path=str(model_path.absolute()) + ) + tmp_pipeline.save_pretrained(save_path, safe_serialization=True) + del tmp_pipeline + + if use_controlnet_ref: + pipeline = StableDiffusionControlNetImg2ImgReferencePipeline.from_pretrained( + save_path, + controlnet=controlnet, + local_files_only=False, + load_safety_checker=False, + safety_checker=None, + ) + else: + pipeline = StableDiffusionControlNetImg2ImgPipeline.from_pretrained( + save_path, + controlnet=controlnet, + local_files_only=False, + load_safety_checker=False, + safety_checker=None, + ) + + elif model_path.is_dir(): + logger.debug("Loading from Diffusers model directory") + if use_controlnet_ref: + pipeline = StableDiffusionControlNetImg2ImgReferencePipeline.from_pretrained( + model_path, + controlnet=controlnet, + local_files_only=True, + load_safety_checker=False, + safety_checker=None, + ) + else: + pipeline = StableDiffusionControlNetImg2ImgPipeline.from_pretrained( + model_path, + controlnet=controlnet, + local_files_only=True, + load_safety_checker=False, + safety_checker=None, + ) + else: + raise FileNotFoundError(f"model_path {model_path} is not a file or directory") + else: + raise ValueError("model_config.path is invalid") + + pipeline.scheduler = scheduler + + # enable xformers if available + if use_xformers: + logger.info("Enabling xformers memory-efficient attention") + pipeline.enable_xformers_memory_efficient_attention() + + # lora + for l in model_config.lora_map: + lora_path = data_dir.joinpath(l) + if lora_path.is_file(): + alpha = model_config.lora_map[l] + if isinstance(alpha, dict): + alpha = 0.75 + + logger.info(f"Loading lora {lora_path}") + logger.info(f"alpha = {alpha}") + load_safetensors_lora2(pipeline.text_encoder, pipeline.unet, lora_path, alpha=alpha,is_animatediff=False) + + # Load TI embeddings + pipeline.unet = pipeline.unet.half() + pipeline.text_encoder = pipeline.text_encoder.half() + + pipeline.text_encoder = pipeline.text_encoder.to("cuda") + + load_text_embeddings(pipeline) + + pipeline.text_encoder = pipeline.text_encoder.to("cpu") + + return pipeline + + +def seed_everything(seed): + import random + + import numpy as np + torch.manual_seed(seed) + torch.cuda.manual_seed_all(seed) + np.random.seed(seed % (2**32)) + random.seed(seed) + +def controlnet_preprocess( + controlnet_map: Dict[str, Any] = None, + width: int = 512, + height: int = 512, + duration: int = 16, + out_dir: PathLike = ..., + device_str:str=None, + is_sdxl:bool = False, + ): + + if not controlnet_map: + return None, None, None, None + + out_dir = Path(out_dir) # ensure out_dir is a Path + + # { 0 : { "type_str" : IMAGE, "type_str2" : IMAGE } } + controlnet_image_map={} + + controlnet_type_map={} + + c_image_dir = data_dir.joinpath( controlnet_map["input_image_dir"] ) + save_detectmap = controlnet_map["save_detectmap"] if "save_detectmap" in controlnet_map else True + + preprocess_on_gpu = controlnet_map["preprocess_on_gpu"] if "preprocess_on_gpu" in controlnet_map else True + device_str = device_str if preprocess_on_gpu else None + + for c in controlnet_map: + if c == "controlnet_ref": + continue + + item = controlnet_map[c] + + processed = False + + if type(item) is dict: + if item["enable"] == True: + + if is_valid_controlnet_type(c, is_sdxl): + preprocessor_map = item["preprocessor"] if "preprocessor" in item else {} + + img_dir = c_image_dir.joinpath( c ) + cond_imgs = sorted(glob.glob( os.path.join(img_dir, "[0-9]*.png"), recursive=False)) + if len(cond_imgs) > 0: + + controlnet_type_map[c] = { + "controlnet_conditioning_scale" : item["controlnet_conditioning_scale"], + "control_guidance_start" : item["control_guidance_start"], + "control_guidance_end" : item["control_guidance_end"], + "control_scale_list" : item["control_scale_list"], + "guess_mode" : item["guess_mode"] if "guess_mode" in item else False, + "control_region_list" : item["control_region_list"] if "control_region_list" in item else [] + } + + use_preprocessor = item["use_preprocessor"] if "use_preprocessor" in item else True + + for img_path in tqdm(cond_imgs, desc=f"Preprocessing images ({c})"): + frame_no = int(Path(img_path).stem) + if frame_no < duration: + if frame_no not in controlnet_image_map: + controlnet_image_map[frame_no] = {} + controlnet_image_map[frame_no][c] = get_preprocessed_img( c, get_resized_image2(img_path, 512) , use_preprocessor, device_str, preprocessor_map) + processed = True + else: + logger.info(f"invalid controlnet type for {'sdxl' if is_sdxl else 'sd15'} : {c}") + + + if save_detectmap and processed: + det_dir = out_dir.joinpath(f"{0:02d}_detectmap/{c}") + det_dir.mkdir(parents=True, exist_ok=True) + for frame_no in tqdm(controlnet_image_map, desc=f"Saving Preprocessed images ({c})"): + save_path = det_dir.joinpath(f"{frame_no:08d}.png") + if c in controlnet_image_map[frame_no]: + controlnet_image_map[frame_no][c].save(save_path) + + clear_controlnet_preprocessor(c) + + clear_controlnet_preprocessor() + + controlnet_ref_map = None + + if "controlnet_ref" in controlnet_map: + r = controlnet_map["controlnet_ref"] + if r["enable"] == True: + org_name = data_dir.joinpath( r["ref_image"]).stem +# ref_image = get_resized_image( data_dir.joinpath( r["ref_image"] ) , width, height) + ref_image = get_resized_image2( data_dir.joinpath( r["ref_image"] ) , 512) + + if ref_image is not None: + controlnet_ref_map = { + "ref_image" : ref_image, + "style_fidelity" : r["style_fidelity"], + "attention_auto_machine_weight" : r["attention_auto_machine_weight"], + "gn_auto_machine_weight" : r["gn_auto_machine_weight"], + "reference_attn" : r["reference_attn"], + "reference_adain" : r["reference_adain"], + "scale_pattern" : r["scale_pattern"] + } + + if save_detectmap: + det_dir = out_dir.joinpath(f"{0:02d}_detectmap/controlnet_ref") + det_dir.mkdir(parents=True, exist_ok=True) + save_path = det_dir.joinpath(f"{org_name}.png") + ref_image.save(save_path) + + controlnet_no_shrink = ["controlnet_tile","animatediff_controlnet","controlnet_canny","controlnet_normalbae","controlnet_depth","controlnet_lineart","controlnet_lineart_anime","controlnet_scribble","controlnet_seg","controlnet_softedge","controlnet_mlsd"] + if "no_shrink_list" in controlnet_map: + controlnet_no_shrink = controlnet_map["no_shrink_list"] + + return controlnet_image_map, controlnet_type_map, controlnet_ref_map, controlnet_no_shrink + + +def ip_adapter_preprocess( + ip_adapter_config_map: Dict[str, Any] = None, + width: int = 512, + height: int = 512, + duration: int = 16, + out_dir: PathLike = ..., + is_sdxl: bool = False, + ): + + ip_adapter_map={} + + processed = False + + if ip_adapter_config_map: + if ip_adapter_config_map["enable"] == True: + resized_to_square = ip_adapter_config_map["resized_to_square"] if "resized_to_square" in ip_adapter_config_map else False + image_dir = data_dir.joinpath( ip_adapter_config_map["input_image_dir"] ) + imgs = sorted(chain.from_iterable([glob.glob(os.path.join(image_dir, f"[0-9]*{ext}")) for ext in IMG_EXTENSIONS])) + if len(imgs) > 0: + prepare_ip_adapter_sdxl() if is_sdxl else prepare_ip_adapter() + ip_adapter_map["images"] = {} + for img_path in tqdm(imgs, desc=f"Preprocessing images (ip_adapter)"): + frame_no = int(Path(img_path).stem) + if frame_no < duration: + if resized_to_square: + ip_adapter_map["images"][frame_no] = get_resized_image(img_path, 256, 256) + else: + ip_adapter_map["images"][frame_no] = get_resized_image2(img_path, 256) + processed = True + + if processed: + ip_adapter_config_map["prompt_fixed_ratio"] = max(min(1.0, ip_adapter_config_map["prompt_fixed_ratio"]),0) + + prompt_fixed_ratio = ip_adapter_config_map["prompt_fixed_ratio"] + prompt_map = ip_adapter_map["images"] + prompt_map = dict(sorted(prompt_map.items())) + key_list = list(prompt_map.keys()) + for k0,k1 in zip(key_list,key_list[1:]+[duration]): + k05 = k0 + round((k1-k0) * prompt_fixed_ratio) + if k05 == k1: + k05 -= 1 + if k05 != k0: + prompt_map[k05] = prompt_map[k0] + ip_adapter_map["images"] = prompt_map + + if (ip_adapter_config_map["save_input_image"] == True) and processed: + det_dir = out_dir.joinpath(f"{0:02d}_ip_adapter/") + det_dir.mkdir(parents=True, exist_ok=True) + for frame_no in tqdm(ip_adapter_map["images"], desc=f"Saving Preprocessed images (ip_adapter)"): + save_path = det_dir.joinpath(f"{frame_no:08d}.png") + ip_adapter_map["images"][frame_no].save(save_path) + + return ip_adapter_map if processed else None + +def prompt_preprocess( + prompt_config_map: Dict[str, Any], + head_prompt: str, + tail_prompt: str, + prompt_fixed_ratio: float, + video_length: int, +): + prompt_map = {} + for k in prompt_config_map.keys(): + if int(k) < video_length: + pr = prompt_config_map[k] + if head_prompt: + pr = head_prompt + "," + pr + if tail_prompt: + pr = pr + "," + tail_prompt + + prompt_map[int(k)]=pr + + prompt_map = dict(sorted(prompt_map.items())) + key_list = list(prompt_map.keys()) + for k0,k1 in zip(key_list,key_list[1:]+[video_length]): + k05 = k0 + round((k1-k0) * prompt_fixed_ratio) + if k05 == k1: + k05 -= 1 + if k05 != k0: + prompt_map[k05] = prompt_map[k0] + + return prompt_map + + +def region_preprocess( + model_config: ModelConfig = ..., + width: int = 512, + height: int = 512, + duration: int = 16, + out_dir: PathLike = ..., + is_init_img_exist: bool = False, + is_sdxl:bool = False, + ): + + is_bg_init_img = False + if is_init_img_exist: + if model_config.region_map: + if "background" in model_config.region_map: + is_bg_init_img = model_config.region_map["background"]["is_init_img"] + + + region_condi_list=[] + region2index={} + + condi_index = 0 + + prev_ip_map = None + + if not is_bg_init_img: + ip_map = ip_adapter_preprocess( + model_config.ip_adapter_map, + width, + height, + duration, + out_dir, + is_sdxl + ) + + if ip_map: + prev_ip_map = ip_map + + condition_map = { + "prompt_map": prompt_preprocess( + model_config.prompt_map, + model_config.head_prompt, + model_config.tail_prompt, + model_config.prompt_fixed_ratio, + duration + ), + "ip_adapter_map": ip_map + } + + region_condi_list.append( condition_map ) + + bg_src = condi_index + condi_index += 1 + else: + bg_src = -1 + + region_list=[ + { + "mask_images": None, + "src" : bg_src, + "crop_generation_rate" : 0 + } + ] + region2index["background"]=bg_src + + if model_config.region_map: + for r in model_config.region_map: + if r == "background": + continue + if model_config.region_map[r]["enable"] != True: + continue + region_dir = out_dir.joinpath(f"region_{int(r):05d}/") + region_dir.mkdir(parents=True, exist_ok=True) + + mask_map = mask_preprocess( + model_config.region_map[r], + width, + height, + duration, + region_dir + ) + + if not mask_map: + continue + + if model_config.region_map[r]["is_init_img"] == False: + ip_map = ip_adapter_preprocess( + model_config.region_map[r]["condition"]["ip_adapter_map"], + width, + height, + duration, + region_dir, + is_sdxl + ) + + if ip_map: + prev_ip_map = ip_map + + condition_map={ + "prompt_map": prompt_preprocess( + model_config.region_map[r]["condition"]["prompt_map"], + model_config.region_map[r]["condition"]["head_prompt"], + model_config.region_map[r]["condition"]["tail_prompt"], + model_config.region_map[r]["condition"]["prompt_fixed_ratio"], + duration + ), + "ip_adapter_map": ip_map + } + + region_condi_list.append( condition_map ) + + src = condi_index + condi_index += 1 + else: + if is_init_img_exist == False: + logger.warn("'is_init_img' : true / BUT init_img is not exist -> ignore region") + continue + src = -1 + + region_list.append( + { + "mask_images": mask_map, + "src" : src, + "crop_generation_rate" : model_config.region_map[r]["crop_generation_rate"] if "crop_generation_rate" in model_config.region_map[r] else 0 + } + ) + region2index[r]=src + + ip_adapter_config_map = None + + if prev_ip_map is not None: + ip_adapter_config_map={} + ip_adapter_config_map["scale"] = model_config.ip_adapter_map["scale"] + ip_adapter_config_map["is_plus"] = model_config.ip_adapter_map["is_plus"] + ip_adapter_config_map["is_plus_face"] = model_config.ip_adapter_map["is_plus_face"] if "is_plus_face" in model_config.ip_adapter_map else False + ip_adapter_config_map["is_light"] = model_config.ip_adapter_map["is_light"] if "is_light" in model_config.ip_adapter_map else False + ip_adapter_config_map["is_full_face"] = model_config.ip_adapter_map["is_full_face"] if "is_full_face" in model_config.ip_adapter_map else False + for c in region_condi_list: + if c["ip_adapter_map"] == None: + logger.info(f"fill map") + c["ip_adapter_map"] = prev_ip_map + + + + + #for c in region_condi_list: + # logger.info(f"{c['prompt_map']=}") + + + if not region_condi_list: + raise ValueError("erro! There is not a single valid region") + + return region_condi_list, region_list, ip_adapter_config_map, region2index + +def img2img_preprocess( + img2img_config_map: Dict[str, Any] = None, + width: int = 512, + height: int = 512, + duration: int = 16, + out_dir: PathLike = ..., + ): + + img2img_map={} + + processed = False + + if img2img_config_map: + if img2img_config_map["enable"] == True: + image_dir = data_dir.joinpath( img2img_config_map["init_img_dir"] ) + imgs = sorted(glob.glob( os.path.join(image_dir, "[0-9]*.png"), recursive=False)) + if len(imgs) > 0: + img2img_map["images"] = {} + img2img_map["denoising_strength"] = img2img_config_map["denoising_strength"] + for img_path in tqdm(imgs, desc=f"Preprocessing images (img2img)"): + frame_no = int(Path(img_path).stem) + if frame_no < duration: + img2img_map["images"][frame_no] = get_resized_image(img_path, width, height) + processed = True + + if (img2img_config_map["save_init_image"] == True) and processed: + det_dir = out_dir.joinpath(f"{0:02d}_img2img_init_img/") + det_dir.mkdir(parents=True, exist_ok=True) + for frame_no in tqdm(img2img_map["images"], desc=f"Saving Preprocessed images (img2img)"): + save_path = det_dir.joinpath(f"{frame_no:08d}.png") + img2img_map["images"][frame_no].save(save_path) + + return img2img_map if processed else None + +def mask_preprocess( + region_config_map: Dict[str, Any] = None, + width: int = 512, + height: int = 512, + duration: int = 16, + out_dir: PathLike = ..., + ): + + mask_map={} + + processed = False + size = None + mode = None + + if region_config_map: + image_dir = data_dir.joinpath( region_config_map["mask_dir"] ) + imgs = sorted(glob.glob( os.path.join(image_dir, "[0-9]*.png"), recursive=False)) + if len(imgs) > 0: + for img_path in tqdm(imgs, desc=f"Preprocessing images (mask)"): + frame_no = int(Path(img_path).stem) + if frame_no < duration: + mask_map[frame_no] = get_resized_image(img_path, width, height) + if size is None: + size = mask_map[frame_no].size + mode = mask_map[frame_no].mode + + processed = True + + if processed: + if 0 in mask_map: + prev_img = mask_map[0] + else: + prev_img = Image.new(mode, size, color=0) + + for i in range(duration): + if i in mask_map: + prev_img = mask_map[i] + else: + mask_map[i] = prev_img + + if (region_config_map["save_mask"] == True) and processed: + det_dir = out_dir.joinpath(f"mask/") + det_dir.mkdir(parents=True, exist_ok=True) + for frame_no in tqdm(mask_map, desc=f"Saving Preprocessed images (mask)"): + save_path = det_dir.joinpath(f"{frame_no:08d}.png") + mask_map[frame_no].save(save_path) + + return mask_map if processed else None + +def wild_card_conversion(model_config: ModelConfig = ...,): + from animatediff.utils.wild_card import replace_wild_card + + wild_card_dir = get_dir("wildcards") + for k in model_config.prompt_map.keys(): + model_config.prompt_map[k] = replace_wild_card(model_config.prompt_map[k], wild_card_dir) + + if model_config.head_prompt: + model_config.head_prompt = replace_wild_card(model_config.head_prompt, wild_card_dir) + if model_config.tail_prompt: + model_config.tail_prompt = replace_wild_card(model_config.tail_prompt, wild_card_dir) + + model_config.prompt_fixed_ratio = max(min(1.0, model_config.prompt_fixed_ratio),0) + + if model_config.region_map: + for r in model_config.region_map: + if r == "background": + continue + + if "condition" in model_config.region_map[r]: + c = model_config.region_map[r]["condition"] + for k in c["prompt_map"].keys(): + c["prompt_map"][k] = replace_wild_card(c["prompt_map"][k], wild_card_dir) + + if "head_prompt" in c: + c["head_prompt"] = replace_wild_card(c["head_prompt"], wild_card_dir) + if "tail_prompt" in c: + c["tail_prompt"] = replace_wild_card(c["tail_prompt"], wild_card_dir) + if "prompt_fixed_ratio" in c: + c["prompt_fixed_ratio"] = max(min(1.0, c["prompt_fixed_ratio"]),0) + +def save_output( + pipeline_output, + frame_dir:str, + out_file:str, + output_map : Dict[str,Any] = {}, + no_frames : bool = False, + save_frames=save_frames, + save_video=None, +): + + output_format = "gif" + output_fps = 8 + if output_map: + output_format = output_map["format"] if "format" in output_map else output_format + output_fps = output_map["fps"] if "fps" in output_map else output_fps + if output_format == "mp4": + output_format = "h264" + + if output_format == "gif": + out_file = out_file.with_suffix(".gif") + if no_frames is not True: + if save_frames: + save_frames(pipeline_output,frame_dir) + + # generate the output filename and save the video + if save_video: + save_video(pipeline_output, out_file, output_fps) + else: + pipeline_output[0].save( + fp=out_file, format="GIF", append_images=pipeline_output[1:], save_all=True, duration=(1 / output_fps * 1000), loop=0 + ) + + else: + + if save_frames: + save_frames(pipeline_output,frame_dir) + + from animatediff.rife.ffmpeg import (FfmpegEncoder, VideoCodec, + codec_extn) + + out_file = out_file.with_suffix( f".{codec_extn(output_format)}" ) + + logger.info("Creating ffmpeg encoder...") + encoder = FfmpegEncoder( + frames_dir=frame_dir, + out_file=out_file, + codec=output_format, + in_fps=output_fps, + out_fps=output_fps, + lossless=False, + param= output_map["encode_param"] if "encode_param" in output_map else {} + ) + logger.info("Encoding interpolated frames with ffmpeg...") + result = encoder.encode() + logger.debug(f"ffmpeg result: {result}") + + + +def run_inference( + pipeline: DiffusionPipeline, + n_prompt: str = ..., + seed: int = -1, + steps: int = 25, + guidance_scale: float = 7.5, + unet_batch_size: int = 1, + width: int = 512, + height: int = 512, + duration: int = 16, + idx: int = 0, + out_dir: PathLike = ..., + context_frames: int = -1, + context_stride: int = 3, + context_overlap: int = 4, + context_schedule: str = "uniform", + clip_skip: int = 1, + controlnet_map: Dict[str, Any] = None, + controlnet_image_map: Dict[str,Any] = None, + controlnet_type_map: Dict[str,Any] = None, + controlnet_ref_map: Dict[str,Any] = None, + controlnet_no_shrink:List[str]=None, + no_frames :bool = False, + img2img_map: Dict[str,Any] = None, + ip_adapter_config_map: Dict[str,Any] = None, + region_list: List[Any] = None, + region_condi_list: List[Any] = None, + output_map: Dict[str,Any] = None, + is_single_prompt_mode: bool = False, + is_sdxl:bool=False, + apply_lcm_lora:bool=False, + gradual_latent_map: Dict[str,Any] = None, +): + out_dir = Path(out_dir) # ensure out_dir is a Path + + # Trim and clean up the prompt for filename use + prompt_map = region_condi_list[0]["prompt_map"] + prompt_tags = [re_clean_prompt.sub("", tag).strip().replace(" ", "-") for tag in prompt_map[list(prompt_map.keys())[0]].split(",")] + prompt_str = "_".join((prompt_tags[:6]))[:50] + frame_dir = out_dir.joinpath(f"{idx:02d}-{seed}") + out_file = out_dir.joinpath(f"{idx:02d}_{seed}_{prompt_str}") + + def preview_callback(i: int, video: torch.Tensor, save_fn: Callable[[torch.Tensor], None], out_file: str) -> None: + save_fn(video, out_file=Path(f"{out_file}_preview@{i}")) + + save_fn = partial( + save_output, + frame_dir=frame_dir, + output_map=output_map, + no_frames=no_frames, + save_frames=partial(save_frames, show_progress=False), + save_video=save_video + ) + callback = partial(preview_callback, save_fn=save_fn, out_file=out_file) + + seed_everything(seed) + + logger.info(f"{len( region_condi_list )=}") + logger.info(f"{len( region_list )=}") + + pipeline_output = pipeline( + negative_prompt=n_prompt, + num_inference_steps=steps, + guidance_scale=guidance_scale, + unet_batch_size=unet_batch_size, + width=width, + height=height, + video_length=duration, + return_dict=False, + context_frames=context_frames, + context_stride=context_stride + 1, + context_overlap=context_overlap, + context_schedule=context_schedule, + clip_skip=clip_skip, + controlnet_type_map=controlnet_type_map, + controlnet_image_map=controlnet_image_map, + controlnet_ref_map=controlnet_ref_map, + controlnet_no_shrink=controlnet_no_shrink, + controlnet_max_samples_on_vram=controlnet_map["max_samples_on_vram"] if "max_samples_on_vram" in controlnet_map else 999, + controlnet_max_models_on_vram=controlnet_map["max_models_on_vram"] if "max_models_on_vram" in controlnet_map else 99, + controlnet_is_loop = controlnet_map["is_loop"] if "is_loop" in controlnet_map else True, + img2img_map=img2img_map, + ip_adapter_config_map=ip_adapter_config_map, + region_list=region_list, + region_condi_list=region_condi_list, + interpolation_factor=1, + is_single_prompt_mode=is_single_prompt_mode, + apply_lcm_lora=apply_lcm_lora, + gradual_latent_map=gradual_latent_map, + callback=callback, + callback_steps=output_map.get("preview_steps"), + ) + logger.info("Generation complete, saving...") + + save_fn(pipeline_output, out_file=out_file) + + logger.info(f"Saved sample to {out_file}") + return pipeline_output + + +def run_upscale( + org_imgs: List[str], + pipeline: DiffusionPipeline, + prompt_map: Dict[int, str] = None, + n_prompt: str = ..., + seed: int = -1, + steps: int = 25, + strength: float = 0.5, + guidance_scale: float = 7.5, + clip_skip: int = 1, + us_width: int = 512, + us_height: int = 512, + idx: int = 0, + out_dir: PathLike = ..., + upscale_config:Dict[str, Any]=None, + use_controlnet_ref: bool = False, + use_controlnet_tile: bool = False, + use_controlnet_line_anime: bool = False, + use_controlnet_ip2p: bool = False, + no_frames:bool = False, + output_map: Dict[str,Any] = None, +): + from animatediff.utils.lpw_stable_diffusion import lpw_encode_prompt + + pipeline.set_progress_bar_config(disable=True) + + images = get_resized_images(org_imgs, us_width, us_height) + + steps = steps if "steps" not in upscale_config else upscale_config["steps"] + scheduler = scheduler if "scheduler" not in upscale_config else upscale_config["scheduler"] + guidance_scale = guidance_scale if "guidance_scale" not in upscale_config else upscale_config["guidance_scale"] + clip_skip = clip_skip if "clip_skip" not in upscale_config else upscale_config["clip_skip"] + strength = strength if "strength" not in upscale_config else upscale_config["strength"] + + controlnet_conditioning_scale = [] + guess_mode = [] + control_guidance_start = [] + control_guidance_end = [] + + # for controlnet tile + if use_controlnet_tile: + controlnet_conditioning_scale.append(upscale_config["controlnet_tile"]["controlnet_conditioning_scale"]) + guess_mode.append(upscale_config["controlnet_tile"]["guess_mode"]) + control_guidance_start.append(upscale_config["controlnet_tile"]["control_guidance_start"]) + control_guidance_end.append(upscale_config["controlnet_tile"]["control_guidance_end"]) + + # for controlnet line_anime + if use_controlnet_line_anime: + controlnet_conditioning_scale.append(upscale_config["controlnet_line_anime"]["controlnet_conditioning_scale"]) + guess_mode.append(upscale_config["controlnet_line_anime"]["guess_mode"]) + control_guidance_start.append(upscale_config["controlnet_line_anime"]["control_guidance_start"]) + control_guidance_end.append(upscale_config["controlnet_line_anime"]["control_guidance_end"]) + + # for controlnet ip2p + if use_controlnet_ip2p: + controlnet_conditioning_scale.append(upscale_config["controlnet_ip2p"]["controlnet_conditioning_scale"]) + guess_mode.append(upscale_config["controlnet_ip2p"]["guess_mode"]) + control_guidance_start.append(upscale_config["controlnet_ip2p"]["control_guidance_start"]) + control_guidance_end.append(upscale_config["controlnet_ip2p"]["control_guidance_end"]) + + # for controlnet ref + ref_image = None + if use_controlnet_ref: + if not upscale_config["controlnet_ref"]["use_frame_as_ref_image"] and not upscale_config["controlnet_ref"]["use_1st_frame_as_ref_image"]: + ref_image = get_resized_images([ data_dir.joinpath( upscale_config["controlnet_ref"]["ref_image"] ) ], us_width, us_height)[0] + + + generator = torch.manual_seed(seed) + + seed_everything(seed) + + prompt_embeds_map = {} + prompt_map = dict(sorted(prompt_map.items())) + negative = None + + do_classifier_free_guidance=guidance_scale > 1.0 + + prompt_list = [prompt_map[key_frame] for key_frame in prompt_map.keys()] + + prompt_embeds,neg_embeds = lpw_encode_prompt( + pipe=pipeline, + prompt=prompt_list, + do_classifier_free_guidance=do_classifier_free_guidance, + negative_prompt=n_prompt, + ) + + if do_classifier_free_guidance: + negative = neg_embeds.chunk(neg_embeds.shape[0], 0) + positive = prompt_embeds.chunk(prompt_embeds.shape[0], 0) + else: + negative = [None] + positive = prompt_embeds.chunk(prompt_embeds.shape[0], 0) + + for i, key_frame in enumerate(prompt_map): + prompt_embeds_map[key_frame] = positive[i] + + key_first =list(prompt_map.keys())[0] + key_last =list(prompt_map.keys())[-1] + + def get_current_prompt_embeds( + center_frame: int = 0, + video_length : int = 0 + ): + + key_prev = key_last + key_next = key_first + + for p in prompt_map.keys(): + if p > center_frame: + key_next = p + break + key_prev = p + + dist_prev = center_frame - key_prev + if dist_prev < 0: + dist_prev += video_length + dist_next = key_next - center_frame + if dist_next < 0: + dist_next += video_length + + if key_prev == key_next or dist_prev + dist_next == 0: + return prompt_embeds_map[key_prev] + + rate = dist_prev / (dist_prev + dist_next) + + return get_tensor_interpolation_method()(prompt_embeds_map[key_prev],prompt_embeds_map[key_next], rate) + + + line_anime_processor = LineartAnimeDetector.from_pretrained("lllyasviel/Annotators") + + + out_images=[] + + logger.info(f"{use_controlnet_tile=}") + logger.info(f"{use_controlnet_line_anime=}") + logger.info(f"{use_controlnet_ip2p=}") + + logger.info(f"{controlnet_conditioning_scale=}") + logger.info(f"{guess_mode=}") + logger.info(f"{control_guidance_start=}") + logger.info(f"{control_guidance_end=}") + + + for i, org_image in enumerate(tqdm(images, desc=f"Upscaling...")): + + cur_positive = get_current_prompt_embeds(i, len(images)) + +# logger.info(f"w {condition_image.size[0]}") +# logger.info(f"h {condition_image.size[1]}") + condition_image = [] + + if use_controlnet_tile: + condition_image.append( org_image ) + if use_controlnet_line_anime: + condition_image.append( line_anime_processor(org_image) ) + if use_controlnet_ip2p: + condition_image.append( org_image ) + + if not use_controlnet_ref: + out_image = pipeline( + prompt_embeds=cur_positive, + negative_prompt_embeds=negative[0], + image=org_image, + control_image=condition_image, + width=org_image.size[0], + height=org_image.size[1], + strength=strength, + num_inference_steps=steps, + guidance_scale=guidance_scale, + generator=generator, + + controlnet_conditioning_scale= controlnet_conditioning_scale if len(controlnet_conditioning_scale) > 1 else controlnet_conditioning_scale[0], + guess_mode= guess_mode[0], + control_guidance_start= control_guidance_start if len(control_guidance_start) > 1 else control_guidance_start[0], + control_guidance_end= control_guidance_end if len(control_guidance_end) > 1 else control_guidance_end[0], + + ).images[0] + else: + + if upscale_config["controlnet_ref"]["use_1st_frame_as_ref_image"]: + if i == 0: + ref_image = org_image + elif upscale_config["controlnet_ref"]["use_frame_as_ref_image"]: + ref_image = org_image + + out_image = pipeline( + prompt_embeds=cur_positive, + negative_prompt_embeds=negative[0], + image=org_image, + control_image=condition_image, + width=org_image.size[0], + height=org_image.size[1], + strength=strength, + num_inference_steps=steps, + guidance_scale=guidance_scale, + generator=generator, + + controlnet_conditioning_scale= controlnet_conditioning_scale if len(controlnet_conditioning_scale) > 1 else controlnet_conditioning_scale[0], + guess_mode= guess_mode[0], + # control_guidance_start= control_guidance_start, + # control_guidance_end= control_guidance_end, + + ### for controlnet ref + ref_image=ref_image, + attention_auto_machine_weight = upscale_config["controlnet_ref"]["attention_auto_machine_weight"], + gn_auto_machine_weight = upscale_config["controlnet_ref"]["gn_auto_machine_weight"], + style_fidelity = upscale_config["controlnet_ref"]["style_fidelity"], + reference_attn= upscale_config["controlnet_ref"]["reference_attn"], + reference_adain= upscale_config["controlnet_ref"]["reference_adain"], + + ).images[0] + + out_images.append(out_image) + + # Trim and clean up the prompt for filename use + prompt_tags = [re_clean_prompt.sub("", tag).strip().replace(" ", "-") for tag in prompt_map[list(prompt_map.keys())[0]].split(",")] + prompt_str = "_".join((prompt_tags[:6]))[:50] + + # generate the output filename and save the video + out_file = out_dir.joinpath(f"{idx:02d}_{seed}_{prompt_str}") + + frame_dir = out_dir.joinpath(f"{idx:02d}-{seed}-upscaled") + + save_output( out_images, frame_dir, out_file, output_map, no_frames, save_imgs, None ) + + logger.info(f"Saved sample to {out_file}") + + return out_images diff --git a/animate/src/animatediff/ip_adapter/__init__.py b/animate/src/animatediff/ip_adapter/__init__.py new file mode 100644 index 0000000000000000000000000000000000000000..b364c9f385d2c528f743b4ce69ef33ec179250a0 --- /dev/null +++ b/animate/src/animatediff/ip_adapter/__init__.py @@ -0,0 +1,10 @@ +from .ip_adapter import (IPAdapter, IPAdapterFull, IPAdapterPlus, + IPAdapterPlusXL, IPAdapterXL) + +__all__ = [ + "IPAdapter", + "IPAdapterPlus", + "IPAdapterPlusXL", + "IPAdapterXL", + "IPAdapterFull", +] diff --git a/animate/src/animatediff/ip_adapter/attention_processor.py b/animate/src/animatediff/ip_adapter/attention_processor.py new file mode 100644 index 0000000000000000000000000000000000000000..4754be00e0e7cde21ff07fdc10199196ccf4812a --- /dev/null +++ b/animate/src/animatediff/ip_adapter/attention_processor.py @@ -0,0 +1,390 @@ +# modified from https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py +import torch +import torch.nn as nn +import torch.nn.functional as F + + +class AttnProcessor(nn.Module): + r""" + Default processor for performing attention-related computations. + """ + def __init__( + self, + hidden_size=None, + cross_attention_dim=None, + ): + super().__init__() + + def __call__( + self, + attn, + hidden_states, + encoder_hidden_states=None, + attention_mask=None, + temb=None, + ): + residual = hidden_states + + if attn.spatial_norm is not None: + hidden_states = attn.spatial_norm(hidden_states, temb) + + input_ndim = hidden_states.ndim + + if input_ndim == 4: + batch_size, channel, height, width = hidden_states.shape + hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2) + + batch_size, sequence_length, _ = ( + hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape + ) + attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size) + + if attn.group_norm is not None: + hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2) + + query = attn.to_q(hidden_states) + + if encoder_hidden_states is None: + encoder_hidden_states = hidden_states + elif attn.norm_cross: + encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states) + + key = attn.to_k(encoder_hidden_states) + value = attn.to_v(encoder_hidden_states) + + query = attn.head_to_batch_dim(query) + key = attn.head_to_batch_dim(key) + value = attn.head_to_batch_dim(value) + + attention_probs = attn.get_attention_scores(query, key, attention_mask) + hidden_states = torch.bmm(attention_probs, value) + hidden_states = attn.batch_to_head_dim(hidden_states) + + # linear proj + hidden_states = attn.to_out[0](hidden_states) + # dropout + hidden_states = attn.to_out[1](hidden_states) + + if input_ndim == 4: + hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width) + + if attn.residual_connection: + hidden_states = hidden_states + residual + + hidden_states = hidden_states / attn.rescale_output_factor + + return hidden_states + + +class IPAttnProcessor(nn.Module): + r""" + Attention processor for IP-Adapater. + Args: + hidden_size (`int`): + The hidden size of the attention layer. + cross_attention_dim (`int`): + The number of channels in the `encoder_hidden_states`. + text_context_len (`int`, defaults to 77): + The context length of the text features. + scale (`float`, defaults to 1.0): + the weight scale of image prompt. + """ + + def __init__(self, hidden_size, cross_attention_dim=None, text_context_len=77, scale=1.0): + super().__init__() + + self.hidden_size = hidden_size + self.cross_attention_dim = cross_attention_dim + self.text_context_len = text_context_len + self.scale = scale + + self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False) + self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False) + + def __call__( + self, + attn, + hidden_states, + encoder_hidden_states=None, + attention_mask=None, + temb=None, + ): + residual = hidden_states + + if attn.spatial_norm is not None: + hidden_states = attn.spatial_norm(hidden_states, temb) + + input_ndim = hidden_states.ndim + + if input_ndim == 4: + batch_size, channel, height, width = hidden_states.shape + hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2) + + batch_size, sequence_length, _ = ( + hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape + ) + attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size) + + if attn.group_norm is not None: + hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2) + + query = attn.to_q(hidden_states) + + if encoder_hidden_states is None: + encoder_hidden_states = hidden_states + elif attn.norm_cross: + encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states) + + # split hidden states + encoder_hidden_states, ip_hidden_states = encoder_hidden_states[:, :self.text_context_len, :], encoder_hidden_states[:, self.text_context_len:, :] + + key = attn.to_k(encoder_hidden_states) + value = attn.to_v(encoder_hidden_states) + + query = attn.head_to_batch_dim(query) + key = attn.head_to_batch_dim(key) + value = attn.head_to_batch_dim(value) + + attention_probs = attn.get_attention_scores(query, key, attention_mask) + hidden_states = torch.bmm(attention_probs, value) + hidden_states = attn.batch_to_head_dim(hidden_states) + + # for ip-adapter + ip_key = self.to_k_ip(ip_hidden_states) + ip_value = self.to_v_ip(ip_hidden_states) + + ip_key = attn.head_to_batch_dim(ip_key) + ip_value = attn.head_to_batch_dim(ip_value) + + ip_attention_probs = attn.get_attention_scores(query, ip_key, None) + ip_hidden_states = torch.bmm(ip_attention_probs, ip_value) + ip_hidden_states = attn.batch_to_head_dim(ip_hidden_states) + + hidden_states = hidden_states + self.scale * ip_hidden_states + + # linear proj + hidden_states = attn.to_out[0](hidden_states) + # dropout + hidden_states = attn.to_out[1](hidden_states) + + if input_ndim == 4: + hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width) + + if attn.residual_connection: + hidden_states = hidden_states + residual + + hidden_states = hidden_states / attn.rescale_output_factor + + return hidden_states + + +class AttnProcessor2_0(torch.nn.Module): + r""" + Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0). + """ + def __init__( + self, + hidden_size=None, + cross_attention_dim=None, + ): + super().__init__() + if not hasattr(F, "scaled_dot_product_attention"): + raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.") + + def __call__( + self, + attn, + hidden_states, + encoder_hidden_states=None, + attention_mask=None, + temb=None, + ): + residual = hidden_states + + if attn.spatial_norm is not None: + hidden_states = attn.spatial_norm(hidden_states, temb) + + input_ndim = hidden_states.ndim + + if input_ndim == 4: + batch_size, channel, height, width = hidden_states.shape + hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2) + + batch_size, sequence_length, _ = ( + hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape + ) + + if attention_mask is not None: + attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size) + # scaled_dot_product_attention expects attention_mask shape to be + # (batch, heads, source_length, target_length) + attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1]) + + if attn.group_norm is not None: + hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2) + + query = attn.to_q(hidden_states) + + if encoder_hidden_states is None: + encoder_hidden_states = hidden_states + elif attn.norm_cross: + encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states) + + key = attn.to_k(encoder_hidden_states) + value = attn.to_v(encoder_hidden_states) + + inner_dim = key.shape[-1] + head_dim = inner_dim // attn.heads + + query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2) + + key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2) + value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2) + + # the output of sdp = (batch, num_heads, seq_len, head_dim) + # TODO: add support for attn.scale when we move to Torch 2.1 + hidden_states = F.scaled_dot_product_attention( + query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False + ) + + hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim) + hidden_states = hidden_states.to(query.dtype) + + # linear proj + hidden_states = attn.to_out[0](hidden_states) + # dropout + hidden_states = attn.to_out[1](hidden_states) + + if input_ndim == 4: + hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width) + + if attn.residual_connection: + hidden_states = hidden_states + residual + + hidden_states = hidden_states / attn.rescale_output_factor + + return hidden_states + + +class IPAttnProcessor2_0(torch.nn.Module): + r""" + Attention processor for IP-Adapater for PyTorch 2.0. + Args: + hidden_size (`int`): + The hidden size of the attention layer. + cross_attention_dim (`int`): + The number of channels in the `encoder_hidden_states`. + text_context_len (`int`, defaults to 77): + The context length of the text features. + scale (`float`, defaults to 1.0): + the weight scale of image prompt. + """ + + def __init__(self, hidden_size, cross_attention_dim=None, text_context_len=77, scale=1.0): + super().__init__() + + if not hasattr(F, "scaled_dot_product_attention"): + raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.") + + self.hidden_size = hidden_size + self.cross_attention_dim = cross_attention_dim + self.text_context_len = text_context_len + self.scale = scale + + self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False) + self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False) + + def __call__( + self, + attn, + hidden_states, + encoder_hidden_states=None, + attention_mask=None, + temb=None, + ): + residual = hidden_states + + if attn.spatial_norm is not None: + hidden_states = attn.spatial_norm(hidden_states, temb) + + input_ndim = hidden_states.ndim + + if input_ndim == 4: + batch_size, channel, height, width = hidden_states.shape + hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2) + + batch_size, sequence_length, _ = ( + hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape + ) + + if attention_mask is not None: + attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size) + # scaled_dot_product_attention expects attention_mask shape to be + # (batch, heads, source_length, target_length) + attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1]) + + if attn.group_norm is not None: + hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2) + + query = attn.to_q(hidden_states) + + if encoder_hidden_states is None: + encoder_hidden_states = hidden_states + elif attn.norm_cross: + encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states) + + # split hidden states + encoder_hidden_states, ip_hidden_states = encoder_hidden_states[:, :self.text_context_len, :], encoder_hidden_states[:, self.text_context_len:, :] + + key = attn.to_k(encoder_hidden_states) + value = attn.to_v(encoder_hidden_states) + + inner_dim = key.shape[-1] + head_dim = inner_dim // attn.heads + + query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2) + + key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2) + value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2) + + # the output of sdp = (batch, num_heads, seq_len, head_dim) + # TODO: add support for attn.scale when we move to Torch 2.1 + hidden_states = F.scaled_dot_product_attention( + query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False + ) + + hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim) + hidden_states = hidden_states.to(query.dtype) + + # for ip-adapter + ip_key = self.to_k_ip(ip_hidden_states) + ip_value = self.to_v_ip(ip_hidden_states) + + ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2) + ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2) + + # the output of sdp = (batch, num_heads, seq_len, head_dim) + # TODO: add support for attn.scale when we move to Torch 2.1 + ip_hidden_states = F.scaled_dot_product_attention( + query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False + ) + + ip_hidden_states = ip_hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim) + ip_hidden_states = ip_hidden_states.to(query.dtype) + + hidden_states = hidden_states + self.scale * ip_hidden_states + + # linear proj + hidden_states = attn.to_out[0](hidden_states) + # dropout + hidden_states = attn.to_out[1](hidden_states) + + if input_ndim == 4: + hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width) + + if attn.residual_connection: + hidden_states = hidden_states + residual + + hidden_states = hidden_states / attn.rescale_output_factor + + return hidden_states diff --git a/animate/src/animatediff/ip_adapter/ip_adapter.py b/animate/src/animatediff/ip_adapter/ip_adapter.py new file mode 100644 index 0000000000000000000000000000000000000000..c63d578c52fde9b64f471105fa191b3cb9632f6a --- /dev/null +++ b/animate/src/animatediff/ip_adapter/ip_adapter.py @@ -0,0 +1,389 @@ +import os +from typing import List + +import torch +from diffusers import StableDiffusionPipeline +from PIL import Image +from safetensors import safe_open +from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection + +from .utils import is_torch2_available + +if is_torch2_available(): + from .attention_processor import AttnProcessor2_0 as AttnProcessor + from .attention_processor import IPAttnProcessor2_0 as IPAttnProcessor +else: + from .attention_processor import IPAttnProcessor, AttnProcessor + +import logging + +from .resampler import Resampler + +logger = logging.getLogger(__name__) + +class ImageProjModel(torch.nn.Module): + """Projection Model""" + def __init__(self, cross_attention_dim=1024, clip_embeddings_dim=1024, clip_extra_context_tokens=4): + super().__init__() + + self.cross_attention_dim = cross_attention_dim + self.clip_extra_context_tokens = clip_extra_context_tokens + self.proj = torch.nn.Linear(clip_embeddings_dim, self.clip_extra_context_tokens * cross_attention_dim) + self.norm = torch.nn.LayerNorm(cross_attention_dim) + + def forward(self, image_embeds): + embeds = image_embeds + clip_extra_context_tokens = self.proj(embeds).reshape(-1, self.clip_extra_context_tokens, self.cross_attention_dim) + clip_extra_context_tokens = self.norm(clip_extra_context_tokens) + return clip_extra_context_tokens + + +class MLPProjModel(torch.nn.Module): + """SD model with image prompt""" + def __init__(self, cross_attention_dim=1024, clip_embeddings_dim=1024): + super().__init__() + + self.proj = torch.nn.Sequential( + torch.nn.Linear(clip_embeddings_dim, clip_embeddings_dim), + torch.nn.GELU(), + torch.nn.Linear(clip_embeddings_dim, cross_attention_dim), + torch.nn.LayerNorm(cross_attention_dim) + ) + + def forward(self, image_embeds): + clip_extra_context_tokens = self.proj(image_embeds) + return clip_extra_context_tokens + + +class IPAdapter: + + def __init__(self, sd_pipe, image_encoder_path, ip_ckpt, device, num_tokens=4): + + self.device = device + self.image_encoder_path = image_encoder_path + self.ip_ckpt = ip_ckpt + self.num_tokens = num_tokens + + self.pipe = sd_pipe + self.set_ip_adapter() + + # load image encoder + self.image_encoder = CLIPVisionModelWithProjection.from_pretrained(self.image_encoder_path).to(self.device, dtype=torch.float16) + self.clip_image_processor = CLIPImageProcessor() + # image proj model + self.image_proj_model = self.init_proj() + + self.load_ip_adapter() + + def init_proj(self): + image_proj_model = ImageProjModel( + cross_attention_dim=self.pipe.unet.config.cross_attention_dim, + clip_embeddings_dim=self.image_encoder.config.projection_dim, + clip_extra_context_tokens=self.num_tokens, + ).to(self.device, dtype=torch.float16) + return image_proj_model + + def set_ip_adapter(self): + unet = self.pipe.unet + attn_procs = {} + for name in unet.attn_processors.keys(): + cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim + if name.startswith("mid_block"): + hidden_size = unet.config.block_out_channels[-1] + elif name.startswith("up_blocks"): + block_id = int(name[len("up_blocks.")]) + hidden_size = list(reversed(unet.config.block_out_channels))[block_id] + elif name.startswith("down_blocks"): + block_id = int(name[len("down_blocks.")]) + hidden_size = unet.config.block_out_channels[block_id] + if cross_attention_dim is None: + attn_procs[name] = AttnProcessor() + else: + attn_procs[name] = IPAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim, + scale=1.0).to(self.device, dtype=torch.float16) + unet.set_attn_processor(attn_procs) + + + def load_ip_adapter(self): + if os.path.splitext(self.ip_ckpt)[-1] == ".safetensors": + state_dict = {"image_proj": {}, "ip_adapter": {}} + with safe_open(self.ip_ckpt, framework="pt", device="cpu") as f: + for key in f.keys(): + if key.startswith("image_proj."): + state_dict["image_proj"][key.replace("image_proj.", "")] = f.get_tensor(key) + elif key.startswith("ip_adapter."): + state_dict["ip_adapter"][key.replace("ip_adapter.", "")] = f.get_tensor(key) + else: + state_dict = torch.load(self.ip_ckpt, map_location="cpu") + self.image_proj_model.load_state_dict(state_dict["image_proj"]) + ip_layers = torch.nn.ModuleList(self.pipe.unet.attn_processors.values()) + ip_layers.load_state_dict(state_dict["ip_adapter"]) + + @torch.inference_mode() + def get_image_embeds(self, pil_image): + if isinstance(pil_image, Image.Image): + pil_image = [pil_image] + clip_image = self.clip_image_processor(images=pil_image, return_tensors="pt").pixel_values + clip_image_embeds = self.image_encoder(clip_image.to(self.device, dtype=torch.float16)).image_embeds + image_prompt_embeds = self.image_proj_model(clip_image_embeds) + uncond_image_prompt_embeds = self.image_proj_model(torch.zeros_like(clip_image_embeds)) + return image_prompt_embeds, uncond_image_prompt_embeds + + def set_scale(self, scale): + for attn_processor in self.pipe.unet.attn_processors.values(): + if isinstance(attn_processor, IPAttnProcessor): + attn_processor.scale = scale + + def set_text_length(self, text_length): + for attn_processor in self.pipe.unet.attn_processors.values(): + if isinstance(attn_processor, IPAttnProcessor): + attn_processor.text_context_len = text_length + + def unload(self): + unet = self.pipe.unet + attn_procs = {} + for name in unet.attn_processors.keys(): + attn_procs[name] = AttnProcessor() + unet.set_attn_processor(attn_procs) + + def delete_encoder(self): + del self.image_encoder + del self.clip_image_processor + del self.image_proj_model + torch.cuda.empty_cache() + + def generate( + self, + pil_image, + prompt=None, + negative_prompt=None, + scale=1.0, + num_samples=4, + seed=-1, + guidance_scale=7.5, + num_inference_steps=30, + **kwargs, + ): + self.set_scale(scale) + + if isinstance(pil_image, Image.Image): + num_prompts = 1 + else: + num_prompts = len(pil_image) + + if prompt is None: + prompt = "best quality, high quality" + if negative_prompt is None: + negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality" + + if not isinstance(prompt, List): + prompt = [prompt] * num_prompts + if not isinstance(negative_prompt, List): + negative_prompt = [negative_prompt] * num_prompts + + image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(pil_image) + bs_embed, seq_len, _ = image_prompt_embeds.shape + image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1) + image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1) + uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1) + uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1) + + with torch.inference_mode(): + prompt_embeds = self.pipe._encode_prompt( + prompt, device=self.device, num_images_per_prompt=num_samples, do_classifier_free_guidance=True, negative_prompt=negative_prompt) + negative_prompt_embeds_, prompt_embeds_ = prompt_embeds.chunk(2) + prompt_embeds = torch.cat([prompt_embeds_, image_prompt_embeds], dim=1) + negative_prompt_embeds = torch.cat([negative_prompt_embeds_, uncond_image_prompt_embeds], dim=1) + + generator = torch.Generator(self.device).manual_seed(seed) if seed is not None else None + images = self.pipe( + prompt_embeds=prompt_embeds, + negative_prompt_embeds=negative_prompt_embeds, + guidance_scale=guidance_scale, + num_inference_steps=num_inference_steps, + generator=generator, + **kwargs, + ).images + + return images + + +class IPAdapterXL(IPAdapter): + """SDXL""" + + def generate( + self, + pil_image, + prompt=None, + negative_prompt=None, + scale=1.0, + num_samples=4, + seed=-1, + num_inference_steps=30, + **kwargs, + ): + self.set_scale(scale) + + if isinstance(pil_image, Image.Image): + num_prompts = 1 + else: + num_prompts = len(pil_image) + + if prompt is None: + prompt = "best quality, high quality" + if negative_prompt is None: + negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality" + + if not isinstance(prompt, List): + prompt = [prompt] * num_prompts + if not isinstance(negative_prompt, List): + negative_prompt = [negative_prompt] * num_prompts + + image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(pil_image) + bs_embed, seq_len, _ = image_prompt_embeds.shape + image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1) + image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1) + uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1) + uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1) + + with torch.inference_mode(): + prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds = self.pipe.encode_prompt( + prompt, num_images_per_prompt=num_samples, do_classifier_free_guidance=True, negative_prompt=negative_prompt) + prompt_embeds = torch.cat([prompt_embeds, image_prompt_embeds], dim=1) + negative_prompt_embeds = torch.cat([negative_prompt_embeds, uncond_image_prompt_embeds], dim=1) + + generator = torch.Generator(self.device).manual_seed(seed) if seed is not None else None + images = self.pipe( + prompt_embeds=prompt_embeds, + negative_prompt_embeds=negative_prompt_embeds, + pooled_prompt_embeds=pooled_prompt_embeds, + negative_pooled_prompt_embeds=negative_pooled_prompt_embeds, + num_inference_steps=num_inference_steps, + generator=generator, + **kwargs, + ).images + + return images + + +class IPAdapterPlus(IPAdapter): + """IP-Adapter with fine-grained features""" + + def init_proj(self): + image_proj_model = Resampler( + dim=self.pipe.unet.config.cross_attention_dim, + depth=4, + dim_head=64, + heads=12, + num_queries=self.num_tokens, + embedding_dim=self.image_encoder.config.hidden_size, + output_dim=self.pipe.unet.config.cross_attention_dim, + ff_mult=4 + ).to(self.device, dtype=torch.float16) + return image_proj_model + + @torch.inference_mode() + def get_image_embeds(self, pil_image): + if isinstance(pil_image, Image.Image): + pil_image = [pil_image] + clip_image = self.clip_image_processor(images=pil_image, return_tensors="pt").pixel_values + clip_image = clip_image.to(self.device, dtype=torch.float16) + clip_image_embeds = self.image_encoder(clip_image, output_hidden_states=True).hidden_states[-2] + image_prompt_embeds = self.image_proj_model(clip_image_embeds) + uncond_clip_image_embeds = self.image_encoder(torch.zeros_like(clip_image), output_hidden_states=True).hidden_states[-2] + uncond_image_prompt_embeds = self.image_proj_model(uncond_clip_image_embeds) + return image_prompt_embeds, uncond_image_prompt_embeds + + +class IPAdapterFull(IPAdapterPlus): + """IP-Adapter with full features""" + + def init_proj(self): + image_proj_model = MLPProjModel( + cross_attention_dim=self.pipe.unet.config.cross_attention_dim, + clip_embeddings_dim=self.image_encoder.config.hidden_size, + ).to(self.device, dtype=torch.float16) + return image_proj_model + + +class IPAdapterPlusXL(IPAdapter): + """SDXL""" + + def init_proj(self): + image_proj_model = Resampler( + dim=1280, + depth=4, + dim_head=64, + heads=20, + num_queries=self.num_tokens, + embedding_dim=self.image_encoder.config.hidden_size, + output_dim=self.pipe.unet.config.cross_attention_dim, + ff_mult=4 + ).to(self.device, dtype=torch.float16) + return image_proj_model + + @torch.inference_mode() + def get_image_embeds(self, pil_image): + if isinstance(pil_image, Image.Image): + pil_image = [pil_image] + clip_image = self.clip_image_processor(images=pil_image, return_tensors="pt").pixel_values + clip_image = clip_image.to(self.device, dtype=torch.float16) + clip_image_embeds = self.image_encoder(clip_image, output_hidden_states=True).hidden_states[-2] + image_prompt_embeds = self.image_proj_model(clip_image_embeds) + uncond_clip_image_embeds = self.image_encoder(torch.zeros_like(clip_image), output_hidden_states=True).hidden_states[-2] + uncond_image_prompt_embeds = self.image_proj_model(uncond_clip_image_embeds) + return image_prompt_embeds, uncond_image_prompt_embeds + + def generate( + self, + pil_image, + prompt=None, + negative_prompt=None, + scale=1.0, + num_samples=4, + seed=-1, + num_inference_steps=30, + **kwargs, + ): + self.set_scale(scale) + + if isinstance(pil_image, Image.Image): + num_prompts = 1 + else: + num_prompts = len(pil_image) + + if prompt is None: + prompt = "best quality, high quality" + if negative_prompt is None: + negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality" + + if not isinstance(prompt, List): + prompt = [prompt] * num_prompts + if not isinstance(negative_prompt, List): + negative_prompt = [negative_prompt] * num_prompts + + image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(pil_image) + bs_embed, seq_len, _ = image_prompt_embeds.shape + image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1) + image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1) + uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1) + uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1) + + with torch.inference_mode(): + prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds = self.pipe.encode_prompt( + prompt, num_images_per_prompt=num_samples, do_classifier_free_guidance=True, negative_prompt=negative_prompt) + prompt_embeds = torch.cat([prompt_embeds, image_prompt_embeds], dim=1) + negative_prompt_embeds = torch.cat([negative_prompt_embeds, uncond_image_prompt_embeds], dim=1) + + generator = torch.Generator(self.device).manual_seed(seed) if seed is not None else None + images = self.pipe( + prompt_embeds=prompt_embeds, + negative_prompt_embeds=negative_prompt_embeds, + pooled_prompt_embeds=pooled_prompt_embeds, + negative_pooled_prompt_embeds=negative_pooled_prompt_embeds, + num_inference_steps=num_inference_steps, + generator=generator, + **kwargs, + ).images + + return images \ No newline at end of file diff --git a/animate/src/animatediff/ip_adapter/resampler.py b/animate/src/animatediff/ip_adapter/resampler.py new file mode 100644 index 0000000000000000000000000000000000000000..509969819384a8998d37f38894d3161b72e3aa1d --- /dev/null +++ b/animate/src/animatediff/ip_adapter/resampler.py @@ -0,0 +1,158 @@ +# modified from https://github.com/mlfoundations/open_flamingo/blob/main/open_flamingo/src/helpers.py +# and https://github.com/lucidrains/imagen-pytorch/blob/main/imagen_pytorch/imagen_pytorch.py +import math + +import torch +import torch.nn as nn +from einops import rearrange +from einops.layers.torch import Rearrange + + +# FFN +def FeedForward(dim, mult=4): + inner_dim = int(dim * mult) + return nn.Sequential( + nn.LayerNorm(dim), + nn.Linear(dim, inner_dim, bias=False), + nn.GELU(), + nn.Linear(inner_dim, dim, bias=False), + ) + + +def reshape_tensor(x, heads): + bs, length, width = x.shape + #(bs, length, width) --> (bs, length, n_heads, dim_per_head) + x = x.view(bs, length, heads, -1) + # (bs, length, n_heads, dim_per_head) --> (bs, n_heads, length, dim_per_head) + x = x.transpose(1, 2) + # (bs, n_heads, length, dim_per_head) --> (bs*n_heads, length, dim_per_head) + x = x.reshape(bs, heads, length, -1) + return x + + +class PerceiverAttention(nn.Module): + def __init__(self, *, dim, dim_head=64, heads=8): + super().__init__() + self.scale = dim_head**-0.5 + self.dim_head = dim_head + self.heads = heads + inner_dim = dim_head * heads + + self.norm1 = nn.LayerNorm(dim) + self.norm2 = nn.LayerNorm(dim) + + self.to_q = nn.Linear(dim, inner_dim, bias=False) + self.to_kv = nn.Linear(dim, inner_dim * 2, bias=False) + self.to_out = nn.Linear(inner_dim, dim, bias=False) + + + def forward(self, x, latents): + """ + Args: + x (torch.Tensor): image features + shape (b, n1, D) + latent (torch.Tensor): latent features + shape (b, n2, D) + """ + x = self.norm1(x) + latents = self.norm2(latents) + + b, l, _ = latents.shape + + q = self.to_q(latents) + kv_input = torch.cat((x, latents), dim=-2) + k, v = self.to_kv(kv_input).chunk(2, dim=-1) + + q = reshape_tensor(q, self.heads) + k = reshape_tensor(k, self.heads) + v = reshape_tensor(v, self.heads) + + # attention + scale = 1 / math.sqrt(math.sqrt(self.dim_head)) + weight = (q * scale) @ (k * scale).transpose(-2, -1) # More stable with f16 than dividing afterwards + weight = torch.softmax(weight.float(), dim=-1).type(weight.dtype) + out = weight @ v + + out = out.permute(0, 2, 1, 3).reshape(b, l, -1) + + return self.to_out(out) + + +class Resampler(nn.Module): + def __init__( + self, + dim=1024, + depth=8, + dim_head=64, + heads=16, + num_queries=8, + embedding_dim=768, + output_dim=1024, + ff_mult=4, + max_seq_len: int = 257, # CLIP tokens + CLS token + apply_pos_emb: bool = False, + num_latents_mean_pooled: int = 0, # number of latents derived from mean pooled representation of the sequence + ): + super().__init__() + self.pos_emb = nn.Embedding(max_seq_len, embedding_dim) if apply_pos_emb else None + + self.latents = nn.Parameter(torch.randn(1, num_queries, dim) / dim**0.5) + + self.proj_in = nn.Linear(embedding_dim, dim) + + self.proj_out = nn.Linear(dim, output_dim) + self.norm_out = nn.LayerNorm(output_dim) + + self.to_latents_from_mean_pooled_seq = ( + nn.Sequential( + nn.LayerNorm(dim), + nn.Linear(dim, dim * num_latents_mean_pooled), + Rearrange("b (n d) -> b n d", n=num_latents_mean_pooled), + ) + if num_latents_mean_pooled > 0 + else None + ) + + self.layers = nn.ModuleList([]) + for _ in range(depth): + self.layers.append( + nn.ModuleList( + [ + PerceiverAttention(dim=dim, dim_head=dim_head, heads=heads), + FeedForward(dim=dim, mult=ff_mult), + ] + ) + ) + + def forward(self, x): + if self.pos_emb is not None: + n, device = x.shape[1], x.device + pos_emb = self.pos_emb(torch.arange(n, device=device)) + x = x + pos_emb + + latents = self.latents.repeat(x.size(0), 1, 1) + + x = self.proj_in(x) + + if self.to_latents_from_mean_pooled_seq: + meanpooled_seq = masked_mean(x, dim=1, mask=torch.ones(x.shape[:2], device=x.device, dtype=torch.bool)) + meanpooled_latents = self.to_latents_from_mean_pooled_seq(meanpooled_seq) + latents = torch.cat((meanpooled_latents, latents), dim=-2) + + for attn, ff in self.layers: + latents = attn(x, latents) + latents + latents = ff(latents) + latents + + latents = self.proj_out(latents) + return self.norm_out(latents) + + +def masked_mean(t, *, dim, mask=None): + if mask is None: + return t.mean(dim=dim) + + denom = mask.sum(dim=dim, keepdim=True) + mask = rearrange(mask, "b n -> b n 1") + masked_t = t.masked_fill(~mask, 0.0) + + return masked_t.sum(dim=dim) / denom.clamp(min=1e-5) diff --git a/animate/src/animatediff/ip_adapter/utils.py b/animate/src/animatediff/ip_adapter/utils.py new file mode 100644 index 0000000000000000000000000000000000000000..cf02e561680dd62d53c9bab3e0171c7eb7702b07 --- /dev/null +++ b/animate/src/animatediff/ip_adapter/utils.py @@ -0,0 +1,367 @@ +import inspect +import warnings +from typing import Any, Callable, Dict, List, Optional, Tuple, Union + +import numpy as np +import PIL.Image +import torch +import torch.nn.functional as F +from diffusers.models import ControlNetModel +from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel +from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput +from diffusers.utils.torch_utils import is_compiled_module + + +def is_torch2_available(): + return hasattr(F, "scaled_dot_product_attention") + + +@torch.no_grad() +def generate( + self, + prompt: Union[str, List[str]] = None, + image: Union[ + torch.FloatTensor, + PIL.Image.Image, + np.ndarray, + List[torch.FloatTensor], + List[PIL.Image.Image], + List[np.ndarray], + ] = None, + height: Optional[int] = None, + width: Optional[int] = None, + num_inference_steps: int = 50, + guidance_scale: float = 7.5, + negative_prompt: Optional[Union[str, List[str]]] = None, + num_images_per_prompt: Optional[int] = 1, + eta: float = 0.0, + generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None, + latents: Optional[torch.FloatTensor] = None, + prompt_embeds: Optional[torch.FloatTensor] = None, + negative_prompt_embeds: Optional[torch.FloatTensor] = None, + output_type: Optional[str] = "pil", + return_dict: bool = True, + callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None, + callback_steps: int = 1, + cross_attention_kwargs: Optional[Dict[str, Any]] = None, + controlnet_conditioning_scale: Union[float, List[float]] = 1.0, + guess_mode: bool = False, + control_guidance_start: Union[float, List[float]] = 0.0, + control_guidance_end: Union[float, List[float]] = 1.0, +): + r""" + Function invoked when calling the pipeline for generation. + + Args: + prompt (`str` or `List[str]`, *optional*): + The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`. + instead. + image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,: + `List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`): + The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If + the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can + also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If + height and/or width are passed, `image` is resized according to them. If multiple ControlNets are + specified in init, images must be passed as a list such that each element of the list can be correctly + batched for input to a single controlnet. + height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor): + The height in pixels of the generated image. + width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor): + The width in pixels of the generated image. + num_inference_steps (`int`, *optional*, defaults to 50): + The number of denoising steps. More denoising steps usually lead to a higher quality image at the + expense of slower inference. + guidance_scale (`float`, *optional*, defaults to 7.5): + Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598). + `guidance_scale` is defined as `w` of equation 2. of [Imagen + Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale > + 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`, + usually at the expense of lower image quality. + negative_prompt (`str` or `List[str]`, *optional*): + The prompt or prompts not to guide the image generation. If not defined, one has to pass + `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is + less than `1`). + num_images_per_prompt (`int`, *optional*, defaults to 1): + The number of images to generate per prompt. + eta (`float`, *optional*, defaults to 0.0): + Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to + [`schedulers.DDIMScheduler`], will be ignored for others. + generator (`torch.Generator` or `List[torch.Generator]`, *optional*): + One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html) + to make generation deterministic. + latents (`torch.FloatTensor`, *optional*): + Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image + generation. Can be used to tweak the same generation with different prompts. If not provided, a latents + tensor will ge generated by sampling using the supplied random `generator`. + prompt_embeds (`torch.FloatTensor`, *optional*): + Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not + provided, text embeddings will be generated from `prompt` input argument. + negative_prompt_embeds (`torch.FloatTensor`, *optional*): + Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt + weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input + argument. + output_type (`str`, *optional*, defaults to `"pil"`): + The output format of the generate image. Choose between + [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`. + return_dict (`bool`, *optional*, defaults to `True`): + Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a + plain tuple. + callback (`Callable`, *optional*): + A function that will be called every `callback_steps` steps during inference. The function will be + called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`. + callback_steps (`int`, *optional*, defaults to 1): + The frequency at which the `callback` function will be called. If not specified, the callback will be + called at every step. + cross_attention_kwargs (`dict`, *optional*): + A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under + `self.processor` in + [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py). + controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0): + The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added + to the residual in the original unet. If multiple ControlNets are specified in init, you can set the + corresponding scale as a list. + guess_mode (`bool`, *optional*, defaults to `False`): + In this mode, the ControlNet encoder will try best to recognize the content of the input image even if + you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended. + control_guidance_start (`float` or `List[float]`, *optional*, defaults to 0.0): + The percentage of total steps at which the controlnet starts applying. + control_guidance_end (`float` or `List[float]`, *optional*, defaults to 1.0): + The percentage of total steps at which the controlnet stops applying. + + Examples: + + Returns: + [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`: + [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple. + When returning a tuple, the first element is a list with the generated images, and the second element is a + list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work" + (nsfw) content, according to the `safety_checker`. + """ + controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet + + # align format for control guidance + if not isinstance(control_guidance_start, list) and isinstance(control_guidance_end, list): + control_guidance_start = len(control_guidance_end) * [control_guidance_start] + elif not isinstance(control_guidance_end, list) and isinstance(control_guidance_start, list): + control_guidance_end = len(control_guidance_start) * [control_guidance_end] + elif not isinstance(control_guidance_start, list) and not isinstance(control_guidance_end, list): + mult = len(controlnet.nets) if isinstance(controlnet, MultiControlNetModel) else 1 + control_guidance_start, control_guidance_end = mult * [control_guidance_start], mult * [ + control_guidance_end + ] + + # 1. Check inputs. Raise error if not correct + self.check_inputs( + prompt, + image, + callback_steps, + negative_prompt, + prompt_embeds, + negative_prompt_embeds, + controlnet_conditioning_scale, + control_guidance_start, + control_guidance_end, + ) + + # 2. Define call parameters + if prompt is not None and isinstance(prompt, str): + batch_size = 1 + elif prompt is not None and isinstance(prompt, list): + batch_size = len(prompt) + else: + batch_size = prompt_embeds.shape[0] + + device = self._execution_device + # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2) + # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1` + # corresponds to doing no classifier free guidance. + do_classifier_free_guidance = guidance_scale > 1.0 + + if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float): + controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets) + + global_pool_conditions = ( + controlnet.config.global_pool_conditions + if isinstance(controlnet, ControlNetModel) + else controlnet.nets[0].config.global_pool_conditions + ) + guess_mode = guess_mode or global_pool_conditions + + # 3. Encode input prompt + text_encoder_lora_scale = ( + cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None + ) + prompt_embeds = self._encode_prompt( + prompt, + device, + num_images_per_prompt, + do_classifier_free_guidance, + negative_prompt, + prompt_embeds=prompt_embeds, + negative_prompt_embeds=negative_prompt_embeds, + lora_scale=text_encoder_lora_scale, + ) + + # 4. Prepare image + if isinstance(controlnet, ControlNetModel): + image = self.prepare_image( + image=image, + width=width, + height=height, + batch_size=batch_size * num_images_per_prompt, + num_images_per_prompt=num_images_per_prompt, + device=device, + dtype=controlnet.dtype, + do_classifier_free_guidance=do_classifier_free_guidance, + guess_mode=guess_mode, + ) + height, width = image.shape[-2:] + elif isinstance(controlnet, MultiControlNetModel): + images = [] + + for image_ in image: + image_ = self.prepare_image( + image=image_, + width=width, + height=height, + batch_size=batch_size * num_images_per_prompt, + num_images_per_prompt=num_images_per_prompt, + device=device, + dtype=controlnet.dtype, + do_classifier_free_guidance=do_classifier_free_guidance, + guess_mode=guess_mode, + ) + + images.append(image_) + + image = images + height, width = image[0].shape[-2:] + else: + assert False + + # 5. Prepare timesteps + self.scheduler.set_timesteps(num_inference_steps, device=device) + timesteps = self.scheduler.timesteps + + # 6. Prepare latent variables + num_channels_latents = self.unet.config.in_channels + latents = self.prepare_latents( + batch_size * num_images_per_prompt, + num_channels_latents, + height, + width, + prompt_embeds.dtype, + device, + generator, + latents, + ) + + # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline + extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta) + + # 7.1 Create tensor stating which controlnets to keep + controlnet_keep = [] + for i in range(len(timesteps)): + keeps = [ + 1.0 - float(i / len(timesteps) < s or (i + 1) / len(timesteps) > e) + for s, e in zip(control_guidance_start, control_guidance_end) + ] + controlnet_keep.append(keeps[0] if isinstance(controlnet, ControlNetModel) else keeps) + + # 8. Denoising loop + num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order + with self.progress_bar(total=num_inference_steps) as progress_bar: + for i, t in enumerate(timesteps): + # expand the latents if we are doing classifier free guidance + latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents + latent_model_input = self.scheduler.scale_model_input(latent_model_input, t) + + # controlnet(s) inference + if guess_mode and do_classifier_free_guidance: + # Infer ControlNet only for the conditional batch. + control_model_input = latents + control_model_input = self.scheduler.scale_model_input(control_model_input, t) + controlnet_prompt_embeds = prompt_embeds[:, :77, :].chunk(2)[1] + else: + control_model_input = latent_model_input + controlnet_prompt_embeds = prompt_embeds[:, :77, :] + + if isinstance(controlnet_keep[i], list): + cond_scale = [c * s for c, s in zip(controlnet_conditioning_scale, controlnet_keep[i])] + else: + controlnet_cond_scale = controlnet_conditioning_scale + if isinstance(controlnet_cond_scale, list): + controlnet_cond_scale = controlnet_cond_scale[0] + cond_scale = controlnet_cond_scale * controlnet_keep[i] + + down_block_res_samples, mid_block_res_sample = self.controlnet( + control_model_input, + t, + encoder_hidden_states=controlnet_prompt_embeds, + controlnet_cond=image, + conditioning_scale=cond_scale, + guess_mode=guess_mode, + return_dict=False, + ) + + if guess_mode and do_classifier_free_guidance: + # Infered ControlNet only for the conditional batch. + # To apply the output of ControlNet to both the unconditional and conditional batches, + # add 0 to the unconditional batch to keep it unchanged. + down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples] + mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample]) + + # predict the noise residual + noise_pred = self.unet( + latent_model_input, + t, + encoder_hidden_states=prompt_embeds, + cross_attention_kwargs=cross_attention_kwargs, + down_block_additional_residuals=down_block_res_samples, + mid_block_additional_residual=mid_block_res_sample, + return_dict=False, + )[0] + + # perform guidance + if do_classifier_free_guidance: + noise_pred_uncond, noise_pred_text = noise_pred.chunk(2) + noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond) + + # compute the previous noisy sample x_t -> x_t-1 + latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0] + + # call the callback, if provided + if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0): + progress_bar.update() + if callback is not None and i % callback_steps == 0: + callback(i, t, latents) + + # If we do sequential model offloading, let's offload unet and controlnet + # manually for max memory savings + if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None: + self.unet.to("cpu") + self.controlnet.to("cpu") + torch.cuda.empty_cache() + + if not output_type == "latent": + image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0] + image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype) + else: + image = latents + has_nsfw_concept = None + + if has_nsfw_concept is None: + do_denormalize = [True] * image.shape[0] + else: + do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept] + + image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize) + + # Offload last model to CPU + if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None: + self.final_offload_hook.offload() + + if not return_dict: + return (image, has_nsfw_concept) + + return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept) \ No newline at end of file diff --git a/animate/src/animatediff/models/__init__.py b/animate/src/animatediff/models/__init__.py new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/animate/src/animatediff/models/attention.py b/animate/src/animatediff/models/attention.py new file mode 100644 index 0000000000000000000000000000000000000000..83cace31a49a7b7776167e9a0d2b137aac4090d6 --- /dev/null +++ b/animate/src/animatediff/models/attention.py @@ -0,0 +1,326 @@ +# Adapted from https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention.py + +import logging +from dataclasses import dataclass +from typing import Any, Dict, Optional + +import torch +from diffusers.configuration_utils import ConfigMixin, register_to_config +from diffusers.models import ModelMixin +from diffusers.models.attention import AdaLayerNorm, Attention, FeedForward +from diffusers.utils import BaseOutput +from diffusers.utils.torch_utils import maybe_allow_in_graph +from einops import rearrange, repeat +from torch import Tensor, nn + +logger = logging.getLogger(__name__) + +@dataclass +class Transformer3DModelOutput(BaseOutput): + sample: torch.FloatTensor + + +@maybe_allow_in_graph +class Transformer3DModel(ModelMixin, ConfigMixin): + @register_to_config + def __init__( + self, + num_attention_heads: int = 16, + attention_head_dim: int = 88, + in_channels: Optional[int] = None, + num_layers: int = 1, + dropout: float = 0.0, + norm_num_groups: int = 32, + cross_attention_dim: Optional[int] = None, + attention_bias: bool = False, + activation_fn: str = "geglu", + num_embeds_ada_norm: Optional[int] = None, + use_linear_projection: bool = False, + only_cross_attention: bool = False, + upcast_attention: bool = False, + unet_use_cross_frame_attention=None, + unet_use_temporal_attention=None, + ): + super().__init__() + self.use_linear_projection = use_linear_projection + self.num_attention_heads = num_attention_heads + self.attention_head_dim = attention_head_dim + inner_dim = num_attention_heads * attention_head_dim + + # Define input layers + self.in_channels = in_channels + + self.norm = torch.nn.GroupNorm( + num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True + ) + if use_linear_projection: + self.proj_in = nn.Linear(in_channels, inner_dim) + else: + self.proj_in = nn.Conv2d(in_channels, inner_dim, kernel_size=1, stride=1, padding=0) + + # Define transformers blocks + self.transformer_blocks = nn.ModuleList( + [ + BasicTransformerBlock( + inner_dim, + num_attention_heads, + attention_head_dim, + dropout=dropout, + cross_attention_dim=cross_attention_dim, + activation_fn=activation_fn, + num_embeds_ada_norm=num_embeds_ada_norm, + attention_bias=attention_bias, + only_cross_attention=only_cross_attention, + upcast_attention=upcast_attention, + unet_use_cross_frame_attention=unet_use_cross_frame_attention, + unet_use_temporal_attention=unet_use_temporal_attention, + ) + for d in range(num_layers) + ] + ) + + # 4. Define output layers + if use_linear_projection: + self.proj_out = nn.Linear(in_channels, inner_dim) + else: + self.proj_out = nn.Conv2d(inner_dim, in_channels, kernel_size=1, stride=1, padding=0) + + def forward( + self, + hidden_states: torch.Tensor, + encoder_hidden_states: Optional[torch.Tensor] = None, + timestep: Optional[torch.LongTensor] = None, + cross_attention_kwargs: Dict[str, Any] = None, + attention_mask: Optional[torch.Tensor] = None, + encoder_attention_mask: Optional[torch.Tensor] = None, + return_dict: bool = True, + ) -> tuple[Tensor] | Transformer3DModelOutput: + # validate input dim + if hidden_states.dim() != 5: + raise ValueError(f"Expected hidden_states to have ndim=5, but got ndim={hidden_states.dim()}.") + + # ensure attention_mask is a bias, and give it a singleton query_tokens dimension. + # we may have done this conversion already, e.g. if we came here via UNet2DConditionModel#forward. + # we can tell by counting dims; if ndim == 2: it's a mask rather than a bias. + # expects mask of shape: + # [batch, key_tokens] + # adds singleton query_tokens dimension: + # [batch, 1, key_tokens] + # this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes: + # [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn) + # [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn) + if attention_mask is not None and attention_mask.ndim == 2: + # assume that mask is expressed as: + # (1 = keep, 0 = discard) + # convert mask into a bias that can be added to attention scores: + # (keep = +0, discard = -10000.0) + attention_mask = (1 - attention_mask.to(hidden_states.dtype)) * -10000.0 + attention_mask = attention_mask.unsqueeze(1) + + # convert encoder_attention_mask to a bias the same way we do for attention_mask + if encoder_attention_mask is not None and encoder_attention_mask.ndim == 2: + encoder_attention_mask = (1 - encoder_attention_mask.to(hidden_states.dtype)) * -10000.0 + encoder_attention_mask = encoder_attention_mask.unsqueeze(1) + + # shenanigans for motion module + video_length = hidden_states.shape[2] + hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w") + + if encoder_hidden_states.shape[0] < video_length: + encoder_hidden_states = repeat(encoder_hidden_states, "b n c -> (b f) n c", f=video_length) + + # 1. Input + batch, _, height, width = hidden_states.shape + residual = hidden_states + + hidden_states = self.norm(hidden_states) + if not self.use_linear_projection: + hidden_states = self.proj_in(hidden_states) + inner_dim = hidden_states.shape[1] + hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * width, inner_dim) + else: + inner_dim = hidden_states.shape[1] + hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * width, inner_dim) + hidden_states = self.proj_in(hidden_states) + + # 2. Blocks + for block in self.transformer_blocks: + hidden_states = block( + hidden_states, + attention_mask=attention_mask, + encoder_hidden_states=encoder_hidden_states, + timestep=timestep, + video_length=video_length, + encoder_attention_mask=encoder_attention_mask, + cross_attention_kwargs=cross_attention_kwargs, + ) + + # 3. Output + if not self.use_linear_projection: + hidden_states = ( + hidden_states.reshape(batch, height, width, inner_dim).permute(0, 3, 1, 2).contiguous() + ) + hidden_states = self.proj_out(hidden_states) + else: + hidden_states = self.proj_out(hidden_states) + hidden_states = ( + hidden_states.reshape(batch, height, width, inner_dim).permute(0, 3, 1, 2).contiguous() + ) + + output = hidden_states + residual + + output = rearrange(output, "(b f) c h w -> b c f h w", f=video_length) + if not return_dict: + return (output,) + + return Transformer3DModelOutput(sample=output) + + +@maybe_allow_in_graph +class BasicTransformerBlock(nn.Module): + def __init__( + self, + dim: int, + num_attention_heads: int, + attention_head_dim: int, + dropout: float = 0.0, + cross_attention_dim: Optional[int] = None, + activation_fn: str = "geglu", + num_embeds_ada_norm: Optional[int] = None, + attention_bias: bool = False, + only_cross_attention: bool = False, + upcast_attention: bool = False, + norm_elementwise_affine: bool = True, + unet_use_cross_frame_attention: bool = False, + unet_use_temporal_attention: bool = False, + final_dropout: bool = False, + ) -> None: + super().__init__() + self.only_cross_attention = only_cross_attention + self.use_ada_layer_norm = num_embeds_ada_norm is not None + self.unet_use_cross_frame_attention = unet_use_cross_frame_attention + self.unet_use_temporal_attention = unet_use_temporal_attention + + # Define 3 blocks. Each block has its own normalization layer. + # 1. Self-Attn / SC-Attn + if self.use_ada_layer_norm: + self.norm1 = AdaLayerNorm(dim, num_embeds_ada_norm) + else: + self.norm1 = nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine) + + if unet_use_cross_frame_attention: + # this isn't actually implemented anywhere in the AnimateDiff codebase or in Diffusers... + raise NotImplementedError("SC-Attn is not implemented yet.") + else: + self.attn1 = Attention( + query_dim=dim, + cross_attention_dim=cross_attention_dim if only_cross_attention else None, + heads=num_attention_heads, + dim_head=attention_head_dim, + dropout=dropout, + bias=attention_bias, + upcast_attention=upcast_attention, + ) + + # 2. Cross-Attn + if cross_attention_dim is not None: + self.norm2 = ( + AdaLayerNorm(dim, num_embeds_ada_norm) + if self.use_ada_layer_norm + else nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine) + ) + self.attn2 = Attention( + query_dim=dim, + cross_attention_dim=cross_attention_dim, + heads=num_attention_heads, + dim_head=attention_head_dim, + dropout=dropout, + bias=attention_bias, + upcast_attention=upcast_attention, + ) # is self-attn if encoder_hidden_states is none + else: + self.norm2 = None + self.attn2 = None + + # 3. Feed-forward + self.norm3 = nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine) + self.ff = FeedForward(dim, dropout=dropout, activation_fn=activation_fn, final_dropout=final_dropout) + + # 4. Temporal Attn + assert unet_use_temporal_attention is not None + if unet_use_temporal_attention: + self.attn_temp = Attention( + query_dim=dim, + heads=num_attention_heads, + dim_head=attention_head_dim, + dropout=dropout, + bias=attention_bias, + upcast_attention=upcast_attention, + ) + nn.init.zeros_(self.attn_temp.to_out[0].weight.data) + if self.use_ada_layer_norm: + self.norm1 = AdaLayerNorm(dim, num_embeds_ada_norm) + else: + self.norm1 = nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine) + + def forward( + self, + hidden_states: torch.FloatTensor, + attention_mask: Optional[torch.FloatTensor] = None, + encoder_hidden_states: Optional[torch.FloatTensor] = None, + encoder_attention_mask: Optional[torch.FloatTensor] = None, + timestep: Optional[torch.LongTensor] = None, + cross_attention_kwargs: Dict[str, Any] = None, + video_length=None, + ): + # SparseCausal-Attention + # Notice that normalization is always applied before the real computation in the following blocks. + # 1. Self-Attention + if self.use_ada_layer_norm: + norm_hidden_states = self.norm1(hidden_states, timestep) + else: + norm_hidden_states = self.norm1(hidden_states) + + cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {} + if self.unet_use_cross_frame_attention: + cross_attention_kwargs["video_length"] = video_length + + attn_output = self.attn1( + norm_hidden_states, + encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None, + attention_mask=attention_mask, + **cross_attention_kwargs, + ) + + hidden_states = attn_output + hidden_states + + # 2. Cross-Attention + if self.attn2 is not None: + norm_hidden_states = ( + self.norm2(hidden_states, timestep) if self.use_ada_layer_norm else self.norm2(hidden_states) + ) + + attn_output = self.attn2( + norm_hidden_states, + encoder_hidden_states=encoder_hidden_states, + attention_mask=encoder_attention_mask, + **cross_attention_kwargs, + ) + hidden_states = attn_output + hidden_states + + # 3. Feed-forward + hidden_states = self.ff(self.norm3(hidden_states)) + hidden_states + + # 4. Temporal-Attention + if self.unet_use_temporal_attention: + d = hidden_states.shape[1] + hidden_states = rearrange(hidden_states, "(b f) d c -> (b d) f c", f=video_length) + norm_hidden_states = ( + self.norm_temp(hidden_states, timestep) + if self.use_ada_layer_norm + else self.norm_temp(hidden_states) + ) + hidden_states = self.attn_temp(norm_hidden_states) + hidden_states + hidden_states = rearrange(hidden_states, "(b d) f c -> (b f) d c", d=d) + + return hidden_states diff --git a/animate/src/animatediff/models/motion_module.py b/animate/src/animatediff/models/motion_module.py new file mode 100644 index 0000000000000000000000000000000000000000..355bd94ee7a3fc1225ac21e415e3625864c80cba --- /dev/null +++ b/animate/src/animatediff/models/motion_module.py @@ -0,0 +1,304 @@ +import logging +import math +from dataclasses import dataclass +from typing import Optional + +import torch +import torch.nn.functional as F +from diffusers.models.attention import Attention, FeedForward +from diffusers.utils import BaseOutput +from diffusers.utils.torch_utils import maybe_allow_in_graph +from einops import rearrange, repeat +from torch import Tensor, nn + +logger = logging.getLogger(__name__) + +def zero_module(module): + # Zero out the parameters of a module and return it. + for p in module.parameters(): + p.detach().zero_() + return module + + +@dataclass +class TemporalTransformer3DModelOutput(BaseOutput): + sample: torch.FloatTensor + + +def get_motion_module(in_channels, motion_module_type: str, motion_module_kwargs: dict): + if motion_module_type == "Vanilla": + return VanillaTemporalModule( + in_channels=in_channels, + **motion_module_kwargs, + ) + else: + raise ValueError + + +class VanillaTemporalModule(nn.Module): + def __init__( + self, + in_channels, + num_attention_heads=8, + num_transformer_block=2, + attention_block_types=("Temporal_Self", "Temporal_Self"), + cross_frame_attention_mode=None, + temporal_position_encoding=False, + temporal_position_encoding_max_len=24, + temporal_attention_dim_div=1, + zero_initialize=True, + ): + super().__init__() + + self.temporal_transformer = TemporalTransformer3DModel( + in_channels=in_channels, + num_attention_heads=num_attention_heads, + attention_head_dim=in_channels // num_attention_heads // temporal_attention_dim_div, + num_layers=num_transformer_block, + attention_block_types=attention_block_types, + cross_frame_attention_mode=cross_frame_attention_mode, + temporal_position_encoding=temporal_position_encoding, + temporal_position_encoding_max_len=temporal_position_encoding_max_len, + ) + + if zero_initialize: + self.temporal_transformer.proj_out = zero_module(self.temporal_transformer.proj_out) + + def forward(self, input_tensor, temb, encoder_hidden_states, attention_mask=None, anchor_frame_idx=None): + hidden_states = input_tensor + hidden_states = self.temporal_transformer(hidden_states, encoder_hidden_states, attention_mask) + + output = hidden_states + return output + + +@maybe_allow_in_graph +class TemporalTransformer3DModel(nn.Module): + def __init__( + self, + in_channels, + num_attention_heads, + attention_head_dim, + num_layers, + attention_block_types=( + "Temporal_Self", + "Temporal_Self", + ), + dropout=0.0, + norm_num_groups=32, + cross_attention_dim=768, + activation_fn="geglu", + attention_bias=False, + upcast_attention=False, + cross_frame_attention_mode=None, + temporal_position_encoding=False, + temporal_position_encoding_max_len=24, + ): + super().__init__() + + inner_dim = num_attention_heads * attention_head_dim + + self.norm = torch.nn.GroupNorm( + num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True + ) + self.proj_in = nn.Linear(in_channels, inner_dim) + + self.transformer_blocks = nn.ModuleList( + [ + TemporalTransformerBlock( + dim=inner_dim, + num_attention_heads=num_attention_heads, + attention_head_dim=attention_head_dim, + attention_block_types=attention_block_types, + dropout=dropout, + norm_num_groups=norm_num_groups, + cross_attention_dim=cross_attention_dim, + activation_fn=activation_fn, + attention_bias=attention_bias, + upcast_attention=upcast_attention, + cross_frame_attention_mode=cross_frame_attention_mode, + temporal_position_encoding=temporal_position_encoding, + temporal_position_encoding_max_len=temporal_position_encoding_max_len, + ) + for d in range(num_layers) + ] + ) + self.proj_out = nn.Linear(inner_dim, in_channels) + + def forward( + self, + hidden_states: Tensor, + encoder_hidden_states: Optional[Tensor] = None, + attention_mask: Optional[Tensor] = None, + ): + assert ( + hidden_states.dim() == 5 + ), f"Expected hidden_states to have ndim=5, but got ndim={hidden_states.dim()}." + video_length = hidden_states.shape[2] + hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w") + + batch, channel, height, weight = hidden_states.shape + residual = hidden_states + + hidden_states = self.norm(hidden_states) + inner_dim = hidden_states.shape[1] + hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * weight, inner_dim) + hidden_states = self.proj_in(hidden_states) + + # Transformer Blocks + for block in self.transformer_blocks: + hidden_states = block( + hidden_states, encoder_hidden_states=encoder_hidden_states, video_length=video_length + ) + + # output + hidden_states = self.proj_out(hidden_states) + hidden_states = ( + hidden_states.reshape(batch, height, weight, inner_dim).permute(0, 3, 1, 2).contiguous() + ) + + output = hidden_states + residual + output = rearrange(output, "(b f) c h w -> b c f h w", f=video_length) + + return output + + +@maybe_allow_in_graph +class TemporalTransformerBlock(nn.Module): + def __init__( + self, + dim: int, + num_attention_heads: int, + attention_head_dim: int, + attention_block_types=( + "Temporal_Self", + "Temporal_Self", + ), + dropout=0.0, + norm_num_groups: int = 32, + cross_attention_dim: int = 768, + activation_fn: str = "geglu", + attention_bias: bool = False, + upcast_attention: bool = False, + cross_frame_attention_mode=None, + temporal_position_encoding: bool = False, + temporal_position_encoding_max_len: int = 24, + ): + super().__init__() + + attention_blocks = [] + norms = [] + + for block_name in attention_block_types: + attention_blocks.append( + VersatileAttention( + attention_mode=block_name.split("_")[0], + cross_attention_dim=cross_attention_dim if block_name.endswith("_Cross") else None, + query_dim=dim, + heads=num_attention_heads, + dim_head=attention_head_dim, + dropout=dropout, + bias=attention_bias, + upcast_attention=upcast_attention, + cross_frame_attention_mode=cross_frame_attention_mode, + temporal_position_encoding=temporal_position_encoding, + temporal_position_encoding_max_len=temporal_position_encoding_max_len, + ) + ) + norms.append(nn.LayerNorm(dim)) + + self.attention_blocks = nn.ModuleList(attention_blocks) + self.norms = nn.ModuleList(norms) + + self.ff = FeedForward(dim, dropout=dropout, activation_fn=activation_fn) + self.ff_norm = nn.LayerNorm(dim) + + def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, video_length=None): + for attention_block, norm in zip(self.attention_blocks, self.norms): + norm_hidden_states = norm(hidden_states) + hidden_states = ( + attention_block( + norm_hidden_states, + encoder_hidden_states=encoder_hidden_states + if attention_block.is_cross_attention + else None, + video_length=video_length, + ) + + hidden_states + ) + + hidden_states = self.ff(self.ff_norm(hidden_states)) + hidden_states + + output = hidden_states + return output + + +class PositionalEncoding(nn.Module): + def __init__(self, d_model, dropout: float = 0.0, max_len: int = 24): + super().__init__() + self.dropout: nn.Module = nn.Dropout(p=dropout) + position = torch.arange(max_len).unsqueeze(1) + div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model)) + pe: Tensor = torch.zeros(1, max_len, d_model) + pe[0, :, 0::2] = torch.sin(position * div_term) + pe[0, :, 1::2] = torch.cos(position * div_term) + self.register_buffer("pe", pe) + + def forward(self, x: Tensor): + x = x + self.pe[:, : x.size(1)] + return self.dropout(x) + + +@maybe_allow_in_graph +class VersatileAttention(Attention): + def __init__( + self, + attention_mode: str = None, + cross_frame_attention_mode: Optional[str] = None, + temporal_position_encoding: bool = False, + temporal_position_encoding_max_len: int = 24, + *args, + **kwargs, + ): + super().__init__(*args, **kwargs) + if attention_mode.lower() != "temporal": + raise ValueError(f"Attention mode {attention_mode} is not supported.") + + self.attention_mode = attention_mode + self.is_cross_attention = kwargs["cross_attention_dim"] is not None + + self.pos_encoder = ( + PositionalEncoding(kwargs["query_dim"], dropout=0.0, max_len=temporal_position_encoding_max_len) + if (temporal_position_encoding and attention_mode == "Temporal") + else None + ) + + def extra_repr(self): + return f"(Module Info) Attention_Mode: {self.attention_mode}, Is_Cross_Attention: {self.is_cross_attention}" + + def forward( + self, hidden_states: Tensor, encoder_hidden_states=None, attention_mask=None, video_length=None + ): + if self.attention_mode == "Temporal": + d = hidden_states.shape[1] + hidden_states = rearrange(hidden_states, "(b f) d c -> (b d) f c", f=video_length) + + if self.pos_encoder is not None: + hidden_states = self.pos_encoder(hidden_states) + + if encoder_hidden_states and encoder_hidden_states.shape[0] < d: + encoder_hidden_states = ( + repeat(encoder_hidden_states, "b n c -> (b d) n c", d=d) + if encoder_hidden_states is not None + else encoder_hidden_states + ) + else: + raise NotImplementedError + + # attention processor makes this easy so that's nice + hidden_states = self.processor(self, hidden_states, encoder_hidden_states, attention_mask) + + if self.attention_mode == "Temporal": + hidden_states = rearrange(hidden_states, "(b d) f c -> (b f) d c", d=d) + + return hidden_states diff --git a/animate/src/animatediff/models/resnet.py b/animate/src/animatediff/models/resnet.py new file mode 100644 index 0000000000000000000000000000000000000000..febecf282babef0be1ec662db805d1dfc688d601 --- /dev/null +++ b/animate/src/animatediff/models/resnet.py @@ -0,0 +1,228 @@ +# Adapted from https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/resnet.py + +from typing import Optional + +import torch +import torch.nn.functional as F +from diffusers.models.lora import LoRACompatibleConv, LoRACompatibleLinear +from einops import rearrange +from torch import Tensor, nn + + +#class InflatedConv3d(nn.Conv2d): +class InflatedConv3d(LoRACompatibleConv): + def forward(self, x: Tensor) -> Tensor: + frames = x.shape[2] + + x = rearrange(x, "b c f h w -> (b f) c h w") + x = F.conv2d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups) + x = rearrange(x, "(b f) c h w -> b c f h w", f=frames) + return x + +class InflatedGroupNorm(nn.GroupNorm): + def forward(self, x): + video_length = x.shape[2] + + x = rearrange(x, "b c f h w -> (b f) c h w") + x = super().forward(x) + x = rearrange(x, "(b f) c h w -> b c f h w", f=video_length) + + return x + +class Upsample3D(nn.Module): + def __init__( + self, + channels: int, + use_conv: bool = False, + use_conv_transpose: bool = False, + out_channels: Optional[int] = None, + name="conv", + ): + super().__init__() + self.channels = channels + self.out_channels = out_channels or channels + self.use_conv = use_conv + self.use_conv_transpose = use_conv_transpose + self.name = name + + if use_conv_transpose: + raise NotImplementedError + elif use_conv: + self.conv = InflatedConv3d(self.channels, self.out_channels, 3, padding=1) + + def forward(self, hidden_states: Tensor, output_size=None): + assert hidden_states.shape[1] == self.channels + + if self.use_conv_transpose: + raise NotImplementedError + + # Cast to float32 to as 'upsample_nearest2d_out_frame' op does not support bfloat16 + dtype = hidden_states.dtype + if dtype == torch.bfloat16: + hidden_states = hidden_states.to(torch.float32) + + # upsample_nearest_nhwc fails with large batch sizes. see https://github.com/huggingface/diffusers/issues/984 + if hidden_states.shape[0] >= 64: + hidden_states = hidden_states.contiguous() + + # if `output_size` is passed we force the interpolation output + # size and do not make use of `scale_factor=2` + if output_size is None: + hidden_states = F.interpolate(hidden_states, scale_factor=[1.0, 2.0, 2.0], mode="nearest") + else: + hidden_states = F.interpolate(hidden_states, size=output_size, mode="nearest") + + # If the input is bfloat16, we cast back to bfloat16 + if dtype == torch.bfloat16: + hidden_states = hidden_states.to(dtype) + + hidden_states = self.conv(hidden_states) + + return hidden_states + + +class Downsample3D(nn.Module): + def __init__( + self, + channels: int, + use_conv: bool = False, + out_channels: Optional[int] = None, + padding: int = 1, + name="conv", + ): + super().__init__() + self.channels = channels + self.out_channels = out_channels or channels + self.use_conv = use_conv + self.padding = padding + stride = 2 + self.name = name + + if use_conv: + self.conv = InflatedConv3d(self.channels, self.out_channels, 3, stride=stride, padding=padding) + else: + raise NotImplementedError + + def forward(self, hidden_states): + assert hidden_states.shape[1] == self.channels + if self.use_conv and self.padding == 0: + raise NotImplementedError + + assert hidden_states.shape[1] == self.channels + hidden_states = self.conv(hidden_states) + + return hidden_states + + +class ResnetBlock3D(nn.Module): + def __init__( + self, + *, + in_channels, + out_channels=None, + conv_shortcut=False, + dropout=0.0, + temb_channels=512, + groups=32, + groups_out=None, + pre_norm=True, + eps=1e-6, + non_linearity="swish", + time_embedding_norm="default", + output_scale_factor=1.0, + use_in_shortcut=None, + use_inflated_groupnorm=None, + ): + super().__init__() + self.pre_norm = pre_norm + self.pre_norm = True + self.in_channels = in_channels + out_channels = in_channels if out_channels is None else out_channels + self.out_channels = out_channels + self.use_conv_shortcut = conv_shortcut + self.time_embedding_norm = time_embedding_norm + self.output_scale_factor = output_scale_factor + + if groups_out is None: + groups_out = groups + + assert use_inflated_groupnorm != None + if use_inflated_groupnorm: + self.norm1 = InflatedGroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True) + else: + self.norm1 = nn.GroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True) + + self.conv1 = InflatedConv3d(in_channels, out_channels, kernel_size=3, stride=1, padding=1) + + if temb_channels is not None: + if self.time_embedding_norm == "default": + time_emb_proj_out_channels = out_channels + elif self.time_embedding_norm == "scale_shift": + time_emb_proj_out_channels = out_channels * 2 + else: + raise ValueError(f"unknown time_embedding_norm : {self.time_embedding_norm} ") + +# self.time_emb_proj = nn.Linear(temb_channels, time_emb_proj_out_channels) + self.time_emb_proj = LoRACompatibleLinear(temb_channels, time_emb_proj_out_channels) + else: + self.time_emb_proj = None + + if use_inflated_groupnorm: + self.norm2 = InflatedGroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True) + else: + self.norm2 = nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True) + + self.dropout = nn.Dropout(dropout) + self.conv2 = InflatedConv3d(out_channels, out_channels, kernel_size=3, stride=1, padding=1) + + if non_linearity == "swish": + self.nonlinearity = lambda x: F.silu(x) + elif non_linearity == "mish": + self.nonlinearity = Mish() + elif non_linearity == "silu": + self.nonlinearity = nn.SiLU() + + self.use_in_shortcut = ( + self.in_channels != self.out_channels if use_in_shortcut is None else use_in_shortcut + ) + + self.conv_shortcut = None + if self.use_in_shortcut: + self.conv_shortcut = InflatedConv3d(in_channels, out_channels, kernel_size=1, stride=1, padding=0) + + def forward(self, input_tensor, temb): + hidden_states = input_tensor + + hidden_states = self.norm1(hidden_states) + hidden_states = self.nonlinearity(hidden_states) + + hidden_states = self.conv1(hidden_states) + + if temb is not None: + temb = self.time_emb_proj(self.nonlinearity(temb))[:, :, None, None, None] + + if temb is not None and self.time_embedding_norm == "default": + hidden_states = hidden_states + temb + + hidden_states = self.norm2(hidden_states) + + if temb is not None and self.time_embedding_norm == "scale_shift": + scale, shift = torch.chunk(temb, 2, dim=1) + hidden_states = hidden_states * (1 + scale) + shift + + hidden_states = self.nonlinearity(hidden_states) + + hidden_states = self.dropout(hidden_states) + hidden_states = self.conv2(hidden_states) + + if self.conv_shortcut is not None: + input_tensor = self.conv_shortcut(input_tensor) + + output_tensor = (input_tensor + hidden_states) / self.output_scale_factor + + return output_tensor + + +class Mish(nn.Module): + def forward(self, hidden_states): + return hidden_states * torch.tanh(torch.nn.functional.softplus(hidden_states)) diff --git a/animate/src/animatediff/models/unet.py b/animate/src/animatediff/models/unet.py new file mode 100644 index 0000000000000000000000000000000000000000..558e2ea25d1319b70a394234293f62054e37e190 --- /dev/null +++ b/animate/src/animatediff/models/unet.py @@ -0,0 +1,643 @@ +# Adapted from https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/unet_2d_condition.py + +from dataclasses import dataclass +from os import PathLike +from pathlib import Path +from typing import Any, Dict, List, Optional, Tuple, Union + +import torch +import torch.utils.checkpoint +from diffusers.configuration_utils import ConfigMixin, register_to_config +from diffusers.models import ModelMixin +from diffusers.models.attention_processor import AttentionProcessor +from diffusers.models.embeddings import TimestepEmbedding, Timesteps +from diffusers.loaders import PeftAdapterMixin, UNet2DConditionLoadersMixin +from diffusers.utils import (SAFETENSORS_WEIGHTS_NAME, WEIGHTS_NAME, + BaseOutput, logging) +from safetensors.torch import load_file +from torch import Tensor, nn + +from .resnet import InflatedConv3d, InflatedGroupNorm +from .unet_blocks import (CrossAttnDownBlock3D, CrossAttnUpBlock3D, + DownBlock3D, UNetMidBlock3DCrossAttn, UpBlock3D, + get_down_block, get_up_block) + +logger = logging.get_logger(__name__) # pylint: disable=invalid-name + + +@dataclass +class UNet3DConditionOutput(BaseOutput): + sample: torch.FloatTensor + + +class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin, PeftAdapterMixin): + _supports_gradient_checkpointing = True + + @register_to_config + def __init__( + self, + sample_size: Optional[int] = None, + in_channels: int = 4, + out_channels: int = 4, + center_input_sample: bool = False, + flip_sin_to_cos: bool = True, + freq_shift: int = 0, + down_block_types: Tuple[str] = ( + "CrossAttnDownBlock3D", + "CrossAttnDownBlock3D", + "CrossAttnDownBlock3D", + "DownBlock3D", + ), + mid_block_type: str = "UNetMidBlock3DCrossAttn", + up_block_types: Tuple[str] = ( + "UpBlock3D", + "CrossAttnUpBlock3D", + "CrossAttnUpBlock3D", + "CrossAttnUpBlock3D", + ), + only_cross_attention: Union[bool, Tuple[bool]] = False, + block_out_channels: Tuple[int] = (320, 640, 1280, 1280), + layers_per_block: int = 2, + downsample_padding: int = 1, + mid_block_scale_factor: float = 1, + act_fn: str = "silu", + norm_num_groups: int = 32, + norm_eps: float = 1e-5, + cross_attention_dim: int = 1280, + attention_head_dim: Union[int, Tuple[int]] = 8, + num_attention_heads: Optional[Union[int, Tuple[int]]] = None, + dual_cross_attention: bool = False, + use_linear_projection: bool = False, + class_embed_type: Optional[str] = None, + num_class_embeds: Optional[int] = None, + upcast_attention: bool = False, + resnet_time_scale_shift: str = "default", + use_inflated_groupnorm=False, + # Additional + use_motion_module=False, + motion_module_resolutions=(1, 2, 4, 8), + motion_module_mid_block=False, + motion_module_decoder_only=False, + motion_module_type=None, + motion_module_kwargs={}, + unet_use_cross_frame_attention=None, + unet_use_temporal_attention=None, + ): + super().__init__() + + self.sample_size = sample_size + time_embed_dim = block_out_channels[0] * 4 + + # input + self.conv_in = InflatedConv3d(in_channels, block_out_channels[0], kernel_size=3, padding=(1, 1)) + + # time + self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift) + timestep_input_dim = block_out_channels[0] + + self.time_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim) + + # class embedding + if class_embed_type is None and num_class_embeds is not None: + self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim) + elif class_embed_type == "timestep": + self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim) + elif class_embed_type == "identity": + self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim) + else: + self.class_embedding = None + + self.down_blocks = nn.ModuleList([]) + self.mid_block = None + self.up_blocks = nn.ModuleList([]) + + if isinstance(only_cross_attention, bool): + only_cross_attention = [only_cross_attention] * len(down_block_types) + + if isinstance(attention_head_dim, int): + attention_head_dim = (attention_head_dim,) * len(down_block_types) + + # down + output_channel = block_out_channels[0] + for i, down_block_type in enumerate(down_block_types): + res = 2**i + input_channel = output_channel + output_channel = block_out_channels[i] + is_final_block = i == len(block_out_channels) - 1 + + down_block = get_down_block( + down_block_type, + num_layers=layers_per_block, + in_channels=input_channel, + out_channels=output_channel, + temb_channels=time_embed_dim, + add_downsample=not is_final_block, + resnet_eps=norm_eps, + resnet_act_fn=act_fn, + resnet_groups=norm_num_groups, + cross_attention_dim=cross_attention_dim, + attn_num_head_channels=attention_head_dim[i], + downsample_padding=downsample_padding, + dual_cross_attention=dual_cross_attention, + use_linear_projection=use_linear_projection, + only_cross_attention=only_cross_attention[i], + upcast_attention=upcast_attention, + resnet_time_scale_shift=resnet_time_scale_shift, + unet_use_cross_frame_attention=unet_use_cross_frame_attention, + unet_use_temporal_attention=unet_use_temporal_attention, + use_inflated_groupnorm=use_inflated_groupnorm, + use_motion_module=use_motion_module + and (res in motion_module_resolutions) + and (not motion_module_decoder_only), + motion_module_type=motion_module_type, + motion_module_kwargs=motion_module_kwargs, + ) + self.down_blocks.append(down_block) + + # mid + if mid_block_type == "UNetMidBlock3DCrossAttn": + self.mid_block = UNetMidBlock3DCrossAttn( + in_channels=block_out_channels[-1], + temb_channels=time_embed_dim, + resnet_eps=norm_eps, + resnet_act_fn=act_fn, + output_scale_factor=mid_block_scale_factor, + resnet_time_scale_shift=resnet_time_scale_shift, + cross_attention_dim=cross_attention_dim, + attn_num_head_channels=attention_head_dim[-1], + resnet_groups=norm_num_groups, + dual_cross_attention=dual_cross_attention, + use_linear_projection=use_linear_projection, + upcast_attention=upcast_attention, + unet_use_cross_frame_attention=unet_use_cross_frame_attention, + unet_use_temporal_attention=unet_use_temporal_attention, + use_inflated_groupnorm=use_inflated_groupnorm, + use_motion_module=use_motion_module and motion_module_mid_block, + motion_module_type=motion_module_type, + motion_module_kwargs=motion_module_kwargs, + ) + else: + raise ValueError(f"unknown mid_block_type : {mid_block_type}") + + # count how many layers upsample the videos + self.num_upsamplers = 0 + + # up + reversed_block_out_channels = list(reversed(block_out_channels)) + reversed_attention_head_dim = list(reversed(attention_head_dim)) + only_cross_attention = list(reversed(only_cross_attention)) + output_channel = reversed_block_out_channels[0] + for i, up_block_type in enumerate(up_block_types): + res = 2 ** (3 - i) + is_final_block = i == len(block_out_channels) - 1 + + prev_output_channel = output_channel + output_channel = reversed_block_out_channels[i] + input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)] + + # add upsample block for all BUT final layer + if not is_final_block: + add_upsample = True + self.num_upsamplers += 1 + else: + add_upsample = False + + up_block = get_up_block( + up_block_type, + num_layers=layers_per_block + 1, + in_channels=input_channel, + out_channels=output_channel, + prev_output_channel=prev_output_channel, + temb_channels=time_embed_dim, + add_upsample=add_upsample, + resnet_eps=norm_eps, + resnet_act_fn=act_fn, + resnet_groups=norm_num_groups, + cross_attention_dim=cross_attention_dim, + attn_num_head_channels=reversed_attention_head_dim[i], + dual_cross_attention=dual_cross_attention, + use_linear_projection=use_linear_projection, + only_cross_attention=only_cross_attention[i], + upcast_attention=upcast_attention, + resnet_time_scale_shift=resnet_time_scale_shift, + unet_use_cross_frame_attention=unet_use_cross_frame_attention, + unet_use_temporal_attention=unet_use_temporal_attention, + use_inflated_groupnorm=use_inflated_groupnorm, + use_motion_module=use_motion_module and (res in motion_module_resolutions), + motion_module_type=motion_module_type, + motion_module_kwargs=motion_module_kwargs, + ) + self.up_blocks.append(up_block) + prev_output_channel = output_channel + + # out + if use_inflated_groupnorm: + self.conv_norm_out = InflatedGroupNorm(num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps) + else: + self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps) + + self.conv_act = nn.SiLU() + self.conv_out = InflatedConv3d(block_out_channels[0], out_channels, kernel_size=3, padding=1) + + def set_attention_slice(self, slice_size): + r""" + Enable sliced attention computation. + + When this option is enabled, the attention module will split the input tensor in slices, to compute attention + in several steps. This is useful to save some memory in exchange for a small speed decrease. + + Args: + slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`): + When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If + `"max"`, maxium amount of memory will be saved by running only one slice at a time. If a number is + provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim` + must be a multiple of `slice_size`. + """ + sliceable_head_dims = [] + + def fn_recursive_retrieve_slicable_dims(module: nn.Module): + if hasattr(module, "set_attention_slice"): + sliceable_head_dims.append(module.sliceable_head_dim) + + for child in module.children(): + fn_recursive_retrieve_slicable_dims(child) + + # retrieve number of attention layers + for module in self.children(): + fn_recursive_retrieve_slicable_dims(module) + + num_slicable_layers = len(sliceable_head_dims) + + if slice_size == "auto": + # half the attention head size is usually a good trade-off between + # speed and memory + slice_size = [dim // 2 for dim in sliceable_head_dims] + elif slice_size == "max": + # make smallest slice possible + slice_size = num_slicable_layers * [1] + + slice_size = num_slicable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size + + if len(slice_size) != len(sliceable_head_dims): + raise ValueError( + f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different" + f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}." + ) + + for i in range(len(slice_size)): + size = slice_size[i] + dim = sliceable_head_dims[i] + if size is not None and size > dim: + raise ValueError(f"size {size} has to be smaller or equal to {dim}.") + + # Recursively walk through all the children. + # Any children which exposes the set_attention_slice method + # gets the message + def fn_recursive_set_attention_slice(module: nn.Module, slice_size: List[int]): + if hasattr(module, "set_attention_slice"): + module.set_attention_slice(slice_size.pop()) + + for child in module.children(): + fn_recursive_set_attention_slice(child, slice_size) + + reversed_slice_size = list(reversed(slice_size)) + for module in self.children(): + fn_recursive_set_attention_slice(module, reversed_slice_size) + + def _set_gradient_checkpointing(self, module, value=False): + if isinstance(module, (CrossAttnDownBlock3D, DownBlock3D, CrossAttnUpBlock3D, UpBlock3D)): + module.gradient_checkpointing = value + + def forward( + self, + sample: torch.FloatTensor, + timestep: Union[Tensor, float, int], + encoder_hidden_states: Tensor, + class_labels: Optional[Tensor] = None, + attention_mask: Optional[Tensor] = None, + cross_attention_kwargs: Optional[Dict[str, Any]] = None, + added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None, + down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None, + mid_block_additional_residual: Optional[torch.Tensor] = None, + encoder_attention_mask: Optional[torch.Tensor] = None, + return_dict: bool = True, + ) -> Union[UNet3DConditionOutput, Tuple]: + r""" + Args: + sample (`torch.FloatTensor`): (batch, channel, height, width) noisy inputs tensor + timestep (`torch.FloatTensor` or `float` or `int`): (batch) timesteps + encoder_hidden_states (`torch.FloatTensor`): (batch, sequence_length, feature_dim) encoder hidden states + return_dict (`bool`, *optional*, defaults to `True`): + Whether or not to return a [`models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain tuple. + + Returns: + [`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`: + [`~models.unet_2d_condition.UNet2DConditionOutput`] if `return_dict` is True, otherwise a `tuple`. When + returning a tuple, the first element is the sample tensor. + """ + # By default samples have to be at least a multiple of the overall upsampling factor. + # The overall upsampling factor is equal to 2 ** (# num of upsampling layears). + # However, the upsampling interpolation output size can be forced to fit any upsampling size + # on the fly if necessary. + default_overall_up_factor = 2**self.num_upsamplers + + # upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor` + forward_upsample_size = False + upsample_size = None + + if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]): + logger.debug("Forward upsample size to force interpolation output size.") + forward_upsample_size = True + + # ensure attention_mask is a bias, and give it a singleton query_tokens dimension + # expects mask of shape: + # [batch, key_tokens] + # adds singleton query_tokens dimension: + # [batch, 1, key_tokens] + # this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes: + # [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn) + # [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn) + if attention_mask is not None: + # assume that mask is expressed as: + # (1 = keep, 0 = discard) + # convert mask into a bias that can be added to attention scores: + # (keep = +0, discard = -10000.0) + attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0 + attention_mask = attention_mask.unsqueeze(1) + + # convert encoder_attention_mask to a bias the same way we do for attention_mask + if encoder_attention_mask is not None: + encoder_attention_mask = (1 - encoder_attention_mask.to(sample.dtype)) * -10000.0 + encoder_attention_mask = encoder_attention_mask.unsqueeze(1) + + # 0. center input if necessary + if self.config.center_input_sample: + sample = 2 * sample - 1.0 + + # 1. time + timesteps = timestep + if not torch.is_tensor(timesteps): + # TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can + # This would be a good case for the `match` statement (Python 3.10+) + is_mps = sample.device.type == "mps" + if isinstance(timestep, float): + dtype = torch.float32 if is_mps else torch.float64 + else: + dtype = torch.int32 if is_mps else torch.int64 + timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device) + elif len(timesteps.shape) == 0: + timesteps = timesteps[None].to(sample.device) + + # broadcast to batch dimension in a way that's compatible with ONNX/Core ML + timesteps = timesteps.expand(sample.shape[0]) + + t_emb = self.time_proj(timesteps) + + # `Timesteps` does not contain any weights and will always return f32 tensors + # but time_embedding might actually be running in fp16. so we need to cast here. + # there might be better ways to encapsulate this. + t_emb = t_emb.to(dtype=sample.dtype) + + emb = self.time_embedding(t_emb) + + if self.class_embedding is not None: + if class_labels is None: + raise ValueError("class_labels should be provided when num_class_embeds > 0") + + if self.config.class_embed_type == "timestep": + class_labels = self.time_proj(class_labels) + + # `Timesteps` does not contain any weights and will always return f32 tensors + # there might be better ways to encapsulate this. + class_labels = class_labels.to(dtype=sample.dtype) + + class_emb = self.class_embedding(class_labels).to(dtype=sample.dtype) + + if self.config.class_embeddings_concat: + emb = torch.cat([emb, class_emb], dim=-1) + else: + emb = emb + class_emb + + # 2. pre-process + sample = self.conv_in(sample) + + # 3. down + down_block_res_samples = (sample,) + for downsample_block in self.down_blocks: + if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention: + sample, res_samples = downsample_block( + hidden_states=sample, + temb=emb, + encoder_hidden_states=encoder_hidden_states, + attention_mask=attention_mask, + cross_attention_kwargs=cross_attention_kwargs, + encoder_attention_mask=encoder_attention_mask, + ) + else: + sample, res_samples = downsample_block( + hidden_states=sample, temb=emb, encoder_hidden_states=encoder_hidden_states + ) + + down_block_res_samples = down_block_res_samples + res_samples + + if down_block_additional_residuals is not None: + new_down_block_res_samples = () + + for down_block_res_sample, down_block_additional_residual in zip( + down_block_res_samples, down_block_additional_residuals + ): + down_block_res_sample = down_block_res_sample + down_block_additional_residual + new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,) + + down_block_res_samples = new_down_block_res_samples + + # 4. mid + if self.mid_block is not None: + sample = self.mid_block( + sample, + emb, + encoder_hidden_states=encoder_hidden_states, + attention_mask=attention_mask, + cross_attention_kwargs=cross_attention_kwargs, + ) + + + if mid_block_additional_residual is not None: + sample = sample + mid_block_additional_residual + + # up + for i, upsample_block in enumerate(self.up_blocks): + is_final_block = i == len(self.up_blocks) - 1 + + res_samples = down_block_res_samples[-len(upsample_block.resnets) :] + down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)] + + # if we have not reached the final block and need to forward the + # upsample size, we do it here + if not is_final_block and forward_upsample_size: + upsample_size = down_block_res_samples[-1].shape[2:] + + if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention: + sample = upsample_block( + hidden_states=sample, + temb=emb, + res_hidden_states_tuple=res_samples, + encoder_hidden_states=encoder_hidden_states, + upsample_size=upsample_size, + attention_mask=attention_mask, + ) + else: + sample = upsample_block( + hidden_states=sample, + temb=emb, + res_hidden_states_tuple=res_samples, + upsample_size=upsample_size, + encoder_hidden_states=encoder_hidden_states, + ) + + # post-process + sample = self.conv_norm_out(sample) + sample = self.conv_act(sample) + sample = self.conv_out(sample) + + if not return_dict: + return (sample,) + + return UNet3DConditionOutput(sample=sample) + + @classmethod + def from_pretrained_2d( + cls: "UNet3DConditionModel", + pretrained_model_path: PathLike, + motion_module_path: PathLike, + subfolder: Optional[str] = None, + unet_additional_kwargs: Optional[dict] = None, + ): + pretrained_model_path = Path(pretrained_model_path) + motion_module_path = Path(motion_module_path) + if subfolder is not None: + pretrained_model_path = pretrained_model_path.joinpath(subfolder) + + logger.debug(f"Loading temporal unet weights into {pretrained_model_path}") + + config_file = pretrained_model_path / "config.json" + if not (config_file.exists() and config_file.is_file()): + raise RuntimeError(f"{config_file} does not exist or is not a file") + + unet_config = cls.load_config(config_file) + unet_config["_class_name"] = cls.__name__ + unet_config["down_block_types"] = [ + "CrossAttnDownBlock3D", + "CrossAttnDownBlock3D", + "CrossAttnDownBlock3D", + "DownBlock3D", + ] + unet_config["up_block_types"] = [ + "UpBlock3D", + "CrossAttnUpBlock3D", + "CrossAttnUpBlock3D", + "CrossAttnUpBlock3D", + ] + unet_config["mid_block_type"] = "UNetMidBlock3DCrossAttn" + + model: nn.Module = cls.from_config(unet_config, **unet_additional_kwargs) + + # load the vanilla weights + if pretrained_model_path.joinpath(SAFETENSORS_WEIGHTS_NAME).exists(): + logger.debug(f"loading safeTensors weights from {pretrained_model_path} ...") + state_dict = load_file(pretrained_model_path.joinpath(SAFETENSORS_WEIGHTS_NAME), device="cpu") + + elif pretrained_model_path.joinpath(WEIGHTS_NAME).exists(): + logger.debug(f"loading weights from {pretrained_model_path} ...") + state_dict = torch.load( + pretrained_model_path.joinpath(WEIGHTS_NAME), map_location="cpu", weights_only=True + ) + else: + raise FileNotFoundError(f"no weights file found in {pretrained_model_path}") + + # load the motion module weights + if motion_module_path.exists() and motion_module_path.is_file(): + if motion_module_path.suffix.lower() in [".pth", ".pt", ".ckpt"]: + motion_state_dict = torch.load(motion_module_path, map_location="cpu", weights_only=True) + elif motion_module_path.suffix.lower() == ".safetensors": + motion_state_dict = load_file(motion_module_path, device="cpu") + else: + raise RuntimeError( + f"unknown file format for motion module weights: {motion_module_path.suffix}" + ) + else: + raise FileNotFoundError(f"no motion module weights found in {motion_module_path}") + + # merge the state dicts + state_dict.update(motion_state_dict) + + # load the weights into the model + m, u = model.load_state_dict(state_dict, strict=False) + logger.debug(f"### missing keys: {len(m)}; \n### unexpected keys: {len(u)};") + + params = [p.numel() if "temporal" in n else 0 for n, p in model.named_parameters()] + logger.info(f"Loaded {sum(params) / 1e6}M-parameter motion module") + + return model + + + @property + def attn_processors(self) -> Dict[str, AttentionProcessor]: + r""" + Returns: + `dict` of attention processors: A dictionary containing all attention processors used in the model with + indexed by its weight name. + """ + # set recursively + processors = {} + + def fn_recursive_add_processors( + name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor] + ): + if hasattr(module, "set_processor"): + processors[f"{name}.processor"] = module.processor + + for sub_name, child in module.named_children(): + if "temporal_transformer" not in sub_name: + fn_recursive_add_processors(f"{name}.{sub_name}", child, processors) + + return processors + + for name, module in self.named_children(): + if "temporal_transformer" not in name: + fn_recursive_add_processors(name, module, processors) + + return processors + + def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]): + r""" + Sets the attention processor to use to compute attention. + Parameters: + processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`): + The instantiated processor class or a dictionary of processor classes that will be set as the processor + for **all** `Attention` layers. + If `processor` is a dict, the key needs to define the path to the corresponding cross attention + processor. This is strongly recommended when setting trainable attention processors. + """ + count = len(self.attn_processors.keys()) + + if isinstance(processor, dict) and len(processor) != count: + raise ValueError( + f"A dict of processors was passed, but the number of processors {len(processor)} does not match the" + f" number of attention layers: {count}. Please make sure to pass {count} processor classes." + ) + + def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor): + if hasattr(module, "set_processor"): + if not isinstance(processor, dict): + module.set_processor(processor) + else: + module.set_processor(processor.pop(f"{name}.processor")) + + for sub_name, child in module.named_children(): + if "temporal_transformer" not in sub_name: + fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor) + + for name, module in self.named_children(): + if "temporal_transformer" not in name: + fn_recursive_attn_processor(name, module, processor) \ No newline at end of file diff --git a/animate/src/animatediff/models/unet_blocks.py b/animate/src/animatediff/models/unet_blocks.py new file mode 100644 index 0000000000000000000000000000000000000000..6f2ee01eacff950b6701bdb94d961fe36ebe2ca7 --- /dev/null +++ b/animate/src/animatediff/models/unet_blocks.py @@ -0,0 +1,843 @@ +# Adapted from https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/unet_2d_blocks.py + +from typing import Any, Dict, Optional, Tuple, Union + +import torch +from torch import nn + +from animatediff.models.attention import Transformer3DModel +from animatediff.models.motion_module import get_motion_module +from animatediff.models.resnet import Downsample3D, ResnetBlock3D, Upsample3D + + +def get_down_block( + down_block_type, + num_layers, + in_channels, + out_channels, + temb_channels, + add_downsample, + resnet_eps, + resnet_act_fn, + attn_num_head_channels, + resnet_groups=None, + cross_attention_dim=None, + downsample_padding=None, + dual_cross_attention=False, + use_linear_projection=False, + only_cross_attention=False, + upcast_attention=False, + resnet_time_scale_shift="default", + unet_use_cross_frame_attention=None, + unet_use_temporal_attention=None, + use_inflated_groupnorm=None, + use_motion_module=None, + motion_module_type=None, + motion_module_kwargs=None, +): + down_block_type = down_block_type[7:] if down_block_type.startswith("UNetRes") else down_block_type + if down_block_type == "DownBlock3D": + return DownBlock3D( + num_layers=num_layers, + in_channels=in_channels, + out_channels=out_channels, + temb_channels=temb_channels, + add_downsample=add_downsample, + resnet_eps=resnet_eps, + resnet_act_fn=resnet_act_fn, + resnet_groups=resnet_groups, + downsample_padding=downsample_padding, + resnet_time_scale_shift=resnet_time_scale_shift, + use_inflated_groupnorm=use_inflated_groupnorm, + use_motion_module=use_motion_module, + motion_module_type=motion_module_type, + motion_module_kwargs=motion_module_kwargs, + ) + elif down_block_type == "CrossAttnDownBlock3D": + if cross_attention_dim is None: + raise ValueError("cross_attention_dim must be specified for CrossAttnDownBlock3D") + return CrossAttnDownBlock3D( + num_layers=num_layers, + in_channels=in_channels, + out_channels=out_channels, + temb_channels=temb_channels, + add_downsample=add_downsample, + resnet_eps=resnet_eps, + resnet_act_fn=resnet_act_fn, + resnet_groups=resnet_groups, + downsample_padding=downsample_padding, + cross_attention_dim=cross_attention_dim, + attn_num_head_channels=attn_num_head_channels, + dual_cross_attention=dual_cross_attention, + use_linear_projection=use_linear_projection, + only_cross_attention=only_cross_attention, + upcast_attention=upcast_attention, + resnet_time_scale_shift=resnet_time_scale_shift, + unet_use_cross_frame_attention=unet_use_cross_frame_attention, + unet_use_temporal_attention=unet_use_temporal_attention, + use_inflated_groupnorm=use_inflated_groupnorm, + use_motion_module=use_motion_module, + motion_module_type=motion_module_type, + motion_module_kwargs=motion_module_kwargs, + ) + raise ValueError(f"{down_block_type} does not exist.") + + +def get_up_block( + up_block_type, + num_layers, + in_channels, + out_channels, + prev_output_channel, + temb_channels, + add_upsample, + resnet_eps, + resnet_act_fn, + attn_num_head_channels, + resnet_groups=None, + cross_attention_dim=None, + dual_cross_attention=False, + use_linear_projection=False, + only_cross_attention=False, + upcast_attention=False, + resnet_time_scale_shift="default", + unet_use_cross_frame_attention=None, + unet_use_temporal_attention=None, + use_inflated_groupnorm=None, + use_motion_module=None, + motion_module_type=None, + motion_module_kwargs=None, +): + up_block_type = up_block_type[7:] if up_block_type.startswith("UNetRes") else up_block_type + if up_block_type == "UpBlock3D": + return UpBlock3D( + num_layers=num_layers, + in_channels=in_channels, + out_channels=out_channels, + prev_output_channel=prev_output_channel, + temb_channels=temb_channels, + add_upsample=add_upsample, + resnet_eps=resnet_eps, + resnet_act_fn=resnet_act_fn, + resnet_groups=resnet_groups, + resnet_time_scale_shift=resnet_time_scale_shift, + use_inflated_groupnorm=use_inflated_groupnorm, + use_motion_module=use_motion_module, + motion_module_type=motion_module_type, + motion_module_kwargs=motion_module_kwargs, + ) + elif up_block_type == "CrossAttnUpBlock3D": + if cross_attention_dim is None: + raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlock3D") + return CrossAttnUpBlock3D( + num_layers=num_layers, + in_channels=in_channels, + out_channels=out_channels, + prev_output_channel=prev_output_channel, + temb_channels=temb_channels, + add_upsample=add_upsample, + resnet_eps=resnet_eps, + resnet_act_fn=resnet_act_fn, + resnet_groups=resnet_groups, + cross_attention_dim=cross_attention_dim, + attn_num_head_channels=attn_num_head_channels, + dual_cross_attention=dual_cross_attention, + use_linear_projection=use_linear_projection, + only_cross_attention=only_cross_attention, + upcast_attention=upcast_attention, + resnet_time_scale_shift=resnet_time_scale_shift, + unet_use_cross_frame_attention=unet_use_cross_frame_attention, + unet_use_temporal_attention=unet_use_temporal_attention, + use_inflated_groupnorm=use_inflated_groupnorm, + use_motion_module=use_motion_module, + motion_module_type=motion_module_type, + motion_module_kwargs=motion_module_kwargs, + ) + raise ValueError(f"{up_block_type} does not exist.") + + +class UNetMidBlock3DCrossAttn(nn.Module): + def __init__( + self, + in_channels: int, + temb_channels: int, + dropout: float = 0.0, + num_layers: int = 1, + resnet_eps: float = 1e-6, + resnet_time_scale_shift: str = "default", + resnet_act_fn: str = "swish", + resnet_groups: int = 32, + resnet_pre_norm: bool = True, + attn_num_head_channels=1, + output_scale_factor=1.0, + cross_attention_dim=1280, + dual_cross_attention=False, + use_linear_projection=False, + upcast_attention=False, + unet_use_cross_frame_attention=None, + unet_use_temporal_attention=None, + use_inflated_groupnorm=None, + use_motion_module=None, + motion_module_type=None, + motion_module_kwargs=None, + ): + super().__init__() + + self.has_cross_attention = True + self.attn_num_head_channels = attn_num_head_channels + resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32) + + # there is always at least one resnet + resnets = [ + ResnetBlock3D( + in_channels=in_channels, + out_channels=in_channels, + temb_channels=temb_channels, + eps=resnet_eps, + groups=resnet_groups, + dropout=dropout, + time_embedding_norm=resnet_time_scale_shift, + non_linearity=resnet_act_fn, + output_scale_factor=output_scale_factor, + pre_norm=resnet_pre_norm, + use_inflated_groupnorm=use_inflated_groupnorm, + ) + ] + attentions = [] + motion_modules = [] + + for _ in range(num_layers): + if dual_cross_attention: + raise NotImplementedError + attentions.append( + Transformer3DModel( + attn_num_head_channels, + in_channels // attn_num_head_channels, + in_channels=in_channels, + num_layers=1, + cross_attention_dim=cross_attention_dim, + norm_num_groups=resnet_groups, + use_linear_projection=use_linear_projection, + upcast_attention=upcast_attention, + unet_use_cross_frame_attention=unet_use_cross_frame_attention, + unet_use_temporal_attention=unet_use_temporal_attention, + ) + ) + motion_modules.append( + get_motion_module( + in_channels=in_channels, + motion_module_type=motion_module_type, + motion_module_kwargs=motion_module_kwargs, + ) + if use_motion_module + else None + ) + resnets.append( + ResnetBlock3D( + in_channels=in_channels, + out_channels=in_channels, + temb_channels=temb_channels, + eps=resnet_eps, + groups=resnet_groups, + dropout=dropout, + time_embedding_norm=resnet_time_scale_shift, + non_linearity=resnet_act_fn, + output_scale_factor=output_scale_factor, + pre_norm=resnet_pre_norm, + use_inflated_groupnorm=use_inflated_groupnorm, + ) + ) + + self.attentions = nn.ModuleList(attentions) + self.resnets = nn.ModuleList(resnets) + self.motion_modules = nn.ModuleList(motion_modules) + + def forward( + self, + hidden_states: torch.FloatTensor, + temb: Optional[torch.FloatTensor] = None, + encoder_hidden_states: Optional[torch.FloatTensor] = None, + attention_mask: Optional[torch.FloatTensor] = None, + cross_attention_kwargs: Optional[Dict[str, Any]] = None, + encoder_attention_mask: Optional[torch.FloatTensor] = None, + ) -> torch.FloatTensor: + hidden_states = self.resnets[0](hidden_states, temb) + for attn, resnet, motion_module in zip(self.attentions, self.resnets[1:], self.motion_modules): + hidden_states = attn( + hidden_states, + encoder_hidden_states=encoder_hidden_states, + cross_attention_kwargs=cross_attention_kwargs, + attention_mask=attention_mask, + encoder_attention_mask=encoder_attention_mask, + return_dict=False, + )[0] + if motion_module is not None: + hidden_states = motion_module( + hidden_states, + temb, + encoder_hidden_states=encoder_hidden_states, + ) + hidden_states = resnet(hidden_states, temb) + + return hidden_states + + +class CrossAttnDownBlock3D(nn.Module): + def __init__( + self, + in_channels: int, + out_channels: int, + temb_channels: int, + dropout: float = 0.0, + num_layers: int = 1, + transformer_layers_per_block: int = 1, + resnet_eps: float = 1e-6, + resnet_time_scale_shift: str = "default", + resnet_act_fn: str = "swish", + resnet_groups: int = 32, + resnet_pre_norm: bool = True, + attn_num_head_channels=1, + cross_attention_dim=1280, + output_scale_factor=1.0, + downsample_padding=1, + add_downsample=True, + dual_cross_attention=False, + use_linear_projection=False, + only_cross_attention=False, + upcast_attention=False, + unet_use_cross_frame_attention=None, + unet_use_temporal_attention=None, + use_inflated_groupnorm=None, + use_motion_module=None, + motion_module_type=None, + motion_module_kwargs=None, + ): + super().__init__() + resnets = [] + attentions = [] + motion_modules = [] + + self.has_cross_attention = True + self.attn_num_head_channels = attn_num_head_channels + + for i in range(num_layers): + in_channels = in_channels if i == 0 else out_channels + resnets.append( + ResnetBlock3D( + in_channels=in_channels, + out_channels=out_channels, + temb_channels=temb_channels, + eps=resnet_eps, + groups=resnet_groups, + dropout=dropout, + time_embedding_norm=resnet_time_scale_shift, + non_linearity=resnet_act_fn, + output_scale_factor=output_scale_factor, + pre_norm=resnet_pre_norm, + use_inflated_groupnorm=use_inflated_groupnorm, + ) + ) + if dual_cross_attention: + raise NotImplementedError + attentions.append( + Transformer3DModel( + num_attention_heads=attn_num_head_channels, + attention_head_dim=out_channels // attn_num_head_channels, + in_channels=out_channels, + num_layers=transformer_layers_per_block, + cross_attention_dim=cross_attention_dim, + norm_num_groups=resnet_groups, + use_linear_projection=use_linear_projection, + only_cross_attention=only_cross_attention, + upcast_attention=upcast_attention, + unet_use_cross_frame_attention=unet_use_cross_frame_attention, + unet_use_temporal_attention=unet_use_temporal_attention, + ) + ) + motion_modules.append( + get_motion_module( + in_channels=out_channels, + motion_module_type=motion_module_type, + motion_module_kwargs=motion_module_kwargs, + ) + if use_motion_module + else None + ) + + self.attentions = nn.ModuleList(attentions) + self.resnets = nn.ModuleList(resnets) + self.motion_modules = nn.ModuleList(motion_modules) + + if add_downsample: + self.downsamplers = nn.ModuleList( + [ + Downsample3D( + out_channels, + use_conv=True, + out_channels=out_channels, + padding=downsample_padding, + name="op", + ) + ] + ) + else: + self.downsamplers = None + + self.gradient_checkpointing = False + + def forward( + self, + hidden_states: torch.FloatTensor, + temb: Optional[torch.FloatTensor] = None, + encoder_hidden_states: Optional[torch.FloatTensor] = None, + attention_mask: Optional[torch.FloatTensor] = None, + cross_attention_kwargs: Optional[Dict[str, Any]] = None, + encoder_attention_mask: Optional[torch.FloatTensor] = None, + ) -> torch.FloatTensor: + output_states = () + + for resnet, attn, motion_module in zip(self.resnets, self.attentions, self.motion_modules): + if self.training and self.gradient_checkpointing: + + def create_custom_forward(module, return_dict=None): + def custom_forward(*inputs): + if return_dict is not None: + return module(*inputs, return_dict=return_dict) + else: + return module(*inputs) + + return custom_forward + + hidden_states = torch.utils.checkpoint.checkpoint( + create_custom_forward(resnet), hidden_states, temb + ) + hidden_states = torch.utils.checkpoint.checkpoint( + create_custom_forward(attn, return_dict=False), + hidden_states, + encoder_hidden_states, + )[0] + if motion_module is not None: + hidden_states = torch.utils.checkpoint.checkpoint( + create_custom_forward(motion_module), + hidden_states.requires_grad_(), + temb, + encoder_hidden_states, + ) + + else: + hidden_states = resnet(hidden_states, temb) + hidden_states = attn( + hidden_states, + encoder_hidden_states=encoder_hidden_states, + cross_attention_kwargs=cross_attention_kwargs, + attention_mask=attention_mask, + encoder_attention_mask=encoder_attention_mask, + return_dict=False, + )[0] + # add motion module + hidden_states = ( + motion_module(hidden_states, temb, encoder_hidden_states=encoder_hidden_states) + if motion_module is not None + else hidden_states + ) + + output_states = output_states + (hidden_states,) + + if self.downsamplers is not None: + for downsampler in self.downsamplers: + hidden_states = downsampler(hidden_states) + + output_states = output_states + (hidden_states,) + + return hidden_states, output_states + + +class DownBlock3D(nn.Module): + def __init__( + self, + in_channels: int, + out_channels: int, + temb_channels: int, + dropout: float = 0.0, + num_layers: int = 1, + resnet_eps: float = 1e-6, + resnet_time_scale_shift: str = "default", + resnet_act_fn: str = "swish", + resnet_groups: int = 32, + resnet_pre_norm: bool = True, + output_scale_factor=1.0, + add_downsample=True, + downsample_padding=1, + use_inflated_groupnorm=None, + use_motion_module=None, + motion_module_type=None, + motion_module_kwargs=None, + ): + super().__init__() + resnets = [] + motion_modules = [] + + for i in range(num_layers): + in_channels = in_channels if i == 0 else out_channels + resnets.append( + ResnetBlock3D( + in_channels=in_channels, + out_channels=out_channels, + temb_channels=temb_channels, + eps=resnet_eps, + groups=resnet_groups, + dropout=dropout, + time_embedding_norm=resnet_time_scale_shift, + non_linearity=resnet_act_fn, + output_scale_factor=output_scale_factor, + pre_norm=resnet_pre_norm, + use_inflated_groupnorm=use_inflated_groupnorm, + ) + ) + motion_modules.append( + get_motion_module( + in_channels=out_channels, + motion_module_type=motion_module_type, + motion_module_kwargs=motion_module_kwargs, + ) + if use_motion_module + else None + ) + + self.resnets = nn.ModuleList(resnets) + self.motion_modules = nn.ModuleList(motion_modules) + + if add_downsample: + self.downsamplers = nn.ModuleList( + [ + Downsample3D( + out_channels, + use_conv=True, + out_channels=out_channels, + padding=downsample_padding, + name="op", + ) + ] + ) + else: + self.downsamplers = None + + self.gradient_checkpointing = False + + def forward(self, hidden_states, temb=None, encoder_hidden_states=None): + output_states = () + + for resnet, motion_module in zip(self.resnets, self.motion_modules): + if self.training and self.gradient_checkpointing: + + def create_custom_forward(module): + def custom_forward(*inputs): + return module(*inputs) + + return custom_forward + + hidden_states = torch.utils.checkpoint.checkpoint( + create_custom_forward(resnet), hidden_states, temb + ) + if motion_module is not None: + hidden_states = torch.utils.checkpoint.checkpoint( + create_custom_forward(motion_module), + hidden_states.requires_grad_(), + temb, + encoder_hidden_states, + ) + else: + hidden_states = resnet(hidden_states, temb) + + # add motion module + if motion_module: + hidden_states = motion_module( + hidden_states, temb, encoder_hidden_states=encoder_hidden_states + ) + + output_states = output_states + (hidden_states,) + + if self.downsamplers is not None: + for downsampler in self.downsamplers: + hidden_states = downsampler(hidden_states) + + output_states = output_states + (hidden_states,) + + return hidden_states, output_states + + +class CrossAttnUpBlock3D(nn.Module): + def __init__( + self, + in_channels: int, + out_channels: int, + prev_output_channel: int, + temb_channels: int, + dropout: float = 0.0, + num_layers: int = 1, + transformer_layers_per_block: int = 1, + resnet_eps: float = 1e-6, + resnet_time_scale_shift: str = "default", + resnet_act_fn: str = "swish", + resnet_groups: int = 32, + resnet_pre_norm: bool = True, + attn_num_head_channels=1, + cross_attention_dim=1280, + output_scale_factor=1.0, + add_upsample=True, + dual_cross_attention=False, + use_linear_projection=False, + only_cross_attention=False, + upcast_attention=False, + unet_use_cross_frame_attention=None, + unet_use_temporal_attention=None, + use_inflated_groupnorm=None, + use_motion_module=None, + motion_module_type=None, + motion_module_kwargs=None, + ): + super().__init__() + resnets = [] + attentions = [] + motion_modules = [] + + self.has_cross_attention = True + self.attn_num_head_channels = attn_num_head_channels + + for i in range(num_layers): + res_skip_channels = in_channels if (i == num_layers - 1) else out_channels + resnet_in_channels = prev_output_channel if i == 0 else out_channels + + resnets.append( + ResnetBlock3D( + in_channels=resnet_in_channels + res_skip_channels, + out_channels=out_channels, + temb_channels=temb_channels, + eps=resnet_eps, + groups=resnet_groups, + dropout=dropout, + time_embedding_norm=resnet_time_scale_shift, + non_linearity=resnet_act_fn, + output_scale_factor=output_scale_factor, + pre_norm=resnet_pre_norm, + use_inflated_groupnorm=use_inflated_groupnorm, + ) + ) + if dual_cross_attention: + raise NotImplementedError + attentions.append( + Transformer3DModel( + attn_num_head_channels, + out_channels // attn_num_head_channels, + in_channels=out_channels, + num_layers=transformer_layers_per_block, + cross_attention_dim=cross_attention_dim, + norm_num_groups=resnet_groups, + use_linear_projection=use_linear_projection, + only_cross_attention=only_cross_attention, + upcast_attention=upcast_attention, + unet_use_cross_frame_attention=unet_use_cross_frame_attention, + unet_use_temporal_attention=unet_use_temporal_attention, + ) + ) + motion_modules.append( + get_motion_module( + in_channels=out_channels, + motion_module_type=motion_module_type, + motion_module_kwargs=motion_module_kwargs, + ) + if use_motion_module + else None + ) + + self.attentions = nn.ModuleList(attentions) + self.resnets = nn.ModuleList(resnets) + self.motion_modules = nn.ModuleList(motion_modules) + + if add_upsample: + self.upsamplers = nn.ModuleList( + [Upsample3D(out_channels, use_conv=True, out_channels=out_channels)] + ) + else: + self.upsamplers = None + + self.gradient_checkpointing = False + + def forward( + self, + hidden_states: torch.FloatTensor, + res_hidden_states_tuple: Tuple[torch.FloatTensor, ...], + temb: Optional[torch.FloatTensor] = None, + encoder_hidden_states: Optional[torch.FloatTensor] = None, + cross_attention_kwargs: Optional[Dict[str, Any]] = None, + upsample_size: Optional[int] = None, + attention_mask: Optional[torch.FloatTensor] = None, + encoder_attention_mask: Optional[torch.FloatTensor] = None, + ): + for resnet, attn, motion_module in zip(self.resnets, self.attentions, self.motion_modules): + # pop res hidden states + res_hidden_states = res_hidden_states_tuple[-1] + res_hidden_states_tuple = res_hidden_states_tuple[:-1] + hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1) + + if self.training and self.gradient_checkpointing: + + def create_custom_forward(module, return_dict=None): + def custom_forward(*inputs): + if return_dict is not None: + return module(*inputs, return_dict=return_dict) + else: + return module(*inputs) + + return custom_forward + + hidden_states = torch.utils.checkpoint.checkpoint( + create_custom_forward(resnet), hidden_states, temb + ) + hidden_states = torch.utils.checkpoint.checkpoint( + create_custom_forward(attn, return_dict=False), + hidden_states, + encoder_hidden_states, + )[0] + if motion_module is not None: + hidden_states = torch.utils.checkpoint.checkpoint( + create_custom_forward(motion_module), + hidden_states.requires_grad_(), + temb, + encoder_hidden_states, + ) + + else: + hidden_states = resnet(hidden_states, temb) + hidden_states = attn( + hidden_states, + encoder_hidden_states=encoder_hidden_states, + cross_attention_kwargs=cross_attention_kwargs, + attention_mask=attention_mask, + encoder_attention_mask=encoder_attention_mask, + return_dict=False, + )[0] + + # add motion module + if motion_module: + hidden_states = motion_module( + hidden_states, temb, encoder_hidden_states=encoder_hidden_states + ) + + if self.upsamplers is not None: + for upsampler in self.upsamplers: + hidden_states = upsampler(hidden_states, upsample_size) + + return hidden_states + + +class UpBlock3D(nn.Module): + def __init__( + self, + in_channels: int, + prev_output_channel: int, + out_channels: int, + temb_channels: int, + dropout: float = 0.0, + num_layers: int = 1, + resnet_eps: float = 1e-6, + resnet_time_scale_shift: str = "default", + resnet_act_fn: str = "swish", + resnet_groups: int = 32, + resnet_pre_norm: bool = True, + output_scale_factor=1.0, + add_upsample=True, + use_inflated_groupnorm=None, + use_motion_module=None, + motion_module_type=None, + motion_module_kwargs=None, + ): + super().__init__() + resnets = [] + motion_modules = [] + + for i in range(num_layers): + res_skip_channels = in_channels if (i == num_layers - 1) else out_channels + resnet_in_channels = prev_output_channel if i == 0 else out_channels + + resnets.append( + ResnetBlock3D( + in_channels=resnet_in_channels + res_skip_channels, + out_channels=out_channels, + temb_channels=temb_channels, + eps=resnet_eps, + groups=resnet_groups, + dropout=dropout, + time_embedding_norm=resnet_time_scale_shift, + non_linearity=resnet_act_fn, + output_scale_factor=output_scale_factor, + pre_norm=resnet_pre_norm, + use_inflated_groupnorm=use_inflated_groupnorm, + ) + ) + motion_modules.append( + get_motion_module( + in_channels=out_channels, + motion_module_type=motion_module_type, + motion_module_kwargs=motion_module_kwargs, + ) + if use_motion_module + else None + ) + + self.resnets = nn.ModuleList(resnets) + self.motion_modules = nn.ModuleList(motion_modules) + + if add_upsample: + self.upsamplers = nn.ModuleList( + [Upsample3D(out_channels, use_conv=True, out_channels=out_channels)] + ) + else: + self.upsamplers = None + + self.gradient_checkpointing = False + + def forward( + self, + hidden_states, + res_hidden_states_tuple, + temb=None, + upsample_size=None, + encoder_hidden_states=None, + ): + for resnet, motion_module in zip(self.resnets, self.motion_modules): + # pop res hidden states + res_hidden_states = res_hidden_states_tuple[-1] + res_hidden_states_tuple = res_hidden_states_tuple[:-1] + hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1) + + if self.training and self.gradient_checkpointing: + + def create_custom_forward(module): + def custom_forward(*inputs): + return module(*inputs) + + return custom_forward + + hidden_states = torch.utils.checkpoint.checkpoint( + create_custom_forward(resnet), hidden_states, temb + ) + if motion_module is not None: + hidden_states = torch.utils.checkpoint.checkpoint( + create_custom_forward(motion_module), + hidden_states.requires_grad_(), + temb, + encoder_hidden_states, + ) + else: + hidden_states = resnet(hidden_states, temb) + if motion_module: + hidden_states = motion_module( + hidden_states, temb, encoder_hidden_states=encoder_hidden_states + ) + + if self.upsamplers is not None: + for upsampler in self.upsamplers: + hidden_states = upsampler(hidden_states, upsample_size) + + return hidden_states diff --git a/animate/src/animatediff/pipelines/__init__.py b/animate/src/animatediff/pipelines/__init__.py new file mode 100644 index 0000000000000000000000000000000000000000..5cb74e5d3aeff6d09d36b56538e83a4935196eee --- /dev/null +++ b/animate/src/animatediff/pipelines/__init__.py @@ -0,0 +1,14 @@ +from .animation import AnimationPipeline, AnimationPipelineOutput +from .context import get_context_scheduler, get_total_steps, ordered_halving, uniform +from .ti import get_text_embeddings, load_text_embeddings + +__all__ = [ + "AnimationPipeline", + "AnimationPipelineOutput", + "get_context_scheduler", + "get_total_steps", + "ordered_halving", + "uniform", + "get_text_embeddings", + "load_text_embeddings", +] diff --git a/animate/src/animatediff/pipelines/animation.py b/animate/src/animatediff/pipelines/animation.py new file mode 100644 index 0000000000000000000000000000000000000000..31df800c0f4f29186627ea68e0f547f621718035 --- /dev/null +++ b/animate/src/animatediff/pipelines/animation.py @@ -0,0 +1,3451 @@ +# Adapted from https://github.com/showlab/Tune-A-Video/blob/main/tuneavideo/pipelines/pipeline_tuneavideo.py + +import inspect +import itertools +import logging +from dataclasses import dataclass +from typing import Any, Callable, Dict, List, Optional, Tuple, Union + +import numpy as np +import torch +from diffusers import LCMScheduler +from diffusers.configuration_utils import FrozenDict +from diffusers.image_processor import VaeImageProcessor +from diffusers.loaders import LoraLoaderMixin, TextualInversionLoaderMixin, StableDiffusionLoraLoaderMixin +from diffusers.models import AutoencoderKL, ControlNetModel +from diffusers.pipelines.pipeline_utils import DiffusionPipeline +from diffusers.schedulers import (DDIMScheduler, DPMSolverMultistepScheduler, + EulerAncestralDiscreteScheduler, + EulerDiscreteScheduler, LMSDiscreteScheduler, + PNDMScheduler) +from diffusers.utils import (BaseOutput, deprecate, is_accelerate_available, + is_accelerate_version) +from diffusers.utils.torch_utils import is_compiled_module, randn_tensor +from einops import rearrange +from packaging import version +from tqdm.rich import tqdm +from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer + +from animatediff.ip_adapter import IPAdapter, IPAdapterFull, IPAdapterPlus +from animatediff.models.attention import BasicTransformerBlock +from animatediff.models.unet import (UNet2DConditionModel, + UNetMidBlock3DCrossAttn) +from animatediff.models.unet_blocks import (CrossAttnDownBlock3D, + CrossAttnUpBlock3D, DownBlock3D, + UpBlock3D) +from animatediff.pipelines.context import (get_context_scheduler, + get_total_steps) +from animatediff.utils.model import nop_train +from animatediff.utils.pipeline import get_memory_format +from animatediff.utils.util import (end_profile, + get_tensor_interpolation_method, show_gpu, + start_profile, stopwatch_record, + stopwatch_start, stopwatch_stop) + +logger = logging.getLogger(__name__) + + + +C_REF_MODE = "write" + + +def torch_dfs(model: torch.nn.Module): + result = [model] + for child in model.children(): + result += torch_dfs(child) + return result + + +class PromptEncoder: + def __init__( + self, + pipe, + device, + latents_device, + num_videos_per_prompt, + do_classifier_free_guidance, + region_condi_list, + negative_prompt, + is_signle_prompt_mode, + clip_skip, + multi_uncond_mode + ): + self.pipe = pipe + self.is_single_prompt_mode=is_signle_prompt_mode + self.do_classifier_free_guidance = do_classifier_free_guidance + + uncond_num = 0 + if do_classifier_free_guidance: + if multi_uncond_mode: + uncond_num = len(region_condi_list) + else: + uncond_num = 1 + + ### text + + prompt_nums = [] + prompt_map_list = [] + prompt_list = [] + + for condi in region_condi_list: + _prompt_map = condi["prompt_map"] + prompt_map_list.append(_prompt_map) + _prompt_map = dict(sorted(_prompt_map.items())) + _prompt_list = [_prompt_map[key_frame] for key_frame in _prompt_map.keys()] + prompt_nums.append( len(_prompt_list) ) + prompt_list += _prompt_list + + prompt_embeds = pipe._encode_prompt( + prompt_list, + device, + num_videos_per_prompt, + do_classifier_free_guidance, + negative_prompt, + prompt_embeds=None, + negative_prompt_embeds=None, + clip_skip=clip_skip, + ).to(device = latents_device) + + self.prompt_embeds_dtype = prompt_embeds.dtype + + + if do_classifier_free_guidance: + negative, positive = prompt_embeds.chunk(2, 0) + negative = negative.chunk(negative.shape[0], 0) + positive = positive.chunk(positive.shape[0], 0) + else: + positive = prompt_embeds + positive = positive.chunk(positive.shape[0], 0) + + if pipe.ip_adapter: + pipe.ip_adapter.set_text_length(positive[0].shape[1]) + + + prompt_embeds_region_list = [] + + if do_classifier_free_guidance: + prompt_embeds_region_list = [ + { + 0:negative[0] + } + ] * uncond_num + prompt_embeds_region_list + + pos_index = 0 + for prompt_map, num in zip(prompt_map_list, prompt_nums): + prompt_embeds_map={} + pos = positive[pos_index:pos_index+num] + + for i, key_frame in enumerate(prompt_map): + prompt_embeds_map[key_frame] = pos[i] + + prompt_embeds_region_list.append( prompt_embeds_map ) + pos_index += num + + if do_classifier_free_guidance: + prompt_map_list = [ + { + 0:negative_prompt + } + ] * uncond_num + prompt_map_list + + self.prompt_map_list = prompt_map_list + self.prompt_embeds_region_list = prompt_embeds_region_list + + ### image + if pipe.ip_adapter: + + ip_im_nums = [] + ip_im_map_list = [] + ip_im_list = [] + + for condi in region_condi_list: + _ip_im_map = condi["ip_adapter_map"]["images"] + ip_im_map_list.append(_ip_im_map) + _ip_im_map = dict(sorted(_ip_im_map.items())) + _ip_im_list = [_ip_im_map[key_frame] for key_frame in _ip_im_map.keys()] + ip_im_nums.append( len(_ip_im_list) ) + ip_im_list += _ip_im_list + + positive, negative = pipe.ip_adapter.get_image_embeds(ip_im_list) + + positive = positive.to(device=latents_device) + negative = negative.to(device=latents_device) + + bs_embed, seq_len, _ = positive.shape + positive = positive.repeat(1, 1, 1) + positive = positive.view(bs_embed * 1, seq_len, -1) + + bs_embed, seq_len, _ = negative.shape + negative = negative.repeat(1, 1, 1) + negative = negative.view(bs_embed * 1, seq_len, -1) + + if do_classifier_free_guidance: + negative = negative.chunk(negative.shape[0], 0) + positive = positive.chunk(positive.shape[0], 0) + else: + positive = positive.chunk(positive.shape[0], 0) + + im_prompt_embeds_region_list = [] + + if do_classifier_free_guidance: + im_prompt_embeds_region_list = [ + { + 0:negative[0] + } + ] * uncond_num + im_prompt_embeds_region_list + + pos_index = 0 + for ip_im_map, num in zip(ip_im_map_list, ip_im_nums): + im_prompt_embeds_map={} + pos = positive[pos_index:pos_index+num] + + for i, key_frame in enumerate(ip_im_map): + im_prompt_embeds_map[key_frame] = pos[i] + + im_prompt_embeds_region_list.append( im_prompt_embeds_map ) + pos_index += num + + + if do_classifier_free_guidance: + ip_im_map_list = [ + { + 0:None + } + ] * uncond_num + ip_im_map_list + + + self.ip_im_map_list = ip_im_map_list + self.im_prompt_embeds_region_list = im_prompt_embeds_region_list + + + def _get_current_prompt_embeds_from_text( + self, + prompt_map, + prompt_embeds_map, + center_frame = None, + video_length : int = 0 + ): + + key_prev = list(prompt_map.keys())[-1] + key_next = list(prompt_map.keys())[0] + + for p in prompt_map.keys(): + if p > center_frame: + key_next = p + break + key_prev = p + + dist_prev = center_frame - key_prev + if dist_prev < 0: + dist_prev += video_length + dist_next = key_next - center_frame + if dist_next < 0: + dist_next += video_length + + if key_prev == key_next or dist_prev + dist_next == 0: + return prompt_embeds_map[key_prev] + + rate = dist_prev / (dist_prev + dist_next) + + return get_tensor_interpolation_method()( prompt_embeds_map[key_prev], prompt_embeds_map[key_next], rate ) + + def get_current_prompt_embeds_from_text( + self, + center_frame = None, + video_length : int = 0 + ): + outputs = () + for prompt_map, prompt_embeds_map in zip(self.prompt_map_list, self.prompt_embeds_region_list): + embs = self._get_current_prompt_embeds_from_text( + prompt_map, + prompt_embeds_map, + center_frame, + video_length) + outputs += (embs,) + + return outputs + + def _get_current_prompt_embeds_from_image( + self, + ip_im_map, + im_prompt_embeds_map, + center_frame = None, + video_length : int = 0 + ): + + key_prev = list(ip_im_map.keys())[-1] + key_next = list(ip_im_map.keys())[0] + + for p in ip_im_map.keys(): + if p > center_frame: + key_next = p + break + key_prev = p + + dist_prev = center_frame - key_prev + if dist_prev < 0: + dist_prev += video_length + dist_next = key_next - center_frame + if dist_next < 0: + dist_next += video_length + + if key_prev == key_next or dist_prev + dist_next == 0: + return im_prompt_embeds_map[key_prev] + + rate = dist_prev / (dist_prev + dist_next) + + return get_tensor_interpolation_method()( im_prompt_embeds_map[key_prev], im_prompt_embeds_map[key_next], rate) + + def get_current_prompt_embeds_from_image( + self, + center_frame = None, + video_length : int = 0 + ): + outputs=() + for prompt_map, prompt_embeds_map in zip(self.ip_im_map_list, self.im_prompt_embeds_region_list): + embs = self._get_current_prompt_embeds_from_image( + prompt_map, + prompt_embeds_map, + center_frame, + video_length) + outputs += (embs,) + + return outputs + + def get_current_prompt_embeds_single( + self, + context: List[int] = None, + video_length : int = 0 + ): + center_frame = context[len(context)//2] + text_emb = self.get_current_prompt_embeds_from_text(center_frame, video_length) + text_emb = torch.cat(text_emb) + if self.pipe.ip_adapter: + image_emb = self.get_current_prompt_embeds_from_image(center_frame, video_length) + image_emb = torch.cat(image_emb) + return torch.cat([text_emb,image_emb], dim=1) + else: + return text_emb + + def get_current_prompt_embeds_multi( + self, + context: List[int] = None, + video_length : int = 0 + ): + + emb_list = [] + for c in context: + t = self.get_current_prompt_embeds_from_text(c, video_length) + for i, emb in enumerate(t): + if i >= len(emb_list): + emb_list.append([]) + emb_list[i].append(emb) + + text_emb = [] + for emb in emb_list: + emb = torch.cat(emb) + text_emb.append(emb) + text_emb = torch.cat(text_emb) + + if self.pipe.ip_adapter == None: + return text_emb + + emb_list = [] + for c in context: + t = self.get_current_prompt_embeds_from_image(c, video_length) + for i, emb in enumerate(t): + if i >= len(emb_list): + emb_list.append([]) + emb_list[i].append(emb) + + image_emb = [] + for emb in emb_list: + emb = torch.cat(emb) + image_emb.append(emb) + image_emb = torch.cat(image_emb) + + return torch.cat([text_emb,image_emb], dim=1) + + def get_current_prompt_embeds( + self, + context: List[int] = None, + video_length : int = 0 + ): + return self.get_current_prompt_embeds_single(context,video_length) if self.is_single_prompt_mode else self.get_current_prompt_embeds_multi(context,video_length) + + def get_prompt_embeds_dtype(self): + return self.prompt_embeds_dtype + + def get_condi_size(self): + return len(self.prompt_embeds_region_list) + + +class RegionMask: + def __init__( + self, + region_list, + batch_size, + num_channels_latents, + video_length, + height, + width, + vae_scale_factor, + dtype, + device, + multi_uncond_mode + ): + shape = ( + batch_size, + num_channels_latents, + video_length, + height // vae_scale_factor, + width // vae_scale_factor, + ) + + def get_area(m:torch.Tensor): + area = torch.where(m == 1) + if len(area[0]) == 0 or len(area[1]) == 0: + return (0,0,0,0) + + ymin = min(area[0]) + ymax = max(area[0]) + xmin = min(area[1]) + xmax = max(area[1]) + h = ymax+1 - ymin + w = xmax+1 - xmin + + mod_h = (h + 7) // 8 * 8 + diff_h = mod_h - h + ymin -= diff_h + if ymin < 0: + ymin = 0 + h = mod_h + + mod_w = (w + 7) // 8 * 8 + diff_w = mod_w - w + xmin -= diff_w + if xmin < 0: + xmin = 0 + w = mod_w + + return (int(xmin), int(ymin), int(w), int(h)) + + + for r in region_list: + mask_latents = torch.zeros(shape) + cur = r["mask_images"] + area_info = None + if cur: + area_info = [ (0,0,0,0) for l in range(video_length)] + + for frame_no in cur: + mask = cur[frame_no] + mask = np.array(mask.convert("L"))[None, None, :] + mask = mask.astype(np.float32) / 255.0 + mask[mask < 0.5] = 0 + mask[mask >= 0.5] = 1 + mask = torch.from_numpy(mask) + mask = torch.nn.functional.interpolate( + mask, size=(height // vae_scale_factor, width // vae_scale_factor) + ) + area_info[frame_no] = get_area(mask[0][0]) + + mask_latents[:,:,frame_no,:,:] = mask + else: + mask_latents = torch.ones(shape) + + w = mask_latents.shape[4] + h = mask_latents.shape[3] + + r["mask_latents"] = mask_latents.to(device=device, dtype=dtype, non_blocking=True) + r["mask_images"] = None + r["area"] = area_info + r["latent_size"] = (w, h) + + self.region_list = region_list + + self.multi_uncond_mode = multi_uncond_mode + + self.cond2region = {} + for i,r in enumerate(self.region_list): + if r["src"] != -1: + self.cond2region[r["src"]] = i + + + def get_mask( + self, + region_index, + ): + return self.region_list[region_index]["mask_latents"] + + def get_region_from_layer( + self, + cond_layer, + cond_nums, + ): + if self.multi_uncond_mode: + cond_layer = cond_layer if cond_layer < cond_nums//2 else cond_layer - cond_nums//2 + else: + if cond_layer == 0: + return -1 #uncond for all layer + + cond_layer -= 1 + + if cond_layer not in self.cond2region: + logger.warn(f"unknown {cond_layer=}") + return -1 + + return self.cond2region[cond_layer] + + + def get_area( + self, + cond_layer, + cond_nums, + context, + ): + + if self.multi_uncond_mode: + cond_layer = cond_layer if cond_layer < cond_nums//2 else cond_layer - cond_nums//2 + else: + if cond_layer == 0: + return None,None + + cond_layer -= 1 + + + if cond_layer not in self.cond2region: + return None,None + + region_index = self.cond2region[cond_layer] + + if region_index == -1: + return None,None + + _,_,w,h = self.region_list[region_index]["area"][context[0]] + + l_w, l_h = self.region_list[region_index]["latent_size"] + + xy_list = [] + for c in context: + x,y,_,_ = self.region_list[region_index]["area"][c] + + if x + w > l_w: + x -= (x+w - l_w) + if y + h > l_h: + y -= (y+h - l_h) + + xy_list.append( (x,y) ) + + + if self.region_list[region_index]["area"]: + return (w,h), xy_list + else: + return None,None + + def get_crop_generation_rate( + self, + cond_layer, + cond_nums, + ): + + if self.multi_uncond_mode: + cond_layer = cond_layer if cond_layer < cond_nums//2 else cond_layer - cond_nums//2 + else: + if cond_layer == 0: + return 0 + + cond_layer -= 1 + + + if cond_layer not in self.cond2region: + return 0 + + region_index = self.cond2region[cond_layer] + + if region_index == -1: + return 0 + + return self.region_list[region_index]["crop_generation_rate"] + + +@dataclass +class AnimationPipelineOutput(BaseOutput): + videos: Union[torch.Tensor, np.ndarray] + + +class AnimationPipeline(DiffusionPipeline, TextualInversionLoaderMixin, StableDiffusionLoraLoaderMixin): + _optional_components = ["feature_extractor"] + ip_adapter: IPAdapter = None + + model_cpu_offload_seq = "text_encoder->unet->vae" + + def __init__( + self, + vae: AutoencoderKL, + text_encoder: CLIPTextModel, + tokenizer: CLIPTokenizer, + unet: UNet2DConditionModel, + scheduler: Union[ + DDIMScheduler, + PNDMScheduler, + LMSDiscreteScheduler, + EulerDiscreteScheduler, + EulerAncestralDiscreteScheduler, + DPMSolverMultistepScheduler, + ], + feature_extractor: CLIPImageProcessor, + controlnet_map: Dict[ str , ControlNetModel ]=None, + ): + super().__init__() + + if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1: + deprecation_message = ( + f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`" + f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure " + "to update the config accordingly as leaving `steps_offset` might led to incorrect results" + " in future versions. If you have downloaded this checkpoint from the Hugging Face Hub," + " it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`" + " file" + ) + deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False) + new_config = dict(scheduler.config) + new_config["steps_offset"] = 1 + scheduler._internal_dict = FrozenDict(new_config) + + if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True: + deprecation_message = ( + f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`." + " `clip_sample` should be set to False in the configuration file. Please make sure to update the" + " config accordingly as not setting `clip_sample` in the config might lead to incorrect results in" + " future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very" + " nice if you could open a Pull request for the `scheduler/scheduler_config.json` file" + ) + deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False) + new_config = dict(scheduler.config) + new_config["clip_sample"] = False + scheduler._internal_dict = FrozenDict(new_config) + + is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse( + version.parse(unet.config._diffusers_version).base_version + ) < version.parse("0.9.0.dev0") + is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64 + if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64: + deprecation_message = ( + "The configuration file of the unet has set the default `sample_size` to smaller than" + " 64 which seems highly unlikely. If your checkpoint is a fine-tuned version of any of the" + " following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-" + " CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5" + " \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the" + " configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`" + " in the config might lead to incorrect results in future versions. If you have downloaded this" + " checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for" + " the `unet/config.json` file" + ) + deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False) + new_config = dict(unet.config) + new_config["sample_size"] = 64 + unet._internal_dict = FrozenDict(new_config) + + self.register_modules( + vae=vae, + text_encoder=text_encoder, + tokenizer=tokenizer, + unet=unet, + scheduler=scheduler, + feature_extractor=feature_extractor, + ) + self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1) + self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor) + self.control_image_processor = VaeImageProcessor( + vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False + ) + self.controlnet_map = controlnet_map + + + def enable_vae_slicing(self): + r""" + Enable sliced VAE decoding. + + When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several + steps. This is useful to save some memory and allow larger batch sizes. + """ + self.vae.enable_slicing() + + def disable_vae_slicing(self): + r""" + Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to + computing decoding in one step. + """ + self.vae.disable_slicing() + + def enable_vae_tiling(self): + r""" + Enable tiled VAE decoding. + + When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in + several steps. This is useful to save a large amount of memory and to allow the processing of larger images. + """ + self.vae.enable_tiling() + + def disable_vae_tiling(self): + r""" + Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to + computing decoding in one step. + """ + self.vae.disable_tiling() + + def __enable_model_cpu_offload(self, gpu_id=0): + r""" + Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared + to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward` + method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with + `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`. + """ + if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"): + from accelerate import cpu_offload_with_hook + else: + raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.") + + device = torch.device(f"cuda:{gpu_id}") + + if self.device.type != "cpu": + self.to("cpu", silence_dtype_warnings=True) + torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist) + + hook = None + for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]: + _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook) + + if self.safety_checker is not None: + _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook) + + # control net hook has be manually offloaded as it alternates with unet + cpu_offload_with_hook(self.controlnet, device) + + # We'll offload the last model manually. + self.final_offload_hook = hook + + @property + def _execution_device(self): + r""" + Returns the device on which the pipeline's models will be executed. After calling + `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module + hooks. + """ + if not hasattr(self.unet, "_hf_hook"): + return self.device + for module in self.unet.modules(): + if ( + hasattr(module, "_hf_hook") + and hasattr(module._hf_hook, "execution_device") + and module._hf_hook.execution_device is not None + ): + return torch.device(module._hf_hook.execution_device) + return self.device + + def _encode_prompt( + self, + prompt, + device, + num_videos_per_prompt: int = 1, + do_classifier_free_guidance: bool = False, + negative_prompt=None, + max_embeddings_multiples=3, + prompt_embeds: Optional[torch.FloatTensor] = None, + negative_prompt_embeds: Optional[torch.FloatTensor] = None, + clip_skip: int = 1, + ): + r""" + Encodes the prompt into text encoder hidden states. + + Args: + prompt (`str` or `list(int)`): + prompt to be encoded + device: (`torch.device`): + torch device + num_videos_per_prompt (`int`): + number of videos that should be generated per prompt + do_classifier_free_guidance (`bool`): + whether to use classifier free guidance or not + negative_prompt (`str` or `List[str]`): + The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored + if `guidance_scale` is less than `1`). + max_embeddings_multiples (`int`, *optional*, defaults to `3`): + The max multiple length of prompt embeddings compared to the max output length of text encoder. + """ + from ..utils.lpw_stable_diffusion import get_weighted_text_embeddings + + if prompt is not None and isinstance(prompt, str): + batch_size = 1 + elif prompt is not None and isinstance(prompt, list): + batch_size = len(prompt) + else: + batch_size = prompt_embeds.shape[0] + + if negative_prompt_embeds is None: + if negative_prompt is None: + negative_prompt = [""] * batch_size + elif isinstance(negative_prompt, str): + negative_prompt = [negative_prompt] * batch_size + if batch_size != len(negative_prompt): + raise ValueError( + f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:" + f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches" + " the batch size of `prompt`." + ) + if prompt_embeds is None or negative_prompt_embeds is None: + if isinstance(self, TextualInversionLoaderMixin): + prompt = self.maybe_convert_prompt(prompt, self.tokenizer) + if do_classifier_free_guidance and negative_prompt_embeds is None: + negative_prompt = self.maybe_convert_prompt(negative_prompt, self.tokenizer) + + prompt_embeds1, negative_prompt_embeds1 = get_weighted_text_embeddings( + pipe=self, + prompt=prompt, + uncond_prompt=negative_prompt if do_classifier_free_guidance else None, + max_embeddings_multiples=max_embeddings_multiples, + clip_skip=clip_skip + ) + if prompt_embeds is None: + prompt_embeds = prompt_embeds1 + if negative_prompt_embeds is None: + negative_prompt_embeds = negative_prompt_embeds1 + + bs_embed, seq_len, _ = prompt_embeds.shape + # duplicate text embeddings for each generation per prompt, using mps friendly method + prompt_embeds = prompt_embeds.repeat(1, num_videos_per_prompt, 1) + prompt_embeds = prompt_embeds.view(bs_embed * num_videos_per_prompt, seq_len, -1) + + if do_classifier_free_guidance: + bs_embed, seq_len, _ = negative_prompt_embeds.shape + negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_videos_per_prompt, 1) + negative_prompt_embeds = negative_prompt_embeds.view(bs_embed * num_videos_per_prompt, seq_len, -1) + prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds]) + + return prompt_embeds + + def __encode_prompt( + self, + prompt, + device, + num_videos_per_prompt: int = 1, + do_classifier_free_guidance: bool = False, + negative_prompt=None, + prompt_embeds: Optional[torch.FloatTensor] = None, + negative_prompt_embeds: Optional[torch.FloatTensor] = None, + lora_scale: Optional[float] = None, + clip_skip: int = 1, + ): + # set lora scale so that monkey patched LoRA + # function of text encoder can correctly access it + if lora_scale is not None and isinstance(self, LoraLoaderMixin): + self._lora_scale = lora_scale + + batch_size = len(prompt) if isinstance(prompt, list) else 1 + + if prompt_embeds is None: + # textual inversion: procecss multi-vector tokens if necessary + if isinstance(self, TextualInversionLoaderMixin): + prompt = self.maybe_convert_prompt(prompt, self.tokenizer) + + text_inputs = self.tokenizer( + prompt, + padding="max_length", + max_length=self.tokenizer.model_max_length, + truncation=True, + return_tensors="pt", + ) + text_input_ids = text_inputs.input_ids + untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids + + if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal( + text_input_ids, untruncated_ids + ): + removed_text = self.tokenizer.batch_decode( + untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1] + ) + logger.warning( + "The following part of your input was truncated because CLIP can only handle sequences up to" + f" {self.tokenizer.model_max_length} tokens: {removed_text}" + ) + + if ( + hasattr(self.text_encoder.config, "use_attention_mask") + and self.text_encoder.config.use_attention_mask + ): + attention_mask = text_inputs.attention_mask.to(device) + else: + attention_mask = None + + prompt_embeds = self.text_encoder( + text_input_ids.to(device), + attention_mask=attention_mask, + clip_skip=clip_skip, + ) + prompt_embeds = prompt_embeds[0] + + bs_embed, seq_len, _ = prompt_embeds.shape + # duplicate text embeddings for each generation per prompt, using mps friendly method + prompt_embeds = prompt_embeds.repeat(1, num_videos_per_prompt, 1) + prompt_embeds = prompt_embeds.view(bs_embed * num_videos_per_prompt, seq_len, -1) + + # get unconditional embeddings for classifier free guidance + if do_classifier_free_guidance and negative_prompt_embeds is None: + uncond_tokens: List[str] + if negative_prompt is None: + uncond_tokens = [""] * batch_size + elif prompt is not None and type(prompt) is not type(negative_prompt): + raise TypeError( + f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !=" + f" {type(prompt)}." + ) + elif isinstance(negative_prompt, str): + uncond_tokens = [negative_prompt] + elif batch_size != len(negative_prompt): + raise ValueError( + f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:" + f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches" + " the batch size of `prompt`." + ) + else: + uncond_tokens = negative_prompt + + # textual inversion: procecss multi-vector tokens if necessary + if isinstance(self, TextualInversionLoaderMixin): + uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer) + + max_length = prompt_embeds.shape[1] + uncond_input = self.tokenizer( + uncond_tokens, + padding="max_length", + max_length=max_length, + truncation=True, + return_tensors="pt", + ) + uncond_input_ids = uncond_input.input_ids + + if ( + hasattr(self.text_encoder.config, "use_attention_mask") + and self.text_encoder.config.use_attention_mask + ): + attention_mask = uncond_input.attention_mask.to(device) + else: + attention_mask = None + + negative_prompt_embeds = self.text_encoder( + uncond_input_ids.to(device), + attention_mask=attention_mask, + clip_skip=clip_skip, + ) + negative_prompt_embeds = negative_prompt_embeds[0] + + if do_classifier_free_guidance: + # duplicate unconditional embeddings for each generation per prompt, using mps friendly method + seq_len = negative_prompt_embeds.shape[1] + + negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device) + + negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_videos_per_prompt, 1) + negative_prompt_embeds = negative_prompt_embeds.view( + batch_size * num_videos_per_prompt, seq_len, -1 + ) + + # For classifier free guidance, we need to do two forward passes. + # Here we concatenate the unconditional and text embeddings into a single batch + # to avoid doing two forward passes + prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds]) + + return prompt_embeds + + def interpolate_latents(self, latents: torch.Tensor, interpolation_factor:int, device ): + if interpolation_factor < 2: + return latents + + new_latents = torch.zeros( + (latents.shape[0],latents.shape[1],((latents.shape[2]-1) * interpolation_factor)+1, latents.shape[3],latents.shape[4]), + device=latents.device, + dtype=latents.dtype, + ) + + org_video_length = latents.shape[2] + rate = [i/interpolation_factor for i in range(interpolation_factor)][1:] + + new_index = 0 + + v0 = None + v1 = None + + for i0,i1 in zip( range( org_video_length ),range( org_video_length )[1:] ): + v0 = latents[:,:,i0,:,:] + v1 = latents[:,:,i1,:,:] + + new_latents[:,:,new_index,:,:] = v0 + new_index += 1 + + for f in rate: + v = get_tensor_interpolation_method()(v0.to(device=device),v1.to(device=device),f) + new_latents[:,:,new_index,:,:] = v.to(latents.device) + new_index += 1 + + new_latents[:,:,new_index,:,:] = v1 + new_index += 1 + + return new_latents + + + + def decode_latents(self, latents: torch.Tensor): + video_length = latents.shape[2] + latents = 1 / self.vae.config.scaling_factor * latents + latents = rearrange(latents, "b c f h w -> (b f) c h w") + # video = self.vae.decode(latents).sample + video = [] + for frame_idx in range(latents.shape[0]): + video.append( + self.vae.decode(latents[frame_idx : frame_idx + 1].to(self.vae.device, self.vae.dtype)).sample.cpu() + ) + video = torch.cat(video) + video = rearrange(video, "(b f) c h w -> b c f h w", f=video_length) + video = (video / 2 + 0.5).clamp(0, 1) + # we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16 + video = video.float().numpy() + return video + + def prepare_extra_step_kwargs(self, generator, eta): + # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature + # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers. + # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502 + # and should be between [0, 1] + + accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys()) + extra_step_kwargs = {} + if accepts_eta: + extra_step_kwargs["eta"] = eta + + # check if the scheduler accepts generator + accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys()) + if accepts_generator: + extra_step_kwargs["generator"] = generator + return extra_step_kwargs + + def check_inputs( + self, + prompt, + height, + width, + callback_steps, + negative_prompt=None, + prompt_embeds=None, + negative_prompt_embeds=None, + ): + if height % 8 != 0 or width % 8 != 0: + raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.") + + if callback_steps is not None: + if not isinstance(callback_steps, list): + raise ValueError("`callback_steps` has to be a list of positive integers.") + for callback_step in callback_steps: + if not isinstance(callback_step, int) or callback_step <= 0: + raise ValueError("`callback_steps` has to be a list of positive integers.") + + if prompt is not None and prompt_embeds is not None: + raise ValueError( + f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to" + " only forward one of the two." + ) + elif prompt is None and prompt_embeds is None: + raise ValueError( + "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined." + ) + elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)): + raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}") + + if negative_prompt is not None and negative_prompt_embeds is not None: + raise ValueError( + f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:" + f" {negative_prompt_embeds}. Please make sure to only forward one of the two." + ) + + if prompt_embeds is not None and negative_prompt_embeds is not None: + if prompt_embeds.shape != negative_prompt_embeds.shape: + raise ValueError( + "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but" + f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`" + f" {negative_prompt_embeds.shape}." + ) + + def prepare_image( + self, + image, + width, + height, + batch_size, + num_images_per_prompt, + device, + dtype, + do_classifier_free_guidance=False, + guess_mode=False, + ): + image = self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32) + image_batch_size = image.shape[0] + + if image_batch_size == 1: + repeat_by = batch_size + else: + # image batch size is the same as prompt batch size + repeat_by = num_images_per_prompt + + image = image.repeat_interleave(repeat_by, dim=0) + + image = image.to(device=device, dtype=dtype) + + #if do_classifier_free_guidance and not guess_mode: + # image = torch.cat([image] * 2) + + return image + + def prepare_ref_image( + self, + image, + width, + height, + batch_size, + num_images_per_prompt, + device, + dtype, + do_classifier_free_guidance=False, + guess_mode=False, + ): + image = self.image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32) + image_batch_size = image.shape[0] + + if image_batch_size == 1: + repeat_by = batch_size + else: + # image batch size is the same as prompt batch size + repeat_by = num_images_per_prompt + + image = image.repeat_interleave(repeat_by, dim=0) + + image = image.to(device=device, dtype=dtype) + + if do_classifier_free_guidance and not guess_mode: + image = torch.cat([image] * 2) + + return image + + def prepare_latents( + self, + batch_size, + num_channels_latents, + video_length, + height, + width, + dtype, + device, + generator, + img2img_map, + timestep, + latents=None, + is_strength_max=True, + return_noise=True, + return_image_latents=True, + ): + shape = ( + batch_size, + num_channels_latents, + video_length, + height // self.vae_scale_factor, + width // self.vae_scale_factor, + ) + if isinstance(generator, list) and len(generator) != batch_size: + raise ValueError( + f"You have passed a list of generators of length {len(generator)}, but requested an effective batch" + f" size of {batch_size}. Make sure the batch size matches the length of the generators." + ) + + image_latents = None + + if img2img_map: + image_latents = torch.zeros(shape, device=device, dtype=dtype) + for frame_no in img2img_map["images"]: + img = img2img_map["images"][frame_no] + img = self.image_processor.preprocess(img) + img = img.to(device="cuda", dtype=self.vae.dtype) + img = self.vae.encode(img).latent_dist.sample(generator) + img = self.vae.config.scaling_factor * img + img = torch.cat([img], dim=0) + image_latents[:,:,frame_no,:,:] = img.to(device=device, dtype=dtype) + + else: + is_strength_max = True + + + if latents is None: + noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype) + latents = noise if is_strength_max else self.scheduler.add_noise(image_latents, noise, timestep) + latents = latents * self.scheduler.init_noise_sigma if is_strength_max else latents + else: + noise = latents.to(device) + latents = noise * self.scheduler.init_noise_sigma + + outputs = (latents.to(device, dtype),) + + if return_noise: + outputs += (noise.to(device, dtype),) + + if return_image_latents: + if image_latents is not None: + outputs += (image_latents.to(device, dtype),) + else: + outputs += (None,) + + + return outputs + + + # from diffusers/examples/community/stable_diffusion_controlnet_reference.py + def prepare_ref_latents(self, refimage, batch_size, dtype, device, generator, do_classifier_free_guidance): + refimage = refimage.to(device=device, dtype=self.vae.dtype) + + # encode the mask image into latents space so we can concatenate it to the latents + if isinstance(generator, list): + ref_image_latents = [ + self.vae.encode(refimage[i : i + 1]).latent_dist.sample(generator=generator[i]) + for i in range(batch_size) + ] + ref_image_latents = torch.cat(ref_image_latents, dim=0) + else: + ref_image_latents = self.vae.encode(refimage).latent_dist.sample(generator=generator) + ref_image_latents = self.vae.config.scaling_factor * ref_image_latents + + ref_image_latents = ref_image_latents.to(device=device, dtype=dtype) + + # duplicate mask and ref_image_latents for each generation per prompt, using mps friendly method + if ref_image_latents.shape[0] < batch_size: + if not batch_size % ref_image_latents.shape[0] == 0: + raise ValueError( + "The passed images and the required batch size don't match. Images are supposed to be duplicated" + f" to a total batch size of {batch_size}, but {ref_image_latents.shape[0]} images were passed." + " Make sure the number of images that you pass is divisible by the total requested batch size." + ) + ref_image_latents = ref_image_latents.repeat(batch_size // ref_image_latents.shape[0], 1, 1, 1) + + ref_image_latents = torch.cat([ref_image_latents] * 2) if do_classifier_free_guidance else ref_image_latents + + # aligning device to prevent device errors when concating it with the latent model input + ref_image_latents = ref_image_latents.to(device=device, dtype=dtype) + return ref_image_latents + + # from diffusers/examples/community/stable_diffusion_controlnet_reference.py + def prepare_controlnet_ref_only_without_motion( + self, + ref_image_latents, + batch_size, + num_images_per_prompt, + do_classifier_free_guidance, + attention_auto_machine_weight, + gn_auto_machine_weight, + style_fidelity, + reference_attn, + reference_adain, + _scale_pattern, + region_num + ): + global C_REF_MODE + # 9. Modify self attention and group norm + C_REF_MODE = "write" + uc_mask = ( + torch.Tensor([1] * batch_size * num_images_per_prompt + [0] * batch_size * num_images_per_prompt * (region_num-1)) + .type_as(ref_image_latents) + .bool() + ) + + _scale_pattern = _scale_pattern * (batch_size // len(_scale_pattern) + 1) + _scale_pattern = _scale_pattern[:batch_size] + _rev_pattern = [1-i for i in _scale_pattern] + + scale_pattern_double = torch.tensor(_scale_pattern*region_num).to(self.device, dtype=self.unet.dtype) + rev_pattern_double = torch.tensor(_rev_pattern*region_num).to(self.device, dtype=self.unet.dtype) + scale_pattern = torch.tensor(_scale_pattern).to(self.device, dtype=self.unet.dtype) + rev_pattern = torch.tensor(_rev_pattern).to(self.device, dtype=self.unet.dtype) + + + def hacked_basic_transformer_inner_forward( + self, + hidden_states: torch.FloatTensor, + attention_mask: Optional[torch.FloatTensor] = None, + encoder_hidden_states: Optional[torch.FloatTensor] = None, + encoder_attention_mask: Optional[torch.FloatTensor] = None, + timestep: Optional[torch.LongTensor] = None, + cross_attention_kwargs: Dict[str, Any] = None, + video_length=None, + ): + if self.use_ada_layer_norm: + norm_hidden_states = self.norm1(hidden_states, timestep) + else: + norm_hidden_states = self.norm1(hidden_states) + + # 1. Self-Attention + cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {} + if self.unet_use_cross_frame_attention: + cross_attention_kwargs["video_length"] = video_length + + if self.only_cross_attention: + attn_output = self.attn1( + norm_hidden_states, + encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None, + attention_mask=attention_mask, + **cross_attention_kwargs, + ) + else: + if C_REF_MODE == "write": + self.bank.append(norm_hidden_states.detach().clone()) + attn_output = self.attn1( + norm_hidden_states, + encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None, + attention_mask=attention_mask, + **cross_attention_kwargs, + ) + if C_REF_MODE == "read": + if attention_auto_machine_weight > self.attn_weight: + attn_output_uc = self.attn1( + norm_hidden_states, + encoder_hidden_states=torch.cat([norm_hidden_states] + self.bank, dim=1), + # attention_mask=attention_mask, + **cross_attention_kwargs, + ) + + if style_fidelity > 0: + attn_output_c = attn_output_uc.clone() + + if do_classifier_free_guidance: + attn_output_c[uc_mask] = self.attn1( + norm_hidden_states[uc_mask], + encoder_hidden_states=norm_hidden_states[uc_mask], + **cross_attention_kwargs, + ) + + attn_output = style_fidelity * attn_output_c + (1.0 - style_fidelity) * attn_output_uc + + else: + attn_output = attn_output_uc + + attn_org = self.attn1( + norm_hidden_states, + encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None, + attention_mask=attention_mask, + **cross_attention_kwargs, + ) + + attn_output = scale_pattern_double[:,None,None] * attn_output + rev_pattern_double[:,None,None] * attn_org + + else: + attn_output = self.attn1( + norm_hidden_states, + encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None, + attention_mask=attention_mask, + **cross_attention_kwargs, + ) + + self.bank.clear() + + hidden_states = attn_output + hidden_states + + if self.attn2 is not None: + norm_hidden_states = ( + self.norm2(hidden_states, timestep) if self.use_ada_layer_norm else self.norm2(hidden_states) + ) + + # 2. Cross-Attention + attn_output = self.attn2( + norm_hidden_states, + encoder_hidden_states=encoder_hidden_states, + attention_mask=encoder_attention_mask, + **cross_attention_kwargs, + ) + hidden_states = attn_output + hidden_states + + # 3. Feed-forward + hidden_states = self.ff(self.norm3(hidden_states)) + hidden_states + + # 4. Temporal-Attention + if self.unet_use_temporal_attention: + d = hidden_states.shape[1] + hidden_states = rearrange(hidden_states, "(b f) d c -> (b d) f c", f=video_length) + norm_hidden_states = ( + self.norm_temp(hidden_states, timestep) + if self.use_ada_layer_norm + else self.norm_temp(hidden_states) + ) + hidden_states = self.attn_temp(norm_hidden_states) + hidden_states + hidden_states = rearrange(hidden_states, "(b d) f c -> (b f) d c", d=d) + + return hidden_states + + def hacked_mid_forward( + self, + hidden_states: torch.FloatTensor, + temb: Optional[torch.FloatTensor] = None, + encoder_hidden_states: Optional[torch.FloatTensor] = None, + attention_mask: Optional[torch.FloatTensor] = None, + cross_attention_kwargs: Optional[Dict[str, Any]] = None, + encoder_attention_mask: Optional[torch.FloatTensor] = None, + ) -> torch.FloatTensor: + + eps = 1e-6 + + hidden_states = self.resnets[0](hidden_states, temb) + for attn, resnet, motion_module in zip(self.attentions, self.resnets[1:], self.motion_modules): + hidden_states = attn( + hidden_states, + encoder_hidden_states=encoder_hidden_states, + cross_attention_kwargs=cross_attention_kwargs, + attention_mask=attention_mask, + encoder_attention_mask=encoder_attention_mask, + return_dict=False, + )[0] + + x = hidden_states + + if C_REF_MODE == "write": + if gn_auto_machine_weight >= self.gn_weight: + var, mean = torch.var_mean(x, dim=(3, 4), keepdim=True, correction=0) + self.mean_bank.append(mean) + self.var_bank.append(var) + if C_REF_MODE == "read": + if len(self.mean_bank) > 0 and len(self.var_bank) > 0: + var, mean = torch.var_mean(x, dim=(3, 4), keepdim=True, correction=0) + std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5 + mean_acc = sum(self.mean_bank) / float(len(self.mean_bank)) + var_acc = sum(self.var_bank) / float(len(self.var_bank)) + std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5 + x_uc = (((x - mean) / std) * std_acc) + mean_acc + x_c = x_uc.clone() + if do_classifier_free_guidance and style_fidelity > 0: + + f = x.shape[2] + x_c = rearrange(x_c, "b c f h w -> (b f) c h w") + x = rearrange(x, "b c f h w -> (b f) c h w") + + x_c[uc_mask] = x[uc_mask] + + x_c = rearrange(x_c, "(b f) c h w -> b c f h w", f=f) + x = rearrange(x, "(b f) c h w -> b c f h w", f=f) + + mod_x = style_fidelity * x_c + (1.0 - style_fidelity) * x_uc + + x = scale_pattern[None,None,:,None,None] * mod_x + rev_pattern[None,None,:,None,None] * x + + self.mean_bank = [] + self.var_bank = [] + + hidden_states = x + + if motion_module is not None: + hidden_states = motion_module( + hidden_states, + temb, + encoder_hidden_states=encoder_hidden_states, + ) + + hidden_states = resnet(hidden_states, temb) + + return hidden_states + + + def hack_CrossAttnDownBlock3D_forward( + self, + hidden_states: torch.FloatTensor, + temb: Optional[torch.FloatTensor] = None, + encoder_hidden_states: Optional[torch.FloatTensor] = None, + attention_mask: Optional[torch.FloatTensor] = None, + cross_attention_kwargs: Optional[Dict[str, Any]] = None, + encoder_attention_mask: Optional[torch.FloatTensor] = None, + ): + eps = 1e-6 + + # TODO(Patrick, William) - attention mask is not used + output_states = () + + for i, (resnet, attn, motion_module) in enumerate(zip(self.resnets, self.attentions, self.motion_modules)): + hidden_states = resnet(hidden_states, temb) + + hidden_states = attn( + hidden_states, + encoder_hidden_states=encoder_hidden_states, + cross_attention_kwargs=cross_attention_kwargs, + attention_mask=attention_mask, + encoder_attention_mask=encoder_attention_mask, + return_dict=False, + )[0] + + if C_REF_MODE == "write": + if gn_auto_machine_weight >= self.gn_weight: + var, mean = torch.var_mean(hidden_states, dim=(3, 4), keepdim=True, correction=0) + self.mean_bank.append([mean]) + self.var_bank.append([var]) + if C_REF_MODE == "read": + if len(self.mean_bank) > 0 and len(self.var_bank) > 0: + var, mean = torch.var_mean(hidden_states, dim=(3, 4), keepdim=True, correction=0) + std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5 + mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i])) + var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i])) + std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5 + hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc + hidden_states_c = hidden_states_uc.clone() + if do_classifier_free_guidance and style_fidelity > 0: + + f = hidden_states.shape[2] + hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w") + hidden_states_c = rearrange(hidden_states_c, "b c f h w -> (b f) c h w") + + hidden_states_c[uc_mask] = hidden_states[uc_mask] + + hidden_states = rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f) + hidden_states_c = rearrange(hidden_states_c, "(b f) c h w -> b c f h w", f=f) + + mod_hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc + + hidden_states = scale_pattern[None,None,:,None,None] * mod_hidden_states + rev_pattern[None,None,:,None,None] * hidden_states + + # add motion module + hidden_states = ( + motion_module(hidden_states, temb, encoder_hidden_states=encoder_hidden_states) + if motion_module is not None + else hidden_states + ) + + output_states = output_states + (hidden_states,) + + if C_REF_MODE == "read": + self.mean_bank = [] + self.var_bank = [] + + if self.downsamplers is not None: + for downsampler in self.downsamplers: + hidden_states = downsampler(hidden_states) + + output_states = output_states + (hidden_states,) + + return hidden_states, output_states + + def hacked_DownBlock3D_forward(self, hidden_states, temb=None, encoder_hidden_states=None): + eps = 1e-6 + + output_states = () + + for i, (resnet, motion_module) in enumerate(zip(self.resnets, self.motion_modules)): + hidden_states = resnet(hidden_states, temb) + + if C_REF_MODE == "write": + if gn_auto_machine_weight >= self.gn_weight: + var, mean = torch.var_mean(hidden_states, dim=(3, 4), keepdim=True, correction=0) + self.mean_bank.append([mean]) + self.var_bank.append([var]) + if C_REF_MODE == "read": + if len(self.mean_bank) > 0 and len(self.var_bank) > 0: + var, mean = torch.var_mean(hidden_states, dim=(3, 4), keepdim=True, correction=0) + std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5 + mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i])) + var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i])) + std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5 + hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc + hidden_states_c = hidden_states_uc.clone() + if do_classifier_free_guidance and style_fidelity > 0: + + f = hidden_states.shape[2] + hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w") + hidden_states_c = rearrange(hidden_states_c, "b c f h w -> (b f) c h w") + + hidden_states_c[uc_mask] = hidden_states[uc_mask] + + hidden_states = rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f) + hidden_states_c = rearrange(hidden_states_c, "(b f) c h w -> b c f h w", f=f) + + mod_hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc + + hidden_states = scale_pattern[None,None,:,None,None] * mod_hidden_states + rev_pattern[None,None,:,None,None] * hidden_states + + # add motion module + if motion_module: + hidden_states = motion_module( + hidden_states, temb, encoder_hidden_states=encoder_hidden_states + ) + + output_states = output_states + (hidden_states,) + + if C_REF_MODE == "read": + self.mean_bank = [] + self.var_bank = [] + + if self.downsamplers is not None: + for downsampler in self.downsamplers: + hidden_states = downsampler(hidden_states) + + output_states = output_states + (hidden_states,) + + return hidden_states, output_states + + def hacked_CrossAttnUpBlock3D_forward( + self, + hidden_states: torch.FloatTensor, + res_hidden_states_tuple: Tuple[torch.FloatTensor, ...], + temb: Optional[torch.FloatTensor] = None, + encoder_hidden_states: Optional[torch.FloatTensor] = None, + cross_attention_kwargs: Optional[Dict[str, Any]] = None, + upsample_size: Optional[int] = None, + attention_mask: Optional[torch.FloatTensor] = None, + encoder_attention_mask: Optional[torch.FloatTensor] = None, + ): + eps = 1e-6 + # TODO(Patrick, William) - attention mask is not used + for i, (resnet, attn, motion_module) in enumerate(zip(self.resnets, self.attentions, self.motion_modules)): + # pop res hidden states + res_hidden_states = res_hidden_states_tuple[-1] + res_hidden_states_tuple = res_hidden_states_tuple[:-1] + hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1) + hidden_states = resnet(hidden_states, temb) + hidden_states = attn( + hidden_states, + encoder_hidden_states=encoder_hidden_states, + cross_attention_kwargs=cross_attention_kwargs, + attention_mask=attention_mask, + encoder_attention_mask=encoder_attention_mask, + return_dict=False, + )[0] + + + if C_REF_MODE == "write": + if gn_auto_machine_weight >= self.gn_weight: + var, mean = torch.var_mean(hidden_states, dim=(3, 4), keepdim=True, correction=0) + self.mean_bank.append([mean]) + self.var_bank.append([var]) + if C_REF_MODE == "read": + if len(self.mean_bank) > 0 and len(self.var_bank) > 0: + var, mean = torch.var_mean(hidden_states, dim=(3, 4), keepdim=True, correction=0) + std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5 + mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i])) + var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i])) + std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5 + hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc + hidden_states_c = hidden_states_uc.clone() + if do_classifier_free_guidance and style_fidelity > 0: + + f = hidden_states.shape[2] + hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w") + hidden_states_c = rearrange(hidden_states_c, "b c f h w -> (b f) c h w") + + hidden_states_c[uc_mask] = hidden_states[uc_mask] + + hidden_states = rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f) + hidden_states_c = rearrange(hidden_states_c, "(b f) c h w -> b c f h w", f=f) + + mod_hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc + + hidden_states = scale_pattern[None,None,:,None,None] * mod_hidden_states + rev_pattern[None,None,:,None,None] * hidden_states + + # add motion module + if motion_module: + hidden_states = motion_module( + hidden_states, temb, encoder_hidden_states=encoder_hidden_states + ) + + + if C_REF_MODE == "read": + self.mean_bank = [] + self.var_bank = [] + + if self.upsamplers is not None: + for upsampler in self.upsamplers: + hidden_states = upsampler(hidden_states, upsample_size) + + return hidden_states + + def hacked_UpBlock3D_forward(self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None, encoder_hidden_states=None): + eps = 1e-6 + for i, (resnet,motion_module) in enumerate(zip(self.resnets, self.motion_modules)): + # pop res hidden states + res_hidden_states = res_hidden_states_tuple[-1] + res_hidden_states_tuple = res_hidden_states_tuple[:-1] + hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1) + hidden_states = resnet(hidden_states, temb) + + if C_REF_MODE == "write": + if gn_auto_machine_weight >= self.gn_weight: + var, mean = torch.var_mean(hidden_states, dim=(3, 4), keepdim=True, correction=0) + self.mean_bank.append([mean]) + self.var_bank.append([var]) + if C_REF_MODE == "read": + if len(self.mean_bank) > 0 and len(self.var_bank) > 0: + var, mean = torch.var_mean(hidden_states, dim=(3, 4), keepdim=True, correction=0) + std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5 + mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i])) + var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i])) + std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5 + hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc + hidden_states_c = hidden_states_uc.clone() + if do_classifier_free_guidance and style_fidelity > 0: + f = hidden_states.shape[2] + hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w") + hidden_states_c = rearrange(hidden_states_c, "b c f h w -> (b f) c h w") + + hidden_states_c[uc_mask] = hidden_states[uc_mask] + + hidden_states = rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f) + hidden_states_c = rearrange(hidden_states_c, "(b f) c h w -> b c f h w", f=f) + + mod_hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc + + hidden_states = scale_pattern[None,None,:,None,None] * mod_hidden_states + rev_pattern[None,None,:,None,None] * hidden_states + + if motion_module: + hidden_states = motion_module( + hidden_states, temb, encoder_hidden_states=encoder_hidden_states + ) + + + + if C_REF_MODE == "read": + self.mean_bank = [] + self.var_bank = [] + + if self.upsamplers is not None: + for upsampler in self.upsamplers: + hidden_states = upsampler(hidden_states, upsample_size) + + return hidden_states + + if reference_attn: + attn_modules = [module for module in torch_dfs(self.unet) if isinstance(module, BasicTransformerBlock)] + attn_modules = sorted(attn_modules, key=lambda x: -x.norm1.normalized_shape[0]) + + for i, module in enumerate(attn_modules): + module._original_inner_forward = module.forward + module.forward = hacked_basic_transformer_inner_forward.__get__(module, BasicTransformerBlock) + module.bank = [] + module.attn_weight = float(i) / float(len(attn_modules)) + + attn_modules = None + torch.cuda.empty_cache() + + if reference_adain: + gn_modules = [self.unet.mid_block] + self.unet.mid_block.gn_weight = 0 + + down_blocks = self.unet.down_blocks + for w, module in enumerate(down_blocks): + module.gn_weight = 1.0 - float(w) / float(len(down_blocks)) + gn_modules.append(module) + + up_blocks = self.unet.up_blocks + for w, module in enumerate(up_blocks): + module.gn_weight = float(w) / float(len(up_blocks)) + gn_modules.append(module) + + for i, module in enumerate(gn_modules): + if getattr(module, "original_forward", None) is None: + module.original_forward = module.forward + if i == 0: + # mid_block + module.forward = hacked_mid_forward.__get__(module, UNetMidBlock3DCrossAttn) + elif isinstance(module, CrossAttnDownBlock3D): + module.forward = hack_CrossAttnDownBlock3D_forward.__get__(module, CrossAttnDownBlock3D) + elif isinstance(module, DownBlock3D): + module.forward = hacked_DownBlock3D_forward.__get__(module, DownBlock3D) + elif isinstance(module, CrossAttnUpBlock3D): + module.forward = hacked_CrossAttnUpBlock3D_forward.__get__(module, CrossAttnUpBlock3D) + elif isinstance(module, UpBlock3D): + module.forward = hacked_UpBlock3D_forward.__get__(module, UpBlock3D) + module.mean_bank = [] + module.var_bank = [] + module.gn_weight *= 2 + + gn_modules = None + torch.cuda.empty_cache() + + + # from diffusers/examples/community/stable_diffusion_controlnet_reference.py + def prepare_controlnet_ref_only( + self, + ref_image_latents, + batch_size, + num_images_per_prompt, + do_classifier_free_guidance, + attention_auto_machine_weight, + gn_auto_machine_weight, + style_fidelity, + reference_attn, + reference_adain, + _scale_pattern, + ): + global C_REF_MODE + # 9. Modify self attention and group norm + C_REF_MODE = "write" + uc_mask = ( + torch.Tensor([1] * batch_size * num_images_per_prompt + [0] * batch_size * num_images_per_prompt) + .type_as(ref_image_latents) + .bool() + ) + + _scale_pattern = _scale_pattern * (batch_size // len(_scale_pattern) + 1) + _scale_pattern = _scale_pattern[:batch_size] + _rev_pattern = [1-i for i in _scale_pattern] + + scale_pattern_double = torch.tensor(_scale_pattern*2).to(self.device, dtype=self.unet.dtype) + rev_pattern_double = torch.tensor(_rev_pattern*2).to(self.device, dtype=self.unet.dtype) + scale_pattern = torch.tensor(_scale_pattern).to(self.device, dtype=self.unet.dtype) + rev_pattern = torch.tensor(_rev_pattern).to(self.device, dtype=self.unet.dtype) + + + + def hacked_basic_transformer_inner_forward( + self, + hidden_states: torch.FloatTensor, + attention_mask: Optional[torch.FloatTensor] = None, + encoder_hidden_states: Optional[torch.FloatTensor] = None, + encoder_attention_mask: Optional[torch.FloatTensor] = None, + timestep: Optional[torch.LongTensor] = None, + cross_attention_kwargs: Dict[str, Any] = None, + video_length=None, + ): + if self.use_ada_layer_norm: + norm_hidden_states = self.norm1(hidden_states, timestep) + else: + norm_hidden_states = self.norm1(hidden_states) + + # 1. Self-Attention + cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {} + if self.unet_use_cross_frame_attention: + cross_attention_kwargs["video_length"] = video_length + + if self.only_cross_attention: + attn_output = self.attn1( + norm_hidden_states, + encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None, + attention_mask=attention_mask, + **cross_attention_kwargs, + ) + else: + if C_REF_MODE == "write": + self.bank.append(norm_hidden_states.detach().clone()) + attn_output = self.attn1( + norm_hidden_states, + encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None, + attention_mask=attention_mask, + **cross_attention_kwargs, + ) + if C_REF_MODE == "read": + if attention_auto_machine_weight > self.attn_weight: + attn_output_uc = self.attn1( + norm_hidden_states, + encoder_hidden_states=torch.cat([norm_hidden_states] + self.bank, dim=1), + # attention_mask=attention_mask, + **cross_attention_kwargs, + ) + + if style_fidelity > 0: + attn_output_c = attn_output_uc.clone() + + if do_classifier_free_guidance: + attn_output_c[uc_mask] = self.attn1( + norm_hidden_states[uc_mask], + encoder_hidden_states=norm_hidden_states[uc_mask], + **cross_attention_kwargs, + ) + + attn_output = style_fidelity * attn_output_c + (1.0 - style_fidelity) * attn_output_uc + + else: + attn_output = attn_output_uc + + attn_org = self.attn1( + norm_hidden_states, + encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None, + attention_mask=attention_mask, + **cross_attention_kwargs, + ) + + attn_output = scale_pattern_double[:,None,None] * attn_output + rev_pattern_double[:,None,None] * attn_org + + else: + attn_output = self.attn1( + norm_hidden_states, + encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None, + attention_mask=attention_mask, + **cross_attention_kwargs, + ) + + self.bank.clear() + + + hidden_states = attn_output + hidden_states + + if self.attn2 is not None: + norm_hidden_states = ( + self.norm2(hidden_states, timestep) if self.use_ada_layer_norm else self.norm2(hidden_states) + ) + + # 2. Cross-Attention + attn_output = self.attn2( + norm_hidden_states, + encoder_hidden_states=encoder_hidden_states, + attention_mask=encoder_attention_mask, + **cross_attention_kwargs, + ) + hidden_states = attn_output + hidden_states + + # 3. Feed-forward + hidden_states = self.ff(self.norm3(hidden_states)) + hidden_states + + # 4. Temporal-Attention + if self.unet_use_temporal_attention: + d = hidden_states.shape[1] + hidden_states = rearrange(hidden_states, "(b f) d c -> (b d) f c", f=video_length) + norm_hidden_states = ( + self.norm_temp(hidden_states, timestep) + if self.use_ada_layer_norm + else self.norm_temp(hidden_states) + ) + hidden_states = self.attn_temp(norm_hidden_states) + hidden_states + hidden_states = rearrange(hidden_states, "(b d) f c -> (b f) d c", d=d) + + return hidden_states + + def hacked_mid_forward( + self, + hidden_states: torch.FloatTensor, + temb: Optional[torch.FloatTensor] = None, + encoder_hidden_states: Optional[torch.FloatTensor] = None, + attention_mask: Optional[torch.FloatTensor] = None, + cross_attention_kwargs: Optional[Dict[str, Any]] = None, + encoder_attention_mask: Optional[torch.FloatTensor] = None, + ) -> torch.FloatTensor: + + eps = 1e-6 + + hidden_states = self.resnets[0](hidden_states, temb) + for attn, resnet, motion_module in zip(self.attentions, self.resnets[1:], self.motion_modules): + hidden_states = attn( + hidden_states, + encoder_hidden_states=encoder_hidden_states, + cross_attention_kwargs=cross_attention_kwargs, + attention_mask=attention_mask, + encoder_attention_mask=encoder_attention_mask, + return_dict=False, + )[0] + if motion_module is not None: + hidden_states = motion_module( + hidden_states, + temb, + encoder_hidden_states=encoder_hidden_states, + ) + hidden_states = resnet(hidden_states, temb) + + x = hidden_states + + if C_REF_MODE == "write": + if gn_auto_machine_weight >= self.gn_weight: + var, mean = torch.var_mean(x, dim=(3, 4), keepdim=True, correction=0) + self.mean_bank.append(mean) + self.var_bank.append(var) + if C_REF_MODE == "read": + if len(self.mean_bank) > 0 and len(self.var_bank) > 0: + var, mean = torch.var_mean(x, dim=(3, 4), keepdim=True, correction=0) + std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5 + mean_acc = sum(self.mean_bank) / float(len(self.mean_bank)) + var_acc = sum(self.var_bank) / float(len(self.var_bank)) + std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5 + x_uc = (((x - mean) / std) * std_acc) + mean_acc + x_c = x_uc.clone() + if do_classifier_free_guidance and style_fidelity > 0: + + f = x.shape[2] + x_c = rearrange(x_c, "b c f h w -> (b f) c h w") + x = rearrange(x, "b c f h w -> (b f) c h w") + + x_c[uc_mask] = x[uc_mask] + + x_c = rearrange(x_c, "(b f) c h w -> b c f h w", f=f) + x = rearrange(x, "(b f) c h w -> b c f h w", f=f) + + mod_x = style_fidelity * x_c + (1.0 - style_fidelity) * x_uc + + x = scale_pattern[None,None,:,None,None] * mod_x + rev_pattern[None,None,:,None,None] * x + + self.mean_bank = [] + self.var_bank = [] + + hidden_states = x + + return hidden_states + + def hack_CrossAttnDownBlock3D_forward( + self, + hidden_states: torch.FloatTensor, + temb: Optional[torch.FloatTensor] = None, + encoder_hidden_states: Optional[torch.FloatTensor] = None, + attention_mask: Optional[torch.FloatTensor] = None, + cross_attention_kwargs: Optional[Dict[str, Any]] = None, + encoder_attention_mask: Optional[torch.FloatTensor] = None, + ): + eps = 1e-6 + + # TODO(Patrick, William) - attention mask is not used + output_states = () + + for i, (resnet, attn, motion_module) in enumerate(zip(self.resnets, self.attentions, self.motion_modules)): + hidden_states = resnet(hidden_states, temb) + + hidden_states = attn( + hidden_states, + encoder_hidden_states=encoder_hidden_states, + cross_attention_kwargs=cross_attention_kwargs, + attention_mask=attention_mask, + encoder_attention_mask=encoder_attention_mask, + return_dict=False, + )[0] + # add motion module + hidden_states = ( + motion_module(hidden_states, temb, encoder_hidden_states=encoder_hidden_states) + if motion_module is not None + else hidden_states + ) + + if C_REF_MODE == "write": + if gn_auto_machine_weight >= self.gn_weight: + var, mean = torch.var_mean(hidden_states, dim=(3, 4), keepdim=True, correction=0) + self.mean_bank.append([mean]) + self.var_bank.append([var]) + if C_REF_MODE == "read": + if len(self.mean_bank) > 0 and len(self.var_bank) > 0: + var, mean = torch.var_mean(hidden_states, dim=(3, 4), keepdim=True, correction=0) + std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5 + mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i])) + var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i])) + std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5 + hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc + hidden_states_c = hidden_states_uc.clone() + if do_classifier_free_guidance and style_fidelity > 0: + + f = hidden_states.shape[2] + hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w") + hidden_states_c = rearrange(hidden_states_c, "b c f h w -> (b f) c h w") + + hidden_states_c[uc_mask] = hidden_states[uc_mask] + + hidden_states = rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f) + hidden_states_c = rearrange(hidden_states_c, "(b f) c h w -> b c f h w", f=f) + + mod_hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc + + hidden_states = scale_pattern[None,None,:,None,None] * mod_hidden_states + rev_pattern[None,None,:,None,None] * hidden_states + + output_states = output_states + (hidden_states,) + + if C_REF_MODE == "read": + self.mean_bank = [] + self.var_bank = [] + + if self.downsamplers is not None: + for downsampler in self.downsamplers: + hidden_states = downsampler(hidden_states) + + output_states = output_states + (hidden_states,) + + return hidden_states, output_states + + def hacked_DownBlock3D_forward(self, hidden_states, temb=None, encoder_hidden_states=None): + eps = 1e-6 + + output_states = () + + for i, (resnet, motion_module) in enumerate(zip(self.resnets, self.motion_modules)): + hidden_states = resnet(hidden_states, temb) + + # add motion module + if motion_module: + hidden_states = motion_module( + hidden_states, temb, encoder_hidden_states=encoder_hidden_states + ) + + if C_REF_MODE == "write": + if gn_auto_machine_weight >= self.gn_weight: + var, mean = torch.var_mean(hidden_states, dim=(3, 4), keepdim=True, correction=0) + self.mean_bank.append([mean]) + self.var_bank.append([var]) + if C_REF_MODE == "read": + if len(self.mean_bank) > 0 and len(self.var_bank) > 0: + var, mean = torch.var_mean(hidden_states, dim=(3, 4), keepdim=True, correction=0) + std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5 + mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i])) + var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i])) + std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5 + hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc + hidden_states_c = hidden_states_uc.clone() + if do_classifier_free_guidance and style_fidelity > 0: + + f = hidden_states.shape[2] + hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w") + hidden_states_c = rearrange(hidden_states_c, "b c f h w -> (b f) c h w") + + hidden_states_c[uc_mask] = hidden_states[uc_mask] + + hidden_states = rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f) + hidden_states_c = rearrange(hidden_states_c, "(b f) c h w -> b c f h w", f=f) + + mod_hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc + + hidden_states = scale_pattern[None,None,:,None,None] * mod_hidden_states + rev_pattern[None,None,:,None,None] * hidden_states + + output_states = output_states + (hidden_states,) + + if C_REF_MODE == "read": + self.mean_bank = [] + self.var_bank = [] + + if self.downsamplers is not None: + for downsampler in self.downsamplers: + hidden_states = downsampler(hidden_states) + + output_states = output_states + (hidden_states,) + + return hidden_states, output_states + + def hacked_CrossAttnUpBlock3D_forward( + self, + hidden_states: torch.FloatTensor, + res_hidden_states_tuple: Tuple[torch.FloatTensor, ...], + temb: Optional[torch.FloatTensor] = None, + encoder_hidden_states: Optional[torch.FloatTensor] = None, + cross_attention_kwargs: Optional[Dict[str, Any]] = None, + upsample_size: Optional[int] = None, + attention_mask: Optional[torch.FloatTensor] = None, + encoder_attention_mask: Optional[torch.FloatTensor] = None, + ): + eps = 1e-6 + # TODO(Patrick, William) - attention mask is not used + for i, (resnet, attn, motion_module) in enumerate(zip(self.resnets, self.attentions, self.motion_modules)): + # pop res hidden states + res_hidden_states = res_hidden_states_tuple[-1] + res_hidden_states_tuple = res_hidden_states_tuple[:-1] + hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1) + hidden_states = resnet(hidden_states, temb) + hidden_states = attn( + hidden_states, + encoder_hidden_states=encoder_hidden_states, + cross_attention_kwargs=cross_attention_kwargs, + attention_mask=attention_mask, + encoder_attention_mask=encoder_attention_mask, + return_dict=False, + )[0] + + # add motion module + if motion_module: + hidden_states = motion_module( + hidden_states, temb, encoder_hidden_states=encoder_hidden_states + ) + + if C_REF_MODE == "write": + if gn_auto_machine_weight >= self.gn_weight: + var, mean = torch.var_mean(hidden_states, dim=(3, 4), keepdim=True, correction=0) + self.mean_bank.append([mean]) + self.var_bank.append([var]) + if C_REF_MODE == "read": + if len(self.mean_bank) > 0 and len(self.var_bank) > 0: + var, mean = torch.var_mean(hidden_states, dim=(3, 4), keepdim=True, correction=0) + std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5 + mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i])) + var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i])) + std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5 + hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc + hidden_states_c = hidden_states_uc.clone() + if do_classifier_free_guidance and style_fidelity > 0: + + f = hidden_states.shape[2] + hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w") + hidden_states_c = rearrange(hidden_states_c, "b c f h w -> (b f) c h w") + + hidden_states_c[uc_mask] = hidden_states[uc_mask] + + hidden_states = rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f) + hidden_states_c = rearrange(hidden_states_c, "(b f) c h w -> b c f h w", f=f) + + mod_hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc + + hidden_states = scale_pattern[None,None,:,None,None] * mod_hidden_states + rev_pattern[None,None,:,None,None] * hidden_states + + + if C_REF_MODE == "read": + self.mean_bank = [] + self.var_bank = [] + + if self.upsamplers is not None: + for upsampler in self.upsamplers: + hidden_states = upsampler(hidden_states, upsample_size) + + return hidden_states + + def hacked_UpBlock3D_forward(self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None, encoder_hidden_states=None): + eps = 1e-6 + for i, (resnet,motion_module) in enumerate(zip(self.resnets, self.motion_modules)): + # pop res hidden states + res_hidden_states = res_hidden_states_tuple[-1] + res_hidden_states_tuple = res_hidden_states_tuple[:-1] + hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1) + hidden_states = resnet(hidden_states, temb) + + if motion_module: + hidden_states = motion_module( + hidden_states, temb, encoder_hidden_states=encoder_hidden_states + ) + + if C_REF_MODE == "write": + if gn_auto_machine_weight >= self.gn_weight: + var, mean = torch.var_mean(hidden_states, dim=(3, 4), keepdim=True, correction=0) + self.mean_bank.append([mean]) + self.var_bank.append([var]) + if C_REF_MODE == "read": + if len(self.mean_bank) > 0 and len(self.var_bank) > 0: + var, mean = torch.var_mean(hidden_states, dim=(3, 4), keepdim=True, correction=0) + std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5 + mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i])) + var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i])) + std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5 + hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc + hidden_states_c = hidden_states_uc.clone() + if do_classifier_free_guidance and style_fidelity > 0: + f = hidden_states.shape[2] + hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w") + hidden_states_c = rearrange(hidden_states_c, "b c f h w -> (b f) c h w") + + hidden_states_c[uc_mask] = hidden_states[uc_mask] + + hidden_states = rearrange(hidden_states, "(b f) c h w -> b c f h w", f=f) + hidden_states_c = rearrange(hidden_states_c, "(b f) c h w -> b c f h w", f=f) + + mod_hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc + + hidden_states = scale_pattern[None,None,:,None,None] * mod_hidden_states + rev_pattern[None,None,:,None,None] * hidden_states + + if C_REF_MODE == "read": + self.mean_bank = [] + self.var_bank = [] + + if self.upsamplers is not None: + for upsampler in self.upsamplers: + hidden_states = upsampler(hidden_states, upsample_size) + + return hidden_states + + if reference_attn: + attn_modules = [module for module in torch_dfs(self.unet) if isinstance(module, BasicTransformerBlock)] + attn_modules = sorted(attn_modules, key=lambda x: -x.norm1.normalized_shape[0]) + + for i, module in enumerate(attn_modules): + module._original_inner_forward = module.forward + module.forward = hacked_basic_transformer_inner_forward.__get__(module, BasicTransformerBlock) + module.bank = [] + module.attn_weight = float(i) / float(len(attn_modules)) + + attn_modules = None + torch.cuda.empty_cache() + + if reference_adain: + gn_modules = [self.unet.mid_block] + self.unet.mid_block.gn_weight = 0 + + down_blocks = self.unet.down_blocks + for w, module in enumerate(down_blocks): + module.gn_weight = 1.0 - float(w) / float(len(down_blocks)) + gn_modules.append(module) + + up_blocks = self.unet.up_blocks + for w, module in enumerate(up_blocks): + module.gn_weight = float(w) / float(len(up_blocks)) + gn_modules.append(module) + + for i, module in enumerate(gn_modules): + if getattr(module, "original_forward", None) is None: + module.original_forward = module.forward + if i == 0: + # mid_block + module.forward = hacked_mid_forward.__get__(module, UNetMidBlock3DCrossAttn) + elif isinstance(module, CrossAttnDownBlock3D): + module.forward = hack_CrossAttnDownBlock3D_forward.__get__(module, CrossAttnDownBlock3D) + elif isinstance(module, DownBlock3D): + module.forward = hacked_DownBlock3D_forward.__get__(module, DownBlock3D) + elif isinstance(module, CrossAttnUpBlock3D): + module.forward = hacked_CrossAttnUpBlock3D_forward.__get__(module, CrossAttnUpBlock3D) + elif isinstance(module, UpBlock3D): + module.forward = hacked_UpBlock3D_forward.__get__(module, UpBlock3D) + module.mean_bank = [] + module.var_bank = [] + module.gn_weight *= 2 + + gn_modules = None + torch.cuda.empty_cache() + + + def unload_controlnet_ref_only( + self, + reference_attn, + reference_adain, + ): + if reference_attn: + attn_modules = [module for module in torch_dfs(self.unet) if isinstance(module, BasicTransformerBlock)] + attn_modules = sorted(attn_modules, key=lambda x: -x.norm1.normalized_shape[0]) + + for i, module in enumerate(attn_modules): + module.forward = module._original_inner_forward + module.bank = [] + + attn_modules = None + torch.cuda.empty_cache() + + if reference_adain: + gn_modules = [self.unet.mid_block] + self.unet.mid_block.gn_weight = 0 + + down_blocks = self.unet.down_blocks + for w, module in enumerate(down_blocks): + module.gn_weight = 1.0 - float(w) / float(len(down_blocks)) + gn_modules.append(module) + + up_blocks = self.unet.up_blocks + for w, module in enumerate(up_blocks): + module.gn_weight = float(w) / float(len(up_blocks)) + gn_modules.append(module) + + for i, module in enumerate(gn_modules): + module.forward = module.original_forward + module.mean_bank = [] + module.var_bank = [] + module.gn_weight *= 2 + + gn_modules = None + torch.cuda.empty_cache() + + def get_img2img_timesteps(self, num_inference_steps, strength, device): + strength = min(1, max(0,strength)) + # get the original timestep using init_timestep + init_timestep = min(int(num_inference_steps * strength), num_inference_steps) + + t_start = max(num_inference_steps - init_timestep, 0) + timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :] + + return timesteps, num_inference_steps - t_start + + @torch.no_grad() + def __call__( + self, + height: Optional[int] = None, + width: Optional[int] = None, + num_inference_steps: int = 50, + guidance_scale: float = 7.5, + unet_batch_size: int = 1, + negative_prompt: Optional[Union[str, List[str]]] = None, + video_length: Optional[int] = None, + num_videos_per_prompt: Optional[int] = 1, + eta: float = 0.0, + generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None, + latents: Optional[torch.FloatTensor] = None, + prompt_embeds: Optional[torch.FloatTensor] = None, + negative_prompt_embeds: Optional[torch.FloatTensor] = None, + output_type: Optional[str] = "tensor", + return_dict: bool = True, + callback: Optional[Callable[[int, torch.FloatTensor], None]] = None, + callback_steps: Optional[List[int]] = None, + cross_attention_kwargs: Optional[Dict[str, Any]] = None, + context_frames: int = -1, + context_stride: int = 3, + context_overlap: int = 4, + context_schedule: str = "uniform", + clip_skip: int = 1, + controlnet_type_map: Dict[str, Dict[str,float]] = None, + controlnet_image_map: Dict[int, Dict[str,Any]] = None, + controlnet_ref_map: Dict[str, Any] = None, + controlnet_no_shrink:List[str]=None, + controlnet_max_samples_on_vram: int = 999, + controlnet_max_models_on_vram: int=99, + controlnet_is_loop: bool=True, + img2img_map: Dict[str, Any] = None, + ip_adapter_config_map: Dict[str,Any] = None, + region_list: List[Any] = None, + region_condi_list: List[Any] = None, + interpolation_factor = 1, + is_single_prompt_mode = False, + gradual_latent_map=None, + **kwargs, + ): + import gc + + global C_REF_MODE + + gradual_latent = False + if gradual_latent_map: + gradual_latent = gradual_latent_map["enable"] + + controlnet_image_map_org = controlnet_image_map + + controlnet_max_models_on_vram = max(controlnet_max_models_on_vram,0) + + # Default height and width to unet + height = height or self.unet.config.sample_size * self.vae_scale_factor + width = width or self.unet.config.sample_size * self.vae_scale_factor + + sequential_mode = video_length is not None and video_length > context_frames + + multi_uncond_mode = self.lora_map is not None + + controlnet_for_region = False + if controlnet_type_map: + for c in controlnet_type_map: + reg_list = controlnet_type_map[c]["control_region_list"] + if reg_list: + controlnet_for_region = True + break + + if controlnet_for_region or multi_uncond_mode: + controlnet_for_region = True + multi_uncond_mode = True + unet_batch_size = 1 + + logger.info(f"{controlnet_for_region=}") + logger.info(f"{multi_uncond_mode=}") + logger.info(f"{unet_batch_size=}") + + # 1. Check inputs. Raise error if not correct + self.check_inputs( + "dummy string", height, width, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds + ) + + # Define call parameters + batch_size = 1 + + device = self._execution_device + latents_device = torch.device("cpu") if sequential_mode else device + + + if ip_adapter_config_map: + if self.ip_adapter is None: + img_enc_path = "data/models/ip_adapter/models/image_encoder/" + if ip_adapter_config_map["is_full_face"]: + self.ip_adapter = IPAdapterFull(self, img_enc_path, "data/models/ip_adapter/models/ip-adapter-full-face_sd15.bin", device, 257) + elif ip_adapter_config_map["is_light"]: + self.ip_adapter = IPAdapter(self, img_enc_path, "data/models/ip_adapter/models/ip-adapter_sd15_light.bin", device, 4) + elif ip_adapter_config_map["is_plus_face"]: + self.ip_adapter = IPAdapterPlus(self, img_enc_path, "data/models/ip_adapter/models/ip-adapter-plus-face_sd15.bin", device, 16) + elif ip_adapter_config_map["is_plus"]: + self.ip_adapter = IPAdapterPlus(self, img_enc_path, "data/models/ip_adapter/models/ip-adapter-plus_sd15.bin", device, 16) + else: + self.ip_adapter = IPAdapter(self, img_enc_path, "data/models/ip_adapter/models/ip-adapter_sd15.bin", device, 4) + self.ip_adapter.set_scale( ip_adapter_config_map["scale"] ) + + # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2) + # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1` + # corresponds to doing no classifier free guidance. + do_classifier_free_guidance = guidance_scale > 1.0 + + # 3. Encode input prompt + text_encoder_lora_scale = ( + cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None + ) + + + prompt_encoder = PromptEncoder( + self, + device, + device,#latents_device, + num_videos_per_prompt, + do_classifier_free_guidance, + region_condi_list, + negative_prompt, + is_single_prompt_mode, + clip_skip, + multi_uncond_mode + ) + + if self.ip_adapter: + self.ip_adapter.delete_encoder() + + if controlnet_ref_map is not None: + if unet_batch_size < prompt_encoder.get_condi_size(): + raise ValueError(f"controlnet_ref is not available in this configuration. {unet_batch_size=} < {prompt_encoder.get_condi_size()}") + if multi_uncond_mode: + raise ValueError(f"controlnet_ref is not available in this configuration. {multi_uncond_mode=}") + + + logger.info(f"{prompt_encoder.get_condi_size()=}") + + + # 3.5 Prepare controlnet variables + + if self.controlnet_map: + for i, type_str in enumerate(self.controlnet_map): + if i < controlnet_max_models_on_vram: + self.controlnet_map[type_str].to(device=device, non_blocking=True) + + + + # controlnet_image_map + # { 0 : { "type_str" : IMAGE, "type_str2" : IMAGE } } + # { "type_str" : { 0 : IMAGE, 15 : IMAGE } } + controlnet_image_map= None + + if controlnet_image_map_org: + controlnet_image_map= {key: {} for key in controlnet_type_map} + for key_frame_no in controlnet_image_map_org: + for t, img in controlnet_image_map_org[key_frame_no].items(): + tmp = self.prepare_image( + image=img, + width=width, + height=height, + batch_size=1 * 1, + num_images_per_prompt=1, + #device=device, + device=latents_device, + dtype=self.controlnet_map[t].dtype, + do_classifier_free_guidance=False, + guess_mode=False, + ) + controlnet_image_map[t][key_frame_no] = torch.cat([tmp] * prompt_encoder.get_condi_size()) + + del controlnet_image_map_org + torch.cuda.empty_cache() + + # { "0_type_str" : { "scales" = [0.1, 0.3, 0.5, 1.0, 0.5, 0.3, 0.1], "frames"=[125, 126, 127, 0, 1, 2, 3] }} + controlnet_scale_map = {} + controlnet_affected_list = np.zeros(video_length,dtype = int) + + is_v2v = True + + if controlnet_image_map: + for type_str in controlnet_image_map: + for key_frame_no in controlnet_image_map[type_str]: + scale_list = controlnet_type_map[type_str]["control_scale_list"] + if len(scale_list) > 0: + is_v2v = False + scale_list = scale_list[0: context_frames] + scale_len = len(scale_list) + + if controlnet_is_loop: + frames = [ i%video_length for i in range(key_frame_no-scale_len, key_frame_no+scale_len+1)] + + controlnet_scale_map[str(key_frame_no) + "_" + type_str] = { + "scales" : scale_list[::-1] + [1.0] + scale_list, + "frames" : frames, + } + else: + frames = [ i for i in range(max(0, key_frame_no-scale_len), min(key_frame_no+scale_len+1, video_length))] + + controlnet_scale_map[str(key_frame_no) + "_" + type_str] = { + "scales" : scale_list[:key_frame_no][::-1] + [1.0] + scale_list[:video_length-key_frame_no-1], + "frames" : frames, + } + + controlnet_affected_list[frames] = 1 + + def controlnet_is_affected( frame_index:int): + return controlnet_affected_list[frame_index] + + def get_controlnet_scale( + type: str, + cur_step: int, + step_length: int, + ): + s = controlnet_type_map[type]["control_guidance_start"] + e = controlnet_type_map[type]["control_guidance_end"] + keep = 1.0 - float(cur_step / len(timesteps) < s or (cur_step + 1) / step_length > e) + + scale = controlnet_type_map[type]["controlnet_conditioning_scale"] + + return keep * scale + + def get_controlnet_variable( + type_str: str, + cur_step: int, + step_length: int, + target_frames: List[int], + ): + cont_vars = [] + + if not controlnet_image_map: + return None + + if type_str not in controlnet_image_map: + return None + + for fr, img in controlnet_image_map[type_str].items(): + + if fr in target_frames: + cont_vars.append( { + "frame_no" : fr, + "image" : img, + "cond_scale" : get_controlnet_scale(type_str, cur_step, step_length), + "guess_mode" : controlnet_type_map[type_str]["guess_mode"] + } ) + + return cont_vars + + # 3.9. Preprocess reference image + c_ref_enable = controlnet_ref_map is not None + + if c_ref_enable: + ref_image = controlnet_ref_map["ref_image"] + + ref_image = self.prepare_ref_image( + image=ref_image, + width=width, + height=height, + batch_size=1 * 1, + num_images_per_prompt=1, + device=device, + dtype=prompt_encoder.get_prompt_embeds_dtype(), + ) + + # 4. Prepare timesteps + self.scheduler.set_timesteps(num_inference_steps, device=latents_device) + if img2img_map: + timesteps, num_inference_steps = self.get_img2img_timesteps(num_inference_steps, img2img_map["denoising_strength"], latents_device) + latent_timestep = timesteps[:1].repeat(batch_size * 1) + else: + timesteps = self.scheduler.timesteps + latent_timestep = None + + is_strength_max = True + if img2img_map: + is_strength_max = img2img_map["denoising_strength"] == 1.0 + + # 5. Prepare latent variables + num_channels_latents = self.unet.config.in_channels + latents_outputs = self.prepare_latents( + batch_size * num_videos_per_prompt, + num_channels_latents, + video_length, + height, + width, + prompt_encoder.get_prompt_embeds_dtype(), + latents_device, # keep latents on cpu for sequential mode + generator, + img2img_map, + latent_timestep, + latents, + is_strength_max, + True, + True, + ) + + latents, noise, image_latents = latents_outputs + + del img2img_map + torch.cuda.empty_cache() + gc.collect() + + # 5.5 Prepare region mask + region_mask = RegionMask( + region_list, + batch_size, + num_channels_latents, + video_length, + height, + width, + self.vae_scale_factor, + prompt_encoder.get_prompt_embeds_dtype(), + latents_device, + multi_uncond_mode + ) + + torch.cuda.empty_cache() + + # 5.9. Prepare reference latent variables + if c_ref_enable: + ref_image_latents = self.prepare_ref_latents( + ref_image, + context_frames * 1, + prompt_encoder.get_prompt_embeds_dtype(), + device, + generator, + do_classifier_free_guidance=False, + ) + ref_image_latents = torch.cat([ref_image_latents] * prompt_encoder.get_condi_size()) + ref_image_latents = rearrange(ref_image_latents, "(b f) c h w -> b c f h w", f=context_frames) + + # 5.99. Modify self attention and group norm +# self.prepare_controlnet_ref_only( + self.prepare_controlnet_ref_only_without_motion( + ref_image_latents=ref_image_latents, + batch_size=context_frames, + num_images_per_prompt=1, + do_classifier_free_guidance=do_classifier_free_guidance, + attention_auto_machine_weight=controlnet_ref_map["attention_auto_machine_weight"], + gn_auto_machine_weight=controlnet_ref_map["gn_auto_machine_weight"], + style_fidelity=controlnet_ref_map["style_fidelity"], + reference_attn=controlnet_ref_map["reference_attn"], + reference_adain=controlnet_ref_map["reference_adain"], + _scale_pattern=controlnet_ref_map["scale_pattern"], + region_num = prompt_encoder.get_condi_size() + ) + + # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline + extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta) + + # 6.5 - Infinite context loop shenanigans + context_scheduler = get_context_scheduler(context_schedule) + total_steps = get_total_steps( + context_scheduler, + timesteps, + num_inference_steps, + latents.shape[2], + context_frames, + context_stride, + context_overlap, + ) + + lat_height, lat_width = latents.shape[-2:] + + def gradual_latent_scale(progress): + if gradual_latent: + cur = 0.5 + for s in gradual_latent_map["scale"]: + v = gradual_latent_map["scale"][s] + if float(s) > progress: + return cur + cur = v + return cur + else: + return 1.0 + def gradual_latent_size(progress): + if gradual_latent: + current_ratio = gradual_latent_scale(progress) + h = int(lat_height * current_ratio) + w = int(lat_width * current_ratio) + return (h,w) + else: + return (lat_height, lat_width) + + def unsharp_mask(img): + imgf = img.float() + k = 0.05 # strength + kernel = torch.FloatTensor([[0, -k, 0], + [-k, 1+4*k, -k], + [0, -k, 0]]) + + conv_kernel = torch.eye(4)[..., None, None] * kernel[None, None, ...] + imgf = torch.nn.functional.conv2d(imgf, conv_kernel.to(img.device), padding=1) + return imgf.to(img.dtype) + + def resize_tensor(ten, size, do_unsharp_mask=False): + ten = rearrange(ten, "b c f h w -> (b f) c h w") + ten = torch.nn.functional.interpolate( + ten.float(), size=size, mode="bicubic", align_corners=False + ).to(ten.dtype) + if do_unsharp_mask: + ten = unsharp_mask(ten) + return rearrange(ten, "(b f) c h w -> b c f h w", f=video_length) + + if gradual_latent: + latents = resize_tensor(latents, gradual_latent_size(0)) + reverse_steps = gradual_latent_map["reverse_steps"] + noise_add_count = gradual_latent_map["noise_add_count"] + total_steps = ((total_steps/num_inference_steps) * (reverse_steps* (len(gradual_latent_map["scale"].keys()) - 1) )) + total_steps + total_steps = int(total_steps) + + prev_gradient_latent_size = gradual_latent_size(0) + + + shrink_controlnet = True + no_shrink_type = controlnet_no_shrink + + if controlnet_type_map: + for nt in no_shrink_type: + if nt in controlnet_type_map: + controlnet_type_map[nt] = controlnet_type_map.pop(nt) + + def need_region_blend(cur_step, total_steps): + if cur_step + 1 == total_steps: + return True + if multi_uncond_mode == False: + return True + return cur_step % 2 == 1 + + # 7. Denoising loop + num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order + with self.progress_bar(total=total_steps) as progress_bar: + i = 0 + real_i = 0 +# for i, t in enumerate(timesteps): + while i < len(timesteps): + t = timesteps[i] + stopwatch_start() + + cur_gradient_latent_size = gradual_latent_size((real_i+1) / len(timesteps)) + + if self.lcm: + self.lcm.apply(i, len(timesteps)) + + noise_pred = torch.zeros( + (prompt_encoder.get_condi_size(), *latents.shape[1:]), + device=latents.device, + dtype=latents.dtype, + ) + counter = torch.zeros( + (1, 1, latents.shape[2], 1, 1), device=latents.device, dtype=latents.dtype + ) + + # { "0_type_str" : (down_samples, mid_sample) } + controlnet_result={} + + def scale_5d_tensor(ten, h, w, f): + ten = rearrange(ten, "b c f h w -> (b f) c h w") + ten = torch.nn.functional.interpolate( + ten, size=(h, w), mode="bicubic", align_corners=False + ) + return rearrange(ten, "(b f) c h w -> b c f h w", f=f) + + def get_controlnet_result(context: List[int] = None, layer:int = -1): + #logger.info(f"get_controlnet_result called {context=}") + + if controlnet_image_map is None: + return None, None + + hit = False + for n in context: + if controlnet_is_affected(n): + hit=True + break + if hit == False: + return None, None + + + def is_control_layer(type_str, layer): + if layer == -1: + return True + region_list = controlnet_type_map[type_str]["control_region_list"] + if not region_list: + return True + r = region_mask.get_region_from_layer(layer, prompt_encoder.get_condi_size()) + if r == -1: + return False + return r in region_list + + + def to_device(sample, target_device): + down_samples = [ + v.to(device = target_device, non_blocking=True) if v.device != target_device else v + for v in sample[0] ] + mid_sample = sample[1].to(device = target_device, non_blocking=True) if sample[1].device != target_device else sample[1] + return (down_samples, mid_sample) + + _down_block_res_samples=[] + + first_down = list(list(controlnet_result.values())[0].values())[0][0] + first_mid = list(list(controlnet_result.values())[0].values())[0][1] + + shape0 = first_mid.shape[0] if layer == -1 else 1 + for ii in range(len(first_down)): + _down_block_res_samples.append( + torch.zeros( + (shape0, first_down[ii].shape[1], len(context) ,*first_down[ii].shape[3:]), + device=device, + dtype=first_down[ii].dtype, + )) + _mid_block_res_samples = torch.zeros( + (shape0, first_mid.shape[1], len(context) ,*first_mid.shape[3:]), + device=device, + dtype=first_mid.dtype, + ) + + + def merge_result(fr, type_str): + nonlocal _mid_block_res_samples, _down_block_res_samples + result = str(fr) + "_" + type_str + + val = controlnet_result[fr][type_str] + + if layer == -1: + cur_down = [ + v.to(device = device, dtype=first_down[0].dtype, non_blocking=True) if v.device != device else v + for v in val[0] + ] + cur_mid =val[1].to(device = device, dtype=first_mid.dtype, non_blocking=True) if val[1].device != device else val[1] + else: + cur_down = [ + v[layer].to(device = device, dtype=first_down[0].dtype, non_blocking=True) if v.device != device else v[layer] + for v in val[0] + ] + cur_mid =val[1][layer].to(device = device, dtype=first_mid.dtype, non_blocking=True) if val[1].device != device else val[1][layer] + + loc = list(set(context) & set(controlnet_scale_map[result]["frames"])) + scales = [] + + for o in loc: + for j, f in enumerate(controlnet_scale_map[result]["frames"]): + if o == f: + scales.append(controlnet_scale_map[result]["scales"][j]) + break + loc_index=[] + + for o in loc: + for j, f in enumerate( context ): + if o==f: + loc_index.append(j) + break + + mod = torch.tensor(scales).to(device, dtype=cur_mid.dtype) + + ''' + for ii in range(len(_down_block_res_samples)): + logger.info(f"{type_str=} / {cur_down[ii].shape=}") + logger.info(f"{type_str=} / {_down_block_res_samples[ii].shape=}") + logger.info(f"{type_str=} / {cur_mid.shape=}") + logger.info(f"{type_str=} / {_mid_block_res_samples.shape=}") + ''' + + add = cur_mid * mod[None,None,:,None,None] + _mid_block_res_samples[:, :, loc_index, :, :] = _mid_block_res_samples[:, :, loc_index, :, :] + add + + for ii in range(len(cur_down)): + add = cur_down[ii] * mod[None,None,:,None,None] + _down_block_res_samples[ii][:, :, loc_index, :, :] = _down_block_res_samples[ii][:, :, loc_index, :, :] + add + + + + + hit = False + + no_shrink_list = [] + + for fr in controlnet_result: + for type_str in controlnet_result[fr]: + if not is_control_layer(type_str, layer): + continue + + hit = True + + if shrink_controlnet and (type_str in no_shrink_type): + no_shrink_list.append(type_str) + continue + + merge_result(fr, type_str) + + cur_d_height, cur_d_width = _down_block_res_samples[0].shape[-2:] + cur_lat_height, cur_lat_width = latents.shape[-2:] + if cur_lat_height != cur_d_height: + #logger.info(f"{cur_lat_height=} / {cur_d_height=}") + for ii, rate in zip(range(len(_down_block_res_samples)), (1,1,1,2,2,2,4,4,4,8,8,8)): + new_h = (cur_lat_height + rate-1) // rate + new_w = (cur_lat_width + rate-1) // rate + #logger.info(f"b {_down_block_res_samples[ii].shape=}") + _down_block_res_samples[ii] = scale_5d_tensor(_down_block_res_samples[ii], new_h, new_w, context_frames) + #logger.info(f"a {_down_block_res_samples[ii].shape=}") + _mid_block_res_samples = scale_5d_tensor(_mid_block_res_samples, (cur_lat_height + rate - 1)// 8, (cur_lat_width + rate - 1)// 8, context_frames) + + + for fr in controlnet_result: + for type_str in controlnet_result[fr]: + if type_str not in no_shrink_list: + continue + merge_result(fr, type_str) + + + if not hit: + return None, None + + return _down_block_res_samples, _mid_block_res_samples + + def process_controlnet( target_frames: List[int] = None ): + #logger.info(f"process_controlnet called {target_frames=}") + nonlocal controlnet_result + + controlnet_samples_on_vram = 0 + + loc = list(set(target_frames) & set(controlnet_result.keys())) + + controlnet_result = {key: controlnet_result[key] for key in loc} + + target_frames = list(set(target_frames) - set(loc)) + #logger.info(f"-> {target_frames=}") + if len(target_frames) == 0: + return + + def sample_to_device( sample ): + nonlocal controlnet_samples_on_vram + + if controlnet_max_samples_on_vram <= controlnet_samples_on_vram: + if sample[0][0].device != torch.device("cpu"): + down_samples = [ v.to(device = torch.device("cpu"), non_blocking=True) for v in sample[0] ] + mid_sample = sample[1].to(device = torch.device("cpu"), non_blocking=True) + else: + down_samples = sample[0] + mid_sample = sample[1] + + else: + if sample[0][0].device != device: + down_samples = [ v.to(device = device, non_blocking=True) for v in sample[0] ] + mid_sample = sample[1].to(device = device, non_blocking=True) + else: + down_samples = sample[0] + mid_sample = sample[1] + + controlnet_samples_on_vram += 1 + return down_samples, mid_sample + + + for fr in controlnet_result: + for type_str in controlnet_result[fr]: + controlnet_result[fr][type_str] = sample_to_device(controlnet_result[fr][type_str]) + + for type_str in controlnet_type_map: + cont_vars = get_controlnet_variable(type_str, i, len(timesteps), target_frames) + if not cont_vars: + continue + + org_device = self.controlnet_map[type_str].device + if org_device != device: + self.controlnet_map[type_str] = self.controlnet_map[type_str].to(device=device, non_blocking=True) + + for cont_var in cont_vars: + frame_no = cont_var["frame_no"] + + if latents.shape[0] == 1: + latent_model_input = ( + latents[:, :, [frame_no]] + .to(device) + .repeat( prompt_encoder.get_condi_size(), 1, 1, 1, 1) + ) + else: + latent_model_input=[] + for s0_index in list(range(latents.shape[0])) + list(range(latents.shape[0])): + latent_model_input.append( latents[[s0_index], :, [frame_no]].to(device).unsqueeze(dim=2) ) + latent_model_input = torch.cat(latent_model_input) + + if shrink_controlnet and (type_str not in no_shrink_type): + cur_lat_height, cur_lat_width = latent_model_input.shape[-2:] + cur = min(cur_lat_height, cur_lat_width) + if cur > 64: # 512 / 8 = 64 + if cur_lat_height > cur_lat_width: + shr_lat_height = 64 * cur_lat_height / cur_lat_width + shr_lat_width = 64 + else: + shr_lat_height = 64 + shr_lat_width = 64 * cur_lat_width / cur_lat_height + shr_lat_height = int(shr_lat_height // 8 * 8) + shr_lat_width = int(shr_lat_width // 8 * 8) + #logger.info(f"b {latent_model_input.shape=}") + latent_model_input = scale_5d_tensor(latent_model_input, shr_lat_height, shr_lat_width, 1) + #logger.info(f"a {latent_model_input.shape=}") + + + control_model_input = self.scheduler.scale_model_input(latent_model_input, t)[:, :, 0] + controlnet_prompt_embeds = prompt_encoder.get_current_prompt_embeds([frame_no], latents.shape[2]) + + + if False: + controlnet_prompt_embeds = controlnet_prompt_embeds.to(device=device, non_blocking=True) + cont_var_img = cont_var["image"].to(device=device, non_blocking=True) + + __down_list=[] + __mid_list=[] + for layer_index in range(0, control_model_input.shape[0], unet_batch_size): + + __control_model_input = control_model_input[layer_index:layer_index+unet_batch_size] + __controlnet_prompt_embeds = controlnet_prompt_embeds[layer_index :(layer_index + unet_batch_size)] + __cont_var_img = cont_var_img[layer_index:layer_index+unet_batch_size] + + __down_samples, __mid_sample = self.controlnet_map[type_str]( + __control_model_input, + t, + encoder_hidden_states=__controlnet_prompt_embeds, + controlnet_cond=__cont_var_img, + conditioning_scale=cont_var["cond_scale"], + guess_mode=cont_var["guess_mode"], + return_dict=False, + ) + __down_list.append(__down_samples) + __mid_list.append(__mid_sample) + + down_samples=[] + for d_no in range(len(__down_list[0])): + down_samples.append( + torch.cat([ + v[d_no] for v in __down_list + ]) + ) + mid_sample = torch.cat(__mid_list) + + else: + cont_var_img = cont_var["image"].to(device=device) + + cur_lat_height, cur_lat_width = latent_model_input.shape[-2:] + cur_img_height, cur_img_width = cont_var_img.shape[-2:] + if (cur_lat_height*8 != cur_img_height) or (cur_lat_width*8 != cur_img_width): + cont_var_img = torch.nn.functional.interpolate( + cont_var_img.float(), size=(cur_lat_height*8, cur_lat_width*8), mode="bicubic", align_corners=False + ).to(cont_var_img.dtype) + + down_samples, mid_sample = self.controlnet_map[type_str]( + control_model_input, + t, + encoder_hidden_states=controlnet_prompt_embeds.to(device=device), + controlnet_cond=cont_var_img, + conditioning_scale=cont_var["cond_scale"], + guess_mode=cont_var["guess_mode"], + return_dict=False, + ) + + for ii in range(len(down_samples)): + down_samples[ii] = rearrange(down_samples[ii], "(b f) c h w -> b c f h w", f=1) + mid_sample = rearrange(mid_sample, "(b f) c h w -> b c f h w", f=1) + + if frame_no not in controlnet_result: + controlnet_result[frame_no] = {} + + ''' + for ii in range(len(down_samples)): + logger.info(f"{type_str=} / {down_samples[ii].shape=}") + logger.info(f"{type_str=} / {mid_sample.shape=}") + ''' + + controlnet_result[frame_no][type_str] = sample_to_device((down_samples, mid_sample)) + + if org_device != device: + self.controlnet_map[type_str] = self.controlnet_map[type_str].to(device=org_device, non_blocking=True) + + #logger.info(f"STEP start") + stopwatch_record("STEP start") + + for context in context_scheduler( + i, num_inference_steps, latents.shape[2], context_frames, context_stride, context_overlap + ): + + stopwatch_record("lora_map UNapply start") + if self.lora_map: + self.lora_map.unapply() + stopwatch_record("lora_map UNapply end") + + if controlnet_image_map: + if is_v2v: + controlnet_target = context + else: + controlnet_target = list(range(context[0]-context_frames, context[0])) + context + list(range(context[-1]+1, context[-1]+1+context_frames)) + controlnet_target = [f%video_length for f in controlnet_target] + controlnet_target = list(set(controlnet_target)) + + process_controlnet(controlnet_target) + + # expand the latents + if latents.shape[0] == 1: + latent_model_input = ( + latents[:, :, context] + .to(device) + .repeat(prompt_encoder.get_condi_size(), 1, 1, 1, 1) + ) + else: + latent_model_input=[] + for s0_index in list(range(latents.shape[0])) + list(range(latents.shape[0])): + latent_model_input.append( latents[s0_index:s0_index+1, :, context].to(device) ) + latent_model_input = torch.cat(latent_model_input) + + + latent_model_input = self.scheduler.scale_model_input(latent_model_input, t) + + cur_prompt = prompt_encoder.get_current_prompt_embeds(context, latents.shape[2]).to(device=device) + + if controlnet_for_region: + down_block_res_samples,mid_block_res_sample = (None,None) + else: + down_block_res_samples,mid_block_res_sample = get_controlnet_result(context) + + + if c_ref_enable: + # ref only part + ref_noise = randn_tensor( + ref_image_latents.shape, generator=generator, device=device, dtype=ref_image_latents.dtype + ) + + ref_xt = self.scheduler.add_noise( + ref_image_latents, + ref_noise, + t.reshape( + 1, + ), + ) + ref_xt = self.scheduler.scale_model_input(ref_xt, t) + + stopwatch_record("C_REF_MODE write start") + + C_REF_MODE = "write" + self.unet( + ref_xt, + t, + encoder_hidden_states=cur_prompt, + cross_attention_kwargs=cross_attention_kwargs, + return_dict=False, + ) + + stopwatch_record("C_REF_MODE write end") + + C_REF_MODE = "read" + + # predict the noise residual + + stopwatch_record("normal unet start") + + __pred = [] + + for layer_index in range(0, latent_model_input.shape[0], unet_batch_size): + + if self.lora_map: + self.lora_map.apply(layer_index, latent_model_input.shape[0], context[len(context)//2]) + + if controlnet_for_region: + __do,__mid = get_controlnet_result(context, layer_index) + else: + __do = [] + if down_block_res_samples is not None: + for do in down_block_res_samples: + __do.append(do[layer_index:layer_index+unet_batch_size]) + else: + __do = None + + __mid = None + if mid_block_res_sample is not None: + __mid = mid_block_res_sample[layer_index:layer_index+unet_batch_size] + + + __lat = latent_model_input[layer_index:layer_index+unet_batch_size] + __cur_prompt = cur_prompt[layer_index * context_frames:(layer_index + unet_batch_size)*context_frames] + + stopwatch_record("self.unet start") + pred_layer = self.unet( + __lat.to(self.unet.device, self.unet.dtype), + t, + encoder_hidden_states=__cur_prompt, + cross_attention_kwargs=cross_attention_kwargs, + down_block_additional_residuals=__do, + mid_block_additional_residual=__mid, + return_dict=False, + )[0] + stopwatch_record("self.unet end") + + wh = None + + if i < len(timesteps) * region_mask.get_crop_generation_rate(layer_index, latent_model_input.shape[0]): + wh, xy_list = region_mask.get_area(layer_index, latent_model_input.shape[0], context) + if wh: + a_w, a_h = wh + __lat_list = [] + for c_index, xy in enumerate( xy_list ): + a_x, a_y = xy + __lat_list.append( __lat[:,:,[c_index],a_y:a_y+a_h, a_x:a_x+a_w ] ) + + __lat = torch.cat(__lat_list, dim=2) + + if __do is not None: + __tmp_do = [] + for _d, rate in zip(__do, (1,1,1,2,2,2,4,4,4,8,8,8)): + _inner_do_list = [] + for c_index, xy in enumerate( xy_list ): + a_x, a_y = xy + _inner_do_list.append(_d[:,:,[c_index],(a_y + rate-1)//rate:((a_y+a_h)+ rate-1)//rate, (a_x+ rate-1)//rate:((a_x+a_w)+ rate-1)//rate ] ) + + __tmp_do.append( torch.cat(_inner_do_list, dim=2) ) + __do = __tmp_do + + if __mid is not None: + rate = 8 + _mid_list = [] + for c_index, xy in enumerate( xy_list ): + a_x, a_y = xy + _mid_list.append( __mid[:,:,[c_index],(a_y+ rate-1)//rate:((a_y+a_h)+ rate-1)//rate, (a_x+ rate-1)//rate:((a_x+a_w)+ rate-1)//rate ] ) + __mid = torch.cat(_mid_list, dim=2) + + stopwatch_record("crop self.unet start") + crop_pred_layer = self.unet( + __lat.to(self.unet.device, self.unet.dtype), + t, + encoder_hidden_states=__cur_prompt, + cross_attention_kwargs=cross_attention_kwargs, + down_block_additional_residuals=__do, + mid_block_additional_residual=__mid, + return_dict=False, + )[0] + stopwatch_record("crop self.unet end") + + if wh: + a_w, a_h = wh + for c_index, xy in enumerate( xy_list ): + a_x, a_y = xy + pred_layer[:,:,[c_index],a_y:a_y+a_h, a_x:a_x+a_w] = crop_pred_layer[:,:,[c_index],:,:] + + __pred.append( pred_layer ) + + __do = None + __mid = None + down_block_res_samples = None + mid_block_res_sample = None + + + pred = torch.cat(__pred) + + + stopwatch_record("normal unet end") + + pred = pred.to(dtype=latents.dtype, device=latents.device) + noise_pred[:, :, context] = noise_pred[:, :, context] + pred + counter[:, :, context] = counter[:, :, context] + 1 + progress_bar.update() + + # perform guidance + noise_size = prompt_encoder.get_condi_size() + if do_classifier_free_guidance: + noise_pred = (noise_pred / counter) + noise_list = list(noise_pred.chunk( noise_size )) + + if multi_uncond_mode: + uc_noise_list = noise_list[:len(noise_list)//2] + noise_list = noise_list[len(noise_list)//2:] + for n in range(len(noise_list)): + noise_list[n] = uc_noise_list[n] + guidance_scale * (noise_list[n] - uc_noise_list[n]) + else: + noise_pred_uncond = noise_list.pop(0) + for n in range(len(noise_list)): + noise_list[n] = noise_pred_uncond + guidance_scale * (noise_list[n] - noise_pred_uncond) + noise_size = len(noise_list) + noise_pred = torch.cat(noise_list) + + # call the callback, if provided + if (i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0)) and ( + callback is not None and (callback_steps is not None and i in callback_steps) + ): + denoised = latents - noise_pred + denoised = self.interpolate_latents(denoised, interpolation_factor, device) + video = torch.from_numpy(self.decode_latents(denoised)) + callback(i, video) + + if gradual_latent: + if prev_gradient_latent_size != cur_gradient_latent_size: + noise_pred = resize_tensor(noise_pred, cur_gradient_latent_size, True) + latents = resize_tensor(latents, cur_gradient_latent_size, True) + + + # compute the previous noisy sample x_t -> x_t-1 + latents = self.scheduler.step( + model_output=noise_pred, + timestep=t, + sample=latents, + **extra_step_kwargs, + return_dict=False, + )[0] + + if need_region_blend(i, len(timesteps)): + latents_list = latents.chunk( noise_size ) + + tmp_latent = torch.zeros( + latents_list[0].shape, device=latents.device, dtype=latents.dtype + ) + + for r_no in range(len(region_list)): + mask = region_mask.get_mask( r_no ) + if gradual_latent: + mask = resize_tensor(mask, cur_gradient_latent_size) + src = region_list[r_no]["src"] + if src == -1: + init_latents_proper = image_latents[:1] + + if i < len(timesteps) - 1: + noise_timestep = timesteps[i + 1] + init_latents_proper = self.scheduler.add_noise( + init_latents_proper, noise, torch.tensor([noise_timestep]) + ) + + if gradual_latent: + lat = resize_tensor(init_latents_proper, cur_gradient_latent_size) + else: + lat = init_latents_proper + + else: + lat = latents_list[src] + + tmp_latent = tmp_latent * (1-mask) + lat * mask + + latents = tmp_latent + + init_latents_proper = None + lat = None + latents_list = None + tmp_latent = None + + i+=1 + real_i = max(i, real_i) + if gradual_latent: + if prev_gradient_latent_size != cur_gradient_latent_size: + reverse = min(i, reverse_steps) + self.scheduler._step_index -= reverse + _noise = resize_tensor(noise, cur_gradient_latent_size) + for count in range(i, i+noise_add_count): + count = min(count,len(timesteps)-1) + latents = self.scheduler.add_noise( + latents, _noise, torch.tensor([timesteps[count]]) + ) + i -= reverse + torch.cuda.empty_cache() + gc.collect() + + prev_gradient_latent_size = cur_gradient_latent_size + + stopwatch_stop("LOOP end") + + controlnet_result = None + torch.cuda.empty_cache() + gc.collect() + + if c_ref_enable: + self.unload_controlnet_ref_only( + reference_attn=controlnet_ref_map["reference_attn"], + reference_adain=controlnet_ref_map["reference_adain"], + ) + + if self.ip_adapter: + show_gpu("before unload ip_adapter") + self.ip_adapter.unload() + self.ip_adapter = None + torch.cuda.empty_cache() + show_gpu("after unload ip_adapter") + + latents = self.interpolate_latents(latents,interpolation_factor, device) + + # Return latents if requested (this will never be a dict) + if not output_type == "latent": + video = self.decode_latents(latents) + else: + video = latents + + # Convert to tensor + if output_type == "tensor": + video = torch.from_numpy(video) + + # Offload last model to CPU + if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None: + self.final_offload_hook.offload() + + if not return_dict: + return video + + return AnimationPipelineOutput(videos=video) + + def freeze(self): + logger.debug("Freezing pipeline...") + _ = self.unet.eval() + self.unet = self.unet.requires_grad_(False) + self.unet.train = nop_train + + _ = self.text_encoder.eval() + self.text_encoder = self.text_encoder.requires_grad_(False) + self.text_encoder.train = nop_train + + _ = self.vae.eval() + self.vae = self.vae.requires_grad_(False) + self.vae.train = nop_train diff --git a/animate/src/animatediff/pipelines/context.py b/animate/src/animatediff/pipelines/context.py new file mode 100644 index 0000000000000000000000000000000000000000..f6569955c3fe36e05ba3086f9cfee5a7c50ec4db --- /dev/null +++ b/animate/src/animatediff/pipelines/context.py @@ -0,0 +1,114 @@ +from typing import Callable, Optional + +import numpy as np + + +# Whatever this is, it's utterly cursed. +def ordered_halving(val): + bin_str = f"{val:064b}" + bin_flip = bin_str[::-1] + as_int = int(bin_flip, 2) + + return as_int / (1 << 64) + + +# I have absolutely no idea how this works and I don't like that. +def uniform( + step: int = ..., + num_steps: Optional[int] = None, + num_frames: int = ..., + context_size: Optional[int] = None, + context_stride: int = 3, + context_overlap: int = 4, + closed_loop: bool = True, +): + if num_frames <= context_size: + yield list(range(num_frames)) + return + + context_stride = min(context_stride, int(np.ceil(np.log2(num_frames / context_size))) + 1) + + for context_step in 1 << np.arange(context_stride): + pad = int(round(num_frames * ordered_halving(step))) + for j in range( + int(ordered_halving(step) * context_step) + pad, + num_frames + pad + (0 if closed_loop else -context_overlap), + (context_size * context_step - context_overlap), + ): + yield [e % num_frames for e in range(j, j + context_size * context_step, context_step)] + + +def shuffle( + step: int = ..., + num_steps: Optional[int] = None, + num_frames: int = ..., + context_size: Optional[int] = None, + context_stride: int = 3, + context_overlap: int = 4, + closed_loop: bool = True, +): + import random + c = list(range(num_frames)) + c = random.sample(c, len(c)) + + if len(c) % context_size: + c += c[0:context_size - len(c) % context_size] + + c = random.sample(c, len(c)) + + for i in range(0, len(c), context_size): + yield c[i:i+context_size] + + +def composite( + step: int = ..., + num_steps: Optional[int] = None, + num_frames: int = ..., + context_size: Optional[int] = None, + context_stride: int = 3, + context_overlap: int = 4, + closed_loop: bool = True, +): + if (step/num_steps) < 0.1: + return shuffle(step,num_steps,num_frames,context_size,context_stride,context_overlap,closed_loop) + else: + return uniform(step,num_steps,num_frames,context_size,context_stride,context_overlap,closed_loop) + + +def get_context_scheduler(name: str) -> Callable: + match name: + case "uniform": + return uniform + case "shuffle": + return shuffle + case "composite": + return composite + case _: + raise ValueError(f"Unknown context_overlap policy {name}") + + +def get_total_steps( + scheduler, + timesteps: list[int], + num_steps: Optional[int] = None, + num_frames: int = ..., + context_size: Optional[int] = None, + context_stride: int = 3, + context_overlap: int = 4, + closed_loop: bool = True, +): + return sum( + len( + list( + scheduler( + i, + num_steps, + num_frames, + context_size, + context_stride, + context_overlap, + ) + ) + ) + for i in range(len(timesteps)) + ) diff --git a/animate/src/animatediff/pipelines/lora.py b/animate/src/animatediff/pipelines/lora.py new file mode 100644 index 0000000000000000000000000000000000000000..0c8654a5552a21ffb870200514a97a6f10829ca7 --- /dev/null +++ b/animate/src/animatediff/pipelines/lora.py @@ -0,0 +1,243 @@ +import logging + +from safetensors.torch import load_file + +from animatediff import get_dir +from animatediff.utils.lora_diffusers import (LoRANetwork, + create_network_from_weights) + +logger = logging.getLogger(__name__) + +data_dir = get_dir("data") + + +def merge_safetensors_lora(text_encoder, unet, lora_path, alpha=0.75, is_animatediff=True): + + def dump(loaded): + for a in loaded: + logger.info(f"{a} {loaded[a].shape}") + + sd = load_file(lora_path) + + if False: + dump(sd) + + print(f"create LoRA network") + lora_network: LoRANetwork = create_network_from_weights(text_encoder, unet, sd, multiplier=alpha, is_animatediff=is_animatediff) + print(f"load LoRA network weights") + lora_network.load_state_dict(sd, False) + lora_network.merge_to(alpha) + +def load_lora_map(pipe, lora_map_config, video_length, is_sdxl=False): + new_map = {} + for item in lora_map_config: + lora_path = data_dir.joinpath(item) + if type(lora_map_config[item]) in (float,int): + te_en = [pipe.text_encoder, pipe.text_encoder_2] if is_sdxl else pipe.text_encoder + merge_safetensors_lora(te_en, pipe.unet, lora_path, lora_map_config[item], not is_sdxl) + else: + new_map[lora_path] = lora_map_config[item] + + lora_map = LoraMap(pipe, new_map, video_length, is_sdxl) + pipe.lora_map = lora_map if lora_map.is_valid else None + +def load_lcm_lora(pipe, lcm_map, is_sdxl=False, is_merge=False): + if is_sdxl: + lora_path = data_dir.joinpath("models/lcm_lora/sdxl/pytorch_lora_weights.safetensors") + else: + lora_path = data_dir.joinpath("models/lcm_lora/sd15/AnimateLCM_sd15_t2v_lora.safetensors") + logger.info(f"{lora_path=}") + + if is_merge: + te_en = [pipe.text_encoder, pipe.text_encoder_2] if is_sdxl else pipe.text_encoder + merge_safetensors_lora(te_en, pipe.unet, lora_path, 1.0, not is_sdxl) + pipe.lcm = None + return + + lcm = LcmLora(pipe, is_sdxl, lora_path, lcm_map) + pipe.lcm = lcm if lcm.is_valid else None + +class LcmLora: + def __init__( + self, + pipe, + is_sdxl, + lora_path, + lcm_map + ): + self.is_valid = False + + sd = load_file(lora_path) + if not sd: + return + + te_en = [pipe.text_encoder, pipe.text_encoder_2] if is_sdxl else pipe.text_encoder + lora_network: LoRANetwork = create_network_from_weights(te_en, pipe.unet, sd, multiplier=1.0, is_animatediff=not is_sdxl) + lora_network.load_state_dict(sd, False) + lora_network.apply_to(1.0) + self.network = lora_network + + self.is_valid = True + + self.start_scale = lcm_map["start_scale"] + self.end_scale = lcm_map["end_scale"] + self.gradient_start = lcm_map["gradient_start"] + self.gradient_end = lcm_map["gradient_end"] + + + def to( + self, + device, + dtype, + ): + self.network.to(device=device, dtype=dtype) + + def apply( + self, + step, + total_steps, + ): + step += 1 + progress = step / total_steps + + if progress < self.gradient_start: + scale = self.start_scale + elif progress > self.gradient_end: + scale = self.end_scale + else: + if (self.gradient_end - self.gradient_start) < 1e-4: + progress = 0 + else: + progress = (progress - self.gradient_start) / (self.gradient_end - self.gradient_start) + scale = (self.end_scale - self.start_scale) * progress + scale += self.start_scale + + self.network.active( scale ) + + def unapply( + self, + ): + self.network.deactive( ) + + + +class LoraMap: + def __init__( + self, + pipe, + lora_map, + video_length, + is_sdxl, + ): + self.networks = [] + + def create_schedule(scales, length): + scales = { int(i):scales[i] for i in scales } + keys = sorted(scales.keys()) + + if len(keys) == 1: + return { i:scales[keys[0]] for i in range(length) } + keys = keys + [keys[0]] + + schedule={} + + def calc(rate,start_v,end_v): + return start_v + (rate * rate)*(end_v - start_v) + + for key_prev,key_next in zip(keys[:-1],keys[1:]): + v1 = scales[key_prev] + v2 = scales[key_next] + if key_prev > key_next: + key_next += length + for i in range(key_prev,key_next): + dist = i-key_prev + if i >= length: + i -= length + schedule[i] = calc( dist/(key_next-key_prev), v1, v2 ) + return schedule + + for lora_path in lora_map: + sd = load_file(lora_path) + if not sd: + continue + te_en = [pipe.text_encoder, pipe.text_encoder_2] if is_sdxl else pipe.text_encoder + lora_network: LoRANetwork = create_network_from_weights(te_en, pipe.unet, sd, multiplier=0.75, is_animatediff=not is_sdxl) + lora_network.load_state_dict(sd, False) + lora_network.apply_to(0.75) + + self.networks.append( + { + "network":lora_network, + "region":lora_map[lora_path]["region"], + "schedule": create_schedule(lora_map[lora_path]["scale"], video_length ) + } + ) + + def region_convert(i): + if i == "background": + return 0 + else: + return int(i) + 1 + + for net in self.networks: + net["region"] = [ region_convert(i) for i in net["region"] ] + +# for n in self.networks: +# logger.info(f"{n['region']=}") +# logger.info(f"{n['schedule']=}") + + if self.networks: + self.is_valid = True + else: + self.is_valid = False + + def to( + self, + device, + dtype, + ): + for net in self.networks: + net["network"].to(device=device, dtype=dtype) + + def apply( + self, + cond_index, + cond_nums, + frame_no, + ): + ''' + neg 0 (bg) + neg 1 + neg 2 + pos 0 (bg) + pos 1 + pos 2 + ''' + + region_index = cond_index if cond_index < cond_nums//2 else cond_index - cond_nums//2 +# logger.info(f"{cond_index=}") +# logger.info(f"{cond_nums=}") +# logger.info(f"{region_index=}") + + + for i,net in enumerate(self.networks): + if region_index in net["region"]: + scale = net["schedule"][frame_no] + if scale > 0: + net["network"].active( scale ) +# logger.info(f"{i=} active {scale=}") + else: + net["network"].deactive( ) +# logger.info(f"{i=} DEactive") + + else: + net["network"].deactive( ) + # logger.info(f"{i=} DEactive") + + def unapply( + self, + ): + + for net in self.networks: + net["network"].deactive( ) + diff --git a/animate/src/animatediff/pipelines/pipeline_controlnet_img2img_reference.py b/animate/src/animatediff/pipelines/pipeline_controlnet_img2img_reference.py new file mode 100644 index 0000000000000000000000000000000000000000..743e9df09242986892f0f261cc2edc9b23d0fc0b --- /dev/null +++ b/animate/src/animatediff/pipelines/pipeline_controlnet_img2img_reference.py @@ -0,0 +1,1595 @@ +# https://github.com/huggingface/diffusers/blob/e831749e11f9b66de36cbbadf5820b9eb8f16ea8/src/diffusers/pipelines/controlnet/pipeline_controlnet_img2img_reference.py + +# Copyright 2023 The HuggingFace Team. All rights reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + + +import inspect +import warnings +from typing import Any, Callable, Dict, List, Optional, Tuple, Union + +import numpy as np +import PIL.Image +import torch +import torch.nn.functional as F +from diffusers.image_processor import VaeImageProcessor +from diffusers.loaders import LoraLoaderMixin, TextualInversionLoaderMixin +from diffusers.models import (AutoencoderKL, ControlNetModel, + UNet2DConditionModel) +from diffusers.models.attention import BasicTransformerBlock +from diffusers.models.unets.unet_2d_blocks import (CrossAttnDownBlock2D, + CrossAttnUpBlock2D, DownBlock2D, + UpBlock2D) +from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel +from diffusers.pipelines.pipeline_utils import DiffusionPipeline +from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput +from diffusers.pipelines.stable_diffusion.safety_checker import \ + StableDiffusionSafetyChecker +from diffusers.schedulers import KarrasDiffusionSchedulers +from diffusers.utils import (deprecate, is_accelerate_available, + is_accelerate_version, logging, + replace_example_docstring) +from diffusers.utils.torch_utils import is_compiled_module, randn_tensor +from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer + +logger = logging.get_logger(__name__) # pylint: disable=invalid-name + + +EXAMPLE_DOC_STRING = """ + Examples: + ```py + >>> import sys + >>> import cv2 + >>> import torch + >>> import numpy as np + >>> from PIL import Image + >>> from diffusers import EulerAncestralDiscreteScheduler, ControlNetModel, StableDiffusionControlNetImg2ImgReferencePipeline + >>> from diffusers.utils import load_image + + >>> input_image = load_image("https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png") + + >>> # get canny image + >>> image = cv2.Canny(np.array(input_image), 100, 200) + >>> image = image[:, :, None] + >>> image = np.concatenate([image, image, image], axis=2) + >>> canny_image = Image.fromarray(image) + + >>> controlnet = [] + >>> controlnet.append(ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)) + >>> model = "runwayml/stable-diffusion-v1-5" + >>> pipe = StableDiffusionControlNetImg2ImgReferencePipeline.from_pretrained( + >>> model, + >>> controlnet=controlnet, + >>> safety_checker=None, + >>> torch_dtype=torch.float16 + >>> ).to('cuda:0') + + >>> pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config) + >>> pipe.enable_xformers_memory_efficient_attention() + >>> pipe.enable_model_cpu_offload() + + >>> result_img = pipe( + >>> prompt="oil painting", + >>> num_inference_steps=20, + >>> image=input_image, + >>> strength=0.8, + >>> control_image=[canny_image], + >>> controlnet_conditioning_scale = [0.01], + >>> ref_image=input_image, + >>> attention_auto_machine_weight = 0.3, + >>> gn_auto_machine_weight = 0.3, + >>> style_fidelity = 1, + >>> reference_attn=True, + >>> reference_adain=True + >>> ).images[0] + + >>> result_img.show() + ``` +""" + + +def prepare_image(image): + if isinstance(image, torch.Tensor): + # Batch single image + if image.ndim == 3: + image = image.unsqueeze(0) + + image = image.to(dtype=torch.float32) + else: + # preprocess image + if isinstance(image, (PIL.Image.Image, np.ndarray)): + image = [image] + + if isinstance(image, list) and isinstance(image[0], PIL.Image.Image): + image = [np.array(i.convert("RGB"))[None, :] for i in image] + image = np.concatenate(image, axis=0) + elif isinstance(image, list) and isinstance(image[0], np.ndarray): + image = np.concatenate([i[None, :] for i in image], axis=0) + + image = image.transpose(0, 3, 1, 2) + image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0 + + return image + +def torch_dfs(model: torch.nn.Module): + result = [model] + for child in model.children(): + result += torch_dfs(child) + return result + +class StableDiffusionControlNetImg2ImgReferencePipeline(DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin): + r""" + Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance. + + This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the + library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.) + + In addition the pipeline inherits the following loading methods: + - *Textual-Inversion*: [`loaders.TextualInversionLoaderMixin.load_textual_inversion`] + + Args: + vae ([`AutoencoderKL`]): + Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations. + text_encoder ([`CLIPTextModel`]): + Frozen text-encoder. Stable Diffusion uses the text portion of + [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically + the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant. + tokenizer (`CLIPTokenizer`): + Tokenizer of class + [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer). + unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents. + controlnet ([`ControlNetModel`] or `List[ControlNetModel]`): + Provides additional conditioning to the unet during the denoising process. If you set multiple ControlNets + as a list, the outputs from each ControlNet are added together to create one combined additional + conditioning. + scheduler ([`SchedulerMixin`]): + A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of + [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`]. + safety_checker ([`StableDiffusionSafetyChecker`]): + Classification module that estimates whether generated images could be considered offensive or harmful. + Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details. + feature_extractor ([`CLIPImageProcessor`]): + Model that extracts features from generated images to be used as inputs for the `safety_checker`. + """ + _optional_components = ["safety_checker", "feature_extractor"] + + def __init__( + self, + vae: AutoencoderKL, + text_encoder: CLIPTextModel, + tokenizer: CLIPTokenizer, + unet: UNet2DConditionModel, + controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel], + scheduler: KarrasDiffusionSchedulers, + safety_checker: StableDiffusionSafetyChecker, + feature_extractor: CLIPImageProcessor, + requires_safety_checker: bool = True, + ): + super().__init__() + + if safety_checker is None and requires_safety_checker: + logger.warning( + f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure" + " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered" + " results in services or applications open to the public. Both the diffusers team and Hugging Face" + " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling" + " it only for use-cases that involve analyzing network behavior or auditing its results. For more" + " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ." + ) + + if safety_checker is not None and feature_extractor is None: + raise ValueError( + "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety" + " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead." + ) + + if isinstance(controlnet, (list, tuple)): + controlnet = MultiControlNetModel(controlnet) + + self.register_modules( + vae=vae, + text_encoder=text_encoder, + tokenizer=tokenizer, + unet=unet, + controlnet=controlnet, + scheduler=scheduler, + safety_checker=safety_checker, + feature_extractor=feature_extractor, + ) + self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1) + self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True) + self.control_image_processor = VaeImageProcessor( + vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False + ) + self.register_to_config(requires_safety_checker=requires_safety_checker) + + def prepare_ref_latents(self, refimage, batch_size, dtype, device, generator, do_classifier_free_guidance): + refimage = refimage.to(device=device, dtype=dtype) + + # encode the mask image into latents space so we can concatenate it to the latents + if isinstance(generator, list): + ref_image_latents = [ + self.vae.encode(refimage[i : i + 1]).latent_dist.sample(generator=generator[i]) + for i in range(batch_size) + ] + ref_image_latents = torch.cat(ref_image_latents, dim=0) + else: + ref_image_latents = self.vae.encode(refimage).latent_dist.sample(generator=generator) + ref_image_latents = self.vae.config.scaling_factor * ref_image_latents + + # duplicate mask and ref_image_latents for each generation per prompt, using mps friendly method + if ref_image_latents.shape[0] < batch_size: + if not batch_size % ref_image_latents.shape[0] == 0: + raise ValueError( + "The passed images and the required batch size don't match. Images are supposed to be duplicated" + f" to a total batch size of {batch_size}, but {ref_image_latents.shape[0]} images were passed." + " Make sure the number of images that you pass is divisible by the total requested batch size." + ) + ref_image_latents = ref_image_latents.repeat(batch_size // ref_image_latents.shape[0], 1, 1, 1) + + ref_image_latents = torch.cat([ref_image_latents] * 2) if do_classifier_free_guidance else ref_image_latents + + # aligning device to prevent device errors when concating it with the latent model input + ref_image_latents = ref_image_latents.to(device=device, dtype=dtype) + return ref_image_latents + + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing + def enable_vae_slicing(self): + r""" + Enable sliced VAE decoding. + + When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several + steps. This is useful to save some memory and allow larger batch sizes. + """ + self.vae.enable_slicing() + + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing + def disable_vae_slicing(self): + r""" + Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to + computing decoding in one step. + """ + self.vae.disable_slicing() + + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling + def enable_vae_tiling(self): + r""" + Enable tiled VAE decoding. + + When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in + several steps. This is useful to save a large amount of memory and to allow the processing of larger images. + """ + self.vae.enable_tiling() + + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling + def disable_vae_tiling(self): + r""" + Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to + computing decoding in one step. + """ + self.vae.disable_tiling() + + def enable_sequential_cpu_offload(self, gpu_id=0): + r""" + Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet, + text_encoder, vae, controlnet, and safety checker have their state dicts saved to CPU and then are moved to a + `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called. + Note that offloading happens on a submodule basis. Memory savings are higher than with + `enable_model_cpu_offload`, but performance is lower. + """ + if is_accelerate_available(): + from accelerate import cpu_offload + else: + raise ImportError("Please install accelerate via `pip install accelerate`") + + device = torch.device(f"cuda:{gpu_id}") + + for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.controlnet]: + cpu_offload(cpu_offloaded_model, device) + + if self.safety_checker is not None: + cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True) + + def enable_model_cpu_offload(self, gpu_id=0): + r""" + Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared + to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward` + method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with + `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`. + """ + if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"): + from accelerate import cpu_offload_with_hook + else: + raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.") + + device = torch.device(f"cuda:{gpu_id}") + + hook = None + for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]: + _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook) + + if self.safety_checker is not None: + # the safety checker can offload the vae again + _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook) + + # control net hook has be manually offloaded as it alternates with unet + cpu_offload_with_hook(self.controlnet, device) + + # We'll offload the last model manually. + self.final_offload_hook = hook + + @property + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device + def _execution_device(self): + r""" + Returns the device on which the pipeline's models will be executed. After calling + `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module + hooks. + """ + if not hasattr(self.unet, "_hf_hook"): + return self.device + for module in self.unet.modules(): + if ( + hasattr(module, "_hf_hook") + and hasattr(module._hf_hook, "execution_device") + and module._hf_hook.execution_device is not None + ): + return torch.device(module._hf_hook.execution_device) + return self.device + + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt + def _encode_prompt( + self, + prompt, + device, + num_images_per_prompt, + do_classifier_free_guidance, + negative_prompt=None, + prompt_embeds: Optional[torch.FloatTensor] = None, + negative_prompt_embeds: Optional[torch.FloatTensor] = None, + lora_scale: Optional[float] = None, + ): + r""" + Encodes the prompt into text encoder hidden states. + + Args: + prompt (`str` or `List[str]`, *optional*): + prompt to be encoded + device: (`torch.device`): + torch device + num_images_per_prompt (`int`): + number of images that should be generated per prompt + do_classifier_free_guidance (`bool`): + whether to use classifier free guidance or not + negative_prompt (`str` or `List[str]`, *optional*): + The prompt or prompts not to guide the image generation. If not defined, one has to pass + `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is + less than `1`). + prompt_embeds (`torch.FloatTensor`, *optional*): + Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not + provided, text embeddings will be generated from `prompt` input argument. + negative_prompt_embeds (`torch.FloatTensor`, *optional*): + Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt + weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input + argument. + lora_scale (`float`, *optional*): + A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded. + """ + # set lora scale so that monkey patched LoRA + # function of text encoder can correctly access it + if lora_scale is not None and isinstance(self, LoraLoaderMixin): + self._lora_scale = lora_scale + + if prompt is not None and isinstance(prompt, str): + batch_size = 1 + elif prompt is not None and isinstance(prompt, list): + batch_size = len(prompt) + else: + batch_size = prompt_embeds.shape[0] + + if prompt_embeds is None: + # textual inversion: procecss multi-vector tokens if necessary + if isinstance(self, TextualInversionLoaderMixin): + prompt = self.maybe_convert_prompt(prompt, self.tokenizer) + + text_inputs = self.tokenizer( + prompt, + padding="max_length", + max_length=self.tokenizer.model_max_length, + truncation=True, + return_tensors="pt", + ) + text_input_ids = text_inputs.input_ids + untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids + + if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal( + text_input_ids, untruncated_ids + ): + removed_text = self.tokenizer.batch_decode( + untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1] + ) + logger.warning( + "The following part of your input was truncated because CLIP can only handle sequences up to" + f" {self.tokenizer.model_max_length} tokens: {removed_text}" + ) + + if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask: + attention_mask = text_inputs.attention_mask.to(device) + else: + attention_mask = None + + prompt_embeds = self.text_encoder( + text_input_ids.to(device), + attention_mask=attention_mask, + ) + prompt_embeds = prompt_embeds[0] + + prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device) + + bs_embed, seq_len, _ = prompt_embeds.shape + # duplicate text embeddings for each generation per prompt, using mps friendly method + prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1) + prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1) + + # get unconditional embeddings for classifier free guidance + if do_classifier_free_guidance and negative_prompt_embeds is None: + uncond_tokens: List[str] + if negative_prompt is None: + uncond_tokens = [""] * batch_size + elif prompt is not None and type(prompt) is not type(negative_prompt): + raise TypeError( + f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !=" + f" {type(prompt)}." + ) + elif isinstance(negative_prompt, str): + uncond_tokens = [negative_prompt] + elif batch_size != len(negative_prompt): + raise ValueError( + f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:" + f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches" + " the batch size of `prompt`." + ) + else: + uncond_tokens = negative_prompt + + # textual inversion: procecss multi-vector tokens if necessary + if isinstance(self, TextualInversionLoaderMixin): + uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer) + + max_length = prompt_embeds.shape[1] + uncond_input = self.tokenizer( + uncond_tokens, + padding="max_length", + max_length=max_length, + truncation=True, + return_tensors="pt", + ) + + if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask: + attention_mask = uncond_input.attention_mask.to(device) + else: + attention_mask = None + + negative_prompt_embeds = self.text_encoder( + uncond_input.input_ids.to(device), + attention_mask=attention_mask, + ) + negative_prompt_embeds = negative_prompt_embeds[0] + + if do_classifier_free_guidance: + # duplicate unconditional embeddings for each generation per prompt, using mps friendly method + seq_len = negative_prompt_embeds.shape[1] + + negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device) + + negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1) + negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1) + + # For classifier free guidance, we need to do two forward passes. + # Here we concatenate the unconditional and text embeddings into a single batch + # to avoid doing two forward passes + prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds]) + + return prompt_embeds + + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker + def run_safety_checker(self, image, device, dtype): + if self.safety_checker is None: + has_nsfw_concept = None + else: + if torch.is_tensor(image): + feature_extractor_input = self.image_processor.postprocess(image, output_type="pil") + else: + feature_extractor_input = self.image_processor.numpy_to_pil(image) + safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device) + image, has_nsfw_concept = self.safety_checker( + images=image, clip_input=safety_checker_input.pixel_values.to(dtype) + ) + return image, has_nsfw_concept + + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents + def decode_latents(self, latents): + warnings.warn( + "The decode_latents method is deprecated and will be removed in a future version. Please" + " use VaeImageProcessor instead", + FutureWarning, + ) + latents = 1 / self.vae.config.scaling_factor * latents + image = self.vae.decode(latents, return_dict=False)[0] + image = (image / 2 + 0.5).clamp(0, 1) + # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16 + image = image.cpu().permute(0, 2, 3, 1).float().numpy() + return image + + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs + def prepare_extra_step_kwargs(self, generator, eta): + # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature + # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers. + # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502 + # and should be between [0, 1] + + accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys()) + extra_step_kwargs = {} + if accepts_eta: + extra_step_kwargs["eta"] = eta + + # check if the scheduler accepts generator + accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys()) + if accepts_generator: + extra_step_kwargs["generator"] = generator + return extra_step_kwargs + + def check_inputs( + self, + prompt, + image, + callback_steps, + negative_prompt=None, + prompt_embeds=None, + negative_prompt_embeds=None, + controlnet_conditioning_scale=1.0, + ): + if (callback_steps is None) or ( + callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0) + ): + raise ValueError( + f"`callback_steps` has to be a positive integer but is {callback_steps} of type" + f" {type(callback_steps)}." + ) + + if prompt is not None and prompt_embeds is not None: + raise ValueError( + f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to" + " only forward one of the two." + ) + elif prompt is None and prompt_embeds is None: + raise ValueError( + "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined." + ) + elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)): + raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}") + + if negative_prompt is not None and negative_prompt_embeds is not None: + raise ValueError( + f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:" + f" {negative_prompt_embeds}. Please make sure to only forward one of the two." + ) + + if prompt_embeds is not None and negative_prompt_embeds is not None: + if prompt_embeds.shape != negative_prompt_embeds.shape: + raise ValueError( + "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but" + f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`" + f" {negative_prompt_embeds.shape}." + ) + + # `prompt` needs more sophisticated handling when there are multiple + # conditionings. + if isinstance(self.controlnet, MultiControlNetModel): + if isinstance(prompt, list): + logger.warning( + f"You have {len(self.controlnet.nets)} ControlNets and you have passed {len(prompt)}" + " prompts. The conditionings will be fixed across the prompts." + ) + + # Check `image` + is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance( + self.controlnet, torch._dynamo.eval_frame.OptimizedModule + ) + if ( + isinstance(self.controlnet, ControlNetModel) + or is_compiled + and isinstance(self.controlnet._orig_mod, ControlNetModel) + ): + self.check_image(image, prompt, prompt_embeds) + elif ( + isinstance(self.controlnet, MultiControlNetModel) + or is_compiled + and isinstance(self.controlnet._orig_mod, MultiControlNetModel) + ): + if not isinstance(image, list): + raise TypeError("For multiple controlnets: `image` must be type `list`") + + # When `image` is a nested list: + # (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]]) + elif any(isinstance(i, list) for i in image): + raise ValueError("A single batch of multiple conditionings are supported at the moment.") + elif len(image) != len(self.controlnet.nets): + raise ValueError( + f"For multiple controlnets: `image` must have the same length as the number of controlnets, but got {len(image)} images and {len(self.controlnet.nets)} ControlNets." + ) + + for image_ in image: + self.check_image(image_, prompt, prompt_embeds) + else: + if self.controlnet == None: + return + assert False + + # Check `controlnet_conditioning_scale` + if ( + isinstance(self.controlnet, ControlNetModel) + or is_compiled + and isinstance(self.controlnet._orig_mod, ControlNetModel) + ): + if not isinstance(controlnet_conditioning_scale, float): + raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.") + elif ( + isinstance(self.controlnet, MultiControlNetModel) + or is_compiled + and isinstance(self.controlnet._orig_mod, MultiControlNetModel) + ): + if isinstance(controlnet_conditioning_scale, list): + if any(isinstance(i, list) for i in controlnet_conditioning_scale): + raise ValueError("A single batch of multiple conditionings are supported at the moment.") + elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len( + self.controlnet.nets + ): + raise ValueError( + "For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have" + " the same length as the number of controlnets" + ) + else: + assert False + + # Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.check_image + def check_image(self, image, prompt, prompt_embeds): + image_is_pil = isinstance(image, PIL.Image.Image) + image_is_tensor = isinstance(image, torch.Tensor) + image_is_np = isinstance(image, np.ndarray) + image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image) + image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor) + image_is_np_list = isinstance(image, list) and isinstance(image[0], np.ndarray) + + if ( + not image_is_pil + and not image_is_tensor + and not image_is_np + and not image_is_pil_list + and not image_is_tensor_list + and not image_is_np_list + ): + raise TypeError( + f"image must be passed and be one of PIL image, numpy array, torch tensor, list of PIL images, list of numpy arrays or list of torch tensors, but is {type(image)}" + ) + + if image_is_pil: + image_batch_size = 1 + else: + image_batch_size = len(image) + + if prompt is not None and isinstance(prompt, str): + prompt_batch_size = 1 + elif prompt is not None and isinstance(prompt, list): + prompt_batch_size = len(prompt) + elif prompt_embeds is not None: + prompt_batch_size = prompt_embeds.shape[0] + + if image_batch_size != 1 and image_batch_size != prompt_batch_size: + raise ValueError( + f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}" + ) + + # Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.prepare_image + def prepare_control_image( + self, + image, + width, + height, + batch_size, + num_images_per_prompt, + device, + dtype, + do_classifier_free_guidance=False, + guess_mode=False, + ): + image = self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32) + image_batch_size = image.shape[0] + + if image_batch_size == 1: + repeat_by = batch_size + else: + # image batch size is the same as prompt batch size + repeat_by = num_images_per_prompt + + image = image.repeat_interleave(repeat_by, dim=0) + + image = image.to(device=device, dtype=dtype) + + if do_classifier_free_guidance and not guess_mode: + image = torch.cat([image] * 2) + + return image + + def prepare_ref_image( + self, + image, + width, + height, + batch_size, + num_images_per_prompt, + device, + dtype, + do_classifier_free_guidance=False, + guess_mode=False, + ): + image = self.image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32) + image_batch_size = image.shape[0] + + if image_batch_size == 1: + repeat_by = batch_size + else: + # image batch size is the same as prompt batch size + repeat_by = num_images_per_prompt + + image = image.repeat_interleave(repeat_by, dim=0) + + image = image.to(device=device, dtype=dtype) + + if do_classifier_free_guidance and not guess_mode: + image = torch.cat([image] * 2) + + return image + + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.get_timesteps + def get_timesteps(self, num_inference_steps, strength, device): + # get the original timestep using init_timestep + init_timestep = min(int(num_inference_steps * strength), num_inference_steps) + + t_start = max(num_inference_steps - init_timestep, 0) + timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :] + + return timesteps, num_inference_steps - t_start + + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.prepare_latents + def prepare_latents(self, image, timestep, batch_size, num_images_per_prompt, dtype, device, generator=None): + if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)): + raise ValueError( + f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}" + ) + + image = image.to(device=device, dtype=dtype) + + batch_size = batch_size * num_images_per_prompt + + if image.shape[1] == 4: + init_latents = image + + else: + if isinstance(generator, list) and len(generator) != batch_size: + raise ValueError( + f"You have passed a list of generators of length {len(generator)}, but requested an effective batch" + f" size of {batch_size}. Make sure the batch size matches the length of the generators." + ) + + elif isinstance(generator, list): + init_latents = [ + self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size) + ] + init_latents = torch.cat(init_latents, dim=0) + else: + init_latents = self.vae.encode(image).latent_dist.sample(generator) + + init_latents = self.vae.config.scaling_factor * init_latents + + if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0: + # expand init_latents for batch_size + deprecation_message = ( + f"You have passed {batch_size} text prompts (`prompt`), but only {init_latents.shape[0]} initial" + " images (`image`). Initial images are now duplicating to match the number of text prompts. Note" + " that this behavior is deprecated and will be removed in a version 1.0.0. Please make sure to update" + " your script to pass as many initial images as text prompts to suppress this warning." + ) + deprecate("len(prompt) != len(image)", "1.0.0", deprecation_message, standard_warn=False) + additional_image_per_prompt = batch_size // init_latents.shape[0] + init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0) + elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0: + raise ValueError( + f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts." + ) + else: + init_latents = torch.cat([init_latents], dim=0) + + shape = init_latents.shape + noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype) + + # get latents + init_latents = self.scheduler.add_noise(init_latents, noise, timestep) + latents = init_latents + + return latents + + @torch.no_grad() + @replace_example_docstring(EXAMPLE_DOC_STRING) + def __call__( + self, + prompt: Union[str, List[str]] = None, + image: Union[ + torch.FloatTensor, + PIL.Image.Image, + np.ndarray, + List[torch.FloatTensor], + List[PIL.Image.Image], + List[np.ndarray], + ] = None, + control_image: Union[ + torch.FloatTensor, + PIL.Image.Image, + np.ndarray, + List[torch.FloatTensor], + List[PIL.Image.Image], + List[np.ndarray], + ] = None, + ref_image: Union[torch.FloatTensor, PIL.Image.Image] = None, + height: Optional[int] = None, + width: Optional[int] = None, + strength: float = 0.8, + num_inference_steps: int = 50, + guidance_scale: float = 7.5, + negative_prompt: Optional[Union[str, List[str]]] = None, + num_images_per_prompt: Optional[int] = 1, + eta: float = 0.0, + generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None, + latents: Optional[torch.FloatTensor] = None, + prompt_embeds: Optional[torch.FloatTensor] = None, + negative_prompt_embeds: Optional[torch.FloatTensor] = None, + output_type: Optional[str] = "pil", + return_dict: bool = True, + callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None, + callback_steps: int = 1, + cross_attention_kwargs: Optional[Dict[str, Any]] = None, + controlnet_conditioning_scale: Union[float, List[float]] = 0.8, + guess_mode: bool = False, + attention_auto_machine_weight: float = 1.0, + gn_auto_machine_weight: float = 1.0, + style_fidelity: float = 0.5, + reference_attn: bool = True, + reference_adain: bool = True, + ): + r""" + Function invoked when calling the pipeline for generation. + + Args: + prompt (`str` or `List[str]`, *optional*): + The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`. + instead. + image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,: + `List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`): + The initial image will be used as the starting point for the image generation process. Can also accpet + image latents as `image`, if passing latents directly, it will not be encoded again. + control_image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,: + `List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`): + The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If + the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can + also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If + height and/or width are passed, `image` is resized according to them. If multiple ControlNets are + specified in init, images must be passed as a list such that each element of the list can be correctly + batched for input to a single controlnet. + ref_image (`torch.FloatTensor`, `PIL.Image.Image`): + The Reference Control input condition. Reference Control uses this input condition to generate guidance to Unet. If + the type is specified as `Torch.FloatTensor`, it is passed to Reference Control as is. `PIL.Image.Image` can + also be accepted as an image. + height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor): + The height in pixels of the generated image. + width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor): + The width in pixels of the generated image. + num_inference_steps (`int`, *optional*, defaults to 50): + The number of denoising steps. More denoising steps usually lead to a higher quality image at the + expense of slower inference. + guidance_scale (`float`, *optional*, defaults to 7.5): + Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598). + `guidance_scale` is defined as `w` of equation 2. of [Imagen + Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale > + 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`, + usually at the expense of lower image quality. + negative_prompt (`str` or `List[str]`, *optional*): + The prompt or prompts not to guide the image generation. If not defined, one has to pass + `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is + less than `1`). + num_images_per_prompt (`int`, *optional*, defaults to 1): + The number of images to generate per prompt. + eta (`float`, *optional*, defaults to 0.0): + Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to + [`schedulers.DDIMScheduler`], will be ignored for others. + generator (`torch.Generator` or `List[torch.Generator]`, *optional*): + One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html) + to make generation deterministic. + latents (`torch.FloatTensor`, *optional*): + Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image + generation. Can be used to tweak the same generation with different prompts. If not provided, a latents + tensor will ge generated by sampling using the supplied random `generator`. + prompt_embeds (`torch.FloatTensor`, *optional*): + Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not + provided, text embeddings will be generated from `prompt` input argument. + negative_prompt_embeds (`torch.FloatTensor`, *optional*): + Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt + weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input + argument. + output_type (`str`, *optional*, defaults to `"pil"`): + The output format of the generate image. Choose between + [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`. + return_dict (`bool`, *optional*, defaults to `True`): + Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a + plain tuple. + callback (`Callable`, *optional*): + A function that will be called every `callback_steps` steps during inference. The function will be + called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`. + callback_steps (`int`, *optional*, defaults to 1): + The frequency at which the `callback` function will be called. If not specified, the callback will be + called at every step. + cross_attention_kwargs (`dict`, *optional*): + A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under + `self.processor` in + [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py). + controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0): + The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added + to the residual in the original unet. If multiple ControlNets are specified in init, you can set the + corresponding scale as a list. Note that by default, we use a smaller conditioning scale for inpainting + than for [`~StableDiffusionControlNetPipeline.__call__`]. + guess_mode (`bool`, *optional*, defaults to `False`): + In this mode, the ControlNet encoder will try best to recognize the content of the input image even if + you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended. + attention_auto_machine_weight (`float`): + Weight of using reference query for self attention's context. + If attention_auto_machine_weight=1.0, use reference query for all self attention's context. + gn_auto_machine_weight (`float`): + Weight of using reference adain. If gn_auto_machine_weight=2.0, use all reference adain plugins. + style_fidelity (`float`): + style fidelity of ref_uncond_xt. If style_fidelity=1.0, control more important, + elif style_fidelity=0.0, prompt more important, else balanced. + reference_attn (`bool`): + Whether to use reference query for self attention's context. + reference_adain (`bool`): + Whether to use reference adain. + + Examples: + + Returns: + [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`: + [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple. + When returning a tuple, the first element is a list with the generated images, and the second element is a + list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work" + (nsfw) content, according to the `safety_checker`. + """ + assert reference_attn or reference_adain, "`reference_attn` or `reference_adain` must be True." + + # 1. Check inputs. Raise error if not correct + self.check_inputs( + prompt, + control_image, + callback_steps, + negative_prompt, + prompt_embeds, + negative_prompt_embeds, + controlnet_conditioning_scale, + ) + + # 2. Define call parameters + if prompt is not None and isinstance(prompt, str): + batch_size = 1 + elif prompt is not None and isinstance(prompt, list): + batch_size = len(prompt) + else: + batch_size = prompt_embeds.shape[0] + + device = self._execution_device + # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2) + # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1` + # corresponds to doing no classifier free guidance. + do_classifier_free_guidance = guidance_scale > 1.0 + + if self.controlnet == None: + pass + else: + controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet + + if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float): + controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets) + + global_pool_conditions = ( + controlnet.config.global_pool_conditions + if isinstance(controlnet, ControlNetModel) + else controlnet.nets[0].config.global_pool_conditions + ) + guess_mode = guess_mode or global_pool_conditions + + # 3. Encode input prompt + text_encoder_lora_scale = ( + cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None + ) + prompt_embeds = self._encode_prompt( + prompt, + device, + num_images_per_prompt, + do_classifier_free_guidance, + negative_prompt, + prompt_embeds=prompt_embeds, + negative_prompt_embeds=negative_prompt_embeds, + lora_scale=text_encoder_lora_scale, + ) + + # 4. Prepare image + image = self.image_processor.preprocess(image).to(dtype=torch.float32) + + # 5. Prepare controlnet_conditioning_image + if self.controlnet == None: + pass + else: + if isinstance(controlnet, ControlNetModel): + control_image = self.prepare_control_image( + image=control_image, + width=width, + height=height, + batch_size=batch_size * num_images_per_prompt, + num_images_per_prompt=num_images_per_prompt, + device=device, + dtype=controlnet.dtype, + do_classifier_free_guidance=do_classifier_free_guidance, + guess_mode=guess_mode, + ) + elif isinstance(controlnet, MultiControlNetModel): + control_images = [] + + for control_image_ in control_image: + control_image_ = self.prepare_control_image( + image=control_image_, + width=width, + height=height, + batch_size=batch_size * num_images_per_prompt, + num_images_per_prompt=num_images_per_prompt, + device=device, + dtype=controlnet.dtype, + do_classifier_free_guidance=do_classifier_free_guidance, + guess_mode=guess_mode, + ) + + control_images.append(control_image_) + + control_image = control_images + else: + assert False + + # 5. Preprocess reference image + ref_image = self.prepare_ref_image( + image=ref_image, + width=width, + height=height, + batch_size=batch_size * num_images_per_prompt, + num_images_per_prompt=num_images_per_prompt, + device=device, + dtype=prompt_embeds.dtype + ) + + # 6. Prepare timesteps + self.scheduler.set_timesteps(num_inference_steps, device=device) + timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device) + latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt) + + # 7. Prepare latent variables + latents = self.prepare_latents( + image, + latent_timestep, + batch_size, + num_images_per_prompt, + prompt_embeds.dtype, + device, + generator, + ) + + # 8. Prepare reference latent variables + ref_image_latents = self.prepare_ref_latents( + ref_image, + batch_size * num_images_per_prompt, + prompt_embeds.dtype, + device, + generator, + do_classifier_free_guidance, + ) + + # 9. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline + extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta) + + # 9. Modify self attention and group norm + MODE = "write" + uc_mask = ( + torch.Tensor([1] * batch_size * num_images_per_prompt + [0] * batch_size * num_images_per_prompt) + .type_as(ref_image_latents) + .bool() + ) + + def hacked_basic_transformer_inner_forward( + self, + hidden_states: torch.FloatTensor, + attention_mask: Optional[torch.FloatTensor] = None, + encoder_hidden_states: Optional[torch.FloatTensor] = None, + encoder_attention_mask: Optional[torch.FloatTensor] = None, + timestep: Optional[torch.LongTensor] = None, + cross_attention_kwargs: Dict[str, Any] = None, + class_labels: Optional[torch.LongTensor] = None, + ): + if self.use_ada_layer_norm: + norm_hidden_states = self.norm1(hidden_states, timestep) + elif self.use_ada_layer_norm_zero: + norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1( + hidden_states, timestep, class_labels, hidden_dtype=hidden_states.dtype + ) + else: + norm_hidden_states = self.norm1(hidden_states) + + # 1. Self-Attention + cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {} + if self.only_cross_attention: + attn_output = self.attn1( + norm_hidden_states, + encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None, + attention_mask=attention_mask, + **cross_attention_kwargs, + ) + else: + if MODE == "write": + self.bank.append(norm_hidden_states.detach().clone()) + attn_output = self.attn1( + norm_hidden_states, + encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None, + attention_mask=attention_mask, + **cross_attention_kwargs, + ) + if MODE == "read": + if attention_auto_machine_weight > self.attn_weight: + attn_output_uc = self.attn1( + norm_hidden_states, + encoder_hidden_states=torch.cat([norm_hidden_states] + self.bank, dim=1), + # attention_mask=attention_mask, + **cross_attention_kwargs, + ) + attn_output_c = attn_output_uc.clone() + if do_classifier_free_guidance and style_fidelity > 0: + attn_output_c[uc_mask] = self.attn1( + norm_hidden_states[uc_mask], + encoder_hidden_states=norm_hidden_states[uc_mask], + **cross_attention_kwargs, + ) + attn_output = style_fidelity * attn_output_c + (1.0 - style_fidelity) * attn_output_uc + else: + attn_output = self.attn1( + norm_hidden_states, + encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None, + attention_mask=attention_mask, + **cross_attention_kwargs, + ) + self.bank.clear() + if self.use_ada_layer_norm_zero: + attn_output = gate_msa.unsqueeze(1) * attn_output + hidden_states = attn_output + hidden_states + + if self.attn2 is not None: + norm_hidden_states = ( + self.norm2(hidden_states, timestep) if self.use_ada_layer_norm else self.norm2(hidden_states) + ) + + # 2. Cross-Attention + attn_output = self.attn2( + norm_hidden_states, + encoder_hidden_states=encoder_hidden_states, + attention_mask=encoder_attention_mask, + **cross_attention_kwargs, + ) + hidden_states = attn_output + hidden_states + + # 3. Feed-forward + norm_hidden_states = self.norm3(hidden_states) + + if self.use_ada_layer_norm_zero: + norm_hidden_states = norm_hidden_states * (1 + scale_mlp[:, None]) + shift_mlp[:, None] + + ff_output = self.ff(norm_hidden_states) + + if self.use_ada_layer_norm_zero: + ff_output = gate_mlp.unsqueeze(1) * ff_output + + hidden_states = ff_output + hidden_states + + return hidden_states + + def hacked_mid_forward(self, *args, **kwargs): + eps = 1e-6 + x = self.original_forward(*args, **kwargs) + if MODE == "write": + if gn_auto_machine_weight >= self.gn_weight: + var, mean = torch.var_mean(x, dim=(2, 3), keepdim=True, correction=0) + self.mean_bank.append(mean) + self.var_bank.append(var) + if MODE == "read": + if len(self.mean_bank) > 0 and len(self.var_bank) > 0: + var, mean = torch.var_mean(x, dim=(2, 3), keepdim=True, correction=0) + std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5 + mean_acc = sum(self.mean_bank) / float(len(self.mean_bank)) + var_acc = sum(self.var_bank) / float(len(self.var_bank)) + std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5 + x_uc = (((x - mean) / std) * std_acc) + mean_acc + x_c = x_uc.clone() + if do_classifier_free_guidance and style_fidelity > 0: + x_c[uc_mask] = x[uc_mask] + x = style_fidelity * x_c + (1.0 - style_fidelity) * x_uc + self.mean_bank = [] + self.var_bank = [] + return x + + def hack_CrossAttnDownBlock2D_forward( + self, + hidden_states: torch.FloatTensor, + temb: Optional[torch.FloatTensor] = None, + encoder_hidden_states: Optional[torch.FloatTensor] = None, + attention_mask: Optional[torch.FloatTensor] = None, + cross_attention_kwargs: Optional[Dict[str, Any]] = None, + encoder_attention_mask: Optional[torch.FloatTensor] = None, + ): + eps = 1e-6 + + # TODO(Patrick, William) - attention mask is not used + output_states = () + + for i, (resnet, attn) in enumerate(zip(self.resnets, self.attentions)): + hidden_states = resnet(hidden_states, temb) + hidden_states = attn( + hidden_states, + encoder_hidden_states=encoder_hidden_states, + cross_attention_kwargs=cross_attention_kwargs, + attention_mask=attention_mask, + encoder_attention_mask=encoder_attention_mask, + return_dict=False, + )[0] + if MODE == "write": + if gn_auto_machine_weight >= self.gn_weight: + var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0) + self.mean_bank.append([mean]) + self.var_bank.append([var]) + if MODE == "read": + if len(self.mean_bank) > 0 and len(self.var_bank) > 0: + var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0) + std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5 + mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i])) + var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i])) + std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5 + hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc + hidden_states_c = hidden_states_uc.clone() + if do_classifier_free_guidance and style_fidelity > 0: + hidden_states_c[uc_mask] = hidden_states[uc_mask] + hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc + + output_states = output_states + (hidden_states,) + + if MODE == "read": + self.mean_bank = [] + self.var_bank = [] + + if self.downsamplers is not None: + for downsampler in self.downsamplers: + hidden_states = downsampler(hidden_states) + + output_states = output_states + (hidden_states,) + + return hidden_states, output_states + + def hacked_DownBlock2D_forward(self, hidden_states, temb=None): + eps = 1e-6 + + output_states = () + + for i, resnet in enumerate(self.resnets): + hidden_states = resnet(hidden_states, temb) + + if MODE == "write": + if gn_auto_machine_weight >= self.gn_weight: + var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0) + self.mean_bank.append([mean]) + self.var_bank.append([var]) + if MODE == "read": + if len(self.mean_bank) > 0 and len(self.var_bank) > 0: + var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0) + std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5 + mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i])) + var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i])) + std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5 + hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc + hidden_states_c = hidden_states_uc.clone() + if do_classifier_free_guidance and style_fidelity > 0: + hidden_states_c[uc_mask] = hidden_states[uc_mask] + hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc + + output_states = output_states + (hidden_states,) + + if MODE == "read": + self.mean_bank = [] + self.var_bank = [] + + if self.downsamplers is not None: + for downsampler in self.downsamplers: + hidden_states = downsampler(hidden_states) + + output_states = output_states + (hidden_states,) + + return hidden_states, output_states + + def hacked_CrossAttnUpBlock2D_forward( + self, + hidden_states: torch.FloatTensor, + res_hidden_states_tuple: Tuple[torch.FloatTensor, ...], + temb: Optional[torch.FloatTensor] = None, + encoder_hidden_states: Optional[torch.FloatTensor] = None, + cross_attention_kwargs: Optional[Dict[str, Any]] = None, + upsample_size: Optional[int] = None, + attention_mask: Optional[torch.FloatTensor] = None, + encoder_attention_mask: Optional[torch.FloatTensor] = None, + ): + eps = 1e-6 + # TODO(Patrick, William) - attention mask is not used + for i, (resnet, attn) in enumerate(zip(self.resnets, self.attentions)): + # pop res hidden states + res_hidden_states = res_hidden_states_tuple[-1] + res_hidden_states_tuple = res_hidden_states_tuple[:-1] + hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1) + hidden_states = resnet(hidden_states, temb) + hidden_states = attn( + hidden_states, + encoder_hidden_states=encoder_hidden_states, + cross_attention_kwargs=cross_attention_kwargs, + attention_mask=attention_mask, + encoder_attention_mask=encoder_attention_mask, + return_dict=False, + )[0] + + if MODE == "write": + if gn_auto_machine_weight >= self.gn_weight: + var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0) + self.mean_bank.append([mean]) + self.var_bank.append([var]) + if MODE == "read": + if len(self.mean_bank) > 0 and len(self.var_bank) > 0: + var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0) + std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5 + mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i])) + var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i])) + std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5 + hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc + hidden_states_c = hidden_states_uc.clone() + if do_classifier_free_guidance and style_fidelity > 0: + hidden_states_c[uc_mask] = hidden_states[uc_mask] + hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc + + if MODE == "read": + self.mean_bank = [] + self.var_bank = [] + + if self.upsamplers is not None: + for upsampler in self.upsamplers: + hidden_states = upsampler(hidden_states, upsample_size) + + return hidden_states + + def hacked_UpBlock2D_forward(self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None): + eps = 1e-6 + for i, resnet in enumerate(self.resnets): + # pop res hidden states + res_hidden_states = res_hidden_states_tuple[-1] + res_hidden_states_tuple = res_hidden_states_tuple[:-1] + hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1) + hidden_states = resnet(hidden_states, temb) + + if MODE == "write": + if gn_auto_machine_weight >= self.gn_weight: + var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0) + self.mean_bank.append([mean]) + self.var_bank.append([var]) + if MODE == "read": + if len(self.mean_bank) > 0 and len(self.var_bank) > 0: + var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0) + std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5 + mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i])) + var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i])) + std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5 + hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc + hidden_states_c = hidden_states_uc.clone() + if do_classifier_free_guidance and style_fidelity > 0: + hidden_states_c[uc_mask] = hidden_states[uc_mask] + hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc + + if MODE == "read": + self.mean_bank = [] + self.var_bank = [] + + if self.upsamplers is not None: + for upsampler in self.upsamplers: + hidden_states = upsampler(hidden_states, upsample_size) + + return hidden_states + + if reference_attn: + attn_modules = [module for module in torch_dfs(self.unet) if isinstance(module, BasicTransformerBlock)] + attn_modules = sorted(attn_modules, key=lambda x: -x.norm1.normalized_shape[0]) + + for i, module in enumerate(attn_modules): + module._original_inner_forward = module.forward + module.forward = hacked_basic_transformer_inner_forward.__get__(module, BasicTransformerBlock) + module.bank = [] + module.attn_weight = float(i) / float(len(attn_modules)) + + if reference_adain: + gn_modules = [self.unet.mid_block] + self.unet.mid_block.gn_weight = 0 + + down_blocks = self.unet.down_blocks + for w, module in enumerate(down_blocks): + module.gn_weight = 1.0 - float(w) / float(len(down_blocks)) + gn_modules.append(module) + + up_blocks = self.unet.up_blocks + for w, module in enumerate(up_blocks): + module.gn_weight = float(w) / float(len(up_blocks)) + gn_modules.append(module) + + for i, module in enumerate(gn_modules): + if getattr(module, "original_forward", None) is None: + module.original_forward = module.forward + if i == 0: + # mid_block + module.forward = hacked_mid_forward.__get__(module, torch.nn.Module) + elif isinstance(module, CrossAttnDownBlock2D): + module.forward = hack_CrossAttnDownBlock2D_forward.__get__(module, CrossAttnDownBlock2D) + elif isinstance(module, DownBlock2D): + module.forward = hacked_DownBlock2D_forward.__get__(module, DownBlock2D) + elif isinstance(module, CrossAttnUpBlock2D): + module.forward = hacked_CrossAttnUpBlock2D_forward.__get__(module, CrossAttnUpBlock2D) + elif isinstance(module, UpBlock2D): + module.forward = hacked_UpBlock2D_forward.__get__(module, UpBlock2D) + module.mean_bank = [] + module.var_bank = [] + module.gn_weight *= 2 + + # 11. Denoising loop + num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order + with self.progress_bar(total=num_inference_steps) as progress_bar: + for i, t in enumerate(timesteps): + # expand the latents if we are doing classifier free guidance + latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents + latent_model_input = self.scheduler.scale_model_input(latent_model_input, t) + + if self.controlnet == None: + down_block_res_samples = None + mid_block_res_sample=None + else: + # controlnet(s) inference + if guess_mode and do_classifier_free_guidance: + # Infer ControlNet only for the conditional batch. + control_model_input = latents + control_model_input = self.scheduler.scale_model_input(control_model_input, t) + controlnet_prompt_embeds = prompt_embeds.chunk(2)[1] + else: + control_model_input = latent_model_input + controlnet_prompt_embeds = prompt_embeds + + down_block_res_samples, mid_block_res_sample = self.controlnet( + control_model_input, + t, + encoder_hidden_states=controlnet_prompt_embeds, + controlnet_cond=control_image, + conditioning_scale=controlnet_conditioning_scale, + guess_mode=guess_mode, + return_dict=False, + ) + + if guess_mode and do_classifier_free_guidance: + # Infered ControlNet only for the conditional batch. + # To apply the output of ControlNet to both the unconditional and conditional batches, + # add 0 to the unconditional batch to keep it unchanged. + down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples] + mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample]) + + # ref only part + noise = randn_tensor( + ref_image_latents.shape, generator=generator, device=device, dtype=ref_image_latents.dtype + ) + ref_xt = self.scheduler.add_noise( + ref_image_latents, + noise, + t.reshape( + 1, + ), + ) + ref_xt = self.scheduler.scale_model_input(ref_xt, t) + + MODE = "write" + self.unet( + ref_xt, + t, + encoder_hidden_states=prompt_embeds, + cross_attention_kwargs=cross_attention_kwargs, + return_dict=False, + ) + + # predict the noise residual + MODE = "read" + noise_pred = self.unet( + latent_model_input, + t, + encoder_hidden_states=prompt_embeds, + cross_attention_kwargs=cross_attention_kwargs, + down_block_additional_residuals=down_block_res_samples, + mid_block_additional_residual=mid_block_res_sample, + return_dict=False, + )[0] + + # perform guidance + if do_classifier_free_guidance: + noise_pred_uncond, noise_pred_text = noise_pred.chunk(2) + noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond) + + # compute the previous noisy sample x_t -> x_t-1 + latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0] + + # call the callback, if provided + if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0): + progress_bar.update() + if callback is not None and i % callback_steps == 0: + callback(i, t, latents) + + # If we do sequential model offloading, let's offload unet and controlnet + # manually for max memory savings + if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None: + self.unet.to("cpu") + self.controlnet.to("cpu") + torch.cuda.empty_cache() + + if not output_type == "latent": + image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0] + image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype) + else: + image = latents + has_nsfw_concept = None + + if has_nsfw_concept is None: + do_denormalize = [True] * image.shape[0] + else: + do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept] + + image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize) + + # Offload last model to CPU + if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None: + self.final_offload_hook.offload() + + if not return_dict: + return (image, has_nsfw_concept) + + return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept) \ No newline at end of file diff --git a/animate/src/animatediff/pipelines/sdxl_animation.py b/animate/src/animatediff/pipelines/sdxl_animation.py new file mode 100644 index 0000000000000000000000000000000000000000..45454c73975825bf51c08ed36a4cd621fc3c8c09 --- /dev/null +++ b/animate/src/animatediff/pipelines/sdxl_animation.py @@ -0,0 +1,2222 @@ +# Copyright 2023 The HuggingFace Team. All rights reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +import inspect +import os +from dataclasses import dataclass +from typing import Any, Callable, Dict, List, Optional, Tuple, Union + +import numpy as np +import torch +from diffusers import LCMScheduler +from diffusers.image_processor import VaeImageProcessor +from diffusers.loaders import (FromSingleFileMixin, StableDiffusionXLLoraLoaderMixin, + TextualInversionLoaderMixin) +from diffusers.models import AutoencoderKL, ControlNetModel +from diffusers.models.attention_processor import (AttnProcessor2_0, + LoRAAttnProcessor2_0, + LoRAXFormersAttnProcessor, + XFormersAttnProcessor) +from diffusers.pipelines.pipeline_utils import DiffusionPipeline +from diffusers.schedulers import KarrasDiffusionSchedulers +from diffusers.utils import (BaseOutput, is_accelerate_available, + is_accelerate_version, logging, + replace_example_docstring) +from diffusers.utils.torch_utils import randn_tensor +from einops import rearrange +from transformers import (CLIPTextModel, CLIPTextModelWithProjection, + CLIPTokenizer) + +from animatediff.ip_adapter import IPAdapterPlusXL, IPAdapterXL +from animatediff.pipelines.animation import PromptEncoder, RegionMask +from animatediff.pipelines.context import (get_context_scheduler, + get_total_steps) +from animatediff.sdxl_models.unet import UNet2DConditionModel +from animatediff.utils.control_net_lllite import ControlNetLLLite +from animatediff.utils.lpw_stable_diffusion_xl import \ + get_weighted_text_embeddings_sdxl2 +from animatediff.utils.util import (get_tensor_interpolation_method, show_gpu, + stopwatch_record, stopwatch_start, + stopwatch_stop) + + +class PromptEncoderSDXL(PromptEncoder): + def __init__( + self, + pipe, + device, + latents_device, + num_videos_per_prompt, + do_classifier_free_guidance, + region_condi_list, + negative_prompt, + is_signle_prompt_mode, + clip_skip, + multi_uncond_mode + ): + self.pipe = pipe + self.is_single_prompt_mode=is_signle_prompt_mode + self.do_classifier_free_guidance = do_classifier_free_guidance + + uncond_num = 0 + if do_classifier_free_guidance: + if multi_uncond_mode: + uncond_num = len(region_condi_list) + else: + uncond_num = 1 + + self.uncond_num = uncond_num + + ### text + + prompt_nums = [] + prompt_map_list = [] + prompt_list = [] + + for condi in region_condi_list: + _prompt_map = condi["prompt_map"] + prompt_map_list.append(_prompt_map) + _prompt_map = dict(sorted(_prompt_map.items())) + _prompt_list = [_prompt_map[key_frame] for key_frame in _prompt_map.keys()] + prompt_nums.append( len(_prompt_list) ) + prompt_list += _prompt_list + + (prompt_embeds_list, negative_prompt_embeds_list, + pooled_prompt_embeds_list, negative_pooled_prompt_embeds_list) = get_weighted_text_embeddings_sdxl2( + pipe, prompt_list, [negative_prompt], latents_device + ) + + self.prompt_embeds_dtype = prompt_embeds_list[0].dtype + + + if do_classifier_free_guidance: + negative = negative_prompt_embeds_list + negative_pooled = negative_pooled_prompt_embeds_list + positive = prompt_embeds_list + positive_pooled = pooled_prompt_embeds_list + else: + positive = prompt_embeds_list + positive_pooled = pooled_prompt_embeds_list + + if pipe.ip_adapter: + pipe.ip_adapter.set_text_length(positive[0].shape[1]) + + prompt_embeds_region_list = [] + pooled_embeds_region_list = [] + + if do_classifier_free_guidance: + prompt_embeds_region_list = [ + { + 0:negative[0] + } + ] * uncond_num + prompt_embeds_region_list + pooled_embeds_region_list = [ + { + 0:negative_pooled[0] + } + ] * uncond_num + pooled_embeds_region_list + + pos_index = 0 + for prompt_map, num in zip(prompt_map_list, prompt_nums): + prompt_embeds_map={} + pooled_embeds_map={} + pos = positive[pos_index:pos_index+num] + pos_pooled = positive_pooled[pos_index:pos_index+num] + + for i, key_frame in enumerate(prompt_map): + prompt_embeds_map[key_frame] = pos[i] + pooled_embeds_map[key_frame] = pos_pooled[i] + + prompt_embeds_region_list.append( prompt_embeds_map ) + pooled_embeds_region_list.append( pooled_embeds_map ) + pos_index += num + + if do_classifier_free_guidance: + prompt_map_list = [ + { + 0:negative_prompt + } + ] * uncond_num + prompt_map_list + + self.prompt_map_list = prompt_map_list + self.prompt_embeds_region_list = prompt_embeds_region_list + self.pooled_embeds_region_list = pooled_embeds_region_list + + ### image + if pipe.ip_adapter: + + ip_im_nums = [] + ip_im_map_list = [] + ip_im_list = [] + + for condi in region_condi_list: + _ip_im_map = condi["ip_adapter_map"]["images"] + ip_im_map_list.append(_ip_im_map) + _ip_im_map = dict(sorted(_ip_im_map.items())) + _ip_im_list = [_ip_im_map[key_frame] for key_frame in _ip_im_map.keys()] + ip_im_nums.append( len(_ip_im_list) ) + ip_im_list += _ip_im_list + + positive, negative = pipe.ip_adapter.get_image_embeds(ip_im_list) + + positive = positive.to(device=latents_device) + negative = negative.to(device=latents_device) + + bs_embed, seq_len, _ = positive.shape + positive = positive.repeat(1, 1, 1) + positive = positive.view(bs_embed * 1, seq_len, -1) + + bs_embed, seq_len, _ = negative.shape + negative = negative.repeat(1, 1, 1) + negative = negative.view(bs_embed * 1, seq_len, -1) + + if do_classifier_free_guidance: + negative = negative.chunk(negative.shape[0], 0) + positive = positive.chunk(positive.shape[0], 0) + else: + positive = positive.chunk(positive.shape[0], 0) + + im_prompt_embeds_region_list = [] + + if do_classifier_free_guidance: + im_prompt_embeds_region_list = [ + { + 0:negative[0] + } + ] * uncond_num + im_prompt_embeds_region_list + + pos_index = 0 + for ip_im_map, num in zip(ip_im_map_list, ip_im_nums): + im_prompt_embeds_map={} + pos = positive[pos_index:pos_index+num] + + for i, key_frame in enumerate(ip_im_map): + im_prompt_embeds_map[key_frame] = pos[i] + + im_prompt_embeds_region_list.append( im_prompt_embeds_map ) + pos_index += num + + + if do_classifier_free_guidance: + ip_im_map_list = [ + { + 0:None + } + ] * uncond_num + ip_im_map_list + + + self.ip_im_map_list = ip_im_map_list + self.im_prompt_embeds_region_list = im_prompt_embeds_region_list + + def is_uncond_layer(self, layer_index): + return self.uncond_num > layer_index + + + def _get_current_prompt_embeds_from_text( + self, + prompt_map, + prompt_embeds_map, + pooled_embeds_map, + center_frame = None, + video_length : int = 0 + ): + + key_prev = list(prompt_map.keys())[-1] + key_next = list(prompt_map.keys())[0] + + for p in prompt_map.keys(): + if p > center_frame: + key_next = p + break + key_prev = p + + dist_prev = center_frame - key_prev + if dist_prev < 0: + dist_prev += video_length + dist_next = key_next - center_frame + if dist_next < 0: + dist_next += video_length + + if key_prev == key_next or dist_prev + dist_next == 0: + return prompt_embeds_map[key_prev], pooled_embeds_map[key_prev] + + rate = dist_prev / (dist_prev + dist_next) + + return (get_tensor_interpolation_method()( prompt_embeds_map[key_prev], prompt_embeds_map[key_next], rate ), + get_tensor_interpolation_method()( pooled_embeds_map[key_prev], pooled_embeds_map[key_next], rate )) + + def get_current_prompt_embeds_from_text( + self, + center_frame = None, + video_length : int = 0 + ): + outputs = () + outputs2 = () + for prompt_map, prompt_embeds_map, pooled_embeds_map in zip(self.prompt_map_list, self.prompt_embeds_region_list, self.pooled_embeds_region_list): + embs,embs2 = self._get_current_prompt_embeds_from_text( + prompt_map, + prompt_embeds_map, + pooled_embeds_map, + center_frame, + video_length) + outputs += (embs,) + outputs2 += (embs2,) + + return outputs, outputs2 + + def get_current_prompt_embeds_single( + self, + context: List[int] = None, + video_length : int = 0 + ): + center_frame = context[len(context)//2] + text_emb, pooled_emb = self.get_current_prompt_embeds_from_text(center_frame, video_length) + text_emb = torch.cat(text_emb) + pooled_emb = torch.cat(pooled_emb) + if self.pipe.ip_adapter: + image_emb = self.get_current_prompt_embeds_from_image(center_frame, video_length) + image_emb = torch.cat(image_emb) + return torch.cat([text_emb,image_emb], dim=1), pooled_emb + else: + return text_emb, pooled_emb + + def get_current_prompt_embeds_multi( + self, + context: List[int] = None, + video_length : int = 0 + ): + + emb_list = [] + pooled_emb_list = [] + for c in context: + t,p = self.get_current_prompt_embeds_from_text(c, video_length) + for i, (emb, pooled) in enumerate(zip(t,p)): + if i >= len(emb_list): + emb_list.append([]) + pooled_emb_list.append([]) + emb_list[i].append(emb) + pooled_emb_list[i].append(pooled) + + text_emb = [] + for emb in emb_list: + emb = torch.cat(emb) + text_emb.append(emb) + text_emb = torch.cat(text_emb) + + pooled_emb = [] + for emb in pooled_emb_list: + emb = torch.cat(emb) + pooled_emb.append(emb) + pooled_emb = torch.cat(pooled_emb) + + if self.pipe.ip_adapter == None: + return text_emb, pooled_emb + + emb_list = [] + for c in context: + t = self.get_current_prompt_embeds_from_image(c, video_length) + for i, emb in enumerate(t): + if i >= len(emb_list): + emb_list.append([]) + emb_list[i].append(emb) + + image_emb = [] + for emb in emb_list: + emb = torch.cat(emb) + image_emb.append(emb) + image_emb = torch.cat(image_emb) + + return torch.cat([text_emb,image_emb], dim=1), pooled_emb + + ''' + def get_current_prompt_embeds( + self, + context: List[int] = None, + video_length : int = 0 + ): + return self.get_current_prompt_embeds_single(context,video_length) if self.is_single_prompt_mode else self.get_current_prompt_embeds_multi(context,video_length) + + def get_prompt_embeds_dtype(self): + return self.prompt_embeds_dtype + + def get_condi_size(self): + return len(self.prompt_embeds_region_list) + ''' + + + + + + + + +@dataclass +class AnimatePipelineOutput(BaseOutput): + """ + Output class for Stable Diffusion pipelines. + + Args: + images (`List[PIL.Image.Image]` or `np.ndarray`) + List of denoised PIL images of length `batch_size` or numpy array of shape `(batch_size, height, width, + num_channels)`. PIL images or numpy array present the denoised images of the diffusion pipeline. + """ + + videos: Union[torch.Tensor, np.ndarray] + + + +logger = logging.get_logger(__name__) # pylint: disable=invalid-name + +EXAMPLE_DOC_STRING = """ + Examples: + ```py + >>> import torch + >>> from diffusers import StableDiffusionXLPipeline + + >>> pipe = StableDiffusionXLPipeline.from_pretrained( + ... "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16 + ... ) + >>> pipe = pipe.to("cuda") + + >>> prompt = "a photo of an astronaut riding a horse on mars" + >>> image = pipe(prompt).images[0] + ``` +""" + + +# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg +def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0): + """ + Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and + Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4 + """ + std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True) + std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True) + # rescale the results from guidance (fixes overexposure) + noise_pred_rescaled = noise_cfg * (std_text / std_cfg) + # mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images + noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg + return noise_cfg + + +class AnimationPipeline(DiffusionPipeline, FromSingleFileMixin, StableDiffusionXLLoraLoaderMixin, TextualInversionLoaderMixin): + r""" + Pipeline for text-to-image generation using Stable Diffusion XL. + + This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the + library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.) + + In addition the pipeline inherits the following loading methods: + - *LoRA*: [`StableDiffusionXLPipeline.load_lora_weights`] + - *Ckpt*: [`loaders.FromSingleFileMixin.from_single_file`] + + as well as the following saving methods: + - *LoRA*: [`loaders.StableDiffusionXLPipeline.save_lora_weights`] + + Args: + vae ([`AutoencoderKL`]): + Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations. + text_encoder ([`CLIPTextModel`]): + Frozen text-encoder. Stable Diffusion XL uses the text portion of + [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically + the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant. + text_encoder_2 ([` CLIPTextModelWithProjection`]): + Second frozen text-encoder. Stable Diffusion XL uses the text and pool portion of + [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModelWithProjection), + specifically the + [laion/CLIP-ViT-bigG-14-laion2B-39B-b160k](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k) + variant. + tokenizer (`CLIPTokenizer`): + Tokenizer of class + [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer). + tokenizer_2 (`CLIPTokenizer`): + Second Tokenizer of class + [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer). + unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents. + scheduler ([`SchedulerMixin`]): + A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of + [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`]. + """ + model_cpu_offload_seq = "text_encoder->text_encoder_2->unet->vae" + + def __init__( + self, + vae: AutoencoderKL, + text_encoder: CLIPTextModel, + text_encoder_2: CLIPTextModelWithProjection, + tokenizer: CLIPTokenizer, + tokenizer_2: CLIPTokenizer, + unet: UNet2DConditionModel, + scheduler: KarrasDiffusionSchedulers, + force_zeros_for_empty_prompt: bool = True, + add_watermarker: Optional[bool] = None, + controlnet_map: Dict[ str , ControlNetModel ]=None, + ): + super().__init__() + + self.register_modules( + vae=vae, + text_encoder=text_encoder, + text_encoder_2=text_encoder_2, + tokenizer=tokenizer, + tokenizer_2=tokenizer_2, + unet=unet, + scheduler=scheduler, + ) + self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt) + self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1) + self.default_sample_size = self.unet.config.sample_size + + self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor) + self.control_image_processor = VaeImageProcessor( + vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False + ) + self.controlnet_map = controlnet_map + + + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing + def enable_vae_slicing(self): + r""" + Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to + compute decoding in several steps. This is useful to save some memory and allow larger batch sizes. + """ + self.vae.enable_slicing() + + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing + def disable_vae_slicing(self): + r""" + Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to + computing decoding in one step. + """ + self.vae.disable_slicing() + + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling + def enable_vae_tiling(self): + r""" + Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to + compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow + processing larger images. + """ + self.vae.enable_tiling() + + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling + def disable_vae_tiling(self): + r""" + Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to + computing decoding in one step. + """ + self.vae.disable_tiling() + + def __enable_model_cpu_offload(self, gpu_id=0): + r""" + Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared + to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward` + method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with + `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`. + """ + if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"): + from accelerate import cpu_offload_with_hook + else: + raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.") + + device = torch.device(f"cuda:{gpu_id}") + + if self.device.type != "cpu": + self.to("cpu", silence_dtype_warnings=True) + torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist) + + model_sequence = ( + [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2] + ) + model_sequence.extend([self.unet, self.vae]) + + hook = None + for cpu_offloaded_model in model_sequence: + _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook) + + # We'll offload the last model manually. + self.final_offload_hook = hook + + def encode_prompt( + self, + prompt: str, + prompt_2: Optional[str] = None, + device: Optional[torch.device] = None, + num_videos_per_prompt: int = 1, + do_classifier_free_guidance: bool = True, + negative_prompt: Optional[str] = None, + negative_prompt_2: Optional[str] = None, + prompt_embeds: Optional[torch.FloatTensor] = None, + negative_prompt_embeds: Optional[torch.FloatTensor] = None, + pooled_prompt_embeds: Optional[torch.FloatTensor] = None, + negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None, + lora_scale: Optional[float] = None, + ): + r""" + Encodes the prompt into text encoder hidden states. + + Args: + prompt (`str` or `List[str]`, *optional*): + prompt to be encoded + prompt_2 (`str` or `List[str]`, *optional*): + The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is + used in both text-encoders + device: (`torch.device`): + torch device + num_videos_per_prompt (`int`): + number of images that should be generated per prompt + do_classifier_free_guidance (`bool`): + whether to use classifier free guidance or not + negative_prompt (`str` or `List[str]`, *optional*): + The prompt or prompts not to guide the image generation. If not defined, one has to pass + `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is + less than `1`). + negative_prompt_2 (`str` or `List[str]`, *optional*): + The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and + `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders + prompt_embeds (`torch.FloatTensor`, *optional*): + Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not + provided, text embeddings will be generated from `prompt` input argument. + negative_prompt_embeds (`torch.FloatTensor`, *optional*): + Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt + weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input + argument. + pooled_prompt_embeds (`torch.FloatTensor`, *optional*): + Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. + If not provided, pooled text embeddings will be generated from `prompt` input argument. + negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*): + Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt + weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt` + input argument. + lora_scale (`float`, *optional*): + A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded. + """ + device = device or self._execution_device + + # set lora scale so that monkey patched LoRA + # function of text encoder can correctly access it + if lora_scale is not None and isinstance(self, LoraLoaderMixin): + self._lora_scale = lora_scale + + if prompt is not None and isinstance(prompt, str): + batch_size = 1 + elif prompt is not None and isinstance(prompt, list): + batch_size = len(prompt) + else: + batch_size = prompt_embeds.shape[0] + + # Define tokenizers and text encoders + tokenizers = [self.tokenizer, self.tokenizer_2] if self.tokenizer is not None else [self.tokenizer_2] + text_encoders = ( + [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2] + ) + + if prompt_embeds is None: + prompt_2 = prompt_2 or prompt + # textual inversion: procecss multi-vector tokens if necessary + prompt_embeds_list = [] + prompts = [prompt, prompt_2] + for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders): + if isinstance(self, TextualInversionLoaderMixin): + prompt = self.maybe_convert_prompt(prompt, tokenizer) + + text_inputs = tokenizer( + prompt, + padding="max_length", + max_length=tokenizer.model_max_length, + truncation=True, + return_tensors="pt", + ) + + text_input_ids = text_inputs.input_ids + untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids + + if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal( + text_input_ids, untruncated_ids + ): + removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1]) + logger.warning( + "The following part of your input was truncated because CLIP can only handle sequences up to" + f" {tokenizer.model_max_length} tokens: {removed_text}" + ) + + prompt_embeds = text_encoder( + text_input_ids.to(device), + output_hidden_states=True, + ) + + # We are only ALWAYS interested in the pooled output of the final text encoder + pooled_prompt_embeds = prompt_embeds[0] + prompt_embeds = prompt_embeds.hidden_states[-2] + + prompt_embeds_list.append(prompt_embeds) + + prompt_embeds = torch.concat(prompt_embeds_list, dim=-1) + + # get unconditional embeddings for classifier free guidance + zero_out_negative_prompt = negative_prompt is None and self.config.force_zeros_for_empty_prompt + if do_classifier_free_guidance and negative_prompt_embeds is None and zero_out_negative_prompt: + negative_prompt_embeds = torch.zeros_like(prompt_embeds) + negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds) + elif do_classifier_free_guidance and negative_prompt_embeds is None: + negative_prompt = negative_prompt or "" + negative_prompt_2 = negative_prompt_2 or negative_prompt + + uncond_tokens: List[str] + if prompt is not None and type(prompt) is not type(negative_prompt): + raise TypeError( + f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !=" + f" {type(prompt)}." + ) + elif isinstance(negative_prompt, str): + uncond_tokens = [negative_prompt, negative_prompt_2] + elif batch_size != len(negative_prompt): + raise ValueError( + f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:" + f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches" + " the batch size of `prompt`." + ) + else: + uncond_tokens = [negative_prompt, negative_prompt_2] + + negative_prompt_embeds_list = [] + for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders): + if isinstance(self, TextualInversionLoaderMixin): + negative_prompt = self.maybe_convert_prompt(negative_prompt, tokenizer) + + max_length = prompt_embeds.shape[1] + uncond_input = tokenizer( + negative_prompt, + padding="max_length", + max_length=max_length, + truncation=True, + return_tensors="pt", + ) + + negative_prompt_embeds = text_encoder( + uncond_input.input_ids.to(device), + output_hidden_states=True, + ) + # We are only ALWAYS interested in the pooled output of the final text encoder + negative_pooled_prompt_embeds = negative_prompt_embeds[0] + negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2] + + negative_prompt_embeds_list.append(negative_prompt_embeds) + + negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1) + + prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device) + + bs_embed, seq_len, _ = prompt_embeds.shape + # duplicate text embeddings for each generation per prompt, using mps friendly method + prompt_embeds = prompt_embeds.repeat(1, num_videos_per_prompt, 1) + prompt_embeds = prompt_embeds.view(bs_embed * num_videos_per_prompt, seq_len, -1) + + if do_classifier_free_guidance: + # duplicate unconditional embeddings for each generation per prompt, using mps friendly method + seq_len = negative_prompt_embeds.shape[1] + negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device) + negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_videos_per_prompt, 1) + negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_videos_per_prompt, seq_len, -1) + + pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_videos_per_prompt).view( + bs_embed * num_videos_per_prompt, -1 + ) + if do_classifier_free_guidance: + negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_videos_per_prompt).view( + bs_embed * num_videos_per_prompt, -1 + ) + + return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds + + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs + def prepare_extra_step_kwargs(self, generator, eta): + # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature + # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers. + # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502 + # and should be between [0, 1] + + accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys()) + extra_step_kwargs = {} + if accepts_eta: + extra_step_kwargs["eta"] = eta + + # check if the scheduler accepts generator + accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys()) + if accepts_generator: + extra_step_kwargs["generator"] = generator + return extra_step_kwargs + + + def prepare_image( + self, + image, + width, + height, + batch_size, + num_images_per_prompt, + device, + dtype, + do_classifier_free_guidance=False, + guess_mode=False, + do_normalize=False, + ): + if do_normalize == False: + image = self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32) + else: + image = self.image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32) + + image_batch_size = image.shape[0] + + if image_batch_size == 1: + repeat_by = batch_size + else: + # image batch size is the same as prompt batch size + repeat_by = num_images_per_prompt + + image = image.repeat_interleave(repeat_by, dim=0) + + image = image.to(device=device, dtype=dtype) + + #if do_classifier_free_guidance and not guess_mode: + # image = torch.cat([image] * 2) + + return image + + + def check_inputs( + self, + prompt, + prompt_2, + height, + width, + callback_steps, + negative_prompt=None, + negative_prompt_2=None, + prompt_embeds=None, + negative_prompt_embeds=None, + pooled_prompt_embeds=None, + negative_pooled_prompt_embeds=None, + ): + if height % 8 != 0 or width % 8 != 0: + raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.") + + ''' + if (callback_steps is None) or ( + callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0) + ): + raise ValueError( + f"`callback_steps` has to be a positive integer but is {callback_steps} of type" + f" {type(callback_steps)}." + ) + ''' + if callback_steps is not None: + if not isinstance(callback_steps, list): + raise ValueError("`callback_steps` has to be a list of positive integers.") + for callback_step in callback_steps: + if not isinstance(callback_step, int) or callback_step <= 0: + raise ValueError("`callback_steps` has to be a list of positive integers.") + + if prompt is not None and prompt_embeds is not None: + raise ValueError( + f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to" + " only forward one of the two." + ) + elif prompt_2 is not None and prompt_embeds is not None: + raise ValueError( + f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to" + " only forward one of the two." + ) + elif prompt is None and prompt_embeds is None: + raise ValueError( + "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined." + ) + elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)): + raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}") + elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)): + raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}") + + if negative_prompt is not None and negative_prompt_embeds is not None: + raise ValueError( + f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:" + f" {negative_prompt_embeds}. Please make sure to only forward one of the two." + ) + elif negative_prompt_2 is not None and negative_prompt_embeds is not None: + raise ValueError( + f"Cannot forward both `negative_prompt_2`: {negative_prompt_2} and `negative_prompt_embeds`:" + f" {negative_prompt_embeds}. Please make sure to only forward one of the two." + ) + + if prompt_embeds is not None and negative_prompt_embeds is not None: + if prompt_embeds.shape != negative_prompt_embeds.shape: + raise ValueError( + "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but" + f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`" + f" {negative_prompt_embeds.shape}." + ) + + if prompt_embeds is not None and pooled_prompt_embeds is None: + raise ValueError( + "If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`." + ) + + if negative_prompt_embeds is not None and negative_pooled_prompt_embeds is None: + raise ValueError( + "If `negative_prompt_embeds` are provided, `negative_pooled_prompt_embeds` also have to be passed. Make sure to generate `negative_pooled_prompt_embeds` from the same text encoder that was used to generate `negative_prompt_embeds`." + ) + + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents + def __prepare_latents(self, batch_size, single_model_length, num_channels_latents, height, width, dtype, device, generator, latents=None): + shape = (batch_size, num_channels_latents, single_model_length, height // self.vae_scale_factor, width // self.vae_scale_factor) + if isinstance(generator, list) and len(generator) != batch_size: + raise ValueError( + f"You have passed a list of generators of length {len(generator)}, but requested an effective batch" + f" size of {batch_size}. Make sure the batch size matches the length of the generators." + ) + + if latents is None: + latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype) + else: + latents = latents.to(device) + + # scale the initial noise by the standard deviation required by the scheduler + latents = latents * self.scheduler.init_noise_sigma + return latents + + def prepare_latents( + self, + batch_size, + num_channels_latents, + video_length, + height, + width, + dtype, + device, + generator, + img2img_map, + timestep, + latents=None, + is_strength_max=True, + return_noise=True, + return_image_latents=True, + ): + shape = ( + batch_size, + num_channels_latents, + video_length, + height // self.vae_scale_factor, + width // self.vae_scale_factor, + ) + if isinstance(generator, list) and len(generator) != batch_size: + raise ValueError( + f"You have passed a list of generators of length {len(generator)}, but requested an effective batch" + f" size of {batch_size}. Make sure the batch size matches the length of the generators." + ) + + # Offload text encoder if `enable_model_cpu_offload` was enabled + if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None: + self.text_encoder_2.to("cpu") + torch.cuda.empty_cache() + + + image_latents = None + + if img2img_map: + + image_latents = torch.zeros(shape, device=device, dtype=dtype) + for frame_no in img2img_map["images"]: + img = img2img_map["images"][frame_no] + img = self.image_processor.preprocess(img) + img = img.to(device="cuda", dtype=self.vae.dtype) + img = self.vae.encode(img).latent_dist.sample(generator) + img = self.vae.config.scaling_factor * img + img = torch.cat([img], dim=0) + image_latents[:,:,frame_no,:,:] = img.to(device=device, dtype=dtype) + + else: + is_strength_max = True + + + if latents is None: + noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype) + latents = noise if is_strength_max else self.scheduler.add_noise(image_latents, noise, timestep) + latents = latents * self.scheduler.init_noise_sigma if is_strength_max else latents + else: + noise = latents.to(device) + latents = noise * self.scheduler.init_noise_sigma + + + outputs = (latents.to(device, dtype),) + + if return_noise: + outputs += (noise.to(device, dtype),) + + if return_image_latents: + if image_latents is not None: + outputs += (image_latents.to(device, dtype),) + else: + outputs += (None,) + + return outputs + + + def __prepare_latents( + self, image, timestep, batch_size, num_images_per_prompt, dtype, device, generator=None, add_noise=True + ): + + image = image.to(device=device, dtype=dtype) + + batch_size = batch_size * num_images_per_prompt + + if image.shape[1] == 4: + init_latents = image + + else: + # make sure the VAE is in float32 mode, as it overflows in float16 + if self.vae.config.force_upcast: + image = image.float() + self.vae.to(dtype=torch.float32) + + if isinstance(generator, list) and len(generator) != batch_size: + raise ValueError( + f"You have passed a list of generators of length {len(generator)}, but requested an effective batch" + f" size of {batch_size}. Make sure the batch size matches the length of the generators." + ) + + elif isinstance(generator, list): + init_latents = [ + self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size) + ] + init_latents = torch.cat(init_latents, dim=0) + else: + init_latents = self.vae.encode(image).latent_dist.sample(generator) + + if self.vae.config.force_upcast: + self.vae.to(dtype) + + init_latents = init_latents.to(dtype) + init_latents = self.vae.config.scaling_factor * init_latents + + if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0: + # expand init_latents for batch_size + additional_image_per_prompt = batch_size // init_latents.shape[0] + init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0) + elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0: + raise ValueError( + f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts." + ) + else: + init_latents = torch.cat([init_latents], dim=0) + + if add_noise: + shape = init_latents.shape + noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype) + # get latents + init_latents = self.scheduler.add_noise(init_latents, noise, timestep) + + latents = init_latents + + return latents + + + + + + + def _get_add_time_ids(self, original_size, crops_coords_top_left, target_size, dtype): + add_time_ids = list(original_size + crops_coords_top_left + target_size) + + passed_add_embed_dim = ( + self.unet.config.addition_time_embed_dim * len(add_time_ids) + self.text_encoder_2.config.projection_dim + ) + expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features + + if expected_add_embed_dim != passed_add_embed_dim: + raise ValueError( + f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`." + ) + + add_time_ids = torch.tensor([add_time_ids], dtype=dtype) + return add_time_ids + + # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae + def upcast_vae(self): + dtype = self.vae.dtype + self.vae.to(dtype=torch.float32) + use_torch_2_0_or_xformers = isinstance( + self.vae.decoder.mid_block.attentions[0].processor, + ( + AttnProcessor2_0, + XFormersAttnProcessor, + LoRAXFormersAttnProcessor, + LoRAAttnProcessor2_0, + ), + ) + # if xformers or torch_2_0 is used attention block does not need + # to be in float32 which can save lots of memory + if use_torch_2_0_or_xformers: + self.vae.post_quant_conv.to(dtype) + self.vae.decoder.conv_in.to(dtype) + self.vae.decoder.mid_block.to(dtype) + + + def decode_latents(self, latents: torch.Tensor): + video_length = latents.shape[2] + latents = 1 / self.vae.config.scaling_factor * latents + latents = rearrange(latents, "b c f h w -> (b f) c h w") + # video = self.vae.decode(latents).sample + video = [] + for frame_idx in range(latents.shape[0]): + video.append( +# self.vae.decode(latents[frame_idx : frame_idx + 1].to(self.vae.device, self.vae.dtype)).sample.cpu() + self.vae.decode(latents[frame_idx : frame_idx + 1].to("cuda", self.vae.dtype)).sample.cpu() + ) + video = torch.cat(video) + video = rearrange(video, "(b f) c h w -> b c f h w", f=video_length) + video = (video / 2 + 0.5).clamp(0, 1) + # we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16 + video = video.float().numpy() + return video + + def get_img2img_timesteps(self, num_inference_steps, strength, device): + strength = min(1, max(0,strength)) + # get the original timestep using init_timestep + init_timestep = min(int(num_inference_steps * strength), num_inference_steps) + + t_start = max(num_inference_steps - init_timestep, 0) + timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :] + + return timesteps, num_inference_steps - t_start + + + @torch.no_grad() + @replace_example_docstring(EXAMPLE_DOC_STRING) + def __call__( + self, + prompt: Union[str, List[str]] = None, + prompt_2: Optional[Union[str, List[str]]] = None, + single_model_length: Optional[int] = 16, + height: Optional[int] = None, + width: Optional[int] = None, + num_inference_steps: int = 50, + denoising_end: Optional[float] = None, + guidance_scale: float = 5.0, + negative_prompt: Optional[Union[str, List[str]]] = None, + negative_prompt_2: Optional[Union[str, List[str]]] = None, + num_videos_per_prompt: Optional[int] = 1, + eta: float = 0.0, + generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None, + latents: Optional[torch.FloatTensor] = None, + prompt_embeds: Optional[torch.FloatTensor] = None, + negative_prompt_embeds: Optional[torch.FloatTensor] = None, + pooled_prompt_embeds: Optional[torch.FloatTensor] = None, + negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None, + output_type: Optional[str] = "tensor", + return_dict: bool = True, + callback: Optional[Callable[[int, torch.FloatTensor], None]] = None, + callback_steps: Optional[List[int]] = None, + cross_attention_kwargs: Optional[Dict[str, Any]] = None, + guidance_rescale: float = 0.0, + original_size: Optional[Tuple[int, int]] = None, + crops_coords_top_left: Tuple[int, int] = (0, 0), + target_size: Optional[Tuple[int, int]] = None, + + unet_batch_size: int = 1, + video_length: Optional[int] = None, + context_frames: int = -1, + context_stride: int = 3, + context_overlap: int = 4, + context_schedule: str = "uniform", + clip_skip: int = 1, + controlnet_type_map: Dict[str, Dict[str,float]] = None, + controlnet_image_map: Dict[int, Dict[str,Any]] = None, + controlnet_ref_map: Dict[str, Any] = None, + controlnet_max_samples_on_vram: int = 999, + controlnet_max_models_on_vram: int=99, + controlnet_is_loop: bool=True, + img2img_map: Dict[str, Any] = None, + ip_adapter_config_map: Dict[str,Any] = None, + region_list: List[Any] = None, + region_condi_list: List[Any] = None, + interpolation_factor = 1, + is_single_prompt_mode = False, + gradual_latent_map=None, + **kwargs, + ): + r""" + Function invoked when calling the pipeline for generation. + + Args: + prompt (`str` or `List[str]`, *optional*): + The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`. + instead. + prompt_2 (`str` or `List[str]`, *optional*): + The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is + used in both text-encoders + height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor): + The height in pixels of the generated image. + width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor): + The width in pixels of the generated image. + num_inference_steps (`int`, *optional*, defaults to 50): + The number of denoising steps. More denoising steps usually lead to a higher quality image at the + expense of slower inference. + denoising_end (`float`, *optional*): + When specified, determines the fraction (between 0.0 and 1.0) of the total denoising process to be + completed before it is intentionally prematurely terminated. As a result, the returned sample will + still retain a substantial amount of noise as determined by the discrete timesteps selected by the + scheduler. The denoising_end parameter should ideally be utilized when this pipeline forms a part of a + "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image + Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output) + guidance_scale (`float`, *optional*, defaults to 5.0): + Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598). + `guidance_scale` is defined as `w` of equation 2. of [Imagen + Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale > + 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`, + usually at the expense of lower image quality. + negative_prompt (`str` or `List[str]`, *optional*): + The prompt or prompts not to guide the image generation. If not defined, one has to pass + `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is + less than `1`). + negative_prompt_2 (`str` or `List[str]`, *optional*): + The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and + `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders + num_videos_per_prompt (`int`, *optional*, defaults to 1): + The number of images to generate per prompt. + eta (`float`, *optional*, defaults to 0.0): + Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to + [`schedulers.DDIMScheduler`], will be ignored for others. + generator (`torch.Generator` or `List[torch.Generator]`, *optional*): + One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html) + to make generation deterministic. + latents (`torch.FloatTensor`, *optional*): + Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image + generation. Can be used to tweak the same generation with different prompts. If not provided, a latents + tensor will ge generated by sampling using the supplied random `generator`. + prompt_embeds (`torch.FloatTensor`, *optional*): + Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not + provided, text embeddings will be generated from `prompt` input argument. + negative_prompt_embeds (`torch.FloatTensor`, *optional*): + Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt + weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input + argument. + pooled_prompt_embeds (`torch.FloatTensor`, *optional*): + Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. + If not provided, pooled text embeddings will be generated from `prompt` input argument. + negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*): + Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt + weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt` + input argument. + output_type (`str`, *optional*, defaults to `"pil"`): + The output format of the generate image. Choose between + [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`. + return_dict (`bool`, *optional*, defaults to `True`): + Whether or not to return a [`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] instead + of a plain tuple. + callback (`Callable`, *optional*): + A function that will be called every `callback_steps` steps during inference. The function will be + called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`. + callback_steps (`int`, *optional*, defaults to 1): + The frequency at which the `callback` function will be called. If not specified, the callback will be + called at every step. + cross_attention_kwargs (`dict`, *optional*): + A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under + `self.processor` in + [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py). + guidance_rescale (`float`, *optional*, defaults to 0.7): + Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are + Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of + [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). + Guidance rescale factor should fix overexposure when using zero terminal SNR. + original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)): + If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled. + `original_size` defaults to `(width, height)` if not specified. Part of SDXL's micro-conditioning as + explained in section 2.2 of + [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). + crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)): + `crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position + `crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting + `crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of + [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). + target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)): + For most cases, `target_size` should be set to the desired height and width of the generated image. If + not specified it will default to `(width, height)`. Part of SDXL's micro-conditioning as explained in + section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). + + Examples: + + Returns: + [`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] or `tuple`: + [`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] if `return_dict` is True, otherwise a + `tuple`. When returning a tuple, the first element is a list with the generated images. + """ + + gradual_latent = False + if gradual_latent_map: + gradual_latent = gradual_latent_map["enable"] + + controlnet_image_map_org = controlnet_image_map + + controlnet_max_models_on_vram = 0 + controlnet_max_samples_on_vram = 0 + + multi_uncond_mode = self.lora_map is not None + logger.info(f"{multi_uncond_mode=}") + + # 0. Default height and width to unet + height = height or self.default_sample_size * self.vae_scale_factor + width = width or self.default_sample_size * self.vae_scale_factor + + original_size = original_size or (height, width) + target_size = target_size or (height, width) + + # 1. Check inputs. Raise error if not correct + self.check_inputs( + "dummy_str", + prompt_2, + height, + width, + callback_steps, + negative_prompt, + negative_prompt_2, + prompt_embeds, + negative_prompt_embeds, + pooled_prompt_embeds, + negative_pooled_prompt_embeds, + ) + + # 2. Define call parameters + if False: + if prompt is not None and isinstance(prompt, str): + batch_size = 1 + elif prompt is not None and isinstance(prompt, list): + batch_size = len(prompt) + else: + batch_size = prompt_embeds.shape[0] + + batch_size = 1 + + sequential_mode = video_length is not None and video_length > context_frames + + device = self._execution_device + latents_device = torch.device("cpu") if sequential_mode else device + + if ip_adapter_config_map: + img_enc_path = "data/models/ip_adapter/models/image_encoder/" + if ip_adapter_config_map["is_plus"]: + self.ip_adapter = IPAdapterPlusXL(self, img_enc_path, "data/models/ip_adapter/sdxl_models/ip-adapter-plus_sdxl_vit-h.bin", device, 16) + elif ip_adapter_config_map["is_plus_face"]: + self.ip_adapter = IPAdapterPlusXL(self, img_enc_path, "data/models/ip_adapter/sdxl_models/ip-adapter-plus-face_sdxl_vit-h.bin", device, 16) + else: + self.ip_adapter = IPAdapterXL(self, img_enc_path, "data/models/ip_adapter/sdxl_models/ip-adapter_sdxl_vit-h.bin", device, 4) + self.ip_adapter.set_scale( ip_adapter_config_map["scale"] ) + else: + self.ip_adapter = None + + + # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2) + # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1` + # corresponds to doing no classifier free guidance. + do_classifier_free_guidance = guidance_scale > 1.0 + + # 3. Encode input prompt + text_encoder_lora_scale = ( + cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None + ) + + prompt_encoder = PromptEncoderSDXL( + self, + device, + device,#latents_device, + num_videos_per_prompt, + do_classifier_free_guidance, + region_condi_list, + negative_prompt, + is_single_prompt_mode, + clip_skip, + multi_uncond_mode=multi_uncond_mode + ) + + if self.ip_adapter: + self.ip_adapter.delete_encoder() + + + condi_size = prompt_encoder.get_condi_size() + + + # 3.5 Prepare controlnet variables + + if self.controlnet_map: + for i, type_str in enumerate(self.controlnet_map): + if i < controlnet_max_models_on_vram: + self.controlnet_map[type_str].to(device=device, non_blocking=True) + + + # controlnet_image_map + # { 0 : { "type_str" : IMAGE, "type_str2" : IMAGE } } + # { "type_str" : { 0 : IMAGE, 15 : IMAGE } } + controlnet_image_map= None + + if controlnet_image_map_org: + controlnet_image_map= {key: {} for key in controlnet_type_map} + for key_frame_no in controlnet_image_map_org: + for t, img in controlnet_image_map_org[key_frame_no].items(): + if isinstance( self.controlnet_map[t], ControlNetLLLite ): + img_size = 1 + do_normalize=True + else: + img_size = prompt_encoder.get_condi_size() + do_normalize=False + c_dtype = torch.float16 #self.controlnet_map[t].dtype + tmp = self.prepare_image( + image=img, + width=width, + height=height, + batch_size=1 * 1, + num_images_per_prompt=1, + #device=device, + device=latents_device, + dtype=c_dtype, + do_classifier_free_guidance=False, + guess_mode=False, + do_normalize=do_normalize, + ) + controlnet_image_map[t][key_frame_no] = torch.cat([tmp] * img_size) + + del controlnet_image_map_org + torch.cuda.empty_cache() + + # { "0_type_str" : { "scales" = [0.1, 0.3, 0.5, 1.0, 0.5, 0.3, 0.1], "frames"=[125, 126, 127, 0, 1, 2, 3] }} + controlnet_scale_map = {} + controlnet_affected_list = np.zeros(video_length,dtype = int) + + is_v2v = True + + if controlnet_image_map: + for type_str in controlnet_image_map: + for key_frame_no in controlnet_image_map[type_str]: + scale_list = controlnet_type_map[type_str]["control_scale_list"] + if len(scale_list) > 0: + is_v2v = False + scale_list = scale_list[0: context_frames] + scale_len = len(scale_list) + + if controlnet_is_loop: + frames = [ i%video_length for i in range(key_frame_no-scale_len, key_frame_no+scale_len+1)] + + controlnet_scale_map[str(key_frame_no) + "_" + type_str] = { + "scales" : scale_list[::-1] + [1.0] + scale_list, + "frames" : frames, + } + else: + frames = [ i for i in range(max(0, key_frame_no-scale_len), min(key_frame_no+scale_len+1, video_length))] + + controlnet_scale_map[str(key_frame_no) + "_" + type_str] = { + "scales" : scale_list[:key_frame_no][::-1] + [1.0] + scale_list[:video_length-key_frame_no-1], + "frames" : frames, + } + + controlnet_affected_list[frames] = 1 + + def controlnet_is_affected( frame_index:int): + return controlnet_affected_list[frame_index] + + def get_controlnet_scale( + type: str, + cur_step: int, + step_length: int, + ): + s = controlnet_type_map[type]["control_guidance_start"] + e = controlnet_type_map[type]["control_guidance_end"] + keep = 1.0 - float(cur_step / len(timesteps) < s or (cur_step + 1) / step_length > e) + + scale = controlnet_type_map[type]["controlnet_conditioning_scale"] + + return keep * scale + + def get_controlnet_variable( + type_str: str, + cur_step: int, + step_length: int, + target_frames: List[int], + ): + cont_vars = [] + + if not controlnet_image_map: + return None + + if type_str not in controlnet_image_map: + return None + + for fr, img in controlnet_image_map[type_str].items(): + + if fr in target_frames: + cont_vars.append( { + "frame_no" : fr, + "image" : img, + "cond_scale" : get_controlnet_scale(type_str, cur_step, step_length), + "guess_mode" : controlnet_type_map[type_str]["guess_mode"] + } ) + + return cont_vars + + + + # 4. Prepare timesteps + self.scheduler.set_timesteps(num_inference_steps, device=latents_device) + if img2img_map: + timesteps, num_inference_steps = self.get_img2img_timesteps(num_inference_steps, img2img_map["denoising_strength"], latents_device) + latent_timestep = timesteps[:1].repeat(batch_size * 1) + else: + timesteps = self.scheduler.timesteps + latent_timestep = None + + is_strength_max = True + if img2img_map: + is_strength_max = img2img_map["denoising_strength"] == 1.0 + + + # 5. Prepare latent variables + num_channels_latents = self.unet.config.in_channels + latents_outputs = self.prepare_latents( + batch_size = 1, + num_channels_latents=num_channels_latents, + video_length=video_length, + height=height, + width=width, + dtype=prompt_encoder.get_prompt_embeds_dtype(), + device=latents_device, + generator=generator, + img2img_map=img2img_map, + timestep=latent_timestep, + latents=latents, + is_strength_max=is_strength_max, + return_noise=True, + return_image_latents=True, + ) + + latents, noise, image_latents = latents_outputs + + del img2img_map + torch.cuda.empty_cache() + + # 5.5 Prepare region mask + region_mask = RegionMask( + region_list, + batch_size, + num_channels_latents, + video_length, + height, + width, + self.vae_scale_factor, + prompt_encoder.get_prompt_embeds_dtype(), + latents_device, + multi_uncond_mode + ) + + torch.cuda.empty_cache() + + + # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline + extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta) + + # 6.5 - Infinite context loop shenanigans + context_scheduler = get_context_scheduler(context_schedule) + total_steps = get_total_steps( + context_scheduler, + timesteps, + num_inference_steps, + latents.shape[2], + context_frames, + context_stride, + context_overlap, + ) + + # 7. Prepare added time ids & embeddings +# add_text_embeds = pooled_prompt_embeds + add_time_ids = self._get_add_time_ids( + original_size, crops_coords_top_left, target_size, dtype=prompt_encoder.get_prompt_embeds_dtype(), + ) + + add_time_ids = torch.cat([add_time_ids for c in range(condi_size)], dim=0) + add_time_ids = add_time_ids.to(device) + + # 8. Denoising loop + num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0) + + if False: + # 7.1 Apply denoising_end + if denoising_end is not None and type(denoising_end) == float and denoising_end > 0 and denoising_end < 1: + discrete_timestep_cutoff = int( + round( + self.scheduler.config.num_train_timesteps + - (denoising_end * self.scheduler.config.num_train_timesteps) + ) + ) + num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps))) + timesteps = timesteps[:num_inference_steps] + + + logger.info(f"{do_classifier_free_guidance=}") + logger.info(f"{condi_size=}") + + if self.lora_map: + self.lora_map.to(device, self.unet.dtype) + if self.lcm: + self.lcm.to(device, self.unet.dtype) + + lat_height, lat_width = latents.shape[-2:] + + def gradual_latent_scale(progress): + if gradual_latent: + cur = 0.5 + for s in gradual_latent_map["scale"]: + v = gradual_latent_map["scale"][s] + if float(s) > progress: + return cur + cur = v + return cur + else: + return 1.0 + def gradual_latent_size(progress): + if gradual_latent: + current_ratio = gradual_latent_scale(progress) + h = int(lat_height * current_ratio) // 8 * 8 + w = int(lat_width * current_ratio) // 8 * 8 + return (h,w) + else: + return (lat_height, lat_width) + + def unsharp_mask(img): + imgf = img.float() + k = 0.05 # strength + kernel = torch.FloatTensor([[0, -k, 0], + [-k, 1+4*k, -k], + [0, -k, 0]]) + + conv_kernel = torch.eye(4)[..., None, None] * kernel[None, None, ...] + imgf = torch.nn.functional.conv2d(imgf, conv_kernel.to(img.device), padding=1) + return imgf.to(img.dtype) + + def resize_tensor(ten, size, do_unsharp_mask=False): + ten = rearrange(ten, "b c f h w -> (b f) c h w") + ten = torch.nn.functional.interpolate( + ten.float(), size=size, mode="bicubic", align_corners=False + ).to(ten.dtype) + if do_unsharp_mask: + ten = unsharp_mask(ten) + return rearrange(ten, "(b f) c h w -> b c f h w", f=video_length) + + if gradual_latent: + latents = resize_tensor(latents, gradual_latent_size(0)) + reverse_steps = gradual_latent_map["reverse_steps"] + noise_add_count = gradual_latent_map["noise_add_count"] + total_steps = ((total_steps/num_inference_steps) * (reverse_steps* (len(gradual_latent_map["scale"].keys()) - 1) )) + total_steps + total_steps = int(total_steps) + + prev_gradient_latent_size = gradual_latent_size(0) + + + + with self.progress_bar(total=total_steps) as progress_bar: + + i = 0 + real_i = 0 +# for i, t in enumerate(timesteps): + while i < len(timesteps): + t = timesteps[i] + + cur_gradient_latent_size = gradual_latent_size((real_i+1) / len(timesteps)) + + if self.lcm: + self.lcm.apply(i, len(timesteps)) + + noise_pred = torch.zeros( + (latents.shape[0] * condi_size, *latents.shape[1:]), + device=latents.device, + dtype=latents.dtype, + ) + counter = torch.zeros( + (1, 1, latents.shape[2], 1, 1), device=latents.device, dtype=latents.dtype + ) + + # { "0_type_str" : (down_samples, mid_sample) } + controlnet_result={} + + def apply_lllite(context: List[int]): + for type_str in controlnet_type_map: + if not isinstance( self.controlnet_map[type_str] , ControlNetLLLite): + continue + + cont_vars = get_controlnet_variable(type_str, i, len(timesteps), context) + if not cont_vars: + self.controlnet_map[type_str].set_multiplier(0.0) + continue + + def get_index(l, x): + return l.index(x) if x in l else -1 + + zero_img = torch.zeros_like(cont_vars[0]["image"]) + + scales=[0.0 for fr in context] + imgs=[zero_img for fr in context] + + for cont_var in cont_vars: + c_fr = cont_var["frame_no"] + scale_index = str(c_fr) + "_" + type_str + + for s_i, fr in enumerate(controlnet_scale_map[scale_index]["frames"]): + index = get_index(context, fr) + if index != -1: + scales[index] = controlnet_scale_map[scale_index]["scales"][s_i] + imgs[index] = cont_var["image"] + + scales = [ s * cont_var["cond_scale"] for s in scales ] + + + imgs = torch.cat(imgs).to(device=device, non_blocking=True) + + key= ".".join(map(str, context)) + key= type_str + "." + key + + self.controlnet_map[type_str].to(device=device) + self.controlnet_map[type_str].set_cond_image(imgs,key) + self.controlnet_map[type_str].set_multiplier(scales) + + def get_controlnet_result(context: List[int] = None): + #logger.info(f"get_controlnet_result called {context=}") + + if controlnet_image_map is None: + return None, None + + hit = False + for n in context: + if controlnet_is_affected(n): + hit=True + break + if hit == False: + return None, None + + apply_lllite(context) + + if len(controlnet_result) == 0: + return None, None + + _down_block_res_samples=[] + + first_down = list(list(controlnet_result.values())[0].values())[0][0] + first_mid = list(list(controlnet_result.values())[0].values())[0][1] + for ii in range(len(first_down)): + _down_block_res_samples.append( + torch.zeros( + (first_down[ii].shape[0], first_down[ii].shape[1], len(context) ,*first_down[ii].shape[3:]), + device=device, + dtype=first_down[ii].dtype, + )) + _mid_block_res_samples = torch.zeros( + (first_mid.shape[0], first_mid.shape[1], len(context) ,*first_mid.shape[3:]), + device=device, + dtype=first_mid.dtype, + ) + + for fr in controlnet_result: + for type_str in controlnet_result[fr]: + result = str(fr) + "_" + type_str + + val = controlnet_result[fr][type_str] + cur_down = [ + v.to(device = device, dtype=first_down[0].dtype, non_blocking=True) if v.device != device else v + for v in val[0] + ] + cur_mid =val[1].to(device = device, dtype=first_mid.dtype, non_blocking=True) if val[1].device != device else val[1] + loc = list(set(context) & set(controlnet_scale_map[result]["frames"])) + scales = [] + + for o in loc: + for j, f in enumerate(controlnet_scale_map[result]["frames"]): + if o == f: + scales.append(controlnet_scale_map[result]["scales"][j]) + break + loc_index=[] + + for o in loc: + for j, f in enumerate( context ): + if o==f: + loc_index.append(j) + break + + mod = torch.tensor(scales).to(device, dtype=cur_mid.dtype) + + add = cur_mid * mod[None,None,:,None,None] + _mid_block_res_samples[:, :, loc_index, :, :] = _mid_block_res_samples[:, :, loc_index, :, :] + add + + for ii in range(len(cur_down)): + add = cur_down[ii] * mod[None,None,:,None,None] + _down_block_res_samples[ii][:, :, loc_index, :, :] = _down_block_res_samples[ii][:, :, loc_index, :, :] + add + + return _down_block_res_samples, _mid_block_res_samples + + def process_controlnet( target_frames: List[int] = None ): + #logger.info(f"process_controlnet called {target_frames=}") + nonlocal controlnet_result + + controlnet_samples_on_vram = 0 + + loc = list(set(target_frames) & set(controlnet_result.keys())) + + controlnet_result = {key: controlnet_result[key] for key in loc} + + target_frames = list(set(target_frames) - set(loc)) + #logger.info(f"-> {target_frames=}") + if len(target_frames) == 0: + return + + def sample_to_device( sample ): + nonlocal controlnet_samples_on_vram + + if controlnet_max_samples_on_vram <= controlnet_samples_on_vram: + down_samples = [ + v.to(device = torch.device("cpu"), non_blocking=True) if v.device != torch.device("cpu") else v + for v in sample[0] ] + mid_sample = sample[1].to(device = torch.device("cpu"), non_blocking=True) if sample[1].device != torch.device("cpu") else sample[1] + else: + if sample[0][0].device != device: + down_samples = [ v.to(device = device, non_blocking=True) for v in sample[0] ] + mid_sample = sample[1].to(device = device, non_blocking=True) + else: + down_samples = sample[0] + mid_sample = sample[1] + controlnet_samples_on_vram += 1 + return down_samples, mid_sample + + + for fr in controlnet_result: + for type_str in controlnet_result[fr]: + controlnet_result[fr][type_str] = sample_to_device(controlnet_result[fr][type_str]) + + for type_str in controlnet_type_map: + + if isinstance( self.controlnet_map[type_str] , ControlNetLLLite): + continue + + cont_vars = get_controlnet_variable(type_str, i, len(timesteps), target_frames) + if not cont_vars: + continue + + org_device = self.controlnet_map[type_str].device + if org_device != device: + self.controlnet_map[type_str] = self.controlnet_map[type_str].to(device=device, non_blocking=True) + + for cont_var in cont_vars: + frame_no = cont_var["frame_no"] + + latent_model_input = ( + latents[:, :, [frame_no]] + .to(device) + .repeat( prompt_encoder.get_condi_size(), 1, 1, 1, 1) + ) + control_model_input = self.scheduler.scale_model_input(latent_model_input, t)[:, :, 0] + controlnet_prompt_embeds, controlnet_add_text_embeds = prompt_encoder.get_current_prompt_embeds([frame_no], latents.shape[2]) + + controlnet_added_cond_kwargs = {"text_embeds": controlnet_add_text_embeds.to(device=device), "time_ids": add_time_ids} + + cont_var_img = cont_var["image"].to(device=device) + + if gradual_latent: + cur_lat_height, cur_lat_width = latents.shape[-2:] + cont_var_img = torch.nn.functional.interpolate( + cont_var_img.float(), size=(cur_lat_height*8, cur_lat_width*8), mode="bicubic", align_corners=False + ).to(cont_var_img.dtype) + + + down_samples, mid_sample = self.controlnet_map[type_str]( + control_model_input, + t, + encoder_hidden_states=controlnet_prompt_embeds.to(device=device), + controlnet_cond=cont_var_img, + conditioning_scale=cont_var["cond_scale"], + guess_mode=cont_var["guess_mode"], + added_cond_kwargs=controlnet_added_cond_kwargs, + return_dict=False, + ) + + for ii in range(len(down_samples)): + down_samples[ii] = rearrange(down_samples[ii], "(b f) c h w -> b c f h w", f=1) + mid_sample = rearrange(mid_sample, "(b f) c h w -> b c f h w", f=1) + + if frame_no not in controlnet_result: + controlnet_result[frame_no] = {} + + controlnet_result[frame_no][type_str] = sample_to_device((down_samples, mid_sample)) + + if org_device != device: + self.controlnet_map[type_str] = self.controlnet_map[type_str].to(device=org_device, non_blocking=True) + + + + for context in context_scheduler( + i, num_inference_steps, latents.shape[2], context_frames, context_stride, context_overlap + ): + + if self.lora_map: + self.lora_map.unapply() + + + if controlnet_image_map: + if is_v2v: + controlnet_target = context + else: + controlnet_target = list(range(context[0]-context_frames, context[0])) + context + list(range(context[-1]+1, context[-1]+1+context_frames)) + controlnet_target = [f%video_length for f in controlnet_target] + controlnet_target = list(set(controlnet_target)) + + process_controlnet(controlnet_target) + + # expand the latents if we are doing classifier free guidance + latent_model_input = ( + latents[:, :, context] + .to(device) + .repeat(condi_size, 1, 1, 1, 1) + ) + latent_model_input = self.scheduler.scale_model_input(latent_model_input, t) + + cur_prompt, add_text_embeds = prompt_encoder.get_current_prompt_embeds(context, latents.shape[2]) + down_block_res_samples,mid_block_res_sample = get_controlnet_result(context) + + cur_prompt = cur_prompt.to(device=device) + add_text_embeds = add_text_embeds.to(device=device) + + # predict the noise residual + #added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids} + ts = torch.tensor([t], dtype=latent_model_input.dtype, device=latent_model_input.device) + if condi_size > 1: + ts = ts.repeat(condi_size) + + + __pred = [] + + for layer_index in range(0, latent_model_input.shape[0], unet_batch_size): + + if self.lora_map: + self.lora_map.apply(layer_index, latent_model_input.shape[0], context[len(context)//2]) + + layer_width = 1 if is_single_prompt_mode else context_frames + + __lat = latent_model_input[layer_index:layer_index+unet_batch_size] + __cur_prompt = cur_prompt[layer_index * layer_width:(layer_index + unet_batch_size)*layer_width] + __added_cond_kwargs = {"text_embeds": add_text_embeds[layer_index * layer_width:(layer_index + unet_batch_size)*layer_width], "time_ids": add_time_ids[layer_index:layer_index+unet_batch_size]} + + __do = [] + if down_block_res_samples is not None: + for do in down_block_res_samples: + __do.append(do[layer_index:layer_index+unet_batch_size]) + else: + __do = None + + __mid = None + if mid_block_res_sample is not None: + __mid = mid_block_res_sample[layer_index:layer_index+unet_batch_size] + + pred_layer = self.unet( + __lat, + ts[layer_index:layer_index+unet_batch_size], + encoder_hidden_states=__cur_prompt, + cross_attention_kwargs=cross_attention_kwargs, + added_cond_kwargs=__added_cond_kwargs, + down_block_additional_residuals=__do, + mid_block_additional_residual=__mid, + return_dict=False, + )[0] + + wh = None + + if i < len(timesteps) * region_mask.get_crop_generation_rate(layer_index, latent_model_input.shape[0]): + #TODO lllite + wh, xy_list = region_mask.get_area(layer_index, latent_model_input.shape[0], context) + if wh: + a_w, a_h = wh + __lat_list = [] + for c_index, xy in enumerate( xy_list ): + a_x, a_y = xy + __lat_list.append( __lat[:,:,[c_index],a_y:a_y+a_h, a_x:a_x+a_w ] ) + + __lat = torch.cat(__lat_list, dim=2) + + if __do is not None: + __tmp_do = [] + for _d, rate in zip(__do, (1,1,1,2,2,2,4,4,4,8,8,8)): + _inner_do_list = [] + for c_index, xy in enumerate( xy_list ): + a_x, a_y = xy + _inner_do_list.append(_d[:,:,[c_index],a_y//rate:(a_y+a_h)//rate, a_x//rate:(a_x+a_w)//rate ] ) + + __tmp_do.append( torch.cat(_inner_do_list, dim=2) ) + __do = __tmp_do + + if __mid is not None: + rate = 8 + _mid_list = [] + for c_index, xy in enumerate( xy_list ): + a_x, a_y = xy + _mid_list.append( __mid[:,:,[c_index],a_y//rate:(a_y+a_h)//rate, a_x//rate:(a_x+a_w)//rate ] ) + __mid = torch.cat(_mid_list, dim=2) + + crop_pred_layer = self.unet( + __lat, + ts[layer_index:layer_index+unet_batch_size], + encoder_hidden_states=__cur_prompt, + cross_attention_kwargs=cross_attention_kwargs, + added_cond_kwargs=__added_cond_kwargs, + down_block_additional_residuals=__do, + mid_block_additional_residual=__mid, + return_dict=False, + )[0] + + if wh: + a_w, a_h = wh + for c_index, xy in enumerate( xy_list ): + a_x, a_y = xy + pred_layer[:,:,[c_index],a_y:a_y+a_h, a_x:a_x+a_w] = crop_pred_layer[:,:,[c_index],:,:] + + + __pred.append( pred_layer ) + + down_block_res_samples = None + mid_block_res_sample = None + + pred = torch.cat(__pred) + + pred = pred.to(dtype=latents.dtype, device=latents.device) + noise_pred[:, :, context] = noise_pred[:, :, context] + pred + counter[:, :, context] = counter[:, :, context] + 1 + progress_bar.update() + + + # perform guidance + noise_size = condi_size + if do_classifier_free_guidance: + noise_pred = (noise_pred / counter) + noise_list = list(noise_pred.chunk( noise_size )) + + if multi_uncond_mode: + uc_noise_list = noise_list[:len(noise_list)//2] + noise_list = noise_list[len(noise_list)//2:] + for n in range(len(noise_list)): + noise_list[n] = uc_noise_list[n] + guidance_scale * (noise_list[n] - uc_noise_list[n]) + else: + noise_pred_uncond = noise_list.pop(0) + for n in range(len(noise_list)): + noise_list[n] = noise_pred_uncond + guidance_scale * (noise_list[n] - noise_pred_uncond) + + noise_size = len(noise_list) + noise_pred = torch.cat(noise_list) + + + if gradual_latent: + if prev_gradient_latent_size != cur_gradient_latent_size: + noise_pred = resize_tensor(noise_pred, cur_gradient_latent_size, True) + latents = resize_tensor(latents, cur_gradient_latent_size, True) + + # compute the previous noisy sample x_t -> x_t-1 + latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0] + + # call the callback, if provided + if (i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0)) and ( + callback is not None and (callback_steps is not None and i in callback_steps) + ): + denoised = latents - noise_pred + #denoised = self.interpolate_latents(denoised, interpolation_factor, device) + video = torch.from_numpy(self.decode_latents(denoised)) + callback(i, video) + + latents_list = latents.chunk( noise_size ) + + tmp_latent = torch.zeros( + latents_list[0].shape, device=latents.device, dtype=latents.dtype + ) + + for r_no in range(len(region_list)): + mask = region_mask.get_mask( r_no ) + if gradual_latent: + mask = resize_tensor(mask, cur_gradient_latent_size) + src = region_list[r_no]["src"] + if src == -1: + init_latents_proper = image_latents[:1] + + if i < len(timesteps) - 1: + noise_timestep = timesteps[i + 1] + init_latents_proper = self.scheduler.add_noise( + init_latents_proper, noise, torch.tensor([noise_timestep]) + ) + + if gradual_latent: + lat = resize_tensor(init_latents_proper, cur_gradient_latent_size) + else: + lat = init_latents_proper + else: + lat = latents_list[src] + + tmp_latent = tmp_latent * (1-mask) + lat * mask + + latents = tmp_latent + + init_latents_proper = None + lat = None + latents_list = None + tmp_latent = None + + i+=1 + real_i = max(i, real_i) + if gradual_latent: + if prev_gradient_latent_size != cur_gradient_latent_size: + reverse = min(i, reverse_steps) + self.scheduler._step_index -= reverse + _noise = resize_tensor(noise, cur_gradient_latent_size) + for count in range(i, i+noise_add_count): + count = min(count,len(timesteps)-1) + latents = self.scheduler.add_noise( + latents, _noise, torch.tensor([timesteps[count]]) + ) + i -= reverse + torch.cuda.empty_cache() + + prev_gradient_latent_size = cur_gradient_latent_size + + + controlnet_result = None + torch.cuda.empty_cache() + + # make sure the VAE is in float32 mode, as it overflows in float16 + if self.vae.dtype == torch.float32 and latents.dtype == torch.float16: + self.upcast_vae() + latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype) + + if self.ip_adapter: + show_gpu("before unload ip_adapter") + self.ip_adapter.unload() + self.ip_adapter = None + torch.cuda.empty_cache() + show_gpu("after unload ip_adapter") + + self.maybe_free_model_hooks() + torch.cuda.empty_cache() + + if False: + if not output_type == "latent": + latents = rearrange(latents, "b c f h w -> (b f) c h w") + image = self.vae.decode((latents / self.vae.config.scaling_factor).to(self.vae.device, self.vae.dtype), return_dict=False)[0] + else: + raise ValueError(f"{output_type=} not supported") + image = latents + return StableDiffusionXLPipelineOutput(images=image) + + #image = self.image_processor.postprocess(image, output_type=output_type) + + # Offload last model to CPU + if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None: + self.final_offload_hook.offload() + image = ((image + 1) / 2).clamp(0, 1) + video = rearrange(image, "(b f) c h w -> b c f h w", f=single_model_length).cpu() + if not return_dict: + return (video,) + else: + # Return latents if requested (this will never be a dict) + if not output_type == "latent": + video = self.decode_latents(latents) + else: + video = latents + + # Convert to tensor + if output_type == "tensor": + video = torch.from_numpy(video) + + # Offload all models + self.maybe_free_model_hooks() + + if not return_dict: + return video + + + return AnimatePipelineOutput(videos=video) + + + # Overrride to properly handle the loading and unloading of the additional text encoder. + def load_lora_weights(self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], **kwargs): + # We could have accessed the unet config from `lora_state_dict()` too. We pass + # it here explicitly to be able to tell that it's coming from an SDXL + # pipeline. + + state_dict, network_alphas = self.lora_state_dict( + pretrained_model_name_or_path_or_dict, + unet_config=self.unet.config, + **kwargs, + ) + self.load_lora_into_unet(state_dict, network_alphas=network_alphas, unet=self.unet) + + text_encoder_state_dict = {k: v for k, v in state_dict.items() if "text_encoder." in k} + if len(text_encoder_state_dict) > 0: + self.load_lora_into_text_encoder( + text_encoder_state_dict, + network_alphas=network_alphas, + text_encoder=self.text_encoder, + prefix="text_encoder", + lora_scale=self.lora_scale, + ) + + text_encoder_2_state_dict = {k: v for k, v in state_dict.items() if "text_encoder_2." in k} + if len(text_encoder_2_state_dict) > 0: + self.load_lora_into_text_encoder( + text_encoder_2_state_dict, + network_alphas=network_alphas, + text_encoder=self.text_encoder_2, + prefix="text_encoder_2", + lora_scale=self.lora_scale, + ) + + @classmethod + def save_lora_weights( + self, + save_directory: Union[str, os.PathLike], + unet_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None, + text_encoder_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None, + text_encoder_2_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None, + is_main_process: bool = True, + weight_name: str = None, + save_function: Callable = None, + safe_serialization: bool = True, + ): + state_dict = {} + + def pack_weights(layers, prefix): + layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers + layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()} + return layers_state_dict + + state_dict.update(pack_weights(unet_lora_layers, "unet")) + + if text_encoder_lora_layers and text_encoder_2_lora_layers: + state_dict.update(pack_weights(text_encoder_lora_layers, "text_encoder")) + state_dict.update(pack_weights(text_encoder_2_lora_layers, "text_encoder_2")) + + self.write_lora_layers( + state_dict=state_dict, + save_directory=save_directory, + is_main_process=is_main_process, + weight_name=weight_name, + save_function=save_function, + safe_serialization=safe_serialization, + ) + + def _remove_text_encoder_monkey_patch(self): + self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder) + self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder_2) \ No newline at end of file diff --git a/animate/src/animatediff/pipelines/ti.py b/animate/src/animatediff/pipelines/ti.py new file mode 100644 index 0000000000000000000000000000000000000000..6157f9e06e95a7ae4b67133eae711433bb782259 --- /dev/null +++ b/animate/src/animatediff/pipelines/ti.py @@ -0,0 +1,155 @@ +import logging +from pathlib import Path +from typing import Optional, Union + +import torch +from diffusers import DiffusionPipeline +from safetensors.torch import load_file +from torch import Tensor + +from animatediff import get_dir + +EMBED_DIR = get_dir("data").joinpath("embeddings") +EMBED_DIR_SDXL = get_dir("data").joinpath("sdxl_embeddings") +EMBED_EXTS = [".pt", ".pth", ".bin", ".safetensors"] + +logger = logging.getLogger(__name__) + + +def scan_text_embeddings(is_sdxl=False) -> list[Path]: + embed_dir=EMBED_DIR_SDXL if is_sdxl else EMBED_DIR + return [x for x in embed_dir.rglob("**/*") if x.is_file() and x.suffix.lower() in EMBED_EXTS] + + +def get_text_embeddings(return_tensors: bool = True, is_sdxl:bool = False) -> dict[str, Union[Tensor, Path]]: + embed_dir=EMBED_DIR_SDXL if is_sdxl else EMBED_DIR + embeds = {} + skipped = {} + path: Path + for path in scan_text_embeddings(is_sdxl): + if path.stem not in embeds: + # new token/name, add it + logger.debug(f"Found embedding token {path.stem} at {path.relative_to(embed_dir)}") + embeds[path.stem] = path + else: + # duplicate token/name, skip it + skipped[path.stem] = path + logger.debug(f"Duplicate embedding token {path.stem} at {path.relative_to(embed_dir)}") + + # warn the user if there are duplicates we skipped + if skipped: + logger.warn(f"Skipped {len(skipped)} embeddings with duplicate tokens!") + logger.warn(f"Skipped paths: {[x.relative_to(embed_dir) for x in skipped.values()]}") + logger.warn("Rename these files to avoid collisions!") + + # we can optionally return the tensors instead of the paths + if return_tensors: + # load the embeddings + embeds = {k: load_embed_weights(v) for k, v in embeds.items()} + # filter out the ones that failed to load + loaded_embeds = {k: v for k, v in embeds.items() if v is not None} + if len(loaded_embeds) != len(embeds): + logger.warn(f"Failed to load {len(embeds) - len(loaded_embeds)} embeddings!") + logger.warn(f"Skipped embeddings: {[x for x in embeds.keys() if x not in loaded_embeds]}") + + # return a dict of {token: path | embedding} + return embeds + + +def load_embed_weights(path: Path, key: Optional[str] = None) -> Optional[Tensor]: + """Load an embedding from a file. + Accepts an optional key to load a specific embedding from a file with multiple embeddings, otherwise + it will try to load the first one it finds. + """ + if not path.exists() and path.is_file(): + raise ValueError(f"Embedding path {path} does not exist or is not a file!") + try: + if path.suffix.lower() == ".safetensors": + state_dict = load_file(path, device="cpu") + elif path.suffix.lower() in EMBED_EXTS: + state_dict = torch.load(path, weights_only=True, map_location="cpu") + except Exception: + logger.error(f"Failed to load embedding {path}", exc_info=True) + return None + + embedding = None + if len(state_dict) == 1: + logger.debug(f"Found single key in {path.stem}, using it") + embedding = next(iter(state_dict.values())) + elif key is not None and key in state_dict: + logger.debug(f"Using passed key {key} for {path.stem}") + embedding = state_dict[key] + elif "string_to_param" in state_dict: + logger.debug(f"A1111 style embedding found for {path.stem}") + embedding = next(iter(state_dict["string_to_param"].values())) + else: + # we couldn't find the embedding key, warn the user and just use the first key that's a Tensor + logger.warn(f"Could not find embedding key in {path.stem}!") + logger.warn("Taking a wild guess and using the first Tensor we find...") + for key, value in state_dict.items(): + if torch.is_tensor(value): + embedding = value + logger.warn(f"Using key: {key}") + break + + return embedding + + +def load_text_embeddings( + pipeline: DiffusionPipeline, text_embeds: Optional[tuple[str, torch.Tensor]] = None, is_sdxl = False +) -> None: + if text_embeds is None: + text_embeds = get_text_embeddings(False, is_sdxl) + if len(text_embeds) < 1: + logger.info("No TI embeddings found") + return + + logger.info(f"Loading {len(text_embeds)} TI embeddings...") + loaded, skipped, failed = [], [], [] + + if True: + vocab = pipeline.tokenizer.get_vocab() # get the tokenizer vocab so we can skip loaded embeddings + for token, emb_path in text_embeds.items(): + try: + if token not in vocab: + if is_sdxl: + embed = load_embed_weights(emb_path, "clip_g").to(pipeline.text_encoder_2.device) + pipeline.load_textual_inversion(embed, token=token, text_encoder=pipeline.text_encoder_2, tokenizer=pipeline.tokenizer_2) + embed = load_embed_weights(emb_path, "clip_l").to(pipeline.text_encoder.device) + pipeline.load_textual_inversion(embed, token=token, text_encoder=pipeline.text_encoder, tokenizer=pipeline.tokenizer) + else: + embed = load_embed_weights(emb_path).to(pipeline.text_encoder.device) + pipeline.load_textual_inversion({token: embed}) + logger.debug(f"Loaded embedding '{token}'") + loaded.append(token) + else: + logger.debug(f"Skipping embedding '{token}' (already loaded)") + skipped.append(token) + except Exception: + logger.error(f"Failed to load TI embedding: {token}", exc_info=True) + failed.append(token) + + else: + vocab = pipeline.tokenizer.get_vocab() # get the tokenizer vocab so we can skip loaded embeddings + for token, embed in text_embeds.items(): + try: + if token not in vocab: + if is_sdxl: + pipeline.load_textual_inversion(text_encoder_sd, token=token, text_encoder=pipe.text_encoder, tokenizer=pipe.tokenizer) + else: + pipeline.load_textual_inversion({token: embed}) + logger.debug(f"Loaded embedding '{token}'") + loaded.append(token) + else: + logger.debug(f"Skipping embedding '{token}' (already loaded)") + skipped.append(token) + except Exception: + logger.error(f"Failed to load TI embedding: {token}", exc_info=True) + failed.append(token) + + # Print a summary of what we loaded + logger.info(f"Loaded {len(loaded)} embeddings, {len(skipped)} existing, {len(failed)} failed") + logger.info(f"Available embeddings: {', '.join(loaded + skipped)}") + if len(failed) > 0: + # only print failed if there were failures + logger.warn(f"Failed to load embeddings: {', '.join(failed)}") diff --git a/animate/src/animatediff/repo/.gitignore b/animate/src/animatediff/repo/.gitignore new file mode 100644 index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d --- /dev/null +++ b/animate/src/animatediff/repo/.gitignore @@ -0,0 +1,2 @@ +* +!.gitignore diff --git a/animate/src/animatediff/rife/__init__.py b/animate/src/animatediff/rife/__init__.py new file mode 100644 index 0000000000000000000000000000000000000000..ae2d868cc0ef3284e7f4464bd720dd03c065ddee --- /dev/null +++ b/animate/src/animatediff/rife/__init__.py @@ -0,0 +1,5 @@ +from .rife import app + +__all__ = [ + "app", +] diff --git a/animate/src/animatediff/rife/ffmpeg.py b/animate/src/animatediff/rife/ffmpeg.py new file mode 100644 index 0000000000000000000000000000000000000000..d3b825db1c45877daa21b84bc9f23aee4ffef4fe --- /dev/null +++ b/animate/src/animatediff/rife/ffmpeg.py @@ -0,0 +1,231 @@ +from enum import Enum +from pathlib import Path +from re import split +from typing import Annotated, Optional, Union + +import ffmpeg +from ffmpeg.nodes import FilterNode, InputNode +from torch import Value + + +class VideoCodec(str, Enum): + gif = "gif" + vp9 = "vp9" + webm = "webm" + webp = "webp" + h264 = "h264" + hevc = "hevc" + + +def codec_extn(codec: VideoCodec): + match codec: + case VideoCodec.gif: + return "gif" + case VideoCodec.vp9: + return "webm" + case VideoCodec.webm: + return "webm" + case VideoCodec.webp: + return "webp" + case VideoCodec.h264: + return "mp4" + case VideoCodec.hevc: + return "mp4" + case _: + raise ValueError(f"Unknown codec {codec}") + + +def clamp_gif_fps(fps: int): + """Clamp FPS to a value that is supported by GIFs. + + GIF frame duration is measured in 1/100ths of a second, so we need to clamp the + FPS to a value that 100 is a factor of. + """ + # the sky is not the limit, sadly... + if fps > 100: + return 100 + + # if 100/fps is an integer, we're good + if 100 % fps == 0: + return fps + + # but of course, it was never going to be that easy. + match fps: + case x if x > 50: + # 50 is the highest FPS that 100 is a factor of. + # people will ask for 60. they will get 50, and they will like it. + return 50 + case x if x >= 30: + return 33 + case x if x >= 24: + return 25 + case x if x >= 20: + return 20 + case x if x >= 15: + # ffmpeg will pad a few frames to make this work + return 16 + case x if x >= 12: + return 12 + case x if x >= 10: + # idk why anyone would request 11fps, but they're getting 10 + return 10 + case x if x >= 6: + # also invalid but ffmpeg will pad it + return 6 + case 4: + return 4 # FINE, I GUESS + case _: + return 1 # I don't know why you would want this, but here you go + + +class FfmpegEncoder: + def __init__( + self, + frames_dir: Path, + out_file: Path, + codec: VideoCodec, + in_fps: int = 60, + out_fps: int = 60, + lossless: bool = False, + param={}, + ): + self.frames_dir = frames_dir + self.out_file = out_file + self.codec = codec + self.in_fps = in_fps + self.out_fps = out_fps + self.lossless = lossless + self.param = param + + self.input: Optional[InputNode] = None + + def encode(self) -> tuple: + self.input: InputNode = ffmpeg.input( + str(self.frames_dir.resolve().joinpath("%08d.png")), framerate=self.in_fps + ).filter("fps", fps=self.in_fps) + match self.codec: + case VideoCodec.gif: + return self._encode_gif() + case VideoCodec.webm: + return self._encode_webm() + case VideoCodec.webp: + return self._encode_webp() + case VideoCodec.h264: + return self._encode_h264() + case VideoCodec.hevc: + return self._encode_hevc() + case _: + raise ValueError(f"Unknown codec {self.codec}") + + @property + def _out_file(self) -> Path: + return str(self.out_file.resolve()) + + @staticmethod + def _interpolate(stream, out_fps: int) -> FilterNode: + return stream.filter( + "minterpolate", fps=out_fps, mi_mode="mci", mc_mode="aobmc", me_mode="bidir", vsbmc=1 + ) + + def _encode_gif(self) -> tuple: + stream: FilterNode = self.input + + # Output FPS must be divisible by 100 for GIFs, so we clamp it + out_fps = clamp_gif_fps(self.out_fps) + if self.in_fps != out_fps: + stream = self._interpolate(stream, out_fps) + + # split into two streams for palettegen and paletteuse + split_stream = stream.split() + + # generate the palette, then use it to encode the GIF + palette = split_stream[0].filter("palettegen") + stream = ffmpeg.filter([split_stream[1], palette], "paletteuse").output( + self._out_file, vcodec="gif", loop=0 + ) + return stream.run() + + def _encode_webm(self) -> tuple: + stream: FilterNode = self.input + if self.in_fps != self.out_fps: + stream = self._interpolate(stream, self.out_fps) + param = { + "pix_fmt":"yuv420p", + "vcodec":"libvpx-vp9", + "video_bitrate":0, + "crf":24, + } + param.update(**self.param) + stream = stream.output( + self._out_file, **param + ) + return stream.run() + + def _encode_webp(self) -> tuple: + stream: FilterNode = self.input + if self.in_fps != self.out_fps: + stream = self._interpolate(stream, self.out_fps) + + if self.lossless: + param = { + "pix_fmt":"bgra", + "vcodec":"libwebp_anim", + "lossless":1, + "compression_level":5, + "qscale":75, + "loop":0, + } + param.update(**self.param) + stream = stream.output( + self._out_file, + **param + ) + else: + param = { + "pix_fmt":"yuv420p", + "vcodec":"libwebp_anim", + "lossless":0, + "compression_level":5, + "qscale":90, + "loop":0, + } + param.update(**self.param) + stream = stream.output( + self._out_file, + **param + ) + return stream.run() + + def _encode_h264(self) -> tuple: + stream: FilterNode = self.input + if self.in_fps != self.out_fps: + stream = self._interpolate(stream, self.out_fps) + + param = { + "pix_fmt":"yuv420p", + "vcodec":"libx264", + "crf":21, + "tune":"animation", + } + param.update(**self.param) + + stream = stream.output( + self._out_file, **param + ) + return stream.run() + + def _encode_hevc(self) -> tuple: + stream: FilterNode = self.input + if self.in_fps != self.out_fps: + stream = self._interpolate(stream, self.out_fps) + + param = { + "pix_fmt":"yuv420p", + "vcodec":"libx264", + "crf":21, + "tune":"animation", + } + param.update(**self.param) + + stream = stream.output(self._out_file, **param) + return stream.run() diff --git a/animate/src/animatediff/rife/ncnn.py b/animate/src/animatediff/rife/ncnn.py new file mode 100644 index 0000000000000000000000000000000000000000..8f544a649aa15f4ae54ac113625dc25592d1b5d3 --- /dev/null +++ b/animate/src/animatediff/rife/ncnn.py @@ -0,0 +1,84 @@ +import logging +from pathlib import Path +from typing import Optional + +from pydantic import BaseModel, Field + +logger = logging.getLogger(__name__) + + +class RifeNCNNOptions(BaseModel): + model_path: Path = Field(..., description="Path to RIFE model directory") + input_path: Path = Field(..., description="Path to source frames directory") + output_path: Optional[Path] = Field(None, description="Path to output frames directory") + num_frame: Optional[int] = Field(None, description="Number of frames to generate (default N*2)") + time_step: float = Field(0.5, description="Time step for interpolation (default 0.5)", gt=0.0, le=1.0) + gpu_id: Optional[int | list[int]] = Field( + None, description="GPU ID(s) to use (default: auto, -1 for CPU)" + ) + load_threads: int = Field(1, description="Number of threads for frame loading", gt=0) + process_threads: int = Field(2, description="Number of threads used for frame processing", gt=0) + save_threads: int = Field(2, description="Number of threads for frame saving", gt=0) + spatial_tta: bool = Field(False, description="Enable spatial TTA mode") + temporal_tta: bool = Field(False, description="Enable temporal TTA mode") + uhd: bool = Field(False, description="Enable UHD mode") + verbose: bool = Field(False, description="Enable verbose logging") + + def get_args(self, frame_multiplier: int = 7) -> list[str]: + """Generate arguments to pass to rife-ncnn-vulkan. + + Frame multiplier is used to calculate the number of frames to generate, if num_frame is not set. + """ + if self.output_path is None: + self.output_path = self.input_path.joinpath("out") + + # calc num frames + if self.num_frame is None: + num_src_frames = len([x for x in self.input_path.glob("*.png") if x.is_file()]) + logger.info(f"Found {num_src_frames} source frames, using multiplier {frame_multiplier}") + num_frame = num_src_frames * frame_multiplier + logger.info(f"We will generate {num_frame} frames") + else: + num_frame = self.num_frame + + # GPU ID and process threads are comma-separated lists, so we need to convert them to strings + if self.gpu_id is None: + gpu_id = "auto" + process_threads = self.process_threads + elif isinstance(self.gpu_id, list): + gpu_id = ",".join([str(x) for x in self.gpu_id]) + process_threads = ",".join([str(self.process_threads) for _ in self.gpu_id]) + else: + gpu_id = str(self.gpu_id) + process_threads = str(self.process_threads) + + # Build args list + args_list = [ + "-i", + f"{self.input_path.resolve()}/", + "-o", + f"{self.output_path.resolve()}/", + "-m", + f"{self.model_path.resolve()}/", + "-n", + num_frame, + "-s", + f"{self.time_step:.5f}", + "-g", + gpu_id, + "-j", + f"{self.load_threads}:{process_threads}:{self.save_threads}", + ] + + # Add flags if set + if self.spatial_tta: + args_list.append("-x") + if self.temporal_tta: + args_list.append("-z") + if self.uhd: + args_list.append("-u") + if self.verbose: + args_list.append("-v") + + # Convert all args to strings and return + return [str(x) for x in args_list] diff --git a/animate/src/animatediff/rife/rife.py b/animate/src/animatediff/rife/rife.py new file mode 100644 index 0000000000000000000000000000000000000000..fbb4cfdaf6531a4a8024a0cc8960b9100c77b47e --- /dev/null +++ b/animate/src/animatediff/rife/rife.py @@ -0,0 +1,195 @@ +import logging +import subprocess +from math import ceil +from pathlib import Path +from typing import Annotated, Optional + +import typer + +from animatediff import get_dir + +from .ffmpeg import FfmpegEncoder, VideoCodec, codec_extn +from .ncnn import RifeNCNNOptions + +rife_dir = get_dir("data/rife") +rife_ncnn_vulkan = rife_dir.joinpath("rife-ncnn-vulkan") + +logger = logging.getLogger(__name__) + +app: typer.Typer = typer.Typer( + name="rife", + context_settings=dict(help_option_names=["-h", "--help"]), + rich_markup_mode="rich", + pretty_exceptions_show_locals=False, + help="RIFE motion flow interpolation (MORE FPS!)", +) + +def rife_interpolate( + input_frames_dir:str, + output_frames_dir:str, + frame_multiplier:int = 2, + rife_model:str = "rife-v4.6", + spatial_tta:bool = False, + temporal_tta:bool = False, + uhd:bool = False, +): + + rife_model_dir = rife_dir.joinpath(rife_model) + if not rife_model_dir.joinpath("flownet.bin").exists(): + raise FileNotFoundError(f"RIFE model dir {rife_model_dir} does not have a model in it!") + + + rife_opts = RifeNCNNOptions( + model_path=rife_model_dir, + input_path=input_frames_dir, + output_path=output_frames_dir, + time_step=1 / frame_multiplier, + spatial_tta=spatial_tta, + temporal_tta=temporal_tta, + uhd=uhd, + ) + rife_args = rife_opts.get_args(frame_multiplier=frame_multiplier) + + # actually run RIFE + logger.info("Running RIFE, this may take a little while...") + with subprocess.Popen( + [rife_ncnn_vulkan, *rife_args], stdout=subprocess.PIPE, stderr=subprocess.PIPE + ) as proc: + errs = [] + for line in proc.stderr: + line = line.decode("utf-8").strip() + if line: + logger.debug(line) + stdout, _ = proc.communicate() + if proc.returncode != 0: + raise RuntimeError(f"RIFE failed with code {proc.returncode}:\n" + "\n".join(errs)) + + import glob + import os + org_images = sorted(glob.glob( os.path.join(output_frames_dir, "[0-9]*.png"), recursive=False)) + for o in org_images: + p = Path(o) + new_no = int(p.stem) - 1 + new_p = p.with_stem(f"{new_no:08d}") + p.rename(new_p) + + + +@app.command(no_args_is_help=True) +def interpolate( + rife_model: Annotated[ + str, + typer.Option("--rife-model", "-m", help="RIFE model to use (subdirectory of data/rife/)"), + ] = "rife-v4.6", + in_fps: Annotated[ + int, + typer.Option("--in-fps", "-I", help="Input frame FPS (8 for AnimateDiff)", show_default=True), + ] = 8, + frame_multiplier: Annotated[ + int, + typer.Option( + "--frame-multiplier", "-M", help="Multiply total frame count by this", show_default=True + ), + ] = 8, + out_fps: Annotated[ + int, + typer.Option("--out-fps", "-F", help="Target FPS", show_default=True), + ] = 50, + codec: Annotated[ + VideoCodec, + typer.Option("--codec", "-c", help="Output video codec", show_default=True), + ] = VideoCodec.webm, + lossless: Annotated[ + bool, + typer.Option("--lossless", "-L", is_flag=True, help="Use lossless encoding (WebP only)"), + ] = False, + spatial_tta: Annotated[ + bool, + typer.Option("--spatial-tta", "-x", is_flag=True, help="Enable RIFE Spatial TTA mode"), + ] = False, + temporal_tta: Annotated[ + bool, + typer.Option("--temporal-tta", "-z", is_flag=True, help="Enable RIFE Temporal TTA mode"), + ] = False, + uhd: Annotated[ + bool, + typer.Option("--uhd", "-u", is_flag=True, help="Enable RIFE UHD mode"), + ] = False, + frames_dir: Annotated[ + Path, + typer.Argument(path_type=Path, file_okay=False, exists=True, help="Path to source frames directory"), + ] = ..., + out_file: Annotated[ + Optional[Path], + typer.Argument( + dir_okay=False, + help="Path to output file (default: frames_dir/rife-output.
 +
+For our previous work on SepConv, see: https://github.com/sniklaus/revisiting-sepconv
+
+## setup
+The softmax splatting is implemented in CUDA using CuPy, which is why CuPy is a required dependency. It can be installed using `pip install cupy` or alternatively using one of the provided [binary packages](https://docs.cupy.dev/en/stable/install.html#installing-cupy) as outlined in the CuPy repository.
+
+If you plan to process videos, then please also make sure to have `pip install moviepy` installed.
+
+## usage
+To run it on your own pair of frames, use the following command.
+
+```
+python run.py --model lf --one ./images/one.png --two ./images/two.png --out ./out.png
+```
+
+To run in on a video, use the following command.
+
+```
+python run.py --model lf --video ./videos/car-turn.mp4 --out ./out.mp4
+```
+
+For a quick benchmark using examples from the Middlebury benchmark for optical flow, run `python benchmark_middlebury.py`. You can use it to easily verify that the provided implementation runs as expected.
+
+## warping
+We provide a small script to replicate the third figure of our paper [1]. You can simply run the following to obtain the comparison between summation splatting, average splatting, linear splatting, and softmax splatting.
+
+The example script is using OpenCV to load and display images, as well as to read the provided optical flow file. An easy way to install OpenCV for Python is using the `pip install opencv-contrib-python` package.
+
+```
+import cv2
+import numpy
+import torch
+
+import run
+
+import softsplat # the custom softmax splatting layer
+
+##########################################################
+
+torch.set_grad_enabled(False) # make sure to not compute gradients for computational performance
+
+torch.backends.cudnn.enabled = True # make sure to use cudnn for computational performance
+
+##########################################################
+
+tenOne = torch.FloatTensor(numpy.ascontiguousarray(cv2.imread(filename='./images/one.png', flags=-1).transpose(2, 0, 1)[None, :, :, :].astype(numpy.float32) * (1.0 / 255.0))).cuda()
+tenTwo = torch.FloatTensor(numpy.ascontiguousarray(cv2.imread(filename='./images/two.png', flags=-1).transpose(2, 0, 1)[None, :, :, :].astype(numpy.float32) * (1.0 / 255.0))).cuda()
+tenFlow = torch.FloatTensor(numpy.ascontiguousarray(run.read_flo('./images/flow.flo').transpose(2, 0, 1)[None, :, :, :])).cuda()
+
+tenMetric = torch.nn.functional.l1_loss(input=tenOne, target=run.backwarp(tenIn=tenTwo, tenFlow=tenFlow), reduction='none').mean([1], True)
+
+for intTime, fltTime in enumerate(numpy.linspace(0.0, 1.0, 11).tolist()):
+ tenSummation = softsplat.softsplat(tenIn=tenOne, tenFlow=tenFlow * fltTime, tenMetric=None, strMode='sum')
+ tenAverage = softsplat.softsplat(tenIn=tenOne, tenFlow=tenFlow * fltTime, tenMetric=None, strMode='avg')
+ tenLinear = softsplat.softsplat(tenIn=tenOne, tenFlow=tenFlow * fltTime, tenMetric=(0.3 - tenMetric).clip(0.001, 1.0), strMode='linear') # finding a good linearly metric is difficult, and it is not invariant to translations
+ tenSoftmax = softsplat.softsplat(tenIn=tenOne, tenFlow=tenFlow * fltTime, tenMetric=(-20.0 * tenMetric).clip(-20.0, 20.0), strMode='soft') # -20.0 is a hyperparameter, called 'alpha' in the paper, that could be learned using a torch.Parameter
+
+ cv2.imshow(winname='summation', mat=tenSummation[0, :, :, :].cpu().numpy().transpose(1, 2, 0))
+ cv2.imshow(winname='average', mat=tenAverage[0, :, :, :].cpu().numpy().transpose(1, 2, 0))
+ cv2.imshow(winname='linear', mat=tenLinear[0, :, :, :].cpu().numpy().transpose(1, 2, 0))
+ cv2.imshow(winname='softmax', mat=tenSoftmax[0, :, :, :].cpu().numpy().transpose(1, 2, 0))
+ cv2.waitKey(delay=0)
+# end
+```
+
+## xiph
+In our paper, we propose to use 4K video clips from Xiph to evaluate video frame interpolation on high-resolution footage. Please see the supplementary `benchmark_xiph.py` on how to reproduce the shown metrics.
+
+## video
+
+
+For our previous work on SepConv, see: https://github.com/sniklaus/revisiting-sepconv
+
+## setup
+The softmax splatting is implemented in CUDA using CuPy, which is why CuPy is a required dependency. It can be installed using `pip install cupy` or alternatively using one of the provided [binary packages](https://docs.cupy.dev/en/stable/install.html#installing-cupy) as outlined in the CuPy repository.
+
+If you plan to process videos, then please also make sure to have `pip install moviepy` installed.
+
+## usage
+To run it on your own pair of frames, use the following command.
+
+```
+python run.py --model lf --one ./images/one.png --two ./images/two.png --out ./out.png
+```
+
+To run in on a video, use the following command.
+
+```
+python run.py --model lf --video ./videos/car-turn.mp4 --out ./out.mp4
+```
+
+For a quick benchmark using examples from the Middlebury benchmark for optical flow, run `python benchmark_middlebury.py`. You can use it to easily verify that the provided implementation runs as expected.
+
+## warping
+We provide a small script to replicate the third figure of our paper [1]. You can simply run the following to obtain the comparison between summation splatting, average splatting, linear splatting, and softmax splatting.
+
+The example script is using OpenCV to load and display images, as well as to read the provided optical flow file. An easy way to install OpenCV for Python is using the `pip install opencv-contrib-python` package.
+
+```
+import cv2
+import numpy
+import torch
+
+import run
+
+import softsplat # the custom softmax splatting layer
+
+##########################################################
+
+torch.set_grad_enabled(False) # make sure to not compute gradients for computational performance
+
+torch.backends.cudnn.enabled = True # make sure to use cudnn for computational performance
+
+##########################################################
+
+tenOne = torch.FloatTensor(numpy.ascontiguousarray(cv2.imread(filename='./images/one.png', flags=-1).transpose(2, 0, 1)[None, :, :, :].astype(numpy.float32) * (1.0 / 255.0))).cuda()
+tenTwo = torch.FloatTensor(numpy.ascontiguousarray(cv2.imread(filename='./images/two.png', flags=-1).transpose(2, 0, 1)[None, :, :, :].astype(numpy.float32) * (1.0 / 255.0))).cuda()
+tenFlow = torch.FloatTensor(numpy.ascontiguousarray(run.read_flo('./images/flow.flo').transpose(2, 0, 1)[None, :, :, :])).cuda()
+
+tenMetric = torch.nn.functional.l1_loss(input=tenOne, target=run.backwarp(tenIn=tenTwo, tenFlow=tenFlow), reduction='none').mean([1], True)
+
+for intTime, fltTime in enumerate(numpy.linspace(0.0, 1.0, 11).tolist()):
+ tenSummation = softsplat.softsplat(tenIn=tenOne, tenFlow=tenFlow * fltTime, tenMetric=None, strMode='sum')
+ tenAverage = softsplat.softsplat(tenIn=tenOne, tenFlow=tenFlow * fltTime, tenMetric=None, strMode='avg')
+ tenLinear = softsplat.softsplat(tenIn=tenOne, tenFlow=tenFlow * fltTime, tenMetric=(0.3 - tenMetric).clip(0.001, 1.0), strMode='linear') # finding a good linearly metric is difficult, and it is not invariant to translations
+ tenSoftmax = softsplat.softsplat(tenIn=tenOne, tenFlow=tenFlow * fltTime, tenMetric=(-20.0 * tenMetric).clip(-20.0, 20.0), strMode='soft') # -20.0 is a hyperparameter, called 'alpha' in the paper, that could be learned using a torch.Parameter
+
+ cv2.imshow(winname='summation', mat=tenSummation[0, :, :, :].cpu().numpy().transpose(1, 2, 0))
+ cv2.imshow(winname='average', mat=tenAverage[0, :, :, :].cpu().numpy().transpose(1, 2, 0))
+ cv2.imshow(winname='linear', mat=tenLinear[0, :, :, :].cpu().numpy().transpose(1, 2, 0))
+ cv2.imshow(winname='softmax', mat=tenSoftmax[0, :, :, :].cpu().numpy().transpose(1, 2, 0))
+ cv2.waitKey(delay=0)
+# end
+```
+
+## xiph
+In our paper, we propose to use 4K video clips from Xiph to evaluate video frame interpolation on high-resolution footage. Please see the supplementary `benchmark_xiph.py` on how to reproduce the shown metrics.
+
+## video
+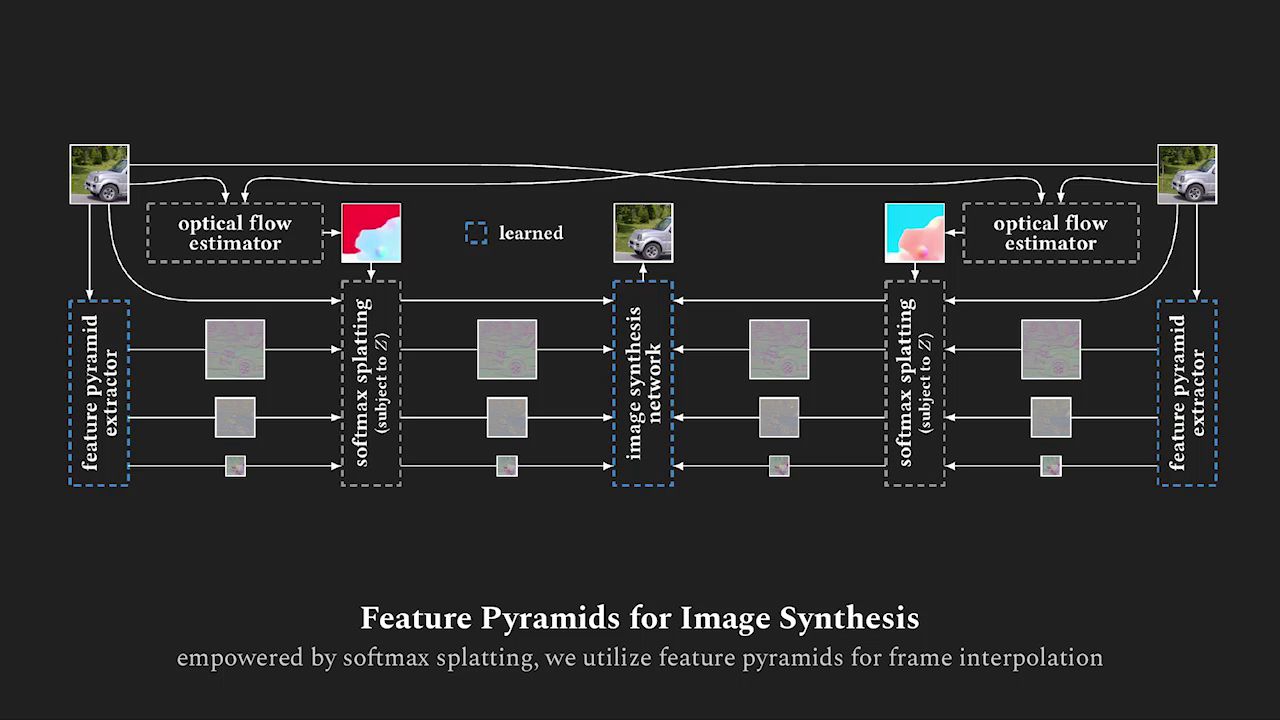 +
+## license
+The provided implementation is strictly for academic purposes only. Should you be interested in using our technology for any commercial use, please feel free to contact us.
+
+## references
+```
+[1] @inproceedings{Niklaus_CVPR_2020,
+ author = {Simon Niklaus and Feng Liu},
+ title = {Softmax Splatting for Video Frame Interpolation},
+ booktitle = {IEEE Conference on Computer Vision and Pattern Recognition},
+ year = {2020}
+ }
+```
+
+## acknowledgment
+The video above uses materials under a Creative Common license as detailed at the end.
\ No newline at end of file
diff --git a/animate/src/animatediff/softmax_splatting/correlation/README.md b/animate/src/animatediff/softmax_splatting/correlation/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a8e0ca529d50b7e09d521cc288daae7771514188
--- /dev/null
+++ b/animate/src/animatediff/softmax_splatting/correlation/README.md
@@ -0,0 +1 @@
+This is an adaptation of the FlowNet2 implementation in order to compute cost volumes. Should you be making use of this work, please make sure to adhere to the licensing terms of the original authors. Should you be making use or modify this particular implementation, please acknowledge it appropriately.
\ No newline at end of file
diff --git a/animate/src/animatediff/softmax_splatting/correlation/correlation.py b/animate/src/animatediff/softmax_splatting/correlation/correlation.py
new file mode 100644
index 0000000000000000000000000000000000000000..5b560d41d55655945d0cf7a81de39c8d2678f0e1
--- /dev/null
+++ b/animate/src/animatediff/softmax_splatting/correlation/correlation.py
@@ -0,0 +1,395 @@
+#!/usr/bin/env python
+
+import cupy
+import re
+import torch
+
+kernel_Correlation_rearrange = '''
+ extern "C" __global__ void kernel_Correlation_rearrange(
+ const int n,
+ const float* input,
+ float* output
+ ) {
+ int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x;
+
+ if (intIndex >= n) {
+ return;
+ }
+
+ int intSample = blockIdx.z;
+ int intChannel = blockIdx.y;
+
+ float fltValue = input[(((intSample * SIZE_1(input)) + intChannel) * SIZE_2(input) * SIZE_3(input)) + intIndex];
+
+ __syncthreads();
+
+ int intPaddedY = (intIndex / SIZE_3(input)) + 4;
+ int intPaddedX = (intIndex % SIZE_3(input)) + 4;
+ int intRearrange = ((SIZE_3(input) + 8) * intPaddedY) + intPaddedX;
+
+ output[(((intSample * SIZE_1(output) * SIZE_2(output)) + intRearrange) * SIZE_1(input)) + intChannel] = fltValue;
+ }
+'''
+
+kernel_Correlation_updateOutput = '''
+ extern "C" __global__ void kernel_Correlation_updateOutput(
+ const int n,
+ const float* rbot0,
+ const float* rbot1,
+ float* top
+ ) {
+ extern __shared__ char patch_data_char[];
+
+ float *patch_data = (float *)patch_data_char;
+
+ // First (upper left) position of kernel upper-left corner in current center position of neighborhood in image 1
+ int x1 = blockIdx.x + 4;
+ int y1 = blockIdx.y + 4;
+ int item = blockIdx.z;
+ int ch_off = threadIdx.x;
+
+ // Load 3D patch into shared shared memory
+ for (int j = 0; j < 1; j++) { // HEIGHT
+ for (int i = 0; i < 1; i++) { // WIDTH
+ int ji_off = (j + i) * SIZE_3(rbot0);
+ for (int ch = ch_off; ch < SIZE_3(rbot0); ch += 32) { // CHANNELS
+ int idx1 = ((item * SIZE_1(rbot0) + y1+j) * SIZE_2(rbot0) + x1+i) * SIZE_3(rbot0) + ch;
+ int idxPatchData = ji_off + ch;
+ patch_data[idxPatchData] = rbot0[idx1];
+ }
+ }
+ }
+
+ __syncthreads();
+
+ __shared__ float sum[32];
+
+ // Compute correlation
+ for (int top_channel = 0; top_channel < SIZE_1(top); top_channel++) {
+ sum[ch_off] = 0;
+
+ int s2o = top_channel % 9 - 4;
+ int s2p = top_channel / 9 - 4;
+
+ for (int j = 0; j < 1; j++) { // HEIGHT
+ for (int i = 0; i < 1; i++) { // WIDTH
+ int ji_off = (j + i) * SIZE_3(rbot0);
+ for (int ch = ch_off; ch < SIZE_3(rbot0); ch += 32) { // CHANNELS
+ int x2 = x1 + s2o;
+ int y2 = y1 + s2p;
+
+ int idxPatchData = ji_off + ch;
+ int idx2 = ((item * SIZE_1(rbot0) + y2+j) * SIZE_2(rbot0) + x2+i) * SIZE_3(rbot0) + ch;
+
+ sum[ch_off] += patch_data[idxPatchData] * rbot1[idx2];
+ }
+ }
+ }
+
+ __syncthreads();
+
+ if (ch_off == 0) {
+ float total_sum = 0;
+ for (int idx = 0; idx < 32; idx++) {
+ total_sum += sum[idx];
+ }
+ const int sumelems = SIZE_3(rbot0);
+ const int index = ((top_channel*SIZE_2(top) + blockIdx.y)*SIZE_3(top))+blockIdx.x;
+ top[index + item*SIZE_1(top)*SIZE_2(top)*SIZE_3(top)] = total_sum / (float)sumelems;
+ }
+ }
+ }
+'''
+
+kernel_Correlation_updateGradOne = '''
+ #define ROUND_OFF 50000
+
+ extern "C" __global__ void kernel_Correlation_updateGradOne(
+ const int n,
+ const int intSample,
+ const float* rbot0,
+ const float* rbot1,
+ const float* gradOutput,
+ float* gradOne,
+ float* gradTwo
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ int n = intIndex % SIZE_1(gradOne); // channels
+ int l = (intIndex / SIZE_1(gradOne)) % SIZE_3(gradOne) + 4; // w-pos
+ int m = (intIndex / SIZE_1(gradOne) / SIZE_3(gradOne)) % SIZE_2(gradOne) + 4; // h-pos
+
+ // round_off is a trick to enable integer division with ceil, even for negative numbers
+ // We use a large offset, for the inner part not to become negative.
+ const int round_off = ROUND_OFF;
+ const int round_off_s1 = round_off;
+
+ // We add round_off before_s1 the int division and subtract round_off after it, to ensure the formula matches ceil behavior:
+ int xmin = (l - 4 + round_off_s1 - 1) + 1 - round_off; // ceil (l - 4)
+ int ymin = (m - 4 + round_off_s1 - 1) + 1 - round_off; // ceil (l - 4)
+
+ // Same here:
+ int xmax = (l - 4 + round_off_s1) - round_off; // floor (l - 4)
+ int ymax = (m - 4 + round_off_s1) - round_off; // floor (m - 4)
+
+ float sum = 0;
+ if (xmax>=0 && ymax>=0 && (xmin<=SIZE_3(gradOutput)-1) && (ymin<=SIZE_2(gradOutput)-1)) {
+ xmin = max(0,xmin);
+ xmax = min(SIZE_3(gradOutput)-1,xmax);
+
+ ymin = max(0,ymin);
+ ymax = min(SIZE_2(gradOutput)-1,ymax);
+
+ for (int p = -4; p <= 4; p++) {
+ for (int o = -4; o <= 4; o++) {
+ // Get rbot1 data:
+ int s2o = o;
+ int s2p = p;
+ int idxbot1 = ((intSample * SIZE_1(rbot0) + (m+s2p)) * SIZE_2(rbot0) + (l+s2o)) * SIZE_3(rbot0) + n;
+ float bot1tmp = rbot1[idxbot1]; // rbot1[l+s2o,m+s2p,n]
+
+ // Index offset for gradOutput in following loops:
+ int op = (p+4) * 9 + (o+4); // index[o,p]
+ int idxopoffset = (intSample * SIZE_1(gradOutput) + op);
+
+ for (int y = ymin; y <= ymax; y++) {
+ for (int x = xmin; x <= xmax; x++) {
+ int idxgradOutput = (idxopoffset * SIZE_2(gradOutput) + y) * SIZE_3(gradOutput) + x; // gradOutput[x,y,o,p]
+ sum += gradOutput[idxgradOutput] * bot1tmp;
+ }
+ }
+ }
+ }
+ }
+ const int sumelems = SIZE_1(gradOne);
+ const int bot0index = ((n * SIZE_2(gradOne)) + (m-4)) * SIZE_3(gradOne) + (l-4);
+ gradOne[bot0index + intSample*SIZE_1(gradOne)*SIZE_2(gradOne)*SIZE_3(gradOne)] = sum / (float)sumelems;
+ } }
+'''
+
+kernel_Correlation_updateGradTwo = '''
+ #define ROUND_OFF 50000
+
+ extern "C" __global__ void kernel_Correlation_updateGradTwo(
+ const int n,
+ const int intSample,
+ const float* rbot0,
+ const float* rbot1,
+ const float* gradOutput,
+ float* gradOne,
+ float* gradTwo
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ int n = intIndex % SIZE_1(gradTwo); // channels
+ int l = (intIndex / SIZE_1(gradTwo)) % SIZE_3(gradTwo) + 4; // w-pos
+ int m = (intIndex / SIZE_1(gradTwo) / SIZE_3(gradTwo)) % SIZE_2(gradTwo) + 4; // h-pos
+
+ // round_off is a trick to enable integer division with ceil, even for negative numbers
+ // We use a large offset, for the inner part not to become negative.
+ const int round_off = ROUND_OFF;
+ const int round_off_s1 = round_off;
+
+ float sum = 0;
+ for (int p = -4; p <= 4; p++) {
+ for (int o = -4; o <= 4; o++) {
+ int s2o = o;
+ int s2p = p;
+
+ //Get X,Y ranges and clamp
+ // We add round_off before_s1 the int division and subtract round_off after it, to ensure the formula matches ceil behavior:
+ int xmin = (l - 4 - s2o + round_off_s1 - 1) + 1 - round_off; // ceil (l - 4 - s2o)
+ int ymin = (m - 4 - s2p + round_off_s1 - 1) + 1 - round_off; // ceil (l - 4 - s2o)
+
+ // Same here:
+ int xmax = (l - 4 - s2o + round_off_s1) - round_off; // floor (l - 4 - s2o)
+ int ymax = (m - 4 - s2p + round_off_s1) - round_off; // floor (m - 4 - s2p)
+
+ if (xmax>=0 && ymax>=0 && (xmin<=SIZE_3(gradOutput)-1) && (ymin<=SIZE_2(gradOutput)-1)) {
+ xmin = max(0,xmin);
+ xmax = min(SIZE_3(gradOutput)-1,xmax);
+
+ ymin = max(0,ymin);
+ ymax = min(SIZE_2(gradOutput)-1,ymax);
+
+ // Get rbot0 data:
+ int idxbot0 = ((intSample * SIZE_1(rbot0) + (m-s2p)) * SIZE_2(rbot0) + (l-s2o)) * SIZE_3(rbot0) + n;
+ float bot0tmp = rbot0[idxbot0]; // rbot1[l+s2o,m+s2p,n]
+
+ // Index offset for gradOutput in following loops:
+ int op = (p+4) * 9 + (o+4); // index[o,p]
+ int idxopoffset = (intSample * SIZE_1(gradOutput) + op);
+
+ for (int y = ymin; y <= ymax; y++) {
+ for (int x = xmin; x <= xmax; x++) {
+ int idxgradOutput = (idxopoffset * SIZE_2(gradOutput) + y) * SIZE_3(gradOutput) + x; // gradOutput[x,y,o,p]
+ sum += gradOutput[idxgradOutput] * bot0tmp;
+ }
+ }
+ }
+ }
+ }
+ const int sumelems = SIZE_1(gradTwo);
+ const int bot1index = ((n * SIZE_2(gradTwo)) + (m-4)) * SIZE_3(gradTwo) + (l-4);
+ gradTwo[bot1index + intSample*SIZE_1(gradTwo)*SIZE_2(gradTwo)*SIZE_3(gradTwo)] = sum / (float)sumelems;
+ } }
+'''
+
+def cupy_kernel(strFunction, objVariables):
+ strKernel = globals()[strFunction]
+
+ while True:
+ objMatch = re.search('(SIZE_)([0-4])(\()([^\)]*)(\))', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intArg = int(objMatch.group(2))
+
+ strTensor = objMatch.group(4)
+ intSizes = objVariables[strTensor].size()
+
+ strKernel = strKernel.replace(objMatch.group(), str(intSizes[intArg] if torch.is_tensor(intSizes[intArg]) == False else intSizes[intArg].item()))
+
+ while True:
+ objMatch = re.search('(VALUE_)([0-4])(\()([^\)]+)(\))', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intArgs = int(objMatch.group(2))
+ strArgs = objMatch.group(4).split(',')
+
+ strTensor = strArgs[0]
+ intStrides = objVariables[strTensor].stride()
+ strIndex = [ '((' + strArgs[intArg + 1].replace('{', '(').replace('}', ')').strip() + ')*' + str(intStrides[intArg] if torch.is_tensor(intStrides[intArg]) == False else intStrides[intArg].item()) + ')' for intArg in range(intArgs) ]
+
+ strKernel = strKernel.replace(objMatch.group(0), strTensor + '[' + str.join('+', strIndex) + ']')
+ # end
+
+ return strKernel
+# end
+
+@cupy.memoize(for_each_device=True)
+def cupy_launch(strFunction, strKernel):
+ return cupy.cuda.compile_with_cache(strKernel).get_function(strFunction)
+# end
+
+class _FunctionCorrelation(torch.autograd.Function):
+ @staticmethod
+ def forward(self, one, two):
+ rbot0 = one.new_zeros([ one.shape[0], one.shape[2] + 8, one.shape[3] + 8, one.shape[1] ])
+ rbot1 = one.new_zeros([ one.shape[0], one.shape[2] + 8, one.shape[3] + 8, one.shape[1] ])
+
+ one = one.contiguous(); assert(one.is_cuda == True)
+ two = two.contiguous(); assert(two.is_cuda == True)
+
+ output = one.new_zeros([ one.shape[0], 81, one.shape[2], one.shape[3] ])
+
+ if one.is_cuda == True:
+ n = one.shape[2] * one.shape[3]
+ cupy_launch('kernel_Correlation_rearrange', cupy_kernel('kernel_Correlation_rearrange', {
+ 'input': one,
+ 'output': rbot0
+ }))(
+ grid=tuple([ int((n + 16 - 1) / 16), one.shape[1], one.shape[0] ]),
+ block=tuple([ 16, 1, 1 ]),
+ args=[ cupy.int32(n), one.data_ptr(), rbot0.data_ptr() ]
+ )
+
+ n = two.shape[2] * two.shape[3]
+ cupy_launch('kernel_Correlation_rearrange', cupy_kernel('kernel_Correlation_rearrange', {
+ 'input': two,
+ 'output': rbot1
+ }))(
+ grid=tuple([ int((n + 16 - 1) / 16), two.shape[1], two.shape[0] ]),
+ block=tuple([ 16, 1, 1 ]),
+ args=[ cupy.int32(n), two.data_ptr(), rbot1.data_ptr() ]
+ )
+
+ n = output.shape[1] * output.shape[2] * output.shape[3]
+ cupy_launch('kernel_Correlation_updateOutput', cupy_kernel('kernel_Correlation_updateOutput', {
+ 'rbot0': rbot0,
+ 'rbot1': rbot1,
+ 'top': output
+ }))(
+ grid=tuple([ output.shape[3], output.shape[2], output.shape[0] ]),
+ block=tuple([ 32, 1, 1 ]),
+ shared_mem=one.shape[1] * 4,
+ args=[ cupy.int32(n), rbot0.data_ptr(), rbot1.data_ptr(), output.data_ptr() ]
+ )
+
+ elif one.is_cuda == False:
+ raise NotImplementedError()
+
+ # end
+
+ self.save_for_backward(one, two, rbot0, rbot1)
+
+ return output
+ # end
+
+ @staticmethod
+ def backward(self, gradOutput):
+ one, two, rbot0, rbot1 = self.saved_tensors
+
+ gradOutput = gradOutput.contiguous(); assert(gradOutput.is_cuda == True)
+
+ gradOne = one.new_zeros([ one.shape[0], one.shape[1], one.shape[2], one.shape[3] ]) if self.needs_input_grad[0] == True else None
+ gradTwo = one.new_zeros([ one.shape[0], one.shape[1], one.shape[2], one.shape[3] ]) if self.needs_input_grad[1] == True else None
+
+ if one.is_cuda == True:
+ if gradOne is not None:
+ for intSample in range(one.shape[0]):
+ n = one.shape[1] * one.shape[2] * one.shape[3]
+ cupy_launch('kernel_Correlation_updateGradOne', cupy_kernel('kernel_Correlation_updateGradOne', {
+ 'rbot0': rbot0,
+ 'rbot1': rbot1,
+ 'gradOutput': gradOutput,
+ 'gradOne': gradOne,
+ 'gradTwo': None
+ }))(
+ grid=tuple([ int((n + 512 - 1) / 512), 1, 1 ]),
+ block=tuple([ 512, 1, 1 ]),
+ args=[ cupy.int32(n), intSample, rbot0.data_ptr(), rbot1.data_ptr(), gradOutput.data_ptr(), gradOne.data_ptr(), None ]
+ )
+ # end
+ # end
+
+ if gradTwo is not None:
+ for intSample in range(one.shape[0]):
+ n = one.shape[1] * one.shape[2] * one.shape[3]
+ cupy_launch('kernel_Correlation_updateGradTwo', cupy_kernel('kernel_Correlation_updateGradTwo', {
+ 'rbot0': rbot0,
+ 'rbot1': rbot1,
+ 'gradOutput': gradOutput,
+ 'gradOne': None,
+ 'gradTwo': gradTwo
+ }))(
+ grid=tuple([ int((n + 512 - 1) / 512), 1, 1 ]),
+ block=tuple([ 512, 1, 1 ]),
+ args=[ cupy.int32(n), intSample, rbot0.data_ptr(), rbot1.data_ptr(), gradOutput.data_ptr(), None, gradTwo.data_ptr() ]
+ )
+ # end
+ # end
+
+ elif one.is_cuda == False:
+ raise NotImplementedError()
+
+ # end
+
+ return gradOne, gradTwo
+ # end
+# end
+
+def FunctionCorrelation(tenOne, tenTwo):
+ return _FunctionCorrelation.apply(tenOne, tenTwo)
+# end
+
+class ModuleCorrelation(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ # end
+
+ def forward(self, tenOne, tenTwo):
+ return _FunctionCorrelation.apply(tenOne, tenTwo)
+ # end
+# end
diff --git a/animate/src/animatediff/softmax_splatting/run.py b/animate/src/animatediff/softmax_splatting/run.py
new file mode 100644
index 0000000000000000000000000000000000000000..22313f889dabafb31c675f199029713332751952
--- /dev/null
+++ b/animate/src/animatediff/softmax_splatting/run.py
@@ -0,0 +1,871 @@
+#!/usr/bin/env python
+
+import getopt
+import math
+import sys
+import typing
+
+import numpy
+import PIL
+import PIL.Image
+import torch
+
+from . import softsplat # the custom softmax splatting layer
+
+try:
+ from .correlation import correlation # the custom cost volume layer
+except:
+ sys.path.insert(0, './correlation'); import correlation # you should consider upgrading python
+# end
+
+##########################################################
+
+torch.set_grad_enabled(False) # make sure to not compute gradients for computational performance
+
+torch.backends.cudnn.enabled = True # make sure to use cudnn for computational performance
+
+##########################################################
+
+arguments_strModel = 'lf'
+arguments_strOne = './images/one.png'
+arguments_strTwo = './images/two.png'
+arguments_strVideo = './videos/car-turn.mp4'
+arguments_strOut = './out.png'
+arguments_strVideo2 = ''
+
+for strOption, strArgument in getopt.getopt(sys.argv[1:], '', [strParameter[2:] + '=' for strParameter in sys.argv[1::2]])[0]:
+ if strOption == '--model' and strArgument != '': arguments_strModel = strArgument # which model to use
+ if strOption == '--one' and strArgument != '': arguments_strOne = strArgument # path to the first frame
+ if strOption == '--two' and strArgument != '': arguments_strTwo = strArgument # path to the second frame
+ if strOption == '--video' and strArgument != '': arguments_strVideo = strArgument # path to a video
+ if strOption == '--video2' and strArgument != '': arguments_strVideo2 = strArgument # path to a video
+ if strOption == '--out' and strArgument != '': arguments_strOut = strArgument # path to where the output should be stored
+# end
+
+##########################################################
+
+def read_flo(strFile):
+ with open(strFile, 'rb') as objFile:
+ strFlow = objFile.read()
+ # end
+
+ assert(numpy.frombuffer(buffer=strFlow, dtype=numpy.float32, count=1, offset=0) == 202021.25)
+
+ intWidth = numpy.frombuffer(buffer=strFlow, dtype=numpy.int32, count=1, offset=4)[0]
+ intHeight = numpy.frombuffer(buffer=strFlow, dtype=numpy.int32, count=1, offset=8)[0]
+
+ return numpy.frombuffer(buffer=strFlow, dtype=numpy.float32, count=intHeight * intWidth * 2, offset=12).reshape(intHeight, intWidth, 2)
+# end
+
+##########################################################
+
+backwarp_tenGrid = {}
+
+def backwarp(tenIn, tenFlow):
+ if str(tenFlow.shape) not in backwarp_tenGrid:
+ tenHor = torch.linspace(start=-1.0, end=1.0, steps=tenFlow.shape[3], dtype=tenFlow.dtype, device=tenFlow.device).view(1, 1, 1, -1).repeat(1, 1, tenFlow.shape[2], 1)
+ tenVer = torch.linspace(start=-1.0, end=1.0, steps=tenFlow.shape[2], dtype=tenFlow.dtype, device=tenFlow.device).view(1, 1, -1, 1).repeat(1, 1, 1, tenFlow.shape[3])
+
+ backwarp_tenGrid[str(tenFlow.shape)] = torch.cat([tenHor, tenVer], 1).cuda()
+ # end
+
+ tenFlow = torch.cat([tenFlow[:, 0:1, :, :] / ((tenIn.shape[3] - 1.0) / 2.0), tenFlow[:, 1:2, :, :] / ((tenIn.shape[2] - 1.0) / 2.0)], 1)
+
+ return torch.nn.functional.grid_sample(input=tenIn, grid=(backwarp_tenGrid[str(tenFlow.shape)] + tenFlow).permute(0, 2, 3, 1), mode='bilinear', padding_mode='zeros', align_corners=True)
+# end
+
+##########################################################
+
+class Flow(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ class Extractor(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netFirst = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=16, out_channels=16, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netSecond = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netThird = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netFourth = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=64, out_channels=96, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=96, out_channels=96, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netFifth = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=96, out_channels=128, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netSixth = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=128, out_channels=192, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=192, out_channels=192, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+ # end
+
+ def forward(self, tenInput):
+ tenFirst = self.netFirst(tenInput)
+ tenSecond = self.netSecond(tenFirst)
+ tenThird = self.netThird(tenSecond)
+ tenFourth = self.netFourth(tenThird)
+ tenFifth = self.netFifth(tenFourth)
+ tenSixth = self.netSixth(tenFifth)
+
+ return [tenFirst, tenSecond, tenThird, tenFourth, tenFifth, tenSixth]
+ # end
+ # end
+
+ class Decoder(torch.nn.Module):
+ def __init__(self, intChannels):
+ super().__init__()
+
+ self.netMain = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=intChannels, out_channels=128, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=128, out_channels=96, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=96, out_channels=64, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=64, out_channels=32, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=32, out_channels=2, kernel_size=3, stride=1, padding=1)
+ )
+ # end
+
+ def forward(self, tenOne, tenTwo, objPrevious):
+ intWidth = tenOne.shape[3] and tenTwo.shape[3]
+ intHeight = tenOne.shape[2] and tenTwo.shape[2]
+
+ tenMain = None
+
+ if objPrevious is None:
+ tenVolume = correlation.FunctionCorrelation(tenOne=tenOne, tenTwo=tenTwo)
+
+ tenMain = torch.cat([tenOne, tenVolume], 1)
+
+ elif objPrevious is not None:
+ tenForward = torch.nn.functional.interpolate(input=objPrevious['tenForward'], size=(intHeight, intWidth), mode='bilinear', align_corners=False) / float(objPrevious['tenForward'].shape[3]) * float(intWidth)
+
+ tenVolume = correlation.FunctionCorrelation(tenOne=tenOne, tenTwo=backwarp(tenTwo, tenForward))
+
+ tenMain = torch.cat([tenOne, tenVolume, tenForward], 1)
+
+ # end
+
+ return {
+ 'tenForward': self.netMain(tenMain)
+ }
+ # end
+ # end
+
+ self.netExtractor = Extractor()
+
+ self.netFirst = Decoder(16 + 81 + 2)
+ self.netSecond = Decoder(32 + 81 + 2)
+ self.netThird = Decoder(64 + 81 + 2)
+ self.netFourth = Decoder(96 + 81 + 2)
+ self.netFifth = Decoder(128 + 81 + 2)
+ self.netSixth = Decoder(192 + 81)
+ # end
+
+ def forward(self, tenOne, tenTwo):
+ intWidth = tenOne.shape[3] and tenTwo.shape[3]
+ intHeight = tenOne.shape[2] and tenTwo.shape[2]
+
+ tenOne = self.netExtractor(tenOne)
+ tenTwo = self.netExtractor(tenTwo)
+
+ objForward = None
+ objBackward = None
+
+ objForward = self.netSixth(tenOne[-1], tenTwo[-1], objForward)
+ objBackward = self.netSixth(tenTwo[-1], tenOne[-1], objBackward)
+
+ objForward = self.netFifth(tenOne[-2], tenTwo[-2], objForward)
+ objBackward = self.netFifth(tenTwo[-2], tenOne[-2], objBackward)
+
+ objForward = self.netFourth(tenOne[-3], tenTwo[-3], objForward)
+ objBackward = self.netFourth(tenTwo[-3], tenOne[-3], objBackward)
+
+ objForward = self.netThird(tenOne[-4], tenTwo[-4], objForward)
+ objBackward = self.netThird(tenTwo[-4], tenOne[-4], objBackward)
+
+ objForward = self.netSecond(tenOne[-5], tenTwo[-5], objForward)
+ objBackward = self.netSecond(tenTwo[-5], tenOne[-5], objBackward)
+
+ objForward = self.netFirst(tenOne[-6], tenTwo[-6], objForward)
+ objBackward = self.netFirst(tenTwo[-6], tenOne[-6], objBackward)
+
+ return {
+ 'tenForward': torch.nn.functional.interpolate(input=objForward['tenForward'], size=(intHeight, intWidth), mode='bilinear', align_corners=False) * (float(intWidth) / float(objForward['tenForward'].shape[3])),
+ 'tenBackward': torch.nn.functional.interpolate(input=objBackward['tenForward'], size=(intHeight, intWidth), mode='bilinear', align_corners=False) * (float(intWidth) / float(objBackward['tenForward'].shape[3]))
+ }
+ # end
+# end
+
+##########################################################
+
+class Synthesis(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ class Basic(torch.nn.Module):
+ def __init__(self, strType, intChannels, boolSkip):
+ super().__init__()
+
+ if strType == 'relu-conv-relu-conv':
+ self.netMain = torch.nn.Sequential(
+ torch.nn.PReLU(num_parameters=intChannels[0], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[1], kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=intChannels[1], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[1], out_channels=intChannels[2], kernel_size=3, stride=1, padding=1, bias=False)
+ )
+
+ elif strType == 'conv-relu-conv':
+ self.netMain = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[1], kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=intChannels[1], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[1], out_channels=intChannels[2], kernel_size=3, stride=1, padding=1, bias=False)
+ )
+
+ # end
+
+ self.boolSkip = boolSkip
+
+ if boolSkip == True:
+ if intChannels[0] == intChannels[2]:
+ self.netShortcut = None
+
+ elif intChannels[0] != intChannels[2]:
+ self.netShortcut = torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[2], kernel_size=1, stride=1, padding=0, bias=False)
+
+ # end
+ # end
+ # end
+
+ def forward(self, tenInput):
+ if self.boolSkip == False:
+ return self.netMain(tenInput)
+ # end
+
+ if self.netShortcut is None:
+ return self.netMain(tenInput) + tenInput
+
+ elif self.netShortcut is not None:
+ return self.netMain(tenInput) + self.netShortcut(tenInput)
+
+ # end
+ # end
+ # end
+
+ class Downsample(torch.nn.Module):
+ def __init__(self, intChannels):
+ super().__init__()
+
+ self.netMain = torch.nn.Sequential(
+ torch.nn.PReLU(num_parameters=intChannels[0], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[1], kernel_size=3, stride=2, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=intChannels[1], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[1], out_channels=intChannels[2], kernel_size=3, stride=1, padding=1, bias=False)
+ )
+ # end
+
+ def forward(self, tenInput):
+ return self.netMain(tenInput)
+ # end
+ # end
+
+ class Upsample(torch.nn.Module):
+ def __init__(self, intChannels):
+ super().__init__()
+
+ self.netMain = torch.nn.Sequential(
+ torch.nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False),
+ torch.nn.PReLU(num_parameters=intChannels[0], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[1], kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=intChannels[1], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[1], out_channels=intChannels[2], kernel_size=3, stride=1, padding=1, bias=False)
+ )
+ # end
+
+ def forward(self, tenInput):
+ return self.netMain(tenInput)
+ # end
+ # end
+
+ class Encode(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netOne = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=32, init=0.25),
+ torch.nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=32, init=0.25)
+ )
+
+ self.netTwo = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=64, init=0.25),
+ torch.nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=64, init=0.25)
+ )
+
+ self.netThr = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=64, out_channels=96, kernel_size=3, stride=2, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=96, init=0.25),
+ torch.nn.Conv2d(in_channels=96, out_channels=96, kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=96, init=0.25)
+ )
+ # end
+
+ def forward(self, tenInput):
+ tenOutput = []
+
+ tenOutput.append(self.netOne(tenInput))
+ tenOutput.append(self.netTwo(tenOutput[-1]))
+ tenOutput.append(self.netThr(tenOutput[-1]))
+
+ return [torch.cat([tenInput, tenOutput[0]], 1)] + tenOutput[1:]
+ # end
+ # end
+
+ class Softmetric(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netInput = torch.nn.Conv2d(in_channels=3, out_channels=12, kernel_size=3, stride=1, padding=1, bias=False)
+ self.netError = torch.nn.Conv2d(in_channels=1, out_channels=4, kernel_size=3, stride=1, padding=1, bias=False)
+
+ for intRow, intFeatures in [(0, 16), (1, 32), (2, 64), (3, 96)]:
+ self.add_module(str(intRow) + 'x0' + ' - ' + str(intRow) + 'x1', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ # end
+
+ for intCol in [0]:
+ self.add_module('0x' + str(intCol) + ' - ' + '1x' + str(intCol), Downsample([16, 32, 32]))
+ self.add_module('1x' + str(intCol) + ' - ' + '2x' + str(intCol), Downsample([32, 64, 64]))
+ self.add_module('2x' + str(intCol) + ' - ' + '3x' + str(intCol), Downsample([64, 96, 96]))
+ # end
+
+ for intCol in [1]:
+ self.add_module('3x' + str(intCol) + ' - ' + '2x' + str(intCol), Upsample([96, 64, 64]))
+ self.add_module('2x' + str(intCol) + ' - ' + '1x' + str(intCol), Upsample([64, 32, 32]))
+ self.add_module('1x' + str(intCol) + ' - ' + '0x' + str(intCol), Upsample([32, 16, 16]))
+ # end
+
+ self.netOutput = Basic('conv-relu-conv', [16, 16, 1], True)
+ # end
+
+ def forward(self, tenEncone, tenEnctwo, tenFlow):
+ tenColumn = [None, None, None, None]
+
+ tenColumn[0] = torch.cat([self.netInput(tenEncone[0][:, 0:3, :, :]), self.netError(torch.nn.functional.l1_loss(input=tenEncone[0], target=backwarp(tenEnctwo[0], tenFlow), reduction='none').mean([1], True))], 1)
+ tenColumn[1] = self._modules['0x0 - 1x0'](tenColumn[0])
+ tenColumn[2] = self._modules['1x0 - 2x0'](tenColumn[1])
+ tenColumn[3] = self._modules['2x0 - 3x0'](tenColumn[2])
+
+ intColumn = 1
+ for intRow in range(len(tenColumn) -1, -1, -1):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != len(tenColumn) - 1:
+ tenUp = self._modules[str(intRow + 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow + 1])
+
+ if tenUp.shape[2] != tenColumn[intRow].shape[2]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, 0, 0, -1], mode='constant', value=0.0)
+ if tenUp.shape[3] != tenColumn[intRow].shape[3]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, -1, 0, 0], mode='constant', value=0.0)
+
+ tenColumn[intRow] = tenColumn[intRow] + tenUp
+ # end
+ # end
+
+ return self.netOutput(tenColumn[0])
+ # end
+ # end
+
+ class Warp(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netOne = Basic('conv-relu-conv', [3 + 3 + 32 + 32 + 1 + 1, 32, 32], True)
+ self.netTwo = Basic('conv-relu-conv', [0 + 0 + 64 + 64 + 1 + 1, 64, 64], True)
+ self.netThr = Basic('conv-relu-conv', [0 + 0 + 96 + 96 + 1 + 1, 96, 96], True)
+ # end
+
+ def forward(self, tenEncone, tenEnctwo, tenMetricone, tenMetrictwo, tenForward, tenBackward):
+ tenOutput = []
+
+ for intLevel in range(3):
+ if intLevel != 0:
+ tenMetricone = torch.nn.functional.interpolate(input=tenMetricone, size=(tenEncone[intLevel].shape[2], tenEncone[intLevel].shape[3]), mode='bilinear', align_corners=False)
+ tenMetrictwo = torch.nn.functional.interpolate(input=tenMetrictwo, size=(tenEnctwo[intLevel].shape[2], tenEnctwo[intLevel].shape[3]), mode='bilinear', align_corners=False)
+
+ tenForward = torch.nn.functional.interpolate(input=tenForward, size=(tenEncone[intLevel].shape[2], tenEncone[intLevel].shape[3]), mode='bilinear', align_corners=False) * (float(tenEncone[intLevel].shape[3]) / float(tenForward.shape[3]))
+ tenBackward = torch.nn.functional.interpolate(input=tenBackward, size=(tenEnctwo[intLevel].shape[2], tenEnctwo[intLevel].shape[3]), mode='bilinear', align_corners=False) * (float(tenEnctwo[intLevel].shape[3]) / float(tenBackward.shape[3]))
+ # end
+
+ tenOutput.append([self.netOne, self.netTwo, self.netThr][intLevel](torch.cat([
+ softsplat.softsplat(tenIn=torch.cat([tenEncone[intLevel], tenMetricone], 1), tenFlow=tenForward, tenMetric=tenMetricone.neg().clip(-20.0, 20.0), strMode='soft'),
+ softsplat.softsplat(tenIn=torch.cat([tenEnctwo[intLevel], tenMetrictwo], 1), tenFlow=tenBackward, tenMetric=tenMetrictwo.neg().clip(-20.0, 20.0), strMode='soft')
+ ], 1)))
+ # end
+
+ return tenOutput
+ # end
+ # end
+
+ self.netEncode = Encode()
+
+ self.netSoftmetric = Softmetric()
+
+ self.netWarp = Warp()
+
+ for intRow, intFeatures in [(0, 32), (1, 64), (2, 96)]:
+ self.add_module(str(intRow) + 'x0' + ' - ' + str(intRow) + 'x1', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ self.add_module(str(intRow) + 'x1' + ' - ' + str(intRow) + 'x2', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ self.add_module(str(intRow) + 'x2' + ' - ' + str(intRow) + 'x3', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ self.add_module(str(intRow) + 'x3' + ' - ' + str(intRow) + 'x4', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ self.add_module(str(intRow) + 'x4' + ' - ' + str(intRow) + 'x5', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ # end
+
+ for intCol in [0, 1, 2]:
+ self.add_module('0x' + str(intCol) + ' - ' + '1x' + str(intCol), Downsample([32, 64, 64]))
+ self.add_module('1x' + str(intCol) + ' - ' + '2x' + str(intCol), Downsample([64, 96, 96]))
+ # end
+
+ for intCol in [3, 4, 5]:
+ self.add_module('2x' + str(intCol) + ' - ' + '1x' + str(intCol), Upsample([96, 64, 64]))
+ self.add_module('1x' + str(intCol) + ' - ' + '0x' + str(intCol), Upsample([64, 32, 32]))
+ # end
+
+ self.netOutput = Basic('conv-relu-conv', [32, 32, 3], True)
+ # end
+
+ def forward(self, tenOne, tenTwo, tenForward, tenBackward, fltTime):
+ tenEncone = self.netEncode(tenOne)
+ tenEnctwo = self.netEncode(tenTwo)
+
+ tenMetricone = self.netSoftmetric(tenEncone, tenEnctwo, tenForward) * 2.0 * fltTime
+ tenMetrictwo = self.netSoftmetric(tenEnctwo, tenEncone, tenBackward) * 2.0 * (1.0 - fltTime)
+
+ tenForward = tenForward * fltTime
+ tenBackward = tenBackward * (1.0 - fltTime)
+
+ tenWarp = self.netWarp(tenEncone, tenEnctwo, tenMetricone, tenMetrictwo, tenForward, tenBackward)
+
+ tenColumn = [None, None, None]
+
+ tenColumn[0] = tenWarp[0]
+ tenColumn[1] = tenWarp[1] + self._modules['0x0 - 1x0'](tenColumn[0])
+ tenColumn[2] = tenWarp[2] + self._modules['1x0 - 2x0'](tenColumn[1])
+
+ intColumn = 1
+ for intRow in range(len(tenColumn)):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != 0:
+ tenColumn[intRow] = tenColumn[intRow] + self._modules[str(intRow - 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow - 1])
+ # end
+ # end
+
+ intColumn = 2
+ for intRow in range(len(tenColumn)):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != 0:
+ tenColumn[intRow] = tenColumn[intRow] + self._modules[str(intRow - 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow - 1])
+ # end
+ # end
+
+ intColumn = 3
+ for intRow in range(len(tenColumn) -1, -1, -1):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != len(tenColumn) - 1:
+ tenUp = self._modules[str(intRow + 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow + 1])
+
+ if tenUp.shape[2] != tenColumn[intRow].shape[2]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, 0, 0, -1], mode='constant', value=0.0)
+ if tenUp.shape[3] != tenColumn[intRow].shape[3]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, -1, 0, 0], mode='constant', value=0.0)
+
+ tenColumn[intRow] = tenColumn[intRow] + tenUp
+ # end
+ # end
+
+ intColumn = 4
+ for intRow in range(len(tenColumn) -1, -1, -1):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != len(tenColumn) - 1:
+ tenUp = self._modules[str(intRow + 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow + 1])
+
+ if tenUp.shape[2] != tenColumn[intRow].shape[2]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, 0, 0, -1], mode='constant', value=0.0)
+ if tenUp.shape[3] != tenColumn[intRow].shape[3]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, -1, 0, 0], mode='constant', value=0.0)
+
+ tenColumn[intRow] = tenColumn[intRow] + tenUp
+ # end
+ # end
+
+ intColumn = 5
+ for intRow in range(len(tenColumn) -1, -1, -1):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != len(tenColumn) - 1:
+ tenUp = self._modules[str(intRow + 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow + 1])
+
+ if tenUp.shape[2] != tenColumn[intRow].shape[2]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, 0, 0, -1], mode='constant', value=0.0)
+ if tenUp.shape[3] != tenColumn[intRow].shape[3]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, -1, 0, 0], mode='constant', value=0.0)
+
+ tenColumn[intRow] = tenColumn[intRow] + tenUp
+ # end
+ # end
+
+ return self.netOutput(tenColumn[0])
+ # end
+# end
+
+##########################################################
+
+class Network(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netFlow = Flow()
+
+ self.netSynthesis = Synthesis()
+
+ self.load_state_dict({strKey.replace('module', 'net'): tenWeight for strKey, tenWeight in torch.hub.load_state_dict_from_url(url='http://content.sniklaus.com/softsplat/network-' + arguments_strModel + '.pytorch', file_name='softsplat-' + arguments_strModel).items()})
+ # end
+
+ def forward(self, tenOne, tenTwo, fltTimes):
+ with torch.set_grad_enabled(False):
+ tenStats = [tenOne, tenTwo]
+ tenMean = sum([tenIn.mean([1, 2, 3], True) for tenIn in tenStats]) / len(tenStats)
+ tenStd = (sum([tenIn.std([1, 2, 3], False, True).square() + (tenMean - tenIn.mean([1, 2, 3], True)).square() for tenIn in tenStats]) / len(tenStats)).sqrt()
+ tenOne = ((tenOne - tenMean) / (tenStd + 0.0000001)).detach()
+ tenTwo = ((tenTwo - tenMean) / (tenStd + 0.0000001)).detach()
+ # end
+
+ objFlow = self.netFlow(tenOne, tenTwo)
+
+ tenImages = [self.netSynthesis(tenOne, tenTwo, objFlow['tenForward'], objFlow['tenBackward'], fltTime) for fltTime in fltTimes]
+
+ return [(tenImage * tenStd) + tenMean for tenImage in tenImages]
+ # end
+# end
+
+netNetwork = None
+
+##########################################################
+
+def estimate(tenOne, tenTwo, fltTimes):
+ global netNetwork
+
+ if netNetwork is None:
+ netNetwork = Network().cuda().eval()
+ # end
+
+ assert(tenOne.shape[1] == tenTwo.shape[1])
+ assert(tenOne.shape[2] == tenTwo.shape[2])
+
+ intWidth = tenOne.shape[2]
+ intHeight = tenOne.shape[1]
+
+ tenPreprocessedOne = tenOne.cuda().view(1, 3, intHeight, intWidth)
+ tenPreprocessedTwo = tenTwo.cuda().view(1, 3, intHeight, intWidth)
+
+ intPadr = (2 - (intWidth % 2)) % 2
+ intPadb = (2 - (intHeight % 2)) % 2
+
+ tenPreprocessedOne = torch.nn.functional.pad(input=tenPreprocessedOne, pad=[0, intPadr, 0, intPadb], mode='replicate')
+ tenPreprocessedTwo = torch.nn.functional.pad(input=tenPreprocessedTwo, pad=[0, intPadr, 0, intPadb], mode='replicate')
+
+ return [tenImage[0, :, :intHeight, :intWidth].cpu() for tenImage in netNetwork(tenPreprocessedOne, tenPreprocessedTwo, fltTimes)]
+# end
+##########################################################
+import logging
+
+logger = logging.getLogger(__name__)
+
+raft = None
+
+class Raft:
+ def __init__(self):
+ from torchvision.models.optical_flow import (Raft_Large_Weights,
+ raft_large)
+
+ weights = Raft_Large_Weights.DEFAULT
+ self.device = "cuda" if torch.cuda.is_available() else "cpu"
+ model = raft_large(weights=weights, progress=False).to(self.device)
+ self.model = model.eval()
+
+ def __call__(self,img1,img2):
+ with torch.no_grad():
+ img1 = img1.to(self.device)
+ img2 = img2.to(self.device)
+ i1 = torch.vstack([img1,img2])
+ i2 = torch.vstack([img2,img1])
+ list_of_flows = self.model(i1, i2)
+
+ predicted_flows = list_of_flows[-1]
+ return { 'tenForward' : predicted_flows[0].unsqueeze(dim=0) , 'tenBackward' : predicted_flows[1].unsqueeze(dim=0) }
+
+img_count = 0
+def debug_save_img(img, comment, inc=False):
+ return
+ global img_count
+ from torchvision.utils import save_image
+
+ save_image(img, f"debug0/{img_count:04d}_{comment}.png")
+
+ if inc:
+ img_count += 1
+
+
+class Network2(torch.nn.Module):
+ def __init__(self, model_file_path):
+ super().__init__()
+
+ self.netFlow = Flow()
+
+ self.netSynthesis = Synthesis()
+
+ d = torch.load(model_file_path)
+
+ d = {strKey.replace('module', 'net'): tenWeight for strKey, tenWeight in d.items()}
+
+ self.load_state_dict(d)
+ # end
+
+ def forward(self, tenOne, tenTwo, guideFrameList):
+ global raft
+
+ do_composite = True
+ use_raft = True
+
+ if use_raft:
+ if raft is None:
+ raft = Raft()
+
+
+ with torch.set_grad_enabled(False):
+ tenStats = [tenOne, tenTwo]
+ tenMean = sum([tenIn.mean([1, 2, 3], True) for tenIn in tenStats]) / len(tenStats)
+ tenStd = (sum([tenIn.std([1, 2, 3], False, True).square() + (tenMean - tenIn.mean([1, 2, 3], True)).square() for tenIn in tenStats]) / len(tenStats)).sqrt()
+ tenOne = ((tenOne - tenMean) / (tenStd + 0.0000001)).detach()
+ tenTwo = ((tenTwo - tenMean) / (tenStd + 0.0000001)).detach()
+
+ gtenStats = guideFrameList
+ gtenMean = sum([tenIn.mean([1, 2, 3], True) for tenIn in gtenStats]) / len(gtenStats)
+ gtenStd = (sum([tenIn.std([1, 2, 3], False, True).square() + (gtenMean - tenIn.mean([1, 2, 3], True)).square() for tenIn in gtenStats]) / len(gtenStats)).sqrt()
+ guideFrameList = [((g - gtenMean) / (gtenStd + 0.0000001)).detach() for g in guideFrameList]
+
+ # end
+
+ tenImages =[]
+ l = len(guideFrameList)
+ i = 1
+ g1 = guideFrameList.pop(0)
+
+ if use_raft:
+ styleFlow = raft(tenOne, tenTwo)
+ else:
+ styleFlow = self.netFlow(tenOne, tenTwo)
+
+ def composite1(fA, fB, nA, nB):
+ # 1,2,768,512
+ A = fA[:,0,:,:]
+ B = fA[:,1,:,:]
+ Z = nA
+
+ UA = A / Z
+ UB = B / Z
+
+ A2 = fB[:,0,:,:]
+ B2 = fB[:,1,:,:]
+ Z2 = nB
+ fB[:,0,:,:] = Z2 * UA
+ fB[:,1,:,:] = Z2 * UB
+ return fB
+
+ def mask_dilate(ten, kernel_size=3):
+ ten = ten.to(torch.float32)
+ k=torch.ones(1, 1, kernel_size, kernel_size, dtype=torch.float32).cuda()
+ ten = torch.nn.functional.conv2d(ten, k, padding=(kernel_size//2, kernel_size// 2))
+ result = torch.clamp(ten, 0, 1)
+ return result.to(torch.bool)
+
+ def composite2(fA, fB, nA, nB):
+ Z = nA
+ Z2 = nB
+
+ mean2 = torch.mean(Z2)
+ max2 = torch.max(Z2)
+ mask2 = (Z2 > (mean2+max2)/2)
+ debug_save_img(mask2.to(torch.float), "mask2_0")
+ mask2 = mask_dilate(mask2, 9)
+ debug_save_img(mask2.to(torch.float), "mask2_1")
+ mask2 = ~mask2
+
+ debug_save_img(mask2.to(torch.float), "mask2")
+
+ mean1 = torch.mean(Z)
+ max1 = torch.max(Z)
+ mask1 = (Z > (mean1+max1)/2)
+
+ debug_save_img(mask1.to(torch.float), "mask1")
+
+ mask = mask1 & mask2
+ mask = mask.squeeze()
+
+ debug_save_img(mask.to(torch.float), "cmask", True)
+
+ fB[:,:,mask] = fA[:,:,mask]
+
+ return fB
+
+
+ def composite(fA, fB):
+ A = fA[:,0,:,:]
+ B = fA[:,1,:,:]
+ Z = (A*A + B*B)**0.5
+ A2 = fB[:,0,:,:]
+ B2 = fB[:,1,:,:]
+ Z2 = (A2*A2 + B2*B2)**0.5
+
+ fB = composite1(fA, fB, Z, Z2)
+ fB = composite2(fA, fB, Z, Z2)
+ return fB
+
+ for g2 in guideFrameList:
+ if use_raft:
+ objFlow = raft(g1, g2)
+ else:
+ objFlow = self.netFlow(g1, g2)
+
+
+ objFlow['tenForward'] = objFlow['tenForward'] * (l/i)
+ objFlow['tenBackward'] = objFlow['tenBackward'] * (l/i)
+
+ if do_composite:
+ objFlow['tenForward'] = composite(objFlow['tenForward'], styleFlow['tenForward'])
+ objFlow['tenBackward'] = composite(objFlow['tenBackward'], styleFlow['tenBackward'])
+
+ img = self.netSynthesis(tenOne, tenTwo, objFlow['tenForward'], objFlow['tenBackward'], i/l)
+ tenImages.append(img)
+ i += 1
+
+ return [(tenImage * tenStd) + tenMean for tenImage in tenImages]
+
+
+# end
+
+netNetwork = None
+
+##########################################################
+
+def estimate2(img1: PIL.Image, img2:PIL.Image, guideFrames, model_file_path):
+ global netNetwork
+
+ if netNetwork is None:
+ netNetwork = Network2(model_file_path).cuda().eval()
+ # end
+
+ def forTensor(im):
+ return torch.FloatTensor(numpy.ascontiguousarray(numpy.array(im)[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+
+ tenOne = forTensor(img1)
+ tenTwo = forTensor(img2)
+
+ tenGuideFrames=[]
+ for g in guideFrames:
+ tenGuideFrames.append(forTensor(g))
+
+ assert(tenOne.shape[1] == tenTwo.shape[1])
+ assert(tenOne.shape[2] == tenTwo.shape[2])
+
+ intWidth = tenOne.shape[2]
+ intHeight = tenOne.shape[1]
+
+ tenPreprocessedOne = tenOne.cuda().view(1, 3, intHeight, intWidth)
+ tenPreprocessedTwo = tenTwo.cuda().view(1, 3, intHeight, intWidth)
+ tenGuideFrames = [ ten.cuda().view(1, 3, intHeight, intWidth) for ten in tenGuideFrames]
+
+ intPadr = (2 - (intWidth % 2)) % 2
+ intPadb = (2 - (intHeight % 2)) % 2
+
+ tenPreprocessedOne = torch.nn.functional.pad(input=tenPreprocessedOne, pad=[0, intPadr, 0, intPadb], mode='replicate')
+ tenPreprocessedTwo = torch.nn.functional.pad(input=tenPreprocessedTwo, pad=[0, intPadr, 0, intPadb], mode='replicate')
+ tenGuideFrames = [ torch.nn.functional.pad(input=ten, pad=[0, intPadr, 0, intPadb], mode='replicate') for ten in tenGuideFrames]
+
+ result = [tenImage[0, :, :intHeight, :intWidth].cpu() for tenImage in netNetwork(tenPreprocessedOne, tenPreprocessedTwo, tenGuideFrames)]
+ result = [ PIL.Image.fromarray((r.clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8)) for r in result]
+
+ return result
+# end
+
+##########################################################
+'''
+if __name__ == '__main__':
+ if arguments_strOut.split('.')[-1] in ['bmp', 'jpg', 'jpeg', 'png']:
+ tenOne = torch.FloatTensor(numpy.ascontiguousarray(numpy.array(PIL.Image.open(arguments_strOne))[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+ tenTwo = torch.FloatTensor(numpy.ascontiguousarray(numpy.array(PIL.Image.open(arguments_strTwo))[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+
+ tenOutput = estimate(tenOne, tenTwo, [0.5])[0]
+
+ PIL.Image.fromarray((tenOutput.clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8)).save(arguments_strOut)
+
+ elif arguments_strOut.split('.')[-1] in ['avi', 'mp4', 'webm', 'wmv']:
+ import moviepy
+ import moviepy.editor
+ import moviepy.video.io.ffmpeg_writer
+
+ objVideoreader = moviepy.editor.VideoFileClip(filename=arguments_strVideo)
+ objVideoreader2 = moviepy.editor.VideoFileClip(filename=arguments_strVideo2)
+
+ from moviepy.video.fx.resize import resize
+ objVideoreader2 = resize(objVideoreader2, (objVideoreader.w, objVideoreader.h))
+
+ intWidth = objVideoreader.w
+ intHeight = objVideoreader.h
+
+ tenFrames = [None, None, None, None]
+
+ with moviepy.video.io.ffmpeg_writer.FFMPEG_VideoWriter(filename=arguments_strOut, size=(intWidth, intHeight), fps=objVideoreader.fps) as objVideowriter:
+ for npyFrame in objVideoreader.iter_frames():
+ tenFrames[3] = torch.FloatTensor(numpy.ascontiguousarray(npyFrame[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+
+ if tenFrames[0] is not None:
+ tenFrames[1:3] = estimate(tenFrames[0], tenFrames[3], [0.333, 0.666])
+
+ objVideowriter.write_frame((tenFrames[0].clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8))
+ objVideowriter.write_frame((tenFrames[1].clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8))
+ objVideowriter.write_frame((tenFrames[2].clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8))
+# objVideowriter.write_frame((tenFrames[3].clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8))
+ # end
+
+ tenFrames[0] = torch.FloatTensor(numpy.ascontiguousarray(npyFrame[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+ # end
+ # end
+
+ # end
+# end
+'''
\ No newline at end of file
diff --git a/animate/src/animatediff/softmax_splatting/softsplat.py b/animate/src/animatediff/softmax_splatting/softsplat.py
new file mode 100644
index 0000000000000000000000000000000000000000..f35ccc21604479940c2c86580c287e73f3dc327d
--- /dev/null
+++ b/animate/src/animatediff/softmax_splatting/softsplat.py
@@ -0,0 +1,529 @@
+#!/usr/bin/env python
+
+import collections
+import cupy
+import os
+import re
+import torch
+import typing
+
+
+##########################################################
+
+
+objCudacache = {}
+
+
+def cuda_int32(intIn:int):
+ return cupy.int32(intIn)
+# end
+
+
+def cuda_float32(fltIn:float):
+ return cupy.float32(fltIn)
+# end
+
+
+def cuda_kernel(strFunction:str, strKernel:str, objVariables:typing.Dict):
+ if 'device' not in objCudacache:
+ objCudacache['device'] = torch.cuda.get_device_name()
+ # end
+
+ strKey = strFunction
+
+ for strVariable in objVariables:
+ objValue = objVariables[strVariable]
+
+ strKey += strVariable
+
+ if objValue is None:
+ continue
+
+ elif type(objValue) == int:
+ strKey += str(objValue)
+
+ elif type(objValue) == float:
+ strKey += str(objValue)
+
+ elif type(objValue) == bool:
+ strKey += str(objValue)
+
+ elif type(objValue) == str:
+ strKey += objValue
+
+ elif type(objValue) == torch.Tensor:
+ strKey += str(objValue.dtype)
+ strKey += str(objValue.shape)
+ strKey += str(objValue.stride())
+
+ elif True:
+ print(strVariable, type(objValue))
+ assert(False)
+
+ # end
+ # end
+
+ strKey += objCudacache['device']
+
+ if strKey not in objCudacache:
+ for strVariable in objVariables:
+ objValue = objVariables[strVariable]
+
+ if objValue is None:
+ continue
+
+ elif type(objValue) == int:
+ strKernel = strKernel.replace('{{' + strVariable + '}}', str(objValue))
+
+ elif type(objValue) == float:
+ strKernel = strKernel.replace('{{' + strVariable + '}}', str(objValue))
+
+ elif type(objValue) == bool:
+ strKernel = strKernel.replace('{{' + strVariable + '}}', str(objValue))
+
+ elif type(objValue) == str:
+ strKernel = strKernel.replace('{{' + strVariable + '}}', objValue)
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.uint8:
+ strKernel = strKernel.replace('{{type}}', 'unsigned char')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.float16:
+ strKernel = strKernel.replace('{{type}}', 'half')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.float32:
+ strKernel = strKernel.replace('{{type}}', 'float')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.float64:
+ strKernel = strKernel.replace('{{type}}', 'double')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.int32:
+ strKernel = strKernel.replace('{{type}}', 'int')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.int64:
+ strKernel = strKernel.replace('{{type}}', 'long')
+
+ elif type(objValue) == torch.Tensor:
+ print(strVariable, objValue.dtype)
+ assert(False)
+
+ elif True:
+ print(strVariable, type(objValue))
+ assert(False)
+
+ # end
+ # end
+
+ while True:
+ objMatch = re.search('(SIZE_)([0-4])(\()([^\)]*)(\))', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intArg = int(objMatch.group(2))
+
+ strTensor = objMatch.group(4)
+ intSizes = objVariables[strTensor].size()
+
+ strKernel = strKernel.replace(objMatch.group(), str(intSizes[intArg] if torch.is_tensor(intSizes[intArg]) == False else intSizes[intArg].item()))
+ # end
+
+ while True:
+ objMatch = re.search('(OFFSET_)([0-4])(\()', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intStart = objMatch.span()[1]
+ intStop = objMatch.span()[1]
+ intParentheses = 1
+
+ while True:
+ intParentheses += 1 if strKernel[intStop] == '(' else 0
+ intParentheses -= 1 if strKernel[intStop] == ')' else 0
+
+ if intParentheses == 0:
+ break
+ # end
+
+ intStop += 1
+ # end
+
+ intArgs = int(objMatch.group(2))
+ strArgs = strKernel[intStart:intStop].split(',')
+
+ assert(intArgs == len(strArgs) - 1)
+
+ strTensor = strArgs[0]
+ intStrides = objVariables[strTensor].stride()
+
+ strIndex = []
+
+ for intArg in range(intArgs):
+ strIndex.append('((' + strArgs[intArg + 1].replace('{', '(').replace('}', ')').strip() + ')*' + str(intStrides[intArg] if torch.is_tensor(intStrides[intArg]) == False else intStrides[intArg].item()) + ')')
+ # end
+
+ strKernel = strKernel.replace('OFFSET_' + str(intArgs) + '(' + strKernel[intStart:intStop] + ')', '(' + str.join('+', strIndex) + ')')
+ # end
+
+ while True:
+ objMatch = re.search('(VALUE_)([0-4])(\()', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intStart = objMatch.span()[1]
+ intStop = objMatch.span()[1]
+ intParentheses = 1
+
+ while True:
+ intParentheses += 1 if strKernel[intStop] == '(' else 0
+ intParentheses -= 1 if strKernel[intStop] == ')' else 0
+
+ if intParentheses == 0:
+ break
+ # end
+
+ intStop += 1
+ # end
+
+ intArgs = int(objMatch.group(2))
+ strArgs = strKernel[intStart:intStop].split(',')
+
+ assert(intArgs == len(strArgs) - 1)
+
+ strTensor = strArgs[0]
+ intStrides = objVariables[strTensor].stride()
+
+ strIndex = []
+
+ for intArg in range(intArgs):
+ strIndex.append('((' + strArgs[intArg + 1].replace('{', '(').replace('}', ')').strip() + ')*' + str(intStrides[intArg] if torch.is_tensor(intStrides[intArg]) == False else intStrides[intArg].item()) + ')')
+ # end
+
+ strKernel = strKernel.replace('VALUE_' + str(intArgs) + '(' + strKernel[intStart:intStop] + ')', strTensor + '[' + str.join('+', strIndex) + ']')
+ # end
+
+ objCudacache[strKey] = {
+ 'strFunction': strFunction,
+ 'strKernel': strKernel
+ }
+ # end
+
+ return strKey
+# end
+
+
+@cupy.memoize(for_each_device=True)
+def cuda_launch(strKey:str):
+ if 'CUDA_HOME' not in os.environ:
+ os.environ['CUDA_HOME'] = cupy.cuda.get_cuda_path()
+ # end
+
+ return cupy.cuda.compile_with_cache(objCudacache[strKey]['strKernel'], tuple(['-I ' + os.environ['CUDA_HOME'], '-I ' + os.environ['CUDA_HOME'] + '/include'])).get_function(objCudacache[strKey]['strFunction'])
+# end
+
+
+##########################################################
+
+
+def softsplat(tenIn:torch.Tensor, tenFlow:torch.Tensor, tenMetric:torch.Tensor, strMode:str):
+ assert(strMode.split('-')[0] in ['sum', 'avg', 'linear', 'soft'])
+
+ if strMode == 'sum': assert(tenMetric is None)
+ if strMode == 'avg': assert(tenMetric is None)
+ if strMode.split('-')[0] == 'linear': assert(tenMetric is not None)
+ if strMode.split('-')[0] == 'soft': assert(tenMetric is not None)
+
+ if strMode == 'avg':
+ tenIn = torch.cat([tenIn, tenIn.new_ones([tenIn.shape[0], 1, tenIn.shape[2], tenIn.shape[3]])], 1)
+
+ elif strMode.split('-')[0] == 'linear':
+ tenIn = torch.cat([tenIn * tenMetric, tenMetric], 1)
+
+ elif strMode.split('-')[0] == 'soft':
+ tenIn = torch.cat([tenIn * tenMetric.exp(), tenMetric.exp()], 1)
+
+ # end
+
+ tenOut = softsplat_func.apply(tenIn, tenFlow)
+
+ if strMode.split('-')[0] in ['avg', 'linear', 'soft']:
+ tenNormalize = tenOut[:, -1:, :, :]
+
+ if len(strMode.split('-')) == 1:
+ tenNormalize = tenNormalize + 0.0000001
+
+ elif strMode.split('-')[1] == 'addeps':
+ tenNormalize = tenNormalize + 0.0000001
+
+ elif strMode.split('-')[1] == 'zeroeps':
+ tenNormalize[tenNormalize == 0.0] = 1.0
+
+ elif strMode.split('-')[1] == 'clipeps':
+ tenNormalize = tenNormalize.clip(0.0000001, None)
+
+ # end
+
+ tenOut = tenOut[:, :-1, :, :] / tenNormalize
+ # end
+
+ return tenOut
+# end
+
+
+class softsplat_func(torch.autograd.Function):
+ @staticmethod
+ @torch.cuda.amp.custom_fwd(cast_inputs=torch.float32)
+ def forward(self, tenIn, tenFlow):
+ tenOut = tenIn.new_zeros([tenIn.shape[0], tenIn.shape[1], tenIn.shape[2], tenIn.shape[3]])
+
+ if tenIn.is_cuda == True:
+ cuda_launch(cuda_kernel('softsplat_out', '''
+ extern "C" __global__ void __launch_bounds__(512) softsplat_out(
+ const int n,
+ const {{type}}* __restrict__ tenIn,
+ const {{type}}* __restrict__ tenFlow,
+ {{type}}* __restrict__ tenOut
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ const int intN = ( intIndex / SIZE_3(tenOut) / SIZE_2(tenOut) / SIZE_1(tenOut) ) % SIZE_0(tenOut);
+ const int intC = ( intIndex / SIZE_3(tenOut) / SIZE_2(tenOut) ) % SIZE_1(tenOut);
+ const int intY = ( intIndex / SIZE_3(tenOut) ) % SIZE_2(tenOut);
+ const int intX = ( intIndex ) % SIZE_3(tenOut);
+
+ assert(SIZE_1(tenFlow) == 2);
+
+ {{type}} fltX = ({{type}}) (intX) + VALUE_4(tenFlow, intN, 0, intY, intX);
+ {{type}} fltY = ({{type}}) (intY) + VALUE_4(tenFlow, intN, 1, intY, intX);
+
+ if (isfinite(fltX) == false) { return; }
+ if (isfinite(fltY) == false) { return; }
+
+ {{type}} fltIn = VALUE_4(tenIn, intN, intC, intY, intX);
+
+ int intNorthwestX = (int) (floor(fltX));
+ int intNorthwestY = (int) (floor(fltY));
+ int intNortheastX = intNorthwestX + 1;
+ int intNortheastY = intNorthwestY;
+ int intSouthwestX = intNorthwestX;
+ int intSouthwestY = intNorthwestY + 1;
+ int intSoutheastX = intNorthwestX + 1;
+ int intSoutheastY = intNorthwestY + 1;
+
+ {{type}} fltNorthwest = (({{type}}) (intSoutheastX) - fltX) * (({{type}}) (intSoutheastY) - fltY);
+ {{type}} fltNortheast = (fltX - ({{type}}) (intSouthwestX)) * (({{type}}) (intSouthwestY) - fltY);
+ {{type}} fltSouthwest = (({{type}}) (intNortheastX) - fltX) * (fltY - ({{type}}) (intNortheastY));
+ {{type}} fltSoutheast = (fltX - ({{type}}) (intNorthwestX)) * (fltY - ({{type}}) (intNorthwestY));
+
+ if ((intNorthwestX >= 0) && (intNorthwestX < SIZE_3(tenOut)) && (intNorthwestY >= 0) && (intNorthwestY < SIZE_2(tenOut))) {
+ atomicAdd(&tenOut[OFFSET_4(tenOut, intN, intC, intNorthwestY, intNorthwestX)], fltIn * fltNorthwest);
+ }
+
+ if ((intNortheastX >= 0) && (intNortheastX < SIZE_3(tenOut)) && (intNortheastY >= 0) && (intNortheastY < SIZE_2(tenOut))) {
+ atomicAdd(&tenOut[OFFSET_4(tenOut, intN, intC, intNortheastY, intNortheastX)], fltIn * fltNortheast);
+ }
+
+ if ((intSouthwestX >= 0) && (intSouthwestX < SIZE_3(tenOut)) && (intSouthwestY >= 0) && (intSouthwestY < SIZE_2(tenOut))) {
+ atomicAdd(&tenOut[OFFSET_4(tenOut, intN, intC, intSouthwestY, intSouthwestX)], fltIn * fltSouthwest);
+ }
+
+ if ((intSoutheastX >= 0) && (intSoutheastX < SIZE_3(tenOut)) && (intSoutheastY >= 0) && (intSoutheastY < SIZE_2(tenOut))) {
+ atomicAdd(&tenOut[OFFSET_4(tenOut, intN, intC, intSoutheastY, intSoutheastX)], fltIn * fltSoutheast);
+ }
+ } }
+ ''', {
+ 'tenIn': tenIn,
+ 'tenFlow': tenFlow,
+ 'tenOut': tenOut
+ }))(
+ grid=tuple([int((tenOut.nelement() + 512 - 1) / 512), 1, 1]),
+ block=tuple([512, 1, 1]),
+ args=[cuda_int32(tenOut.nelement()), tenIn.data_ptr(), tenFlow.data_ptr(), tenOut.data_ptr()],
+ stream=collections.namedtuple('Stream', 'ptr')(torch.cuda.current_stream().cuda_stream)
+ )
+
+ elif tenIn.is_cuda != True:
+ assert(False)
+
+ # end
+
+ self.save_for_backward(tenIn, tenFlow)
+
+ return tenOut
+ # end
+
+ @staticmethod
+ @torch.cuda.amp.custom_bwd
+ def backward(self, tenOutgrad):
+ tenIn, tenFlow = self.saved_tensors
+
+ tenOutgrad = tenOutgrad.contiguous(); assert(tenOutgrad.is_cuda == True)
+
+ tenIngrad = tenIn.new_zeros([tenIn.shape[0], tenIn.shape[1], tenIn.shape[2], tenIn.shape[3]]) if self.needs_input_grad[0] == True else None
+ tenFlowgrad = tenFlow.new_zeros([tenFlow.shape[0], tenFlow.shape[1], tenFlow.shape[2], tenFlow.shape[3]]) if self.needs_input_grad[1] == True else None
+
+ if tenIngrad is not None:
+ cuda_launch(cuda_kernel('softsplat_ingrad', '''
+ extern "C" __global__ void __launch_bounds__(512) softsplat_ingrad(
+ const int n,
+ const {{type}}* __restrict__ tenIn,
+ const {{type}}* __restrict__ tenFlow,
+ const {{type}}* __restrict__ tenOutgrad,
+ {{type}}* __restrict__ tenIngrad,
+ {{type}}* __restrict__ tenFlowgrad
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ const int intN = ( intIndex / SIZE_3(tenIngrad) / SIZE_2(tenIngrad) / SIZE_1(tenIngrad) ) % SIZE_0(tenIngrad);
+ const int intC = ( intIndex / SIZE_3(tenIngrad) / SIZE_2(tenIngrad) ) % SIZE_1(tenIngrad);
+ const int intY = ( intIndex / SIZE_3(tenIngrad) ) % SIZE_2(tenIngrad);
+ const int intX = ( intIndex ) % SIZE_3(tenIngrad);
+
+ assert(SIZE_1(tenFlow) == 2);
+
+ {{type}} fltIngrad = 0.0f;
+
+ {{type}} fltX = ({{type}}) (intX) + VALUE_4(tenFlow, intN, 0, intY, intX);
+ {{type}} fltY = ({{type}}) (intY) + VALUE_4(tenFlow, intN, 1, intY, intX);
+
+ if (isfinite(fltX) == false) { return; }
+ if (isfinite(fltY) == false) { return; }
+
+ int intNorthwestX = (int) (floor(fltX));
+ int intNorthwestY = (int) (floor(fltY));
+ int intNortheastX = intNorthwestX + 1;
+ int intNortheastY = intNorthwestY;
+ int intSouthwestX = intNorthwestX;
+ int intSouthwestY = intNorthwestY + 1;
+ int intSoutheastX = intNorthwestX + 1;
+ int intSoutheastY = intNorthwestY + 1;
+
+ {{type}} fltNorthwest = (({{type}}) (intSoutheastX) - fltX) * (({{type}}) (intSoutheastY) - fltY);
+ {{type}} fltNortheast = (fltX - ({{type}}) (intSouthwestX)) * (({{type}}) (intSouthwestY) - fltY);
+ {{type}} fltSouthwest = (({{type}}) (intNortheastX) - fltX) * (fltY - ({{type}}) (intNortheastY));
+ {{type}} fltSoutheast = (fltX - ({{type}}) (intNorthwestX)) * (fltY - ({{type}}) (intNorthwestY));
+
+ if ((intNorthwestX >= 0) && (intNorthwestX < SIZE_3(tenOutgrad)) && (intNorthwestY >= 0) && (intNorthwestY < SIZE_2(tenOutgrad))) {
+ fltIngrad += VALUE_4(tenOutgrad, intN, intC, intNorthwestY, intNorthwestX) * fltNorthwest;
+ }
+
+ if ((intNortheastX >= 0) && (intNortheastX < SIZE_3(tenOutgrad)) && (intNortheastY >= 0) && (intNortheastY < SIZE_2(tenOutgrad))) {
+ fltIngrad += VALUE_4(tenOutgrad, intN, intC, intNortheastY, intNortheastX) * fltNortheast;
+ }
+
+ if ((intSouthwestX >= 0) && (intSouthwestX < SIZE_3(tenOutgrad)) && (intSouthwestY >= 0) && (intSouthwestY < SIZE_2(tenOutgrad))) {
+ fltIngrad += VALUE_4(tenOutgrad, intN, intC, intSouthwestY, intSouthwestX) * fltSouthwest;
+ }
+
+ if ((intSoutheastX >= 0) && (intSoutheastX < SIZE_3(tenOutgrad)) && (intSoutheastY >= 0) && (intSoutheastY < SIZE_2(tenOutgrad))) {
+ fltIngrad += VALUE_4(tenOutgrad, intN, intC, intSoutheastY, intSoutheastX) * fltSoutheast;
+ }
+
+ tenIngrad[intIndex] = fltIngrad;
+ } }
+ ''', {
+ 'tenIn': tenIn,
+ 'tenFlow': tenFlow,
+ 'tenOutgrad': tenOutgrad,
+ 'tenIngrad': tenIngrad,
+ 'tenFlowgrad': tenFlowgrad
+ }))(
+ grid=tuple([int((tenIngrad.nelement() + 512 - 1) / 512), 1, 1]),
+ block=tuple([512, 1, 1]),
+ args=[cuda_int32(tenIngrad.nelement()), tenIn.data_ptr(), tenFlow.data_ptr(), tenOutgrad.data_ptr(), tenIngrad.data_ptr(), None],
+ stream=collections.namedtuple('Stream', 'ptr')(torch.cuda.current_stream().cuda_stream)
+ )
+ # end
+
+ if tenFlowgrad is not None:
+ cuda_launch(cuda_kernel('softsplat_flowgrad', '''
+ extern "C" __global__ void __launch_bounds__(512) softsplat_flowgrad(
+ const int n,
+ const {{type}}* __restrict__ tenIn,
+ const {{type}}* __restrict__ tenFlow,
+ const {{type}}* __restrict__ tenOutgrad,
+ {{type}}* __restrict__ tenIngrad,
+ {{type}}* __restrict__ tenFlowgrad
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ const int intN = ( intIndex / SIZE_3(tenFlowgrad) / SIZE_2(tenFlowgrad) / SIZE_1(tenFlowgrad) ) % SIZE_0(tenFlowgrad);
+ const int intC = ( intIndex / SIZE_3(tenFlowgrad) / SIZE_2(tenFlowgrad) ) % SIZE_1(tenFlowgrad);
+ const int intY = ( intIndex / SIZE_3(tenFlowgrad) ) % SIZE_2(tenFlowgrad);
+ const int intX = ( intIndex ) % SIZE_3(tenFlowgrad);
+
+ assert(SIZE_1(tenFlow) == 2);
+
+ {{type}} fltFlowgrad = 0.0f;
+
+ {{type}} fltX = ({{type}}) (intX) + VALUE_4(tenFlow, intN, 0, intY, intX);
+ {{type}} fltY = ({{type}}) (intY) + VALUE_4(tenFlow, intN, 1, intY, intX);
+
+ if (isfinite(fltX) == false) { return; }
+ if (isfinite(fltY) == false) { return; }
+
+ int intNorthwestX = (int) (floor(fltX));
+ int intNorthwestY = (int) (floor(fltY));
+ int intNortheastX = intNorthwestX + 1;
+ int intNortheastY = intNorthwestY;
+ int intSouthwestX = intNorthwestX;
+ int intSouthwestY = intNorthwestY + 1;
+ int intSoutheastX = intNorthwestX + 1;
+ int intSoutheastY = intNorthwestY + 1;
+
+ {{type}} fltNorthwest = 0.0f;
+ {{type}} fltNortheast = 0.0f;
+ {{type}} fltSouthwest = 0.0f;
+ {{type}} fltSoutheast = 0.0f;
+
+ if (intC == 0) {
+ fltNorthwest = (({{type}}) (-1.0f)) * (({{type}}) (intSoutheastY) - fltY);
+ fltNortheast = (({{type}}) (+1.0f)) * (({{type}}) (intSouthwestY) - fltY);
+ fltSouthwest = (({{type}}) (-1.0f)) * (fltY - ({{type}}) (intNortheastY));
+ fltSoutheast = (({{type}}) (+1.0f)) * (fltY - ({{type}}) (intNorthwestY));
+
+ } else if (intC == 1) {
+ fltNorthwest = (({{type}}) (intSoutheastX) - fltX) * (({{type}}) (-1.0f));
+ fltNortheast = (fltX - ({{type}}) (intSouthwestX)) * (({{type}}) (-1.0f));
+ fltSouthwest = (({{type}}) (intNortheastX) - fltX) * (({{type}}) (+1.0f));
+ fltSoutheast = (fltX - ({{type}}) (intNorthwestX)) * (({{type}}) (+1.0f));
+
+ }
+
+ for (int intChannel = 0; intChannel < SIZE_1(tenOutgrad); intChannel += 1) {
+ {{type}} fltIn = VALUE_4(tenIn, intN, intChannel, intY, intX);
+
+ if ((intNorthwestX >= 0) && (intNorthwestX < SIZE_3(tenOutgrad)) && (intNorthwestY >= 0) && (intNorthwestY < SIZE_2(tenOutgrad))) {
+ fltFlowgrad += VALUE_4(tenOutgrad, intN, intChannel, intNorthwestY, intNorthwestX) * fltIn * fltNorthwest;
+ }
+
+ if ((intNortheastX >= 0) && (intNortheastX < SIZE_3(tenOutgrad)) && (intNortheastY >= 0) && (intNortheastY < SIZE_2(tenOutgrad))) {
+ fltFlowgrad += VALUE_4(tenOutgrad, intN, intChannel, intNortheastY, intNortheastX) * fltIn * fltNortheast;
+ }
+
+ if ((intSouthwestX >= 0) && (intSouthwestX < SIZE_3(tenOutgrad)) && (intSouthwestY >= 0) && (intSouthwestY < SIZE_2(tenOutgrad))) {
+ fltFlowgrad += VALUE_4(tenOutgrad, intN, intChannel, intSouthwestY, intSouthwestX) * fltIn * fltSouthwest;
+ }
+
+ if ((intSoutheastX >= 0) && (intSoutheastX < SIZE_3(tenOutgrad)) && (intSoutheastY >= 0) && (intSoutheastY < SIZE_2(tenOutgrad))) {
+ fltFlowgrad += VALUE_4(tenOutgrad, intN, intChannel, intSoutheastY, intSoutheastX) * fltIn * fltSoutheast;
+ }
+ }
+
+ tenFlowgrad[intIndex] = fltFlowgrad;
+ } }
+ ''', {
+ 'tenIn': tenIn,
+ 'tenFlow': tenFlow,
+ 'tenOutgrad': tenOutgrad,
+ 'tenIngrad': tenIngrad,
+ 'tenFlowgrad': tenFlowgrad
+ }))(
+ grid=tuple([int((tenFlowgrad.nelement() + 512 - 1) / 512), 1, 1]),
+ block=tuple([512, 1, 1]),
+ args=[cuda_int32(tenFlowgrad.nelement()), tenIn.data_ptr(), tenFlow.data_ptr(), tenOutgrad.data_ptr(), None, tenFlowgrad.data_ptr()],
+ stream=collections.namedtuple('Stream', 'ptr')(torch.cuda.current_stream().cuda_stream)
+ )
+ # end
+
+ return tenIngrad, tenFlowgrad
+ # end
+# end
diff --git a/animate/src/animatediff/stylize.py b/animate/src/animatediff/stylize.py
new file mode 100644
index 0000000000000000000000000000000000000000..edd6879be55911e509efa0db97295dfa664377c6
--- /dev/null
+++ b/animate/src/animatediff/stylize.py
@@ -0,0 +1,1716 @@
+import glob
+import json
+import logging
+import os.path
+import shutil
+from datetime import datetime
+from pathlib import Path
+from typing import Annotated, Optional
+
+import torch
+import typer
+from PIL import Image
+from tqdm.rich import tqdm
+
+from animatediff import __version__, get_dir
+from animatediff.settings import ModelConfig, get_model_config
+from animatediff.utils.tagger import get_labels
+from animatediff.utils.util import (extract_frames, get_resized_image,
+ path_from_cwd, prepare_anime_seg,
+ prepare_groundingDINO, prepare_propainter,
+ prepare_sam_hq, prepare_softsplat)
+
+logger = logging.getLogger(__name__)
+
+
+
+stylize: typer.Typer = typer.Typer(
+ name="stylize",
+ context_settings=dict(help_option_names=["-h", "--help"]),
+ rich_markup_mode="rich",
+ pretty_exceptions_show_locals=False,
+ help="stylize video",
+)
+
+data_dir = get_dir("data")
+
+controlnet_dirs = [
+ "controlnet_canny",
+ "controlnet_depth",
+ "controlnet_inpaint",
+ "controlnet_ip2p",
+ "controlnet_lineart",
+ "controlnet_lineart_anime",
+ "controlnet_mlsd",
+ "controlnet_normalbae",
+ "controlnet_openpose",
+ "controlnet_scribble",
+ "controlnet_seg",
+ "controlnet_shuffle",
+ "controlnet_softedge",
+ "controlnet_tile",
+ "qr_code_monster_v1",
+ "qr_code_monster_v2",
+ "controlnet_mediapipe_face",
+ "animatediff_controlnet",
+ ]
+
+def create_controlnet_dir(controlnet_root):
+ for c in controlnet_dirs:
+ c_dir = controlnet_root.joinpath(c)
+ c_dir.mkdir(parents=True, exist_ok=True)
+
+@stylize.command(no_args_is_help=True)
+def create_config(
+ org_movie: Annotated[
+ Path,
+ typer.Argument(path_type=Path, file_okay=True, dir_okay=False, exists=True, help="Path to movie file"),
+ ] = ...,
+ config_org: Annotated[
+ Path,
+ typer.Option(
+ "--config-org",
+ "-c",
+ path_type=Path,
+ dir_okay=False,
+ exists=True,
+ help="Path to original config file",
+ ),
+ ] = Path("config/prompts/prompt_travel.json"),
+ ignore_list: Annotated[
+ Path,
+ typer.Option(
+ "--ignore-list",
+ "-g",
+ path_type=Path,
+ dir_okay=False,
+ exists=True,
+ help="path to ignore token list file",
+ ),
+ ] = Path("config/prompts/ignore_tokens.txt"),
+ out_dir: Annotated[
+ Optional[Path],
+ typer.Option(
+ "--out-dir",
+ "-o",
+ path_type=Path,
+ file_okay=False,
+ help="output directory",
+ ),
+ ] = Path("stylize/"),
+ fps: Annotated[
+ int,
+ typer.Option(
+ "--fps",
+ "-f",
+ min=1,
+ max=120,
+ help="fps",
+ ),
+ ] = 8,
+ duration: Annotated[
+ int,
+ typer.Option(
+ "--duration",
+ "-d",
+ min=-1,
+ max=3600,
+ help="Video duration in seconds. -1 means that the duration of the input video is used as is",
+ ),
+ ] = -1,
+ offset: Annotated[
+ int,
+ typer.Option(
+ "--offset",
+ "-of",
+ min=0,
+ max=3600,
+ help="offset in seconds. '-d 30 -of 1200' means to use 1200-1230 seconds of the input video",
+ ),
+ ] = 0,
+ aspect_ratio: Annotated[
+ float,
+ typer.Option(
+ "--aspect-ratio",
+ "-a",
+ min=-1,
+ max=5.0,
+ help="aspect ratio (width / height). (ex. 512 / 512 = 1.0 , 512 / 768 = 0.6666 , 768 / 512 = 1.5) -1 means that the aspect ratio of the input video is used as is.",
+ ),
+ ] = -1,
+ size_of_short_edge: Annotated[
+ int,
+ typer.Option(
+ "--short-edge",
+ "-sh",
+ min=100,
+ max=1024,
+ help="size of short edge",
+ ),
+ ] = 512,
+ predicte_interval: Annotated[
+ int,
+ typer.Option(
+ "--predicte-interval",
+ "-p",
+ min=1,
+ max=120,
+ help="Interval of frames to be predicted",
+ ),
+ ] = 1,
+ general_threshold: Annotated[
+ float,
+ typer.Option(
+ "--threshold",
+ "-th",
+ min=0.0,
+ max=1.0,
+ help="threshold for general token confidence",
+ ),
+ ] = 0.35,
+ character_threshold: Annotated[
+ float,
+ typer.Option(
+ "--threshold2",
+ "-th2",
+ min=0.0,
+ max=1.0,
+ help="threshold for character token confidence",
+ ),
+ ] = 0.85,
+ without_confidence: Annotated[
+ bool,
+ typer.Option(
+ "--no-confidence-format",
+ "-ncf",
+ is_flag=True,
+ help="confidence token format or not. ex. '(close-up:0.57), (monochrome:1.1)' -> 'close-up, monochrome'",
+ ),
+ ] = False,
+ is_no_danbooru_format: Annotated[
+ bool,
+ typer.Option(
+ "--no-danbooru-format",
+ "-ndf",
+ is_flag=True,
+ help="danbooru token format or not. ex. 'bandaid_on_leg, short_hair' -> 'bandaid on leg, short hair'",
+ ),
+ ] = False,
+ is_img2img: Annotated[
+ bool,
+ typer.Option(
+ "--img2img",
+ "-i2i",
+ is_flag=True,
+ help="img2img or not(txt2img).",
+ ),
+ ] = False,
+ low_vram: Annotated[
+ bool,
+ typer.Option(
+ "--low_vram",
+ "-lo",
+ is_flag=True,
+ help="low vram mode",
+ ),
+ ] = False,
+ gradual_latent_hires_fix: Annotated[
+ bool,
+ typer.Option(
+ "--gradual_latent_hires_fix",
+ "-gh",
+ is_flag=True,
+ help="gradual latent hires fix",
+ ),
+ ] = False,
+):
+ """Create a config file for video stylization"""
+ is_danbooru_format = not is_no_danbooru_format
+ with_confidence = not without_confidence
+ logger.info(f"{org_movie=}")
+ logger.info(f"{config_org=}")
+ logger.info(f"{ignore_list=}")
+ logger.info(f"{out_dir=}")
+ logger.info(f"{fps=}")
+ logger.info(f"{duration=}")
+ logger.info(f"{offset=}")
+ logger.info(f"{aspect_ratio=}")
+ logger.info(f"{size_of_short_edge=}")
+ logger.info(f"{predicte_interval=}")
+ logger.info(f"{general_threshold=}")
+ logger.info(f"{character_threshold=}")
+ logger.info(f"{with_confidence=}")
+ logger.info(f"{is_danbooru_format=}")
+ logger.info(f"{is_img2img=}")
+ logger.info(f"{low_vram=}")
+ logger.info(f"{gradual_latent_hires_fix=}")
+
+ model_config: ModelConfig = get_model_config(config_org)
+
+ # get a timestamp for the output directory
+ time_str = datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
+ # make the output directory
+ save_dir = out_dir.joinpath(f"{time_str}-{model_config.save_name}")
+ save_dir.mkdir(parents=True, exist_ok=True)
+ logger.info(f"Will save outputs to ./{path_from_cwd(save_dir)}")
+
+ img2img_dir = save_dir.joinpath("00_img2img")
+ img2img_dir.mkdir(parents=True, exist_ok=True)
+ extract_frames(org_movie, fps, img2img_dir, aspect_ratio, duration, offset, size_of_short_edge, low_vram)
+
+ controlnet_img_dir = save_dir.joinpath("00_controlnet_image")
+
+ create_controlnet_dir(controlnet_img_dir)
+
+ shutil.copytree(img2img_dir, controlnet_img_dir.joinpath("controlnet_openpose"), dirs_exist_ok=True)
+
+ #shutil.copytree(img2img_dir, controlnet_img_dir.joinpath("controlnet_ip2p"), dirs_exist_ok=True)
+
+
+ black_list = []
+ if ignore_list.is_file():
+ with open(ignore_list) as f:
+ black_list = [s.strip() for s in f.readlines()]
+
+ model_config.prompt_map = get_labels(
+ frame_dir=img2img_dir,
+ interval=predicte_interval,
+ general_threshold=general_threshold,
+ character_threshold=character_threshold,
+ ignore_tokens=black_list,
+ with_confidence=with_confidence,
+ is_danbooru_format=is_danbooru_format,
+ is_cpu = False,
+ )
+
+
+ model_config.head_prompt = ""
+ model_config.tail_prompt = ""
+ model_config.controlnet_map["input_image_dir"] = os.path.relpath(controlnet_img_dir.absolute(), data_dir)
+ model_config.controlnet_map["is_loop"] = False
+
+ model_config.lora_map={}
+ model_config.motion_lora_map={}
+
+ model_config.controlnet_map["max_samples_on_vram"] = 0
+ model_config.controlnet_map["max_models_on_vram"] = 0
+
+
+ model_config.controlnet_map["controlnet_openpose"] = {
+ "enable": True,
+ "use_preprocessor":True,
+ "guess_mode":False,
+ "controlnet_conditioning_scale": 1.0,
+ "control_guidance_start": 0.0,
+ "control_guidance_end": 1.0,
+ "control_scale_list":[],
+ "control_region_list":[]
+ }
+
+
+ model_config.controlnet_map["controlnet_ip2p"] = {
+ "enable": True,
+ "use_preprocessor":True,
+ "guess_mode":False,
+ "controlnet_conditioning_scale": 0.5,
+ "control_guidance_start": 0.0,
+ "control_guidance_end": 1.0,
+ "control_scale_list":[],
+ "control_region_list":[]
+ }
+
+ for m in model_config.controlnet_map:
+ if isinstance(model_config.controlnet_map[m] ,dict):
+ if "control_scale_list" in model_config.controlnet_map[m]:
+ model_config.controlnet_map[m]["control_scale_list"]=[]
+
+ ip_adapter_dir = save_dir.joinpath("00_ipadapter")
+ ip_adapter_dir.mkdir(parents=True, exist_ok=True)
+
+ model_config.ip_adapter_map = {
+ "enable": True,
+ "input_image_dir": os.path.relpath(ip_adapter_dir.absolute(), data_dir),
+ "prompt_fixed_ratio": 0.5,
+ "save_input_image": True,
+ "resized_to_square": False,
+ "scale": 0.5,
+ "is_full_face": False,
+ "is_plus_face": False,
+ "is_plus": True,
+ "is_light": False
+ }
+
+ model_config.img2img_map = {
+ "enable": is_img2img,
+ "init_img_dir" : os.path.relpath(img2img_dir.absolute(), data_dir),
+ "save_init_image": True,
+ "denoising_strength" : 0.7
+ }
+
+ model_config.region_map = {
+
+ }
+
+ model_config.gradual_latent_hires_fix_map = {
+ "enable" : True,
+ "scale" : {
+ "0": 0.5,
+ "0.7": 1.0
+ },
+ "reverse_steps": 5,
+ "noise_add_count": 3
+ }
+
+ model_config.output = {
+ "format" : "mp4",
+ "fps" : fps,
+ "encode_param":{
+ "crf": 10
+ }
+ }
+
+ img = Image.open( img2img_dir.joinpath("00000000.png") )
+ W, H = img.size
+
+ base_size = 768 if gradual_latent_hires_fix else 512
+
+ if W < H:
+ width = base_size
+ height = int(base_size * H/W)
+ else:
+ width = int(base_size * W/H)
+ height = base_size
+
+ width = int(width//8*8)
+ height = int(height//8*8)
+
+ length = len(glob.glob( os.path.join(img2img_dir, "[0-9]*.png"), recursive=False))
+
+ model_config.stylize_config={
+ "original_video":{
+ "path":org_movie,
+ "aspect_ratio":aspect_ratio,
+ "offset":offset,
+ },
+ "create_mask": [
+ "person"
+ ],
+ "composite": {
+ "fg_list": [
+ {
+ "path" : " absolute path to frame dir ",
+ "mask_path" : " absolute path to mask dir (this is optional) ",
+ "mask_prompt" : "person"
+ },
+ {
+ "path" : " absolute path to frame dir ",
+ "mask_path" : " absolute path to mask dir (this is optional) ",
+ "mask_prompt" : "cat"
+ },
+ ],
+ "bg_frame_dir": "Absolute path to the BG frame directory",
+ "hint": ""
+ },
+ "0":{
+ "width": width,
+ "height": height,
+ "length": length,
+ "context": 16,
+ "overlap": 16//4,
+ "stride": 0,
+ },
+ "1":{
+ "steps": model_config.steps,
+ "guidance_scale": model_config.guidance_scale,
+ "width": int(width * 1.5 //8*8),
+ "height": int(height * 1.5 //8*8),
+ "length": length,
+ "context": 8,
+ "overlap": 8//4,
+ "stride": 0,
+ "controlnet_tile":{
+ "enable": True,
+ "use_preprocessor":True,
+ "guess_mode":False,
+ "controlnet_conditioning_scale": 1.0,
+ "control_guidance_start": 0.0,
+ "control_guidance_end": 1.0,
+ "control_scale_list":[]
+ },
+ "controlnet_ip2p": {
+ "enable": False,
+ "use_preprocessor":True,
+ "guess_mode":False,
+ "controlnet_conditioning_scale": 0.5,
+ "control_guidance_start": 0.0,
+ "control_guidance_end": 1.0,
+ "control_scale_list":[]
+ },
+ "ip_adapter": False,
+ "reference": False,
+ "img2img": False,
+ "interpolation_multiplier": 1
+ }
+ }
+
+ if gradual_latent_hires_fix:
+ model_config.stylize_config.pop("1")
+
+
+ save_config_path = save_dir.joinpath("prompt.json")
+ save_config_path.write_text(model_config.json(indent=4), encoding="utf-8")
+
+ logger.info(f"config = { save_config_path }")
+ logger.info(f"stylize_dir = { save_dir }")
+
+ logger.info(f"!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!")
+ logger.info(f"Hint. Edit the config file before starting the generation")
+ logger.info(f"!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!")
+ logger.info(f"1. Change 'path' and 'motion_module' as needed")
+ logger.info(f"2. Enter the 'head_prompt' or 'tail_prompt' with your preferred prompt, quality prompt, lora trigger word, or any other prompt you wish to add.")
+ logger.info(f"3. Change 'n_prompt' as needed")
+ logger.info(f"4. Add the lora you need to 'lora_map'")
+ logger.info(f"5. If you do not like the default settings, edit 'ip_adapter_map' or 'controlnet_map'. \nIf you want to change the controlnet type, you need to replace the input image.")
+ logger.info(f"6. Change 'stylize_config' as needed. By default, it is generated twice: once for normal generation and once for upscaling.\nIf you don't need upscaling, delete the whole '1'.")
+ logger.info(f"7. Change 'output' as needed. Changing the 'fps' at this timing is not recommended as it will change the playback speed.\nIf you want to change the fps, specify it with the create-config option")
+
+
+@stylize.command(no_args_is_help=True)
+def generate(
+ stylize_dir: Annotated[
+ Path,
+ typer.Argument(path_type=Path, file_okay=False, dir_okay=True, exists=True, help="Path to stylize dir"),
+ ] = ...,
+ length: Annotated[
+ int,
+ typer.Option(
+ "--length",
+ "-L",
+ min=-1,
+ max=9999,
+ help="Number of frames to generate. -1 means that the value in the config file is referenced.",
+ rich_help_panel="Generation",
+ ),
+ ] = -1,
+ frame_offset: Annotated[
+ int,
+ typer.Option(
+ "--frame-offset",
+ "-FO",
+ min=0,
+ max=999999,
+ help="Frame offset at generation.",
+ rich_help_panel="Generation",
+ ),
+ ] = 0,
+):
+ """Run video stylization"""
+ from animatediff.cli import generate
+
+ time_str = datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
+
+
+ config_org = stylize_dir.joinpath("prompt.json")
+
+ model_config: ModelConfig = get_model_config(config_org)
+
+ if length == -1:
+ length = model_config.stylize_config["0"]["length"]
+
+ model_config.stylize_config["0"]["length"] = min(model_config.stylize_config["0"]["length"] - frame_offset, length)
+ if "1" in model_config.stylize_config:
+ model_config.stylize_config["1"]["length"] = min(model_config.stylize_config["1"]["length"] - frame_offset, length)
+
+ if frame_offset > 0:
+ #controlnet
+ org_controlnet_img_dir = data_dir.joinpath( model_config.controlnet_map["input_image_dir"] )
+ new_controlnet_img_dir = org_controlnet_img_dir.parent / "00_tmp_controlnet_image"
+ if new_controlnet_img_dir.is_dir():
+ shutil.rmtree(new_controlnet_img_dir)
+ new_controlnet_img_dir.mkdir(parents=True, exist_ok=True)
+
+ for c in controlnet_dirs:
+ src_dir = org_controlnet_img_dir.joinpath(c)
+ dst_dir = new_controlnet_img_dir.joinpath(c)
+ if src_dir.is_dir():
+ dst_dir.mkdir(parents=True, exist_ok=True)
+
+ frame_length = model_config.stylize_config["0"]["length"]
+
+ src_imgs = sorted(glob.glob( os.path.join(src_dir, "[0-9]*.png"), recursive=False))
+ for img in src_imgs:
+ n = int(Path(img).stem)
+ if n in range(frame_offset, frame_offset + frame_length):
+ dst_img_path = dst_dir.joinpath( f"{n-frame_offset:08d}.png" )
+ shutil.copy(img, dst_img_path)
+ #img2img
+ org_img2img_img_dir = data_dir.joinpath( model_config.img2img_map["init_img_dir"] )
+ new_img2img_img_dir = org_img2img_img_dir.parent / "00_tmp_init_img_dir"
+ if new_img2img_img_dir.is_dir():
+ shutil.rmtree(new_img2img_img_dir)
+ new_img2img_img_dir.mkdir(parents=True, exist_ok=True)
+
+ src_dir = org_img2img_img_dir
+ dst_dir = new_img2img_img_dir
+ if src_dir.is_dir():
+ dst_dir.mkdir(parents=True, exist_ok=True)
+
+ frame_length = model_config.stylize_config["0"]["length"]
+
+ src_imgs = sorted(glob.glob( os.path.join(src_dir, "[0-9]*.png"), recursive=False))
+ for img in src_imgs:
+ n = int(Path(img).stem)
+ if n in range(frame_offset, frame_offset + frame_length):
+ dst_img_path = dst_dir.joinpath( f"{n-frame_offset:08d}.png" )
+ shutil.copy(img, dst_img_path)
+
+ new_prompt_map = {}
+ for p in model_config.prompt_map:
+ n = int(p)
+ if n in range(frame_offset, frame_offset + frame_length):
+ new_prompt_map[str(n-frame_offset)]=model_config.prompt_map[p]
+
+ model_config.prompt_map = new_prompt_map
+
+ model_config.controlnet_map["input_image_dir"] = os.path.relpath(new_controlnet_img_dir.absolute(), data_dir)
+ model_config.img2img_map["init_img_dir"] = os.path.relpath(new_img2img_img_dir.absolute(), data_dir)
+
+ tmp_config_path = stylize_dir.joinpath("prompt_tmp.json")
+ tmp_config_path.write_text(model_config.json(indent=4), encoding="utf-8")
+ config_org = tmp_config_path
+
+
+ output_0_dir = generate(
+ config_path=config_org,
+ width=model_config.stylize_config["0"]["width"],
+ height=model_config.stylize_config["0"]["height"],
+ length=model_config.stylize_config["0"]["length"],
+ context=model_config.stylize_config["0"]["context"],
+ overlap=model_config.stylize_config["0"]["overlap"],
+ stride=model_config.stylize_config["0"]["stride"],
+ out_dir=stylize_dir
+ )
+
+ torch.cuda.empty_cache()
+
+ output_0_dir = output_0_dir.rename(output_0_dir.parent / f"{time_str}_{0:02d}")
+
+
+ if "1" not in model_config.stylize_config:
+ logger.info(f"Stylized results are output to {output_0_dir}")
+ return
+
+ logger.info(f"Intermediate files have been output to {output_0_dir}")
+
+ output_0_img_dir = glob.glob( os.path.join(output_0_dir, "00-[0-9]*"), recursive=False)[0]
+
+ interpolation_multiplier = 1
+ if "interpolation_multiplier" in model_config.stylize_config["1"]:
+ interpolation_multiplier = model_config.stylize_config["1"]["interpolation_multiplier"]
+
+ if interpolation_multiplier > 1:
+ from animatediff.rife.rife import rife_interpolate
+
+ rife_img_dir = stylize_dir.joinpath(f"{1:02d}_rife_frame")
+ if rife_img_dir.is_dir():
+ shutil.rmtree(rife_img_dir)
+ rife_img_dir.mkdir(parents=True, exist_ok=True)
+
+ rife_interpolate(output_0_img_dir, rife_img_dir, interpolation_multiplier)
+ model_config.stylize_config["1"]["length"] *= interpolation_multiplier
+
+ if model_config.output:
+ model_config.output["fps"] *= interpolation_multiplier
+ if model_config.prompt_map:
+ model_config.prompt_map = { str(int(i)*interpolation_multiplier): model_config.prompt_map[i] for i in model_config.prompt_map }
+
+ output_0_img_dir = rife_img_dir
+
+
+ controlnet_img_dir = stylize_dir.joinpath("01_controlnet_image")
+ img2img_dir = stylize_dir.joinpath("01_img2img")
+ img2img_dir.mkdir(parents=True, exist_ok=True)
+
+ create_controlnet_dir(controlnet_img_dir)
+
+ ip2p_for_upscale = model_config.stylize_config["1"]["controlnet_ip2p"]["enable"]
+ ip_adapter_for_upscale = model_config.stylize_config["1"]["ip_adapter"]
+ ref_for_upscale = model_config.stylize_config["1"]["reference"]
+
+ shutil.copytree(output_0_img_dir, controlnet_img_dir.joinpath("controlnet_tile"), dirs_exist_ok=True)
+ if ip2p_for_upscale:
+ shutil.copytree(controlnet_img_dir.joinpath("controlnet_tile"), controlnet_img_dir.joinpath("controlnet_ip2p"), dirs_exist_ok=True)
+
+ shutil.copytree(controlnet_img_dir.joinpath("controlnet_tile"), img2img_dir, dirs_exist_ok=True)
+
+ model_config.controlnet_map["input_image_dir"] = os.path.relpath(controlnet_img_dir.absolute(), data_dir)
+
+ model_config.controlnet_map["controlnet_tile"] = model_config.stylize_config["1"]["controlnet_tile"]
+ model_config.controlnet_map["controlnet_ip2p"] = model_config.stylize_config["1"]["controlnet_ip2p"]
+
+ if "controlnet_ref" in model_config.controlnet_map:
+ model_config.controlnet_map["controlnet_ref"]["enable"] = ref_for_upscale
+
+ model_config.ip_adapter_map["enable"] = ip_adapter_for_upscale
+ for r in model_config.region_map:
+ reg = model_config.region_map[r]
+ if "condition" in reg:
+ if "ip_adapter_map" in reg["condition"]:
+ reg["condition"]["ip_adapter_map"]["enable"] = ip_adapter_for_upscale
+
+ model_config.steps = model_config.stylize_config["1"]["steps"] if "steps" in model_config.stylize_config["1"] else model_config.steps
+ model_config.guidance_scale = model_config.stylize_config["1"]["guidance_scale"] if "guidance_scale" in model_config.stylize_config["1"] else model_config.guidance_scale
+
+ model_config.img2img_map["enable"] = model_config.stylize_config["1"]["img2img"]
+
+ if model_config.img2img_map["enable"]:
+ model_config.img2img_map["init_img_dir"] = os.path.relpath(Path(output_0_img_dir).absolute(), data_dir)
+
+ save_config_path = stylize_dir.joinpath("prompt_01.json")
+ save_config_path.write_text(model_config.json(indent=4), encoding="utf-8")
+
+ output_1_dir = generate(
+ config_path=save_config_path,
+ width=model_config.stylize_config["1"]["width"],
+ height=model_config.stylize_config["1"]["height"],
+ length=model_config.stylize_config["1"]["length"],
+ context=model_config.stylize_config["1"]["context"],
+ overlap=model_config.stylize_config["1"]["overlap"],
+ stride=model_config.stylize_config["1"]["stride"],
+ out_dir=stylize_dir
+ )
+
+ output_1_dir = output_1_dir.rename(output_1_dir.parent / f"{time_str}_{1:02d}")
+
+ logger.info(f"Stylized results are output to {output_1_dir}")
+
+
+
+
+@stylize.command(no_args_is_help=True)
+def interpolate(
+ frame_dir: Annotated[
+ Path,
+ typer.Argument(path_type=Path, file_okay=False, dir_okay=True, exists=True, help="Path to frame dir"),
+ ] = ...,
+ interpolation_multiplier: Annotated[
+ int,
+ typer.Option(
+ "--interpolation_multiplier",
+ "-m",
+ min=1,
+ max=10,
+ help="interpolation_multiplier",
+ ),
+ ] = 1,
+):
+ """Interpolation with original frames. This function does not work well if the shape of the subject is changed from the original video. Large movements can also ruin the picture.(Since this command is experimental, it is better to use other interpolation methods in most cases.)"""
+
+ try:
+ import cupy
+ except:
+ logger.info(f"!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!")
+ logger.info(f"cupy is required to run interpolate")
+ logger.info(f"Your CUDA version is {torch.version.cuda}")
+ logger.info(f"Please find the installation method of cupy for your CUDA version from the following URL")
+ logger.info(f"https://docs.cupy.dev/en/latest/install.html#installing-cupy-from-pypi")
+ logger.info(f"!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!")
+ return
+
+ prepare_softsplat()
+
+ time_str = datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
+
+ config_org = frame_dir.parent.joinpath("prompt.json")
+
+ model_config: ModelConfig = get_model_config(config_org)
+
+ if "original_video" in model_config.stylize_config:
+ org_video = Path(model_config.stylize_config["original_video"]["path"])
+ offset = model_config.stylize_config["original_video"]["offset"]
+ aspect_ratio = model_config.stylize_config["original_video"]["aspect_ratio"]
+ else:
+ logger.warn('!!! The following parameters are required !!!')
+ logger.warn('"stylize_config": {')
+ logger.warn(' "original_video": {')
+ logger.warn(' "path": "C:\\my_movie\\test.mp4",')
+ logger.warn(' "aspect_ratio": 0.6666,')
+ logger.warn(' "offset": 0')
+ logger.warn(' },')
+ raise ValueError('model_config.stylize_config["original_video"] not found')
+
+
+ save_dir = frame_dir.parent.joinpath(f"optflow_{time_str}")
+
+ org_frame_dir = save_dir.joinpath("org_frame")
+ org_frame_dir.mkdir(parents=True, exist_ok=True)
+
+ stylize_frame = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+ stylize_frame_num = len(stylize_frame)
+
+ duration = int(stylize_frame_num / model_config.output["fps"]) + 1
+
+ extract_frames(org_video, model_config.output["fps"] * interpolation_multiplier, org_frame_dir,aspect_ratio,duration,offset)
+
+ W, H = Image.open(stylize_frame[0]).size
+
+ org_frame = sorted(glob.glob( os.path.join(org_frame_dir, "[0-9]*.png"), recursive=False))
+
+ for org in tqdm(org_frame):
+ img = get_resized_image(org, W, H)
+ img.save(org)
+
+ output_dir = save_dir.joinpath("warp_img")
+ output_dir.mkdir(parents=True, exist_ok=True)
+
+ from animatediff.softmax_splatting.run import estimate2
+
+ for sty1,sty2 in tqdm(zip(stylize_frame,stylize_frame[1:]), total=len(stylize_frame[1:])):
+ sty1 = Path(sty1)
+ sty2 = Path(sty2)
+
+ head = int(sty1.stem)
+
+ sty1_img = Image.open(sty1)
+ sty2_img = Image.open(sty2)
+
+ guide_frames=[org_frame_dir.joinpath(f"{g:08d}.png") for g in range(head*interpolation_multiplier, (head+1)*interpolation_multiplier)]
+
+ guide_frames=[Image.open(g) for g in guide_frames]
+
+ result = estimate2(sty1_img, sty2_img, guide_frames, "data/models/softsplat/softsplat-lf")
+
+ shutil.copy( frame_dir.joinpath(f"{head:08d}.png"), output_dir.joinpath(f"{head*interpolation_multiplier:08d}.png"))
+
+ offset = head*interpolation_multiplier + 1
+ for i, r in enumerate(result):
+ r.save( output_dir.joinpath(f"{offset+i:08d}.png") )
+
+
+ from animatediff.generate import save_output
+
+
+ frames = sorted(glob.glob( os.path.join(output_dir, "[0-9]*.png"), recursive=False))
+ out_images = []
+ for f in frames:
+ out_images.append(Image.open(f))
+
+ model_config.output["fps"] *= interpolation_multiplier
+
+ out_file = save_dir.joinpath(f"01_{model_config.output['fps']}fps")
+ save_output(out_images,output_dir,out_file,model_config.output,True,save_frames=None,save_video=None)
+
+ out_file = save_dir.joinpath(f"00_original")
+ save_output(out_images,org_frame_dir,out_file,model_config.output,True,save_frames=None,save_video=None)
+
+
+@stylize.command(no_args_is_help=True)
+def create_mask(
+ stylize_dir: Annotated[
+ Path,
+ typer.Argument(path_type=Path, file_okay=False, dir_okay=True, exists=True, help="Path to stylize dir"),
+ ] = ...,
+ frame_dir: Annotated[
+ Path,
+ typer.Option(
+ "--frame_dir",
+ "-f",
+ path_type=Path,
+ file_okay=False,
+ help="Path to source frames directory. default is 'STYLIZE_DIR/00_img2img'",
+ ),
+ ] = None,
+ box_threshold: Annotated[
+ float,
+ typer.Option(
+ "--box_threshold",
+ "-b",
+ min=0.0,
+ max=1.0,
+ help="box_threshold",
+ rich_help_panel="create mask",
+ ),
+ ] = 0.3,
+ text_threshold: Annotated[
+ float,
+ typer.Option(
+ "--text_threshold",
+ "-t",
+ min=0.0,
+ max=1.0,
+ help="text_threshold",
+ rich_help_panel="create mask",
+ ),
+ ] = 0.25,
+ mask_padding: Annotated[
+ int,
+ typer.Option(
+ "--mask_padding",
+ "-mp",
+ min=-100,
+ max=100,
+ help="padding pixel value",
+ rich_help_panel="create mask",
+ ),
+ ] = 0,
+ no_gb: Annotated[
+ bool,
+ typer.Option(
+ "--no_gb",
+ "-ng",
+ is_flag=True,
+ help="no green back",
+ rich_help_panel="create mask",
+ ),
+ ] = False,
+ no_crop: Annotated[
+ bool,
+ typer.Option(
+ "--no_crop",
+ "-nc",
+ is_flag=True,
+ help="no crop",
+ rich_help_panel="create mask",
+ ),
+ ] = False,
+ use_rembg: Annotated[
+ bool,
+ typer.Option(
+ "--use_rembg",
+ "-rem",
+ is_flag=True,
+ help="use [rembg] instead of [Sam+GroundingDINO]",
+ rich_help_panel="create mask",
+ ),
+ ] = False,
+ use_animeseg: Annotated[
+ bool,
+ typer.Option(
+ "--use_animeseg",
+ "-anim",
+ is_flag=True,
+ help="use [anime-segmentation] instead of [Sam+GroundingDINO]",
+ rich_help_panel="create mask",
+ ),
+ ] = False,
+ low_vram: Annotated[
+ bool,
+ typer.Option(
+ "--low_vram",
+ "-lo",
+ is_flag=True,
+ help="low vram mode",
+ rich_help_panel="create mask/tag",
+ ),
+ ] = False,
+ ignore_list: Annotated[
+ Path,
+ typer.Option(
+ "--ignore-list",
+ "-g",
+ path_type=Path,
+ dir_okay=False,
+ exists=True,
+ help="path to ignore token list file",
+ rich_help_panel="create tag",
+ ),
+ ] = Path("config/prompts/ignore_tokens.txt"),
+ predicte_interval: Annotated[
+ int,
+ typer.Option(
+ "--predicte-interval",
+ "-p",
+ min=1,
+ max=120,
+ help="Interval of frames to be predicted",
+ rich_help_panel="create tag",
+ ),
+ ] = 1,
+ general_threshold: Annotated[
+ float,
+ typer.Option(
+ "--threshold",
+ "-th",
+ min=0.0,
+ max=1.0,
+ help="threshold for general token confidence",
+ rich_help_panel="create tag",
+ ),
+ ] = 0.35,
+ character_threshold: Annotated[
+ float,
+ typer.Option(
+ "--threshold2",
+ "-th2",
+ min=0.0,
+ max=1.0,
+ help="threshold for character token confidence",
+ rich_help_panel="create tag",
+ ),
+ ] = 0.85,
+ without_confidence: Annotated[
+ bool,
+ typer.Option(
+ "--no-confidence-format",
+ "-ncf",
+ is_flag=True,
+ help="confidence token format or not. ex. '(close-up:0.57), (monochrome:1.1)' -> 'close-up, monochrome'",
+ rich_help_panel="create tag",
+ ),
+ ] = False,
+ is_no_danbooru_format: Annotated[
+ bool,
+ typer.Option(
+ "--no-danbooru-format",
+ "-ndf",
+ is_flag=True,
+ help="danbooru token format or not. ex. 'bandaid_on_leg, short_hair' -> 'bandaid on leg, short hair'",
+ rich_help_panel="create tag",
+ ),
+ ] = False,
+):
+ """Create mask from prompt"""
+ from animatediff.utils.mask import (create_bg, create_fg, crop_frames,
+ crop_mask_list, save_crop_info)
+ from animatediff.utils.mask_animseg import animseg_create_fg
+ from animatediff.utils.mask_rembg import rembg_create_fg
+
+ is_danbooru_format = not is_no_danbooru_format
+ with_confidence = not without_confidence
+
+ if use_animeseg and use_rembg:
+ raise ValueError("use_animeseg and use_rembg cannot be enabled at the same time")
+
+ prepare_sam_hq(low_vram)
+ prepare_groundingDINO()
+ prepare_propainter()
+
+ if use_animeseg:
+ prepare_anime_seg()
+
+ time_str = datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
+
+ config_org = stylize_dir.joinpath("prompt.json")
+
+ model_config: ModelConfig = get_model_config(config_org)
+
+ if frame_dir is None:
+ frame_dir = stylize_dir / "00_img2img"
+
+ if not frame_dir.is_dir():
+ raise ValueError(f'{frame_dir=} does not exist.')
+
+ is_img2img = model_config.img2img_map["enable"] if "enable" in model_config.img2img_map else False
+
+
+ create_mask_list = []
+ if "create_mask" in model_config.stylize_config:
+ create_mask_list = model_config.stylize_config["create_mask"]
+ else:
+ raise ValueError('model_config.stylize_config["create_mask"] not found')
+
+ output_list = []
+
+ stylize_frame = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+ frame_len = len(stylize_frame)
+
+ W, H = Image.open(stylize_frame[0]).size
+ org_frame_size = (H,W)
+
+ masked_area = [None for f in range(frame_len)]
+
+ if use_rembg:
+ create_mask_list = ["rembg"]
+ elif use_animeseg:
+ create_mask_list = ["anime-segmentation"]
+
+
+ for i,mask_token in enumerate(create_mask_list):
+ fg_dir = stylize_dir.joinpath(f"fg_{i:02d}_{time_str}")
+ fg_dir.mkdir(parents=True, exist_ok=True)
+
+ create_controlnet_dir( fg_dir / "00_controlnet_image" )
+
+ fg_masked_dir = fg_dir / "00_img2img"
+ fg_masked_dir.mkdir(parents=True, exist_ok=True)
+
+ fg_mask_dir = fg_dir / "00_mask"
+ fg_mask_dir.mkdir(parents=True, exist_ok=True)
+
+ if use_animeseg:
+ masked_area = animseg_create_fg(
+ frame_dir=frame_dir,
+ output_dir=fg_masked_dir,
+ output_mask_dir=fg_mask_dir,
+ masked_area_list=masked_area,
+ mask_padding=mask_padding,
+ bg_color=None if no_gb else (0,255,0),
+ )
+ elif use_rembg:
+ masked_area = rembg_create_fg(
+ frame_dir=frame_dir,
+ output_dir=fg_masked_dir,
+ output_mask_dir=fg_mask_dir,
+ masked_area_list=masked_area,
+ mask_padding=mask_padding,
+ bg_color=None if no_gb else (0,255,0),
+ )
+ else:
+ masked_area = create_fg(
+ mask_token=mask_token,
+ frame_dir=frame_dir,
+ output_dir=fg_masked_dir,
+ output_mask_dir=fg_mask_dir,
+ masked_area_list=masked_area,
+ box_threshold=box_threshold,
+ text_threshold=text_threshold,
+ mask_padding=mask_padding,
+ sam_checkpoint= "data/models/SAM/sam_hq_vit_h.pth" if not low_vram else "data/models/SAM/sam_hq_vit_b.pth",
+ bg_color=None if no_gb else (0,255,0),
+ )
+
+ if not no_crop:
+ frame_size_hw = (masked_area[0].shape[1],masked_area[0].shape[2])
+ cropped_mask_list, mask_pos_list, crop_size_hw = crop_mask_list(masked_area)
+
+ logger.info(f"crop fg_masked_dir")
+ crop_frames(mask_pos_list, crop_size_hw, fg_masked_dir)
+ logger.info(f"crop fg_mask_dir")
+ crop_frames(mask_pos_list, crop_size_hw, fg_mask_dir)
+ save_crop_info(mask_pos_list, crop_size_hw, frame_size_hw, fg_dir / "crop_info.json")
+ else:
+ crop_size_hw = None
+
+ logger.info(f"mask from [{mask_token}] are output to {fg_dir}")
+
+ shutil.copytree(fg_masked_dir, fg_dir / "00_controlnet_image/controlnet_openpose", dirs_exist_ok=True)
+
+ #shutil.copytree(fg_masked_dir, fg_dir / "00_controlnet_image/controlnet_ip2p", dirs_exist_ok=True)
+
+ if crop_size_hw:
+ if crop_size_hw[0] == 0 or crop_size_hw[1] == 0:
+ crop_size_hw = None
+
+ output_list.append((fg_dir, crop_size_hw))
+
+ torch.cuda.empty_cache()
+
+ bg_dir = stylize_dir.joinpath(f"bg_{time_str}")
+ bg_dir.mkdir(parents=True, exist_ok=True)
+ create_controlnet_dir( bg_dir / "00_controlnet_image" )
+ bg_inpaint_dir = bg_dir / "00_img2img"
+ bg_inpaint_dir.mkdir(parents=True, exist_ok=True)
+
+
+ create_bg(frame_dir, bg_inpaint_dir, masked_area,
+ use_half = True,
+ raft_iter = 20,
+ subvideo_length=80 if not low_vram else 50,
+ neighbor_length=10 if not low_vram else 8,
+ ref_stride=10 if not low_vram else 8,
+ low_vram = low_vram,
+ )
+
+ logger.info(f"background are output to {bg_dir}")
+
+ shutil.copytree(bg_inpaint_dir, bg_dir / "00_controlnet_image/controlnet_tile", dirs_exist_ok=True)
+
+ shutil.copytree(bg_inpaint_dir, bg_dir / "00_controlnet_image/controlnet_ip2p", dirs_exist_ok=True)
+
+ output_list.append((bg_dir,None))
+
+ torch.cuda.empty_cache()
+
+ black_list = []
+ if ignore_list.is_file():
+ with open(ignore_list) as f:
+ black_list = [s.strip() for s in f.readlines()]
+
+ for output, size in output_list:
+
+ model_config.prompt_map = get_labels(
+ frame_dir= output / "00_img2img",
+ interval=predicte_interval,
+ general_threshold=general_threshold,
+ character_threshold=character_threshold,
+ ignore_tokens=black_list,
+ with_confidence=with_confidence,
+ is_danbooru_format=is_danbooru_format,
+ is_cpu = False,
+ )
+
+ model_config.controlnet_map["input_image_dir"] = os.path.relpath((output / "00_controlnet_image" ).absolute(), data_dir)
+ model_config.img2img_map["init_img_dir"] = os.path.relpath((output / "00_img2img" ).absolute(), data_dir)
+
+ if size is not None:
+ h, w = size
+ height = 1024 * (h/(h+w))
+ width = 1024 * (w/(h+w))
+ height = int(height//8 * 8)
+ width = int(width//8 * 8)
+
+ model_config.stylize_config["0"]["width"]=width
+ model_config.stylize_config["0"]["height"]=height
+ if "1" in model_config.stylize_config:
+ model_config.stylize_config["1"]["width"]=int(width * 1.25 //8*8)
+ model_config.stylize_config["1"]["height"]=int(height * 1.25 //8*8)
+ else:
+ height, width = org_frame_size
+ model_config.stylize_config["0"]["width"]=width
+ model_config.stylize_config["0"]["height"]=height
+ if "1" in model_config.stylize_config:
+ model_config.stylize_config["1"]["width"]=int(width * 1.25 //8*8)
+ model_config.stylize_config["1"]["height"]=int(height * 1.25 //8*8)
+
+
+
+ save_config_path = output.joinpath("prompt.json")
+ save_config_path.write_text(model_config.json(indent=4), encoding="utf-8")
+
+
+
+
+@stylize.command(no_args_is_help=True)
+def composite(
+ stylize_dir: Annotated[
+ Path,
+ typer.Argument(path_type=Path, file_okay=False, dir_okay=True, exists=True, help="Path to stylize dir"),
+ ] = ...,
+ box_threshold: Annotated[
+ float,
+ typer.Option(
+ "--box_threshold",
+ "-b",
+ min=0.0,
+ max=1.0,
+ help="box_threshold",
+ rich_help_panel="create mask",
+ ),
+ ] = 0.3,
+ text_threshold: Annotated[
+ float,
+ typer.Option(
+ "--text_threshold",
+ "-t",
+ min=0.0,
+ max=1.0,
+ help="text_threshold",
+ rich_help_panel="create mask",
+ ),
+ ] = 0.25,
+ mask_padding: Annotated[
+ int,
+ typer.Option(
+ "--mask_padding",
+ "-mp",
+ min=-100,
+ max=100,
+ help="padding pixel value",
+ rich_help_panel="create mask",
+ ),
+ ] = 0,
+ use_rembg: Annotated[
+ bool,
+ typer.Option(
+ "--use_rembg",
+ "-rem",
+ is_flag=True,
+ help="use \[rembg] instead of \[Sam+GroundingDINO]",
+ rich_help_panel="create mask",
+ ),
+ ] = False,
+ use_animeseg: Annotated[
+ bool,
+ typer.Option(
+ "--use_animeseg",
+ "-anim",
+ is_flag=True,
+ help="use \[anime-segmentation] instead of \[Sam+GroundingDINO]",
+ rich_help_panel="create mask",
+ ),
+ ] = False,
+ low_vram: Annotated[
+ bool,
+ typer.Option(
+ "--low_vram",
+ "-lo",
+ is_flag=True,
+ help="low vram mode",
+ rich_help_panel="create mask/tag",
+ ),
+ ] = False,
+ is_simple_composite: Annotated[
+ bool,
+ typer.Option(
+ "--simple_composite",
+ "-si",
+ is_flag=True,
+ help="simple composite",
+ rich_help_panel="composite",
+ ),
+ ] = False,
+):
+ """composite FG and BG"""
+
+ from animatediff.utils.composite import composite, simple_composite
+ from animatediff.utils.mask import (create_fg, load_frame_list,
+ load_mask_list, restore_position)
+ from animatediff.utils.mask_animseg import animseg_create_fg
+ from animatediff.utils.mask_rembg import rembg_create_fg
+
+ if use_animeseg and use_rembg:
+ raise ValueError("use_animeseg and use_rembg cannot be enabled at the same time")
+
+ prepare_sam_hq(low_vram)
+ if use_animeseg:
+ prepare_anime_seg()
+
+ time_str = datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
+
+ config_org = stylize_dir.joinpath("prompt.json")
+
+ model_config: ModelConfig = get_model_config(config_org)
+
+
+ composite_config = {}
+ if "composite" in model_config.stylize_config:
+ composite_config = model_config.stylize_config["composite"]
+ else:
+ raise ValueError('model_config.stylize_config["composite"] not found')
+
+ save_dir = stylize_dir.joinpath(f"cp_{time_str}")
+ save_dir.mkdir(parents=True, exist_ok=True)
+
+ save_config_path = save_dir.joinpath("prompt.json")
+ save_config_path.write_text(model_config.json(indent=4), encoding="utf-8")
+
+
+ bg_dir = composite_config["bg_frame_dir"]
+ bg_dir = Path(bg_dir)
+ if not bg_dir.is_dir():
+ raise ValueError('model_config.stylize_config["composite"]["bg_frame_dir"] not valid')
+
+ frame_len = len(sorted(glob.glob( os.path.join(bg_dir, "[0-9]*.png"), recursive=False)))
+
+ fg_list = composite_config["fg_list"]
+
+ for i, fg_param in enumerate(fg_list):
+ mask_token = fg_param["mask_prompt"]
+ frame_dir = Path(fg_param["path"])
+ if not frame_dir.is_dir():
+ logger.warn(f"{frame_dir=} not valid -> skip")
+ continue
+
+ mask_dir = Path(fg_param["mask_path"])
+ if not mask_dir.is_dir():
+ logger.info(f"{mask_dir=} not valid -> create mask")
+
+ fg_tmp_dir = save_dir.joinpath(f"fg_{i:02d}_{time_str}")
+ fg_tmp_dir.mkdir(parents=True, exist_ok=True)
+
+ masked_area_list = [None for f in range(frame_len)]
+
+ if use_animeseg:
+ mask_list = animseg_create_fg(
+ frame_dir=frame_dir,
+ output_dir=fg_tmp_dir,
+ output_mask_dir=None,
+ masked_area_list=masked_area_list,
+ mask_padding=mask_padding,
+ )
+ elif use_rembg:
+ mask_list = rembg_create_fg(
+ frame_dir=frame_dir,
+ output_dir=fg_tmp_dir,
+ output_mask_dir=None,
+ masked_area_list=masked_area_list,
+ mask_padding=mask_padding,
+ )
+ else:
+ mask_list = create_fg(
+ mask_token=mask_token,
+ frame_dir=frame_dir,
+ output_dir=fg_tmp_dir,
+ output_mask_dir=None,
+ masked_area_list=masked_area_list,
+ box_threshold=box_threshold,
+ text_threshold=text_threshold,
+ mask_padding=mask_padding,
+ sam_checkpoint= "data/models/SAM/sam_hq_vit_h.pth" if not low_vram else "data/models/SAM/sam_hq_vit_b.pth",
+ )
+
+ else:
+ logger.info(f"use {mask_dir=} as mask")
+
+ masked_area_list = [None for f in range(frame_len)]
+
+ mask_list = load_mask_list(mask_dir, masked_area_list, mask_padding)
+
+ mask_list = [ m.transpose([1,2,0]) if m is not None else m for m in mask_list]
+
+ crop_info_path = frame_dir.parent.parent / "crop_info.json"
+ crop_info={}
+ if crop_info_path.is_file():
+ with open(crop_info_path, mode="rt", encoding="utf-8") as f:
+ crop_info = json.load(f)
+ mask_list = restore_position(mask_list, crop_info)
+
+
+ fg_list = [None for f in range(frame_len)]
+ fg_list = load_frame_list(frame_dir, fg_list, crop_info)
+
+ output_dir = save_dir.joinpath(f"bg_{i:02d}_{time_str}")
+ output_dir.mkdir(parents=True, exist_ok=True)
+
+ if is_simple_composite:
+ simple_composite(bg_dir, fg_list, output_dir, mask_list)
+ else:
+ composite(bg_dir, fg_list, output_dir, mask_list)
+
+ bg_dir = output_dir
+
+
+ from animatediff.generate import save_output
+
+ frames = sorted(glob.glob( os.path.join(bg_dir, "[0-9]*.png"), recursive=False))
+ out_images = []
+ for f in frames:
+ out_images.append(Image.open(f))
+
+ out_file = save_dir.joinpath(f"composite")
+ save_output(out_images,bg_dir,out_file,model_config.output,True,save_frames=None,save_video=None)
+
+ logger.info(f"output to {out_file}")
+
+
+
+
+@stylize.command(no_args_is_help=True)
+def create_region(
+ stylize_dir: Annotated[
+ Path,
+ typer.Argument(path_type=Path, file_okay=False, dir_okay=True, exists=True, help="Path to stylize dir"),
+ ] = ...,
+ frame_dir: Annotated[
+ Path,
+ typer.Option(
+ "--frame_dir",
+ "-f",
+ path_type=Path,
+ file_okay=False,
+ help="Path to source frames directory. default is 'STYLIZE_DIR/00_img2img'",
+ ),
+ ] = None,
+ box_threshold: Annotated[
+ float,
+ typer.Option(
+ "--box_threshold",
+ "-b",
+ min=0.0,
+ max=1.0,
+ help="box_threshold",
+ rich_help_panel="create mask",
+ ),
+ ] = 0.3,
+ text_threshold: Annotated[
+ float,
+ typer.Option(
+ "--text_threshold",
+ "-t",
+ min=0.0,
+ max=1.0,
+ help="text_threshold",
+ rich_help_panel="create mask",
+ ),
+ ] = 0.25,
+ mask_padding: Annotated[
+ int,
+ typer.Option(
+ "--mask_padding",
+ "-mp",
+ min=-100,
+ max=100,
+ help="padding pixel value",
+ rich_help_panel="create mask",
+ ),
+ ] = 0,
+ use_rembg: Annotated[
+ bool,
+ typer.Option(
+ "--use_rembg",
+ "-rem",
+ is_flag=True,
+ help="use [rembg] instead of [Sam+GroundingDINO]",
+ rich_help_panel="create mask",
+ ),
+ ] = False,
+ use_animeseg: Annotated[
+ bool,
+ typer.Option(
+ "--use_animeseg",
+ "-anim",
+ is_flag=True,
+ help="use [anime-segmentation] instead of [Sam+GroundingDINO]",
+ rich_help_panel="create mask",
+ ),
+ ] = False,
+ low_vram: Annotated[
+ bool,
+ typer.Option(
+ "--low_vram",
+ "-lo",
+ is_flag=True,
+ help="low vram mode",
+ rich_help_panel="create mask/tag",
+ ),
+ ] = False,
+ ignore_list: Annotated[
+ Path,
+ typer.Option(
+ "--ignore-list",
+ "-g",
+ path_type=Path,
+ dir_okay=False,
+ exists=True,
+ help="path to ignore token list file",
+ rich_help_panel="create tag",
+ ),
+ ] = Path("config/prompts/ignore_tokens.txt"),
+ predicte_interval: Annotated[
+ int,
+ typer.Option(
+ "--predicte-interval",
+ "-p",
+ min=1,
+ max=120,
+ help="Interval of frames to be predicted",
+ rich_help_panel="create tag",
+ ),
+ ] = 1,
+ general_threshold: Annotated[
+ float,
+ typer.Option(
+ "--threshold",
+ "-th",
+ min=0.0,
+ max=1.0,
+ help="threshold for general token confidence",
+ rich_help_panel="create tag",
+ ),
+ ] = 0.35,
+ character_threshold: Annotated[
+ float,
+ typer.Option(
+ "--threshold2",
+ "-th2",
+ min=0.0,
+ max=1.0,
+ help="threshold for character token confidence",
+ rich_help_panel="create tag",
+ ),
+ ] = 0.85,
+ without_confidence: Annotated[
+ bool,
+ typer.Option(
+ "--no-confidence-format",
+ "-ncf",
+ is_flag=True,
+ help="confidence token format or not. ex. '(close-up:0.57), (monochrome:1.1)' -> 'close-up, monochrome'",
+ rich_help_panel="create tag",
+ ),
+ ] = False,
+ is_no_danbooru_format: Annotated[
+ bool,
+ typer.Option(
+ "--no-danbooru-format",
+ "-ndf",
+ is_flag=True,
+ help="danbooru token format or not. ex. 'bandaid_on_leg, short_hair' -> 'bandaid on leg, short hair'",
+ rich_help_panel="create tag",
+ ),
+ ] = False,
+):
+ """Create region from prompt"""
+ from animatediff.utils.mask import create_bg, create_fg
+ from animatediff.utils.mask_animseg import animseg_create_fg
+ from animatediff.utils.mask_rembg import rembg_create_fg
+
+ is_danbooru_format = not is_no_danbooru_format
+ with_confidence = not without_confidence
+
+ if use_animeseg and use_rembg:
+ raise ValueError("use_animeseg and use_rembg cannot be enabled at the same time")
+
+ prepare_sam_hq(low_vram)
+ prepare_groundingDINO()
+ prepare_propainter()
+
+ if use_animeseg:
+ prepare_anime_seg()
+
+ time_str = datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
+
+ config_org = stylize_dir.joinpath("prompt.json")
+
+ model_config: ModelConfig = get_model_config(config_org)
+
+ if frame_dir is None:
+ frame_dir = stylize_dir / "00_img2img"
+
+ if not frame_dir.is_dir():
+ raise ValueError(f'{frame_dir=} does not exist.')
+
+
+ create_mask_list = []
+ if "create_mask" in model_config.stylize_config:
+ create_mask_list = model_config.stylize_config["create_mask"]
+ else:
+ raise ValueError('model_config.stylize_config["create_mask"] not found')
+
+ output_list = []
+
+ stylize_frame = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+ frame_len = len(stylize_frame)
+
+ masked_area = [None for f in range(frame_len)]
+
+ if use_rembg:
+ create_mask_list = ["rembg"]
+ elif use_animeseg:
+ create_mask_list = ["anime-segmentation"]
+
+
+ for i,mask_token in enumerate(create_mask_list):
+ fg_dir = stylize_dir.joinpath(f"r_fg_{i:02d}_{time_str}")
+ fg_dir.mkdir(parents=True, exist_ok=True)
+
+ fg_masked_dir = fg_dir / "00_tmp_masked"
+ fg_masked_dir.mkdir(parents=True, exist_ok=True)
+
+ fg_mask_dir = fg_dir / "00_mask"
+ fg_mask_dir.mkdir(parents=True, exist_ok=True)
+
+ if use_animeseg:
+ masked_area = animseg_create_fg(
+ frame_dir=frame_dir,
+ output_dir=fg_masked_dir,
+ output_mask_dir=fg_mask_dir,
+ masked_area_list=masked_area,
+ mask_padding=mask_padding,
+ bg_color=(0,255,0),
+ )
+ elif use_rembg:
+ masked_area = rembg_create_fg(
+ frame_dir=frame_dir,
+ output_dir=fg_masked_dir,
+ output_mask_dir=fg_mask_dir,
+ masked_area_list=masked_area,
+ mask_padding=mask_padding,
+ bg_color=(0,255,0),
+ )
+ else:
+ masked_area = create_fg(
+ mask_token=mask_token,
+ frame_dir=frame_dir,
+ output_dir=fg_masked_dir,
+ output_mask_dir=fg_mask_dir,
+ masked_area_list=masked_area,
+ box_threshold=box_threshold,
+ text_threshold=text_threshold,
+ mask_padding=mask_padding,
+ sam_checkpoint= "data/models/SAM/sam_hq_vit_h.pth" if not low_vram else "data/models/SAM/sam_hq_vit_b.pth",
+ bg_color=(0,255,0),
+ )
+
+ logger.info(f"mask from [{mask_token}] are output to {fg_dir}")
+
+ output_list.append((fg_dir, fg_masked_dir, fg_mask_dir))
+
+ torch.cuda.empty_cache()
+
+ bg_dir = stylize_dir.joinpath(f"r_bg_{time_str}")
+ bg_dir.mkdir(parents=True, exist_ok=True)
+
+ bg_inpaint_dir = bg_dir / "00_tmp_inpainted"
+ bg_inpaint_dir.mkdir(parents=True, exist_ok=True)
+
+
+ create_bg(frame_dir, bg_inpaint_dir, masked_area,
+ use_half = True,
+ raft_iter = 20,
+ subvideo_length=80 if not low_vram else 50,
+ neighbor_length=10 if not low_vram else 8,
+ ref_stride=10 if not low_vram else 8,
+ low_vram = low_vram,
+ )
+
+ logger.info(f"background are output to {bg_dir}")
+
+
+ output_list.append((bg_dir,bg_inpaint_dir,None))
+
+ torch.cuda.empty_cache()
+
+ black_list = []
+ if ignore_list.is_file():
+ with open(ignore_list) as f:
+ black_list = [s.strip() for s in f.readlines()]
+
+ black_list.append("simple_background")
+ black_list.append("green_background")
+
+ region_map = {}
+
+ for i, (output_root, masked_dir, mask_dir) in enumerate(output_list):
+
+ prompt_map = get_labels(
+ frame_dir= masked_dir,
+ interval=predicte_interval,
+ general_threshold=general_threshold,
+ character_threshold=character_threshold,
+ ignore_tokens=black_list,
+ with_confidence=with_confidence,
+ is_danbooru_format=is_danbooru_format,
+ is_cpu = False,
+ )
+
+ if mask_dir:
+
+ ipadapter_dir = output_root / "00_ipadapter"
+ ipadapter_dir.mkdir(parents=True, exist_ok=True)
+
+ region_map[str(i)]={
+ "enable": True,
+ "crop_generation_rate": 0.0,
+ "mask_dir" : os.path.relpath(mask_dir.absolute(), data_dir),
+ "save_mask": True,
+ "is_init_img" : False,
+ "condition" : {
+ "prompt_fixed_ratio": 0.5,
+ "head_prompt": "",
+ "prompt_map": prompt_map,
+ "tail_prompt": "",
+ "ip_adapter_map": {
+ "enable": True,
+ "input_image_dir": os.path.relpath(ipadapter_dir.absolute(), data_dir),
+ "prompt_fixed_ratio": 0.5,
+ "save_input_image": True,
+ "resized_to_square": False
+ }
+ }
+ }
+ else:
+ region_map["background"]={
+ "is_init_img" : False,
+ "hint" : "background's condition refers to the one in root"
+ }
+
+ model_config.prompt_map = prompt_map
+
+
+ model_config.region_map =region_map
+
+
+ config_org.write_text(model_config.json(indent=4), encoding="utf-8")
+
+
diff --git a/animate/src/animatediff/utils/__init__.py b/animate/src/animatediff/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/animate/src/animatediff/utils/civitai2config.py b/animate/src/animatediff/utils/civitai2config.py
new file mode 100644
index 0000000000000000000000000000000000000000..c1ee6a4a84a2068478c4654858856e2fa2339c08
--- /dev/null
+++ b/animate/src/animatediff/utils/civitai2config.py
@@ -0,0 +1,122 @@
+import glob
+import json
+import logging
+import os
+import re
+import shutil
+from pathlib import Path
+
+from animatediff import get_dir
+
+logger = logging.getLogger(__name__)
+
+data_dir = get_dir("data")
+
+extra_loading_regex = r'(<[^>]+?>)'
+
+def generate_config_from_civitai_info(
+ lora_dir:Path,
+ config_org:Path,
+ out_dir:Path,
+ lora_weight:float,
+):
+ lora_abs_dir = lora_dir.absolute()
+ config_org = config_org.absolute()
+ out_dir = out_dir.absolute()
+
+ civitais = sorted(glob.glob( os.path.join(lora_abs_dir, "*.civitai.info"), recursive=False))
+
+ with open(config_org, "r") as cf:
+ org_config = json.load(cf)
+
+ for civ in civitais:
+
+ logger.info(f"convert {civ}")
+
+ with open(civ, "r") as f:
+ # trim .civitai.info
+ name = os.path.splitext(os.path.splitext(os.path.basename(civ))[0])[0]
+
+ output_path = out_dir.joinpath(name + ".json")
+
+ if os.path.isfile(output_path):
+ logger.info("already converted -> skip")
+ continue
+
+ if os.path.isfile( lora_abs_dir.joinpath(name + ".safetensors")):
+ lora_path = os.path.relpath(lora_abs_dir.joinpath(name + ".safetensors"), data_dir)
+ elif os.path.isfile( lora_abs_dir.joinpath(name + ".ckpt")):
+ lora_path = os.path.relpath(lora_abs_dir.joinpath(name + ".ckpt"), data_dir)
+ else:
+ logger.info("lora file not found -> skip")
+ continue
+
+ info = json.load(f)
+
+ if not info:
+ logger.info(f"empty civitai info -> skip")
+ continue
+
+ if info["model"]["type"] not in ("LORA","lora"):
+ logger.info(f"unsupported type {info['model']['type']} -> skip")
+ continue
+
+ new_config = org_config.copy()
+
+ new_config["name"] = name
+
+ new_prompt_map = {}
+ new_n_prompt = ""
+ new_seed = -1
+
+
+ raw_prompt_map = {}
+
+ i = 0
+ for img_info in info["images"]:
+ if img_info["meta"]:
+ try:
+ raw_prompt = img_info["meta"]["prompt"]
+ except Exception as e:
+ logger.info("missing prompt")
+ continue
+
+ raw_prompt_map[str(10000 + i*32)] = raw_prompt
+
+ new_prompt_map[str(i*32)] = re.sub(extra_loading_regex, '', raw_prompt)
+
+ if not new_n_prompt:
+ try:
+ new_n_prompt = img_info["meta"]["negativePrompt"]
+ except Exception as e:
+ new_n_prompt = ""
+ if new_seed == -1:
+ try:
+ new_seed = img_info["meta"]["seed"]
+ except Exception as e:
+ new_seed = -1
+
+ i += 1
+
+ if not new_prompt_map:
+ new_prompt_map[str(0)] = ""
+
+ for k in raw_prompt_map:
+ # comment
+ new_prompt_map[k] = raw_prompt_map[k]
+
+ new_config["prompt_map"] = new_prompt_map
+ new_config["n_prompt"] = [new_n_prompt]
+ new_config["seed"] = [new_seed]
+
+ new_config["lora_map"] = {lora_path.replace(os.sep,'/'):lora_weight}
+
+ with open( out_dir.joinpath(name + ".json"), 'w') as wf:
+ json.dump(new_config, wf, indent=4)
+ logger.info("converted!")
+
+ preview = lora_abs_dir.joinpath(name + ".preview.png")
+ if preview.is_file():
+ shutil.copy(preview, out_dir.joinpath(name + ".preview.png"))
+
+
diff --git a/animate/src/animatediff/utils/composite.py b/animate/src/animatediff/utils/composite.py
new file mode 100644
index 0000000000000000000000000000000000000000..191a8553dcc9e512ecd4e2e5e5740e6622634475
--- /dev/null
+++ b/animate/src/animatediff/utils/composite.py
@@ -0,0 +1,202 @@
+import glob
+import logging
+import os
+import shutil
+from pathlib import Path
+
+import cv2
+import numpy as np
+import torch
+import torch.nn.functional as F
+from PIL import Image
+from tqdm.rich import tqdm
+
+logger = logging.getLogger(__name__)
+
+
+#https://github.com/jinwonkim93/laplacian-pyramid-blend
+#https://blog.shikoan.com/pytorch-laplacian-pyramid/
+class LaplacianPyramidBlender:
+
+ device = None
+
+ def get_gaussian_kernel(self):
+ kernel = np.array([
+ [1, 4, 6, 4, 1],
+ [4, 16, 24, 16, 4],
+ [6, 24, 36, 24, 6],
+ [4, 16, 24, 16, 4],
+ [1, 4, 6, 4, 1]], np.float32) / 256.0
+ gaussian_k = torch.as_tensor(kernel.reshape(1, 1, 5, 5),device=self.device)
+ return gaussian_k
+
+ def pyramid_down(self, image):
+ with torch.no_grad():
+ gaussian_k = self.get_gaussian_kernel()
+ multiband = [F.conv2d(image[:, i:i + 1,:,:], gaussian_k, padding=2, stride=2) for i in range(3)]
+ down_image = torch.cat(multiband, dim=1)
+ return down_image
+
+ def pyramid_up(self, image, size = None):
+ with torch.no_grad():
+ gaussian_k = self.get_gaussian_kernel()
+ if size is None:
+ upsample = F.interpolate(image, scale_factor=2)
+ else:
+ upsample = F.interpolate(image, size=size)
+ multiband = [F.conv2d(upsample[:, i:i + 1,:,:], gaussian_k, padding=2) for i in range(3)]
+ up_image = torch.cat(multiband, dim=1)
+ return up_image
+
+ def gaussian_pyramid(self, original, n_pyramids):
+ x = original
+ # pyramid down
+ pyramids = [original]
+ for i in range(n_pyramids):
+ x = self.pyramid_down(x)
+ pyramids.append(x)
+ return pyramids
+
+ def laplacian_pyramid(self, original, n_pyramids):
+ pyramids = self.gaussian_pyramid(original, n_pyramids)
+
+ # pyramid up - diff
+ laplacian = []
+ for i in range(len(pyramids) - 1):
+ diff = pyramids[i] - self.pyramid_up(pyramids[i + 1], pyramids[i].shape[2:])
+ laplacian.append(diff)
+
+ laplacian.append(pyramids[-1])
+ return laplacian
+
+ def laplacian_pyramid_blending_with_mask(self, src, target, mask, num_levels = 9):
+ # assume mask is float32 [0,1]
+
+ # generate Gaussian pyramid for src,target and mask
+
+ Gsrc = torch.as_tensor(np.expand_dims(src, axis=0), device=self.device)
+ Gtarget = torch.as_tensor(np.expand_dims(target, axis=0), device=self.device)
+ Gmask = torch.as_tensor(np.expand_dims(mask, axis=0), device=self.device)
+
+ lpA = self.laplacian_pyramid(Gsrc,num_levels)[::-1]
+ lpB = self.laplacian_pyramid(Gtarget,num_levels)[::-1]
+ gpMr = self.gaussian_pyramid(Gmask,num_levels)[::-1]
+
+ # Now blend images according to mask in each level
+ LS = []
+ for idx, (la,lb,Gmask) in enumerate(zip(lpA,lpB,gpMr)):
+ lo = lb * (1.0 - Gmask)
+ if idx <= 2:
+ lo += lb * Gmask
+ else:
+ lo += la * Gmask
+ LS.append(lo)
+
+ # now reconstruct
+ ls_ = LS.pop(0)
+ for lap in LS:
+ ls_ = self.pyramid_up(ls_, lap.shape[2:]) + lap
+
+ result = ls_.squeeze(dim=0).to('cpu').detach().numpy().copy()
+
+ return result
+
+ def __call__(self,
+ src_image: np.ndarray,
+ target_image: np.ndarray,
+ mask_image: np.ndarray,
+ device
+ ):
+
+ self.device = device
+
+ num_levels = int(np.log2(src_image.shape[0]))
+ #normalize image to 0, 1
+ mask_image = np.clip(mask_image, 0, 1).transpose([2, 0, 1])
+
+ src_image = src_image.transpose([2, 0, 1]).astype(np.float32) / 255.0
+ target_image = target_image.transpose([2, 0, 1]).astype(np.float32) / 255.0
+ composite_image = self.laplacian_pyramid_blending_with_mask(src_image, target_image, mask_image, num_levels)
+ composite_image = np.clip(composite_image*255, 0 , 255).astype(np.uint8)
+ composite_image=composite_image.transpose([1, 2, 0])
+ return composite_image
+
+
+def composite(bg_dir, fg_list, output_dir, masked_area_list, device="cuda"):
+ bg_list = sorted(glob.glob( os.path.join(bg_dir ,"[0-9]*.png"), recursive=False))
+
+ blender = LaplacianPyramidBlender()
+
+ for bg, fg_array, mask in tqdm(zip(bg_list, fg_list, masked_area_list),total=len(bg_list), desc="compositing"):
+ name = Path(bg).name
+ save_path = output_dir / name
+
+ if fg_array is None:
+ logger.info(f"composite fg_array is None -> skip")
+ shutil.copy(bg, save_path)
+ continue
+
+ if mask is None:
+ logger.info(f"mask is None -> skip")
+ shutil.copy(bg, save_path)
+ continue
+
+ bg = np.asarray(Image.open(bg)).copy()
+ fg = fg_array
+ mask = np.concatenate([mask, mask, mask], 2)
+
+ h, w, _ = bg.shape
+
+ fg = cv2.resize(fg, dsize=(w,h))
+ mask = cv2.resize(mask, dsize=(w,h))
+
+
+ mask = mask.astype(np.float32)
+# mask = mask * 255
+ mask = cv2.GaussianBlur(mask, (15, 15), 0)
+ mask = mask / 255
+
+ fg = fg * mask + bg * (1-mask)
+
+ img = blender(fg, bg, mask,device)
+
+
+ img = Image.fromarray(img)
+ img.save(save_path)
+
+def simple_composite(bg_dir, fg_list, output_dir, masked_area_list, device="cuda"):
+ bg_list = sorted(glob.glob( os.path.join(bg_dir ,"[0-9]*.png"), recursive=False))
+
+ for bg, fg_array, mask in tqdm(zip(bg_list, fg_list, masked_area_list),total=len(bg_list), desc="compositing"):
+ name = Path(bg).name
+ save_path = output_dir / name
+
+ if fg_array is None:
+ logger.info(f"composite fg_array is None -> skip")
+ shutil.copy(bg, save_path)
+ continue
+
+ if mask is None:
+ logger.info(f"mask is None -> skip")
+ shutil.copy(bg, save_path)
+ continue
+
+ bg = np.asarray(Image.open(bg)).copy()
+ fg = fg_array
+ mask = np.concatenate([mask, mask, mask], 2)
+
+ h, w, _ = bg.shape
+
+ fg = cv2.resize(fg, dsize=(w,h))
+ mask = cv2.resize(mask, dsize=(w,h))
+
+
+ mask = mask.astype(np.float32)
+ mask = cv2.GaussianBlur(mask, (15, 15), 0)
+ mask = mask / 255
+
+ img = fg * mask + bg * (1-mask)
+ img = img.clip(0 , 255).astype(np.uint8)
+
+ img = Image.fromarray(img)
+ img.save(save_path)
\ No newline at end of file
diff --git a/animate/src/animatediff/utils/control_net_lllite.py b/animate/src/animatediff/utils/control_net_lllite.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c83cd4d75b44a48ea8dfa7b20e7bf7fb95957cf
--- /dev/null
+++ b/animate/src/animatediff/utils/control_net_lllite.py
@@ -0,0 +1,526 @@
+# https://github.com/kohya-ss/sd-scripts/blob/main/networks/control_net_lllite.py
+
+import bisect
+import os
+from typing import Any, List, Mapping, Optional, Type
+
+import torch
+
+from animatediff.utils.util import show_bytes
+
+# input_blocksに適用するかどうか / if True, input_blocks are not applied
+SKIP_INPUT_BLOCKS = False
+
+# output_blocksに適用するかどうか / if True, output_blocks are not applied
+SKIP_OUTPUT_BLOCKS = True
+
+# conv2dに適用するかどうか / if True, conv2d are not applied
+SKIP_CONV2D = False
+
+# transformer_blocksのみに適用するかどうか。Trueの場合、ResBlockには適用されない
+# if True, only transformer_blocks are applied, and ResBlocks are not applied
+TRANSFORMER_ONLY = True # if True, SKIP_CONV2D is ignored because conv2d is not used in transformer_blocks
+
+# Trueならattn1とattn2にのみ適用し、ffなどには適用しない / if True, apply only to attn1 and attn2, not to ff etc.
+ATTN1_2_ONLY = True
+
+# Trueならattn1のQKV、attn2のQにのみ適用する、ATTN1_2_ONLY指定時のみ有効 / if True, apply only to attn1 QKV and attn2 Q, only valid when ATTN1_2_ONLY is specified
+ATTN_QKV_ONLY = True
+
+# Trueならattn1やffなどにのみ適用し、attn2などには適用しない / if True, apply only to attn1 and ff, not to attn2
+# ATTN1_2_ONLYと同時にTrueにできない / cannot be True at the same time as ATTN1_2_ONLY
+ATTN1_ETC_ONLY = False # True
+
+# transformer_blocksの最大インデックス。Noneなら全てのtransformer_blocksに適用
+# max index of transformer_blocks. if None, apply to all transformer_blocks
+TRANSFORMER_MAX_BLOCK_INDEX = None
+
+
+class LLLiteModule(torch.nn.Module):
+ def __init__(self, depth, cond_emb_dim, name, org_module, mlp_dim, dropout=None, multiplier=1.0):
+ super().__init__()
+ self.cond_cache ={}
+
+ self.is_conv2d = org_module.__class__.__name__ == "Conv2d" or org_module.__class__.__name__ == "LoRACompatibleConv"
+ self.lllite_name = name
+ self.cond_emb_dim = cond_emb_dim
+ self.org_module = [org_module]
+ self.dropout = dropout
+ self.multiplier = multiplier
+
+ if self.is_conv2d:
+ in_dim = org_module.in_channels
+ else:
+ in_dim = org_module.in_features
+
+ # conditioning1はconditioning imageを embedding する。timestepごとに呼ばれない
+ # conditioning1 embeds conditioning image. it is not called for each timestep
+ modules = []
+ modules.append(torch.nn.Conv2d(3, cond_emb_dim // 2, kernel_size=4, stride=4, padding=0)) # to latent (from VAE) size
+ if depth == 1:
+ modules.append(torch.nn.ReLU(inplace=True))
+ modules.append(torch.nn.Conv2d(cond_emb_dim // 2, cond_emb_dim, kernel_size=2, stride=2, padding=0))
+ elif depth == 2:
+ modules.append(torch.nn.ReLU(inplace=True))
+ modules.append(torch.nn.Conv2d(cond_emb_dim // 2, cond_emb_dim, kernel_size=4, stride=4, padding=0))
+ elif depth == 3:
+ # kernel size 8は大きすぎるので、4にする / kernel size 8 is too large, so set it to 4
+ modules.append(torch.nn.ReLU(inplace=True))
+ modules.append(torch.nn.Conv2d(cond_emb_dim // 2, cond_emb_dim // 2, kernel_size=4, stride=4, padding=0))
+ modules.append(torch.nn.ReLU(inplace=True))
+ modules.append(torch.nn.Conv2d(cond_emb_dim // 2, cond_emb_dim, kernel_size=2, stride=2, padding=0))
+
+ self.conditioning1 = torch.nn.Sequential(*modules)
+
+ # downで入力の次元数を削減する。LoRAにヒントを得ていることにする
+ # midでconditioning image embeddingと入力を結合する
+ # upで元の次元数に戻す
+ # これらはtimestepごとに呼ばれる
+ # reduce the number of input dimensions with down. inspired by LoRA
+ # combine conditioning image embedding and input with mid
+ # restore to the original dimension with up
+ # these are called for each timestep
+
+ if self.is_conv2d:
+ self.down = torch.nn.Sequential(
+ torch.nn.Conv2d(in_dim, mlp_dim, kernel_size=1, stride=1, padding=0),
+ torch.nn.ReLU(inplace=True),
+ )
+ self.mid = torch.nn.Sequential(
+ torch.nn.Conv2d(mlp_dim + cond_emb_dim, mlp_dim, kernel_size=1, stride=1, padding=0),
+ torch.nn.ReLU(inplace=True),
+ )
+ self.up = torch.nn.Sequential(
+ torch.nn.Conv2d(mlp_dim, in_dim, kernel_size=1, stride=1, padding=0),
+ )
+ else:
+ # midの前にconditioningをreshapeすること / reshape conditioning before mid
+ self.down = torch.nn.Sequential(
+ torch.nn.Linear(in_dim, mlp_dim),
+ torch.nn.ReLU(inplace=True),
+ )
+ self.mid = torch.nn.Sequential(
+ torch.nn.Linear(mlp_dim + cond_emb_dim, mlp_dim),
+ torch.nn.ReLU(inplace=True),
+ )
+ self.up = torch.nn.Sequential(
+ torch.nn.Linear(mlp_dim, in_dim),
+ )
+
+ # Zero-Convにする / set to Zero-Conv
+ torch.nn.init.zeros_(self.up[0].weight) # zero conv
+
+ self.depth = depth # 1~3
+ self.cond_emb = None
+ self.batch_cond_only = False # Trueなら推論時のcondにのみ適用する / if True, apply only to cond at inference
+ self.use_zeros_for_batch_uncond = False # Trueならuncondのconditioningを0にする / if True, set uncond conditioning to 0
+
+ # batch_cond_onlyとuse_zeros_for_batch_uncondはどちらも適用すると生成画像の色味がおかしくなるので実際には使えそうにない
+ # Controlの種類によっては使えるかも
+ # both batch_cond_only and use_zeros_for_batch_uncond make the color of the generated image strange, so it doesn't seem to be usable in practice
+ # it may be available depending on the type of Control
+
+ def _set_cond_image(self, cond_image):
+ r"""
+ 中でモデルを呼び出すので必要ならwith torch.no_grad()で囲む
+ / call the model inside, so if necessary, surround it with torch.no_grad()
+ """
+ if cond_image is None:
+ self.cond_emb = None
+ return
+
+ # timestepごとに呼ばれないので、あらかじめ計算しておく / it is not called for each timestep, so calculate it in advance
+ # print(f"C {self.lllite_name}, cond_image.shape={cond_image.shape}")
+ cx = self.conditioning1(cond_image)
+ if not self.is_conv2d:
+ # reshape / b,c,h,w -> b,h*w,c
+ n, c, h, w = cx.shape
+ cx = cx.view(n, c, h * w).permute(0, 2, 1)
+ self.cond_emb = cx
+
+ def set_cond_image(self, cond_image, cond_key):
+ self.cond_image = cond_image
+ self.cond_key = cond_key
+ #self.cond_emb = None
+ self.cond_emb = self.get_cond_emb(self.cond_key, "cuda", torch.float16)
+
+ def set_batch_cond_only(self, cond_only, zeros):
+ self.batch_cond_only = cond_only
+ self.use_zeros_for_batch_uncond = zeros
+
+ def apply_to(self):
+ self.org_forward = self.org_module[0].forward
+ self.org_module[0].forward = self.forward
+
+ def unapply_to(self):
+ self.org_module[0].forward = self.org_forward
+ self.cond_cache ={}
+
+ def get_cond_emb(self, key, device, dtype):
+ #if key in self.cond_cache:
+ # return self.cond_cache[key].to(device, dtype=dtype, non_blocking=True)
+ cx = self.conditioning1(self.cond_image.to(device, dtype=dtype))
+ if not self.is_conv2d:
+ # reshape / b,c,h,w -> b,h*w,c
+ n, c, h, w = cx.shape
+ cx = cx.view(n, c, h * w).permute(0, 2, 1)
+ #self.cond_cache[key] = cx.to("cpu", non_blocking=True)
+ return cx
+
+
+ def forward(self, x, scale=1.0):
+ r"""
+ 学習用の便利forward。元のモジュールのforwardを呼び出す
+ / convenient forward for training. call the forward of the original module
+ """
+# if self.multiplier == 0.0 or self.cond_emb is None:
+ if (type(self.multiplier) is int and self.multiplier == 0.0) or self.cond_emb is None:
+ return self.org_forward(x)
+
+ if self.cond_emb is None:
+ # print(f"cond_emb is None, {self.name}")
+ '''
+ cx = self.conditioning1(self.cond_image.to(x.device, dtype=x.dtype))
+ if not self.is_conv2d:
+ # reshape / b,c,h,w -> b,h*w,c
+ n, c, h, w = cx.shape
+ cx = cx.view(n, c, h * w).permute(0, 2, 1)
+ #show_bytes("self.conditioning1", self.conditioning1)
+ #show_bytes("cx", cx)
+ '''
+ self.cond_emb = self.get_cond_emb(self.cond_key, x.device, x.dtype)
+
+
+ cx = self.cond_emb
+
+ if not self.batch_cond_only and x.shape[0] // 2 == cx.shape[0]: # inference only
+ cx = cx.repeat(2, 1, 1, 1) if self.is_conv2d else cx.repeat(2, 1, 1)
+ if self.use_zeros_for_batch_uncond:
+ cx[0::2] = 0.0 # uncond is zero
+ # print(f"C {self.lllite_name}, x.shape={x.shape}, cx.shape={cx.shape}")
+
+ # downで入力の次元数を削減し、conditioning image embeddingと結合する
+ # 加算ではなくchannel方向に結合することで、うまいこと混ぜてくれることを期待している
+ # down reduces the number of input dimensions and combines it with conditioning image embedding
+ # we expect that it will mix well by combining in the channel direction instead of adding
+
+ cx = torch.cat([cx, self.down(x if not self.batch_cond_only else x[1::2])], dim=1 if self.is_conv2d else 2)
+ cx = self.mid(cx)
+
+ if self.dropout is not None and self.training:
+ cx = torch.nn.functional.dropout(cx, p=self.dropout)
+
+ cx = self.up(cx) * self.multiplier
+
+ #print(f"{self.multiplier=}")
+ #print(f"{cx.shape=}")
+
+ #mul = torch.tensor(self.multiplier).to(x.device, dtype=x.dtype)
+ #cx = cx * mul[:,None,None]
+
+ # residual (x) を加算して元のforwardを呼び出す / add residual (x) and call the original forward
+ if self.batch_cond_only:
+ zx = torch.zeros_like(x)
+ zx[1::2] += cx
+ cx = zx
+
+ x = self.org_forward(x + cx) # ここで元のモジュールを呼び出す / call the original module here
+ return x
+
+
+
+
+class ControlNetLLLite(torch.nn.Module):
+ UNET_TARGET_REPLACE_MODULE = ["Transformer2DModel"]
+ UNET_TARGET_REPLACE_MODULE_CONV2D_3X3 = ["ResnetBlock2D", "Downsample2D", "Upsample2D"]
+
+ def __init__(
+ self,
+ unet,
+ cond_emb_dim: int = 16,
+ mlp_dim: int = 16,
+ dropout: Optional[float] = None,
+ varbose: Optional[bool] = False,
+ multiplier: Optional[float] = 1.0,
+ ) -> None:
+ super().__init__()
+ # self.unets = [unet]
+
+ def create_modules(
+ root_module: torch.nn.Module,
+ target_replace_modules: List[torch.nn.Module],
+ module_class: Type[object],
+ ) -> List[torch.nn.Module]:
+ prefix = "lllite_unet"
+
+ modules = []
+ for name, module in root_module.named_modules():
+ if module.__class__.__name__ in target_replace_modules:
+ for child_name, child_module in module.named_modules():
+ is_linear = child_module.__class__.__name__ == "Linear" or child_module.__class__.__name__ == "LoRACompatibleLinear"
+ is_conv2d = child_module.__class__.__name__ == "Conv2d" or child_module.__class__.__name__ == "LoRACompatibleConv"
+
+ if is_linear or (is_conv2d and not SKIP_CONV2D):
+ # block indexからdepthを計算: depthはconditioningのサイズやチャネルを計算するのに使う
+ # block index to depth: depth is using to calculate conditioning size and channels
+ #print(f"{name=} {child_name=}")
+
+ #block_name, index1, index2 = (name + "." + child_name).split(".")[:3]
+ #index1 = int(index1)
+ block_name, num1, block_name2 ,num2 = (name + "." + child_name).split(".")[:4]
+
+ #if block_name == "input_blocks":
+ """
+ hf_down_res_prefix = f"down_blocks.{i}.resnets.{j}."
+ sd_down_res_prefix = f"input_blocks.{3*i + j + 1}.0."
+
+ hf_downsample_prefix = f"down_blocks.{i}.downsamplers.0.conv."
+ sd_downsample_prefix = f"input_blocks.{3*(i+1)}.0.op."
+ """
+ if block_name == "down_blocks" and block_name2=="downsamplers":
+ index1 = 3*(int(num1)+1)
+ if SKIP_INPUT_BLOCKS:
+ continue
+ depth = 1 if index1 <= 2 else (2 if index1 <= 5 else 3)
+ elif block_name == "down_blocks":
+ index1 = 3*int(num1)+int(num2)+1
+ if SKIP_INPUT_BLOCKS:
+ continue
+ depth = 1 if index1 <= 2 else (2 if index1 <= 5 else 3)
+
+ #elif block_name == "middle_block":
+ elif block_name == "mid_block":
+ depth = 3
+
+ #elif block_name == "output_blocks":
+ """
+ hf_up_res_prefix = f"up_blocks.{i}.resnets.{j}."
+ sd_up_res_prefix = f"output_blocks.{3*i + j}.0."
+
+ hf_upsample_prefix = f"up_blocks.{i}.upsamplers.0."
+ sd_upsample_prefix = f"output_blocks.{3*i + 2}.{2}." # change for sdxl
+ """
+ elif block_name == "up_blocks" and block_name2=="upsamplers":
+
+ index1 = 3*int(num1)+2
+ if SKIP_OUTPUT_BLOCKS:
+ continue
+ depth = 3 if index1 <= 2 else (2 if index1 <= 5 else 1)
+ #if int(index2) >= 2:
+ if block_name2 == "upsamplers":
+ depth -= 1
+ elif block_name == "up_blocks":
+ index1 = 3*int(num1)+int(num2)
+ if SKIP_OUTPUT_BLOCKS:
+ continue
+ depth = 3 if index1 <= 2 else (2 if index1 <= 5 else 1)
+ #if int(index2) >= 2:
+ if block_name2 == "upsamplers":
+ depth -= 1
+ else:
+ raise NotImplementedError()
+
+ lllite_name = prefix + "." + name + "." + child_name
+ lllite_name = lllite_name.replace(".", "_")
+
+ if TRANSFORMER_MAX_BLOCK_INDEX is not None:
+ p = lllite_name.find("transformer_blocks")
+ if p >= 0:
+ tf_index = int(lllite_name[p:].split("_")[2])
+ if tf_index > TRANSFORMER_MAX_BLOCK_INDEX:
+ continue
+
+ # time embは適用外とする
+ # attn2のconditioning (CLIPからの入力) はshapeが違うので適用できない
+ # time emb is not applied
+ # attn2 conditioning (input from CLIP) cannot be applied because the shape is different
+ '''
+ if "emb_layers" in lllite_name or (
+ "attn2" in lllite_name and ("to_k" in lllite_name or "to_v" in lllite_name)
+ ):
+ continue
+ '''
+ #("emb_layers.1.", "time_emb_proj."),
+ if "time_emb_proj" in lllite_name or (
+ "attn2" in lllite_name and ("to_k" in lllite_name or "to_v" in lllite_name)
+ ):
+ continue
+
+ if ATTN1_2_ONLY:
+ if not ("attn1" in lllite_name or "attn2" in lllite_name):
+ continue
+ if ATTN_QKV_ONLY:
+ if "to_out" in lllite_name:
+ continue
+
+ if ATTN1_ETC_ONLY:
+ if "proj_out" in lllite_name:
+ pass
+ elif "attn1" in lllite_name and (
+ "to_k" in lllite_name or "to_v" in lllite_name or "to_out" in lllite_name
+ ):
+ pass
+ elif "ff_net_2" in lllite_name:
+ pass
+ else:
+ continue
+
+ module = module_class(
+ depth,
+ cond_emb_dim,
+ lllite_name,
+ child_module,
+ mlp_dim,
+ dropout=dropout,
+ multiplier=multiplier,
+ )
+ modules.append(module)
+ return modules
+
+ target_modules = ControlNetLLLite.UNET_TARGET_REPLACE_MODULE
+ if not TRANSFORMER_ONLY:
+ target_modules = target_modules + ControlNetLLLite.UNET_TARGET_REPLACE_MODULE_CONV2D_3X3
+
+ # create module instances
+ self.unet_modules: List[LLLiteModule] = create_modules(unet, target_modules, LLLiteModule)
+ print(f"create ControlNet LLLite for U-Net: {len(self.unet_modules)} modules.")
+
+ def forward(self, x):
+ return x # dummy
+
+ def set_cond_image(self, cond_image, cond_key):
+ r"""
+ 中でモデルを呼び出すので必要ならwith torch.no_grad()で囲む
+ / call the model inside, so if necessary, surround it with torch.no_grad()
+ """
+ for module in self.unet_modules:
+ module.set_cond_image(cond_image,cond_key)
+
+ def set_batch_cond_only(self, cond_only, zeros):
+ for module in self.unet_modules:
+ module.set_batch_cond_only(cond_only, zeros)
+
+ def set_multiplier(self, multiplier):
+ if isinstance(multiplier, list):
+ multiplier = torch.tensor(multiplier).to("cuda", dtype=torch.float16, non_blocking=True)
+ multiplier = multiplier[:,None,None]
+
+ for module in self.unet_modules:
+ module.multiplier = multiplier
+
+ def load_weights(self, file):
+ if os.path.splitext(file)[1] == ".safetensors":
+ from safetensors.torch import load_file
+
+ weights_sd = load_file(file)
+ else:
+ weights_sd = torch.load(file, map_location="cpu")
+
+ info = self.load_state_dict(weights_sd, False)
+ return info
+
+ def apply_to(self):
+ print("applying LLLite for U-Net...")
+ for module in self.unet_modules:
+ module.apply_to()
+ self.add_module(module.lllite_name, module)
+
+ def unapply_to(self):
+ for module in self.unet_modules:
+ module.unapply_to()
+
+ # マージできるかどうかを返す
+ def is_mergeable(self):
+ return False
+
+ def merge_to(self, text_encoder, unet, weights_sd, dtype, device):
+ raise NotImplementedError()
+
+ def enable_gradient_checkpointing(self):
+ # not supported
+ pass
+
+ def prepare_optimizer_params(self):
+ self.requires_grad_(True)
+ return self.parameters()
+
+ def prepare_grad_etc(self):
+ self.requires_grad_(True)
+
+ def on_epoch_start(self):
+ self.train()
+
+ def get_trainable_params(self):
+ return self.parameters()
+
+ def save_weights(self, file, dtype, metadata):
+ if metadata is not None and len(metadata) == 0:
+ metadata = None
+
+ state_dict = self.state_dict()
+
+ if dtype is not None:
+ for key in list(state_dict.keys()):
+ v = state_dict[key]
+ v = v.detach().clone().to("cpu").to(dtype)
+ state_dict[key] = v
+
+ if os.path.splitext(file)[1] == ".safetensors":
+ from safetensors.torch import save_file
+
+ save_file(state_dict, file, metadata)
+ else:
+ torch.save(state_dict, file)
+
+ def load_state_dict(self, state_dict: Mapping[str, Any], strict: bool = True):
+ from animatediff.utils.lora_diffusers import UNET_CONVERSION_MAP
+
+ # convert SDXL Stability AI's state dict to Diffusers' based state dict
+ map_keys = list(UNET_CONVERSION_MAP.keys()) # prefix of U-Net modules
+ map_keys.sort()
+ for key in list(state_dict.keys()):
+ if key.startswith("lllite_unet" + "_"):
+ search_key = key.replace("lllite_unet" + "_", "")
+ position = bisect.bisect_right(map_keys, search_key)
+ map_key = map_keys[position - 1]
+ if search_key.startswith(map_key):
+ new_key = key.replace(map_key, UNET_CONVERSION_MAP[map_key])
+ state_dict[new_key] = state_dict[key]
+ del state_dict[key]
+
+ # in case of V2, some weights have different shape, so we need to convert them
+ # because V2 LoRA is based on U-Net created by use_linear_projection=False
+ my_state_dict = self.state_dict()
+ for key in state_dict.keys():
+ if state_dict[key].size() != my_state_dict[key].size():
+ # print(f"convert {key} from {state_dict[key].size()} to {my_state_dict[key].size()}")
+ state_dict[key] = state_dict[key].view(my_state_dict[key].size())
+
+ return super().load_state_dict(state_dict, strict)
+
+
+def load_controlnet_lllite(model_file, pipe, torch_dtype=torch.float16):
+ print(f"loading ControlNet-LLLite: {model_file}")
+
+ from safetensors.torch import load_file
+
+ state_dict = load_file(model_file)
+ mlp_dim = None
+ cond_emb_dim = None
+ for key, value in state_dict.items():
+ if mlp_dim is None and "down.0.weight" in key:
+ mlp_dim = value.shape[0]
+ elif cond_emb_dim is None and "conditioning1.0" in key:
+ cond_emb_dim = value.shape[0] * 2
+ if mlp_dim is not None and cond_emb_dim is not None:
+ break
+ assert mlp_dim is not None and cond_emb_dim is not None, f"invalid control net: {model_file}"
+
+ control_net = ControlNetLLLite(pipe.unet, cond_emb_dim, mlp_dim, multiplier=1.0)
+ control_net.apply_to()
+ info = control_net.load_state_dict(state_dict, False)
+ print(info)
+ #control_net.to(dtype).to(device)
+ control_net.to(torch_dtype)
+ control_net.set_batch_cond_only(False, False)
+ return control_net
diff --git a/animate/src/animatediff/utils/convert_from_ckpt.py b/animate/src/animatediff/utils/convert_from_ckpt.py
new file mode 100644
index 0000000000000000000000000000000000000000..84e21397639a911ea236b11754e55c1421b17609
--- /dev/null
+++ b/animate/src/animatediff/utils/convert_from_ckpt.py
@@ -0,0 +1,794 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Conversion script for the Stable Diffusion checkpoints."""
+
+import re
+from io import BytesIO
+from typing import Optional
+
+import requests
+import torch
+from diffusers.models import (AutoencoderKL, ControlNetModel, PriorTransformer,
+ UNet2DConditionModel)
+from diffusers.schedulers import DDIMScheduler
+from diffusers.utils import (is_accelerate_available,
+ logging)
+from transformers import CLIPTextConfig, CLIPTextModel
+
+if is_accelerate_available():
+ from accelerate import init_empty_weights
+ from accelerate.utils import set_module_tensor_to_device
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+def is_safetensors_available():
+ return True
+
+def shave_segments(path, n_shave_prefix_segments=1):
+ """
+ Removes segments. Positive values shave the first segments, negative shave the last segments.
+ """
+ if n_shave_prefix_segments >= 0:
+ return ".".join(path.split(".")[n_shave_prefix_segments:])
+ else:
+ return ".".join(path.split(".")[:n_shave_prefix_segments])
+
+
+def renew_resnet_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside resnets to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item.replace("in_layers.0", "norm1")
+ new_item = new_item.replace("in_layers.2", "conv1")
+
+ new_item = new_item.replace("out_layers.0", "norm2")
+ new_item = new_item.replace("out_layers.3", "conv2")
+
+ new_item = new_item.replace("emb_layers.1", "time_emb_proj")
+ new_item = new_item.replace("skip_connection", "conv_shortcut")
+
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def renew_vae_resnet_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside resnets to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ new_item = new_item.replace("nin_shortcut", "conv_shortcut")
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def renew_attention_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside attentions to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ # new_item = new_item.replace('norm.weight', 'group_norm.weight')
+ # new_item = new_item.replace('norm.bias', 'group_norm.bias')
+
+ # new_item = new_item.replace('proj_out.weight', 'proj_attn.weight')
+ # new_item = new_item.replace('proj_out.bias', 'proj_attn.bias')
+
+ # new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def renew_vae_attention_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside attentions to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ new_item = new_item.replace("norm.weight", "group_norm.weight")
+ new_item = new_item.replace("norm.bias", "group_norm.bias")
+
+ new_item = new_item.replace("q.weight", "to_q.weight")
+ new_item = new_item.replace("q.bias", "to_q.bias")
+
+ new_item = new_item.replace("k.weight", "to_k.weight")
+ new_item = new_item.replace("k.bias", "to_k.bias")
+
+ new_item = new_item.replace("v.weight", "to_v.weight")
+ new_item = new_item.replace("v.bias", "to_v.bias")
+
+ new_item = new_item.replace("proj_out.weight", "to_out.0.weight")
+ new_item = new_item.replace("proj_out.bias", "to_out.0.bias")
+
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def assign_to_checkpoint(
+ paths,
+ checkpoint,
+ old_checkpoint,
+ attention_paths_to_split=None,
+ additional_replacements=None,
+ config=None,
+):
+ """
+ This does the final conversion step: take locally converted weights and apply a global renaming to them. It splits
+ attention layers, and takes into account additional replacements that may arise.
+
+ Assigns the weights to the new checkpoint.
+ """
+ assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
+
+ # Splits the attention layers into three variables.
+ if attention_paths_to_split is not None:
+ for path, path_map in attention_paths_to_split.items():
+ old_tensor = old_checkpoint[path]
+ channels = old_tensor.shape[0] // 3
+
+ target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1)
+
+ num_heads = old_tensor.shape[0] // config["num_head_channels"] // 3
+
+ old_tensor = old_tensor.reshape((num_heads, 3 * channels // num_heads) + old_tensor.shape[1:])
+ query, key, value = old_tensor.split(channels // num_heads, dim=1)
+
+ checkpoint[path_map["query"]] = query.reshape(target_shape)
+ checkpoint[path_map["key"]] = key.reshape(target_shape)
+ checkpoint[path_map["value"]] = value.reshape(target_shape)
+
+ for path in paths:
+ new_path = path["new"]
+
+ # These have already been assigned
+ if attention_paths_to_split is not None and new_path in attention_paths_to_split:
+ continue
+
+ # Global renaming happens here
+ new_path = new_path.replace("middle_block.0", "mid_block.resnets.0")
+ new_path = new_path.replace("middle_block.1", "mid_block.attentions.0")
+ new_path = new_path.replace("middle_block.2", "mid_block.resnets.1")
+
+ if additional_replacements is not None:
+ for replacement in additional_replacements:
+ new_path = new_path.replace(replacement["old"], replacement["new"])
+
+ # proj_attn.weight has to be converted from conv 1D to linear
+ is_attn_weight = "proj_attn.weight" in new_path or ("attentions" in new_path and "to_" in new_path)
+ shape = old_checkpoint[path["old"]].shape
+ if is_attn_weight and len(shape) == 3:
+ checkpoint[new_path] = old_checkpoint[path["old"]][:, :, 0]
+ elif is_attn_weight and len(shape) == 4:
+ checkpoint[new_path] = old_checkpoint[path["old"]][:, :, 0, 0]
+ else:
+ checkpoint[new_path] = old_checkpoint[path["old"]]
+
+
+def conv_attn_to_linear(checkpoint):
+ keys = list(checkpoint.keys())
+ attn_keys = ["query.weight", "key.weight", "value.weight"]
+ for key in keys:
+ if ".".join(key.split(".")[-2:]) in attn_keys:
+ if checkpoint[key].ndim > 2:
+ checkpoint[key] = checkpoint[key][:, :, 0, 0]
+ elif "proj_attn.weight" in key:
+ if checkpoint[key].ndim > 2:
+ checkpoint[key] = checkpoint[key][:, :, 0]
+
+
+def create_unet_diffusers_config(original_config, image_size: int, controlnet=False):
+ """
+ Creates a config for the diffusers based on the config of the LDM model.
+ """
+ if controlnet:
+ unet_params = original_config.model.params.control_stage_config.params
+ else:
+ if (
+ "unet_config" in original_config.model.params
+ and original_config.model.params.unet_config is not None
+ ):
+ unet_params = original_config.model.params.unet_config.params
+ else:
+ unet_params = original_config.model.params.network_config.params
+
+ vae_params = original_config.model.params.first_stage_config.params.ddconfig
+
+ block_out_channels = [unet_params.model_channels * mult for mult in unet_params.channel_mult]
+
+ down_block_types = []
+ resolution = 1
+ for i in range(len(block_out_channels)):
+ block_type = (
+ "CrossAttnDownBlock2D" if resolution in unet_params.attention_resolutions else "DownBlock2D"
+ )
+ down_block_types.append(block_type)
+ if i != len(block_out_channels) - 1:
+ resolution *= 2
+
+ up_block_types = []
+ for i in range(len(block_out_channels)):
+ block_type = "CrossAttnUpBlock2D" if resolution in unet_params.attention_resolutions else "UpBlock2D"
+ up_block_types.append(block_type)
+ resolution //= 2
+
+ if unet_params.transformer_depth is not None:
+ transformer_layers_per_block = (
+ unet_params.transformer_depth
+ if isinstance(unet_params.transformer_depth, int)
+ else list(unet_params.transformer_depth)
+ )
+ else:
+ transformer_layers_per_block = 1
+
+ vae_scale_factor = 2 ** (len(vae_params.ch_mult) - 1)
+
+ head_dim = unet_params.num_heads if "num_heads" in unet_params else None
+ use_linear_projection = (
+ unet_params.use_linear_in_transformer if "use_linear_in_transformer" in unet_params else False
+ )
+ if use_linear_projection:
+ # stable diffusion 2-base-512 and 2-768
+ if head_dim is None:
+ head_dim_mult = unet_params.model_channels // unet_params.num_head_channels
+ head_dim = [head_dim_mult * c for c in list(unet_params.channel_mult)]
+
+ class_embed_type = None
+ addition_embed_type = None
+ addition_time_embed_dim = None
+ projection_class_embeddings_input_dim = None
+ context_dim = None
+
+ if unet_params.context_dim is not None:
+ context_dim = (
+ unet_params.context_dim
+ if isinstance(unet_params.context_dim, int)
+ else unet_params.context_dim[0]
+ )
+
+ if "num_classes" in unet_params:
+ if unet_params.num_classes == "sequential":
+ if context_dim in [2048, 1280]:
+ # SDXL
+ addition_embed_type = "text_time"
+ addition_time_embed_dim = 256
+ else:
+ class_embed_type = "projection"
+ assert "adm_in_channels" in unet_params
+ projection_class_embeddings_input_dim = unet_params.adm_in_channels
+ else:
+ raise NotImplementedError(
+ f"Unknown conditional unet num_classes config: {unet_params.num_classes}"
+ )
+
+ config = {
+ "sample_size": image_size // vae_scale_factor,
+ "in_channels": unet_params.in_channels,
+ "down_block_types": tuple(down_block_types),
+ "block_out_channels": tuple(block_out_channels),
+ "layers_per_block": unet_params.num_res_blocks,
+ "cross_attention_dim": context_dim,
+ "attention_head_dim": head_dim,
+ "use_linear_projection": use_linear_projection,
+ "class_embed_type": class_embed_type,
+ "addition_embed_type": addition_embed_type,
+ "addition_time_embed_dim": addition_time_embed_dim,
+ "projection_class_embeddings_input_dim": projection_class_embeddings_input_dim,
+ "transformer_layers_per_block": transformer_layers_per_block,
+ }
+
+ if controlnet:
+ config["conditioning_channels"] = unet_params.hint_channels
+ else:
+ config["out_channels"] = unet_params.out_channels
+ config["up_block_types"] = tuple(up_block_types)
+
+ return config
+
+
+def create_vae_diffusers_config(original_config, image_size: int):
+ """
+ Creates a config for the diffusers based on the config of the LDM model.
+ """
+ vae_params = original_config.model.params.first_stage_config.params.ddconfig
+ _ = original_config.model.params.first_stage_config.params.embed_dim
+
+ block_out_channels = [vae_params.ch * mult for mult in vae_params.ch_mult]
+ down_block_types = ["DownEncoderBlock2D"] * len(block_out_channels)
+ up_block_types = ["UpDecoderBlock2D"] * len(block_out_channels)
+
+ config = {
+ "sample_size": image_size,
+ "in_channels": vae_params.in_channels,
+ "out_channels": vae_params.out_ch,
+ "down_block_types": tuple(down_block_types),
+ "up_block_types": tuple(up_block_types),
+ "block_out_channels": tuple(block_out_channels),
+ "latent_channels": vae_params.z_channels,
+ "layers_per_block": vae_params.num_res_blocks,
+ }
+ return config
+
+
+def create_diffusers_schedular(original_config):
+ schedular = DDIMScheduler(
+ num_train_timesteps=original_config.model.params.timesteps,
+ beta_start=original_config.model.params.linear_start,
+ beta_end=original_config.model.params.linear_end,
+ beta_schedule="scaled_linear",
+ )
+ return schedular
+
+
+def convert_ldm_unet_checkpoint(
+ checkpoint, config, path=None, extract_ema=False, controlnet=False, skip_extract_state_dict=False
+):
+ """
+ Takes a state dict and a config, and returns a converted checkpoint.
+ """
+
+ if skip_extract_state_dict:
+ unet_state_dict = checkpoint
+ else:
+ # extract state_dict for UNet
+ unet_state_dict = {}
+ keys = list(checkpoint.keys())
+
+ if controlnet:
+ unet_key = "control_model."
+ else:
+ unet_key = "model.diffusion_model."
+
+ # at least a 100 parameters have to start with `model_ema` in order for the checkpoint to be EMA
+ if sum(k.startswith("model_ema") for k in keys) > 100 and extract_ema:
+ logger.warning(f"Checkpoint {path} has both EMA and non-EMA weights.")
+ logger.warning(
+ "In this conversion only the EMA weights are extracted. If you want to instead extract the non-EMA"
+ " weights (useful to continue fine-tuning), please make sure to remove the `--extract_ema` flag."
+ )
+ for key in keys:
+ if key.startswith("model.diffusion_model"):
+ flat_ema_key = "model_ema." + "".join(key.split(".")[1:])
+ unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(flat_ema_key)
+ else:
+ if sum(k.startswith("model_ema") for k in keys) > 100:
+ logger.warning(
+ "In this conversion only the non-EMA weights are extracted. If you want to instead extract the EMA"
+ " weights (usually better for inference), please make sure to add the `--extract_ema` flag."
+ )
+
+ for key in keys:
+ if key.startswith(unet_key):
+ unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(key)
+
+ new_checkpoint = {}
+
+ new_checkpoint["time_embedding.linear_1.weight"] = unet_state_dict["time_embed.0.weight"]
+ new_checkpoint["time_embedding.linear_1.bias"] = unet_state_dict["time_embed.0.bias"]
+ new_checkpoint["time_embedding.linear_2.weight"] = unet_state_dict["time_embed.2.weight"]
+ new_checkpoint["time_embedding.linear_2.bias"] = unet_state_dict["time_embed.2.bias"]
+
+ if config["class_embed_type"] is None:
+ # No parameters to port
+ ...
+ elif config["class_embed_type"] == "timestep" or config["class_embed_type"] == "projection":
+ new_checkpoint["class_embedding.linear_1.weight"] = unet_state_dict["label_emb.0.0.weight"]
+ new_checkpoint["class_embedding.linear_1.bias"] = unet_state_dict["label_emb.0.0.bias"]
+ new_checkpoint["class_embedding.linear_2.weight"] = unet_state_dict["label_emb.0.2.weight"]
+ new_checkpoint["class_embedding.linear_2.bias"] = unet_state_dict["label_emb.0.2.bias"]
+ else:
+ raise NotImplementedError(f"Not implemented `class_embed_type`: {config['class_embed_type']}")
+
+ if config["addition_embed_type"] == "text_time":
+ new_checkpoint["add_embedding.linear_1.weight"] = unet_state_dict["label_emb.0.0.weight"]
+ new_checkpoint["add_embedding.linear_1.bias"] = unet_state_dict["label_emb.0.0.bias"]
+ new_checkpoint["add_embedding.linear_2.weight"] = unet_state_dict["label_emb.0.2.weight"]
+ new_checkpoint["add_embedding.linear_2.bias"] = unet_state_dict["label_emb.0.2.bias"]
+
+ new_checkpoint["conv_in.weight"] = unet_state_dict["input_blocks.0.0.weight"]
+ new_checkpoint["conv_in.bias"] = unet_state_dict["input_blocks.0.0.bias"]
+
+ if not controlnet:
+ new_checkpoint["conv_norm_out.weight"] = unet_state_dict["out.0.weight"]
+ new_checkpoint["conv_norm_out.bias"] = unet_state_dict["out.0.bias"]
+ new_checkpoint["conv_out.weight"] = unet_state_dict["out.2.weight"]
+ new_checkpoint["conv_out.bias"] = unet_state_dict["out.2.bias"]
+
+ # Retrieves the keys for the input blocks only
+ num_input_blocks = len(
+ {".".join(layer.split(".")[:2]) for layer in unet_state_dict if "input_blocks" in layer}
+ )
+ input_blocks = {
+ layer_id: [key for key in unet_state_dict if f"input_blocks.{layer_id}" in key]
+ for layer_id in range(num_input_blocks)
+ }
+
+ # Retrieves the keys for the middle blocks only
+ num_middle_blocks = len(
+ {".".join(layer.split(".")[:2]) for layer in unet_state_dict if "middle_block" in layer}
+ )
+ middle_blocks = {
+ layer_id: [key for key in unet_state_dict if f"middle_block.{layer_id}" in key]
+ for layer_id in range(num_middle_blocks)
+ }
+
+ # Retrieves the keys for the output blocks only
+ num_output_blocks = len(
+ {".".join(layer.split(".")[:2]) for layer in unet_state_dict if "output_blocks" in layer}
+ )
+ output_blocks = {
+ layer_id: [key for key in unet_state_dict if f"output_blocks.{layer_id}" in key]
+ for layer_id in range(num_output_blocks)
+ }
+
+ for i in range(1, num_input_blocks):
+ block_id = (i - 1) // (config["layers_per_block"] + 1)
+ layer_in_block_id = (i - 1) % (config["layers_per_block"] + 1)
+
+ resnets = [
+ key
+ for key in input_blocks[i]
+ if f"input_blocks.{i}.0" in key and f"input_blocks.{i}.0.op" not in key
+ ]
+ attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key]
+
+ if f"input_blocks.{i}.0.op.weight" in unet_state_dict:
+ new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.weight"] = unet_state_dict.pop(
+ f"input_blocks.{i}.0.op.weight"
+ )
+ new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.bias"] = unet_state_dict.pop(
+ f"input_blocks.{i}.0.op.bias"
+ )
+
+ paths = renew_resnet_paths(resnets)
+ meta_path = {
+ "old": f"input_blocks.{i}.0",
+ "new": f"down_blocks.{block_id}.resnets.{layer_in_block_id}",
+ }
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ if len(attentions):
+ paths = renew_attention_paths(attentions)
+ meta_path = {
+ "old": f"input_blocks.{i}.1",
+ "new": f"down_blocks.{block_id}.attentions.{layer_in_block_id}",
+ }
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ resnet_0 = middle_blocks[0]
+ attentions = middle_blocks[1]
+ resnet_1 = middle_blocks[2]
+
+ resnet_0_paths = renew_resnet_paths(resnet_0)
+ assign_to_checkpoint(resnet_0_paths, new_checkpoint, unet_state_dict, config=config)
+
+ resnet_1_paths = renew_resnet_paths(resnet_1)
+ assign_to_checkpoint(resnet_1_paths, new_checkpoint, unet_state_dict, config=config)
+
+ attentions_paths = renew_attention_paths(attentions)
+ meta_path = {"old": "middle_block.1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(
+ attentions_paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ for i in range(num_output_blocks):
+ block_id = i // (config["layers_per_block"] + 1)
+ layer_in_block_id = i % (config["layers_per_block"] + 1)
+ output_block_layers = [shave_segments(name, 2) for name in output_blocks[i]]
+ output_block_list = {}
+
+ for layer in output_block_layers:
+ layer_id, layer_name = layer.split(".")[0], shave_segments(layer, 1)
+ if layer_id in output_block_list:
+ output_block_list[layer_id].append(layer_name)
+ else:
+ output_block_list[layer_id] = [layer_name]
+
+ if len(output_block_list) > 1:
+ resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.0" in key]
+ attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.1" in key]
+
+ resnet_0_paths = renew_resnet_paths(resnets)
+ paths = renew_resnet_paths(resnets)
+
+ meta_path = {
+ "old": f"output_blocks.{i}.0",
+ "new": f"up_blocks.{block_id}.resnets.{layer_in_block_id}",
+ }
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ output_block_list = {k: sorted(v) for k, v in output_block_list.items()}
+ if ["conv.bias", "conv.weight"] in output_block_list.values():
+ index = list(output_block_list.values()).index(["conv.bias", "conv.weight"])
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = unet_state_dict[
+ f"output_blocks.{i}.{index}.conv.weight"
+ ]
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = unet_state_dict[
+ f"output_blocks.{i}.{index}.conv.bias"
+ ]
+
+ # Clear attentions as they have been attributed above.
+ if len(attentions) == 2:
+ attentions = []
+
+ if len(attentions):
+ paths = renew_attention_paths(attentions)
+ meta_path = {
+ "old": f"output_blocks.{i}.1",
+ "new": f"up_blocks.{block_id}.attentions.{layer_in_block_id}",
+ }
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+ else:
+ resnet_0_paths = renew_resnet_paths(output_block_layers, n_shave_prefix_segments=1)
+ for path in resnet_0_paths:
+ old_path = ".".join(["output_blocks", str(i), path["old"]])
+ new_path = ".".join(
+ ["up_blocks", str(block_id), "resnets", str(layer_in_block_id), path["new"]]
+ )
+
+ new_checkpoint[new_path] = unet_state_dict[old_path]
+
+ if controlnet:
+ # conditioning embedding
+
+ orig_index = 0
+
+ new_checkpoint["controlnet_cond_embedding.conv_in.weight"] = unet_state_dict.pop(
+ f"input_hint_block.{orig_index}.weight"
+ )
+ new_checkpoint["controlnet_cond_embedding.conv_in.bias"] = unet_state_dict.pop(
+ f"input_hint_block.{orig_index}.bias"
+ )
+
+ orig_index += 2
+
+ diffusers_index = 0
+
+ while diffusers_index < 6:
+ new_checkpoint[
+ f"controlnet_cond_embedding.blocks.{diffusers_index}.weight"
+ ] = unet_state_dict.pop(f"input_hint_block.{orig_index}.weight")
+ new_checkpoint[f"controlnet_cond_embedding.blocks.{diffusers_index}.bias"] = unet_state_dict.pop(
+ f"input_hint_block.{orig_index}.bias"
+ )
+ diffusers_index += 1
+ orig_index += 2
+
+ new_checkpoint["controlnet_cond_embedding.conv_out.weight"] = unet_state_dict.pop(
+ f"input_hint_block.{orig_index}.weight"
+ )
+ new_checkpoint["controlnet_cond_embedding.conv_out.bias"] = unet_state_dict.pop(
+ f"input_hint_block.{orig_index}.bias"
+ )
+
+ # down blocks
+ for i in range(num_input_blocks):
+ new_checkpoint[f"controlnet_down_blocks.{i}.weight"] = unet_state_dict.pop(
+ f"zero_convs.{i}.0.weight"
+ )
+ new_checkpoint[f"controlnet_down_blocks.{i}.bias"] = unet_state_dict.pop(f"zero_convs.{i}.0.bias")
+
+ # mid block
+ new_checkpoint["controlnet_mid_block.weight"] = unet_state_dict.pop("middle_block_out.0.weight")
+ new_checkpoint["controlnet_mid_block.bias"] = unet_state_dict.pop("middle_block_out.0.bias")
+
+ return new_checkpoint
+
+
+def convert_ldm_vae_checkpoint(checkpoint, config, is_extract=False):
+ # extract state dict for VAE
+ vae_state_dict = {}
+ if is_extract:
+ vae_key = "first_stage_model."
+ keys = list(checkpoint.keys())
+ for key in keys:
+ if is_extract:
+ if key.startswith(vae_key):
+ vae_state_dict[key.replace(vae_key, "")] = checkpoint.get(key)
+ else:
+ vae_state_dict = checkpoint
+
+
+ new_checkpoint = {}
+
+ new_checkpoint["encoder.conv_in.weight"] = vae_state_dict["encoder.conv_in.weight"]
+ new_checkpoint["encoder.conv_in.bias"] = vae_state_dict["encoder.conv_in.bias"]
+ new_checkpoint["encoder.conv_out.weight"] = vae_state_dict["encoder.conv_out.weight"]
+ new_checkpoint["encoder.conv_out.bias"] = vae_state_dict["encoder.conv_out.bias"]
+ new_checkpoint["encoder.conv_norm_out.weight"] = vae_state_dict["encoder.norm_out.weight"]
+ new_checkpoint["encoder.conv_norm_out.bias"] = vae_state_dict["encoder.norm_out.bias"]
+
+ new_checkpoint["decoder.conv_in.weight"] = vae_state_dict["decoder.conv_in.weight"]
+ new_checkpoint["decoder.conv_in.bias"] = vae_state_dict["decoder.conv_in.bias"]
+ new_checkpoint["decoder.conv_out.weight"] = vae_state_dict["decoder.conv_out.weight"]
+ new_checkpoint["decoder.conv_out.bias"] = vae_state_dict["decoder.conv_out.bias"]
+ new_checkpoint["decoder.conv_norm_out.weight"] = vae_state_dict["decoder.norm_out.weight"]
+ new_checkpoint["decoder.conv_norm_out.bias"] = vae_state_dict["decoder.norm_out.bias"]
+
+ new_checkpoint["quant_conv.weight"] = vae_state_dict["quant_conv.weight"]
+ new_checkpoint["quant_conv.bias"] = vae_state_dict["quant_conv.bias"]
+ new_checkpoint["post_quant_conv.weight"] = vae_state_dict["post_quant_conv.weight"]
+ new_checkpoint["post_quant_conv.bias"] = vae_state_dict["post_quant_conv.bias"]
+
+ # Retrieves the keys for the encoder down blocks only
+ num_down_blocks = len(
+ {".".join(layer.split(".")[:3]) for layer in vae_state_dict if "encoder.down" in layer}
+ )
+ down_blocks = {
+ layer_id: [key for key in vae_state_dict if f"down.{layer_id}" in key]
+ for layer_id in range(num_down_blocks)
+ }
+
+ # Retrieves the keys for the decoder up blocks only
+ num_up_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "decoder.up" in layer})
+ up_blocks = {
+ layer_id: [key for key in vae_state_dict if f"up.{layer_id}" in key]
+ for layer_id in range(num_up_blocks)
+ }
+
+ for i in range(num_down_blocks):
+ resnets = [key for key in down_blocks[i] if f"down.{i}" in key and f"down.{i}.downsample" not in key]
+
+ if f"encoder.down.{i}.downsample.conv.weight" in vae_state_dict:
+ new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.weight"] = vae_state_dict.pop(
+ f"encoder.down.{i}.downsample.conv.weight"
+ )
+ new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.bias"] = vae_state_dict.pop(
+ f"encoder.down.{i}.downsample.conv.bias"
+ )
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"down.{i}.block", "new": f"down_blocks.{i}.resnets"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ mid_resnets = [key for key in vae_state_dict if "encoder.mid.block" in key]
+ num_mid_res_blocks = 2
+ for i in range(1, num_mid_res_blocks + 1):
+ resnets = [key for key in mid_resnets if f"encoder.mid.block_{i}" in key]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ mid_attentions = [key for key in vae_state_dict if "encoder.mid.attn" in key]
+ paths = renew_vae_attention_paths(mid_attentions)
+ meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config
+ )
+ conv_attn_to_linear(new_checkpoint)
+
+ for i in range(num_up_blocks):
+ block_id = num_up_blocks - 1 - i
+ resnets = [
+ key
+ for key in up_blocks[block_id]
+ if f"up.{block_id}" in key and f"up.{block_id}.upsample" not in key
+ ]
+
+ if f"decoder.up.{block_id}.upsample.conv.weight" in vae_state_dict:
+ new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.weight"] = vae_state_dict[
+ f"decoder.up.{block_id}.upsample.conv.weight"
+ ]
+ new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.bias"] = vae_state_dict[
+ f"decoder.up.{block_id}.upsample.conv.bias"
+ ]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"up.{block_id}.block", "new": f"up_blocks.{i}.resnets"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ mid_resnets = [key for key in vae_state_dict if "decoder.mid.block" in key]
+ num_mid_res_blocks = 2
+ for i in range(1, num_mid_res_blocks + 1):
+ resnets = [key for key in mid_resnets if f"decoder.mid.block_{i}" in key]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ mid_attentions = [key for key in vae_state_dict if "decoder.mid.attn" in key]
+ paths = renew_vae_attention_paths(mid_attentions)
+ meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config
+ )
+ conv_attn_to_linear(new_checkpoint)
+ return new_checkpoint
+
+
+def convert_ldm_clip_checkpoint(checkpoint, local_files_only=False, text_model=None):
+ if text_model is None:
+ config_name = "openai/clip-vit-large-patch14"
+ config = CLIPTextConfig.from_pretrained(config_name)
+
+ with init_empty_weights():
+ text_model = CLIPTextModel(config)
+
+ keys = list(checkpoint.keys())
+
+ text_model_dict = {}
+
+ remove_prefixes = ["cond_stage_model.transformer", "conditioner.embedders.0.transformer"]
+
+ for key in keys:
+ for prefix in remove_prefixes:
+ if key.startswith(prefix):
+ text_model_dict[key[len(prefix + ".") :]] = checkpoint[key]
+
+ for param_name, param in text_model_dict.items():
+ set_module_tensor_to_device(text_model, param_name, "cpu", value=param)
+
+ return text_model
+
+
+textenc_conversion_lst = [
+ ("positional_embedding", "text_model.embeddings.position_embedding.weight"),
+ ("token_embedding.weight", "text_model.embeddings.token_embedding.weight"),
+ ("ln_final.weight", "text_model.final_layer_norm.weight"),
+ ("ln_final.bias", "text_model.final_layer_norm.bias"),
+ ("text_projection", "text_projection.weight"),
+]
+textenc_conversion_map = {x[0]: x[1] for x in textenc_conversion_lst}
+
+textenc_transformer_conversion_lst = [
+ # (stable-diffusion, HF Diffusers)
+ ("resblocks.", "text_model.encoder.layers."),
+ ("ln_1", "layer_norm1"),
+ ("ln_2", "layer_norm2"),
+ (".c_fc.", ".fc1."),
+ (".c_proj.", ".fc2."),
+ (".attn", ".self_attn"),
+ ("ln_final.", "transformer.text_model.final_layer_norm."),
+ ("token_embedding.weight", "transformer.text_model.embeddings.token_embedding.weight"),
+ ("positional_embedding", "transformer.text_model.embeddings.position_embedding.weight"),
+]
+protected = {re.escape(x[0]): x[1] for x in textenc_transformer_conversion_lst}
+textenc_pattern = re.compile("|".join(protected.keys()))
diff --git a/animate/src/animatediff/utils/convert_lora_safetensor_to_diffusers.py b/animate/src/animatediff/utils/convert_lora_safetensor_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..cc38ed8a2c8d9f8ede894a9ff4149905f991d5da
--- /dev/null
+++ b/animate/src/animatediff/utils/convert_lora_safetensor_to_diffusers.py
@@ -0,0 +1,141 @@
+# coding=utf-8
+# Copyright 2023, Haofan Wang, Qixun Wang, All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+""" Conversion script for the LoRA's safetensors checkpoints. """
+
+import argparse
+
+import torch
+
+
+def convert_lora(
+ pipeline, state_dict, LORA_PREFIX_UNET="lora_unet", LORA_PREFIX_TEXT_ENCODER="lora_te", alpha=0.6
+):
+ # load base model
+ # pipeline = StableDiffusionPipeline.from_pretrained(base_model_path, torch_dtype=torch.float32)
+
+ # load LoRA weight from .safetensors
+ # state_dict = load_file(checkpoint_path)
+
+ visited = []
+
+ # directly update weight in diffusers model
+ for key in state_dict:
+ # it is suggested to print out the key, it usually will be something like below
+ # "lora_te_text_model_encoder_layers_0_self_attn_k_proj.lora_down.weight"
+
+ # as we have set the alpha beforehand, so just skip
+ if ".alpha" in key or key in visited:
+ continue
+
+ if "text" in key:
+ layer_infos = key.split(".")[0].split(LORA_PREFIX_TEXT_ENCODER + "_")[-1].split("_")
+ curr_layer = pipeline.text_encoder
+ else:
+ layer_infos = key.split(".")[0].split(LORA_PREFIX_UNET + "_")[-1].split("_")
+ curr_layer = pipeline.unet
+
+ # find the target layer
+ temp_name = layer_infos.pop(0)
+ while len(layer_infos) > -1:
+ try:
+ curr_layer = curr_layer.__getattr__(temp_name)
+ if len(layer_infos) > 0:
+ temp_name = layer_infos.pop(0)
+ elif len(layer_infos) == 0:
+ break
+ except Exception:
+ if len(temp_name) > 0:
+ temp_name += "_" + layer_infos.pop(0)
+ else:
+ temp_name = layer_infos.pop(0)
+
+ pair_keys = []
+ if "lora_down" in key:
+ pair_keys.append(key.replace("lora_down", "lora_up"))
+ pair_keys.append(key)
+ else:
+ pair_keys.append(key)
+ pair_keys.append(key.replace("lora_up", "lora_down"))
+
+ # update weight
+ if len(state_dict[pair_keys[0]].shape) == 4:
+ weight_up = state_dict[pair_keys[0]].squeeze(3).squeeze(2).to(torch.float32)
+ weight_down = state_dict[pair_keys[1]].squeeze(3).squeeze(2).to(torch.float32)
+ curr_layer.weight.data += alpha * torch.mm(weight_up, weight_down).unsqueeze(2).unsqueeze(3).to(
+ curr_layer.weight.data.device
+ )
+ else:
+ weight_up = state_dict[pair_keys[0]].to(torch.float32)
+ weight_down = state_dict[pair_keys[1]].to(torch.float32)
+ curr_layer.weight.data += alpha * torch.mm(weight_up, weight_down).to(
+ curr_layer.weight.data.device
+ )
+
+ # update visited list
+ for item in pair_keys:
+ visited.append(item)
+
+ return pipeline
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--base_model_path",
+ default=None,
+ type=str,
+ required=True,
+ help="Path to the base model in diffusers format.",
+ )
+ parser.add_argument(
+ "--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
+ )
+ parser.add_argument(
+ "--dump_path", default=None, type=str, required=True, help="Path to the output model."
+ )
+ parser.add_argument(
+ "--lora_prefix_unet", default="lora_unet", type=str, help="The prefix of UNet weight in safetensors"
+ )
+ parser.add_argument(
+ "--lora_prefix_text_encoder",
+ default="lora_te",
+ type=str,
+ help="The prefix of text encoder weight in safetensors",
+ )
+ parser.add_argument(
+ "--alpha", default=0.75, type=float, help="The merging ratio in W = W0 + alpha * deltaW"
+ )
+ parser.add_argument(
+ "--to_safetensors",
+ action="store_true",
+ help="Whether to store pipeline in safetensors format or not.",
+ )
+ parser.add_argument("--device", type=str, help="Device to use (e.g. cpu, cuda:0, cuda:1, etc.)")
+
+ args = parser.parse_args()
+
+ base_model_path = args.base_model_path
+ checkpoint_path = args.checkpoint_path
+ dump_path = args.dump_path
+ lora_prefix_unet = args.lora_prefix_unet
+ lora_prefix_text_encoder = args.lora_prefix_text_encoder
+ alpha = args.alpha
+
+ pipe = convert_lora(base_model_path, checkpoint_path, lora_prefix_unet, lora_prefix_text_encoder, alpha)
+
+ pipe = pipe.to(args.device)
+ pipe.save_pretrained(args.dump_path, safe_serialization=args.to_safetensors)
diff --git a/animate/src/animatediff/utils/device.py b/animate/src/animatediff/utils/device.py
new file mode 100644
index 0000000000000000000000000000000000000000..8a481521dd7c3dd1a4494638b8a59f2b830633c6
--- /dev/null
+++ b/animate/src/animatediff/utils/device.py
@@ -0,0 +1,112 @@
+import logging
+from functools import lru_cache
+from math import ceil
+from typing import Union
+
+import torch
+
+logger = logging.getLogger(__name__)
+
+
+def device_info_str(device: torch.device) -> str:
+ device_info = torch.cuda.get_device_properties(device)
+ return (
+ f"{device_info.name} {ceil(device_info.total_memory / 1024 ** 3)}GB, "
+ + f"CC {device_info.major}.{device_info.minor}, {device_info.multi_processor_count} SM(s)"
+ )
+
+
+@lru_cache(maxsize=4)
+def supports_bfloat16(device: Union[str, torch.device]) -> bool:
+ """A non-exhaustive check for bfloat16 support on a given device.
+ Weird that torch doesn't have a global function for this. If your device
+ does support bfloat16 and it's not listed here, go ahead and add it.
+ """
+ device = torch.device(device) # make sure device is a torch.device
+ match device.type:
+ case "cpu":
+ ret = False
+ case "cuda":
+ with device:
+ ret = torch.cuda.is_bf16_supported()
+ case "xla":
+ ret = True
+ case "mps":
+ ret = True
+ case _:
+ ret = False
+ return ret
+
+
+@lru_cache(maxsize=4)
+def maybe_bfloat16(
+ device: Union[str, torch.device],
+ fallback: torch.dtype = torch.float32,
+) -> torch.dtype:
+ """Returns torch.bfloat16 if available, otherwise the fallback dtype (default float32)"""
+ device = torch.device(device) # make sure device is a torch.device
+ return torch.bfloat16 if supports_bfloat16(device) else fallback
+
+
+def dtype_for_model(model: str, device: torch.device) -> torch.dtype:
+ match model:
+ case "unet":
+ return torch.float32 if device.type == "cpu" else torch.float16
+ case "tenc":
+ return torch.float32 if device.type == "cpu" else torch.float16
+ case "vae":
+ return maybe_bfloat16(device, fallback=torch.float32)
+ case unknown:
+ raise ValueError(f"Invalid model {unknown}")
+
+
+def get_model_dtypes(
+ device: Union[str, torch.device],
+ force_half_vae: bool = False,
+) -> tuple[torch.dtype, torch.dtype, torch.dtype]:
+ device = torch.device(device) # make sure device is a torch.device
+ unet_dtype = dtype_for_model("unet", device)
+ tenc_dtype = dtype_for_model("tenc", device)
+ vae_dtype = dtype_for_model("vae", device)
+
+ if device.type == "cpu":
+ logger.warn("Device explicitly set to CPU, will run everything in fp32")
+ logger.warn("This is likely to be *incredibly* slow, but I don't tell you how to live.")
+
+ if force_half_vae:
+ if device.type == "cpu":
+ logger.critical("Can't force VAE to fp16 mode on CPU! Exiting...")
+ raise RuntimeError("Can't force VAE to fp16 mode on CPU!")
+ if vae_dtype == torch.bfloat16:
+ logger.warn("Forcing VAE to use fp16 despite bfloat16 support! This is a bad idea!")
+ logger.warn("If you're not sure why you're doing this, you probably shouldn't be.")
+ vae_dtype = torch.float16
+ else:
+ logger.warn("Forcing VAE to use fp16 instead of fp32 on CUDA! This may result in black outputs!")
+ logger.warn("Running a VAE in fp16 can result in black images or poor output quality.")
+ logger.warn("I don't tell you how to live, but you probably shouldn't do this.")
+ vae_dtype = torch.float16
+
+ logger.info(f"Selected data types: {unet_dtype=}, {tenc_dtype=}, {vae_dtype=}")
+ return unet_dtype, tenc_dtype, vae_dtype
+
+
+def get_memory_format(device: Union[str, torch.device]) -> torch.memory_format:
+ device = torch.device(device) # make sure device is a torch.device
+ # if we have a cuda device
+ if device.type == "cuda":
+ device_info = torch.cuda.get_device_properties(device)
+ # Volta and newer seem to like channels_last. This will probably bite me on TU11x cards.
+ if device_info.major >= 7:
+ ret = torch.channels_last
+ else:
+ ret = torch.contiguous_format
+ elif device.type == "xpu":
+ # Intel ARC GPUs/XPUs like channels_last
+ ret = torch.channels_last
+ else:
+ # TODO: Does MPS like channels_last? do other devices?
+ ret = torch.contiguous_format
+ if ret == torch.channels_last:
+ logger.info("Using channels_last memory format for UNet and VAE")
+ return ret
\ No newline at end of file
diff --git a/animate/src/animatediff/utils/huggingface.py b/animate/src/animatediff/utils/huggingface.py
new file mode 100644
index 0000000000000000000000000000000000000000..c56171502a768194992ae32acb77ec9fc17f261e
--- /dev/null
+++ b/animate/src/animatediff/utils/huggingface.py
@@ -0,0 +1,149 @@
+import logging
+from os import PathLike
+from pathlib import Path
+from typing import Optional
+
+from diffusers import StableDiffusionPipeline, StableDiffusionXLPipeline
+from huggingface_hub import hf_hub_download, snapshot_download
+from tqdm.rich import tqdm
+
+from animatediff import HF_HUB_CACHE, HF_LIB_NAME, HF_LIB_VER, get_dir
+from animatediff.utils.util import path_from_cwd
+
+logger = logging.getLogger(__name__)
+
+data_dir = get_dir("data")
+checkpoint_dir = data_dir.joinpath("models/sd")
+pipeline_dir = data_dir.joinpath("models/huggingface")
+
+IGNORE_TF = ["*.git*", "*.h5", "tf_*"]
+IGNORE_FLAX = ["*.git*", "flax_*", "*.msgpack"]
+IGNORE_TF_FLAX = IGNORE_TF + IGNORE_FLAX
+
+
+class DownloadTqdm(tqdm):
+ def __init__(self, *args, **kwargs):
+ kwargs.update(
+ {
+ "ncols": 100,
+ "dynamic_ncols": False,
+ "disable": None,
+ }
+ )
+ super().__init__(*args, **kwargs)
+
+
+def get_hf_file(
+ repo_id: Path,
+ filename: str,
+ target_dir: Path,
+ subfolder: Optional[PathLike] = None,
+ revision: Optional[str] = None,
+ force: bool = False,
+) -> Path:
+ target_path = target_dir.joinpath(filename)
+ if target_path.exists() and force is not True:
+ raise FileExistsError(
+ f"File {path_from_cwd(target_path)} already exists! Pass force=True to overwrite"
+ )
+
+ target_dir.mkdir(exist_ok=True, parents=True)
+ save_path = hf_hub_download(
+ repo_id=str(repo_id),
+ filename=filename,
+ revision=revision or "main",
+ subfolder=subfolder,
+ local_dir=target_dir,
+ local_dir_use_symlinks=False,
+ cache_dir=HF_HUB_CACHE,
+ resume_download=True,
+ )
+ return Path(save_path)
+
+
+def get_hf_repo(
+ repo_id: Path,
+ target_dir: Path,
+ subfolder: Optional[PathLike] = None,
+ revision: Optional[str] = None,
+ force: bool = False,
+) -> Path:
+ if target_dir.exists() and force is not True:
+ raise FileExistsError(
+ f"Target dir {path_from_cwd(target_dir)} already exists! Pass force=True to overwrite"
+ )
+
+ target_dir.mkdir(exist_ok=True, parents=True)
+ save_path = snapshot_download(
+ repo_id=str(repo_id),
+ revision=revision or "main",
+ subfolder=subfolder,
+ library_name=HF_LIB_NAME,
+ library_version=HF_LIB_VER,
+ local_dir=target_dir,
+ local_dir_use_symlinks=False,
+ ignore_patterns=IGNORE_TF_FLAX,
+ cache_dir=HF_HUB_CACHE,
+ tqdm_class=DownloadTqdm,
+ max_workers=2,
+ resume_download=True,
+ )
+ return Path(save_path)
+
+
+def get_hf_pipeline(
+ repo_id: Path,
+ target_dir: Path,
+ save: bool = True,
+ force_download: bool = False,
+) -> StableDiffusionPipeline:
+ pipeline_exists = target_dir.joinpath("model_index.json").exists()
+ if pipeline_exists and force_download is not True:
+ pipeline = StableDiffusionPipeline.from_pretrained(
+ pretrained_model_name_or_path=target_dir,
+ local_files_only=True,
+ )
+ else:
+ target_dir.mkdir(exist_ok=True, parents=True)
+ pipeline = StableDiffusionPipeline.from_pretrained(
+ pretrained_model_name_or_path=str(repo_id).lstrip("./").replace("\\", "/"),
+ cache_dir=HF_HUB_CACHE,
+ resume_download=True,
+ )
+ if save and force_download:
+ logger.warning(f"Pipeline already exists at {path_from_cwd(target_dir)}. Overwriting!")
+ pipeline.save_pretrained(target_dir, safe_serialization=True)
+ elif save and not pipeline_exists:
+ #logger.info(f"Saving pipeline to {path_from_cwd(target_dir)}")
+ pipeline.save_pretrained(target_dir, safe_serialization=True)
+ return pipeline
+
+def get_hf_pipeline_sdxl(
+ repo_id: Path,
+ target_dir: Path,
+ save: bool = True,
+ force_download: bool = False,
+) -> StableDiffusionXLPipeline:
+ import torch
+ pipeline_exists = target_dir.joinpath("model_index.json").exists()
+ if pipeline_exists and force_download is not True:
+ pipeline = StableDiffusionXLPipeline.from_pretrained(
+ pretrained_model_name_or_path=target_dir,
+ local_files_only=True,
+ torch_dtype=torch.float16, use_safetensors=True, variant="fp16"
+ )
+ else:
+ target_dir.mkdir(exist_ok=True, parents=True)
+ pipeline = StableDiffusionXLPipeline.from_pretrained(
+ pretrained_model_name_or_path=str(repo_id).lstrip("./").replace("\\", "/"),
+ cache_dir=HF_HUB_CACHE,
+ resume_download=True,
+ torch_dtype=torch.float16, use_safetensors=True, variant="fp16"
+ )
+ if save and force_download:
+ logger.warning(f"Pipeline already exists at {path_from_cwd(target_dir)}. Overwriting!")
+ pipeline.save_pretrained(target_dir, safe_serialization=True)
+ elif save and not pipeline_exists:
+ #logger.info(f"Saving pipeline to {path_from_cwd(target_dir)}")
+ pipeline.save_pretrained(target_dir, safe_serialization=True)
+ return pipeline
diff --git a/animate/src/animatediff/utils/lora_diffusers.py b/animate/src/animatediff/utils/lora_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..2576fa78154e4461381b4514266076177e070f98
--- /dev/null
+++ b/animate/src/animatediff/utils/lora_diffusers.py
@@ -0,0 +1,649 @@
+# https://github.com/kohya-ss/sd-scripts/blob/dev/networks/lora_diffusers.py
+
+# Diffusersで動くLoRA。このファイル単独で完結する。
+# LoRA module for Diffusers. This file works independently.
+
+import bisect
+import math
+import random
+from typing import Any, Dict, List, Mapping, Optional, Union
+
+import numpy as np
+import torch
+from diffusers import UNet2DConditionModel
+from tqdm import tqdm
+from transformers import CLIPTextModel
+
+
+def make_unet_conversion_map() -> Dict[str, str]:
+ unet_conversion_map_layer = []
+
+ for i in range(3): # num_blocks is 3 in sdxl
+ # loop over downblocks/upblocks
+ for j in range(2):
+ # loop over resnets/attentions for downblocks
+ hf_down_res_prefix = f"down_blocks.{i}.resnets.{j}."
+ sd_down_res_prefix = f"input_blocks.{3*i + j + 1}.0."
+ unet_conversion_map_layer.append((sd_down_res_prefix, hf_down_res_prefix))
+
+ if i < 3:
+ # no attention layers in down_blocks.3
+ hf_down_atn_prefix = f"down_blocks.{i}.attentions.{j}."
+ sd_down_atn_prefix = f"input_blocks.{3*i + j + 1}.1."
+ unet_conversion_map_layer.append((sd_down_atn_prefix, hf_down_atn_prefix))
+
+ for j in range(3):
+ # loop over resnets/attentions for upblocks
+ hf_up_res_prefix = f"up_blocks.{i}.resnets.{j}."
+ sd_up_res_prefix = f"output_blocks.{3*i + j}.0."
+ unet_conversion_map_layer.append((sd_up_res_prefix, hf_up_res_prefix))
+
+ # if i > 0: commentout for sdxl
+ # no attention layers in up_blocks.0
+ hf_up_atn_prefix = f"up_blocks.{i}.attentions.{j}."
+ sd_up_atn_prefix = f"output_blocks.{3*i + j}.1."
+ unet_conversion_map_layer.append((sd_up_atn_prefix, hf_up_atn_prefix))
+
+ if i < 3:
+ # no downsample in down_blocks.3
+ hf_downsample_prefix = f"down_blocks.{i}.downsamplers.0.conv."
+ sd_downsample_prefix = f"input_blocks.{3*(i+1)}.0.op."
+ unet_conversion_map_layer.append((sd_downsample_prefix, hf_downsample_prefix))
+
+ # no upsample in up_blocks.3
+ hf_upsample_prefix = f"up_blocks.{i}.upsamplers.0."
+ sd_upsample_prefix = f"output_blocks.{3*i + 2}.{2}." # change for sdxl
+ unet_conversion_map_layer.append((sd_upsample_prefix, hf_upsample_prefix))
+
+ hf_mid_atn_prefix = "mid_block.attentions.0."
+ sd_mid_atn_prefix = "middle_block.1."
+ unet_conversion_map_layer.append((sd_mid_atn_prefix, hf_mid_atn_prefix))
+
+ for j in range(2):
+ hf_mid_res_prefix = f"mid_block.resnets.{j}."
+ sd_mid_res_prefix = f"middle_block.{2*j}."
+ unet_conversion_map_layer.append((sd_mid_res_prefix, hf_mid_res_prefix))
+
+ unet_conversion_map_resnet = [
+ # (stable-diffusion, HF Diffusers)
+ ("in_layers.0.", "norm1."),
+ ("in_layers.2.", "conv1."),
+ ("out_layers.0.", "norm2."),
+ ("out_layers.3.", "conv2."),
+ ("emb_layers.1.", "time_emb_proj."),
+ ("skip_connection.", "conv_shortcut."),
+ ]
+
+ unet_conversion_map = []
+ for sd, hf in unet_conversion_map_layer:
+ if "resnets" in hf:
+ for sd_res, hf_res in unet_conversion_map_resnet:
+ unet_conversion_map.append((sd + sd_res, hf + hf_res))
+ else:
+ unet_conversion_map.append((sd, hf))
+
+ for j in range(2):
+ hf_time_embed_prefix = f"time_embedding.linear_{j+1}."
+ sd_time_embed_prefix = f"time_embed.{j*2}."
+ unet_conversion_map.append((sd_time_embed_prefix, hf_time_embed_prefix))
+
+ for j in range(2):
+ hf_label_embed_prefix = f"add_embedding.linear_{j+1}."
+ sd_label_embed_prefix = f"label_emb.0.{j*2}."
+ unet_conversion_map.append((sd_label_embed_prefix, hf_label_embed_prefix))
+
+ unet_conversion_map.append(("input_blocks.0.0.", "conv_in."))
+ unet_conversion_map.append(("out.0.", "conv_norm_out."))
+ unet_conversion_map.append(("out.2.", "conv_out."))
+
+ sd_hf_conversion_map = {sd.replace(".", "_")[:-1]: hf.replace(".", "_")[:-1] for sd, hf in unet_conversion_map}
+ return sd_hf_conversion_map
+
+
+UNET_CONVERSION_MAP = make_unet_conversion_map()
+
+
+class LoRAModule(torch.nn.Module):
+ """
+ replaces forward method of the original Linear, instead of replacing the original Linear module.
+ """
+
+ def __init__(
+ self,
+ lora_name,
+ org_module: torch.nn.Module,
+ multiplier=1.0,
+ lora_dim=4,
+ alpha=1,
+ ):
+ """if alpha == 0 or None, alpha is rank (no scaling)."""
+ super().__init__()
+ self.lora_name = lora_name
+
+ if org_module.__class__.__name__ == "Conv2d" or org_module.__class__.__name__ == "LoRACompatibleConv" or org_module.__class__.__name__ == "InflatedConv3d":
+ in_dim = org_module.in_channels
+ out_dim = org_module.out_channels
+ else:
+ in_dim = org_module.in_features
+ out_dim = org_module.out_features
+
+ self.lora_dim = lora_dim
+
+ self.need_rearrange = False
+ if org_module.__class__.__name__ == "InflatedConv3d":
+ self.need_rearrange = True
+
+ if org_module.__class__.__name__ == "Conv2d" or org_module.__class__.__name__ == "LoRACompatibleConv" or org_module.__class__.__name__ == "InflatedConv3d":
+ kernel_size = org_module.kernel_size
+ stride = org_module.stride
+ padding = org_module.padding
+ self.lora_down = torch.nn.Conv2d(in_dim, self.lora_dim, kernel_size, stride, padding, bias=False)
+ self.lora_up = torch.nn.Conv2d(self.lora_dim, out_dim, (1, 1), (1, 1), bias=False)
+ else:
+ self.lora_down = torch.nn.Linear(in_dim, self.lora_dim, bias=False)
+ self.lora_up = torch.nn.Linear(self.lora_dim, out_dim, bias=False)
+
+ if type(alpha) == torch.Tensor:
+ alpha = alpha.detach().float().numpy() # without casting, bf16 causes error
+ alpha = self.lora_dim if alpha is None or alpha == 0 else alpha
+ self.scale = alpha / self.lora_dim
+ self.register_buffer("alpha", torch.tensor(alpha)) # 勾配計算に含めない / not included in gradient calculation
+
+ # same as microsoft's
+ torch.nn.init.kaiming_uniform_(self.lora_down.weight, a=math.sqrt(5))
+ torch.nn.init.zeros_(self.lora_up.weight)
+
+ self.multiplier = multiplier
+ self.org_module = [org_module]
+ self.enabled = True
+ self.network: LoRANetwork = None
+ self.org_forward = None
+
+ # override org_module's forward method
+ def apply_to(self, multiplier=None):
+ if multiplier is not None:
+ self.multiplier = multiplier
+ if self.org_forward is None:
+ self.org_forward = self.org_module[0].forward
+ self.org_module[0].forward = self.forward
+
+ # restore org_module's forward method
+ def unapply_to(self):
+ if self.org_forward is not None:
+ self.org_module[0].forward = self.org_forward
+
+ # forward with lora
+ # scale is used LoRACompatibleConv, but we ignore it because we have multiplier
+ def forward(self, x, scale=1.0):
+ from einops import rearrange
+ if not self.enabled:
+ return self.org_forward(x)
+
+ if self.need_rearrange:
+ org = self.org_forward(x)
+ frames = x.shape[2]
+ x = rearrange(x, "b c f h w -> (b f) c h w")
+ x = self.lora_up(self.lora_down(x)) * self.multiplier * self.scale
+ x = rearrange(x, "(b f) c h w -> b c f h w", f=frames)
+ return org + x
+ else:
+ return self.org_forward(x) + self.lora_up(self.lora_down(x)) * self.multiplier * self.scale
+
+ def set_network(self, network):
+ self.network = network
+
+ # merge lora weight to org weight
+ def merge_to(self, multiplier=1.0):
+ # get lora weight
+ lora_weight = self.get_weight(multiplier)
+
+ # get org weight
+ org_sd = self.org_module[0].state_dict()
+ org_weight = org_sd["weight"]
+ weight = org_weight + lora_weight.to(org_weight.device, dtype=org_weight.dtype)
+
+ # set weight to org_module
+ org_sd["weight"] = weight
+ self.org_module[0].load_state_dict(org_sd)
+
+ # restore org weight from lora weight
+ def restore_from(self, multiplier=1.0):
+ # get lora weight
+ lora_weight = self.get_weight(multiplier)
+
+ # get org weight
+ org_sd = self.org_module[0].state_dict()
+ org_weight = org_sd["weight"]
+ weight = org_weight - lora_weight.to(org_weight.device, dtype=org_weight.dtype)
+
+ # set weight to org_module
+ org_sd["weight"] = weight
+ self.org_module[0].load_state_dict(org_sd)
+
+ # return lora weight
+ def get_weight(self, multiplier=None):
+ if multiplier is None:
+ multiplier = self.multiplier
+
+ # get up/down weight from module
+ up_weight = self.lora_up.weight.to(torch.float)
+ down_weight = self.lora_down.weight.to(torch.float)
+
+ # pre-calculated weight
+ if len(down_weight.size()) == 2:
+ # linear
+ weight = self.multiplier * (up_weight @ down_weight) * self.scale
+ elif down_weight.size()[2:4] == (1, 1):
+ # conv2d 1x1
+ weight = (
+ self.multiplier
+ * (up_weight.squeeze(3).squeeze(2) @ down_weight.squeeze(3).squeeze(2)).unsqueeze(2).unsqueeze(3)
+ * self.scale
+ )
+ else:
+ # conv2d 3x3
+ conved = torch.nn.functional.conv2d(down_weight.permute(1, 0, 2, 3), up_weight).permute(1, 0, 2, 3)
+ weight = self.multiplier * conved * self.scale
+
+ return weight
+
+
+# Create network from weights for inference, weights are not loaded here
+def create_network_from_weights(
+ text_encoder: Union[CLIPTextModel, List[CLIPTextModel]], unet: UNet2DConditionModel, weights_sd: Dict, multiplier: float = 1.0, is_animatediff = True,
+):
+ # get dim/alpha mapping
+ modules_dim = {}
+ modules_alpha = {}
+
+ for key, value in weights_sd.items():
+ if "." not in key:
+ #print(f"skip {key}")
+ continue
+
+ lora_name = key.split(".")[0]
+ if "alpha" in key:
+ #print(f"{key} have alpha -> modules_alpha")
+ modules_alpha[lora_name] = value
+ elif "lora_down" in key:
+ #print(f"{key} have lora_down -> modules_dim")
+ dim = value.size()[0]
+ modules_dim[lora_name] = dim
+ #print(lora_name, value.size(), dim)
+
+ # support old LoRA without alpha
+ for key in modules_dim.keys():
+ if key not in modules_alpha:
+ modules_alpha[key] = modules_dim[key]
+
+ return LoRANetwork(text_encoder, unet, multiplier=multiplier, modules_dim=modules_dim, modules_alpha=modules_alpha, is_animatediff=is_animatediff)
+
+
+def merge_lora_weights(pipe, weights_sd: Dict, multiplier: float = 1.0):
+ text_encoders = [pipe.text_encoder, pipe.text_encoder_2] if hasattr(pipe, "text_encoder_2") else [pipe.text_encoder]
+ unet = pipe.unet
+
+ lora_network = create_network_from_weights(text_encoders, unet, weights_sd, multiplier=multiplier)
+ lora_network.load_state_dict(weights_sd)
+ lora_network.merge_to(multiplier=multiplier)
+
+
+# block weightや学習に対応しない簡易版 / simple version without block weight and training
+class LoRANetwork(torch.nn.Module):
+ UNET_TARGET_REPLACE_MODULE_TYPE1 = ["Transformer3DModel"]
+ UNET_TARGET_REPLACE_MODULE_CONV2D_3X3_TYPE1 = ["ResnetBlock3D", "Downsample3D", "Upsample3D"]
+ UNET_TARGET_REPLACE_MODULE_TYPE2 = ["Transformer2DModel"]
+ UNET_TARGET_REPLACE_MODULE_CONV2D_3X3_TYPE2 = ["ResnetBlock2D", "Downsample2D", "Upsample2D"]
+ TEXT_ENCODER_TARGET_REPLACE_MODULE = ["CLIPAttention", "CLIPMLP"]
+ LORA_PREFIX_UNET = "lora_unet"
+ LORA_PREFIX_TEXT_ENCODER = "lora_te"
+
+ # SDXL: must starts with LORA_PREFIX_TEXT_ENCODER
+ LORA_PREFIX_TEXT_ENCODER1 = "lora_te1"
+ LORA_PREFIX_TEXT_ENCODER2 = "lora_te2"
+
+ def __init__(
+ self,
+ text_encoder: Union[List[CLIPTextModel], CLIPTextModel],
+ unet: UNet2DConditionModel,
+ multiplier: float = 1.0,
+ modules_dim: Optional[Dict[str, int]] = None,
+ modules_alpha: Optional[Dict[str, int]] = None,
+ varbose: Optional[bool] = False,
+ is_animatediff: bool = True,
+ ) -> None:
+ super().__init__()
+ self.multiplier = multiplier
+
+ print(f"create LoRA network from weights")
+
+ # convert SDXL Stability AI's U-Net modules to Diffusers
+ converted = self.convert_unet_modules(modules_dim, modules_alpha)
+ if converted:
+ print(f"converted {converted} Stability AI's U-Net LoRA modules to Diffusers (SDXL)")
+
+ # create module instances
+ def create_modules(
+ is_unet: bool,
+ text_encoder_idx: Optional[int], # None, 1, 2
+ root_module: torch.nn.Module,
+ target_replace_modules: List[torch.nn.Module],
+ ) -> List[LoRAModule]:
+ prefix = (
+ self.LORA_PREFIX_UNET
+ if is_unet
+ else (
+ self.LORA_PREFIX_TEXT_ENCODER
+ if text_encoder_idx is None
+ else (self.LORA_PREFIX_TEXT_ENCODER1 if text_encoder_idx == 1 else self.LORA_PREFIX_TEXT_ENCODER2)
+ )
+ )
+ loras = []
+ skipped = []
+ for name, module in root_module.named_modules():
+ if module.__class__.__name__ in target_replace_modules:
+ for child_name, child_module in module.named_modules():
+ #print(f"{name=} / {child_name=} / {child_module.__class__.__name__}")
+ is_linear = (
+ child_module.__class__.__name__ == "Linear" or child_module.__class__.__name__ == "LoRACompatibleLinear"
+ )
+ is_conv2d = (
+ child_module.__class__.__name__ == "Conv2d" or child_module.__class__.__name__ == "LoRACompatibleConv" or child_module.__class__.__name__ == "InflatedConv3d"
+ )
+
+ if is_linear or is_conv2d:
+ lora_name = prefix + "." + name + "." + child_name
+ lora_name = lora_name.replace(".", "_")
+
+ if lora_name not in modules_dim:
+ print(f"skipped {lora_name} (not found in modules_dim)")
+ skipped.append(lora_name)
+ continue
+
+ dim = modules_dim[lora_name]
+ alpha = modules_alpha[lora_name]
+ lora = LoRAModule(
+ lora_name,
+ child_module,
+ self.multiplier,
+ dim,
+ alpha,
+ )
+ #print(f"{lora_name=}")
+ loras.append(lora)
+ return loras, skipped
+
+ text_encoders = text_encoder if type(text_encoder) == list else [text_encoder]
+
+ # create LoRA for text encoder
+ # 毎回すべてのモジュールを作るのは無駄なので要検討 / it is wasteful to create all modules every time, need to consider
+ self.text_encoder_loras: List[LoRAModule] = []
+ skipped_te = []
+ for i, text_encoder in enumerate(text_encoders):
+ if len(text_encoders) > 1:
+ index = i + 1
+ else:
+ index = None
+
+ text_encoder_loras, skipped = create_modules(False, index, text_encoder, LoRANetwork.TEXT_ENCODER_TARGET_REPLACE_MODULE)
+ self.text_encoder_loras.extend(text_encoder_loras)
+ skipped_te += skipped
+ print(f"create LoRA for Text Encoder: {len(self.text_encoder_loras)} modules.")
+ if len(skipped_te) > 0:
+ print(f"skipped {len(skipped_te)} modules because of missing weight for text encoder.")
+
+ # extend U-Net target modules to include Conv2d 3x3
+ if is_animatediff:
+ target_modules = LoRANetwork.UNET_TARGET_REPLACE_MODULE_TYPE1 + LoRANetwork.UNET_TARGET_REPLACE_MODULE_CONV2D_3X3_TYPE1
+ else:
+ target_modules = LoRANetwork.UNET_TARGET_REPLACE_MODULE_TYPE2 + LoRANetwork.UNET_TARGET_REPLACE_MODULE_CONV2D_3X3_TYPE2
+
+ self.unet_loras: List[LoRAModule]
+ self.unet_loras, skipped_un = create_modules(True, None, unet, target_modules)
+ print(f"create LoRA for U-Net: {len(self.unet_loras)} modules.")
+ if len(skipped_un) > 0:
+ print(f"skipped {len(skipped_un)} modules because of missing weight for U-Net.")
+
+ # assertion
+ names = set()
+ for lora in self.text_encoder_loras + self.unet_loras:
+ names.add(lora.lora_name)
+ for lora_name in modules_dim.keys():
+ assert lora_name in names, f"{lora_name} is not found in created LoRA modules."
+
+ # make to work load_state_dict
+ for lora in self.text_encoder_loras + self.unet_loras:
+ self.add_module(lora.lora_name, lora)
+
+ # SDXL: convert SDXL Stability AI's U-Net modules to Diffusers
+ def convert_unet_modules(self, modules_dim, modules_alpha):
+ converted_count = 0
+ not_converted_count = 0
+
+ map_keys = list(UNET_CONVERSION_MAP.keys())
+ map_keys.sort()
+
+ for key in list(modules_dim.keys()):
+ if key.startswith(LoRANetwork.LORA_PREFIX_UNET + "_"):
+ search_key = key.replace(LoRANetwork.LORA_PREFIX_UNET + "_", "")
+ position = bisect.bisect_right(map_keys, search_key)
+ map_key = map_keys[position - 1]
+ if search_key.startswith(map_key):
+ new_key = key.replace(map_key, UNET_CONVERSION_MAP[map_key])
+ modules_dim[new_key] = modules_dim[key]
+ modules_alpha[new_key] = modules_alpha[key]
+ del modules_dim[key]
+ del modules_alpha[key]
+ converted_count += 1
+ else:
+ not_converted_count += 1
+ assert (
+ converted_count == 0 or not_converted_count == 0
+ ), f"some modules are not converted: {converted_count} converted, {not_converted_count} not converted"
+ return converted_count
+
+ def set_multiplier(self, multiplier):
+ self.multiplier = multiplier
+ for lora in self.text_encoder_loras + self.unet_loras:
+ lora.multiplier = self.multiplier
+
+ def active(self, multiplier):
+ self.multiplier = multiplier
+ for lora in self.text_encoder_loras + self.unet_loras:
+ lora.multiplier = self.multiplier
+ lora.enabled = True
+
+ def deactive(self):
+ for lora in self.text_encoder_loras + self.unet_loras:
+ lora.enabled = False
+
+ def apply_to(self, multiplier=1.0, apply_text_encoder=True, apply_unet=True):
+ if apply_text_encoder:
+ print("enable LoRA for text encoder")
+ for lora in self.text_encoder_loras:
+ lora.apply_to(multiplier)
+ if apply_unet:
+ print("enable LoRA for U-Net")
+ for lora in self.unet_loras:
+ lora.apply_to(multiplier)
+
+ def unapply_to(self):
+ for lora in self.text_encoder_loras + self.unet_loras:
+ lora.unapply_to()
+
+ def merge_to(self, multiplier=1.0):
+ print("merge LoRA weights to original weights")
+ for lora in tqdm(self.text_encoder_loras + self.unet_loras):
+ lora.merge_to(multiplier)
+ print(f"weights are merged")
+
+ def restore_from(self, multiplier=1.0):
+ print("restore LoRA weights from original weights")
+ for lora in tqdm(self.text_encoder_loras + self.unet_loras):
+ lora.restore_from(multiplier)
+ print(f"weights are restored")
+
+ def load_state_dict(self, state_dict: Mapping[str, Any], strict: bool = True):
+ # convert SDXL Stability AI's state dict to Diffusers' based state dict
+ map_keys = list(UNET_CONVERSION_MAP.keys()) # prefix of U-Net modules
+ map_keys.sort()
+ for key in list(state_dict.keys()):
+ if key.startswith(LoRANetwork.LORA_PREFIX_UNET + "_"):
+ search_key = key.replace(LoRANetwork.LORA_PREFIX_UNET + "_", "")
+ position = bisect.bisect_right(map_keys, search_key)
+ map_key = map_keys[position - 1]
+ if search_key.startswith(map_key):
+ new_key = key.replace(map_key, UNET_CONVERSION_MAP[map_key])
+ state_dict[new_key] = state_dict[key]
+ del state_dict[key]
+
+ # in case of V2, some weights have different shape, so we need to convert them
+ # because V2 LoRA is based on U-Net created by use_linear_projection=False
+ my_state_dict = self.state_dict()
+ for key in state_dict.keys():
+ if state_dict[key].size() != my_state_dict[key].size():
+ # print(f"convert {key} from {state_dict[key].size()} to {my_state_dict[key].size()}")
+ state_dict[key] = state_dict[key].view(my_state_dict[key].size())
+
+ return super().load_state_dict(state_dict, strict)
+
+
+if __name__ == "__main__":
+ # sample code to use LoRANetwork
+ import argparse
+ import os
+
+ import torch
+ from diffusers import StableDiffusionPipeline, StableDiffusionXLPipeline
+
+ device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--model_id", type=str, default=None, help="model id for huggingface")
+ parser.add_argument("--lora_weights", type=str, default=None, help="path to LoRA weights")
+ parser.add_argument("--sdxl", action="store_true", help="use SDXL model")
+ parser.add_argument("--prompt", type=str, default="A photo of cat", help="prompt text")
+ parser.add_argument("--negative_prompt", type=str, default="", help="negative prompt text")
+ parser.add_argument("--seed", type=int, default=0, help="random seed")
+ args = parser.parse_args()
+
+ image_prefix = args.model_id.replace("/", "_") + "_"
+
+ # load Diffusers model
+ print(f"load model from {args.model_id}")
+ pipe: Union[StableDiffusionPipeline, StableDiffusionXLPipeline]
+ if args.sdxl:
+ # use_safetensors=True does not work with 0.18.2
+ pipe = StableDiffusionXLPipeline.from_pretrained(args.model_id, variant="fp16", torch_dtype=torch.float16)
+ else:
+ pipe = StableDiffusionPipeline.from_pretrained(args.model_id, variant="fp16", torch_dtype=torch.float16)
+ pipe.to(device)
+ pipe.set_use_memory_efficient_attention_xformers(True)
+
+ text_encoders = [pipe.text_encoder, pipe.text_encoder_2] if args.sdxl else [pipe.text_encoder]
+
+ # load LoRA weights
+ print(f"load LoRA weights from {args.lora_weights}")
+ if os.path.splitext(args.lora_weights)[1] == ".safetensors":
+ from safetensors.torch import load_file
+
+ lora_sd = load_file(args.lora_weights)
+ else:
+ lora_sd = torch.load(args.lora_weights)
+
+ # create by LoRA weights and load weights
+ print(f"create LoRA network")
+ lora_network: LoRANetwork = create_network_from_weights(text_encoders, pipe.unet, lora_sd, multiplier=1.0)
+
+ print(f"load LoRA network weights")
+ lora_network.load_state_dict(lora_sd)
+
+ lora_network.to(device, dtype=pipe.unet.dtype) # required to apply_to. merge_to works without this
+
+ # 必要があれば、元のモデルの重みをバックアップしておく
+ # back-up unet/text encoder weights if necessary
+ def detach_and_move_to_cpu(state_dict):
+ for k, v in state_dict.items():
+ state_dict[k] = v.detach().cpu()
+ return state_dict
+
+ org_unet_sd = pipe.unet.state_dict()
+ detach_and_move_to_cpu(org_unet_sd)
+
+ org_text_encoder_sd = pipe.text_encoder.state_dict()
+ detach_and_move_to_cpu(org_text_encoder_sd)
+
+ if args.sdxl:
+ org_text_encoder_2_sd = pipe.text_encoder_2.state_dict()
+ detach_and_move_to_cpu(org_text_encoder_2_sd)
+
+ def seed_everything(seed):
+ torch.manual_seed(seed)
+ torch.cuda.manual_seed_all(seed)
+ np.random.seed(seed)
+ random.seed(seed)
+
+ # create image with original weights
+ print(f"create image with original weights")
+ seed_everything(args.seed)
+ image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
+ image.save(image_prefix + "original.png")
+
+ # apply LoRA network to the model: slower than merge_to, but can be reverted easily
+ print(f"apply LoRA network to the model")
+ lora_network.apply_to(multiplier=1.0)
+
+ print(f"create image with applied LoRA")
+ seed_everything(args.seed)
+ image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
+ image.save(image_prefix + "applied_lora.png")
+
+ # unapply LoRA network to the model
+ print(f"unapply LoRA network to the model")
+ lora_network.unapply_to()
+
+ print(f"create image with unapplied LoRA")
+ seed_everything(args.seed)
+ image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
+ image.save(image_prefix + "unapplied_lora.png")
+
+ # merge LoRA network to the model: faster than apply_to, but requires back-up of original weights (or unmerge_to)
+ print(f"merge LoRA network to the model")
+ lora_network.merge_to(multiplier=1.0)
+
+ print(f"create image with LoRA")
+ seed_everything(args.seed)
+ image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
+ image.save(image_prefix + "merged_lora.png")
+
+ # restore (unmerge) LoRA weights: numerically unstable
+ # マージされた重みを元に戻す。計算誤差のため、元の重みと完全に一致しないことがあるかもしれない
+ # 保存したstate_dictから元の重みを復元するのが確実
+ print(f"restore (unmerge) LoRA weights")
+ lora_network.restore_from(multiplier=1.0)
+
+ print(f"create image without LoRA")
+ seed_everything(args.seed)
+ image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
+ image.save(image_prefix + "unmerged_lora.png")
+
+ # restore original weights
+ print(f"restore original weights")
+ pipe.unet.load_state_dict(org_unet_sd)
+ pipe.text_encoder.load_state_dict(org_text_encoder_sd)
+ if args.sdxl:
+ pipe.text_encoder_2.load_state_dict(org_text_encoder_2_sd)
+
+ print(f"create image with restored original weights")
+ seed_everything(args.seed)
+ image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
+ image.save(image_prefix + "restore_original.png")
+
+ # use convenience function to merge LoRA weights
+ print(f"merge LoRA weights with convenience function")
+ merge_lora_weights(pipe, lora_sd, multiplier=1.0)
+
+ print(f"create image with merged LoRA weights")
+ seed_everything(args.seed)
+ image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
+ image.save(image_prefix + "convenience_merged_lora.png")
diff --git a/animate/src/animatediff/utils/lpw_stable_diffusion.py b/animate/src/animatediff/utils/lpw_stable_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..2773170fe13f12c63f3bcc64587d6c32c5f91478
--- /dev/null
+++ b/animate/src/animatediff/utils/lpw_stable_diffusion.py
@@ -0,0 +1,1431 @@
+import inspect
+import re
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import numpy as np
+import PIL.Image
+import torch
+from packaging import version
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from diffusers import DiffusionPipeline
+from diffusers.configuration_utils import FrozenDict
+from diffusers.image_processor import VaeImageProcessor
+from diffusers.loaders import FromSingleFileMixin, StableDiffusionLoraLoaderMixin, TextualInversionLoaderMixin
+from diffusers.models import AutoencoderKL, UNet2DConditionModel
+from diffusers.models.lora import adjust_lora_scale_text_encoder
+from diffusers.pipelines.pipeline_utils import StableDiffusionMixin
+from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput, StableDiffusionSafetyChecker
+from diffusers.schedulers import KarrasDiffusionSchedulers
+from diffusers.utils import (
+ PIL_INTERPOLATION,
+ USE_PEFT_BACKEND,
+ deprecate,
+ logging,
+ scale_lora_layers,
+ unscale_lora_layers,
+)
+from diffusers.utils.torch_utils import randn_tensor
+
+
+# ------------------------------------------------------------------------------
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+re_attention = re.compile(
+ r"""
+\\\(|
+\\\)|
+\\\[|
+\\]|
+\\\\|
+\\|
+\(|
+\[|
+:([+-]?[.\d]+)\)|
+\)|
+]|
+[^\\()\[\]:]+|
+:
+""",
+ re.X,
+)
+
+
+def parse_prompt_attention(text):
+ """
+ Parses a string with attention tokens and returns a list of pairs: text and its associated weight.
+ Accepted tokens are:
+ (abc) - increases attention to abc by a multiplier of 1.1
+ (abc:3.12) - increases attention to abc by a multiplier of 3.12
+ [abc] - decreases attention to abc by a multiplier of 1.1
+ \\( - literal character '('
+ \\[ - literal character '['
+ \\) - literal character ')'
+ \\] - literal character ']'
+ \\ - literal character '\'
+ anything else - just text
+ >>> parse_prompt_attention('normal text')
+ [['normal text', 1.0]]
+ >>> parse_prompt_attention('an (important) word')
+ [['an ', 1.0], ['important', 1.1], [' word', 1.0]]
+ >>> parse_prompt_attention('(unbalanced')
+ [['unbalanced', 1.1]]
+ >>> parse_prompt_attention('\\(literal\\]')
+ [['(literal]', 1.0]]
+ >>> parse_prompt_attention('(unnecessary)(parens)')
+ [['unnecessaryparens', 1.1]]
+ >>> parse_prompt_attention('a (((house:1.3)) [on] a (hill:0.5), sun, (((sky))).')
+ [['a ', 1.0],
+ ['house', 1.5730000000000004],
+ [' ', 1.1],
+ ['on', 1.0],
+ [' a ', 1.1],
+ ['hill', 0.55],
+ [', sun, ', 1.1],
+ ['sky', 1.4641000000000006],
+ ['.', 1.1]]
+ """
+
+ res = []
+ round_brackets = []
+ square_brackets = []
+
+ round_bracket_multiplier = 1.1
+ square_bracket_multiplier = 1 / 1.1
+
+ def multiply_range(start_position, multiplier):
+ for p in range(start_position, len(res)):
+ res[p][1] *= multiplier
+
+ for m in re_attention.finditer(text):
+ text = m.group(0)
+ weight = m.group(1)
+
+ if text.startswith("\\"):
+ res.append([text[1:], 1.0])
+ elif text == "(":
+ round_brackets.append(len(res))
+ elif text == "[":
+ square_brackets.append(len(res))
+ elif weight is not None and len(round_brackets) > 0:
+ multiply_range(round_brackets.pop(), float(weight))
+ elif text == ")" and len(round_brackets) > 0:
+ multiply_range(round_brackets.pop(), round_bracket_multiplier)
+ elif text == "]" and len(square_brackets) > 0:
+ multiply_range(square_brackets.pop(), square_bracket_multiplier)
+ else:
+ res.append([text, 1.0])
+
+ for pos in round_brackets:
+ multiply_range(pos, round_bracket_multiplier)
+
+ for pos in square_brackets:
+ multiply_range(pos, square_bracket_multiplier)
+
+ if len(res) == 0:
+ res = [["", 1.0]]
+
+ # merge runs of identical weights
+ i = 0
+ while i + 1 < len(res):
+ if res[i][1] == res[i + 1][1]:
+ res[i][0] += res[i + 1][0]
+ res.pop(i + 1)
+ else:
+ i += 1
+
+ return res
+
+
+def get_prompts_with_weights(pipe: DiffusionPipeline, prompt: List[str], max_length: int):
+ r"""
+ Tokenize a list of prompts and return its tokens with weights of each token.
+
+ No padding, starting or ending token is included.
+ """
+ tokens = []
+ weights = []
+ truncated = False
+ for text in prompt:
+ texts_and_weights = parse_prompt_attention(text)
+ text_token = []
+ text_weight = []
+ for word, weight in texts_and_weights:
+ # tokenize and discard the starting and the ending token
+ token = pipe.tokenizer(word).input_ids[1:-1]
+ text_token += token
+ # copy the weight by length of token
+ text_weight += [weight] * len(token)
+ # stop if the text is too long (longer than truncation limit)
+ if len(text_token) > max_length:
+ truncated = True
+ break
+ # truncate
+ if len(text_token) > max_length:
+ truncated = True
+ text_token = text_token[:max_length]
+ text_weight = text_weight[:max_length]
+ tokens.append(text_token)
+ weights.append(text_weight)
+ if truncated:
+ logger.warning("Prompt was truncated. Try to shorten the prompt or increase max_embeddings_multiples")
+ return tokens, weights
+
+
+def pad_tokens_and_weights(tokens, weights, max_length, bos, eos, pad, no_boseos_middle=True, chunk_length=77):
+ r"""
+ Pad the tokens (with starting and ending tokens) and weights (with 1.0) to max_length.
+ """
+ max_embeddings_multiples = (max_length - 2) // (chunk_length - 2)
+ weights_length = max_length if no_boseos_middle else max_embeddings_multiples * chunk_length
+ for i in range(len(tokens)):
+ tokens[i] = [bos] + tokens[i] + [pad] * (max_length - 1 - len(tokens[i]) - 1) + [eos]
+ if no_boseos_middle:
+ weights[i] = [1.0] + weights[i] + [1.0] * (max_length - 1 - len(weights[i]))
+ else:
+ w = []
+ if len(weights[i]) == 0:
+ w = [1.0] * weights_length
+ else:
+ for j in range(max_embeddings_multiples):
+ w.append(1.0) # weight for starting token in this chunk
+ w += weights[i][j * (chunk_length - 2) : min(len(weights[i]), (j + 1) * (chunk_length - 2))]
+ w.append(1.0) # weight for ending token in this chunk
+ w += [1.0] * (weights_length - len(w))
+ weights[i] = w[:]
+
+ return tokens, weights
+
+
+def get_unweighted_text_embeddings(
+ pipe: DiffusionPipeline,
+ text_input: torch.Tensor,
+ chunk_length: int,
+ no_boseos_middle: Optional[bool] = True,
+ clip_skip: Optional[int] = None,
+):
+ """
+ When the length of tokens is a multiple of the capacity of the text encoder,
+ it should be split into chunks and sent to the text encoder individually.
+ """
+ max_embeddings_multiples = (text_input.shape[1] - 2) // (chunk_length - 2)
+ if max_embeddings_multiples > 1:
+ text_embeddings = []
+ for i in range(max_embeddings_multiples):
+ # extract the i-th chunk
+ text_input_chunk = text_input[:, i * (chunk_length - 2) : (i + 1) * (chunk_length - 2) + 2].clone()
+
+ # cover the head and the tail by the starting and the ending tokens
+ text_input_chunk[:, 0] = text_input[0, 0]
+ text_input_chunk[:, -1] = text_input[0, -1]
+ if clip_skip is None:
+ prompt_embeds = pipe.text_encoder(text_input_chunk.to(pipe.device))
+ text_embedding = prompt_embeds[0]
+ else:
+ prompt_embeds = pipe.text_encoder(text_input_chunk.to(pipe.device), output_hidden_states=True)
+ # Access the `hidden_states` first, that contains a tuple of
+ # all the hidden states from the encoder layers. Then index into
+ # the tuple to access the hidden states from the desired layer.
+ prompt_embeds = prompt_embeds[-1][-(clip_skip + 1)]
+ # We also need to apply the final LayerNorm here to not mess with the
+ # representations. The `last_hidden_states` that we typically use for
+ # obtaining the final prompt representations passes through the LayerNorm
+ # layer.
+ text_embedding = pipe.text_encoder.text_model.final_layer_norm(prompt_embeds)
+
+ if no_boseos_middle:
+ if i == 0:
+ # discard the ending token
+ text_embedding = text_embedding[:, :-1]
+ elif i == max_embeddings_multiples - 1:
+ # discard the starting token
+ text_embedding = text_embedding[:, 1:]
+ else:
+ # discard both starting and ending tokens
+ text_embedding = text_embedding[:, 1:-1]
+
+ text_embeddings.append(text_embedding)
+ text_embeddings = torch.concat(text_embeddings, axis=1)
+ else:
+ if clip_skip is None:
+ clip_skip = 0
+ prompt_embeds = pipe.text_encoder(text_input, output_hidden_states=True)[-1][-(clip_skip + 1)]
+ text_embeddings = pipe.text_encoder.text_model.final_layer_norm(prompt_embeds)
+ return text_embeddings
+
+
+def get_weighted_text_embeddings(
+ pipe: DiffusionPipeline,
+ prompt: Union[str, List[str]],
+ uncond_prompt: Optional[Union[str, List[str]]] = None,
+ max_embeddings_multiples: Optional[int] = 3,
+ no_boseos_middle: Optional[bool] = False,
+ skip_parsing: Optional[bool] = False,
+ skip_weighting: Optional[bool] = False,
+ clip_skip=None,
+ lora_scale=None,
+):
+ r"""
+ Prompts can be assigned with local weights using brackets. For example,
+ prompt 'A (very beautiful) masterpiece' highlights the words 'very beautiful',
+ and the embedding tokens corresponding to the words get multiplied by a constant, 1.1.
+
+ Also, to regularize of the embedding, the weighted embedding would be scaled to preserve the original mean.
+
+ Args:
+ pipe (`DiffusionPipeline`):
+ Pipe to provide access to the tokenizer and the text encoder.
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ uncond_prompt (`str` or `List[str]`):
+ The unconditional prompt or prompts for guide the image generation. If unconditional prompt
+ is provided, the embeddings of prompt and uncond_prompt are concatenated.
+ max_embeddings_multiples (`int`, *optional*, defaults to `3`):
+ The max multiple length of prompt embeddings compared to the max output length of text encoder.
+ no_boseos_middle (`bool`, *optional*, defaults to `False`):
+ If the length of text token is multiples of the capacity of text encoder, whether reserve the starting and
+ ending token in each of the chunk in the middle.
+ skip_parsing (`bool`, *optional*, defaults to `False`):
+ Skip the parsing of brackets.
+ skip_weighting (`bool`, *optional*, defaults to `False`):
+ Skip the weighting. When the parsing is skipped, it is forced True.
+ """
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(pipe, StableDiffusionLoraLoaderMixin):
+ pipe._lora_scale = lora_scale
+
+ # dynamically adjust the LoRA scale
+ if not USE_PEFT_BACKEND:
+ adjust_lora_scale_text_encoder(pipe.text_encoder, lora_scale)
+ else:
+ scale_lora_layers(pipe.text_encoder, lora_scale)
+ max_length = (pipe.tokenizer.model_max_length - 2) * max_embeddings_multiples + 2
+ if isinstance(prompt, str):
+ prompt = [prompt]
+
+ if not skip_parsing:
+ prompt_tokens, prompt_weights = get_prompts_with_weights(pipe, prompt, max_length - 2)
+ if uncond_prompt is not None:
+ if isinstance(uncond_prompt, str):
+ uncond_prompt = [uncond_prompt]
+ uncond_tokens, uncond_weights = get_prompts_with_weights(pipe, uncond_prompt, max_length - 2)
+ else:
+ prompt_tokens = [
+ token[1:-1] for token in pipe.tokenizer(prompt, max_length=max_length, truncation=True).input_ids
+ ]
+ prompt_weights = [[1.0] * len(token) for token in prompt_tokens]
+ if uncond_prompt is not None:
+ if isinstance(uncond_prompt, str):
+ uncond_prompt = [uncond_prompt]
+ uncond_tokens = [
+ token[1:-1]
+ for token in pipe.tokenizer(uncond_prompt, max_length=max_length, truncation=True).input_ids
+ ]
+ uncond_weights = [[1.0] * len(token) for token in uncond_tokens]
+
+ # round up the longest length of tokens to a multiple of (model_max_length - 2)
+ max_length = max([len(token) for token in prompt_tokens])
+ if uncond_prompt is not None:
+ max_length = max(max_length, max([len(token) for token in uncond_tokens]))
+
+ max_embeddings_multiples = min(
+ max_embeddings_multiples,
+ (max_length - 1) // (pipe.tokenizer.model_max_length - 2) + 1,
+ )
+ max_embeddings_multiples = max(1, max_embeddings_multiples)
+ max_length = (pipe.tokenizer.model_max_length - 2) * max_embeddings_multiples + 2
+
+ # pad the length of tokens and weights
+ bos = pipe.tokenizer.bos_token_id
+ eos = pipe.tokenizer.eos_token_id
+ pad = getattr(pipe.tokenizer, "pad_token_id", eos)
+ prompt_tokens, prompt_weights = pad_tokens_and_weights(
+ prompt_tokens,
+ prompt_weights,
+ max_length,
+ bos,
+ eos,
+ pad,
+ no_boseos_middle=no_boseos_middle,
+ chunk_length=pipe.tokenizer.model_max_length,
+ )
+ prompt_tokens = torch.tensor(prompt_tokens, dtype=torch.long, device=pipe.device)
+ if uncond_prompt is not None:
+ uncond_tokens, uncond_weights = pad_tokens_and_weights(
+ uncond_tokens,
+ uncond_weights,
+ max_length,
+ bos,
+ eos,
+ pad,
+ no_boseos_middle=no_boseos_middle,
+ chunk_length=pipe.tokenizer.model_max_length,
+ )
+ uncond_tokens = torch.tensor(uncond_tokens, dtype=torch.long, device=pipe.device)
+
+ # get the embeddings
+ text_embeddings = get_unweighted_text_embeddings(
+ pipe, prompt_tokens, pipe.tokenizer.model_max_length, no_boseos_middle=no_boseos_middle, clip_skip=clip_skip
+ )
+ prompt_weights = torch.tensor(prompt_weights, dtype=text_embeddings.dtype, device=text_embeddings.device)
+ if uncond_prompt is not None:
+ uncond_embeddings = get_unweighted_text_embeddings(
+ pipe,
+ uncond_tokens,
+ pipe.tokenizer.model_max_length,
+ no_boseos_middle=no_boseos_middle,
+ clip_skip=clip_skip,
+ )
+ uncond_weights = torch.tensor(uncond_weights, dtype=uncond_embeddings.dtype, device=uncond_embeddings.device)
+
+ # assign weights to the prompts and normalize in the sense of mean
+ # TODO: should we normalize by chunk or in a whole (current implementation)?
+ if (not skip_parsing) and (not skip_weighting):
+ previous_mean = text_embeddings.float().mean(axis=[-2, -1]).to(text_embeddings.dtype)
+ text_embeddings *= prompt_weights.unsqueeze(-1)
+ current_mean = text_embeddings.float().mean(axis=[-2, -1]).to(text_embeddings.dtype)
+ text_embeddings *= (previous_mean / current_mean).unsqueeze(-1).unsqueeze(-1)
+ if uncond_prompt is not None:
+ previous_mean = uncond_embeddings.float().mean(axis=[-2, -1]).to(uncond_embeddings.dtype)
+ uncond_embeddings *= uncond_weights.unsqueeze(-1)
+ current_mean = uncond_embeddings.float().mean(axis=[-2, -1]).to(uncond_embeddings.dtype)
+ uncond_embeddings *= (previous_mean / current_mean).unsqueeze(-1).unsqueeze(-1)
+
+ if pipe.text_encoder is not None:
+ if isinstance(pipe, StableDiffusionLoraLoaderMixin) and USE_PEFT_BACKEND:
+ # Retrieve the original scale by scaling back the LoRA layers
+ unscale_lora_layers(pipe.text_encoder, lora_scale)
+
+ if uncond_prompt is not None:
+ return text_embeddings, uncond_embeddings
+ return text_embeddings, None
+
+
+def preprocess_image(image, batch_size):
+ w, h = image.size
+ w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
+ image = image.resize((w, h), resample=PIL_INTERPOLATION["lanczos"])
+ image = np.array(image).astype(np.float32) / 255.0
+ image = np.vstack([image[None].transpose(0, 3, 1, 2)] * batch_size)
+ image = torch.from_numpy(image)
+ return 2.0 * image - 1.0
+
+
+def preprocess_mask(mask, batch_size, scale_factor=8):
+ if not isinstance(mask, torch.Tensor):
+ mask = mask.convert("L")
+ w, h = mask.size
+ w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
+ mask = mask.resize((w // scale_factor, h // scale_factor), resample=PIL_INTERPOLATION["nearest"])
+ mask = np.array(mask).astype(np.float32) / 255.0
+ mask = np.tile(mask, (4, 1, 1))
+ mask = np.vstack([mask[None]] * batch_size)
+ mask = 1 - mask # repaint white, keep black
+ mask = torch.from_numpy(mask)
+ return mask
+
+ else:
+ valid_mask_channel_sizes = [1, 3]
+ # if mask channel is fourth tensor dimension, permute dimensions to pytorch standard (B, C, H, W)
+ if mask.shape[3] in valid_mask_channel_sizes:
+ mask = mask.permute(0, 3, 1, 2)
+ elif mask.shape[1] not in valid_mask_channel_sizes:
+ raise ValueError(
+ f"Mask channel dimension of size in {valid_mask_channel_sizes} should be second or fourth dimension,"
+ f" but received mask of shape {tuple(mask.shape)}"
+ )
+ # (potentially) reduce mask channel dimension from 3 to 1 for broadcasting to latent shape
+ mask = mask.mean(dim=1, keepdim=True)
+ h, w = mask.shape[-2:]
+ h, w = (x - x % 8 for x in (h, w)) # resize to integer multiple of 8
+ mask = torch.nn.functional.interpolate(mask, (h // scale_factor, w // scale_factor))
+ return mask
+
+
+class StableDiffusionLongPromptWeightingPipeline(
+ DiffusionPipeline,
+ StableDiffusionMixin,
+ TextualInversionLoaderMixin,
+ StableDiffusionLoraLoaderMixin,
+ FromSingleFileMixin,
+):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion without tokens length limit, and support parsing
+ weighting in prompt.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/CompVis/stable-diffusion-v1-4) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+
+ model_cpu_offload_seq = "text_encoder-->unet->vae"
+ _optional_components = ["safety_checker", "feature_extractor"]
+ _exclude_from_cpu_offload = ["safety_checker"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if scheduler is not None and getattr(scheduler.config, "steps_offset", 1) != 1:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
+ f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
+ "to update the config accordingly as leaving `steps_offset` might led to incorrect results"
+ " in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
+ " it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
+ " file"
+ )
+ deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["steps_offset"] = 1
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if scheduler is not None and getattr(scheduler.config, "clip_sample", False) is True:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
+ " `clip_sample` should be set to False in the configuration file. Please make sure to update the"
+ " config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
+ " future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
+ " nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
+ )
+ deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["clip_sample"] = False
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ is_unet_version_less_0_9_0 = (
+ unet is not None
+ and hasattr(unet.config, "_diffusers_version")
+ and version.parse(version.parse(unet.config._diffusers_version).base_version) < version.parse("0.9.0.dev0")
+ )
+ is_unet_sample_size_less_64 = (
+ unet is not None and hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
+ )
+ if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
+ deprecation_message = (
+ "The configuration file of the unet has set the default `sample_size` to smaller than"
+ " 64 which seems highly unlikely. If your checkpoint is a fine-tuned version of any of the"
+ " following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
+ " CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
+ " \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
+ " configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
+ " in the config might lead to incorrect results in future versions. If you have downloaded this"
+ " checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
+ " the `unet/config.json` file"
+ )
+ deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(unet.config)
+ new_config["sample_size"] = 64
+ unet._internal_dict = FrozenDict(new_config)
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1) if getattr(self, "vae", None) else 8
+
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.register_to_config(
+ requires_safety_checker=requires_safety_checker,
+ )
+
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ max_embeddings_multiples=3,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ clip_skip: Optional[int] = None,
+ lora_scale: Optional[float] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `list(int)`):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ max_embeddings_multiples (`int`, *optional*, defaults to `3`):
+ The max multiple length of prompt embeddings compared to the max output length of text encoder.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if negative_prompt_embeds is None:
+ if negative_prompt is None:
+ negative_prompt = [""] * batch_size
+ elif isinstance(negative_prompt, str):
+ negative_prompt = [negative_prompt] * batch_size
+ if batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ if prompt_embeds is None or negative_prompt_embeds is None:
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ negative_prompt = self.maybe_convert_prompt(negative_prompt, self.tokenizer)
+
+ prompt_embeds1, negative_prompt_embeds1 = get_weighted_text_embeddings(
+ pipe=self,
+ prompt=prompt,
+ uncond_prompt=negative_prompt if do_classifier_free_guidance else None,
+ max_embeddings_multiples=max_embeddings_multiples,
+ clip_skip=clip_skip,
+ lora_scale=lora_scale,
+ )
+ if prompt_embeds is None:
+ prompt_embeds = prompt_embeds1
+ if negative_prompt_embeds is None:
+ negative_prompt_embeds = negative_prompt_embeds1
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ if do_classifier_free_guidance:
+ bs_embed, seq_len, _ = negative_prompt_embeds.shape
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ def check_inputs(
+ self,
+ prompt,
+ height,
+ width,
+ strength,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if strength < 0 or strength > 1:
+ raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ def get_timesteps(self, num_inference_steps, strength, device, is_text2img):
+ if is_text2img:
+ return self.scheduler.timesteps.to(device), num_inference_steps
+ else:
+ # get the original timestep using init_timestep
+ init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
+
+ t_start = max(num_inference_steps - init_timestep, 0)
+ timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
+
+ return timesteps, num_inference_steps - t_start
+
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def prepare_latents(
+ self,
+ image,
+ timestep,
+ num_images_per_prompt,
+ batch_size,
+ num_channels_latents,
+ height,
+ width,
+ dtype,
+ device,
+ generator,
+ latents=None,
+ ):
+ if image is None:
+ batch_size = batch_size * num_images_per_prompt
+ shape = (
+ batch_size,
+ num_channels_latents,
+ int(height) // self.vae_scale_factor,
+ int(width) // self.vae_scale_factor,
+ )
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents, None, None
+ else:
+ image = image.to(device=self.device, dtype=dtype)
+ init_latent_dist = self.vae.encode(image).latent_dist
+ init_latents = init_latent_dist.sample(generator=generator)
+ init_latents = self.vae.config.scaling_factor * init_latents
+
+ # Expand init_latents for batch_size and num_images_per_prompt
+ init_latents = torch.cat([init_latents] * num_images_per_prompt, dim=0)
+ init_latents_orig = init_latents
+
+ # add noise to latents using the timesteps
+ noise = randn_tensor(init_latents.shape, generator=generator, device=self.device, dtype=dtype)
+ init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
+ latents = init_latents
+ return latents, init_latents_orig, noise
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]],
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ image: Union[torch.Tensor, PIL.Image.Image] = None,
+ mask_image: Union[torch.Tensor, PIL.Image.Image] = None,
+ height: int = 512,
+ width: int = 512,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ strength: float = 0.8,
+ num_images_per_prompt: Optional[int] = 1,
+ add_predicted_noise: Optional[bool] = False,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.Tensor] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ max_embeddings_multiples: Optional[int] = 3,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.Tensor], None]] = None,
+ is_cancelled_callback: Optional[Callable[[], bool]] = None,
+ clip_skip: Optional[int] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ image (`torch.Tensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, that will be used as the starting point for the
+ process.
+ mask_image (`torch.Tensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
+ replaced by noise and therefore repainted, while black pixels will be preserved. If `mask_image` is a
+ PIL image, it will be converted to a single channel (luminance) before use. If it's a tensor, it should
+ contain one color channel (L) instead of 3, so the expected shape would be `(B, H, W, 1)`.
+ height (`int`, *optional*, defaults to 512):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to 512):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ strength (`float`, *optional*, defaults to 0.8):
+ Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1.
+ `image` will be used as a starting point, adding more noise to it the larger the `strength`. The
+ number of denoising steps depends on the amount of noise initially added. When `strength` is 1, added
+ noise will be maximum and the denoising process will run for the full number of iterations specified in
+ `num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ add_predicted_noise (`bool`, *optional*, defaults to True):
+ Use predicted noise instead of random noise when constructing noisy versions of the original image in
+ the reverse diffusion process
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.Tensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ max_embeddings_multiples (`int`, *optional*, defaults to `3`):
+ The max multiple length of prompt embeddings compared to the max output length of text encoder.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.Tensor)`.
+ is_cancelled_callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. If the function returns
+ `True`, the inference will be cancelled.
+ clip_skip (`int`, *optional*):
+ Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
+ the output of the pre-final layer will be used for computing the prompt embeddings.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+
+ Returns:
+ `None` if cancelled by `is_cancelled_callback`,
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt, height, width, strength, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+ lora_scale = cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ max_embeddings_multiples,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ clip_skip=clip_skip,
+ lora_scale=lora_scale,
+ )
+ dtype = prompt_embeds.dtype
+
+ # 4. Preprocess image and mask
+ if isinstance(image, PIL.Image.Image):
+ image = preprocess_image(image, batch_size)
+ if image is not None:
+ image = image.to(device=self.device, dtype=dtype)
+ if isinstance(mask_image, PIL.Image.Image):
+ mask_image = preprocess_mask(mask_image, batch_size, self.vae_scale_factor)
+ if mask_image is not None:
+ mask = mask_image.to(device=self.device, dtype=dtype)
+ mask = torch.cat([mask] * num_images_per_prompt)
+ else:
+ mask = None
+
+ # 5. set timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device, image is None)
+ latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
+
+ # 6. Prepare latent variables
+ latents, init_latents_orig, noise = self.prepare_latents(
+ image,
+ latent_timestep,
+ num_images_per_prompt,
+ batch_size,
+ self.unet.config.in_channels,
+ height,
+ width,
+ dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 8. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ if mask is not None:
+ # masking
+ if add_predicted_noise:
+ init_latents_proper = self.scheduler.add_noise(
+ init_latents_orig, noise_pred_uncond, torch.tensor([t])
+ )
+ else:
+ init_latents_proper = self.scheduler.add_noise(init_latents_orig, noise, torch.tensor([t]))
+ latents = (init_latents_proper * mask) + (latents * (1 - mask))
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if i % callback_steps == 0:
+ if callback is not None:
+ step_idx = i // getattr(self.scheduler, "order", 1)
+ callback(step_idx, t, latents)
+ if is_cancelled_callback is not None and is_cancelled_callback():
+ return None
+
+ if output_type == "latent":
+ image = latents
+ has_nsfw_concept = None
+ elif output_type == "pil":
+ # 9. Post-processing
+ image = self.decode_latents(latents)
+
+ # 10. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # 11. Convert to PIL
+ image = self.numpy_to_pil(image)
+ else:
+ # 9. Post-processing
+ image = self.decode_latents(latents)
+
+ # 10. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return image, has_nsfw_concept
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
+
+ def text2img(
+ self,
+ prompt: Union[str, List[str]],
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ height: int = 512,
+ width: int = 512,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.Tensor] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ max_embeddings_multiples: Optional[int] = 3,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.Tensor], None]] = None,
+ is_cancelled_callback: Optional[Callable[[], bool]] = None,
+ clip_skip=None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function for text-to-image generation.
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ height (`int`, *optional*, defaults to 512):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to 512):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.Tensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ max_embeddings_multiples (`int`, *optional*, defaults to `3`):
+ The max multiple length of prompt embeddings compared to the max output length of text encoder.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.Tensor)`.
+ is_cancelled_callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. If the function returns
+ `True`, the inference will be cancelled.
+ clip_skip (`int`, *optional*):
+ Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
+ the output of the pre-final layer will be used for computing the prompt embeddings.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+
+ Returns:
+ `None` if cancelled by `is_cancelled_callback`,
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ return self.__call__(
+ prompt=prompt,
+ negative_prompt=negative_prompt,
+ height=height,
+ width=width,
+ num_inference_steps=num_inference_steps,
+ guidance_scale=guidance_scale,
+ num_images_per_prompt=num_images_per_prompt,
+ eta=eta,
+ generator=generator,
+ latents=latents,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ max_embeddings_multiples=max_embeddings_multiples,
+ output_type=output_type,
+ return_dict=return_dict,
+ callback=callback,
+ is_cancelled_callback=is_cancelled_callback,
+ clip_skip=clip_skip,
+ callback_steps=callback_steps,
+ cross_attention_kwargs=cross_attention_kwargs,
+ )
+
+ def img2img(
+ self,
+ image: Union[torch.Tensor, PIL.Image.Image],
+ prompt: Union[str, List[str]],
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ strength: float = 0.8,
+ num_inference_steps: Optional[int] = 50,
+ guidance_scale: Optional[float] = 7.5,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: Optional[float] = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ max_embeddings_multiples: Optional[int] = 3,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.Tensor], None]] = None,
+ is_cancelled_callback: Optional[Callable[[], bool]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function for image-to-image generation.
+ Args:
+ image (`torch.Tensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, that will be used as the starting point for the
+ process.
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ strength (`float`, *optional*, defaults to 0.8):
+ Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1.
+ `image` will be used as a starting point, adding more noise to it the larger the `strength`. The
+ number of denoising steps depends on the amount of noise initially added. When `strength` is 1, added
+ noise will be maximum and the denoising process will run for the full number of iterations specified in
+ `num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference. This parameter will be modulated by `strength`.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ max_embeddings_multiples (`int`, *optional*, defaults to `3`):
+ The max multiple length of prompt embeddings compared to the max output length of text encoder.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.Tensor)`.
+ is_cancelled_callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. If the function returns
+ `True`, the inference will be cancelled.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+
+ Returns:
+ `None` if cancelled by `is_cancelled_callback`,
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ return self.__call__(
+ prompt=prompt,
+ negative_prompt=negative_prompt,
+ image=image,
+ num_inference_steps=num_inference_steps,
+ guidance_scale=guidance_scale,
+ strength=strength,
+ num_images_per_prompt=num_images_per_prompt,
+ eta=eta,
+ generator=generator,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ max_embeddings_multiples=max_embeddings_multiples,
+ output_type=output_type,
+ return_dict=return_dict,
+ callback=callback,
+ is_cancelled_callback=is_cancelled_callback,
+ callback_steps=callback_steps,
+ cross_attention_kwargs=cross_attention_kwargs,
+ )
+
+ def inpaint(
+ self,
+ image: Union[torch.Tensor, PIL.Image.Image],
+ mask_image: Union[torch.Tensor, PIL.Image.Image],
+ prompt: Union[str, List[str]],
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ strength: float = 0.8,
+ num_inference_steps: Optional[int] = 50,
+ guidance_scale: Optional[float] = 7.5,
+ num_images_per_prompt: Optional[int] = 1,
+ add_predicted_noise: Optional[bool] = False,
+ eta: Optional[float] = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ max_embeddings_multiples: Optional[int] = 3,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.Tensor], None]] = None,
+ is_cancelled_callback: Optional[Callable[[], bool]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function for inpaint.
+ Args:
+ image (`torch.Tensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, that will be used as the starting point for the
+ process. This is the image whose masked region will be inpainted.
+ mask_image (`torch.Tensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
+ replaced by noise and therefore repainted, while black pixels will be preserved. If `mask_image` is a
+ PIL image, it will be converted to a single channel (luminance) before use. If it's a tensor, it should
+ contain one color channel (L) instead of 3, so the expected shape would be `(B, H, W, 1)`.
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ strength (`float`, *optional*, defaults to 0.8):
+ Conceptually, indicates how much to inpaint the masked area. Must be between 0 and 1. When `strength`
+ is 1, the denoising process will be run on the masked area for the full number of iterations specified
+ in `num_inference_steps`. `image` will be used as a reference for the masked area, adding more
+ noise to that region the larger the `strength`. If `strength` is 0, no inpainting will occur.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The reference number of denoising steps. More denoising steps usually lead to a higher quality image at
+ the expense of slower inference. This parameter will be modulated by `strength`, as explained above.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ add_predicted_noise (`bool`, *optional*, defaults to True):
+ Use predicted noise instead of random noise when constructing noisy versions of the original image in
+ the reverse diffusion process
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ max_embeddings_multiples (`int`, *optional*, defaults to `3`):
+ The max multiple length of prompt embeddings compared to the max output length of text encoder.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.Tensor)`.
+ is_cancelled_callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. If the function returns
+ `True`, the inference will be cancelled.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+
+ Returns:
+ `None` if cancelled by `is_cancelled_callback`,
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ return self.__call__(
+ prompt=prompt,
+ negative_prompt=negative_prompt,
+ image=image,
+ mask_image=mask_image,
+ num_inference_steps=num_inference_steps,
+ guidance_scale=guidance_scale,
+ strength=strength,
+ num_images_per_prompt=num_images_per_prompt,
+ add_predicted_noise=add_predicted_noise,
+ eta=eta,
+ generator=generator,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ max_embeddings_multiples=max_embeddings_multiples,
+ output_type=output_type,
+ return_dict=return_dict,
+ callback=callback,
+ is_cancelled_callback=is_cancelled_callback,
+ callback_steps=callback_steps,
+ cross_attention_kwargs=cross_attention_kwargs,
+ )
\ No newline at end of file
diff --git a/animate/src/animatediff/utils/lpw_stable_diffusion_xl.py b/animate/src/animatediff/utils/lpw_stable_diffusion_xl.py
new file mode 100644
index 0000000000000000000000000000000000000000..ed071a6ec21ca2adb2907eee2e99b94880b1c0a2
--- /dev/null
+++ b/animate/src/animatediff/utils/lpw_stable_diffusion_xl.py
@@ -0,0 +1,2250 @@
+## ----------------------------------------------------------
+# A SDXL pipeline can take unlimited weighted prompt
+#
+# Author: Andrew Zhu
+# GitHub: https://github.com/xhinker
+# Medium: https://medium.com/@xhinker
+## -----------------------------------------------------------
+
+import inspect
+import os
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import torch
+from PIL import Image
+from transformers import (
+ CLIPImageProcessor,
+ CLIPTextModel,
+ CLIPTextModelWithProjection,
+ CLIPTokenizer,
+ CLIPVisionModelWithProjection,
+)
+
+from diffusers import DiffusionPipeline, StableDiffusionXLPipeline
+from diffusers.image_processor import PipelineImageInput, VaeImageProcessor
+from diffusers.loaders import (
+ FromSingleFileMixin,
+ IPAdapterMixin,
+ StableDiffusionXLLoraLoaderMixin,
+ TextualInversionLoaderMixin,
+)
+from diffusers.models import AutoencoderKL, ImageProjection, UNet2DConditionModel
+from diffusers.models.attention_processor import AttnProcessor2_0, XFormersAttnProcessor
+from diffusers.models.lora import adjust_lora_scale_text_encoder
+from diffusers.pipelines.pipeline_utils import StableDiffusionMixin
+from diffusers.pipelines.stable_diffusion_xl.pipeline_output import StableDiffusionXLPipelineOutput
+from diffusers.schedulers import KarrasDiffusionSchedulers
+from diffusers.utils import (
+ USE_PEFT_BACKEND,
+ deprecate,
+ is_accelerate_available,
+ is_accelerate_version,
+ is_invisible_watermark_available,
+ logging,
+ replace_example_docstring,
+ scale_lora_layers,
+ unscale_lora_layers,
+)
+from diffusers.utils.torch_utils import randn_tensor
+
+
+if is_invisible_watermark_available():
+ from diffusers.pipelines.stable_diffusion_xl.watermark import StableDiffusionXLWatermarker
+
+
+def parse_prompt_attention(text):
+ """
+ Parses a string with attention tokens and returns a list of pairs: text and its associated weight.
+ Accepted tokens are:
+ (abc) - increases attention to abc by a multiplier of 1.1
+ (abc:3.12) - increases attention to abc by a multiplier of 3.12
+ [abc] - decreases attention to abc by a multiplier of 1.1
+ \\( - literal character '('
+ \\[ - literal character '['
+ \\) - literal character ')'
+ \\] - literal character ']'
+ \\ - literal character '\'
+ anything else - just text
+
+ >>> parse_prompt_attention('normal text')
+ [['normal text', 1.0]]
+ >>> parse_prompt_attention('an (important) word')
+ [['an ', 1.0], ['important', 1.1], [' word', 1.0]]
+ >>> parse_prompt_attention('(unbalanced')
+ [['unbalanced', 1.1]]
+ >>> parse_prompt_attention('\\(literal\\]')
+ [['(literal]', 1.0]]
+ >>> parse_prompt_attention('(unnecessary)(parens)')
+ [['unnecessaryparens', 1.1]]
+ >>> parse_prompt_attention('a (((house:1.3)) [on] a (hill:0.5), sun, (((sky))).')
+ [['a ', 1.0],
+ ['house', 1.5730000000000004],
+ [' ', 1.1],
+ ['on', 1.0],
+ [' a ', 1.1],
+ ['hill', 0.55],
+ [', sun, ', 1.1],
+ ['sky', 1.4641000000000006],
+ ['.', 1.1]]
+ """
+ import re
+
+ re_attention = re.compile(
+ r"""
+ \\\(|\\\)|\\\[|\\]|\\\\|\\|\(|\[|:([+-]?[.\d]+)\)|
+ \)|]|[^\\()\[\]:]+|:
+ """,
+ re.X,
+ )
+
+ re_break = re.compile(r"\s*\bBREAK\b\s*", re.S)
+
+ res = []
+ round_brackets = []
+ square_brackets = []
+
+ round_bracket_multiplier = 1.1
+ square_bracket_multiplier = 1 / 1.1
+
+ def multiply_range(start_position, multiplier):
+ for p in range(start_position, len(res)):
+ res[p][1] *= multiplier
+
+ for m in re_attention.finditer(text):
+ text = m.group(0)
+ weight = m.group(1)
+
+ if text.startswith("\\"):
+ res.append([text[1:], 1.0])
+ elif text == "(":
+ round_brackets.append(len(res))
+ elif text == "[":
+ square_brackets.append(len(res))
+ elif weight is not None and len(round_brackets) > 0:
+ multiply_range(round_brackets.pop(), float(weight))
+ elif text == ")" and len(round_brackets) > 0:
+ multiply_range(round_brackets.pop(), round_bracket_multiplier)
+ elif text == "]" and len(square_brackets) > 0:
+ multiply_range(square_brackets.pop(), square_bracket_multiplier)
+ else:
+ parts = re.split(re_break, text)
+ for i, part in enumerate(parts):
+ if i > 0:
+ res.append(["BREAK", -1])
+ res.append([part, 1.0])
+
+ for pos in round_brackets:
+ multiply_range(pos, round_bracket_multiplier)
+
+ for pos in square_brackets:
+ multiply_range(pos, square_bracket_multiplier)
+
+ if len(res) == 0:
+ res = [["", 1.0]]
+
+ # merge runs of identical weights
+ i = 0
+ while i + 1 < len(res):
+ if res[i][1] == res[i + 1][1]:
+ res[i][0] += res[i + 1][0]
+ res.pop(i + 1)
+ else:
+ i += 1
+
+ return res
+
+
+def get_prompts_tokens_with_weights(clip_tokenizer: CLIPTokenizer, prompt: str):
+ """
+ Get prompt token ids and weights, this function works for both prompt and negative prompt
+
+ Args:
+ pipe (CLIPTokenizer)
+ A CLIPTokenizer
+ prompt (str)
+ A prompt string with weights
+
+ Returns:
+ text_tokens (list)
+ A list contains token ids
+ text_weight (list)
+ A list contains the correspondent weight of token ids
+
+ Example:
+ import torch
+ from transformers import CLIPTokenizer
+
+ clip_tokenizer = CLIPTokenizer.from_pretrained(
+ "stablediffusionapi/deliberate-v2"
+ , subfolder = "tokenizer"
+ , dtype = torch.float16
+ )
+
+ token_id_list, token_weight_list = get_prompts_tokens_with_weights(
+ clip_tokenizer = clip_tokenizer
+ ,prompt = "a (red:1.5) cat"*70
+ )
+ """
+ texts_and_weights = parse_prompt_attention(prompt)
+ text_tokens, text_weights = [], []
+ for word, weight in texts_and_weights:
+ # tokenize and discard the starting and the ending token
+ token = clip_tokenizer(word, truncation=False).input_ids[1:-1] # so that tokenize whatever length prompt
+ # the returned token is a 1d list: [320, 1125, 539, 320]
+
+ # merge the new tokens to the all tokens holder: text_tokens
+ text_tokens = [*text_tokens, *token]
+
+ # each token chunk will come with one weight, like ['red cat', 2.0]
+ # need to expand weight for each token.
+ chunk_weights = [weight] * len(token)
+
+ # append the weight back to the weight holder: text_weights
+ text_weights = [*text_weights, *chunk_weights]
+ return text_tokens, text_weights
+
+
+def group_tokens_and_weights(token_ids: list, weights: list, pad_last_block=False):
+ """
+ Produce tokens and weights in groups and pad the missing tokens
+
+ Args:
+ token_ids (list)
+ The token ids from tokenizer
+ weights (list)
+ The weights list from function get_prompts_tokens_with_weights
+ pad_last_block (bool)
+ Control if fill the last token list to 75 tokens with eos
+ Returns:
+ new_token_ids (2d list)
+ new_weights (2d list)
+
+ Example:
+ token_groups,weight_groups = group_tokens_and_weights(
+ token_ids = token_id_list
+ , weights = token_weight_list
+ )
+ """
+ bos, eos = 49406, 49407
+
+ # this will be a 2d list
+ new_token_ids = []
+ new_weights = []
+ while len(token_ids) >= 75:
+ # get the first 75 tokens
+ head_75_tokens = [token_ids.pop(0) for _ in range(75)]
+ head_75_weights = [weights.pop(0) for _ in range(75)]
+
+ # extract token ids and weights
+ temp_77_token_ids = [bos] + head_75_tokens + [eos]
+ temp_77_weights = [1.0] + head_75_weights + [1.0]
+
+ # add 77 token and weights chunk to the holder list
+ new_token_ids.append(temp_77_token_ids)
+ new_weights.append(temp_77_weights)
+
+ # padding the left
+ if len(token_ids) > 0:
+ padding_len = 75 - len(token_ids) if pad_last_block else 0
+
+ temp_77_token_ids = [bos] + token_ids + [eos] * padding_len + [eos]
+ new_token_ids.append(temp_77_token_ids)
+
+ temp_77_weights = [1.0] + weights + [1.0] * padding_len + [1.0]
+ new_weights.append(temp_77_weights)
+
+ return new_token_ids, new_weights
+
+
+def get_weighted_text_embeddings_sdxl(
+ pipe: StableDiffusionXLPipeline,
+ prompt: str = "",
+ prompt_2: str = None,
+ neg_prompt: str = "",
+ neg_prompt_2: str = None,
+ num_images_per_prompt: int = 1,
+ device: Optional[torch.device] = None,
+ clip_skip: Optional[int] = None,
+ lora_scale: Optional[int] = None,
+):
+ """
+ This function can process long prompt with weights, no length limitation
+ for Stable Diffusion XL
+
+ Args:
+ pipe (StableDiffusionPipeline)
+ prompt (str)
+ prompt_2 (str)
+ neg_prompt (str)
+ neg_prompt_2 (str)
+ num_images_per_prompt (int)
+ device (torch.device)
+ clip_skip (int)
+ Returns:
+ prompt_embeds (torch.Tensor)
+ neg_prompt_embeds (torch.Tensor)
+ """
+ device = device or pipe._execution_device
+
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(pipe, StableDiffusionXLLoraLoaderMixin):
+ pipe._lora_scale = lora_scale
+
+ # dynamically adjust the LoRA scale
+ if pipe.text_encoder is not None:
+ if not USE_PEFT_BACKEND:
+ adjust_lora_scale_text_encoder(pipe.text_encoder, lora_scale)
+ else:
+ scale_lora_layers(pipe.text_encoder, lora_scale)
+
+ if pipe.text_encoder_2 is not None:
+ if not USE_PEFT_BACKEND:
+ adjust_lora_scale_text_encoder(pipe.text_encoder_2, lora_scale)
+ else:
+ scale_lora_layers(pipe.text_encoder_2, lora_scale)
+
+ if prompt_2:
+ prompt = f"{prompt} {prompt_2}"
+
+ if neg_prompt_2:
+ neg_prompt = f"{neg_prompt} {neg_prompt_2}"
+
+ prompt_t1 = prompt_t2 = prompt
+ neg_prompt_t1 = neg_prompt_t2 = neg_prompt
+
+ if isinstance(pipe, TextualInversionLoaderMixin):
+ prompt_t1 = pipe.maybe_convert_prompt(prompt_t1, pipe.tokenizer)
+ neg_prompt_t1 = pipe.maybe_convert_prompt(neg_prompt_t1, pipe.tokenizer)
+ prompt_t2 = pipe.maybe_convert_prompt(prompt_t2, pipe.tokenizer_2)
+ neg_prompt_t2 = pipe.maybe_convert_prompt(neg_prompt_t2, pipe.tokenizer_2)
+
+ eos = pipe.tokenizer.eos_token_id
+
+ # tokenizer 1
+ prompt_tokens, prompt_weights = get_prompts_tokens_with_weights(pipe.tokenizer, prompt_t1)
+ neg_prompt_tokens, neg_prompt_weights = get_prompts_tokens_with_weights(pipe.tokenizer, neg_prompt_t1)
+
+ # tokenizer 2
+ prompt_tokens_2, prompt_weights_2 = get_prompts_tokens_with_weights(pipe.tokenizer_2, prompt_t2)
+ neg_prompt_tokens_2, neg_prompt_weights_2 = get_prompts_tokens_with_weights(pipe.tokenizer_2, neg_prompt_t2)
+
+ # padding the shorter one for prompt set 1
+ prompt_token_len = len(prompt_tokens)
+ neg_prompt_token_len = len(neg_prompt_tokens)
+
+ if prompt_token_len > neg_prompt_token_len:
+ # padding the neg_prompt with eos token
+ neg_prompt_tokens = neg_prompt_tokens + [eos] * abs(prompt_token_len - neg_prompt_token_len)
+ neg_prompt_weights = neg_prompt_weights + [1.0] * abs(prompt_token_len - neg_prompt_token_len)
+ else:
+ # padding the prompt
+ prompt_tokens = prompt_tokens + [eos] * abs(prompt_token_len - neg_prompt_token_len)
+ prompt_weights = prompt_weights + [1.0] * abs(prompt_token_len - neg_prompt_token_len)
+
+ # padding the shorter one for token set 2
+ prompt_token_len_2 = len(prompt_tokens_2)
+ neg_prompt_token_len_2 = len(neg_prompt_tokens_2)
+
+ if prompt_token_len_2 > neg_prompt_token_len_2:
+ # padding the neg_prompt with eos token
+ neg_prompt_tokens_2 = neg_prompt_tokens_2 + [eos] * abs(prompt_token_len_2 - neg_prompt_token_len_2)
+ neg_prompt_weights_2 = neg_prompt_weights_2 + [1.0] * abs(prompt_token_len_2 - neg_prompt_token_len_2)
+ else:
+ # padding the prompt
+ prompt_tokens_2 = prompt_tokens_2 + [eos] * abs(prompt_token_len_2 - neg_prompt_token_len_2)
+ prompt_weights_2 = prompt_weights + [1.0] * abs(prompt_token_len_2 - neg_prompt_token_len_2)
+
+ embeds = []
+ neg_embeds = []
+
+ prompt_token_groups, prompt_weight_groups = group_tokens_and_weights(prompt_tokens.copy(), prompt_weights.copy())
+
+ neg_prompt_token_groups, neg_prompt_weight_groups = group_tokens_and_weights(
+ neg_prompt_tokens.copy(), neg_prompt_weights.copy()
+ )
+
+ prompt_token_groups_2, prompt_weight_groups_2 = group_tokens_and_weights(
+ prompt_tokens_2.copy(), prompt_weights_2.copy()
+ )
+
+ neg_prompt_token_groups_2, neg_prompt_weight_groups_2 = group_tokens_and_weights(
+ neg_prompt_tokens_2.copy(), neg_prompt_weights_2.copy()
+ )
+
+ # get prompt embeddings one by one is not working.
+ for i in range(len(prompt_token_groups)):
+ # get positive prompt embeddings with weights
+ token_tensor = torch.tensor([prompt_token_groups[i]], dtype=torch.long, device=device)
+ weight_tensor = torch.tensor(prompt_weight_groups[i], dtype=torch.float16, device=device)
+
+ token_tensor_2 = torch.tensor([prompt_token_groups_2[i]], dtype=torch.long, device=device)
+
+ # use first text encoder
+ prompt_embeds_1 = pipe.text_encoder(token_tensor.to(device), output_hidden_states=True)
+
+ # use second text encoder
+ prompt_embeds_2 = pipe.text_encoder_2(token_tensor_2.to(device), output_hidden_states=True)
+ pooled_prompt_embeds = prompt_embeds_2[0]
+
+ if clip_skip is None:
+ prompt_embeds_1_hidden_states = prompt_embeds_1.hidden_states[-2]
+ prompt_embeds_2_hidden_states = prompt_embeds_2.hidden_states[-2]
+ else:
+ # "2" because SDXL always indexes from the penultimate layer.
+ prompt_embeds_1_hidden_states = prompt_embeds_1.hidden_states[-(clip_skip + 2)]
+ prompt_embeds_2_hidden_states = prompt_embeds_2.hidden_states[-(clip_skip + 2)]
+
+ prompt_embeds_list = [prompt_embeds_1_hidden_states, prompt_embeds_2_hidden_states]
+ token_embedding = torch.concat(prompt_embeds_list, dim=-1).squeeze(0)
+
+ for j in range(len(weight_tensor)):
+ if weight_tensor[j] != 1.0:
+ token_embedding[j] = (
+ token_embedding[-1] + (token_embedding[j] - token_embedding[-1]) * weight_tensor[j]
+ )
+
+ token_embedding = token_embedding.unsqueeze(0)
+ embeds.append(token_embedding)
+
+ # get negative prompt embeddings with weights
+ neg_token_tensor = torch.tensor([neg_prompt_token_groups[i]], dtype=torch.long, device=device)
+ neg_token_tensor_2 = torch.tensor([neg_prompt_token_groups_2[i]], dtype=torch.long, device=device)
+ neg_weight_tensor = torch.tensor(neg_prompt_weight_groups[i], dtype=torch.float16, device=device)
+
+ # use first text encoder
+ neg_prompt_embeds_1 = pipe.text_encoder(neg_token_tensor.to(device), output_hidden_states=True)
+ neg_prompt_embeds_1_hidden_states = neg_prompt_embeds_1.hidden_states[-2]
+
+ # use second text encoder
+ neg_prompt_embeds_2 = pipe.text_encoder_2(neg_token_tensor_2.to(device), output_hidden_states=True)
+ neg_prompt_embeds_2_hidden_states = neg_prompt_embeds_2.hidden_states[-2]
+ negative_pooled_prompt_embeds = neg_prompt_embeds_2[0]
+
+ neg_prompt_embeds_list = [neg_prompt_embeds_1_hidden_states, neg_prompt_embeds_2_hidden_states]
+ neg_token_embedding = torch.concat(neg_prompt_embeds_list, dim=-1).squeeze(0)
+
+ for z in range(len(neg_weight_tensor)):
+ if neg_weight_tensor[z] != 1.0:
+ neg_token_embedding[z] = (
+ neg_token_embedding[-1] + (neg_token_embedding[z] - neg_token_embedding[-1]) * neg_weight_tensor[z]
+ )
+
+ neg_token_embedding = neg_token_embedding.unsqueeze(0)
+ neg_embeds.append(neg_token_embedding)
+
+ prompt_embeds = torch.cat(embeds, dim=1)
+ negative_prompt_embeds = torch.cat(neg_embeds, dim=1)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt, 1).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+ negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt, 1).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+
+ if pipe.text_encoder is not None:
+ if isinstance(pipe, StableDiffusionXLLoraLoaderMixin) and USE_PEFT_BACKEND:
+ # Retrieve the original scale by scaling back the LoRA layers
+ unscale_lora_layers(pipe.text_encoder, lora_scale)
+
+ if pipe.text_encoder_2 is not None:
+ if isinstance(pipe, StableDiffusionXLLoraLoaderMixin) and USE_PEFT_BACKEND:
+ # Retrieve the original scale by scaling back the LoRA layers
+ unscale_lora_layers(pipe.text_encoder_2, lora_scale)
+
+ return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
+
+
+# -------------------------------------------------------------------------------------------------------------------------------
+# reuse the backbone code from StableDiffusionXLPipeline
+# -------------------------------------------------------------------------------------------------------------------------------
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ from diffusers import DiffusionPipeline
+ import torch
+
+ pipe = DiffusionPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-xl-base-1.0"
+ , torch_dtype = torch.float16
+ , use_safetensors = True
+ , variant = "fp16"
+ , custom_pipeline = "lpw_stable_diffusion_xl",
+ )
+
+ prompt = "a white cat running on the grass"*20
+ prompt2 = "play a football"*20
+ prompt = f"{prompt},{prompt2}"
+ neg_prompt = "blur, low quality"
+
+ pipe.to("cuda")
+ images = pipe(
+ prompt = prompt
+ , negative_prompt = neg_prompt
+ ).images[0]
+
+ pipe.to("cpu")
+ torch.cuda.empty_cache()
+ images
+ ```
+"""
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg
+def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
+ """
+ Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
+ Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ """
+ std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
+ std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
+ # rescale the results from guidance (fixes overexposure)
+ noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
+ # mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
+ noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
+ return noise_cfg
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.retrieve_latents
+def retrieve_latents(
+ encoder_output: torch.Tensor, generator: Optional[torch.Generator] = None, sample_mode: str = "sample"
+):
+ if hasattr(encoder_output, "latent_dist") and sample_mode == "sample":
+ return encoder_output.latent_dist.sample(generator)
+ elif hasattr(encoder_output, "latent_dist") and sample_mode == "argmax":
+ return encoder_output.latent_dist.mode()
+ elif hasattr(encoder_output, "latents"):
+ return encoder_output.latents
+ else:
+ raise AttributeError("Could not access latents of provided encoder_output")
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.retrieve_timesteps
+def retrieve_timesteps(
+ scheduler,
+ num_inference_steps: Optional[int] = None,
+ device: Optional[Union[str, torch.device]] = None,
+ timesteps: Optional[List[int]] = None,
+ **kwargs,
+):
+ """
+ Calls the scheduler's `set_timesteps` method and retrieves timesteps from the scheduler after the call. Handles
+ custom timesteps. Any kwargs will be supplied to `scheduler.set_timesteps`.
+
+ Args:
+ scheduler (`SchedulerMixin`):
+ The scheduler to get timesteps from.
+ num_inference_steps (`int`):
+ The number of diffusion steps used when generating samples with a pre-trained model. If used,
+ `timesteps` must be `None`.
+ device (`str` or `torch.device`, *optional*):
+ The device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
+ timesteps (`List[int]`, *optional*):
+ Custom timesteps used to support arbitrary spacing between timesteps. If `None`, then the default
+ timestep spacing strategy of the scheduler is used. If `timesteps` is passed, `num_inference_steps`
+ must be `None`.
+
+ Returns:
+ `Tuple[torch.Tensor, int]`: A tuple where the first element is the timestep schedule from the scheduler and the
+ second element is the number of inference steps.
+ """
+ if timesteps is not None:
+ accepts_timesteps = "timesteps" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())
+ if not accepts_timesteps:
+ raise ValueError(
+ f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"
+ f" timestep schedules. Please check whether you are using the correct scheduler."
+ )
+ scheduler.set_timesteps(timesteps=timesteps, device=device, **kwargs)
+ timesteps = scheduler.timesteps
+ num_inference_steps = len(timesteps)
+ else:
+ scheduler.set_timesteps(num_inference_steps, device=device, **kwargs)
+ timesteps = scheduler.timesteps
+ return timesteps, num_inference_steps
+
+
+class SDXLLongPromptWeightingPipeline(
+ DiffusionPipeline,
+ StableDiffusionMixin,
+ FromSingleFileMixin,
+ IPAdapterMixin,
+ StableDiffusionXLLoraLoaderMixin,
+ TextualInversionLoaderMixin,
+):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion XL.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
+ implemented for all pipelines (downloading, saving, running on a particular device, etc.).
+
+ The pipeline also inherits the following loading methods:
+ - [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
+ - [`~loaders.IPAdapterMixin.load_ip_adapter`] for loading IP Adapters
+ - [`~loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`] for loading LoRA weights
+ - [`~loaders.StableDiffusionXLLoraLoaderMixin.save_lora_weights`] for saving LoRA weights
+ - [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion XL uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ text_encoder_2 ([` CLIPTextModelWithProjection`]):
+ Second frozen text-encoder. Stable Diffusion XL uses the text and pool portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModelWithProjection),
+ specifically the
+ [laion/CLIP-ViT-bigG-14-laion2B-39B-b160k](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k)
+ variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ tokenizer_2 (`CLIPTokenizer`):
+ Second Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]):
+ Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ feature_extractor ([`~transformers.CLIPImageProcessor`]):
+ A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
+ """
+
+ model_cpu_offload_seq = "text_encoder->text_encoder_2->image_encoder->unet->vae"
+ _optional_components = [
+ "tokenizer",
+ "tokenizer_2",
+ "text_encoder",
+ "text_encoder_2",
+ "image_encoder",
+ "feature_extractor",
+ ]
+ _callback_tensor_inputs = [
+ "latents",
+ "prompt_embeds",
+ "negative_prompt_embeds",
+ "add_text_embeds",
+ "add_time_ids",
+ "negative_pooled_prompt_embeds",
+ "negative_add_time_ids",
+ ]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ text_encoder_2: CLIPTextModelWithProjection,
+ tokenizer: CLIPTokenizer,
+ tokenizer_2: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ feature_extractor: Optional[CLIPImageProcessor] = None,
+ image_encoder: Optional[CLIPVisionModelWithProjection] = None,
+ force_zeros_for_empty_prompt: bool = True,
+ add_watermarker: Optional[bool] = None,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ tokenizer=tokenizer,
+ tokenizer_2=tokenizer_2,
+ unet=unet,
+ scheduler=scheduler,
+ feature_extractor=feature_extractor,
+ image_encoder=image_encoder,
+ )
+ self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt)
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1) if getattr(self, "vae", None) else 8
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.mask_processor = VaeImageProcessor(
+ vae_scale_factor=self.vae_scale_factor, do_normalize=False, do_binarize=True, do_convert_grayscale=True
+ )
+ self.default_sample_size = (
+ self.unet.config.sample_size
+ if hasattr(self, "unet") and self.unet is not None and hasattr(self.unet.config, "sample_size")
+ else 128
+ )
+
+ add_watermarker = add_watermarker if add_watermarker is not None else is_invisible_watermark_available()
+
+ if add_watermarker:
+ self.watermark = StableDiffusionXLWatermarker()
+ else:
+ self.watermark = None
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ model_sequence = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+ model_sequence.extend([self.unet, self.vae])
+
+ hook = None
+ for cpu_offloaded_model in model_sequence:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.encode_prompt
+ def encode_prompt(
+ self,
+ prompt: str,
+ prompt_2: Optional[str] = None,
+ device: Optional[torch.device] = None,
+ num_images_per_prompt: int = 1,
+ do_classifier_free_guidance: bool = True,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ lora_scale: Optional[float] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
+ `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ pooled_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
+ input argument.
+ lora_scale (`float`, *optional*):
+ A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
+ """
+ device = device or self._execution_device
+
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(self, StableDiffusionXLLoraLoaderMixin):
+ self._lora_scale = lora_scale
+
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ # Define tokenizers and text encoders
+ tokenizers = [self.tokenizer, self.tokenizer_2] if self.tokenizer is not None else [self.tokenizer_2]
+ text_encoders = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+
+ if prompt_embeds is None:
+ prompt_2 = prompt_2 or prompt
+ # textual inversion: process multi-vector tokens if necessary
+ prompt_embeds_list = []
+ prompts = [prompt, prompt_2]
+ for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, tokenizer)
+
+ text_inputs = tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = text_encoder(
+ text_input_ids.to(device),
+ output_hidden_states=True,
+ )
+
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ if pooled_prompt_embeds is None and prompt_embeds[0].ndim == 2:
+ pooled_prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.hidden_states[-2]
+
+ prompt_embeds_list.append(prompt_embeds)
+
+ prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
+
+ # get unconditional embeddings for classifier free guidance
+ zero_out_negative_prompt = negative_prompt is None and self.config.force_zeros_for_empty_prompt
+ if do_classifier_free_guidance and negative_prompt_embeds is None and zero_out_negative_prompt:
+ negative_prompt_embeds = torch.zeros_like(prompt_embeds)
+ negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
+ elif do_classifier_free_guidance and negative_prompt_embeds is None:
+ negative_prompt = negative_prompt or ""
+ negative_prompt_2 = negative_prompt_2 or negative_prompt
+
+ uncond_tokens: List[str]
+ if prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+
+ negative_prompt_embeds_list = []
+ for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ negative_prompt = self.maybe_convert_prompt(negative_prompt, tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = tokenizer(
+ negative_prompt,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ negative_prompt_embeds = text_encoder(
+ uncond_input.input_ids.to(device),
+ output_hidden_states=True,
+ )
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ if negative_pooled_prompt_embeds is None and negative_prompt_embeds[0].ndim == 2:
+ negative_pooled_prompt_embeds = negative_prompt_embeds[0]
+ negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2]
+
+ negative_prompt_embeds_list.append(negative_prompt_embeds)
+
+ negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1)
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+ if do_classifier_free_guidance:
+ negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+
+ return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.encode_image
+ def encode_image(self, image, device, num_images_per_prompt, output_hidden_states=None):
+ dtype = next(self.image_encoder.parameters()).dtype
+
+ if not isinstance(image, torch.Tensor):
+ image = self.feature_extractor(image, return_tensors="pt").pixel_values
+
+ image = image.to(device=device, dtype=dtype)
+ if output_hidden_states:
+ image_enc_hidden_states = self.image_encoder(image, output_hidden_states=True).hidden_states[-2]
+ image_enc_hidden_states = image_enc_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
+ uncond_image_enc_hidden_states = self.image_encoder(
+ torch.zeros_like(image), output_hidden_states=True
+ ).hidden_states[-2]
+ uncond_image_enc_hidden_states = uncond_image_enc_hidden_states.repeat_interleave(
+ num_images_per_prompt, dim=0
+ )
+ return image_enc_hidden_states, uncond_image_enc_hidden_states
+ else:
+ image_embeds = self.image_encoder(image).image_embeds
+ image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
+ uncond_image_embeds = torch.zeros_like(image_embeds)
+
+ return image_embeds, uncond_image_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ prompt_2,
+ height,
+ width,
+ strength,
+ callback_steps,
+ negative_prompt=None,
+ negative_prompt_2=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ pooled_prompt_embeds=None,
+ negative_pooled_prompt_embeds=None,
+ callback_on_step_end_tensor_inputs=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if strength < 0 or strength > 1:
+ raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
+
+ if callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if callback_on_step_end_tensor_inputs is not None and not all(
+ k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
+ ):
+ raise ValueError(
+ f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt_2 is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+ elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)):
+ raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+ elif negative_prompt_2 is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt_2`: {negative_prompt_2} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ if prompt_embeds is not None and pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
+ )
+
+ if negative_prompt_embeds is not None and negative_pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `negative_prompt_embeds` are provided, `negative_pooled_prompt_embeds` also have to be passed. Make sure to generate `negative_pooled_prompt_embeds` from the same text encoder that was used to generate `negative_prompt_embeds`."
+ )
+
+ def get_timesteps(self, num_inference_steps, strength, device, denoising_start=None):
+ # get the original timestep using init_timestep
+ if denoising_start is None:
+ init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
+ t_start = max(num_inference_steps - init_timestep, 0)
+ else:
+ t_start = 0
+
+ timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
+
+ # Strength is irrelevant if we directly request a timestep to start at;
+ # that is, strength is determined by the denoising_start instead.
+ if denoising_start is not None:
+ discrete_timestep_cutoff = int(
+ round(
+ self.scheduler.config.num_train_timesteps
+ - (denoising_start * self.scheduler.config.num_train_timesteps)
+ )
+ )
+
+ num_inference_steps = (timesteps < discrete_timestep_cutoff).sum().item()
+ if self.scheduler.order == 2 and num_inference_steps % 2 == 0:
+ # if the scheduler is a 2nd order scheduler we might have to do +1
+ # because `num_inference_steps` might be even given that every timestep
+ # (except the highest one) is duplicated. If `num_inference_steps` is even it would
+ # mean that we cut the timesteps in the middle of the denoising step
+ # (between 1st and 2nd derivative) which leads to incorrect results. By adding 1
+ # we ensure that the denoising process always ends after the 2nd derivate step of the scheduler
+ num_inference_steps = num_inference_steps + 1
+
+ # because t_n+1 >= t_n, we slice the timesteps starting from the end
+ timesteps = timesteps[-num_inference_steps:]
+ return timesteps, num_inference_steps
+
+ return timesteps, num_inference_steps - t_start
+
+ def prepare_latents(
+ self,
+ image,
+ mask,
+ width,
+ height,
+ num_channels_latents,
+ timestep,
+ batch_size,
+ num_images_per_prompt,
+ dtype,
+ device,
+ generator=None,
+ add_noise=True,
+ latents=None,
+ is_strength_max=True,
+ return_noise=False,
+ return_image_latents=False,
+ ):
+ batch_size *= num_images_per_prompt
+
+ if image is None:
+ shape = (
+ batch_size,
+ num_channels_latents,
+ int(height) // self.vae_scale_factor,
+ int(width) // self.vae_scale_factor,
+ )
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ elif mask is None:
+ if not isinstance(image, (torch.Tensor, Image.Image, list)):
+ raise ValueError(
+ f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
+ )
+
+ # Offload text encoder if `enable_model_cpu_offload` was enabled
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.text_encoder_2.to("cpu")
+ torch.cuda.empty_cache()
+
+ image = image.to(device=device, dtype=dtype)
+
+ if image.shape[1] == 4:
+ init_latents = image
+
+ else:
+ # make sure the VAE is in float32 mode, as it overflows in float16
+ if self.vae.config.force_upcast:
+ image = image.float()
+ self.vae.to(dtype=torch.float32)
+
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ elif isinstance(generator, list):
+ init_latents = [
+ retrieve_latents(self.vae.encode(image[i : i + 1]), generator=generator[i])
+ for i in range(batch_size)
+ ]
+ init_latents = torch.cat(init_latents, dim=0)
+ else:
+ init_latents = retrieve_latents(self.vae.encode(image), generator=generator)
+
+ if self.vae.config.force_upcast:
+ self.vae.to(dtype)
+
+ init_latents = init_latents.to(dtype)
+ init_latents = self.vae.config.scaling_factor * init_latents
+
+ if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
+ # expand init_latents for batch_size
+ additional_image_per_prompt = batch_size // init_latents.shape[0]
+ init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0)
+ elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
+ raise ValueError(
+ f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
+ )
+ else:
+ init_latents = torch.cat([init_latents], dim=0)
+
+ if add_noise:
+ shape = init_latents.shape
+ noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ # get latents
+ init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
+
+ latents = init_latents
+ return latents
+
+ else:
+ shape = (
+ batch_size,
+ num_channels_latents,
+ int(height) // self.vae_scale_factor,
+ int(width) // self.vae_scale_factor,
+ )
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if (image is None or timestep is None) and not is_strength_max:
+ raise ValueError(
+ "Since strength < 1. initial latents are to be initialised as a combination of Image + Noise."
+ "However, either the image or the noise timestep has not been provided."
+ )
+
+ if image.shape[1] == 4:
+ image_latents = image.to(device=device, dtype=dtype)
+ image_latents = image_latents.repeat(batch_size // image_latents.shape[0], 1, 1, 1)
+ elif return_image_latents or (latents is None and not is_strength_max):
+ image = image.to(device=device, dtype=dtype)
+ image_latents = self._encode_vae_image(image=image, generator=generator)
+ image_latents = image_latents.repeat(batch_size // image_latents.shape[0], 1, 1, 1)
+
+ if latents is None and add_noise:
+ noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ # if strength is 1. then initialise the latents to noise, else initial to image + noise
+ latents = noise if is_strength_max else self.scheduler.add_noise(image_latents, noise, timestep)
+ # if pure noise then scale the initial latents by the Scheduler's init sigma
+ latents = latents * self.scheduler.init_noise_sigma if is_strength_max else latents
+ elif add_noise:
+ noise = latents.to(device)
+ latents = noise * self.scheduler.init_noise_sigma
+ else:
+ noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ latents = image_latents.to(device)
+
+ outputs = (latents,)
+
+ if return_noise:
+ outputs += (noise,)
+
+ if return_image_latents:
+ outputs += (image_latents,)
+
+ return outputs
+
+ def _encode_vae_image(self, image: torch.Tensor, generator: torch.Generator):
+ dtype = image.dtype
+ if self.vae.config.force_upcast:
+ image = image.float()
+ self.vae.to(dtype=torch.float32)
+
+ if isinstance(generator, list):
+ image_latents = [
+ retrieve_latents(self.vae.encode(image[i : i + 1]), generator=generator[i])
+ for i in range(image.shape[0])
+ ]
+ image_latents = torch.cat(image_latents, dim=0)
+ else:
+ image_latents = retrieve_latents(self.vae.encode(image), generator=generator)
+
+ if self.vae.config.force_upcast:
+ self.vae.to(dtype)
+
+ image_latents = image_latents.to(dtype)
+ image_latents = self.vae.config.scaling_factor * image_latents
+
+ return image_latents
+
+ def prepare_mask_latents(
+ self, mask, masked_image, batch_size, height, width, dtype, device, generator, do_classifier_free_guidance
+ ):
+ # resize the mask to latents shape as we concatenate the mask to the latents
+ # we do that before converting to dtype to avoid breaking in case we're using cpu_offload
+ # and half precision
+ mask = torch.nn.functional.interpolate(
+ mask, size=(height // self.vae_scale_factor, width // self.vae_scale_factor)
+ )
+ mask = mask.to(device=device, dtype=dtype)
+
+ # duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
+ if mask.shape[0] < batch_size:
+ if not batch_size % mask.shape[0] == 0:
+ raise ValueError(
+ "The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
+ f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
+ " of masks that you pass is divisible by the total requested batch size."
+ )
+ mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
+
+ mask = torch.cat([mask] * 2) if do_classifier_free_guidance else mask
+
+ if masked_image is not None and masked_image.shape[1] == 4:
+ masked_image_latents = masked_image
+ else:
+ masked_image_latents = None
+
+ if masked_image is not None:
+ if masked_image_latents is None:
+ masked_image = masked_image.to(device=device, dtype=dtype)
+ masked_image_latents = self._encode_vae_image(masked_image, generator=generator)
+
+ if masked_image_latents.shape[0] < batch_size:
+ if not batch_size % masked_image_latents.shape[0] == 0:
+ raise ValueError(
+ "The passed images and the required batch size don't match. Images are supposed to be duplicated"
+ f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
+ " Make sure the number of images that you pass is divisible by the total requested batch size."
+ )
+ masked_image_latents = masked_image_latents.repeat(
+ batch_size // masked_image_latents.shape[0], 1, 1, 1
+ )
+
+ masked_image_latents = (
+ torch.cat([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
+ )
+
+ # aligning device to prevent device errors when concating it with the latent model input
+ masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
+
+ return mask, masked_image_latents
+
+ def _get_add_time_ids(self, original_size, crops_coords_top_left, target_size, dtype):
+ add_time_ids = list(original_size + crops_coords_top_left + target_size)
+
+ passed_add_embed_dim = (
+ self.unet.config.addition_time_embed_dim * len(add_time_ids) + self.text_encoder_2.config.projection_dim
+ )
+ expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
+
+ if expected_add_embed_dim != passed_add_embed_dim:
+ raise ValueError(
+ f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
+ )
+
+ add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
+ return add_time_ids
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae
+ def upcast_vae(self):
+ dtype = self.vae.dtype
+ self.vae.to(dtype=torch.float32)
+ use_torch_2_0_or_xformers = isinstance(
+ self.vae.decoder.mid_block.attentions[0].processor,
+ (AttnProcessor2_0, XFormersAttnProcessor),
+ )
+ # if xformers or torch_2_0 is used attention block does not need
+ # to be in float32 which can save lots of memory
+ if use_torch_2_0_or_xformers:
+ self.vae.post_quant_conv.to(dtype)
+ self.vae.decoder.conv_in.to(dtype)
+ self.vae.decoder.mid_block.to(dtype)
+
+ # Copied from diffusers.pipelines.latent_consistency_models.pipeline_latent_consistency_text2img.LatentConsistencyModelPipeline.get_guidance_scale_embedding
+ def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
+ """
+ See https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
+
+ Args:
+ timesteps (`torch.Tensor`):
+ generate embedding vectors at these timesteps
+ embedding_dim (`int`, *optional*, defaults to 512):
+ dimension of the embeddings to generate
+ dtype:
+ data type of the generated embeddings
+
+ Returns:
+ `torch.Tensor`: Embedding vectors with shape `(len(timesteps), embedding_dim)`
+ """
+ assert len(w.shape) == 1
+ w = w * 1000.0
+
+ half_dim = embedding_dim // 2
+ emb = torch.log(torch.tensor(10000.0)) / (half_dim - 1)
+ emb = torch.exp(torch.arange(half_dim, dtype=dtype) * -emb)
+ emb = w.to(dtype)[:, None] * emb[None, :]
+ emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
+ if embedding_dim % 2 == 1: # zero pad
+ emb = torch.nn.functional.pad(emb, (0, 1))
+ assert emb.shape == (w.shape[0], embedding_dim)
+ return emb
+
+ @property
+ def guidance_scale(self):
+ return self._guidance_scale
+
+ @property
+ def guidance_rescale(self):
+ return self._guidance_rescale
+
+ @property
+ def clip_skip(self):
+ return self._clip_skip
+
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ @property
+ def do_classifier_free_guidance(self):
+ return self._guidance_scale > 1 and self.unet.config.time_cond_proj_dim is None
+
+ @property
+ def cross_attention_kwargs(self):
+ return self._cross_attention_kwargs
+
+ @property
+ def denoising_end(self):
+ return self._denoising_end
+
+ @property
+ def denoising_start(self):
+ return self._denoising_start
+
+ @property
+ def num_timesteps(self):
+ return self._num_timesteps
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: str = None,
+ prompt_2: Optional[str] = None,
+ image: Optional[PipelineImageInput] = None,
+ mask_image: Optional[PipelineImageInput] = None,
+ masked_image_latents: Optional[torch.Tensor] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ strength: float = 0.8,
+ num_inference_steps: int = 50,
+ timesteps: List[int] = None,
+ denoising_start: Optional[float] = None,
+ denoising_end: Optional[float] = None,
+ guidance_scale: float = 5.0,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.Tensor] = None,
+ ip_adapter_image: Optional[PipelineImageInput] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ original_size: Optional[Tuple[int, int]] = None,
+ crops_coords_top_left: Tuple[int, int] = (0, 0),
+ target_size: Optional[Tuple[int, int]] = None,
+ clip_skip: Optional[int] = None,
+ callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
+ callback_on_step_end_tensor_inputs: List[str] = ["latents"],
+ **kwargs,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str`):
+ The prompt to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ prompt_2 (`str`):
+ The prompt to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders
+ image (`PipelineImageInput`, *optional*):
+ `Image`, or tensor representing an image batch, that will be used as the starting point for the
+ process.
+ mask_image (`PipelineImageInput`, *optional*):
+ `Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
+ replaced by noise and therefore repainted, while black pixels will be preserved. If `mask_image` is a
+ PIL image, it will be converted to a single channel (luminance) before use. If it's a tensor, it should
+ contain one color channel (L) instead of 3, so the expected shape would be `(B, H, W, 1)`.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ strength (`float`, *optional*, defaults to 0.8):
+ Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1.
+ `image` will be used as a starting point, adding more noise to it the larger the `strength`. The
+ number of denoising steps depends on the amount of noise initially added. When `strength` is 1, added
+ noise will be maximum and the denoising process will run for the full number of iterations specified in
+ `num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ timesteps (`List[int]`, *optional*):
+ Custom timesteps to use for the denoising process with schedulers which support a `timesteps` argument
+ in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
+ passed will be used. Must be in descending order.
+ denoising_start (`float`, *optional*):
+ When specified, indicates the fraction (between 0.0 and 1.0) of the total denoising process to be
+ bypassed before it is initiated. Consequently, the initial part of the denoising process is skipped and
+ it is assumed that the passed `image` is a partly denoised image. Note that when this is specified,
+ strength will be ignored. The `denoising_start` parameter is particularly beneficial when this pipeline
+ is integrated into a "Mixture of Denoisers" multi-pipeline setup, as detailed in [**Refine Image
+ Quality**](https://huggingface.co/docs/diffusers/using-diffusers/sdxl#refine-image-quality).
+ denoising_end (`float`, *optional*):
+ When specified, determines the fraction (between 0.0 and 1.0) of the total denoising process to be
+ completed before it is intentionally prematurely terminated. As a result, the returned sample will
+ still retain a substantial amount of noise (ca. final 20% of timesteps still needed) and should be
+ denoised by a successor pipeline that has `denoising_start` set to 0.8 so that it only denoises the
+ final 20% of the scheduler. The denoising_end parameter should ideally be utilized when this pipeline
+ forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refine Image
+ Quality**](https://huggingface.co/docs/diffusers/using-diffusers/sdxl#refine-image-quality).
+ guidance_scale (`float`, *optional*, defaults to 5.0):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str`):
+ The prompt not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ negative_prompt_2 (`str`):
+ The prompt not to guide the image generation to be sent to `tokenizer_2` and
+ `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.Tensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ ip_adapter_image: (`PipelineImageInput`, *optional*):
+ Optional image input to work with IP Adapters.
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ pooled_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
+ input argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] instead
+ of a plain tuple.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+ guidance_rescale (`float`, *optional*, defaults to 0.0):
+ Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Guidance rescale factor should fix overexposure when using zero terminal SNR.
+ original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
+ `original_size` defaults to `(height, width)` if not specified. Part of SDXL's micro-conditioning as
+ explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
+ `crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
+ `crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
+ `crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ For most cases, `target_size` should be set to the desired height and width of the generated image. If
+ not specified it will default to `(height, width)`. Part of SDXL's micro-conditioning as explained in
+ section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ clip_skip (`int`, *optional*):
+ Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
+ the output of the pre-final layer will be used for computing the prompt embeddings.
+ callback_on_step_end (`Callable`, *optional*):
+ A function that calls at the end of each denoising steps during the inference. The function is called
+ with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
+ callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
+ `callback_on_step_end_tensor_inputs`.
+ callback_on_step_end_tensor_inputs (`List`, *optional*):
+ The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
+ will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
+ `._callback_tensor_inputs` attribute of your pipeline class.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] if `return_dict` is True, otherwise a
+ `tuple`. When returning a tuple, the first element is a list with the generated images.
+ """
+
+ callback = kwargs.pop("callback", None)
+ callback_steps = kwargs.pop("callback_steps", None)
+
+ if callback is not None:
+ deprecate(
+ "callback",
+ "1.0.0",
+ "Passing `callback` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
+ )
+ if callback_steps is not None:
+ deprecate(
+ "callback_steps",
+ "1.0.0",
+ "Passing `callback_steps` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
+ )
+
+ # 0. Default height and width to unet
+ height = height or self.default_sample_size * self.vae_scale_factor
+ width = width or self.default_sample_size * self.vae_scale_factor
+
+ original_size = original_size or (height, width)
+ target_size = target_size or (height, width)
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ prompt_2,
+ height,
+ width,
+ strength,
+ callback_steps,
+ negative_prompt,
+ negative_prompt_2,
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ callback_on_step_end_tensor_inputs,
+ )
+
+ self._guidance_scale = guidance_scale
+ self._guidance_rescale = guidance_rescale
+ self._clip_skip = clip_skip
+ self._cross_attention_kwargs = cross_attention_kwargs
+ self._denoising_end = denoising_end
+ self._denoising_start = denoising_start
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+
+ if ip_adapter_image is not None:
+ output_hidden_state = False if isinstance(self.unet.encoder_hid_proj, ImageProjection) else True
+ image_embeds, negative_image_embeds = self.encode_image(
+ ip_adapter_image, device, num_images_per_prompt, output_hidden_state
+ )
+ if self.do_classifier_free_guidance:
+ image_embeds = torch.cat([negative_image_embeds, image_embeds])
+
+ # 3. Encode input prompt
+ lora_scale = (
+ self._cross_attention_kwargs.get("scale", None) if self._cross_attention_kwargs is not None else None
+ )
+
+ negative_prompt = negative_prompt if negative_prompt is not None else ""
+
+ (
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ ) = get_weighted_text_embeddings_sdxl(
+ pipe=self,
+ prompt=prompt,
+ neg_prompt=negative_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ clip_skip=clip_skip,
+ lora_scale=lora_scale,
+ )
+ dtype = prompt_embeds.dtype
+
+ if isinstance(image, Image.Image):
+ image = self.image_processor.preprocess(image, height=height, width=width)
+ if image is not None:
+ image = image.to(device=self.device, dtype=dtype)
+
+ if isinstance(mask_image, Image.Image):
+ mask = self.mask_processor.preprocess(mask_image, height=height, width=width)
+ else:
+ mask = mask_image
+ if mask_image is not None:
+ mask = mask.to(device=self.device, dtype=dtype)
+
+ if masked_image_latents is not None:
+ masked_image = masked_image_latents
+ elif image.shape[1] == 4:
+ # if image is in latent space, we can't mask it
+ masked_image = None
+ else:
+ masked_image = image * (mask < 0.5)
+ else:
+ mask = None
+
+ # 4. Prepare timesteps
+ def denoising_value_valid(dnv):
+ return isinstance(dnv, float) and 0 < dnv < 1
+
+ timesteps, num_inference_steps = retrieve_timesteps(self.scheduler, num_inference_steps, device, timesteps)
+ if image is not None:
+ timesteps, num_inference_steps = self.get_timesteps(
+ num_inference_steps,
+ strength,
+ device,
+ denoising_start=self.denoising_start if denoising_value_valid(self.denoising_start) else None,
+ )
+
+ # check that number of inference steps is not < 1 - as this doesn't make sense
+ if num_inference_steps < 1:
+ raise ValueError(
+ f"After adjusting the num_inference_steps by strength parameter: {strength}, the number of pipeline"
+ f"steps is {num_inference_steps} which is < 1 and not appropriate for this pipeline."
+ )
+
+ latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
+ is_strength_max = strength == 1.0
+ add_noise = True if self.denoising_start is None else False
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.vae.config.latent_channels
+ num_channels_unet = self.unet.config.in_channels
+ return_image_latents = num_channels_unet == 4
+
+ latents = self.prepare_latents(
+ image=image,
+ mask=mask,
+ width=width,
+ height=height,
+ num_channels_latents=num_channels_unet,
+ timestep=latent_timestep,
+ batch_size=batch_size,
+ num_images_per_prompt=num_images_per_prompt,
+ dtype=prompt_embeds.dtype,
+ device=device,
+ generator=generator,
+ add_noise=add_noise,
+ latents=latents,
+ is_strength_max=is_strength_max,
+ return_noise=True,
+ return_image_latents=return_image_latents,
+ )
+
+ if mask is not None:
+ if return_image_latents:
+ latents, noise, image_latents = latents
+ else:
+ latents, noise = latents
+
+ # 5.1 Prepare mask latent variables
+ if mask is not None:
+ mask, masked_image_latents = self.prepare_mask_latents(
+ mask=mask,
+ masked_image=masked_image,
+ batch_size=batch_size * num_images_per_prompt,
+ height=height,
+ width=width,
+ dtype=prompt_embeds.dtype,
+ device=device,
+ generator=generator,
+ do_classifier_free_guidance=self.do_classifier_free_guidance,
+ )
+
+ # Check that sizes of mask, masked image and latents match
+ if num_channels_unet == 9:
+ # default case for runwayml/stable-diffusion-inpainting
+ num_channels_mask = mask.shape[1]
+ num_channels_masked_image = masked_image_latents.shape[1]
+ if num_channels_latents + num_channels_mask + num_channels_masked_image != num_channels_unet:
+ raise ValueError(
+ f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
+ f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
+ f" `num_channels_mask`: {num_channels_mask} + `num_channels_masked_image`: {num_channels_masked_image}"
+ f" = {num_channels_latents+num_channels_masked_image+num_channels_mask}. Please verify the config of"
+ " `pipeline.unet` or your `mask_image` or `image` input."
+ )
+ elif num_channels_unet != 4:
+ raise ValueError(
+ f"The unet {self.unet.__class__} should have either 4 or 9 input channels, not {self.unet.config.in_channels}."
+ )
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 6.1 Add image embeds for IP-Adapter
+ added_cond_kwargs = {"image_embeds": image_embeds} if ip_adapter_image is not None else {}
+
+ height, width = latents.shape[-2:]
+ height = height * self.vae_scale_factor
+ width = width * self.vae_scale_factor
+
+ original_size = original_size or (height, width)
+ target_size = target_size or (height, width)
+
+ # 7. Prepare added time ids & embeddings
+ add_text_embeds = pooled_prompt_embeds
+ add_time_ids = self._get_add_time_ids(
+ original_size, crops_coords_top_left, target_size, dtype=prompt_embeds.dtype
+ )
+
+ if self.do_classifier_free_guidance:
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
+ add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
+ add_time_ids = torch.cat([add_time_ids, add_time_ids], dim=0)
+
+ prompt_embeds = prompt_embeds.to(device)
+ add_text_embeds = add_text_embeds.to(device)
+ add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
+
+ num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
+
+ # 7.1 Apply denoising_end
+ if (
+ self.denoising_end is not None
+ and self.denoising_start is not None
+ and denoising_value_valid(self.denoising_end)
+ and denoising_value_valid(self.denoising_start)
+ and self.denoising_start >= self.denoising_end
+ ):
+ raise ValueError(
+ f"`denoising_start`: {self.denoising_start} cannot be larger than or equal to `denoising_end`: "
+ + f" {self.denoising_end} when using type float."
+ )
+ elif self.denoising_end is not None and denoising_value_valid(self.denoising_end):
+ discrete_timestep_cutoff = int(
+ round(
+ self.scheduler.config.num_train_timesteps
+ - (self.denoising_end * self.scheduler.config.num_train_timesteps)
+ )
+ )
+ num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps)))
+ timesteps = timesteps[:num_inference_steps]
+
+ # 8. Optionally get Guidance Scale Embedding
+ timestep_cond = None
+ if self.unet.config.time_cond_proj_dim is not None:
+ guidance_scale_tensor = torch.tensor(self.guidance_scale - 1).repeat(batch_size * num_images_per_prompt)
+ timestep_cond = self.get_guidance_scale_embedding(
+ guidance_scale_tensor, embedding_dim=self.unet.config.time_cond_proj_dim
+ ).to(device=device, dtype=latents.dtype)
+
+ self._num_timesteps = len(timesteps)
+
+ # 9. Denoising loop
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
+
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ if mask is not None and num_channels_unet == 9:
+ latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
+
+ # predict the noise residual
+ added_cond_kwargs.update({"text_embeds": add_text_embeds, "time_ids": add_time_ids})
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ timestep_cond=timestep_cond,
+ cross_attention_kwargs=self.cross_attention_kwargs,
+ added_cond_kwargs=added_cond_kwargs,
+ return_dict=False,
+ )[0]
+
+ # perform guidance
+ if self.do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ if self.do_classifier_free_guidance and guidance_rescale > 0.0:
+ # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ if mask is not None and num_channels_unet == 4:
+ init_latents_proper = image_latents
+
+ if self.do_classifier_free_guidance:
+ init_mask, _ = mask.chunk(2)
+ else:
+ init_mask = mask
+
+ if i < len(timesteps) - 1:
+ noise_timestep = timesteps[i + 1]
+ init_latents_proper = self.scheduler.add_noise(
+ init_latents_proper, noise, torch.tensor([noise_timestep])
+ )
+
+ latents = (1 - init_mask) * init_latents_proper + init_mask * latents
+
+ if callback_on_step_end is not None:
+ callback_kwargs = {}
+ for k in callback_on_step_end_tensor_inputs:
+ callback_kwargs[k] = locals()[k]
+ callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
+
+ latents = callback_outputs.pop("latents", latents)
+ prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
+ negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)
+ add_text_embeds = callback_outputs.pop("add_text_embeds", add_text_embeds)
+ negative_pooled_prompt_embeds = callback_outputs.pop(
+ "negative_pooled_prompt_embeds", negative_pooled_prompt_embeds
+ )
+ add_time_ids = callback_outputs.pop("add_time_ids", add_time_ids)
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ step_idx = i // getattr(self.scheduler, "order", 1)
+ callback(step_idx, t, latents)
+
+ if not output_type == "latent":
+ # make sure the VAE is in float32 mode, as it overflows in float16
+ needs_upcasting = self.vae.dtype == torch.float16 and self.vae.config.force_upcast
+
+ if needs_upcasting:
+ self.upcast_vae()
+ latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
+
+ image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
+
+ # cast back to fp16 if needed
+ if needs_upcasting:
+ self.vae.to(dtype=torch.float16)
+ else:
+ image = latents
+ return StableDiffusionXLPipelineOutput(images=image)
+
+ # apply watermark if available
+ if self.watermark is not None:
+ image = self.watermark.apply_watermark(image)
+
+ image = self.image_processor.postprocess(image, output_type=output_type)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image,)
+
+ return StableDiffusionXLPipelineOutput(images=image)
+
+ def text2img(
+ self,
+ prompt: str = None,
+ prompt_2: Optional[str] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ timesteps: List[int] = None,
+ denoising_start: Optional[float] = None,
+ denoising_end: Optional[float] = None,
+ guidance_scale: float = 5.0,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.Tensor] = None,
+ ip_adapter_image: Optional[PipelineImageInput] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ original_size: Optional[Tuple[int, int]] = None,
+ crops_coords_top_left: Tuple[int, int] = (0, 0),
+ target_size: Optional[Tuple[int, int]] = None,
+ clip_skip: Optional[int] = None,
+ callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
+ callback_on_step_end_tensor_inputs: List[str] = ["latents"],
+ **kwargs,
+ ):
+ r"""
+ Function invoked when calling pipeline for text-to-image.
+
+ Refer to the documentation of the `__call__` method for parameter descriptions.
+ """
+ return self.__call__(
+ prompt=prompt,
+ prompt_2=prompt_2,
+ height=height,
+ width=width,
+ num_inference_steps=num_inference_steps,
+ timesteps=timesteps,
+ denoising_start=denoising_start,
+ denoising_end=denoising_end,
+ guidance_scale=guidance_scale,
+ negative_prompt=negative_prompt,
+ negative_prompt_2=negative_prompt_2,
+ num_images_per_prompt=num_images_per_prompt,
+ eta=eta,
+ generator=generator,
+ latents=latents,
+ ip_adapter_image=ip_adapter_image,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
+ output_type=output_type,
+ return_dict=return_dict,
+ cross_attention_kwargs=cross_attention_kwargs,
+ guidance_rescale=guidance_rescale,
+ original_size=original_size,
+ crops_coords_top_left=crops_coords_top_left,
+ target_size=target_size,
+ clip_skip=clip_skip,
+ callback_on_step_end=callback_on_step_end,
+ callback_on_step_end_tensor_inputs=callback_on_step_end_tensor_inputs,
+ **kwargs,
+ )
+
+ def img2img(
+ self,
+ prompt: str = None,
+ prompt_2: Optional[str] = None,
+ image: Optional[PipelineImageInput] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ strength: float = 0.8,
+ num_inference_steps: int = 50,
+ timesteps: List[int] = None,
+ denoising_start: Optional[float] = None,
+ denoising_end: Optional[float] = None,
+ guidance_scale: float = 5.0,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.Tensor] = None,
+ ip_adapter_image: Optional[PipelineImageInput] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ original_size: Optional[Tuple[int, int]] = None,
+ crops_coords_top_left: Tuple[int, int] = (0, 0),
+ target_size: Optional[Tuple[int, int]] = None,
+ clip_skip: Optional[int] = None,
+ callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
+ callback_on_step_end_tensor_inputs: List[str] = ["latents"],
+ **kwargs,
+ ):
+ r"""
+ Function invoked when calling pipeline for image-to-image.
+
+ Refer to the documentation of the `__call__` method for parameter descriptions.
+ """
+ return self.__call__(
+ prompt=prompt,
+ prompt_2=prompt_2,
+ image=image,
+ height=height,
+ width=width,
+ strength=strength,
+ num_inference_steps=num_inference_steps,
+ timesteps=timesteps,
+ denoising_start=denoising_start,
+ denoising_end=denoising_end,
+ guidance_scale=guidance_scale,
+ negative_prompt=negative_prompt,
+ negative_prompt_2=negative_prompt_2,
+ num_images_per_prompt=num_images_per_prompt,
+ eta=eta,
+ generator=generator,
+ latents=latents,
+ ip_adapter_image=ip_adapter_image,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
+ output_type=output_type,
+ return_dict=return_dict,
+ cross_attention_kwargs=cross_attention_kwargs,
+ guidance_rescale=guidance_rescale,
+ original_size=original_size,
+ crops_coords_top_left=crops_coords_top_left,
+ target_size=target_size,
+ clip_skip=clip_skip,
+ callback_on_step_end=callback_on_step_end,
+ callback_on_step_end_tensor_inputs=callback_on_step_end_tensor_inputs,
+ **kwargs,
+ )
+
+ def inpaint(
+ self,
+ prompt: str = None,
+ prompt_2: Optional[str] = None,
+ image: Optional[PipelineImageInput] = None,
+ mask_image: Optional[PipelineImageInput] = None,
+ masked_image_latents: Optional[torch.Tensor] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ strength: float = 0.8,
+ num_inference_steps: int = 50,
+ timesteps: List[int] = None,
+ denoising_start: Optional[float] = None,
+ denoising_end: Optional[float] = None,
+ guidance_scale: float = 5.0,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.Tensor] = None,
+ ip_adapter_image: Optional[PipelineImageInput] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ original_size: Optional[Tuple[int, int]] = None,
+ crops_coords_top_left: Tuple[int, int] = (0, 0),
+ target_size: Optional[Tuple[int, int]] = None,
+ clip_skip: Optional[int] = None,
+ callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
+ callback_on_step_end_tensor_inputs: List[str] = ["latents"],
+ **kwargs,
+ ):
+ r"""
+ Function invoked when calling pipeline for inpainting.
+
+ Refer to the documentation of the `__call__` method for parameter descriptions.
+ """
+ return self.__call__(
+ prompt=prompt,
+ prompt_2=prompt_2,
+ image=image,
+ mask_image=mask_image,
+ masked_image_latents=masked_image_latents,
+ height=height,
+ width=width,
+ strength=strength,
+ num_inference_steps=num_inference_steps,
+ timesteps=timesteps,
+ denoising_start=denoising_start,
+ denoising_end=denoising_end,
+ guidance_scale=guidance_scale,
+ negative_prompt=negative_prompt,
+ negative_prompt_2=negative_prompt_2,
+ num_images_per_prompt=num_images_per_prompt,
+ eta=eta,
+ generator=generator,
+ latents=latents,
+ ip_adapter_image=ip_adapter_image,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
+ output_type=output_type,
+ return_dict=return_dict,
+ cross_attention_kwargs=cross_attention_kwargs,
+ guidance_rescale=guidance_rescale,
+ original_size=original_size,
+ crops_coords_top_left=crops_coords_top_left,
+ target_size=target_size,
+ clip_skip=clip_skip,
+ callback_on_step_end=callback_on_step_end,
+ callback_on_step_end_tensor_inputs=callback_on_step_end_tensor_inputs,
+ **kwargs,
+ )
+
+ # Override to properly handle the loading and unloading of the additional text encoder.
+ def load_lora_weights(self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], **kwargs):
+ # We could have accessed the unet config from `lora_state_dict()` too. We pass
+ # it here explicitly to be able to tell that it's coming from an SDXL
+ # pipeline.
+ state_dict, network_alphas = self.lora_state_dict(
+ pretrained_model_name_or_path_or_dict,
+ unet_config=self.unet.config,
+ **kwargs,
+ )
+ self.load_lora_into_unet(state_dict, network_alphas=network_alphas, unet=self.unet)
+
+ text_encoder_state_dict = {k: v for k, v in state_dict.items() if "text_encoder." in k}
+ if len(text_encoder_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder,
+ prefix="text_encoder",
+ lora_scale=self.lora_scale,
+ )
+
+ text_encoder_2_state_dict = {k: v for k, v in state_dict.items() if "text_encoder_2." in k}
+ if len(text_encoder_2_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_2_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder_2,
+ prefix="text_encoder_2",
+ lora_scale=self.lora_scale,
+ )
+
+ @classmethod
+ def save_lora_weights(
+ cls,
+ save_directory: Union[str, os.PathLike],
+ unet_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_2_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ is_main_process: bool = True,
+ weight_name: str = None,
+ save_function: Callable = None,
+ safe_serialization: bool = False,
+ ):
+ state_dict = {}
+
+ def pack_weights(layers, prefix):
+ layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers
+ layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()}
+ return layers_state_dict
+
+ state_dict.update(pack_weights(unet_lora_layers, "unet"))
+
+ if text_encoder_lora_layers and text_encoder_2_lora_layers:
+ state_dict.update(pack_weights(text_encoder_lora_layers, "text_encoder"))
+ state_dict.update(pack_weights(text_encoder_2_lora_layers, "text_encoder_2"))
+
+ cls.write_lora_layers(
+ state_dict=state_dict,
+ save_directory=save_directory,
+ is_main_process=is_main_process,
+ weight_name=weight_name,
+ save_function=save_function,
+ safe_serialization=safe_serialization,
+ )
+
+ def _remove_text_encoder_monkey_patch(self):
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder)
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder_2)
\ No newline at end of file
diff --git a/animate/src/animatediff/utils/mask.py b/animate/src/animatediff/utils/mask.py
new file mode 100644
index 0000000000000000000000000000000000000000..4f4359ac1063187a60cb651159b7359a06045a91
--- /dev/null
+++ b/animate/src/animatediff/utils/mask.py
@@ -0,0 +1,721 @@
+import glob
+import logging
+import os
+from pathlib import Path
+
+import cv2
+import numpy as np
+import torch
+from groundingdino.models import build_model
+from groundingdino.util.slconfig import SLConfig
+from groundingdino.util.utils import clean_state_dict, get_phrases_from_posmap
+from PIL import Image
+from segment_anything_hq import (SamPredictor, build_sam_vit_b,
+ build_sam_vit_h, build_sam_vit_l)
+from segment_anything_hq.build_sam import build_sam_vit_t
+from tqdm.rich import tqdm
+
+logger = logging.getLogger(__name__)
+
+build_sam_table={
+ "sam_hq_vit_l":build_sam_vit_l,
+ "sam_hq_vit_h":build_sam_vit_h,
+ "sam_hq_vit_b":build_sam_vit_b,
+ "sam_hq_vit_tiny":build_sam_vit_t,
+}
+
+# adapted from https://github.com/IDEA-Research/Grounded-Segment-Anything/blob/main/grounded_sam_demo.py
+class MaskPredictor:
+ def __init__(self,model_config_path, model_checkpoint_path,device, sam_checkpoint, box_threshold=0.3, text_threshold=0.25 ):
+ self.groundingdino_model = None
+ self.sam_predictor = None
+
+ self.model_config_path = model_config_path
+ self.model_checkpoint_path = model_checkpoint_path
+ self.device = device
+ self.sam_checkpoint = sam_checkpoint
+
+ self.box_threshold = box_threshold
+ self.text_threshold = text_threshold
+
+ def load_groundingdino_model(self):
+ args = SLConfig.fromfile(self.model_config_path)
+ args.device = self.device
+ model = build_model(args)
+ checkpoint = torch.load(self.model_checkpoint_path, map_location="cpu")
+ load_res = model.load_state_dict(clean_state_dict(checkpoint["model"]), strict=False)
+ #print(load_res)
+ _ = model.eval()
+ self.groundingdino_model = model
+
+ def load_sam_predictor(self):
+ s = Path(self.sam_checkpoint)
+ self.sam_predictor = SamPredictor(build_sam_table[ s.stem ](checkpoint=self.sam_checkpoint).to(self.device))
+
+ def transform_image(self,image_pil):
+ import groundingdino.datasets.transforms as T
+ transform = T.Compose(
+ [
+ T.RandomResize([800], max_size=1333),
+ T.ToTensor(),
+ T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
+ ]
+ )
+ image, _ = transform(image_pil, None) # 3, h, w
+ return image
+
+ def get_grounding_output(self, image, caption, with_logits=True):
+ model = self.groundingdino_model
+ device = self.device
+
+ caption = caption.lower()
+ caption = caption.strip()
+ if not caption.endswith("."):
+ caption = caption + "."
+ model = model.to(device)
+ image = image.to(device)
+ with torch.no_grad():
+ outputs = model(image[None], captions=[caption])
+ logits = outputs["pred_logits"].cpu().sigmoid()[0] # (nq, 256)
+ boxes = outputs["pred_boxes"].cpu()[0] # (nq, 4)
+ logits.shape[0]
+
+ # filter output
+ logits_filt = logits.clone()
+ boxes_filt = boxes.clone()
+ filt_mask = logits_filt.max(dim=1)[0] > self.box_threshold
+ logits_filt = logits_filt[filt_mask] # num_filt, 256
+ boxes_filt = boxes_filt[filt_mask] # num_filt, 4
+ logits_filt.shape[0]
+
+ # get phrase
+ tokenlizer = model.tokenizer
+ tokenized = tokenlizer(caption)
+ # build pred
+ pred_phrases = []
+ for logit, box in zip(logits_filt, boxes_filt):
+ pred_phrase = get_phrases_from_posmap(logit > self.text_threshold, tokenized, tokenlizer)
+ if with_logits:
+ pred_phrases.append(pred_phrase + f"({str(logit.max().item())[:4]})")
+ else:
+ pred_phrases.append(pred_phrase)
+
+ return boxes_filt, pred_phrases
+
+
+ def __call__(self, image_pil:Image, text_prompt):
+ if self.groundingdino_model is None:
+ self.load_groundingdino_model()
+ self.load_sam_predictor()
+
+ transformed_img = self.transform_image(image_pil)
+
+ # run grounding dino model
+ boxes_filt, pred_phrases = self.get_grounding_output(
+ transformed_img, text_prompt
+ )
+
+ if boxes_filt.shape[0] == 0:
+ logger.info(f"object not found")
+ w, h = image_pil.size
+ return np.zeros(shape=(1,h,w), dtype=bool)
+
+ img_array = np.array(image_pil)
+ self.sam_predictor.set_image(img_array)
+
+ size = image_pil.size
+ H, W = size[1], size[0]
+ for i in range(boxes_filt.size(0)):
+ boxes_filt[i] = boxes_filt[i] * torch.Tensor([W, H, W, H])
+ boxes_filt[i][:2] -= boxes_filt[i][2:] / 2
+ boxes_filt[i][2:] += boxes_filt[i][:2]
+
+ boxes_filt = boxes_filt.cpu()
+ transformed_boxes = self.sam_predictor.transform.apply_boxes_torch(boxes_filt, img_array.shape[:2]).to(self.device)
+
+ masks, _, _ = self.sam_predictor.predict_torch(
+ point_coords = None,
+ point_labels = None,
+ boxes = transformed_boxes.to(self.device),
+ multimask_output = False,
+ )
+
+ result = None
+ for m in masks:
+ if result is None:
+ result = m
+ else:
+ result |= m
+
+ result = result.cpu().detach().numpy().copy()
+
+ return result
+
+def load_mask_list(mask_dir, masked_area_list, mask_padding):
+
+ mask_frame_list = sorted(glob.glob( os.path.join(mask_dir, "[0-9]*.png"), recursive=False))
+
+ kernel = np.ones((abs(mask_padding),abs(mask_padding)),np.uint8)
+
+ for m in mask_frame_list:
+ cur = int(Path(m).stem)
+ tmp = np.asarray(Image.open(m))
+
+ if mask_padding < 0:
+ tmp = cv2.erode(tmp, kernel,iterations = 1)
+ elif mask_padding > 0:
+ tmp = cv2.dilate(tmp, kernel,iterations = 1)
+
+ masked_area_list[cur] = tmp[None,...]
+
+ return masked_area_list
+
+def crop_mask_list(mask_list):
+ area_list = []
+
+ max_h = 0
+ max_w = 0
+
+ for m in mask_list:
+ if m is None:
+ area_list.append(None)
+ continue
+ m = m > 127
+ area = np.where(m[0] == True)
+ if area[0].size == 0:
+ area_list.append(None)
+ continue
+
+ ymin = min(area[0])
+ ymax = max(area[0])
+ xmin = min(area[1])
+ xmax = max(area[1])
+ h = ymax+1 - ymin
+ w = xmax+1 - xmin
+ max_h = max(max_h, h)
+ max_w = max(max_w, w)
+ area_list.append( (ymin, ymax, xmin, xmax) )
+ #crop = m[ymin:ymax+1,xmin:xmax+1]
+
+ logger.info(f"{max_h=}")
+ logger.info(f"{max_w=}")
+
+ border_h = mask_list[0].shape[1]
+ border_w = mask_list[0].shape[2]
+
+ mask_pos_list=[]
+ cropped_mask_list=[]
+
+ for a, m in zip(area_list, mask_list):
+ if m is None or a is None:
+ mask_pos_list.append(None)
+ cropped_mask_list.append(None)
+ continue
+
+ ymin,ymax,xmin,xmax = a
+ h = ymax+1 - ymin
+ w = xmax+1 - xmin
+
+ # H
+ diff_h = max_h - h
+ dh1 = diff_h//2
+ dh2 = diff_h - dh1
+ y1 = ymin - dh1
+ y2 = ymax + dh2
+ if y1 < 0:
+ y1 = 0
+ y2 = max_h-1
+ elif y2 >= border_h:
+ y1 = (border_h-1) - (max_h - 1)
+ y2 = (border_h-1)
+
+ # W
+ diff_w = max_w - w
+ dw1 = diff_w//2
+ dw2 = diff_w - dw1
+ x1 = xmin - dw1
+ x2 = xmax + dw2
+ if x1 < 0:
+ x1 = 0
+ x2 = max_w-1
+ elif x2 >= border_w:
+ x1 = (border_w-1) - (max_w - 1)
+ x2 = (border_w-1)
+
+ mask_pos_list.append( (int(x1),int(y1)) )
+ m = m[0][y1:y2+1,x1:x2+1]
+ cropped_mask_list.append( m[None,...] )
+
+
+ return cropped_mask_list, mask_pos_list, (max_h,max_w)
+
+def crop_frames(pos_list, crop_size_hw, frame_dir):
+ h,w = crop_size_hw
+
+ for i,pos in tqdm(enumerate(pos_list),total=len(pos_list)):
+ filename = f"{i:08d}.png"
+ frame_path = frame_dir / filename
+ if not frame_path.is_file():
+ logger.info(f"{frame_path=} not found. skip")
+ continue
+ if pos is None:
+ continue
+
+ x, y = pos
+
+ tmp = np.asarray(Image.open(frame_path))
+ tmp = tmp[y:y+h,x:x+w,...]
+ Image.fromarray(tmp).save(frame_path)
+
+def save_crop_info(mask_pos_list, crop_size_hw, frame_size_hw, save_path):
+ import json
+
+ pos_map = {}
+
+ for i, pos in enumerate(mask_pos_list):
+ if pos is not None:
+ pos_map[str(i)]=pos
+
+ info = {
+ "frame_height" : int(frame_size_hw[0]),
+ "frame_width" : int(frame_size_hw[1]),
+ "height": int(crop_size_hw[0]),
+ "width": int(crop_size_hw[1]),
+ "pos_map" : pos_map,
+ }
+
+ with open(save_path, mode="wt", encoding="utf-8") as f:
+ json.dump(info, f, ensure_ascii=False, indent=4)
+
+def restore_position(mask_list, crop_info):
+
+ f_h = crop_info["frame_height"]
+ f_w = crop_info["frame_width"]
+
+ h = crop_info["height"]
+ w = crop_info["width"]
+ pos_map = crop_info["pos_map"]
+
+ for i in pos_map:
+ x,y = pos_map[i]
+ i = int(i)
+
+ m = mask_list[i]
+
+ if m is None:
+ continue
+
+ m = cv2.resize( m, (w,h) )
+ if len(m.shape) == 2:
+ m = m[...,None]
+
+ frame = np.zeros(shape=(f_h,f_w,m.shape[2]), dtype=np.uint8)
+
+ frame[y:y+h,x:x+w,...] = m
+ mask_list[i] = frame
+
+
+ return mask_list
+
+def load_frame_list(frame_dir, frame_array_list, crop_info):
+ frame_list = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+
+ for f in frame_list:
+ cur = int(Path(f).stem)
+ frame_array_list[cur] = np.asarray(Image.open(f))
+
+ if not crop_info:
+ logger.info(f"crop_info is not exists -> skip restore")
+ return frame_array_list
+
+ for i,f in enumerate(frame_array_list):
+ if f is None:
+ continue
+ frame_array_list[i] = f
+
+ frame_array_list = restore_position(frame_array_list, crop_info)
+
+ return frame_array_list
+
+
+def create_fg(mask_token, frame_dir, output_dir, output_mask_dir, masked_area_list,
+ box_threshold=0.3,
+ text_threshold=0.25,
+ bg_color=(0,255,0),
+ mask_padding=0,
+ groundingdino_config="config/GroundingDINO/GroundingDINO_SwinB_cfg.py",
+ groundingdino_checkpoint="data/models/GroundingDINO/groundingdino_swinb_cogcoor.pth",
+ sam_checkpoint="data/models/SAM/sam_hq_vit_l.pth",
+ device="cuda",
+ ):
+
+ frame_list = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+
+ with torch.no_grad():
+ predictor = MaskPredictor(
+ model_config_path=groundingdino_config,
+ model_checkpoint_path=groundingdino_checkpoint,
+ device=device,
+ sam_checkpoint=sam_checkpoint,
+ box_threshold=box_threshold,
+ text_threshold=text_threshold,
+ )
+
+
+ if mask_padding != 0:
+ kernel = np.ones((abs(mask_padding),abs(mask_padding)),np.uint8)
+ kernel2 = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
+
+ for i, frame in tqdm(enumerate(frame_list),total=len(frame_list), desc=f"creating mask from {mask_token=}"):
+ frame = Path(frame)
+ file_name = frame.name
+
+ cur_frame_no = int(frame.stem)
+
+ img = Image.open(frame)
+
+ mask_array = predictor(img, mask_token)
+ mask_array = mask_array[0].astype(np.uint8) * 255
+
+
+ if mask_padding < 0:
+ mask_array = cv2.erode(mask_array.astype(np.uint8),kernel,iterations = 1)
+ elif mask_padding > 0:
+ mask_array = cv2.dilate(mask_array.astype(np.uint8),kernel,iterations = 1)
+
+ mask_array = cv2.morphologyEx(mask_array.astype(np.uint8), cv2.MORPH_OPEN, kernel2)
+ mask_array = cv2.GaussianBlur(mask_array, (7, 7), sigmaX=3, sigmaY=3, borderType=cv2.BORDER_DEFAULT)
+
+ if masked_area_list[cur_frame_no] is not None:
+ masked_area_list[cur_frame_no] = np.where(masked_area_list[cur_frame_no] > mask_array[None,...], masked_area_list[cur_frame_no], mask_array[None,...])
+ #masked_area_list[cur_frame_no] = masked_area_list[cur_frame_no] | mask_array[None,...]
+ else:
+ masked_area_list[cur_frame_no] = mask_array[None,...]
+
+
+ if output_mask_dir:
+ #mask_array2 = mask_array.astype(np.uint8).clip(0,1)
+ #mask_array2 *= 255
+ Image.fromarray(mask_array).save( output_mask_dir / file_name )
+
+ img_array = np.asarray(img).copy()
+ if bg_color is not None:
+ img_array[mask_array == 0] = bg_color
+
+ img = Image.fromarray(img_array)
+
+ img.save( output_dir / file_name )
+
+ return masked_area_list
+
+
+def dilate_mask(masked_area_list, flow_mask_dilates=8, mask_dilates=5):
+ kernel = np.ones((flow_mask_dilates,flow_mask_dilates),np.uint8)
+ flow_masks = [ cv2.dilate(mask[0].astype(np.uint8),kernel,iterations = 1) for mask in masked_area_list ]
+ flow_masks = [ Image.fromarray(mask * 255) for mask in flow_masks ]
+
+ kernel = np.ones((mask_dilates,mask_dilates),np.uint8)
+ dilated_masks = [ cv2.dilate(mask[0].astype(np.uint8),kernel,iterations = 1) for mask in masked_area_list ]
+ dilated_masks = [ Image.fromarray(mask * 255) for mask in dilated_masks ]
+
+ return flow_masks, dilated_masks
+
+
+# adapted from https://github.com/sczhou/ProPainter/blob/main/inference_propainter.py
+def resize_frames(frames, size=None):
+ if size is not None:
+ out_size = size
+ process_size = (out_size[0]-out_size[0]%8, out_size[1]-out_size[1]%8)
+ frames = [f.resize(process_size) for f in frames]
+ else:
+ out_size = frames[0].size
+ process_size = (out_size[0]-out_size[0]%8, out_size[1]-out_size[1]%8)
+ if not out_size == process_size:
+ frames = [f.resize(process_size) for f in frames]
+
+ return frames, process_size, out_size
+
+def get_ref_index(mid_neighbor_id, neighbor_ids, length, ref_stride=10, ref_num=-1):
+ ref_index = []
+ if ref_num == -1:
+ for i in range(0, length, ref_stride):
+ if i not in neighbor_ids:
+ ref_index.append(i)
+ else:
+ start_idx = max(0, mid_neighbor_id - ref_stride * (ref_num // 2))
+ end_idx = min(length, mid_neighbor_id + ref_stride * (ref_num // 2))
+ for i in range(start_idx, end_idx, ref_stride):
+ if i not in neighbor_ids:
+ if len(ref_index) > ref_num:
+ break
+ ref_index.append(i)
+ return ref_index
+
+def create_bg(frame_dir, output_dir, masked_area_list,
+ use_half = True,
+ raft_iter = 20,
+ subvideo_length=80,
+ neighbor_length=10,
+ ref_stride=10,
+ device="cuda",
+ low_vram = False,
+ ):
+ import sys
+ repo_path = Path("src/animatediff/repo/ProPainter").absolute()
+ repo_path = str(repo_path)
+ sys.path.append(repo_path)
+
+ from animatediff.repo.ProPainter.core.utils import to_tensors
+ from animatediff.repo.ProPainter.model.modules.flow_comp_raft import \
+ RAFT_bi
+ from animatediff.repo.ProPainter.model.propainter import InpaintGenerator
+ from animatediff.repo.ProPainter.model.recurrent_flow_completion import \
+ RecurrentFlowCompleteNet
+ from animatediff.repo.ProPainter.utils.download_util import \
+ load_file_from_url
+
+ pretrain_model_url = 'https://github.com/sczhou/ProPainter/releases/download/v0.1.0/'
+ model_dir = Path("data/models/ProPainter")
+ model_dir.mkdir(parents=True, exist_ok=True)
+
+ frame_list = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+
+ frames = [Image.open(f) for f in frame_list]
+
+ if low_vram:
+ org_size = frames[0].size
+ _w, _h = frames[0].size
+ if max(_w, _h) > 512:
+ _w = int(_w * 0.75)
+ _h = int(_h * 0.75)
+
+ frames, size, out_size = resize_frames(frames, (_w, _h))
+ out_size = org_size
+
+ masked_area_list = [m[0] for m in masked_area_list]
+ masked_area_list = [cv2.resize(m.astype(np.uint8), dsize=size) for m in masked_area_list]
+ masked_area_list = [ m>127 for m in masked_area_list]
+ masked_area_list = [m[None,...] for m in masked_area_list]
+
+ else:
+ frames, size, out_size = resize_frames(frames, None)
+ masked_area_list = [ m>127 for m in masked_area_list]
+
+ w, h = size
+
+ flow_masks,masks_dilated = dilate_mask(masked_area_list)
+
+ frames_inp = [np.array(f).astype(np.uint8) for f in frames]
+ frames = to_tensors()(frames).unsqueeze(0) * 2 - 1
+ flow_masks = to_tensors()(flow_masks).unsqueeze(0)
+ masks_dilated = to_tensors()(masks_dilated).unsqueeze(0)
+ frames, flow_masks, masks_dilated = frames.to(device), flow_masks.to(device), masks_dilated.to(device)
+
+
+ ##############################################
+ # set up RAFT and flow competition model
+ ##############################################
+ ckpt_path = load_file_from_url(url=os.path.join(pretrain_model_url, 'raft-things.pth'),
+ model_dir=model_dir, progress=True, file_name=None)
+ fix_raft = RAFT_bi(ckpt_path, device)
+
+ ckpt_path = load_file_from_url(url=os.path.join(pretrain_model_url, 'recurrent_flow_completion.pth'),
+ model_dir=model_dir, progress=True, file_name=None)
+ fix_flow_complete = RecurrentFlowCompleteNet(ckpt_path)
+ for p in fix_flow_complete.parameters():
+ p.requires_grad = False
+ fix_flow_complete.to(device)
+ fix_flow_complete.eval()
+
+ ##############################################
+ # set up ProPainter model
+ ##############################################
+ ckpt_path = load_file_from_url(url=os.path.join(pretrain_model_url, 'ProPainter.pth'),
+ model_dir=model_dir, progress=True, file_name=None)
+ model = InpaintGenerator(model_path=ckpt_path).to(device)
+ model.eval()
+
+
+
+ ##############################################
+ # ProPainter inference
+ ##############################################
+ video_length = frames.size(1)
+ logger.info(f'\nProcessing: [{video_length} frames]...')
+ with torch.no_grad():
+ # ---- compute flow ----
+ if max(w,h) <= 640:
+ short_clip_len = 12
+ elif max(w,h) <= 720:
+ short_clip_len = 8
+ elif max(w,h) <= 1280:
+ short_clip_len = 4
+ else:
+ short_clip_len = 2
+
+ # use fp32 for RAFT
+ if frames.size(1) > short_clip_len:
+ gt_flows_f_list, gt_flows_b_list = [], []
+ for f in range(0, video_length, short_clip_len):
+ end_f = min(video_length, f + short_clip_len)
+ if f == 0:
+ flows_f, flows_b = fix_raft(frames[:,f:end_f], iters=raft_iter)
+ else:
+ flows_f, flows_b = fix_raft(frames[:,f-1:end_f], iters=raft_iter)
+
+ gt_flows_f_list.append(flows_f)
+ gt_flows_b_list.append(flows_b)
+ torch.cuda.empty_cache()
+
+ gt_flows_f = torch.cat(gt_flows_f_list, dim=1)
+ gt_flows_b = torch.cat(gt_flows_b_list, dim=1)
+ gt_flows_bi = (gt_flows_f, gt_flows_b)
+ else:
+ gt_flows_bi = fix_raft(frames, iters=raft_iter)
+ torch.cuda.empty_cache()
+
+
+ if use_half:
+ frames, flow_masks, masks_dilated = frames.half(), flow_masks.half(), masks_dilated.half()
+ gt_flows_bi = (gt_flows_bi[0].half(), gt_flows_bi[1].half())
+ fix_flow_complete = fix_flow_complete.half()
+ model = model.half()
+
+
+ # ---- complete flow ----
+ flow_length = gt_flows_bi[0].size(1)
+ if flow_length > subvideo_length:
+ pred_flows_f, pred_flows_b = [], []
+ pad_len = 5
+ for f in range(0, flow_length, subvideo_length):
+ s_f = max(0, f - pad_len)
+ e_f = min(flow_length, f + subvideo_length + pad_len)
+ pad_len_s = max(0, f) - s_f
+ pad_len_e = e_f - min(flow_length, f + subvideo_length)
+ pred_flows_bi_sub, _ = fix_flow_complete.forward_bidirect_flow(
+ (gt_flows_bi[0][:, s_f:e_f], gt_flows_bi[1][:, s_f:e_f]),
+ flow_masks[:, s_f:e_f+1])
+ pred_flows_bi_sub = fix_flow_complete.combine_flow(
+ (gt_flows_bi[0][:, s_f:e_f], gt_flows_bi[1][:, s_f:e_f]),
+ pred_flows_bi_sub,
+ flow_masks[:, s_f:e_f+1])
+
+ pred_flows_f.append(pred_flows_bi_sub[0][:, pad_len_s:e_f-s_f-pad_len_e])
+ pred_flows_b.append(pred_flows_bi_sub[1][:, pad_len_s:e_f-s_f-pad_len_e])
+ torch.cuda.empty_cache()
+
+ pred_flows_f = torch.cat(pred_flows_f, dim=1)
+ pred_flows_b = torch.cat(pred_flows_b, dim=1)
+ pred_flows_bi = (pred_flows_f, pred_flows_b)
+ else:
+ pred_flows_bi, _ = fix_flow_complete.forward_bidirect_flow(gt_flows_bi, flow_masks)
+ pred_flows_bi = fix_flow_complete.combine_flow(gt_flows_bi, pred_flows_bi, flow_masks)
+ torch.cuda.empty_cache()
+
+
+ # ---- image propagation ----
+ masked_frames = frames * (1 - masks_dilated)
+ subvideo_length_img_prop = min(100, subvideo_length) # ensure a minimum of 100 frames for image propagation
+ if video_length > subvideo_length_img_prop:
+ updated_frames, updated_masks = [], []
+ pad_len = 10
+ for f in range(0, video_length, subvideo_length_img_prop):
+ s_f = max(0, f - pad_len)
+ e_f = min(video_length, f + subvideo_length_img_prop + pad_len)
+ pad_len_s = max(0, f) - s_f
+ pad_len_e = e_f - min(video_length, f + subvideo_length_img_prop)
+
+ b, t, _, _, _ = masks_dilated[:, s_f:e_f].size()
+ pred_flows_bi_sub = (pred_flows_bi[0][:, s_f:e_f-1], pred_flows_bi[1][:, s_f:e_f-1])
+ prop_imgs_sub, updated_local_masks_sub = model.img_propagation(masked_frames[:, s_f:e_f],
+ pred_flows_bi_sub,
+ masks_dilated[:, s_f:e_f],
+ 'nearest')
+ updated_frames_sub = frames[:, s_f:e_f] * (1 - masks_dilated[:, s_f:e_f]) + \
+ prop_imgs_sub.view(b, t, 3, h, w) * masks_dilated[:, s_f:e_f]
+ updated_masks_sub = updated_local_masks_sub.view(b, t, 1, h, w)
+
+ updated_frames.append(updated_frames_sub[:, pad_len_s:e_f-s_f-pad_len_e])
+ updated_masks.append(updated_masks_sub[:, pad_len_s:e_f-s_f-pad_len_e])
+ torch.cuda.empty_cache()
+
+ updated_frames = torch.cat(updated_frames, dim=1)
+ updated_masks = torch.cat(updated_masks, dim=1)
+ else:
+ b, t, _, _, _ = masks_dilated.size()
+ prop_imgs, updated_local_masks = model.img_propagation(masked_frames, pred_flows_bi, masks_dilated, 'nearest')
+ updated_frames = frames * (1 - masks_dilated) + prop_imgs.view(b, t, 3, h, w) * masks_dilated
+ updated_masks = updated_local_masks.view(b, t, 1, h, w)
+ torch.cuda.empty_cache()
+
+ ori_frames = frames_inp
+ comp_frames = [None] * video_length
+
+ neighbor_stride = neighbor_length // 2
+ if video_length > subvideo_length:
+ ref_num = subvideo_length // ref_stride
+ else:
+ ref_num = -1
+
+ # ---- feature propagation + transformer ----
+ for f in tqdm(range(0, video_length, neighbor_stride)):
+ neighbor_ids = [
+ i for i in range(max(0, f - neighbor_stride),
+ min(video_length, f + neighbor_stride + 1))
+ ]
+ ref_ids = get_ref_index(f, neighbor_ids, video_length, ref_stride, ref_num)
+ selected_imgs = updated_frames[:, neighbor_ids + ref_ids, :, :, :]
+ selected_masks = masks_dilated[:, neighbor_ids + ref_ids, :, :, :]
+ selected_update_masks = updated_masks[:, neighbor_ids + ref_ids, :, :, :]
+ selected_pred_flows_bi = (pred_flows_bi[0][:, neighbor_ids[:-1], :, :, :], pred_flows_bi[1][:, neighbor_ids[:-1], :, :, :])
+
+ with torch.no_grad():
+ # 1.0 indicates mask
+ l_t = len(neighbor_ids)
+
+ # pred_img = selected_imgs # results of image propagation
+ pred_img = model(selected_imgs, selected_pred_flows_bi, selected_masks, selected_update_masks, l_t)
+
+ pred_img = pred_img.view(-1, 3, h, w)
+
+ pred_img = (pred_img + 1) / 2
+ pred_img = pred_img.cpu().permute(0, 2, 3, 1).numpy() * 255
+ binary_masks = masks_dilated[0, neighbor_ids, :, :, :].cpu().permute(
+ 0, 2, 3, 1).numpy().astype(np.uint8)
+ for i in range(len(neighbor_ids)):
+ idx = neighbor_ids[i]
+ img = np.array(pred_img[i]).astype(np.uint8) * binary_masks[i] \
+ + ori_frames[idx] * (1 - binary_masks[i])
+ if comp_frames[idx] is None:
+ comp_frames[idx] = img
+ else:
+ comp_frames[idx] = comp_frames[idx].astype(np.float32) * 0.5 + img.astype(np.float32) * 0.5
+
+ comp_frames[idx] = comp_frames[idx].astype(np.uint8)
+
+ torch.cuda.empty_cache()
+
+ # save each frame
+ for idx in range(video_length):
+ f = comp_frames[idx]
+ f = cv2.resize(f, out_size, interpolation = cv2.INTER_CUBIC)
+ f = cv2.cvtColor(f, cv2.COLOR_BGR2RGB)
+ dst_img_path = output_dir.joinpath( f"{idx:08d}.png" )
+ cv2.imwrite(str(dst_img_path), f)
+
+ sys.path.remove(repo_path)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/animate/src/animatediff/utils/mask_animseg.py b/animate/src/animatediff/utils/mask_animseg.py
new file mode 100644
index 0000000000000000000000000000000000000000..299c8ca0d836d8b2e3a0926276972708435392da
--- /dev/null
+++ b/animate/src/animatediff/utils/mask_animseg.py
@@ -0,0 +1,88 @@
+import glob
+import logging
+import os
+from pathlib import Path
+
+import cv2
+import numpy as np
+import onnxruntime as rt
+import torch
+from PIL import Image
+from rembg import new_session, remove
+from tqdm.rich import tqdm
+
+logger = logging.getLogger(__name__)
+
+def animseg_create_fg(frame_dir, output_dir, output_mask_dir, masked_area_list,
+ bg_color=(0,255,0),
+ mask_padding=0,
+ ):
+
+ frame_list = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+
+ if mask_padding != 0:
+ kernel = np.ones((abs(mask_padding),abs(mask_padding)),np.uint8)
+ kernel2 = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
+
+
+ providers = ['CUDAExecutionProvider', 'CPUExecutionProvider']
+ rmbg_model = rt.InferenceSession("data/models/anime_seg/isnetis.onnx", providers=providers)
+
+ def get_mask(img, s=1024):
+ img = (img / 255).astype(np.float32)
+ h, w = h0, w0 = img.shape[:-1]
+ h, w = (s, int(s * w / h)) if h > w else (int(s * h / w), s)
+ ph, pw = s - h, s - w
+ img_input = np.zeros([s, s, 3], dtype=np.float32)
+ img_input[ph // 2:ph // 2 + h, pw // 2:pw // 2 + w] = cv2.resize(img, (w, h))
+ img_input = np.transpose(img_input, (2, 0, 1))
+ img_input = img_input[np.newaxis, :]
+ mask = rmbg_model.run(None, {'img': img_input})[0][0]
+ mask = np.transpose(mask, (1, 2, 0))
+ mask = mask[ph // 2:ph // 2 + h, pw // 2:pw // 2 + w]
+ mask = cv2.resize(mask, (w0, h0))
+ mask = (mask * 255).astype(np.uint8)
+ return mask
+
+
+ for i, frame in tqdm(enumerate(frame_list),total=len(frame_list), desc=f"creating mask"):
+ frame = Path(frame)
+ file_name = frame.name
+
+ cur_frame_no = int(frame.stem)
+
+ img = Image.open(frame)
+ img_array = np.asarray(img)
+
+ mask_array = get_mask(img_array)
+
+# Image.fromarray(mask_array).save( output_dir / Path("raw_" + file_name))
+
+ if mask_padding < 0:
+ mask_array = cv2.erode(mask_array.astype(np.uint8),kernel,iterations = 1)
+ elif mask_padding > 0:
+ mask_array = cv2.dilate(mask_array.astype(np.uint8),kernel,iterations = 1)
+
+ mask_array = cv2.morphologyEx(mask_array, cv2.MORPH_OPEN, kernel2)
+ mask_array = cv2.GaussianBlur(mask_array, (7, 7), sigmaX=3, sigmaY=3, borderType=cv2.BORDER_DEFAULT)
+
+ if masked_area_list[cur_frame_no] is not None:
+ masked_area_list[cur_frame_no] = np.where(masked_area_list[cur_frame_no] > mask_array[None,...], masked_area_list[cur_frame_no], mask_array[None,...])
+ else:
+ masked_area_list[cur_frame_no] = mask_array[None,...]
+
+ if output_mask_dir:
+ Image.fromarray(mask_array).save( output_mask_dir / file_name )
+
+ img_array = np.asarray(img).copy()
+ if bg_color is not None:
+ img_array[mask_array == 0] = bg_color
+
+ img = Image.fromarray(img_array)
+
+ img.save( output_dir / file_name )
+
+ return masked_area_list
+
+
+
diff --git a/animate/src/animatediff/utils/mask_rembg.py b/animate/src/animatediff/utils/mask_rembg.py
new file mode 100644
index 0000000000000000000000000000000000000000..78514a28dca01dc67fc07881ec98b50e247cec8d
--- /dev/null
+++ b/animate/src/animatediff/utils/mask_rembg.py
@@ -0,0 +1,68 @@
+import glob
+import logging
+import os
+from pathlib import Path
+
+import cv2
+import numpy as np
+import torch
+from PIL import Image
+from rembg import new_session, remove
+from tqdm.rich import tqdm
+
+logger = logging.getLogger(__name__)
+
+def rembg_create_fg(frame_dir, output_dir, output_mask_dir, masked_area_list,
+ bg_color=(0,255,0),
+ mask_padding=0,
+ ):
+
+ frame_list = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+
+ if mask_padding != 0:
+ kernel = np.ones((abs(mask_padding),abs(mask_padding)),np.uint8)
+ kernel2 = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
+
+ session = new_session(providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
+
+ for i, frame in tqdm(enumerate(frame_list),total=len(frame_list), desc=f"creating mask"):
+ frame = Path(frame)
+ file_name = frame.name
+
+ cur_frame_no = int(frame.stem)
+
+ img = Image.open(frame)
+ img_array = np.asarray(img)
+
+ mask_array = remove(img_array, only_mask=True, session=session)
+
+ #mask_array = mask_array[None,...]
+
+ if mask_padding < 0:
+ mask_array = cv2.erode(mask_array.astype(np.uint8),kernel,iterations = 1)
+ elif mask_padding > 0:
+ mask_array = cv2.dilate(mask_array.astype(np.uint8),kernel,iterations = 1)
+
+ mask_array = cv2.morphologyEx(mask_array, cv2.MORPH_OPEN, kernel2)
+ mask_array = cv2.GaussianBlur(mask_array, (7, 7), sigmaX=3, sigmaY=3, borderType=cv2.BORDER_DEFAULT)
+
+ if masked_area_list[cur_frame_no] is not None:
+ masked_area_list[cur_frame_no] = np.where(masked_area_list[cur_frame_no] > mask_array[None,...], masked_area_list[cur_frame_no], mask_array[None,...])
+ else:
+ masked_area_list[cur_frame_no] = mask_array[None,...]
+
+ if output_mask_dir:
+ Image.fromarray(mask_array).save( output_mask_dir / file_name )
+
+ img_array = np.asarray(img).copy()
+ if bg_color is not None:
+ img_array[mask_array == 0] = bg_color
+
+ img = Image.fromarray(img_array)
+
+ img.save( output_dir / file_name )
+
+ return masked_area_list
+
+
+
diff --git a/animate/src/animatediff/utils/model.py b/animate/src/animatediff/utils/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..6ac0f7a6220e24250f1c077e5acbcf6408649801
--- /dev/null
+++ b/animate/src/animatediff/utils/model.py
@@ -0,0 +1,201 @@
+import logging
+from functools import wraps
+from pathlib import Path
+from typing import Optional, TypeVar
+
+from diffusers import StableDiffusionPipeline, StableDiffusionXLPipeline
+from huggingface_hub import hf_hub_download
+from torch import nn
+
+from animatediff import HF_HUB_CACHE, HF_MODULE_REPO, get_dir
+from animatediff.settings import CKPT_EXTENSIONS
+from animatediff.utils.huggingface import get_hf_pipeline, get_hf_pipeline_sdxl
+from animatediff.utils.util import path_from_cwd
+
+logger = logging.getLogger(__name__)
+
+data_dir = get_dir("data")
+checkpoint_dir = data_dir.joinpath("models/sd")
+pipeline_dir = data_dir.joinpath("models/huggingface")
+
+# for the nop_train() monkeypatch
+T = TypeVar("T", bound=nn.Module)
+
+
+def nop_train(self: T, mode: bool = True) -> T:
+ """No-op for monkeypatching train() call to prevent unfreezing module"""
+ return self
+
+
+def get_base_model(model_name_or_path: str, local_dir: Path, force: bool = False, is_sdxl:bool=False) -> Path:
+ model_name_or_path = Path(model_name_or_path)
+
+ model_save_dir = local_dir.joinpath(str(model_name_or_path).split("/")[-1]).resolve()
+ model_is_repo_id = False if model_name_or_path.joinpath("model_index.json").exists() else True
+
+ # if we have a HF repo ID, download it
+ if model_is_repo_id:
+ logger.debug("Base model is a HuggingFace repo ID")
+ if model_save_dir.joinpath("model_index.json").exists():
+ logger.debug(f"Base model already downloaded to: {path_from_cwd(model_save_dir)}")
+ else:
+ logger.info(f"Downloading base model from {model_name_or_path}...")
+ if is_sdxl:
+ _ = get_hf_pipeline_sdxl(model_name_or_path, model_save_dir, save=True, force_download=force)
+ else:
+ _ = get_hf_pipeline(model_name_or_path, model_save_dir, save=True, force_download=force)
+ model_name_or_path = model_save_dir
+
+ return Path(model_name_or_path)
+
+
+def fix_checkpoint_if_needed(checkpoint: Path, debug:bool):
+ def dump(loaded):
+ for a in loaded:
+ logger.info(f"{a} {loaded[a].shape}")
+
+ if debug:
+ from safetensors.torch import load_file, save_file
+ loaded = load_file(checkpoint, "cpu")
+
+ dump(loaded)
+
+ return
+
+ try:
+ pipeline = StableDiffusionPipeline.from_single_file(
+ pretrained_model_link_or_path=str(checkpoint.absolute()),
+ local_files_only=False,
+ load_safety_checker=False,
+ )
+ logger.info("This file works fine.")
+ return
+ except:
+ from safetensors.torch import load_file, save_file
+
+ loaded = load_file(checkpoint, "cpu")
+
+ convert_table_bias={
+ "first_stage_model.decoder.mid.attn_1.to_k.bias":"first_stage_model.decoder.mid.attn_1.k.bias",
+ "first_stage_model.decoder.mid.attn_1.to_out.0.bias":"first_stage_model.decoder.mid.attn_1.proj_out.bias",
+ "first_stage_model.decoder.mid.attn_1.to_q.bias":"first_stage_model.decoder.mid.attn_1.q.bias",
+ "first_stage_model.decoder.mid.attn_1.to_v.bias":"first_stage_model.decoder.mid.attn_1.v.bias",
+ "first_stage_model.encoder.mid.attn_1.to_k.bias":"first_stage_model.encoder.mid.attn_1.k.bias",
+ "first_stage_model.encoder.mid.attn_1.to_out.0.bias":"first_stage_model.encoder.mid.attn_1.proj_out.bias",
+ "first_stage_model.encoder.mid.attn_1.to_q.bias":"first_stage_model.encoder.mid.attn_1.q.bias",
+ "first_stage_model.encoder.mid.attn_1.to_v.bias":"first_stage_model.encoder.mid.attn_1.v.bias",
+ }
+
+ convert_table_weight={
+ "first_stage_model.decoder.mid.attn_1.to_k.weight":"first_stage_model.decoder.mid.attn_1.k.weight",
+ "first_stage_model.decoder.mid.attn_1.to_out.0.weight":"first_stage_model.decoder.mid.attn_1.proj_out.weight",
+ "first_stage_model.decoder.mid.attn_1.to_q.weight":"first_stage_model.decoder.mid.attn_1.q.weight",
+ "first_stage_model.decoder.mid.attn_1.to_v.weight":"first_stage_model.decoder.mid.attn_1.v.weight",
+ "first_stage_model.encoder.mid.attn_1.to_k.weight":"first_stage_model.encoder.mid.attn_1.k.weight",
+ "first_stage_model.encoder.mid.attn_1.to_out.0.weight":"first_stage_model.encoder.mid.attn_1.proj_out.weight",
+ "first_stage_model.encoder.mid.attn_1.to_q.weight":"first_stage_model.encoder.mid.attn_1.q.weight",
+ "first_stage_model.encoder.mid.attn_1.to_v.weight":"first_stage_model.encoder.mid.attn_1.v.weight",
+ }
+
+ for a in list(loaded.keys()):
+ if a in convert_table_bias:
+ new_key = convert_table_bias[a]
+ loaded[new_key] = loaded.pop(a)
+ elif a in convert_table_weight:
+ new_key = convert_table_weight[a]
+ item = loaded.pop(a)
+ if len(item.shape) == 2:
+ item = item.unsqueeze(dim=-1).unsqueeze(dim=-1)
+ loaded[new_key] = item
+
+ new_path = str(checkpoint.parent / checkpoint.stem) + "_fixed"+checkpoint.suffix
+
+ logger.info(f"Saving file to {new_path}")
+ save_file(loaded, Path(new_path))
+
+
+
+def checkpoint_to_pipeline(
+ checkpoint: Path,
+ target_dir: Optional[Path] = None,
+ save: bool = True,
+) -> StableDiffusionPipeline:
+ logger.debug(f"Converting checkpoint {path_from_cwd(checkpoint)}")
+ if target_dir is None:
+ target_dir = pipeline_dir.joinpath(checkpoint.stem)
+
+ pipeline = StableDiffusionPipeline.from_single_file(
+ pretrained_model_link_or_path=str(checkpoint.absolute()),
+ local_files_only=False,
+ safety_checker=None,
+ )
+
+ if save:
+ target_dir.mkdir(parents=True, exist_ok=True)
+ logger.info(f"Saving pipeline to {path_from_cwd(target_dir)}")
+ pipeline.save_pretrained(target_dir, safe_serialization=True)
+ return pipeline, target_dir
+
+def checkpoint_to_pipeline_sdxl(
+ checkpoint: Path,
+ target_dir: Optional[Path] = None,
+ save: bool = True,
+) -> StableDiffusionXLPipeline:
+ logger.debug(f"Converting checkpoint {path_from_cwd(checkpoint)}")
+ if target_dir is None:
+ target_dir = pipeline_dir.joinpath(checkpoint.stem)
+
+ pipeline = StableDiffusionXLPipeline.from_single_file(
+ pretrained_model_link_or_path=str(checkpoint.absolute()),
+ local_files_only=False,
+ safety_checker=None,
+ )
+
+ if save:
+ target_dir.mkdir(parents=True, exist_ok=True)
+ logger.info(f"Saving pipeline to {path_from_cwd(target_dir)}")
+ pipeline.save_pretrained(target_dir, safe_serialization=True)
+ return pipeline, target_dir
+
+def get_checkpoint_weights(checkpoint: Path):
+ temp_pipeline: StableDiffusionPipeline
+ temp_pipeline, _ = checkpoint_to_pipeline(checkpoint, save=False)
+ unet_state_dict = temp_pipeline.unet.state_dict()
+ tenc_state_dict = temp_pipeline.text_encoder.state_dict()
+ vae_state_dict = temp_pipeline.vae.state_dict()
+ return unet_state_dict, tenc_state_dict, vae_state_dict
+
+def get_checkpoint_weights_sdxl(checkpoint: Path):
+ temp_pipeline: StableDiffusionXLPipeline
+ temp_pipeline, _ = checkpoint_to_pipeline_sdxl(checkpoint, save=False)
+ unet_state_dict = temp_pipeline.unet.state_dict()
+ tenc_state_dict = temp_pipeline.text_encoder.state_dict()
+ tenc2_state_dict = temp_pipeline.text_encoder_2.state_dict()
+ vae_state_dict = temp_pipeline.vae.state_dict()
+ return unet_state_dict, tenc_state_dict, tenc2_state_dict, vae_state_dict
+
+
+def ensure_motion_modules(
+ repo_id: str = HF_MODULE_REPO,
+ fp16: bool = False,
+ force: bool = False,
+):
+ """Retrieve the motion modules from HuggingFace Hub."""
+ module_files = ["mm_sd_v14.safetensors", "mm_sd_v15.safetensors"]
+ module_dir = get_dir("data/models/motion-module")
+ for file in module_files:
+ target_path = module_dir.joinpath(file)
+ if fp16:
+ target_path = target_path.with_suffix(".fp16.safetensors")
+ if target_path.exists() and force is not True:
+ logger.debug(f"File {path_from_cwd(target_path)} already exists, skipping download")
+ else:
+ result = hf_hub_download(
+ repo_id=repo_id,
+ filename=target_path.name,
+ cache_dir=HF_HUB_CACHE,
+ local_dir=module_dir,
+ local_dir_use_symlinks=False,
+ resume_download=True,
+ )
+ logger.debug(f"Downloaded {path_from_cwd(result)}")
diff --git a/animate/src/animatediff/utils/pipeline.py b/animate/src/animatediff/utils/pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..f24c2d445acfaf263862f4e5737134eab8cfda40
--- /dev/null
+++ b/animate/src/animatediff/utils/pipeline.py
@@ -0,0 +1,123 @@
+import logging
+from typing import Optional
+
+import torch
+import torch._dynamo as dynamo
+from diffusers import (DiffusionPipeline, StableDiffusionPipeline,
+ StableDiffusionXLPipeline)
+from einops._torch_specific import allow_ops_in_compiled_graph
+
+from animatediff.utils.device import get_memory_format, get_model_dtypes
+from animatediff.utils.model import nop_train
+
+logger = logging.getLogger(__name__)
+
+
+def send_to_device(
+ pipeline: DiffusionPipeline,
+ device: torch.device,
+ freeze: bool = True,
+ force_half: bool = False,
+ compile: bool = False,
+ is_sdxl: bool = False,
+) -> DiffusionPipeline:
+ if is_sdxl:
+ return send_to_device_sdxl(
+ pipeline=pipeline,
+ device=device,
+ freeze=freeze,
+ force_half=force_half,
+ compile=compile,
+ )
+
+ logger.info(f"Sending pipeline to device \"{device.type}{device.index if device.index else ''}\"")
+
+ unet_dtype, tenc_dtype, vae_dtype = get_model_dtypes(device, force_half)
+ model_memory_format = get_memory_format(device)
+
+ if hasattr(pipeline, 'controlnet'):
+ unet_dtype = tenc_dtype = vae_dtype
+
+ logger.info(f"-> Selected data types: {unet_dtype=},{tenc_dtype=},{vae_dtype=}")
+
+ if hasattr(pipeline.controlnet, 'nets'):
+ for i in range(len(pipeline.controlnet.nets)):
+ pipeline.controlnet.nets[i] = pipeline.controlnet.nets[i].to(device=device, dtype=vae_dtype, memory_format=model_memory_format)
+ else:
+ if pipeline.controlnet:
+ pipeline.controlnet = pipeline.controlnet.to(device=device, dtype=vae_dtype, memory_format=model_memory_format)
+
+ if hasattr(pipeline, 'controlnet_map'):
+ if pipeline.controlnet_map:
+ for c in pipeline.controlnet_map:
+ #pipeline.controlnet_map[c] = pipeline.controlnet_map[c].to(device=device, dtype=unet_dtype, memory_format=model_memory_format)
+ pipeline.controlnet_map[c] = pipeline.controlnet_map[c].to(dtype=unet_dtype, memory_format=model_memory_format)
+
+ if hasattr(pipeline, 'lora_map'):
+ if pipeline.lora_map:
+ pipeline.lora_map.to(device=device, dtype=unet_dtype)
+
+ if hasattr(pipeline, 'lcm'):
+ if pipeline.lcm:
+ pipeline.lcm.to(device=device, dtype=unet_dtype)
+
+ pipeline.unet = pipeline.unet.to(device=device, dtype=unet_dtype, memory_format=model_memory_format)
+ pipeline.text_encoder = pipeline.text_encoder.to(device=device, dtype=tenc_dtype)
+ pipeline.vae = pipeline.vae.to(device=device, dtype=vae_dtype, memory_format=model_memory_format)
+
+ # Compile model if enabled
+ if compile:
+ if not isinstance(pipeline.unet, dynamo.OptimizedModule):
+ allow_ops_in_compiled_graph() # make einops behave
+ logger.warn("Enabling model compilation with TorchDynamo, this may take a while...")
+ logger.warn("Model compilation is experimental and may not work as expected!")
+ pipeline.unet = torch.compile(
+ pipeline.unet,
+ backend="inductor",
+ mode="reduce-overhead",
+ )
+ else:
+ logger.debug("Skipping model compilation, already compiled!")
+
+ return pipeline
+
+
+def send_to_device_sdxl(
+ pipeline: StableDiffusionXLPipeline,
+ device: torch.device,
+ freeze: bool = True,
+ force_half: bool = False,
+ compile: bool = False,
+) -> StableDiffusionXLPipeline:
+ logger.info(f"Sending pipeline to device \"{device.type}{device.index if device.index else ''}\"")
+
+ pipeline.unet = pipeline.unet.half()
+ pipeline.text_encoder = pipeline.text_encoder.half()
+ pipeline.text_encoder_2 = pipeline.text_encoder_2.half()
+
+ if False:
+ pipeline.to(device)
+ else:
+ pipeline.enable_model_cpu_offload()
+
+ pipeline.enable_xformers_memory_efficient_attention()
+ pipeline.enable_vae_slicing()
+ pipeline.enable_vae_tiling()
+
+ return pipeline
+
+
+
+def get_context_params(
+ length: int,
+ context: Optional[int] = None,
+ overlap: Optional[int] = None,
+ stride: Optional[int] = None,
+):
+ if context is None:
+ context = min(length, 16)
+ if overlap is None:
+ overlap = context // 4
+ if stride is None:
+ stride = 0
+ return context, overlap, stride
diff --git a/animate/src/animatediff/utils/tagger.py b/animate/src/animatediff/utils/tagger.py
new file mode 100644
index 0000000000000000000000000000000000000000..3e63c42312aedbc9e852ca319bc5b7ca10abe4c0
--- /dev/null
+++ b/animate/src/animatediff/utils/tagger.py
@@ -0,0 +1,161 @@
+# https://huggingface.co/spaces/SmilingWolf/wd-v1-4-tags/blob/main/app.py
+
+import glob
+import logging
+import os
+
+import cv2
+import numpy as np
+import onnxruntime
+import pandas as pd
+from PIL import Image
+from tqdm.rich import tqdm
+
+from animatediff.utils.util import prepare_wd14tagger
+
+logger = logging.getLogger(__name__)
+
+
+def make_square(img, target_size):
+ old_size = img.shape[:2]
+ desired_size = max(old_size)
+ desired_size = max(desired_size, target_size)
+
+ delta_w = desired_size - old_size[1]
+ delta_h = desired_size - old_size[0]
+ top, bottom = delta_h // 2, delta_h - (delta_h // 2)
+ left, right = delta_w // 2, delta_w - (delta_w // 2)
+
+ color = [255, 255, 255]
+ new_im = cv2.copyMakeBorder(
+ img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color
+ )
+ return new_im
+
+def smart_resize(img, size):
+ # Assumes the image has already gone through make_square
+ if img.shape[0] > size:
+ img = cv2.resize(img, (size, size), interpolation=cv2.INTER_AREA)
+ elif img.shape[0] < size:
+ img = cv2.resize(img, (size, size), interpolation=cv2.INTER_CUBIC)
+ return img
+
+
+class Tagger:
+ def __init__(self, general_threshold, character_threshold, ignore_tokens, with_confidence, is_danbooru_format,is_cpu):
+ prepare_wd14tagger()
+# self.model = onnxruntime.InferenceSession("data/models/WD14tagger/model.onnx", providers=['CUDAExecutionProvider','CPUExecutionProvider'])
+ if is_cpu:
+ self.model = onnxruntime.InferenceSession("data/models/WD14tagger/model.onnx", providers=['CPUExecutionProvider'])
+ else:
+ self.model = onnxruntime.InferenceSession("data/models/WD14tagger/model.onnx", providers=['CUDAExecutionProvider'])
+ df = pd.read_csv("data/models/WD14tagger/selected_tags.csv")
+ self.tag_names = df["name"].tolist()
+ self.rating_indexes = list(np.where(df["category"] == 9)[0])
+ self.general_indexes = list(np.where(df["category"] == 0)[0])
+ self.character_indexes = list(np.where(df["category"] == 4)[0])
+
+ self.general_threshold = general_threshold
+ self.character_threshold = character_threshold
+ self.ignore_tokens = ignore_tokens
+ self.with_confidence = with_confidence
+ self.is_danbooru_format = is_danbooru_format
+
+ def __call__(
+ self,
+ image: Image,
+ ):
+
+ _, height, width, _ = self.model.get_inputs()[0].shape
+
+ # Alpha to white
+ image = image.convert("RGBA")
+ new_image = Image.new("RGBA", image.size, "WHITE")
+ new_image.paste(image, mask=image)
+ image = new_image.convert("RGB")
+ image = np.asarray(image)
+
+ # PIL RGB to OpenCV BGR
+ image = image[:, :, ::-1]
+
+ image = make_square(image, height)
+ image = smart_resize(image, height)
+ image = image.astype(np.float32)
+ image = np.expand_dims(image, 0)
+
+ input_name = self.model.get_inputs()[0].name
+ label_name = self.model.get_outputs()[0].name
+ probs = self.model.run([label_name], {input_name: image})[0]
+
+ labels = list(zip(self.tag_names, probs[0].astype(float)))
+
+ # First 4 labels are actually ratings: pick one with argmax
+ ratings_names = [labels[i] for i in self.rating_indexes]
+ rating = dict(ratings_names)
+
+ # Then we have general tags: pick any where prediction confidence > threshold
+ general_names = [labels[i] for i in self.general_indexes]
+ general_res = [x for x in general_names if x[1] > self.general_threshold]
+ general_res = dict(general_res)
+
+ # Everything else is characters: pick any where prediction confidence > threshold
+ character_names = [labels[i] for i in self.character_indexes]
+ character_res = [x for x in character_names if x[1] > self.character_threshold]
+ character_res = dict(character_res)
+
+ #logger.info(f"{rating=}")
+ #logger.info(f"{general_res=}")
+ #logger.info(f"{character_res=}")
+
+ general_res = {k:general_res[k] for k in (general_res.keys() - set(self.ignore_tokens)) }
+ character_res = {k:character_res[k] for k in (character_res.keys() - set(self.ignore_tokens)) }
+
+ prompt = ""
+
+ if self.with_confidence:
+ prompt = [ f"({i}:{character_res[i]:.2f})" for i in (character_res.keys()) ]
+ prompt += [ f"({i}:{general_res[i]:.2f})" for i in (general_res.keys()) ]
+ else:
+ prompt = [ i for i in (character_res.keys()) ]
+ prompt += [ i for i in (general_res.keys()) ]
+
+ prompt = ",".join(prompt)
+
+ if not self.is_danbooru_format:
+ prompt = prompt.replace("_", " ")
+
+ #logger.info(f"{prompt=}")
+ return prompt
+
+
+def get_labels(frame_dir, interval, general_threshold, character_threshold, ignore_tokens, with_confidence, is_danbooru_format, is_cpu =False):
+
+ import torch
+
+ result = {}
+ if os.path.isdir(frame_dir):
+ png_list = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+
+ png_map ={}
+ for png_path in png_list:
+ basename_without_ext = os.path.splitext(os.path.basename(png_path))[0]
+ png_map[int(basename_without_ext)] = png_path
+
+ with torch.no_grad():
+ tagger = Tagger(general_threshold, character_threshold, ignore_tokens, with_confidence, is_danbooru_format, is_cpu)
+
+ for i in tqdm(range(0, len(png_list), interval ), desc=f"WD14tagger"):
+ path = png_map[i]
+
+ #logger.info(f"{path=}")
+
+ result[str(i)] = tagger(
+ image= Image.open(path)
+ )
+
+ tagger = None
+
+ torch.cuda.empty_cache()
+
+ return result
+
diff --git a/animate/src/animatediff/utils/util.py b/animate/src/animatediff/utils/util.py
new file mode 100644
index 0000000000000000000000000000000000000000..70475b7babc53dfcd8c2da23e2c507e6660bf814
--- /dev/null
+++ b/animate/src/animatediff/utils/util.py
@@ -0,0 +1,666 @@
+import logging
+from os import PathLike
+from pathlib import Path
+from typing import List
+
+import torch
+import torch.distributed as dist
+from einops import rearrange
+from PIL import Image
+from torch import Tensor
+from torchvision.utils import save_image
+from tqdm.rich import tqdm
+
+logger = logging.getLogger(__name__)
+
+def zero_rank_print(s):
+ if not isinstance(s, str): s = repr(s)
+ if (not dist.is_initialized()) or (dist.is_initialized() and dist.get_rank() == 0): print("### " + s)
+
+
+def save_frames(video: Tensor, frames_dir: PathLike, show_progress:bool=True):
+ frames_dir = Path(frames_dir)
+ frames_dir.mkdir(parents=True, exist_ok=True)
+ frames = rearrange(video, "b c t h w -> t b c h w")
+ if show_progress:
+ for idx, frame in enumerate(tqdm(frames, desc=f"Saving frames to {frames_dir.stem}")):
+ save_image(frame, frames_dir.joinpath(f"{idx:08d}.png"))
+ else:
+ for idx, frame in enumerate(frames):
+ save_image(frame, frames_dir.joinpath(f"{idx:08d}.png"))
+
+
+def save_imgs(imgs:List[Image.Image], frames_dir: PathLike):
+ frames_dir = Path(frames_dir)
+ frames_dir.mkdir(parents=True, exist_ok=True)
+ for idx, img in enumerate(tqdm(imgs, desc=f"Saving frames to {frames_dir.stem}")):
+ img.save( frames_dir.joinpath(f"{idx:08d}.png") )
+
+def save_video(video: Tensor, save_path: PathLike, fps: int = 8):
+ save_path = Path(save_path)
+ save_path.parent.mkdir(parents=True, exist_ok=True)
+
+ if video.ndim == 5:
+ # batch, channels, frame, width, height -> frame, channels, width, height
+ frames = video.permute(0, 2, 1, 3, 4).squeeze(0)
+ elif video.ndim == 4:
+ # channels, frame, width, height -> frame, channels, width, height
+ frames = video.permute(1, 0, 2, 3)
+ else:
+ raise ValueError(f"video must be 4 or 5 dimensional, got {video.ndim}")
+
+ # Add 0.5 after unnormalizing to [0, 255] to round to the nearest integer
+ frames = frames.mul(255).add_(0.5).clamp_(0, 255).permute(0, 2, 3, 1).to("cpu", torch.uint8).numpy()
+
+ images = [Image.fromarray(frame) for frame in frames]
+ images[0].save(
+ fp=save_path, format="GIF", append_images=images[1:], save_all=True, duration=(1 / fps * 1000), loop=0
+ )
+
+
+def path_from_cwd(path: PathLike) -> str:
+ path = Path(path)
+ return str(path.absolute().relative_to(Path.cwd()))
+
+
+def resize_for_condition_image(input_image: Image, us_width: int, us_height: int):
+ input_image = input_image.convert("RGB")
+ H = int(round(us_height / 8.0)) * 8
+ W = int(round(us_width / 8.0)) * 8
+ img = input_image.resize((W, H), resample=Image.LANCZOS)
+ return img
+
+def get_resized_images(org_images_path: List[str], us_width: int, us_height: int):
+
+ images = [Image.open( p ) for p in org_images_path]
+
+ W, H = images[0].size
+
+ if us_width == -1:
+ us_width = W/H * us_height
+ elif us_height == -1:
+ us_height = H/W * us_width
+
+ return [resize_for_condition_image(img, us_width, us_height) for img in images]
+
+def get_resized_image(org_image_path: str, us_width: int, us_height: int):
+
+ image = Image.open( org_image_path )
+
+ W, H = image.size
+
+ if us_width == -1:
+ us_width = W/H * us_height
+ elif us_height == -1:
+ us_height = H/W * us_width
+
+ return resize_for_condition_image(image, us_width, us_height)
+
+def get_resized_image2(org_image_path: str, size: int):
+
+ image = Image.open( org_image_path )
+
+ W, H = image.size
+
+ if size < 0:
+ return resize_for_condition_image(image, W, H)
+
+ if W < H:
+ us_width = size
+ us_height = int(size * H/W)
+ else:
+ us_width = int(size * W/H)
+ us_height = size
+
+ return resize_for_condition_image(image, us_width, us_height)
+
+
+def show_bytes(comment, obj):
+
+ import sys
+# memory_size = sys.getsizeof(tensor) + torch.numel(tensor)*tensor.element_size()
+
+ if torch.is_tensor(obj):
+ logger.info(f"{comment} : {obj.dtype=}")
+
+ cpu_mem = sys.getsizeof(obj)/1024/1024
+ cpu_mem = 0 if cpu_mem < 1 else cpu_mem
+ logger.info(f"{comment} : CPU {cpu_mem} MB")
+
+ gpu_mem = torch.numel(obj)*obj.element_size()/1024/1024
+ gpu_mem = 0 if gpu_mem < 1 else gpu_mem
+ logger.info(f"{comment} : GPU {gpu_mem} MB")
+ elif type(obj) is tuple:
+ logger.info(f"{comment} : {type(obj)}")
+ cpu_mem = 0
+ gpu_mem = 0
+
+ for o in obj:
+ cpu_mem += sys.getsizeof(o)/1024/1024
+ gpu_mem += torch.numel(o)*o.element_size()/1024/1024
+
+ cpu_mem = 0 if cpu_mem < 1 else cpu_mem
+ logger.info(f"{comment} : CPU {cpu_mem} MB")
+
+ gpu_mem = 0 if gpu_mem < 1 else gpu_mem
+ logger.info(f"{comment} : GPU {gpu_mem} MB")
+
+ else:
+ logger.info(f"{comment} : unknown type")
+
+
+
+def show_gpu(comment=""):
+ return
+ import inspect
+ callerframerecord = inspect.stack()[1]
+ frame = callerframerecord[0]
+ info = inspect.getframeinfo(frame)
+
+ import time
+
+ import GPUtil
+ torch.cuda.synchronize()
+
+# time.sleep(1.5)
+
+ #logger.info(comment)
+ logger.info(f"{info.filename}/{info.lineno}/{comment}")
+ GPUtil.showUtilization()
+
+
+PROFILE_ON = False
+
+def start_profile():
+ if PROFILE_ON:
+ import cProfile
+
+ pr = cProfile.Profile()
+ pr.enable()
+ return pr
+ else:
+ return None
+
+def end_profile(pr, file_name):
+ if PROFILE_ON:
+ import io
+ import pstats
+
+ pr.disable()
+ s = io.StringIO()
+ ps = pstats.Stats(pr, stream=s).sort_stats('cumtime')
+ ps.print_stats()
+
+ with open(file_name, 'w+') as f:
+ f.write(s.getvalue())
+
+STOPWATCH_ON = False
+
+time_record = []
+start_time = 0
+
+def stopwatch_start():
+ global start_time,time_record
+ import time
+
+ if STOPWATCH_ON:
+ time_record = []
+ torch.cuda.synchronize()
+ start_time = time.time()
+
+def stopwatch_record(comment):
+ import time
+
+ if STOPWATCH_ON:
+ torch.cuda.synchronize()
+ time_record.append(((time.time() - start_time) , comment))
+
+def stopwatch_stop(comment):
+
+ if STOPWATCH_ON:
+ stopwatch_record(comment)
+
+ for rec in time_record:
+ logger.info(rec)
+
+
+def prepare_ip_adapter():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/ip_adapter/models/image_encoder", exist_ok=True)
+ for hub_file in [
+ "models/image_encoder/config.json",
+ "models/image_encoder/pytorch_model.bin",
+ "models/ip-adapter-plus_sd15.bin",
+ "models/ip-adapter_sd15.bin",
+ "models/ip-adapter_sd15_light.bin",
+ "models/ip-adapter-plus-face_sd15.bin",
+ "models/ip-adapter-full-face_sd15.bin",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/ip_adapter" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="h94/IP-Adapter", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/ip_adapter"
+ )
+
+def prepare_ip_adapter_sdxl():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/ip_adapter/sdxl_models/image_encoder", exist_ok=True)
+ for hub_file in [
+ "models/image_encoder/config.json",
+ "models/image_encoder/pytorch_model.bin",
+ "sdxl_models/ip-adapter-plus_sdxl_vit-h.bin",
+ "sdxl_models/ip-adapter-plus-face_sdxl_vit-h.bin",
+ "sdxl_models/ip-adapter_sdxl_vit-h.bin",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/ip_adapter" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="h94/IP-Adapter", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/ip_adapter"
+ )
+
+
+def prepare_lcm_lora():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/lcm_lora/sdxl", exist_ok=True)
+ for hub_file in [
+ "pytorch_lora_weights.safetensors",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/lcm_lora/sdxl" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="latent-consistency/lcm-lora-sdxl", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/lcm_lora/sdxl"
+ )
+
+ os.makedirs("data/models/lcm_lora/sd15", exist_ok=True)
+ for hub_file in [
+ "AnimateLCM_sd15_t2v_lora.safetensors",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/lcm_lora/sd15" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="chaowenguo/AnimateLCM", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/lcm_lora/sd15"
+ )
+
+def prepare_lllite():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/lllite", exist_ok=True)
+ for hub_file in [
+ "bdsqlsz_controlllite_xl_canny.safetensors",
+ "bdsqlsz_controlllite_xl_depth.safetensors",
+ "bdsqlsz_controlllite_xl_dw_openpose.safetensors",
+ "bdsqlsz_controlllite_xl_lineart_anime_denoise.safetensors",
+ "bdsqlsz_controlllite_xl_mlsd_V2.safetensors",
+ "bdsqlsz_controlllite_xl_normal.safetensors",
+ "bdsqlsz_controlllite_xl_recolor_luminance.safetensors",
+ "bdsqlsz_controlllite_xl_segment_animeface_V2.safetensors",
+ "bdsqlsz_controlllite_xl_sketch.safetensors",
+ "bdsqlsz_controlllite_xl_softedge.safetensors",
+ "bdsqlsz_controlllite_xl_t2i-adapter_color_shuffle.safetensors",
+ "bdsqlsz_controlllite_xl_tile_anime_alpha.safetensors", # alpha
+ "bdsqlsz_controlllite_xl_tile_anime_beta.safetensors", # beta
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/lllite" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="bdsqlsz/qinglong_controlnet-lllite", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/lllite"
+ )
+
+
+def prepare_extra_controlnet():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/controlnet/animatediff_controlnet", exist_ok=True)
+ for hub_file in [
+ "controlnet_checkpoint.ckpt"
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/controlnet/animatediff_controlnet" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="crishhh/animatediff_controlnet", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/controlnet/animatediff_controlnet"
+ )
+
+
+def prepare_motion_module():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/motion-module", exist_ok=True)
+ for hub_file in [
+ "AnimateLCM_sd15_t2v.ckpt"
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/motion-module" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="chaowenguo/AnimateLCM", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/motion-module"
+ )
+
+def prepare_wd14tagger():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/WD14tagger", exist_ok=True)
+ for hub_file in [
+ "model.onnx",
+ "selected_tags.csv",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/WD14tagger" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="SmilingWolf/wd-v1-4-moat-tagger-v2", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/WD14tagger"
+ )
+
+def prepare_dwpose():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/DWPose", exist_ok=True)
+ for hub_file in [
+ "dw-ll_ucoco_384.onnx",
+ "yolox_l.onnx",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/DWPose" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="yzd-v/DWPose", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/DWPose"
+ )
+
+
+
+def prepare_softsplat():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/softsplat", exist_ok=True)
+ for hub_file in [
+ "softsplat-lf",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/softsplat" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="s9roll74/softsplat_mirror", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/softsplat"
+ )
+
+
+def extract_frames(movie_file_path, fps, out_dir, aspect_ratio, duration, offset, size_of_short_edge=-1, low_vram_mode=False):
+ import ffmpeg
+
+ probe = ffmpeg.probe(movie_file_path)
+ video = next((stream for stream in probe['streams'] if stream['codec_type'] == 'video'), None)
+ width = int(video['width'])
+ height = int(video['height'])
+
+ node = ffmpeg.input( str(movie_file_path.resolve()) )
+
+ node = node.filter( "fps", fps=fps )
+
+
+ if duration > 0:
+ node = node.trim(start=offset,end=offset+duration).setpts('PTS-STARTPTS')
+ elif offset > 0:
+ node = node.trim(start=offset).setpts('PTS-STARTPTS')
+
+ if size_of_short_edge != -1:
+ if width < height:
+ r = height / width
+ width = size_of_short_edge
+ height = int( (size_of_short_edge * r)//8 * 8)
+ node = node.filter('scale', size_of_short_edge, height)
+ else:
+ r = width / height
+ height = size_of_short_edge
+ width = int( (size_of_short_edge * r)//8 * 8)
+ node = node.filter('scale', width, size_of_short_edge)
+
+ if low_vram_mode:
+ if aspect_ratio == -1:
+ aspect_ratio = width/height
+ logger.info(f"low {aspect_ratio=}")
+ aspect_ratio = max(min( aspect_ratio, 1.5 ), 0.6666)
+ logger.info(f"low {aspect_ratio=}")
+
+ if aspect_ratio > 0:
+ # aspect ratio (width / height)
+ ww = round(height * aspect_ratio)
+ if ww < width:
+ x= (width - ww)//2
+ y= 0
+ w = ww
+ h = height
+ else:
+ hh = round(width/aspect_ratio)
+ x = 0
+ y = (height - hh)//2
+ w = width
+ h = hh
+ w = int(w // 8 * 8)
+ h = int(h // 8 * 8)
+ logger.info(f"crop to {w=},{h=}")
+ node = node.crop(x, y, w, h)
+
+ node = node.output( str(out_dir.resolve().joinpath("%08d.png")), start_number=0 )
+
+ node.run(quiet=True, overwrite_output=True)
+
+
+
+
+
+
+def is_v2_motion_module(motion_module_path:Path):
+ if motion_module_path.suffix == ".safetensors":
+ from safetensors.torch import load_file
+ loaded = load_file(motion_module_path, "cpu")
+ else:
+ from torch import load
+ loaded = load(motion_module_path, "cpu")
+
+ is_v2 = "mid_block.motion_modules.0.temporal_transformer.norm.bias" in loaded
+
+ loaded = None
+ torch.cuda.empty_cache()
+
+ logger.info(f"{is_v2=}")
+
+ return is_v2
+
+def is_sdxl_checkpoint(checkpoint_path:Path):
+ if checkpoint_path.suffix == ".safetensors":
+ from safetensors.torch import load_file
+ loaded = load_file(checkpoint_path, "cpu")
+ else:
+ from torch import load
+ loaded = load(checkpoint_path, "cpu")
+
+ is_sdxl = False
+
+ if "conditioner.embedders.1.model.ln_final.weight" in loaded:
+ is_sdxl = True
+ if "conditioner.embedders.0.model.ln_final.weight" in loaded:
+ is_sdxl = True
+
+ loaded = None
+ torch.cuda.empty_cache()
+
+ logger.info(f"{is_sdxl=}")
+ return is_sdxl
+
+
+tensor_interpolation = None
+
+def get_tensor_interpolation_method():
+ return tensor_interpolation
+
+def set_tensor_interpolation_method(is_slerp):
+ global tensor_interpolation
+ tensor_interpolation = slerp if is_slerp else linear
+
+def linear(v1, v2, t):
+ return (1.0 - t) * v1 + t * v2
+
+def slerp(
+ v0: torch.Tensor, v1: torch.Tensor, t: float, DOT_THRESHOLD: float = 0.9995
+) -> torch.Tensor:
+ u0 = v0 / v0.norm()
+ u1 = v1 / v1.norm()
+ dot = (u0 * u1).sum()
+ if dot.abs() > DOT_THRESHOLD:
+ #logger.info(f'warning: v0 and v1 close to parallel, using linear interpolation instead.')
+ return (1.0 - t) * v0 + t * v1
+ omega = dot.acos()
+ return (((1.0 - t) * omega).sin() * v0 + (t * omega).sin() * v1) / omega.sin()
+
+
+
+def prepare_sam_hq(low_vram):
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/SAM", exist_ok=True)
+ for hub_file in [
+ "sam_hq_vit_h.pth" if not low_vram else "sam_hq_vit_b.pth"
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/SAM" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="lkeab/hq-sam", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/SAM"
+ )
+
+def prepare_groundingDINO():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/GroundingDINO", exist_ok=True)
+ for hub_file in [
+ "groundingdino_swinb_cogcoor.pth",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/GroundingDINO" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="ShilongLiu/GroundingDINO", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/GroundingDINO"
+ )
+
+
+def prepare_propainter():
+ import os
+
+ import git
+
+ if os.path.isdir("src/animatediff/repo/ProPainter"):
+ if os.listdir("src/animatediff/repo/ProPainter"):
+ return
+
+ repo = git.Repo.clone_from(url="https://github.com/sczhou/ProPainter", to_path="src/animatediff/repo/ProPainter", no_checkout=True )
+ repo.git.checkout("a8a5827ca5e7e8c1b4c360ea77cbb2adb3c18370")
+
+
+def prepare_anime_seg():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/anime_seg", exist_ok=True)
+ for hub_file in [
+ "isnetis.onnx",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/anime_seg" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="skytnt/anime-seg", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/anime_seg"
+ )
diff --git a/animate/src/animatediff/utils/wild_card.py b/animate/src/animatediff/utils/wild_card.py
new file mode 100644
index 0000000000000000000000000000000000000000..6e4ef1a75a8741437674409ebff80a60565e6ab4
--- /dev/null
+++ b/animate/src/animatediff/utils/wild_card.py
@@ -0,0 +1,39 @@
+import glob
+import os
+import random
+import re
+
+wild_card_regex = r'(\A|\W)__([\w-]+)__(\W|\Z)'
+
+
+def create_wild_card_map(wild_card_dir):
+ result = {}
+ if os.path.isdir(wild_card_dir):
+ txt_list = glob.glob( os.path.join(wild_card_dir ,"**/*.txt"), recursive=True)
+ for txt in txt_list:
+ basename_without_ext = os.path.splitext(os.path.basename(txt))[0]
+ with open(txt, encoding='utf-8') as f:
+ try:
+ result[basename_without_ext] = [s.rstrip() for s in f.readlines()]
+ except Exception as e:
+ print(e)
+ print("can not read ", txt)
+ return result
+
+def replace_wild_card_token(match_obj, wild_card_map):
+ m1 = match_obj.group(1)
+ m3 = match_obj.group(3)
+
+ dict_name = match_obj.group(2)
+
+ if dict_name in wild_card_map:
+ token_list = wild_card_map[dict_name]
+ token = token_list[random.randint(0,len(token_list)-1)]
+ return m1+token+m3
+ else:
+ return match_obj.group(0)
+
+def replace_wild_card(prompt, wild_card_dir):
+ wild_card_map = create_wild_card_map(wild_card_dir)
+ prompt = re.sub(wild_card_regex, lambda x: replace_wild_card_token(x, wild_card_map ), prompt)
+ return prompt
diff --git a/animate/stylize/.gitignore b/animate/stylize/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d
--- /dev/null
+++ b/animate/stylize/.gitignore
@@ -0,0 +1,2 @@
+*
+!.gitignore
diff --git a/animate/upscaled/.gitignore b/animate/upscaled/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d
--- /dev/null
+++ b/animate/upscaled/.gitignore
@@ -0,0 +1,2 @@
+*
+!.gitignore
diff --git a/animate/wildcards/.gitignore b/animate/wildcards/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d
--- /dev/null
+++ b/animate/wildcards/.gitignore
@@ -0,0 +1,2 @@
+*
+!.gitignore
+
+## license
+The provided implementation is strictly for academic purposes only. Should you be interested in using our technology for any commercial use, please feel free to contact us.
+
+## references
+```
+[1] @inproceedings{Niklaus_CVPR_2020,
+ author = {Simon Niklaus and Feng Liu},
+ title = {Softmax Splatting for Video Frame Interpolation},
+ booktitle = {IEEE Conference on Computer Vision and Pattern Recognition},
+ year = {2020}
+ }
+```
+
+## acknowledgment
+The video above uses materials under a Creative Common license as detailed at the end.
\ No newline at end of file
diff --git a/animate/src/animatediff/softmax_splatting/correlation/README.md b/animate/src/animatediff/softmax_splatting/correlation/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a8e0ca529d50b7e09d521cc288daae7771514188
--- /dev/null
+++ b/animate/src/animatediff/softmax_splatting/correlation/README.md
@@ -0,0 +1 @@
+This is an adaptation of the FlowNet2 implementation in order to compute cost volumes. Should you be making use of this work, please make sure to adhere to the licensing terms of the original authors. Should you be making use or modify this particular implementation, please acknowledge it appropriately.
\ No newline at end of file
diff --git a/animate/src/animatediff/softmax_splatting/correlation/correlation.py b/animate/src/animatediff/softmax_splatting/correlation/correlation.py
new file mode 100644
index 0000000000000000000000000000000000000000..5b560d41d55655945d0cf7a81de39c8d2678f0e1
--- /dev/null
+++ b/animate/src/animatediff/softmax_splatting/correlation/correlation.py
@@ -0,0 +1,395 @@
+#!/usr/bin/env python
+
+import cupy
+import re
+import torch
+
+kernel_Correlation_rearrange = '''
+ extern "C" __global__ void kernel_Correlation_rearrange(
+ const int n,
+ const float* input,
+ float* output
+ ) {
+ int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x;
+
+ if (intIndex >= n) {
+ return;
+ }
+
+ int intSample = blockIdx.z;
+ int intChannel = blockIdx.y;
+
+ float fltValue = input[(((intSample * SIZE_1(input)) + intChannel) * SIZE_2(input) * SIZE_3(input)) + intIndex];
+
+ __syncthreads();
+
+ int intPaddedY = (intIndex / SIZE_3(input)) + 4;
+ int intPaddedX = (intIndex % SIZE_3(input)) + 4;
+ int intRearrange = ((SIZE_3(input) + 8) * intPaddedY) + intPaddedX;
+
+ output[(((intSample * SIZE_1(output) * SIZE_2(output)) + intRearrange) * SIZE_1(input)) + intChannel] = fltValue;
+ }
+'''
+
+kernel_Correlation_updateOutput = '''
+ extern "C" __global__ void kernel_Correlation_updateOutput(
+ const int n,
+ const float* rbot0,
+ const float* rbot1,
+ float* top
+ ) {
+ extern __shared__ char patch_data_char[];
+
+ float *patch_data = (float *)patch_data_char;
+
+ // First (upper left) position of kernel upper-left corner in current center position of neighborhood in image 1
+ int x1 = blockIdx.x + 4;
+ int y1 = blockIdx.y + 4;
+ int item = blockIdx.z;
+ int ch_off = threadIdx.x;
+
+ // Load 3D patch into shared shared memory
+ for (int j = 0; j < 1; j++) { // HEIGHT
+ for (int i = 0; i < 1; i++) { // WIDTH
+ int ji_off = (j + i) * SIZE_3(rbot0);
+ for (int ch = ch_off; ch < SIZE_3(rbot0); ch += 32) { // CHANNELS
+ int idx1 = ((item * SIZE_1(rbot0) + y1+j) * SIZE_2(rbot0) + x1+i) * SIZE_3(rbot0) + ch;
+ int idxPatchData = ji_off + ch;
+ patch_data[idxPatchData] = rbot0[idx1];
+ }
+ }
+ }
+
+ __syncthreads();
+
+ __shared__ float sum[32];
+
+ // Compute correlation
+ for (int top_channel = 0; top_channel < SIZE_1(top); top_channel++) {
+ sum[ch_off] = 0;
+
+ int s2o = top_channel % 9 - 4;
+ int s2p = top_channel / 9 - 4;
+
+ for (int j = 0; j < 1; j++) { // HEIGHT
+ for (int i = 0; i < 1; i++) { // WIDTH
+ int ji_off = (j + i) * SIZE_3(rbot0);
+ for (int ch = ch_off; ch < SIZE_3(rbot0); ch += 32) { // CHANNELS
+ int x2 = x1 + s2o;
+ int y2 = y1 + s2p;
+
+ int idxPatchData = ji_off + ch;
+ int idx2 = ((item * SIZE_1(rbot0) + y2+j) * SIZE_2(rbot0) + x2+i) * SIZE_3(rbot0) + ch;
+
+ sum[ch_off] += patch_data[idxPatchData] * rbot1[idx2];
+ }
+ }
+ }
+
+ __syncthreads();
+
+ if (ch_off == 0) {
+ float total_sum = 0;
+ for (int idx = 0; idx < 32; idx++) {
+ total_sum += sum[idx];
+ }
+ const int sumelems = SIZE_3(rbot0);
+ const int index = ((top_channel*SIZE_2(top) + blockIdx.y)*SIZE_3(top))+blockIdx.x;
+ top[index + item*SIZE_1(top)*SIZE_2(top)*SIZE_3(top)] = total_sum / (float)sumelems;
+ }
+ }
+ }
+'''
+
+kernel_Correlation_updateGradOne = '''
+ #define ROUND_OFF 50000
+
+ extern "C" __global__ void kernel_Correlation_updateGradOne(
+ const int n,
+ const int intSample,
+ const float* rbot0,
+ const float* rbot1,
+ const float* gradOutput,
+ float* gradOne,
+ float* gradTwo
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ int n = intIndex % SIZE_1(gradOne); // channels
+ int l = (intIndex / SIZE_1(gradOne)) % SIZE_3(gradOne) + 4; // w-pos
+ int m = (intIndex / SIZE_1(gradOne) / SIZE_3(gradOne)) % SIZE_2(gradOne) + 4; // h-pos
+
+ // round_off is a trick to enable integer division with ceil, even for negative numbers
+ // We use a large offset, for the inner part not to become negative.
+ const int round_off = ROUND_OFF;
+ const int round_off_s1 = round_off;
+
+ // We add round_off before_s1 the int division and subtract round_off after it, to ensure the formula matches ceil behavior:
+ int xmin = (l - 4 + round_off_s1 - 1) + 1 - round_off; // ceil (l - 4)
+ int ymin = (m - 4 + round_off_s1 - 1) + 1 - round_off; // ceil (l - 4)
+
+ // Same here:
+ int xmax = (l - 4 + round_off_s1) - round_off; // floor (l - 4)
+ int ymax = (m - 4 + round_off_s1) - round_off; // floor (m - 4)
+
+ float sum = 0;
+ if (xmax>=0 && ymax>=0 && (xmin<=SIZE_3(gradOutput)-1) && (ymin<=SIZE_2(gradOutput)-1)) {
+ xmin = max(0,xmin);
+ xmax = min(SIZE_3(gradOutput)-1,xmax);
+
+ ymin = max(0,ymin);
+ ymax = min(SIZE_2(gradOutput)-1,ymax);
+
+ for (int p = -4; p <= 4; p++) {
+ for (int o = -4; o <= 4; o++) {
+ // Get rbot1 data:
+ int s2o = o;
+ int s2p = p;
+ int idxbot1 = ((intSample * SIZE_1(rbot0) + (m+s2p)) * SIZE_2(rbot0) + (l+s2o)) * SIZE_3(rbot0) + n;
+ float bot1tmp = rbot1[idxbot1]; // rbot1[l+s2o,m+s2p,n]
+
+ // Index offset for gradOutput in following loops:
+ int op = (p+4) * 9 + (o+4); // index[o,p]
+ int idxopoffset = (intSample * SIZE_1(gradOutput) + op);
+
+ for (int y = ymin; y <= ymax; y++) {
+ for (int x = xmin; x <= xmax; x++) {
+ int idxgradOutput = (idxopoffset * SIZE_2(gradOutput) + y) * SIZE_3(gradOutput) + x; // gradOutput[x,y,o,p]
+ sum += gradOutput[idxgradOutput] * bot1tmp;
+ }
+ }
+ }
+ }
+ }
+ const int sumelems = SIZE_1(gradOne);
+ const int bot0index = ((n * SIZE_2(gradOne)) + (m-4)) * SIZE_3(gradOne) + (l-4);
+ gradOne[bot0index + intSample*SIZE_1(gradOne)*SIZE_2(gradOne)*SIZE_3(gradOne)] = sum / (float)sumelems;
+ } }
+'''
+
+kernel_Correlation_updateGradTwo = '''
+ #define ROUND_OFF 50000
+
+ extern "C" __global__ void kernel_Correlation_updateGradTwo(
+ const int n,
+ const int intSample,
+ const float* rbot0,
+ const float* rbot1,
+ const float* gradOutput,
+ float* gradOne,
+ float* gradTwo
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ int n = intIndex % SIZE_1(gradTwo); // channels
+ int l = (intIndex / SIZE_1(gradTwo)) % SIZE_3(gradTwo) + 4; // w-pos
+ int m = (intIndex / SIZE_1(gradTwo) / SIZE_3(gradTwo)) % SIZE_2(gradTwo) + 4; // h-pos
+
+ // round_off is a trick to enable integer division with ceil, even for negative numbers
+ // We use a large offset, for the inner part not to become negative.
+ const int round_off = ROUND_OFF;
+ const int round_off_s1 = round_off;
+
+ float sum = 0;
+ for (int p = -4; p <= 4; p++) {
+ for (int o = -4; o <= 4; o++) {
+ int s2o = o;
+ int s2p = p;
+
+ //Get X,Y ranges and clamp
+ // We add round_off before_s1 the int division and subtract round_off after it, to ensure the formula matches ceil behavior:
+ int xmin = (l - 4 - s2o + round_off_s1 - 1) + 1 - round_off; // ceil (l - 4 - s2o)
+ int ymin = (m - 4 - s2p + round_off_s1 - 1) + 1 - round_off; // ceil (l - 4 - s2o)
+
+ // Same here:
+ int xmax = (l - 4 - s2o + round_off_s1) - round_off; // floor (l - 4 - s2o)
+ int ymax = (m - 4 - s2p + round_off_s1) - round_off; // floor (m - 4 - s2p)
+
+ if (xmax>=0 && ymax>=0 && (xmin<=SIZE_3(gradOutput)-1) && (ymin<=SIZE_2(gradOutput)-1)) {
+ xmin = max(0,xmin);
+ xmax = min(SIZE_3(gradOutput)-1,xmax);
+
+ ymin = max(0,ymin);
+ ymax = min(SIZE_2(gradOutput)-1,ymax);
+
+ // Get rbot0 data:
+ int idxbot0 = ((intSample * SIZE_1(rbot0) + (m-s2p)) * SIZE_2(rbot0) + (l-s2o)) * SIZE_3(rbot0) + n;
+ float bot0tmp = rbot0[idxbot0]; // rbot1[l+s2o,m+s2p,n]
+
+ // Index offset for gradOutput in following loops:
+ int op = (p+4) * 9 + (o+4); // index[o,p]
+ int idxopoffset = (intSample * SIZE_1(gradOutput) + op);
+
+ for (int y = ymin; y <= ymax; y++) {
+ for (int x = xmin; x <= xmax; x++) {
+ int idxgradOutput = (idxopoffset * SIZE_2(gradOutput) + y) * SIZE_3(gradOutput) + x; // gradOutput[x,y,o,p]
+ sum += gradOutput[idxgradOutput] * bot0tmp;
+ }
+ }
+ }
+ }
+ }
+ const int sumelems = SIZE_1(gradTwo);
+ const int bot1index = ((n * SIZE_2(gradTwo)) + (m-4)) * SIZE_3(gradTwo) + (l-4);
+ gradTwo[bot1index + intSample*SIZE_1(gradTwo)*SIZE_2(gradTwo)*SIZE_3(gradTwo)] = sum / (float)sumelems;
+ } }
+'''
+
+def cupy_kernel(strFunction, objVariables):
+ strKernel = globals()[strFunction]
+
+ while True:
+ objMatch = re.search('(SIZE_)([0-4])(\()([^\)]*)(\))', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intArg = int(objMatch.group(2))
+
+ strTensor = objMatch.group(4)
+ intSizes = objVariables[strTensor].size()
+
+ strKernel = strKernel.replace(objMatch.group(), str(intSizes[intArg] if torch.is_tensor(intSizes[intArg]) == False else intSizes[intArg].item()))
+
+ while True:
+ objMatch = re.search('(VALUE_)([0-4])(\()([^\)]+)(\))', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intArgs = int(objMatch.group(2))
+ strArgs = objMatch.group(4).split(',')
+
+ strTensor = strArgs[0]
+ intStrides = objVariables[strTensor].stride()
+ strIndex = [ '((' + strArgs[intArg + 1].replace('{', '(').replace('}', ')').strip() + ')*' + str(intStrides[intArg] if torch.is_tensor(intStrides[intArg]) == False else intStrides[intArg].item()) + ')' for intArg in range(intArgs) ]
+
+ strKernel = strKernel.replace(objMatch.group(0), strTensor + '[' + str.join('+', strIndex) + ']')
+ # end
+
+ return strKernel
+# end
+
+@cupy.memoize(for_each_device=True)
+def cupy_launch(strFunction, strKernel):
+ return cupy.cuda.compile_with_cache(strKernel).get_function(strFunction)
+# end
+
+class _FunctionCorrelation(torch.autograd.Function):
+ @staticmethod
+ def forward(self, one, two):
+ rbot0 = one.new_zeros([ one.shape[0], one.shape[2] + 8, one.shape[3] + 8, one.shape[1] ])
+ rbot1 = one.new_zeros([ one.shape[0], one.shape[2] + 8, one.shape[3] + 8, one.shape[1] ])
+
+ one = one.contiguous(); assert(one.is_cuda == True)
+ two = two.contiguous(); assert(two.is_cuda == True)
+
+ output = one.new_zeros([ one.shape[0], 81, one.shape[2], one.shape[3] ])
+
+ if one.is_cuda == True:
+ n = one.shape[2] * one.shape[3]
+ cupy_launch('kernel_Correlation_rearrange', cupy_kernel('kernel_Correlation_rearrange', {
+ 'input': one,
+ 'output': rbot0
+ }))(
+ grid=tuple([ int((n + 16 - 1) / 16), one.shape[1], one.shape[0] ]),
+ block=tuple([ 16, 1, 1 ]),
+ args=[ cupy.int32(n), one.data_ptr(), rbot0.data_ptr() ]
+ )
+
+ n = two.shape[2] * two.shape[3]
+ cupy_launch('kernel_Correlation_rearrange', cupy_kernel('kernel_Correlation_rearrange', {
+ 'input': two,
+ 'output': rbot1
+ }))(
+ grid=tuple([ int((n + 16 - 1) / 16), two.shape[1], two.shape[0] ]),
+ block=tuple([ 16, 1, 1 ]),
+ args=[ cupy.int32(n), two.data_ptr(), rbot1.data_ptr() ]
+ )
+
+ n = output.shape[1] * output.shape[2] * output.shape[3]
+ cupy_launch('kernel_Correlation_updateOutput', cupy_kernel('kernel_Correlation_updateOutput', {
+ 'rbot0': rbot0,
+ 'rbot1': rbot1,
+ 'top': output
+ }))(
+ grid=tuple([ output.shape[3], output.shape[2], output.shape[0] ]),
+ block=tuple([ 32, 1, 1 ]),
+ shared_mem=one.shape[1] * 4,
+ args=[ cupy.int32(n), rbot0.data_ptr(), rbot1.data_ptr(), output.data_ptr() ]
+ )
+
+ elif one.is_cuda == False:
+ raise NotImplementedError()
+
+ # end
+
+ self.save_for_backward(one, two, rbot0, rbot1)
+
+ return output
+ # end
+
+ @staticmethod
+ def backward(self, gradOutput):
+ one, two, rbot0, rbot1 = self.saved_tensors
+
+ gradOutput = gradOutput.contiguous(); assert(gradOutput.is_cuda == True)
+
+ gradOne = one.new_zeros([ one.shape[0], one.shape[1], one.shape[2], one.shape[3] ]) if self.needs_input_grad[0] == True else None
+ gradTwo = one.new_zeros([ one.shape[0], one.shape[1], one.shape[2], one.shape[3] ]) if self.needs_input_grad[1] == True else None
+
+ if one.is_cuda == True:
+ if gradOne is not None:
+ for intSample in range(one.shape[0]):
+ n = one.shape[1] * one.shape[2] * one.shape[3]
+ cupy_launch('kernel_Correlation_updateGradOne', cupy_kernel('kernel_Correlation_updateGradOne', {
+ 'rbot0': rbot0,
+ 'rbot1': rbot1,
+ 'gradOutput': gradOutput,
+ 'gradOne': gradOne,
+ 'gradTwo': None
+ }))(
+ grid=tuple([ int((n + 512 - 1) / 512), 1, 1 ]),
+ block=tuple([ 512, 1, 1 ]),
+ args=[ cupy.int32(n), intSample, rbot0.data_ptr(), rbot1.data_ptr(), gradOutput.data_ptr(), gradOne.data_ptr(), None ]
+ )
+ # end
+ # end
+
+ if gradTwo is not None:
+ for intSample in range(one.shape[0]):
+ n = one.shape[1] * one.shape[2] * one.shape[3]
+ cupy_launch('kernel_Correlation_updateGradTwo', cupy_kernel('kernel_Correlation_updateGradTwo', {
+ 'rbot0': rbot0,
+ 'rbot1': rbot1,
+ 'gradOutput': gradOutput,
+ 'gradOne': None,
+ 'gradTwo': gradTwo
+ }))(
+ grid=tuple([ int((n + 512 - 1) / 512), 1, 1 ]),
+ block=tuple([ 512, 1, 1 ]),
+ args=[ cupy.int32(n), intSample, rbot0.data_ptr(), rbot1.data_ptr(), gradOutput.data_ptr(), None, gradTwo.data_ptr() ]
+ )
+ # end
+ # end
+
+ elif one.is_cuda == False:
+ raise NotImplementedError()
+
+ # end
+
+ return gradOne, gradTwo
+ # end
+# end
+
+def FunctionCorrelation(tenOne, tenTwo):
+ return _FunctionCorrelation.apply(tenOne, tenTwo)
+# end
+
+class ModuleCorrelation(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ # end
+
+ def forward(self, tenOne, tenTwo):
+ return _FunctionCorrelation.apply(tenOne, tenTwo)
+ # end
+# end
diff --git a/animate/src/animatediff/softmax_splatting/run.py b/animate/src/animatediff/softmax_splatting/run.py
new file mode 100644
index 0000000000000000000000000000000000000000..22313f889dabafb31c675f199029713332751952
--- /dev/null
+++ b/animate/src/animatediff/softmax_splatting/run.py
@@ -0,0 +1,871 @@
+#!/usr/bin/env python
+
+import getopt
+import math
+import sys
+import typing
+
+import numpy
+import PIL
+import PIL.Image
+import torch
+
+from . import softsplat # the custom softmax splatting layer
+
+try:
+ from .correlation import correlation # the custom cost volume layer
+except:
+ sys.path.insert(0, './correlation'); import correlation # you should consider upgrading python
+# end
+
+##########################################################
+
+torch.set_grad_enabled(False) # make sure to not compute gradients for computational performance
+
+torch.backends.cudnn.enabled = True # make sure to use cudnn for computational performance
+
+##########################################################
+
+arguments_strModel = 'lf'
+arguments_strOne = './images/one.png'
+arguments_strTwo = './images/two.png'
+arguments_strVideo = './videos/car-turn.mp4'
+arguments_strOut = './out.png'
+arguments_strVideo2 = ''
+
+for strOption, strArgument in getopt.getopt(sys.argv[1:], '', [strParameter[2:] + '=' for strParameter in sys.argv[1::2]])[0]:
+ if strOption == '--model' and strArgument != '': arguments_strModel = strArgument # which model to use
+ if strOption == '--one' and strArgument != '': arguments_strOne = strArgument # path to the first frame
+ if strOption == '--two' and strArgument != '': arguments_strTwo = strArgument # path to the second frame
+ if strOption == '--video' and strArgument != '': arguments_strVideo = strArgument # path to a video
+ if strOption == '--video2' and strArgument != '': arguments_strVideo2 = strArgument # path to a video
+ if strOption == '--out' and strArgument != '': arguments_strOut = strArgument # path to where the output should be stored
+# end
+
+##########################################################
+
+def read_flo(strFile):
+ with open(strFile, 'rb') as objFile:
+ strFlow = objFile.read()
+ # end
+
+ assert(numpy.frombuffer(buffer=strFlow, dtype=numpy.float32, count=1, offset=0) == 202021.25)
+
+ intWidth = numpy.frombuffer(buffer=strFlow, dtype=numpy.int32, count=1, offset=4)[0]
+ intHeight = numpy.frombuffer(buffer=strFlow, dtype=numpy.int32, count=1, offset=8)[0]
+
+ return numpy.frombuffer(buffer=strFlow, dtype=numpy.float32, count=intHeight * intWidth * 2, offset=12).reshape(intHeight, intWidth, 2)
+# end
+
+##########################################################
+
+backwarp_tenGrid = {}
+
+def backwarp(tenIn, tenFlow):
+ if str(tenFlow.shape) not in backwarp_tenGrid:
+ tenHor = torch.linspace(start=-1.0, end=1.0, steps=tenFlow.shape[3], dtype=tenFlow.dtype, device=tenFlow.device).view(1, 1, 1, -1).repeat(1, 1, tenFlow.shape[2], 1)
+ tenVer = torch.linspace(start=-1.0, end=1.0, steps=tenFlow.shape[2], dtype=tenFlow.dtype, device=tenFlow.device).view(1, 1, -1, 1).repeat(1, 1, 1, tenFlow.shape[3])
+
+ backwarp_tenGrid[str(tenFlow.shape)] = torch.cat([tenHor, tenVer], 1).cuda()
+ # end
+
+ tenFlow = torch.cat([tenFlow[:, 0:1, :, :] / ((tenIn.shape[3] - 1.0) / 2.0), tenFlow[:, 1:2, :, :] / ((tenIn.shape[2] - 1.0) / 2.0)], 1)
+
+ return torch.nn.functional.grid_sample(input=tenIn, grid=(backwarp_tenGrid[str(tenFlow.shape)] + tenFlow).permute(0, 2, 3, 1), mode='bilinear', padding_mode='zeros', align_corners=True)
+# end
+
+##########################################################
+
+class Flow(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ class Extractor(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netFirst = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=16, out_channels=16, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netSecond = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netThird = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netFourth = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=64, out_channels=96, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=96, out_channels=96, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netFifth = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=96, out_channels=128, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netSixth = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=128, out_channels=192, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=192, out_channels=192, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+ # end
+
+ def forward(self, tenInput):
+ tenFirst = self.netFirst(tenInput)
+ tenSecond = self.netSecond(tenFirst)
+ tenThird = self.netThird(tenSecond)
+ tenFourth = self.netFourth(tenThird)
+ tenFifth = self.netFifth(tenFourth)
+ tenSixth = self.netSixth(tenFifth)
+
+ return [tenFirst, tenSecond, tenThird, tenFourth, tenFifth, tenSixth]
+ # end
+ # end
+
+ class Decoder(torch.nn.Module):
+ def __init__(self, intChannels):
+ super().__init__()
+
+ self.netMain = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=intChannels, out_channels=128, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=128, out_channels=96, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=96, out_channels=64, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=64, out_channels=32, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=32, out_channels=2, kernel_size=3, stride=1, padding=1)
+ )
+ # end
+
+ def forward(self, tenOne, tenTwo, objPrevious):
+ intWidth = tenOne.shape[3] and tenTwo.shape[3]
+ intHeight = tenOne.shape[2] and tenTwo.shape[2]
+
+ tenMain = None
+
+ if objPrevious is None:
+ tenVolume = correlation.FunctionCorrelation(tenOne=tenOne, tenTwo=tenTwo)
+
+ tenMain = torch.cat([tenOne, tenVolume], 1)
+
+ elif objPrevious is not None:
+ tenForward = torch.nn.functional.interpolate(input=objPrevious['tenForward'], size=(intHeight, intWidth), mode='bilinear', align_corners=False) / float(objPrevious['tenForward'].shape[3]) * float(intWidth)
+
+ tenVolume = correlation.FunctionCorrelation(tenOne=tenOne, tenTwo=backwarp(tenTwo, tenForward))
+
+ tenMain = torch.cat([tenOne, tenVolume, tenForward], 1)
+
+ # end
+
+ return {
+ 'tenForward': self.netMain(tenMain)
+ }
+ # end
+ # end
+
+ self.netExtractor = Extractor()
+
+ self.netFirst = Decoder(16 + 81 + 2)
+ self.netSecond = Decoder(32 + 81 + 2)
+ self.netThird = Decoder(64 + 81 + 2)
+ self.netFourth = Decoder(96 + 81 + 2)
+ self.netFifth = Decoder(128 + 81 + 2)
+ self.netSixth = Decoder(192 + 81)
+ # end
+
+ def forward(self, tenOne, tenTwo):
+ intWidth = tenOne.shape[3] and tenTwo.shape[3]
+ intHeight = tenOne.shape[2] and tenTwo.shape[2]
+
+ tenOne = self.netExtractor(tenOne)
+ tenTwo = self.netExtractor(tenTwo)
+
+ objForward = None
+ objBackward = None
+
+ objForward = self.netSixth(tenOne[-1], tenTwo[-1], objForward)
+ objBackward = self.netSixth(tenTwo[-1], tenOne[-1], objBackward)
+
+ objForward = self.netFifth(tenOne[-2], tenTwo[-2], objForward)
+ objBackward = self.netFifth(tenTwo[-2], tenOne[-2], objBackward)
+
+ objForward = self.netFourth(tenOne[-3], tenTwo[-3], objForward)
+ objBackward = self.netFourth(tenTwo[-3], tenOne[-3], objBackward)
+
+ objForward = self.netThird(tenOne[-4], tenTwo[-4], objForward)
+ objBackward = self.netThird(tenTwo[-4], tenOne[-4], objBackward)
+
+ objForward = self.netSecond(tenOne[-5], tenTwo[-5], objForward)
+ objBackward = self.netSecond(tenTwo[-5], tenOne[-5], objBackward)
+
+ objForward = self.netFirst(tenOne[-6], tenTwo[-6], objForward)
+ objBackward = self.netFirst(tenTwo[-6], tenOne[-6], objBackward)
+
+ return {
+ 'tenForward': torch.nn.functional.interpolate(input=objForward['tenForward'], size=(intHeight, intWidth), mode='bilinear', align_corners=False) * (float(intWidth) / float(objForward['tenForward'].shape[3])),
+ 'tenBackward': torch.nn.functional.interpolate(input=objBackward['tenForward'], size=(intHeight, intWidth), mode='bilinear', align_corners=False) * (float(intWidth) / float(objBackward['tenForward'].shape[3]))
+ }
+ # end
+# end
+
+##########################################################
+
+class Synthesis(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ class Basic(torch.nn.Module):
+ def __init__(self, strType, intChannels, boolSkip):
+ super().__init__()
+
+ if strType == 'relu-conv-relu-conv':
+ self.netMain = torch.nn.Sequential(
+ torch.nn.PReLU(num_parameters=intChannels[0], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[1], kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=intChannels[1], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[1], out_channels=intChannels[2], kernel_size=3, stride=1, padding=1, bias=False)
+ )
+
+ elif strType == 'conv-relu-conv':
+ self.netMain = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[1], kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=intChannels[1], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[1], out_channels=intChannels[2], kernel_size=3, stride=1, padding=1, bias=False)
+ )
+
+ # end
+
+ self.boolSkip = boolSkip
+
+ if boolSkip == True:
+ if intChannels[0] == intChannels[2]:
+ self.netShortcut = None
+
+ elif intChannels[0] != intChannels[2]:
+ self.netShortcut = torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[2], kernel_size=1, stride=1, padding=0, bias=False)
+
+ # end
+ # end
+ # end
+
+ def forward(self, tenInput):
+ if self.boolSkip == False:
+ return self.netMain(tenInput)
+ # end
+
+ if self.netShortcut is None:
+ return self.netMain(tenInput) + tenInput
+
+ elif self.netShortcut is not None:
+ return self.netMain(tenInput) + self.netShortcut(tenInput)
+
+ # end
+ # end
+ # end
+
+ class Downsample(torch.nn.Module):
+ def __init__(self, intChannels):
+ super().__init__()
+
+ self.netMain = torch.nn.Sequential(
+ torch.nn.PReLU(num_parameters=intChannels[0], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[1], kernel_size=3, stride=2, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=intChannels[1], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[1], out_channels=intChannels[2], kernel_size=3, stride=1, padding=1, bias=False)
+ )
+ # end
+
+ def forward(self, tenInput):
+ return self.netMain(tenInput)
+ # end
+ # end
+
+ class Upsample(torch.nn.Module):
+ def __init__(self, intChannels):
+ super().__init__()
+
+ self.netMain = torch.nn.Sequential(
+ torch.nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False),
+ torch.nn.PReLU(num_parameters=intChannels[0], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[1], kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=intChannels[1], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[1], out_channels=intChannels[2], kernel_size=3, stride=1, padding=1, bias=False)
+ )
+ # end
+
+ def forward(self, tenInput):
+ return self.netMain(tenInput)
+ # end
+ # end
+
+ class Encode(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netOne = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=32, init=0.25),
+ torch.nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=32, init=0.25)
+ )
+
+ self.netTwo = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=64, init=0.25),
+ torch.nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=64, init=0.25)
+ )
+
+ self.netThr = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=64, out_channels=96, kernel_size=3, stride=2, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=96, init=0.25),
+ torch.nn.Conv2d(in_channels=96, out_channels=96, kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=96, init=0.25)
+ )
+ # end
+
+ def forward(self, tenInput):
+ tenOutput = []
+
+ tenOutput.append(self.netOne(tenInput))
+ tenOutput.append(self.netTwo(tenOutput[-1]))
+ tenOutput.append(self.netThr(tenOutput[-1]))
+
+ return [torch.cat([tenInput, tenOutput[0]], 1)] + tenOutput[1:]
+ # end
+ # end
+
+ class Softmetric(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netInput = torch.nn.Conv2d(in_channels=3, out_channels=12, kernel_size=3, stride=1, padding=1, bias=False)
+ self.netError = torch.nn.Conv2d(in_channels=1, out_channels=4, kernel_size=3, stride=1, padding=1, bias=False)
+
+ for intRow, intFeatures in [(0, 16), (1, 32), (2, 64), (3, 96)]:
+ self.add_module(str(intRow) + 'x0' + ' - ' + str(intRow) + 'x1', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ # end
+
+ for intCol in [0]:
+ self.add_module('0x' + str(intCol) + ' - ' + '1x' + str(intCol), Downsample([16, 32, 32]))
+ self.add_module('1x' + str(intCol) + ' - ' + '2x' + str(intCol), Downsample([32, 64, 64]))
+ self.add_module('2x' + str(intCol) + ' - ' + '3x' + str(intCol), Downsample([64, 96, 96]))
+ # end
+
+ for intCol in [1]:
+ self.add_module('3x' + str(intCol) + ' - ' + '2x' + str(intCol), Upsample([96, 64, 64]))
+ self.add_module('2x' + str(intCol) + ' - ' + '1x' + str(intCol), Upsample([64, 32, 32]))
+ self.add_module('1x' + str(intCol) + ' - ' + '0x' + str(intCol), Upsample([32, 16, 16]))
+ # end
+
+ self.netOutput = Basic('conv-relu-conv', [16, 16, 1], True)
+ # end
+
+ def forward(self, tenEncone, tenEnctwo, tenFlow):
+ tenColumn = [None, None, None, None]
+
+ tenColumn[0] = torch.cat([self.netInput(tenEncone[0][:, 0:3, :, :]), self.netError(torch.nn.functional.l1_loss(input=tenEncone[0], target=backwarp(tenEnctwo[0], tenFlow), reduction='none').mean([1], True))], 1)
+ tenColumn[1] = self._modules['0x0 - 1x0'](tenColumn[0])
+ tenColumn[2] = self._modules['1x0 - 2x0'](tenColumn[1])
+ tenColumn[3] = self._modules['2x0 - 3x0'](tenColumn[2])
+
+ intColumn = 1
+ for intRow in range(len(tenColumn) -1, -1, -1):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != len(tenColumn) - 1:
+ tenUp = self._modules[str(intRow + 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow + 1])
+
+ if tenUp.shape[2] != tenColumn[intRow].shape[2]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, 0, 0, -1], mode='constant', value=0.0)
+ if tenUp.shape[3] != tenColumn[intRow].shape[3]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, -1, 0, 0], mode='constant', value=0.0)
+
+ tenColumn[intRow] = tenColumn[intRow] + tenUp
+ # end
+ # end
+
+ return self.netOutput(tenColumn[0])
+ # end
+ # end
+
+ class Warp(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netOne = Basic('conv-relu-conv', [3 + 3 + 32 + 32 + 1 + 1, 32, 32], True)
+ self.netTwo = Basic('conv-relu-conv', [0 + 0 + 64 + 64 + 1 + 1, 64, 64], True)
+ self.netThr = Basic('conv-relu-conv', [0 + 0 + 96 + 96 + 1 + 1, 96, 96], True)
+ # end
+
+ def forward(self, tenEncone, tenEnctwo, tenMetricone, tenMetrictwo, tenForward, tenBackward):
+ tenOutput = []
+
+ for intLevel in range(3):
+ if intLevel != 0:
+ tenMetricone = torch.nn.functional.interpolate(input=tenMetricone, size=(tenEncone[intLevel].shape[2], tenEncone[intLevel].shape[3]), mode='bilinear', align_corners=False)
+ tenMetrictwo = torch.nn.functional.interpolate(input=tenMetrictwo, size=(tenEnctwo[intLevel].shape[2], tenEnctwo[intLevel].shape[3]), mode='bilinear', align_corners=False)
+
+ tenForward = torch.nn.functional.interpolate(input=tenForward, size=(tenEncone[intLevel].shape[2], tenEncone[intLevel].shape[3]), mode='bilinear', align_corners=False) * (float(tenEncone[intLevel].shape[3]) / float(tenForward.shape[3]))
+ tenBackward = torch.nn.functional.interpolate(input=tenBackward, size=(tenEnctwo[intLevel].shape[2], tenEnctwo[intLevel].shape[3]), mode='bilinear', align_corners=False) * (float(tenEnctwo[intLevel].shape[3]) / float(tenBackward.shape[3]))
+ # end
+
+ tenOutput.append([self.netOne, self.netTwo, self.netThr][intLevel](torch.cat([
+ softsplat.softsplat(tenIn=torch.cat([tenEncone[intLevel], tenMetricone], 1), tenFlow=tenForward, tenMetric=tenMetricone.neg().clip(-20.0, 20.0), strMode='soft'),
+ softsplat.softsplat(tenIn=torch.cat([tenEnctwo[intLevel], tenMetrictwo], 1), tenFlow=tenBackward, tenMetric=tenMetrictwo.neg().clip(-20.0, 20.0), strMode='soft')
+ ], 1)))
+ # end
+
+ return tenOutput
+ # end
+ # end
+
+ self.netEncode = Encode()
+
+ self.netSoftmetric = Softmetric()
+
+ self.netWarp = Warp()
+
+ for intRow, intFeatures in [(0, 32), (1, 64), (2, 96)]:
+ self.add_module(str(intRow) + 'x0' + ' - ' + str(intRow) + 'x1', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ self.add_module(str(intRow) + 'x1' + ' - ' + str(intRow) + 'x2', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ self.add_module(str(intRow) + 'x2' + ' - ' + str(intRow) + 'x3', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ self.add_module(str(intRow) + 'x3' + ' - ' + str(intRow) + 'x4', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ self.add_module(str(intRow) + 'x4' + ' - ' + str(intRow) + 'x5', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ # end
+
+ for intCol in [0, 1, 2]:
+ self.add_module('0x' + str(intCol) + ' - ' + '1x' + str(intCol), Downsample([32, 64, 64]))
+ self.add_module('1x' + str(intCol) + ' - ' + '2x' + str(intCol), Downsample([64, 96, 96]))
+ # end
+
+ for intCol in [3, 4, 5]:
+ self.add_module('2x' + str(intCol) + ' - ' + '1x' + str(intCol), Upsample([96, 64, 64]))
+ self.add_module('1x' + str(intCol) + ' - ' + '0x' + str(intCol), Upsample([64, 32, 32]))
+ # end
+
+ self.netOutput = Basic('conv-relu-conv', [32, 32, 3], True)
+ # end
+
+ def forward(self, tenOne, tenTwo, tenForward, tenBackward, fltTime):
+ tenEncone = self.netEncode(tenOne)
+ tenEnctwo = self.netEncode(tenTwo)
+
+ tenMetricone = self.netSoftmetric(tenEncone, tenEnctwo, tenForward) * 2.0 * fltTime
+ tenMetrictwo = self.netSoftmetric(tenEnctwo, tenEncone, tenBackward) * 2.0 * (1.0 - fltTime)
+
+ tenForward = tenForward * fltTime
+ tenBackward = tenBackward * (1.0 - fltTime)
+
+ tenWarp = self.netWarp(tenEncone, tenEnctwo, tenMetricone, tenMetrictwo, tenForward, tenBackward)
+
+ tenColumn = [None, None, None]
+
+ tenColumn[0] = tenWarp[0]
+ tenColumn[1] = tenWarp[1] + self._modules['0x0 - 1x0'](tenColumn[0])
+ tenColumn[2] = tenWarp[2] + self._modules['1x0 - 2x0'](tenColumn[1])
+
+ intColumn = 1
+ for intRow in range(len(tenColumn)):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != 0:
+ tenColumn[intRow] = tenColumn[intRow] + self._modules[str(intRow - 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow - 1])
+ # end
+ # end
+
+ intColumn = 2
+ for intRow in range(len(tenColumn)):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != 0:
+ tenColumn[intRow] = tenColumn[intRow] + self._modules[str(intRow - 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow - 1])
+ # end
+ # end
+
+ intColumn = 3
+ for intRow in range(len(tenColumn) -1, -1, -1):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != len(tenColumn) - 1:
+ tenUp = self._modules[str(intRow + 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow + 1])
+
+ if tenUp.shape[2] != tenColumn[intRow].shape[2]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, 0, 0, -1], mode='constant', value=0.0)
+ if tenUp.shape[3] != tenColumn[intRow].shape[3]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, -1, 0, 0], mode='constant', value=0.0)
+
+ tenColumn[intRow] = tenColumn[intRow] + tenUp
+ # end
+ # end
+
+ intColumn = 4
+ for intRow in range(len(tenColumn) -1, -1, -1):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != len(tenColumn) - 1:
+ tenUp = self._modules[str(intRow + 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow + 1])
+
+ if tenUp.shape[2] != tenColumn[intRow].shape[2]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, 0, 0, -1], mode='constant', value=0.0)
+ if tenUp.shape[3] != tenColumn[intRow].shape[3]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, -1, 0, 0], mode='constant', value=0.0)
+
+ tenColumn[intRow] = tenColumn[intRow] + tenUp
+ # end
+ # end
+
+ intColumn = 5
+ for intRow in range(len(tenColumn) -1, -1, -1):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != len(tenColumn) - 1:
+ tenUp = self._modules[str(intRow + 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow + 1])
+
+ if tenUp.shape[2] != tenColumn[intRow].shape[2]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, 0, 0, -1], mode='constant', value=0.0)
+ if tenUp.shape[3] != tenColumn[intRow].shape[3]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, -1, 0, 0], mode='constant', value=0.0)
+
+ tenColumn[intRow] = tenColumn[intRow] + tenUp
+ # end
+ # end
+
+ return self.netOutput(tenColumn[0])
+ # end
+# end
+
+##########################################################
+
+class Network(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netFlow = Flow()
+
+ self.netSynthesis = Synthesis()
+
+ self.load_state_dict({strKey.replace('module', 'net'): tenWeight for strKey, tenWeight in torch.hub.load_state_dict_from_url(url='http://content.sniklaus.com/softsplat/network-' + arguments_strModel + '.pytorch', file_name='softsplat-' + arguments_strModel).items()})
+ # end
+
+ def forward(self, tenOne, tenTwo, fltTimes):
+ with torch.set_grad_enabled(False):
+ tenStats = [tenOne, tenTwo]
+ tenMean = sum([tenIn.mean([1, 2, 3], True) for tenIn in tenStats]) / len(tenStats)
+ tenStd = (sum([tenIn.std([1, 2, 3], False, True).square() + (tenMean - tenIn.mean([1, 2, 3], True)).square() for tenIn in tenStats]) / len(tenStats)).sqrt()
+ tenOne = ((tenOne - tenMean) / (tenStd + 0.0000001)).detach()
+ tenTwo = ((tenTwo - tenMean) / (tenStd + 0.0000001)).detach()
+ # end
+
+ objFlow = self.netFlow(tenOne, tenTwo)
+
+ tenImages = [self.netSynthesis(tenOne, tenTwo, objFlow['tenForward'], objFlow['tenBackward'], fltTime) for fltTime in fltTimes]
+
+ return [(tenImage * tenStd) + tenMean for tenImage in tenImages]
+ # end
+# end
+
+netNetwork = None
+
+##########################################################
+
+def estimate(tenOne, tenTwo, fltTimes):
+ global netNetwork
+
+ if netNetwork is None:
+ netNetwork = Network().cuda().eval()
+ # end
+
+ assert(tenOne.shape[1] == tenTwo.shape[1])
+ assert(tenOne.shape[2] == tenTwo.shape[2])
+
+ intWidth = tenOne.shape[2]
+ intHeight = tenOne.shape[1]
+
+ tenPreprocessedOne = tenOne.cuda().view(1, 3, intHeight, intWidth)
+ tenPreprocessedTwo = tenTwo.cuda().view(1, 3, intHeight, intWidth)
+
+ intPadr = (2 - (intWidth % 2)) % 2
+ intPadb = (2 - (intHeight % 2)) % 2
+
+ tenPreprocessedOne = torch.nn.functional.pad(input=tenPreprocessedOne, pad=[0, intPadr, 0, intPadb], mode='replicate')
+ tenPreprocessedTwo = torch.nn.functional.pad(input=tenPreprocessedTwo, pad=[0, intPadr, 0, intPadb], mode='replicate')
+
+ return [tenImage[0, :, :intHeight, :intWidth].cpu() for tenImage in netNetwork(tenPreprocessedOne, tenPreprocessedTwo, fltTimes)]
+# end
+##########################################################
+import logging
+
+logger = logging.getLogger(__name__)
+
+raft = None
+
+class Raft:
+ def __init__(self):
+ from torchvision.models.optical_flow import (Raft_Large_Weights,
+ raft_large)
+
+ weights = Raft_Large_Weights.DEFAULT
+ self.device = "cuda" if torch.cuda.is_available() else "cpu"
+ model = raft_large(weights=weights, progress=False).to(self.device)
+ self.model = model.eval()
+
+ def __call__(self,img1,img2):
+ with torch.no_grad():
+ img1 = img1.to(self.device)
+ img2 = img2.to(self.device)
+ i1 = torch.vstack([img1,img2])
+ i2 = torch.vstack([img2,img1])
+ list_of_flows = self.model(i1, i2)
+
+ predicted_flows = list_of_flows[-1]
+ return { 'tenForward' : predicted_flows[0].unsqueeze(dim=0) , 'tenBackward' : predicted_flows[1].unsqueeze(dim=0) }
+
+img_count = 0
+def debug_save_img(img, comment, inc=False):
+ return
+ global img_count
+ from torchvision.utils import save_image
+
+ save_image(img, f"debug0/{img_count:04d}_{comment}.png")
+
+ if inc:
+ img_count += 1
+
+
+class Network2(torch.nn.Module):
+ def __init__(self, model_file_path):
+ super().__init__()
+
+ self.netFlow = Flow()
+
+ self.netSynthesis = Synthesis()
+
+ d = torch.load(model_file_path)
+
+ d = {strKey.replace('module', 'net'): tenWeight for strKey, tenWeight in d.items()}
+
+ self.load_state_dict(d)
+ # end
+
+ def forward(self, tenOne, tenTwo, guideFrameList):
+ global raft
+
+ do_composite = True
+ use_raft = True
+
+ if use_raft:
+ if raft is None:
+ raft = Raft()
+
+
+ with torch.set_grad_enabled(False):
+ tenStats = [tenOne, tenTwo]
+ tenMean = sum([tenIn.mean([1, 2, 3], True) for tenIn in tenStats]) / len(tenStats)
+ tenStd = (sum([tenIn.std([1, 2, 3], False, True).square() + (tenMean - tenIn.mean([1, 2, 3], True)).square() for tenIn in tenStats]) / len(tenStats)).sqrt()
+ tenOne = ((tenOne - tenMean) / (tenStd + 0.0000001)).detach()
+ tenTwo = ((tenTwo - tenMean) / (tenStd + 0.0000001)).detach()
+
+ gtenStats = guideFrameList
+ gtenMean = sum([tenIn.mean([1, 2, 3], True) for tenIn in gtenStats]) / len(gtenStats)
+ gtenStd = (sum([tenIn.std([1, 2, 3], False, True).square() + (gtenMean - tenIn.mean([1, 2, 3], True)).square() for tenIn in gtenStats]) / len(gtenStats)).sqrt()
+ guideFrameList = [((g - gtenMean) / (gtenStd + 0.0000001)).detach() for g in guideFrameList]
+
+ # end
+
+ tenImages =[]
+ l = len(guideFrameList)
+ i = 1
+ g1 = guideFrameList.pop(0)
+
+ if use_raft:
+ styleFlow = raft(tenOne, tenTwo)
+ else:
+ styleFlow = self.netFlow(tenOne, tenTwo)
+
+ def composite1(fA, fB, nA, nB):
+ # 1,2,768,512
+ A = fA[:,0,:,:]
+ B = fA[:,1,:,:]
+ Z = nA
+
+ UA = A / Z
+ UB = B / Z
+
+ A2 = fB[:,0,:,:]
+ B2 = fB[:,1,:,:]
+ Z2 = nB
+ fB[:,0,:,:] = Z2 * UA
+ fB[:,1,:,:] = Z2 * UB
+ return fB
+
+ def mask_dilate(ten, kernel_size=3):
+ ten = ten.to(torch.float32)
+ k=torch.ones(1, 1, kernel_size, kernel_size, dtype=torch.float32).cuda()
+ ten = torch.nn.functional.conv2d(ten, k, padding=(kernel_size//2, kernel_size// 2))
+ result = torch.clamp(ten, 0, 1)
+ return result.to(torch.bool)
+
+ def composite2(fA, fB, nA, nB):
+ Z = nA
+ Z2 = nB
+
+ mean2 = torch.mean(Z2)
+ max2 = torch.max(Z2)
+ mask2 = (Z2 > (mean2+max2)/2)
+ debug_save_img(mask2.to(torch.float), "mask2_0")
+ mask2 = mask_dilate(mask2, 9)
+ debug_save_img(mask2.to(torch.float), "mask2_1")
+ mask2 = ~mask2
+
+ debug_save_img(mask2.to(torch.float), "mask2")
+
+ mean1 = torch.mean(Z)
+ max1 = torch.max(Z)
+ mask1 = (Z > (mean1+max1)/2)
+
+ debug_save_img(mask1.to(torch.float), "mask1")
+
+ mask = mask1 & mask2
+ mask = mask.squeeze()
+
+ debug_save_img(mask.to(torch.float), "cmask", True)
+
+ fB[:,:,mask] = fA[:,:,mask]
+
+ return fB
+
+
+ def composite(fA, fB):
+ A = fA[:,0,:,:]
+ B = fA[:,1,:,:]
+ Z = (A*A + B*B)**0.5
+ A2 = fB[:,0,:,:]
+ B2 = fB[:,1,:,:]
+ Z2 = (A2*A2 + B2*B2)**0.5
+
+ fB = composite1(fA, fB, Z, Z2)
+ fB = composite2(fA, fB, Z, Z2)
+ return fB
+
+ for g2 in guideFrameList:
+ if use_raft:
+ objFlow = raft(g1, g2)
+ else:
+ objFlow = self.netFlow(g1, g2)
+
+
+ objFlow['tenForward'] = objFlow['tenForward'] * (l/i)
+ objFlow['tenBackward'] = objFlow['tenBackward'] * (l/i)
+
+ if do_composite:
+ objFlow['tenForward'] = composite(objFlow['tenForward'], styleFlow['tenForward'])
+ objFlow['tenBackward'] = composite(objFlow['tenBackward'], styleFlow['tenBackward'])
+
+ img = self.netSynthesis(tenOne, tenTwo, objFlow['tenForward'], objFlow['tenBackward'], i/l)
+ tenImages.append(img)
+ i += 1
+
+ return [(tenImage * tenStd) + tenMean for tenImage in tenImages]
+
+
+# end
+
+netNetwork = None
+
+##########################################################
+
+def estimate2(img1: PIL.Image, img2:PIL.Image, guideFrames, model_file_path):
+ global netNetwork
+
+ if netNetwork is None:
+ netNetwork = Network2(model_file_path).cuda().eval()
+ # end
+
+ def forTensor(im):
+ return torch.FloatTensor(numpy.ascontiguousarray(numpy.array(im)[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+
+ tenOne = forTensor(img1)
+ tenTwo = forTensor(img2)
+
+ tenGuideFrames=[]
+ for g in guideFrames:
+ tenGuideFrames.append(forTensor(g))
+
+ assert(tenOne.shape[1] == tenTwo.shape[1])
+ assert(tenOne.shape[2] == tenTwo.shape[2])
+
+ intWidth = tenOne.shape[2]
+ intHeight = tenOne.shape[1]
+
+ tenPreprocessedOne = tenOne.cuda().view(1, 3, intHeight, intWidth)
+ tenPreprocessedTwo = tenTwo.cuda().view(1, 3, intHeight, intWidth)
+ tenGuideFrames = [ ten.cuda().view(1, 3, intHeight, intWidth) for ten in tenGuideFrames]
+
+ intPadr = (2 - (intWidth % 2)) % 2
+ intPadb = (2 - (intHeight % 2)) % 2
+
+ tenPreprocessedOne = torch.nn.functional.pad(input=tenPreprocessedOne, pad=[0, intPadr, 0, intPadb], mode='replicate')
+ tenPreprocessedTwo = torch.nn.functional.pad(input=tenPreprocessedTwo, pad=[0, intPadr, 0, intPadb], mode='replicate')
+ tenGuideFrames = [ torch.nn.functional.pad(input=ten, pad=[0, intPadr, 0, intPadb], mode='replicate') for ten in tenGuideFrames]
+
+ result = [tenImage[0, :, :intHeight, :intWidth].cpu() for tenImage in netNetwork(tenPreprocessedOne, tenPreprocessedTwo, tenGuideFrames)]
+ result = [ PIL.Image.fromarray((r.clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8)) for r in result]
+
+ return result
+# end
+
+##########################################################
+'''
+if __name__ == '__main__':
+ if arguments_strOut.split('.')[-1] in ['bmp', 'jpg', 'jpeg', 'png']:
+ tenOne = torch.FloatTensor(numpy.ascontiguousarray(numpy.array(PIL.Image.open(arguments_strOne))[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+ tenTwo = torch.FloatTensor(numpy.ascontiguousarray(numpy.array(PIL.Image.open(arguments_strTwo))[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+
+ tenOutput = estimate(tenOne, tenTwo, [0.5])[0]
+
+ PIL.Image.fromarray((tenOutput.clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8)).save(arguments_strOut)
+
+ elif arguments_strOut.split('.')[-1] in ['avi', 'mp4', 'webm', 'wmv']:
+ import moviepy
+ import moviepy.editor
+ import moviepy.video.io.ffmpeg_writer
+
+ objVideoreader = moviepy.editor.VideoFileClip(filename=arguments_strVideo)
+ objVideoreader2 = moviepy.editor.VideoFileClip(filename=arguments_strVideo2)
+
+ from moviepy.video.fx.resize import resize
+ objVideoreader2 = resize(objVideoreader2, (objVideoreader.w, objVideoreader.h))
+
+ intWidth = objVideoreader.w
+ intHeight = objVideoreader.h
+
+ tenFrames = [None, None, None, None]
+
+ with moviepy.video.io.ffmpeg_writer.FFMPEG_VideoWriter(filename=arguments_strOut, size=(intWidth, intHeight), fps=objVideoreader.fps) as objVideowriter:
+ for npyFrame in objVideoreader.iter_frames():
+ tenFrames[3] = torch.FloatTensor(numpy.ascontiguousarray(npyFrame[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+
+ if tenFrames[0] is not None:
+ tenFrames[1:3] = estimate(tenFrames[0], tenFrames[3], [0.333, 0.666])
+
+ objVideowriter.write_frame((tenFrames[0].clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8))
+ objVideowriter.write_frame((tenFrames[1].clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8))
+ objVideowriter.write_frame((tenFrames[2].clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8))
+# objVideowriter.write_frame((tenFrames[3].clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8))
+ # end
+
+ tenFrames[0] = torch.FloatTensor(numpy.ascontiguousarray(npyFrame[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+ # end
+ # end
+
+ # end
+# end
+'''
\ No newline at end of file
diff --git a/animate/src/animatediff/softmax_splatting/softsplat.py b/animate/src/animatediff/softmax_splatting/softsplat.py
new file mode 100644
index 0000000000000000000000000000000000000000..f35ccc21604479940c2c86580c287e73f3dc327d
--- /dev/null
+++ b/animate/src/animatediff/softmax_splatting/softsplat.py
@@ -0,0 +1,529 @@
+#!/usr/bin/env python
+
+import collections
+import cupy
+import os
+import re
+import torch
+import typing
+
+
+##########################################################
+
+
+objCudacache = {}
+
+
+def cuda_int32(intIn:int):
+ return cupy.int32(intIn)
+# end
+
+
+def cuda_float32(fltIn:float):
+ return cupy.float32(fltIn)
+# end
+
+
+def cuda_kernel(strFunction:str, strKernel:str, objVariables:typing.Dict):
+ if 'device' not in objCudacache:
+ objCudacache['device'] = torch.cuda.get_device_name()
+ # end
+
+ strKey = strFunction
+
+ for strVariable in objVariables:
+ objValue = objVariables[strVariable]
+
+ strKey += strVariable
+
+ if objValue is None:
+ continue
+
+ elif type(objValue) == int:
+ strKey += str(objValue)
+
+ elif type(objValue) == float:
+ strKey += str(objValue)
+
+ elif type(objValue) == bool:
+ strKey += str(objValue)
+
+ elif type(objValue) == str:
+ strKey += objValue
+
+ elif type(objValue) == torch.Tensor:
+ strKey += str(objValue.dtype)
+ strKey += str(objValue.shape)
+ strKey += str(objValue.stride())
+
+ elif True:
+ print(strVariable, type(objValue))
+ assert(False)
+
+ # end
+ # end
+
+ strKey += objCudacache['device']
+
+ if strKey not in objCudacache:
+ for strVariable in objVariables:
+ objValue = objVariables[strVariable]
+
+ if objValue is None:
+ continue
+
+ elif type(objValue) == int:
+ strKernel = strKernel.replace('{{' + strVariable + '}}', str(objValue))
+
+ elif type(objValue) == float:
+ strKernel = strKernel.replace('{{' + strVariable + '}}', str(objValue))
+
+ elif type(objValue) == bool:
+ strKernel = strKernel.replace('{{' + strVariable + '}}', str(objValue))
+
+ elif type(objValue) == str:
+ strKernel = strKernel.replace('{{' + strVariable + '}}', objValue)
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.uint8:
+ strKernel = strKernel.replace('{{type}}', 'unsigned char')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.float16:
+ strKernel = strKernel.replace('{{type}}', 'half')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.float32:
+ strKernel = strKernel.replace('{{type}}', 'float')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.float64:
+ strKernel = strKernel.replace('{{type}}', 'double')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.int32:
+ strKernel = strKernel.replace('{{type}}', 'int')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.int64:
+ strKernel = strKernel.replace('{{type}}', 'long')
+
+ elif type(objValue) == torch.Tensor:
+ print(strVariable, objValue.dtype)
+ assert(False)
+
+ elif True:
+ print(strVariable, type(objValue))
+ assert(False)
+
+ # end
+ # end
+
+ while True:
+ objMatch = re.search('(SIZE_)([0-4])(\()([^\)]*)(\))', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intArg = int(objMatch.group(2))
+
+ strTensor = objMatch.group(4)
+ intSizes = objVariables[strTensor].size()
+
+ strKernel = strKernel.replace(objMatch.group(), str(intSizes[intArg] if torch.is_tensor(intSizes[intArg]) == False else intSizes[intArg].item()))
+ # end
+
+ while True:
+ objMatch = re.search('(OFFSET_)([0-4])(\()', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intStart = objMatch.span()[1]
+ intStop = objMatch.span()[1]
+ intParentheses = 1
+
+ while True:
+ intParentheses += 1 if strKernel[intStop] == '(' else 0
+ intParentheses -= 1 if strKernel[intStop] == ')' else 0
+
+ if intParentheses == 0:
+ break
+ # end
+
+ intStop += 1
+ # end
+
+ intArgs = int(objMatch.group(2))
+ strArgs = strKernel[intStart:intStop].split(',')
+
+ assert(intArgs == len(strArgs) - 1)
+
+ strTensor = strArgs[0]
+ intStrides = objVariables[strTensor].stride()
+
+ strIndex = []
+
+ for intArg in range(intArgs):
+ strIndex.append('((' + strArgs[intArg + 1].replace('{', '(').replace('}', ')').strip() + ')*' + str(intStrides[intArg] if torch.is_tensor(intStrides[intArg]) == False else intStrides[intArg].item()) + ')')
+ # end
+
+ strKernel = strKernel.replace('OFFSET_' + str(intArgs) + '(' + strKernel[intStart:intStop] + ')', '(' + str.join('+', strIndex) + ')')
+ # end
+
+ while True:
+ objMatch = re.search('(VALUE_)([0-4])(\()', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intStart = objMatch.span()[1]
+ intStop = objMatch.span()[1]
+ intParentheses = 1
+
+ while True:
+ intParentheses += 1 if strKernel[intStop] == '(' else 0
+ intParentheses -= 1 if strKernel[intStop] == ')' else 0
+
+ if intParentheses == 0:
+ break
+ # end
+
+ intStop += 1
+ # end
+
+ intArgs = int(objMatch.group(2))
+ strArgs = strKernel[intStart:intStop].split(',')
+
+ assert(intArgs == len(strArgs) - 1)
+
+ strTensor = strArgs[0]
+ intStrides = objVariables[strTensor].stride()
+
+ strIndex = []
+
+ for intArg in range(intArgs):
+ strIndex.append('((' + strArgs[intArg + 1].replace('{', '(').replace('}', ')').strip() + ')*' + str(intStrides[intArg] if torch.is_tensor(intStrides[intArg]) == False else intStrides[intArg].item()) + ')')
+ # end
+
+ strKernel = strKernel.replace('VALUE_' + str(intArgs) + '(' + strKernel[intStart:intStop] + ')', strTensor + '[' + str.join('+', strIndex) + ']')
+ # end
+
+ objCudacache[strKey] = {
+ 'strFunction': strFunction,
+ 'strKernel': strKernel
+ }
+ # end
+
+ return strKey
+# end
+
+
+@cupy.memoize(for_each_device=True)
+def cuda_launch(strKey:str):
+ if 'CUDA_HOME' not in os.environ:
+ os.environ['CUDA_HOME'] = cupy.cuda.get_cuda_path()
+ # end
+
+ return cupy.cuda.compile_with_cache(objCudacache[strKey]['strKernel'], tuple(['-I ' + os.environ['CUDA_HOME'], '-I ' + os.environ['CUDA_HOME'] + '/include'])).get_function(objCudacache[strKey]['strFunction'])
+# end
+
+
+##########################################################
+
+
+def softsplat(tenIn:torch.Tensor, tenFlow:torch.Tensor, tenMetric:torch.Tensor, strMode:str):
+ assert(strMode.split('-')[0] in ['sum', 'avg', 'linear', 'soft'])
+
+ if strMode == 'sum': assert(tenMetric is None)
+ if strMode == 'avg': assert(tenMetric is None)
+ if strMode.split('-')[0] == 'linear': assert(tenMetric is not None)
+ if strMode.split('-')[0] == 'soft': assert(tenMetric is not None)
+
+ if strMode == 'avg':
+ tenIn = torch.cat([tenIn, tenIn.new_ones([tenIn.shape[0], 1, tenIn.shape[2], tenIn.shape[3]])], 1)
+
+ elif strMode.split('-')[0] == 'linear':
+ tenIn = torch.cat([tenIn * tenMetric, tenMetric], 1)
+
+ elif strMode.split('-')[0] == 'soft':
+ tenIn = torch.cat([tenIn * tenMetric.exp(), tenMetric.exp()], 1)
+
+ # end
+
+ tenOut = softsplat_func.apply(tenIn, tenFlow)
+
+ if strMode.split('-')[0] in ['avg', 'linear', 'soft']:
+ tenNormalize = tenOut[:, -1:, :, :]
+
+ if len(strMode.split('-')) == 1:
+ tenNormalize = tenNormalize + 0.0000001
+
+ elif strMode.split('-')[1] == 'addeps':
+ tenNormalize = tenNormalize + 0.0000001
+
+ elif strMode.split('-')[1] == 'zeroeps':
+ tenNormalize[tenNormalize == 0.0] = 1.0
+
+ elif strMode.split('-')[1] == 'clipeps':
+ tenNormalize = tenNormalize.clip(0.0000001, None)
+
+ # end
+
+ tenOut = tenOut[:, :-1, :, :] / tenNormalize
+ # end
+
+ return tenOut
+# end
+
+
+class softsplat_func(torch.autograd.Function):
+ @staticmethod
+ @torch.cuda.amp.custom_fwd(cast_inputs=torch.float32)
+ def forward(self, tenIn, tenFlow):
+ tenOut = tenIn.new_zeros([tenIn.shape[0], tenIn.shape[1], tenIn.shape[2], tenIn.shape[3]])
+
+ if tenIn.is_cuda == True:
+ cuda_launch(cuda_kernel('softsplat_out', '''
+ extern "C" __global__ void __launch_bounds__(512) softsplat_out(
+ const int n,
+ const {{type}}* __restrict__ tenIn,
+ const {{type}}* __restrict__ tenFlow,
+ {{type}}* __restrict__ tenOut
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ const int intN = ( intIndex / SIZE_3(tenOut) / SIZE_2(tenOut) / SIZE_1(tenOut) ) % SIZE_0(tenOut);
+ const int intC = ( intIndex / SIZE_3(tenOut) / SIZE_2(tenOut) ) % SIZE_1(tenOut);
+ const int intY = ( intIndex / SIZE_3(tenOut) ) % SIZE_2(tenOut);
+ const int intX = ( intIndex ) % SIZE_3(tenOut);
+
+ assert(SIZE_1(tenFlow) == 2);
+
+ {{type}} fltX = ({{type}}) (intX) + VALUE_4(tenFlow, intN, 0, intY, intX);
+ {{type}} fltY = ({{type}}) (intY) + VALUE_4(tenFlow, intN, 1, intY, intX);
+
+ if (isfinite(fltX) == false) { return; }
+ if (isfinite(fltY) == false) { return; }
+
+ {{type}} fltIn = VALUE_4(tenIn, intN, intC, intY, intX);
+
+ int intNorthwestX = (int) (floor(fltX));
+ int intNorthwestY = (int) (floor(fltY));
+ int intNortheastX = intNorthwestX + 1;
+ int intNortheastY = intNorthwestY;
+ int intSouthwestX = intNorthwestX;
+ int intSouthwestY = intNorthwestY + 1;
+ int intSoutheastX = intNorthwestX + 1;
+ int intSoutheastY = intNorthwestY + 1;
+
+ {{type}} fltNorthwest = (({{type}}) (intSoutheastX) - fltX) * (({{type}}) (intSoutheastY) - fltY);
+ {{type}} fltNortheast = (fltX - ({{type}}) (intSouthwestX)) * (({{type}}) (intSouthwestY) - fltY);
+ {{type}} fltSouthwest = (({{type}}) (intNortheastX) - fltX) * (fltY - ({{type}}) (intNortheastY));
+ {{type}} fltSoutheast = (fltX - ({{type}}) (intNorthwestX)) * (fltY - ({{type}}) (intNorthwestY));
+
+ if ((intNorthwestX >= 0) && (intNorthwestX < SIZE_3(tenOut)) && (intNorthwestY >= 0) && (intNorthwestY < SIZE_2(tenOut))) {
+ atomicAdd(&tenOut[OFFSET_4(tenOut, intN, intC, intNorthwestY, intNorthwestX)], fltIn * fltNorthwest);
+ }
+
+ if ((intNortheastX >= 0) && (intNortheastX < SIZE_3(tenOut)) && (intNortheastY >= 0) && (intNortheastY < SIZE_2(tenOut))) {
+ atomicAdd(&tenOut[OFFSET_4(tenOut, intN, intC, intNortheastY, intNortheastX)], fltIn * fltNortheast);
+ }
+
+ if ((intSouthwestX >= 0) && (intSouthwestX < SIZE_3(tenOut)) && (intSouthwestY >= 0) && (intSouthwestY < SIZE_2(tenOut))) {
+ atomicAdd(&tenOut[OFFSET_4(tenOut, intN, intC, intSouthwestY, intSouthwestX)], fltIn * fltSouthwest);
+ }
+
+ if ((intSoutheastX >= 0) && (intSoutheastX < SIZE_3(tenOut)) && (intSoutheastY >= 0) && (intSoutheastY < SIZE_2(tenOut))) {
+ atomicAdd(&tenOut[OFFSET_4(tenOut, intN, intC, intSoutheastY, intSoutheastX)], fltIn * fltSoutheast);
+ }
+ } }
+ ''', {
+ 'tenIn': tenIn,
+ 'tenFlow': tenFlow,
+ 'tenOut': tenOut
+ }))(
+ grid=tuple([int((tenOut.nelement() + 512 - 1) / 512), 1, 1]),
+ block=tuple([512, 1, 1]),
+ args=[cuda_int32(tenOut.nelement()), tenIn.data_ptr(), tenFlow.data_ptr(), tenOut.data_ptr()],
+ stream=collections.namedtuple('Stream', 'ptr')(torch.cuda.current_stream().cuda_stream)
+ )
+
+ elif tenIn.is_cuda != True:
+ assert(False)
+
+ # end
+
+ self.save_for_backward(tenIn, tenFlow)
+
+ return tenOut
+ # end
+
+ @staticmethod
+ @torch.cuda.amp.custom_bwd
+ def backward(self, tenOutgrad):
+ tenIn, tenFlow = self.saved_tensors
+
+ tenOutgrad = tenOutgrad.contiguous(); assert(tenOutgrad.is_cuda == True)
+
+ tenIngrad = tenIn.new_zeros([tenIn.shape[0], tenIn.shape[1], tenIn.shape[2], tenIn.shape[3]]) if self.needs_input_grad[0] == True else None
+ tenFlowgrad = tenFlow.new_zeros([tenFlow.shape[0], tenFlow.shape[1], tenFlow.shape[2], tenFlow.shape[3]]) if self.needs_input_grad[1] == True else None
+
+ if tenIngrad is not None:
+ cuda_launch(cuda_kernel('softsplat_ingrad', '''
+ extern "C" __global__ void __launch_bounds__(512) softsplat_ingrad(
+ const int n,
+ const {{type}}* __restrict__ tenIn,
+ const {{type}}* __restrict__ tenFlow,
+ const {{type}}* __restrict__ tenOutgrad,
+ {{type}}* __restrict__ tenIngrad,
+ {{type}}* __restrict__ tenFlowgrad
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ const int intN = ( intIndex / SIZE_3(tenIngrad) / SIZE_2(tenIngrad) / SIZE_1(tenIngrad) ) % SIZE_0(tenIngrad);
+ const int intC = ( intIndex / SIZE_3(tenIngrad) / SIZE_2(tenIngrad) ) % SIZE_1(tenIngrad);
+ const int intY = ( intIndex / SIZE_3(tenIngrad) ) % SIZE_2(tenIngrad);
+ const int intX = ( intIndex ) % SIZE_3(tenIngrad);
+
+ assert(SIZE_1(tenFlow) == 2);
+
+ {{type}} fltIngrad = 0.0f;
+
+ {{type}} fltX = ({{type}}) (intX) + VALUE_4(tenFlow, intN, 0, intY, intX);
+ {{type}} fltY = ({{type}}) (intY) + VALUE_4(tenFlow, intN, 1, intY, intX);
+
+ if (isfinite(fltX) == false) { return; }
+ if (isfinite(fltY) == false) { return; }
+
+ int intNorthwestX = (int) (floor(fltX));
+ int intNorthwestY = (int) (floor(fltY));
+ int intNortheastX = intNorthwestX + 1;
+ int intNortheastY = intNorthwestY;
+ int intSouthwestX = intNorthwestX;
+ int intSouthwestY = intNorthwestY + 1;
+ int intSoutheastX = intNorthwestX + 1;
+ int intSoutheastY = intNorthwestY + 1;
+
+ {{type}} fltNorthwest = (({{type}}) (intSoutheastX) - fltX) * (({{type}}) (intSoutheastY) - fltY);
+ {{type}} fltNortheast = (fltX - ({{type}}) (intSouthwestX)) * (({{type}}) (intSouthwestY) - fltY);
+ {{type}} fltSouthwest = (({{type}}) (intNortheastX) - fltX) * (fltY - ({{type}}) (intNortheastY));
+ {{type}} fltSoutheast = (fltX - ({{type}}) (intNorthwestX)) * (fltY - ({{type}}) (intNorthwestY));
+
+ if ((intNorthwestX >= 0) && (intNorthwestX < SIZE_3(tenOutgrad)) && (intNorthwestY >= 0) && (intNorthwestY < SIZE_2(tenOutgrad))) {
+ fltIngrad += VALUE_4(tenOutgrad, intN, intC, intNorthwestY, intNorthwestX) * fltNorthwest;
+ }
+
+ if ((intNortheastX >= 0) && (intNortheastX < SIZE_3(tenOutgrad)) && (intNortheastY >= 0) && (intNortheastY < SIZE_2(tenOutgrad))) {
+ fltIngrad += VALUE_4(tenOutgrad, intN, intC, intNortheastY, intNortheastX) * fltNortheast;
+ }
+
+ if ((intSouthwestX >= 0) && (intSouthwestX < SIZE_3(tenOutgrad)) && (intSouthwestY >= 0) && (intSouthwestY < SIZE_2(tenOutgrad))) {
+ fltIngrad += VALUE_4(tenOutgrad, intN, intC, intSouthwestY, intSouthwestX) * fltSouthwest;
+ }
+
+ if ((intSoutheastX >= 0) && (intSoutheastX < SIZE_3(tenOutgrad)) && (intSoutheastY >= 0) && (intSoutheastY < SIZE_2(tenOutgrad))) {
+ fltIngrad += VALUE_4(tenOutgrad, intN, intC, intSoutheastY, intSoutheastX) * fltSoutheast;
+ }
+
+ tenIngrad[intIndex] = fltIngrad;
+ } }
+ ''', {
+ 'tenIn': tenIn,
+ 'tenFlow': tenFlow,
+ 'tenOutgrad': tenOutgrad,
+ 'tenIngrad': tenIngrad,
+ 'tenFlowgrad': tenFlowgrad
+ }))(
+ grid=tuple([int((tenIngrad.nelement() + 512 - 1) / 512), 1, 1]),
+ block=tuple([512, 1, 1]),
+ args=[cuda_int32(tenIngrad.nelement()), tenIn.data_ptr(), tenFlow.data_ptr(), tenOutgrad.data_ptr(), tenIngrad.data_ptr(), None],
+ stream=collections.namedtuple('Stream', 'ptr')(torch.cuda.current_stream().cuda_stream)
+ )
+ # end
+
+ if tenFlowgrad is not None:
+ cuda_launch(cuda_kernel('softsplat_flowgrad', '''
+ extern "C" __global__ void __launch_bounds__(512) softsplat_flowgrad(
+ const int n,
+ const {{type}}* __restrict__ tenIn,
+ const {{type}}* __restrict__ tenFlow,
+ const {{type}}* __restrict__ tenOutgrad,
+ {{type}}* __restrict__ tenIngrad,
+ {{type}}* __restrict__ tenFlowgrad
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ const int intN = ( intIndex / SIZE_3(tenFlowgrad) / SIZE_2(tenFlowgrad) / SIZE_1(tenFlowgrad) ) % SIZE_0(tenFlowgrad);
+ const int intC = ( intIndex / SIZE_3(tenFlowgrad) / SIZE_2(tenFlowgrad) ) % SIZE_1(tenFlowgrad);
+ const int intY = ( intIndex / SIZE_3(tenFlowgrad) ) % SIZE_2(tenFlowgrad);
+ const int intX = ( intIndex ) % SIZE_3(tenFlowgrad);
+
+ assert(SIZE_1(tenFlow) == 2);
+
+ {{type}} fltFlowgrad = 0.0f;
+
+ {{type}} fltX = ({{type}}) (intX) + VALUE_4(tenFlow, intN, 0, intY, intX);
+ {{type}} fltY = ({{type}}) (intY) + VALUE_4(tenFlow, intN, 1, intY, intX);
+
+ if (isfinite(fltX) == false) { return; }
+ if (isfinite(fltY) == false) { return; }
+
+ int intNorthwestX = (int) (floor(fltX));
+ int intNorthwestY = (int) (floor(fltY));
+ int intNortheastX = intNorthwestX + 1;
+ int intNortheastY = intNorthwestY;
+ int intSouthwestX = intNorthwestX;
+ int intSouthwestY = intNorthwestY + 1;
+ int intSoutheastX = intNorthwestX + 1;
+ int intSoutheastY = intNorthwestY + 1;
+
+ {{type}} fltNorthwest = 0.0f;
+ {{type}} fltNortheast = 0.0f;
+ {{type}} fltSouthwest = 0.0f;
+ {{type}} fltSoutheast = 0.0f;
+
+ if (intC == 0) {
+ fltNorthwest = (({{type}}) (-1.0f)) * (({{type}}) (intSoutheastY) - fltY);
+ fltNortheast = (({{type}}) (+1.0f)) * (({{type}}) (intSouthwestY) - fltY);
+ fltSouthwest = (({{type}}) (-1.0f)) * (fltY - ({{type}}) (intNortheastY));
+ fltSoutheast = (({{type}}) (+1.0f)) * (fltY - ({{type}}) (intNorthwestY));
+
+ } else if (intC == 1) {
+ fltNorthwest = (({{type}}) (intSoutheastX) - fltX) * (({{type}}) (-1.0f));
+ fltNortheast = (fltX - ({{type}}) (intSouthwestX)) * (({{type}}) (-1.0f));
+ fltSouthwest = (({{type}}) (intNortheastX) - fltX) * (({{type}}) (+1.0f));
+ fltSoutheast = (fltX - ({{type}}) (intNorthwestX)) * (({{type}}) (+1.0f));
+
+ }
+
+ for (int intChannel = 0; intChannel < SIZE_1(tenOutgrad); intChannel += 1) {
+ {{type}} fltIn = VALUE_4(tenIn, intN, intChannel, intY, intX);
+
+ if ((intNorthwestX >= 0) && (intNorthwestX < SIZE_3(tenOutgrad)) && (intNorthwestY >= 0) && (intNorthwestY < SIZE_2(tenOutgrad))) {
+ fltFlowgrad += VALUE_4(tenOutgrad, intN, intChannel, intNorthwestY, intNorthwestX) * fltIn * fltNorthwest;
+ }
+
+ if ((intNortheastX >= 0) && (intNortheastX < SIZE_3(tenOutgrad)) && (intNortheastY >= 0) && (intNortheastY < SIZE_2(tenOutgrad))) {
+ fltFlowgrad += VALUE_4(tenOutgrad, intN, intChannel, intNortheastY, intNortheastX) * fltIn * fltNortheast;
+ }
+
+ if ((intSouthwestX >= 0) && (intSouthwestX < SIZE_3(tenOutgrad)) && (intSouthwestY >= 0) && (intSouthwestY < SIZE_2(tenOutgrad))) {
+ fltFlowgrad += VALUE_4(tenOutgrad, intN, intChannel, intSouthwestY, intSouthwestX) * fltIn * fltSouthwest;
+ }
+
+ if ((intSoutheastX >= 0) && (intSoutheastX < SIZE_3(tenOutgrad)) && (intSoutheastY >= 0) && (intSoutheastY < SIZE_2(tenOutgrad))) {
+ fltFlowgrad += VALUE_4(tenOutgrad, intN, intChannel, intSoutheastY, intSoutheastX) * fltIn * fltSoutheast;
+ }
+ }
+
+ tenFlowgrad[intIndex] = fltFlowgrad;
+ } }
+ ''', {
+ 'tenIn': tenIn,
+ 'tenFlow': tenFlow,
+ 'tenOutgrad': tenOutgrad,
+ 'tenIngrad': tenIngrad,
+ 'tenFlowgrad': tenFlowgrad
+ }))(
+ grid=tuple([int((tenFlowgrad.nelement() + 512 - 1) / 512), 1, 1]),
+ block=tuple([512, 1, 1]),
+ args=[cuda_int32(tenFlowgrad.nelement()), tenIn.data_ptr(), tenFlow.data_ptr(), tenOutgrad.data_ptr(), None, tenFlowgrad.data_ptr()],
+ stream=collections.namedtuple('Stream', 'ptr')(torch.cuda.current_stream().cuda_stream)
+ )
+ # end
+
+ return tenIngrad, tenFlowgrad
+ # end
+# end
diff --git a/animate/src/animatediff/stylize.py b/animate/src/animatediff/stylize.py
new file mode 100644
index 0000000000000000000000000000000000000000..edd6879be55911e509efa0db97295dfa664377c6
--- /dev/null
+++ b/animate/src/animatediff/stylize.py
@@ -0,0 +1,1716 @@
+import glob
+import json
+import logging
+import os.path
+import shutil
+from datetime import datetime
+from pathlib import Path
+from typing import Annotated, Optional
+
+import torch
+import typer
+from PIL import Image
+from tqdm.rich import tqdm
+
+from animatediff import __version__, get_dir
+from animatediff.settings import ModelConfig, get_model_config
+from animatediff.utils.tagger import get_labels
+from animatediff.utils.util import (extract_frames, get_resized_image,
+ path_from_cwd, prepare_anime_seg,
+ prepare_groundingDINO, prepare_propainter,
+ prepare_sam_hq, prepare_softsplat)
+
+logger = logging.getLogger(__name__)
+
+
+
+stylize: typer.Typer = typer.Typer(
+ name="stylize",
+ context_settings=dict(help_option_names=["-h", "--help"]),
+ rich_markup_mode="rich",
+ pretty_exceptions_show_locals=False,
+ help="stylize video",
+)
+
+data_dir = get_dir("data")
+
+controlnet_dirs = [
+ "controlnet_canny",
+ "controlnet_depth",
+ "controlnet_inpaint",
+ "controlnet_ip2p",
+ "controlnet_lineart",
+ "controlnet_lineart_anime",
+ "controlnet_mlsd",
+ "controlnet_normalbae",
+ "controlnet_openpose",
+ "controlnet_scribble",
+ "controlnet_seg",
+ "controlnet_shuffle",
+ "controlnet_softedge",
+ "controlnet_tile",
+ "qr_code_monster_v1",
+ "qr_code_monster_v2",
+ "controlnet_mediapipe_face",
+ "animatediff_controlnet",
+ ]
+
+def create_controlnet_dir(controlnet_root):
+ for c in controlnet_dirs:
+ c_dir = controlnet_root.joinpath(c)
+ c_dir.mkdir(parents=True, exist_ok=True)
+
+@stylize.command(no_args_is_help=True)
+def create_config(
+ org_movie: Annotated[
+ Path,
+ typer.Argument(path_type=Path, file_okay=True, dir_okay=False, exists=True, help="Path to movie file"),
+ ] = ...,
+ config_org: Annotated[
+ Path,
+ typer.Option(
+ "--config-org",
+ "-c",
+ path_type=Path,
+ dir_okay=False,
+ exists=True,
+ help="Path to original config file",
+ ),
+ ] = Path("config/prompts/prompt_travel.json"),
+ ignore_list: Annotated[
+ Path,
+ typer.Option(
+ "--ignore-list",
+ "-g",
+ path_type=Path,
+ dir_okay=False,
+ exists=True,
+ help="path to ignore token list file",
+ ),
+ ] = Path("config/prompts/ignore_tokens.txt"),
+ out_dir: Annotated[
+ Optional[Path],
+ typer.Option(
+ "--out-dir",
+ "-o",
+ path_type=Path,
+ file_okay=False,
+ help="output directory",
+ ),
+ ] = Path("stylize/"),
+ fps: Annotated[
+ int,
+ typer.Option(
+ "--fps",
+ "-f",
+ min=1,
+ max=120,
+ help="fps",
+ ),
+ ] = 8,
+ duration: Annotated[
+ int,
+ typer.Option(
+ "--duration",
+ "-d",
+ min=-1,
+ max=3600,
+ help="Video duration in seconds. -1 means that the duration of the input video is used as is",
+ ),
+ ] = -1,
+ offset: Annotated[
+ int,
+ typer.Option(
+ "--offset",
+ "-of",
+ min=0,
+ max=3600,
+ help="offset in seconds. '-d 30 -of 1200' means to use 1200-1230 seconds of the input video",
+ ),
+ ] = 0,
+ aspect_ratio: Annotated[
+ float,
+ typer.Option(
+ "--aspect-ratio",
+ "-a",
+ min=-1,
+ max=5.0,
+ help="aspect ratio (width / height). (ex. 512 / 512 = 1.0 , 512 / 768 = 0.6666 , 768 / 512 = 1.5) -1 means that the aspect ratio of the input video is used as is.",
+ ),
+ ] = -1,
+ size_of_short_edge: Annotated[
+ int,
+ typer.Option(
+ "--short-edge",
+ "-sh",
+ min=100,
+ max=1024,
+ help="size of short edge",
+ ),
+ ] = 512,
+ predicte_interval: Annotated[
+ int,
+ typer.Option(
+ "--predicte-interval",
+ "-p",
+ min=1,
+ max=120,
+ help="Interval of frames to be predicted",
+ ),
+ ] = 1,
+ general_threshold: Annotated[
+ float,
+ typer.Option(
+ "--threshold",
+ "-th",
+ min=0.0,
+ max=1.0,
+ help="threshold for general token confidence",
+ ),
+ ] = 0.35,
+ character_threshold: Annotated[
+ float,
+ typer.Option(
+ "--threshold2",
+ "-th2",
+ min=0.0,
+ max=1.0,
+ help="threshold for character token confidence",
+ ),
+ ] = 0.85,
+ without_confidence: Annotated[
+ bool,
+ typer.Option(
+ "--no-confidence-format",
+ "-ncf",
+ is_flag=True,
+ help="confidence token format or not. ex. '(close-up:0.57), (monochrome:1.1)' -> 'close-up, monochrome'",
+ ),
+ ] = False,
+ is_no_danbooru_format: Annotated[
+ bool,
+ typer.Option(
+ "--no-danbooru-format",
+ "-ndf",
+ is_flag=True,
+ help="danbooru token format or not. ex. 'bandaid_on_leg, short_hair' -> 'bandaid on leg, short hair'",
+ ),
+ ] = False,
+ is_img2img: Annotated[
+ bool,
+ typer.Option(
+ "--img2img",
+ "-i2i",
+ is_flag=True,
+ help="img2img or not(txt2img).",
+ ),
+ ] = False,
+ low_vram: Annotated[
+ bool,
+ typer.Option(
+ "--low_vram",
+ "-lo",
+ is_flag=True,
+ help="low vram mode",
+ ),
+ ] = False,
+ gradual_latent_hires_fix: Annotated[
+ bool,
+ typer.Option(
+ "--gradual_latent_hires_fix",
+ "-gh",
+ is_flag=True,
+ help="gradual latent hires fix",
+ ),
+ ] = False,
+):
+ """Create a config file for video stylization"""
+ is_danbooru_format = not is_no_danbooru_format
+ with_confidence = not without_confidence
+ logger.info(f"{org_movie=}")
+ logger.info(f"{config_org=}")
+ logger.info(f"{ignore_list=}")
+ logger.info(f"{out_dir=}")
+ logger.info(f"{fps=}")
+ logger.info(f"{duration=}")
+ logger.info(f"{offset=}")
+ logger.info(f"{aspect_ratio=}")
+ logger.info(f"{size_of_short_edge=}")
+ logger.info(f"{predicte_interval=}")
+ logger.info(f"{general_threshold=}")
+ logger.info(f"{character_threshold=}")
+ logger.info(f"{with_confidence=}")
+ logger.info(f"{is_danbooru_format=}")
+ logger.info(f"{is_img2img=}")
+ logger.info(f"{low_vram=}")
+ logger.info(f"{gradual_latent_hires_fix=}")
+
+ model_config: ModelConfig = get_model_config(config_org)
+
+ # get a timestamp for the output directory
+ time_str = datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
+ # make the output directory
+ save_dir = out_dir.joinpath(f"{time_str}-{model_config.save_name}")
+ save_dir.mkdir(parents=True, exist_ok=True)
+ logger.info(f"Will save outputs to ./{path_from_cwd(save_dir)}")
+
+ img2img_dir = save_dir.joinpath("00_img2img")
+ img2img_dir.mkdir(parents=True, exist_ok=True)
+ extract_frames(org_movie, fps, img2img_dir, aspect_ratio, duration, offset, size_of_short_edge, low_vram)
+
+ controlnet_img_dir = save_dir.joinpath("00_controlnet_image")
+
+ create_controlnet_dir(controlnet_img_dir)
+
+ shutil.copytree(img2img_dir, controlnet_img_dir.joinpath("controlnet_openpose"), dirs_exist_ok=True)
+
+ #shutil.copytree(img2img_dir, controlnet_img_dir.joinpath("controlnet_ip2p"), dirs_exist_ok=True)
+
+
+ black_list = []
+ if ignore_list.is_file():
+ with open(ignore_list) as f:
+ black_list = [s.strip() for s in f.readlines()]
+
+ model_config.prompt_map = get_labels(
+ frame_dir=img2img_dir,
+ interval=predicte_interval,
+ general_threshold=general_threshold,
+ character_threshold=character_threshold,
+ ignore_tokens=black_list,
+ with_confidence=with_confidence,
+ is_danbooru_format=is_danbooru_format,
+ is_cpu = False,
+ )
+
+
+ model_config.head_prompt = ""
+ model_config.tail_prompt = ""
+ model_config.controlnet_map["input_image_dir"] = os.path.relpath(controlnet_img_dir.absolute(), data_dir)
+ model_config.controlnet_map["is_loop"] = False
+
+ model_config.lora_map={}
+ model_config.motion_lora_map={}
+
+ model_config.controlnet_map["max_samples_on_vram"] = 0
+ model_config.controlnet_map["max_models_on_vram"] = 0
+
+
+ model_config.controlnet_map["controlnet_openpose"] = {
+ "enable": True,
+ "use_preprocessor":True,
+ "guess_mode":False,
+ "controlnet_conditioning_scale": 1.0,
+ "control_guidance_start": 0.0,
+ "control_guidance_end": 1.0,
+ "control_scale_list":[],
+ "control_region_list":[]
+ }
+
+
+ model_config.controlnet_map["controlnet_ip2p"] = {
+ "enable": True,
+ "use_preprocessor":True,
+ "guess_mode":False,
+ "controlnet_conditioning_scale": 0.5,
+ "control_guidance_start": 0.0,
+ "control_guidance_end": 1.0,
+ "control_scale_list":[],
+ "control_region_list":[]
+ }
+
+ for m in model_config.controlnet_map:
+ if isinstance(model_config.controlnet_map[m] ,dict):
+ if "control_scale_list" in model_config.controlnet_map[m]:
+ model_config.controlnet_map[m]["control_scale_list"]=[]
+
+ ip_adapter_dir = save_dir.joinpath("00_ipadapter")
+ ip_adapter_dir.mkdir(parents=True, exist_ok=True)
+
+ model_config.ip_adapter_map = {
+ "enable": True,
+ "input_image_dir": os.path.relpath(ip_adapter_dir.absolute(), data_dir),
+ "prompt_fixed_ratio": 0.5,
+ "save_input_image": True,
+ "resized_to_square": False,
+ "scale": 0.5,
+ "is_full_face": False,
+ "is_plus_face": False,
+ "is_plus": True,
+ "is_light": False
+ }
+
+ model_config.img2img_map = {
+ "enable": is_img2img,
+ "init_img_dir" : os.path.relpath(img2img_dir.absolute(), data_dir),
+ "save_init_image": True,
+ "denoising_strength" : 0.7
+ }
+
+ model_config.region_map = {
+
+ }
+
+ model_config.gradual_latent_hires_fix_map = {
+ "enable" : True,
+ "scale" : {
+ "0": 0.5,
+ "0.7": 1.0
+ },
+ "reverse_steps": 5,
+ "noise_add_count": 3
+ }
+
+ model_config.output = {
+ "format" : "mp4",
+ "fps" : fps,
+ "encode_param":{
+ "crf": 10
+ }
+ }
+
+ img = Image.open( img2img_dir.joinpath("00000000.png") )
+ W, H = img.size
+
+ base_size = 768 if gradual_latent_hires_fix else 512
+
+ if W < H:
+ width = base_size
+ height = int(base_size * H/W)
+ else:
+ width = int(base_size * W/H)
+ height = base_size
+
+ width = int(width//8*8)
+ height = int(height//8*8)
+
+ length = len(glob.glob( os.path.join(img2img_dir, "[0-9]*.png"), recursive=False))
+
+ model_config.stylize_config={
+ "original_video":{
+ "path":org_movie,
+ "aspect_ratio":aspect_ratio,
+ "offset":offset,
+ },
+ "create_mask": [
+ "person"
+ ],
+ "composite": {
+ "fg_list": [
+ {
+ "path" : " absolute path to frame dir ",
+ "mask_path" : " absolute path to mask dir (this is optional) ",
+ "mask_prompt" : "person"
+ },
+ {
+ "path" : " absolute path to frame dir ",
+ "mask_path" : " absolute path to mask dir (this is optional) ",
+ "mask_prompt" : "cat"
+ },
+ ],
+ "bg_frame_dir": "Absolute path to the BG frame directory",
+ "hint": ""
+ },
+ "0":{
+ "width": width,
+ "height": height,
+ "length": length,
+ "context": 16,
+ "overlap": 16//4,
+ "stride": 0,
+ },
+ "1":{
+ "steps": model_config.steps,
+ "guidance_scale": model_config.guidance_scale,
+ "width": int(width * 1.5 //8*8),
+ "height": int(height * 1.5 //8*8),
+ "length": length,
+ "context": 8,
+ "overlap": 8//4,
+ "stride": 0,
+ "controlnet_tile":{
+ "enable": True,
+ "use_preprocessor":True,
+ "guess_mode":False,
+ "controlnet_conditioning_scale": 1.0,
+ "control_guidance_start": 0.0,
+ "control_guidance_end": 1.0,
+ "control_scale_list":[]
+ },
+ "controlnet_ip2p": {
+ "enable": False,
+ "use_preprocessor":True,
+ "guess_mode":False,
+ "controlnet_conditioning_scale": 0.5,
+ "control_guidance_start": 0.0,
+ "control_guidance_end": 1.0,
+ "control_scale_list":[]
+ },
+ "ip_adapter": False,
+ "reference": False,
+ "img2img": False,
+ "interpolation_multiplier": 1
+ }
+ }
+
+ if gradual_latent_hires_fix:
+ model_config.stylize_config.pop("1")
+
+
+ save_config_path = save_dir.joinpath("prompt.json")
+ save_config_path.write_text(model_config.json(indent=4), encoding="utf-8")
+
+ logger.info(f"config = { save_config_path }")
+ logger.info(f"stylize_dir = { save_dir }")
+
+ logger.info(f"!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!")
+ logger.info(f"Hint. Edit the config file before starting the generation")
+ logger.info(f"!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!")
+ logger.info(f"1. Change 'path' and 'motion_module' as needed")
+ logger.info(f"2. Enter the 'head_prompt' or 'tail_prompt' with your preferred prompt, quality prompt, lora trigger word, or any other prompt you wish to add.")
+ logger.info(f"3. Change 'n_prompt' as needed")
+ logger.info(f"4. Add the lora you need to 'lora_map'")
+ logger.info(f"5. If you do not like the default settings, edit 'ip_adapter_map' or 'controlnet_map'. \nIf you want to change the controlnet type, you need to replace the input image.")
+ logger.info(f"6. Change 'stylize_config' as needed. By default, it is generated twice: once for normal generation and once for upscaling.\nIf you don't need upscaling, delete the whole '1'.")
+ logger.info(f"7. Change 'output' as needed. Changing the 'fps' at this timing is not recommended as it will change the playback speed.\nIf you want to change the fps, specify it with the create-config option")
+
+
+@stylize.command(no_args_is_help=True)
+def generate(
+ stylize_dir: Annotated[
+ Path,
+ typer.Argument(path_type=Path, file_okay=False, dir_okay=True, exists=True, help="Path to stylize dir"),
+ ] = ...,
+ length: Annotated[
+ int,
+ typer.Option(
+ "--length",
+ "-L",
+ min=-1,
+ max=9999,
+ help="Number of frames to generate. -1 means that the value in the config file is referenced.",
+ rich_help_panel="Generation",
+ ),
+ ] = -1,
+ frame_offset: Annotated[
+ int,
+ typer.Option(
+ "--frame-offset",
+ "-FO",
+ min=0,
+ max=999999,
+ help="Frame offset at generation.",
+ rich_help_panel="Generation",
+ ),
+ ] = 0,
+):
+ """Run video stylization"""
+ from animatediff.cli import generate
+
+ time_str = datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
+
+
+ config_org = stylize_dir.joinpath("prompt.json")
+
+ model_config: ModelConfig = get_model_config(config_org)
+
+ if length == -1:
+ length = model_config.stylize_config["0"]["length"]
+
+ model_config.stylize_config["0"]["length"] = min(model_config.stylize_config["0"]["length"] - frame_offset, length)
+ if "1" in model_config.stylize_config:
+ model_config.stylize_config["1"]["length"] = min(model_config.stylize_config["1"]["length"] - frame_offset, length)
+
+ if frame_offset > 0:
+ #controlnet
+ org_controlnet_img_dir = data_dir.joinpath( model_config.controlnet_map["input_image_dir"] )
+ new_controlnet_img_dir = org_controlnet_img_dir.parent / "00_tmp_controlnet_image"
+ if new_controlnet_img_dir.is_dir():
+ shutil.rmtree(new_controlnet_img_dir)
+ new_controlnet_img_dir.mkdir(parents=True, exist_ok=True)
+
+ for c in controlnet_dirs:
+ src_dir = org_controlnet_img_dir.joinpath(c)
+ dst_dir = new_controlnet_img_dir.joinpath(c)
+ if src_dir.is_dir():
+ dst_dir.mkdir(parents=True, exist_ok=True)
+
+ frame_length = model_config.stylize_config["0"]["length"]
+
+ src_imgs = sorted(glob.glob( os.path.join(src_dir, "[0-9]*.png"), recursive=False))
+ for img in src_imgs:
+ n = int(Path(img).stem)
+ if n in range(frame_offset, frame_offset + frame_length):
+ dst_img_path = dst_dir.joinpath( f"{n-frame_offset:08d}.png" )
+ shutil.copy(img, dst_img_path)
+ #img2img
+ org_img2img_img_dir = data_dir.joinpath( model_config.img2img_map["init_img_dir"] )
+ new_img2img_img_dir = org_img2img_img_dir.parent / "00_tmp_init_img_dir"
+ if new_img2img_img_dir.is_dir():
+ shutil.rmtree(new_img2img_img_dir)
+ new_img2img_img_dir.mkdir(parents=True, exist_ok=True)
+
+ src_dir = org_img2img_img_dir
+ dst_dir = new_img2img_img_dir
+ if src_dir.is_dir():
+ dst_dir.mkdir(parents=True, exist_ok=True)
+
+ frame_length = model_config.stylize_config["0"]["length"]
+
+ src_imgs = sorted(glob.glob( os.path.join(src_dir, "[0-9]*.png"), recursive=False))
+ for img in src_imgs:
+ n = int(Path(img).stem)
+ if n in range(frame_offset, frame_offset + frame_length):
+ dst_img_path = dst_dir.joinpath( f"{n-frame_offset:08d}.png" )
+ shutil.copy(img, dst_img_path)
+
+ new_prompt_map = {}
+ for p in model_config.prompt_map:
+ n = int(p)
+ if n in range(frame_offset, frame_offset + frame_length):
+ new_prompt_map[str(n-frame_offset)]=model_config.prompt_map[p]
+
+ model_config.prompt_map = new_prompt_map
+
+ model_config.controlnet_map["input_image_dir"] = os.path.relpath(new_controlnet_img_dir.absolute(), data_dir)
+ model_config.img2img_map["init_img_dir"] = os.path.relpath(new_img2img_img_dir.absolute(), data_dir)
+
+ tmp_config_path = stylize_dir.joinpath("prompt_tmp.json")
+ tmp_config_path.write_text(model_config.json(indent=4), encoding="utf-8")
+ config_org = tmp_config_path
+
+
+ output_0_dir = generate(
+ config_path=config_org,
+ width=model_config.stylize_config["0"]["width"],
+ height=model_config.stylize_config["0"]["height"],
+ length=model_config.stylize_config["0"]["length"],
+ context=model_config.stylize_config["0"]["context"],
+ overlap=model_config.stylize_config["0"]["overlap"],
+ stride=model_config.stylize_config["0"]["stride"],
+ out_dir=stylize_dir
+ )
+
+ torch.cuda.empty_cache()
+
+ output_0_dir = output_0_dir.rename(output_0_dir.parent / f"{time_str}_{0:02d}")
+
+
+ if "1" not in model_config.stylize_config:
+ logger.info(f"Stylized results are output to {output_0_dir}")
+ return
+
+ logger.info(f"Intermediate files have been output to {output_0_dir}")
+
+ output_0_img_dir = glob.glob( os.path.join(output_0_dir, "00-[0-9]*"), recursive=False)[0]
+
+ interpolation_multiplier = 1
+ if "interpolation_multiplier" in model_config.stylize_config["1"]:
+ interpolation_multiplier = model_config.stylize_config["1"]["interpolation_multiplier"]
+
+ if interpolation_multiplier > 1:
+ from animatediff.rife.rife import rife_interpolate
+
+ rife_img_dir = stylize_dir.joinpath(f"{1:02d}_rife_frame")
+ if rife_img_dir.is_dir():
+ shutil.rmtree(rife_img_dir)
+ rife_img_dir.mkdir(parents=True, exist_ok=True)
+
+ rife_interpolate(output_0_img_dir, rife_img_dir, interpolation_multiplier)
+ model_config.stylize_config["1"]["length"] *= interpolation_multiplier
+
+ if model_config.output:
+ model_config.output["fps"] *= interpolation_multiplier
+ if model_config.prompt_map:
+ model_config.prompt_map = { str(int(i)*interpolation_multiplier): model_config.prompt_map[i] for i in model_config.prompt_map }
+
+ output_0_img_dir = rife_img_dir
+
+
+ controlnet_img_dir = stylize_dir.joinpath("01_controlnet_image")
+ img2img_dir = stylize_dir.joinpath("01_img2img")
+ img2img_dir.mkdir(parents=True, exist_ok=True)
+
+ create_controlnet_dir(controlnet_img_dir)
+
+ ip2p_for_upscale = model_config.stylize_config["1"]["controlnet_ip2p"]["enable"]
+ ip_adapter_for_upscale = model_config.stylize_config["1"]["ip_adapter"]
+ ref_for_upscale = model_config.stylize_config["1"]["reference"]
+
+ shutil.copytree(output_0_img_dir, controlnet_img_dir.joinpath("controlnet_tile"), dirs_exist_ok=True)
+ if ip2p_for_upscale:
+ shutil.copytree(controlnet_img_dir.joinpath("controlnet_tile"), controlnet_img_dir.joinpath("controlnet_ip2p"), dirs_exist_ok=True)
+
+ shutil.copytree(controlnet_img_dir.joinpath("controlnet_tile"), img2img_dir, dirs_exist_ok=True)
+
+ model_config.controlnet_map["input_image_dir"] = os.path.relpath(controlnet_img_dir.absolute(), data_dir)
+
+ model_config.controlnet_map["controlnet_tile"] = model_config.stylize_config["1"]["controlnet_tile"]
+ model_config.controlnet_map["controlnet_ip2p"] = model_config.stylize_config["1"]["controlnet_ip2p"]
+
+ if "controlnet_ref" in model_config.controlnet_map:
+ model_config.controlnet_map["controlnet_ref"]["enable"] = ref_for_upscale
+
+ model_config.ip_adapter_map["enable"] = ip_adapter_for_upscale
+ for r in model_config.region_map:
+ reg = model_config.region_map[r]
+ if "condition" in reg:
+ if "ip_adapter_map" in reg["condition"]:
+ reg["condition"]["ip_adapter_map"]["enable"] = ip_adapter_for_upscale
+
+ model_config.steps = model_config.stylize_config["1"]["steps"] if "steps" in model_config.stylize_config["1"] else model_config.steps
+ model_config.guidance_scale = model_config.stylize_config["1"]["guidance_scale"] if "guidance_scale" in model_config.stylize_config["1"] else model_config.guidance_scale
+
+ model_config.img2img_map["enable"] = model_config.stylize_config["1"]["img2img"]
+
+ if model_config.img2img_map["enable"]:
+ model_config.img2img_map["init_img_dir"] = os.path.relpath(Path(output_0_img_dir).absolute(), data_dir)
+
+ save_config_path = stylize_dir.joinpath("prompt_01.json")
+ save_config_path.write_text(model_config.json(indent=4), encoding="utf-8")
+
+ output_1_dir = generate(
+ config_path=save_config_path,
+ width=model_config.stylize_config["1"]["width"],
+ height=model_config.stylize_config["1"]["height"],
+ length=model_config.stylize_config["1"]["length"],
+ context=model_config.stylize_config["1"]["context"],
+ overlap=model_config.stylize_config["1"]["overlap"],
+ stride=model_config.stylize_config["1"]["stride"],
+ out_dir=stylize_dir
+ )
+
+ output_1_dir = output_1_dir.rename(output_1_dir.parent / f"{time_str}_{1:02d}")
+
+ logger.info(f"Stylized results are output to {output_1_dir}")
+
+
+
+
+@stylize.command(no_args_is_help=True)
+def interpolate(
+ frame_dir: Annotated[
+ Path,
+ typer.Argument(path_type=Path, file_okay=False, dir_okay=True, exists=True, help="Path to frame dir"),
+ ] = ...,
+ interpolation_multiplier: Annotated[
+ int,
+ typer.Option(
+ "--interpolation_multiplier",
+ "-m",
+ min=1,
+ max=10,
+ help="interpolation_multiplier",
+ ),
+ ] = 1,
+):
+ """Interpolation with original frames. This function does not work well if the shape of the subject is changed from the original video. Large movements can also ruin the picture.(Since this command is experimental, it is better to use other interpolation methods in most cases.)"""
+
+ try:
+ import cupy
+ except:
+ logger.info(f"!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!")
+ logger.info(f"cupy is required to run interpolate")
+ logger.info(f"Your CUDA version is {torch.version.cuda}")
+ logger.info(f"Please find the installation method of cupy for your CUDA version from the following URL")
+ logger.info(f"https://docs.cupy.dev/en/latest/install.html#installing-cupy-from-pypi")
+ logger.info(f"!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!")
+ return
+
+ prepare_softsplat()
+
+ time_str = datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
+
+ config_org = frame_dir.parent.joinpath("prompt.json")
+
+ model_config: ModelConfig = get_model_config(config_org)
+
+ if "original_video" in model_config.stylize_config:
+ org_video = Path(model_config.stylize_config["original_video"]["path"])
+ offset = model_config.stylize_config["original_video"]["offset"]
+ aspect_ratio = model_config.stylize_config["original_video"]["aspect_ratio"]
+ else:
+ logger.warn('!!! The following parameters are required !!!')
+ logger.warn('"stylize_config": {')
+ logger.warn(' "original_video": {')
+ logger.warn(' "path": "C:\\my_movie\\test.mp4",')
+ logger.warn(' "aspect_ratio": 0.6666,')
+ logger.warn(' "offset": 0')
+ logger.warn(' },')
+ raise ValueError('model_config.stylize_config["original_video"] not found')
+
+
+ save_dir = frame_dir.parent.joinpath(f"optflow_{time_str}")
+
+ org_frame_dir = save_dir.joinpath("org_frame")
+ org_frame_dir.mkdir(parents=True, exist_ok=True)
+
+ stylize_frame = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+ stylize_frame_num = len(stylize_frame)
+
+ duration = int(stylize_frame_num / model_config.output["fps"]) + 1
+
+ extract_frames(org_video, model_config.output["fps"] * interpolation_multiplier, org_frame_dir,aspect_ratio,duration,offset)
+
+ W, H = Image.open(stylize_frame[0]).size
+
+ org_frame = sorted(glob.glob( os.path.join(org_frame_dir, "[0-9]*.png"), recursive=False))
+
+ for org in tqdm(org_frame):
+ img = get_resized_image(org, W, H)
+ img.save(org)
+
+ output_dir = save_dir.joinpath("warp_img")
+ output_dir.mkdir(parents=True, exist_ok=True)
+
+ from animatediff.softmax_splatting.run import estimate2
+
+ for sty1,sty2 in tqdm(zip(stylize_frame,stylize_frame[1:]), total=len(stylize_frame[1:])):
+ sty1 = Path(sty1)
+ sty2 = Path(sty2)
+
+ head = int(sty1.stem)
+
+ sty1_img = Image.open(sty1)
+ sty2_img = Image.open(sty2)
+
+ guide_frames=[org_frame_dir.joinpath(f"{g:08d}.png") for g in range(head*interpolation_multiplier, (head+1)*interpolation_multiplier)]
+
+ guide_frames=[Image.open(g) for g in guide_frames]
+
+ result = estimate2(sty1_img, sty2_img, guide_frames, "data/models/softsplat/softsplat-lf")
+
+ shutil.copy( frame_dir.joinpath(f"{head:08d}.png"), output_dir.joinpath(f"{head*interpolation_multiplier:08d}.png"))
+
+ offset = head*interpolation_multiplier + 1
+ for i, r in enumerate(result):
+ r.save( output_dir.joinpath(f"{offset+i:08d}.png") )
+
+
+ from animatediff.generate import save_output
+
+
+ frames = sorted(glob.glob( os.path.join(output_dir, "[0-9]*.png"), recursive=False))
+ out_images = []
+ for f in frames:
+ out_images.append(Image.open(f))
+
+ model_config.output["fps"] *= interpolation_multiplier
+
+ out_file = save_dir.joinpath(f"01_{model_config.output['fps']}fps")
+ save_output(out_images,output_dir,out_file,model_config.output,True,save_frames=None,save_video=None)
+
+ out_file = save_dir.joinpath(f"00_original")
+ save_output(out_images,org_frame_dir,out_file,model_config.output,True,save_frames=None,save_video=None)
+
+
+@stylize.command(no_args_is_help=True)
+def create_mask(
+ stylize_dir: Annotated[
+ Path,
+ typer.Argument(path_type=Path, file_okay=False, dir_okay=True, exists=True, help="Path to stylize dir"),
+ ] = ...,
+ frame_dir: Annotated[
+ Path,
+ typer.Option(
+ "--frame_dir",
+ "-f",
+ path_type=Path,
+ file_okay=False,
+ help="Path to source frames directory. default is 'STYLIZE_DIR/00_img2img'",
+ ),
+ ] = None,
+ box_threshold: Annotated[
+ float,
+ typer.Option(
+ "--box_threshold",
+ "-b",
+ min=0.0,
+ max=1.0,
+ help="box_threshold",
+ rich_help_panel="create mask",
+ ),
+ ] = 0.3,
+ text_threshold: Annotated[
+ float,
+ typer.Option(
+ "--text_threshold",
+ "-t",
+ min=0.0,
+ max=1.0,
+ help="text_threshold",
+ rich_help_panel="create mask",
+ ),
+ ] = 0.25,
+ mask_padding: Annotated[
+ int,
+ typer.Option(
+ "--mask_padding",
+ "-mp",
+ min=-100,
+ max=100,
+ help="padding pixel value",
+ rich_help_panel="create mask",
+ ),
+ ] = 0,
+ no_gb: Annotated[
+ bool,
+ typer.Option(
+ "--no_gb",
+ "-ng",
+ is_flag=True,
+ help="no green back",
+ rich_help_panel="create mask",
+ ),
+ ] = False,
+ no_crop: Annotated[
+ bool,
+ typer.Option(
+ "--no_crop",
+ "-nc",
+ is_flag=True,
+ help="no crop",
+ rich_help_panel="create mask",
+ ),
+ ] = False,
+ use_rembg: Annotated[
+ bool,
+ typer.Option(
+ "--use_rembg",
+ "-rem",
+ is_flag=True,
+ help="use [rembg] instead of [Sam+GroundingDINO]",
+ rich_help_panel="create mask",
+ ),
+ ] = False,
+ use_animeseg: Annotated[
+ bool,
+ typer.Option(
+ "--use_animeseg",
+ "-anim",
+ is_flag=True,
+ help="use [anime-segmentation] instead of [Sam+GroundingDINO]",
+ rich_help_panel="create mask",
+ ),
+ ] = False,
+ low_vram: Annotated[
+ bool,
+ typer.Option(
+ "--low_vram",
+ "-lo",
+ is_flag=True,
+ help="low vram mode",
+ rich_help_panel="create mask/tag",
+ ),
+ ] = False,
+ ignore_list: Annotated[
+ Path,
+ typer.Option(
+ "--ignore-list",
+ "-g",
+ path_type=Path,
+ dir_okay=False,
+ exists=True,
+ help="path to ignore token list file",
+ rich_help_panel="create tag",
+ ),
+ ] = Path("config/prompts/ignore_tokens.txt"),
+ predicte_interval: Annotated[
+ int,
+ typer.Option(
+ "--predicte-interval",
+ "-p",
+ min=1,
+ max=120,
+ help="Interval of frames to be predicted",
+ rich_help_panel="create tag",
+ ),
+ ] = 1,
+ general_threshold: Annotated[
+ float,
+ typer.Option(
+ "--threshold",
+ "-th",
+ min=0.0,
+ max=1.0,
+ help="threshold for general token confidence",
+ rich_help_panel="create tag",
+ ),
+ ] = 0.35,
+ character_threshold: Annotated[
+ float,
+ typer.Option(
+ "--threshold2",
+ "-th2",
+ min=0.0,
+ max=1.0,
+ help="threshold for character token confidence",
+ rich_help_panel="create tag",
+ ),
+ ] = 0.85,
+ without_confidence: Annotated[
+ bool,
+ typer.Option(
+ "--no-confidence-format",
+ "-ncf",
+ is_flag=True,
+ help="confidence token format or not. ex. '(close-up:0.57), (monochrome:1.1)' -> 'close-up, monochrome'",
+ rich_help_panel="create tag",
+ ),
+ ] = False,
+ is_no_danbooru_format: Annotated[
+ bool,
+ typer.Option(
+ "--no-danbooru-format",
+ "-ndf",
+ is_flag=True,
+ help="danbooru token format or not. ex. 'bandaid_on_leg, short_hair' -> 'bandaid on leg, short hair'",
+ rich_help_panel="create tag",
+ ),
+ ] = False,
+):
+ """Create mask from prompt"""
+ from animatediff.utils.mask import (create_bg, create_fg, crop_frames,
+ crop_mask_list, save_crop_info)
+ from animatediff.utils.mask_animseg import animseg_create_fg
+ from animatediff.utils.mask_rembg import rembg_create_fg
+
+ is_danbooru_format = not is_no_danbooru_format
+ with_confidence = not without_confidence
+
+ if use_animeseg and use_rembg:
+ raise ValueError("use_animeseg and use_rembg cannot be enabled at the same time")
+
+ prepare_sam_hq(low_vram)
+ prepare_groundingDINO()
+ prepare_propainter()
+
+ if use_animeseg:
+ prepare_anime_seg()
+
+ time_str = datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
+
+ config_org = stylize_dir.joinpath("prompt.json")
+
+ model_config: ModelConfig = get_model_config(config_org)
+
+ if frame_dir is None:
+ frame_dir = stylize_dir / "00_img2img"
+
+ if not frame_dir.is_dir():
+ raise ValueError(f'{frame_dir=} does not exist.')
+
+ is_img2img = model_config.img2img_map["enable"] if "enable" in model_config.img2img_map else False
+
+
+ create_mask_list = []
+ if "create_mask" in model_config.stylize_config:
+ create_mask_list = model_config.stylize_config["create_mask"]
+ else:
+ raise ValueError('model_config.stylize_config["create_mask"] not found')
+
+ output_list = []
+
+ stylize_frame = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+ frame_len = len(stylize_frame)
+
+ W, H = Image.open(stylize_frame[0]).size
+ org_frame_size = (H,W)
+
+ masked_area = [None for f in range(frame_len)]
+
+ if use_rembg:
+ create_mask_list = ["rembg"]
+ elif use_animeseg:
+ create_mask_list = ["anime-segmentation"]
+
+
+ for i,mask_token in enumerate(create_mask_list):
+ fg_dir = stylize_dir.joinpath(f"fg_{i:02d}_{time_str}")
+ fg_dir.mkdir(parents=True, exist_ok=True)
+
+ create_controlnet_dir( fg_dir / "00_controlnet_image" )
+
+ fg_masked_dir = fg_dir / "00_img2img"
+ fg_masked_dir.mkdir(parents=True, exist_ok=True)
+
+ fg_mask_dir = fg_dir / "00_mask"
+ fg_mask_dir.mkdir(parents=True, exist_ok=True)
+
+ if use_animeseg:
+ masked_area = animseg_create_fg(
+ frame_dir=frame_dir,
+ output_dir=fg_masked_dir,
+ output_mask_dir=fg_mask_dir,
+ masked_area_list=masked_area,
+ mask_padding=mask_padding,
+ bg_color=None if no_gb else (0,255,0),
+ )
+ elif use_rembg:
+ masked_area = rembg_create_fg(
+ frame_dir=frame_dir,
+ output_dir=fg_masked_dir,
+ output_mask_dir=fg_mask_dir,
+ masked_area_list=masked_area,
+ mask_padding=mask_padding,
+ bg_color=None if no_gb else (0,255,0),
+ )
+ else:
+ masked_area = create_fg(
+ mask_token=mask_token,
+ frame_dir=frame_dir,
+ output_dir=fg_masked_dir,
+ output_mask_dir=fg_mask_dir,
+ masked_area_list=masked_area,
+ box_threshold=box_threshold,
+ text_threshold=text_threshold,
+ mask_padding=mask_padding,
+ sam_checkpoint= "data/models/SAM/sam_hq_vit_h.pth" if not low_vram else "data/models/SAM/sam_hq_vit_b.pth",
+ bg_color=None if no_gb else (0,255,0),
+ )
+
+ if not no_crop:
+ frame_size_hw = (masked_area[0].shape[1],masked_area[0].shape[2])
+ cropped_mask_list, mask_pos_list, crop_size_hw = crop_mask_list(masked_area)
+
+ logger.info(f"crop fg_masked_dir")
+ crop_frames(mask_pos_list, crop_size_hw, fg_masked_dir)
+ logger.info(f"crop fg_mask_dir")
+ crop_frames(mask_pos_list, crop_size_hw, fg_mask_dir)
+ save_crop_info(mask_pos_list, crop_size_hw, frame_size_hw, fg_dir / "crop_info.json")
+ else:
+ crop_size_hw = None
+
+ logger.info(f"mask from [{mask_token}] are output to {fg_dir}")
+
+ shutil.copytree(fg_masked_dir, fg_dir / "00_controlnet_image/controlnet_openpose", dirs_exist_ok=True)
+
+ #shutil.copytree(fg_masked_dir, fg_dir / "00_controlnet_image/controlnet_ip2p", dirs_exist_ok=True)
+
+ if crop_size_hw:
+ if crop_size_hw[0] == 0 or crop_size_hw[1] == 0:
+ crop_size_hw = None
+
+ output_list.append((fg_dir, crop_size_hw))
+
+ torch.cuda.empty_cache()
+
+ bg_dir = stylize_dir.joinpath(f"bg_{time_str}")
+ bg_dir.mkdir(parents=True, exist_ok=True)
+ create_controlnet_dir( bg_dir / "00_controlnet_image" )
+ bg_inpaint_dir = bg_dir / "00_img2img"
+ bg_inpaint_dir.mkdir(parents=True, exist_ok=True)
+
+
+ create_bg(frame_dir, bg_inpaint_dir, masked_area,
+ use_half = True,
+ raft_iter = 20,
+ subvideo_length=80 if not low_vram else 50,
+ neighbor_length=10 if not low_vram else 8,
+ ref_stride=10 if not low_vram else 8,
+ low_vram = low_vram,
+ )
+
+ logger.info(f"background are output to {bg_dir}")
+
+ shutil.copytree(bg_inpaint_dir, bg_dir / "00_controlnet_image/controlnet_tile", dirs_exist_ok=True)
+
+ shutil.copytree(bg_inpaint_dir, bg_dir / "00_controlnet_image/controlnet_ip2p", dirs_exist_ok=True)
+
+ output_list.append((bg_dir,None))
+
+ torch.cuda.empty_cache()
+
+ black_list = []
+ if ignore_list.is_file():
+ with open(ignore_list) as f:
+ black_list = [s.strip() for s in f.readlines()]
+
+ for output, size in output_list:
+
+ model_config.prompt_map = get_labels(
+ frame_dir= output / "00_img2img",
+ interval=predicte_interval,
+ general_threshold=general_threshold,
+ character_threshold=character_threshold,
+ ignore_tokens=black_list,
+ with_confidence=with_confidence,
+ is_danbooru_format=is_danbooru_format,
+ is_cpu = False,
+ )
+
+ model_config.controlnet_map["input_image_dir"] = os.path.relpath((output / "00_controlnet_image" ).absolute(), data_dir)
+ model_config.img2img_map["init_img_dir"] = os.path.relpath((output / "00_img2img" ).absolute(), data_dir)
+
+ if size is not None:
+ h, w = size
+ height = 1024 * (h/(h+w))
+ width = 1024 * (w/(h+w))
+ height = int(height//8 * 8)
+ width = int(width//8 * 8)
+
+ model_config.stylize_config["0"]["width"]=width
+ model_config.stylize_config["0"]["height"]=height
+ if "1" in model_config.stylize_config:
+ model_config.stylize_config["1"]["width"]=int(width * 1.25 //8*8)
+ model_config.stylize_config["1"]["height"]=int(height * 1.25 //8*8)
+ else:
+ height, width = org_frame_size
+ model_config.stylize_config["0"]["width"]=width
+ model_config.stylize_config["0"]["height"]=height
+ if "1" in model_config.stylize_config:
+ model_config.stylize_config["1"]["width"]=int(width * 1.25 //8*8)
+ model_config.stylize_config["1"]["height"]=int(height * 1.25 //8*8)
+
+
+
+ save_config_path = output.joinpath("prompt.json")
+ save_config_path.write_text(model_config.json(indent=4), encoding="utf-8")
+
+
+
+
+@stylize.command(no_args_is_help=True)
+def composite(
+ stylize_dir: Annotated[
+ Path,
+ typer.Argument(path_type=Path, file_okay=False, dir_okay=True, exists=True, help="Path to stylize dir"),
+ ] = ...,
+ box_threshold: Annotated[
+ float,
+ typer.Option(
+ "--box_threshold",
+ "-b",
+ min=0.0,
+ max=1.0,
+ help="box_threshold",
+ rich_help_panel="create mask",
+ ),
+ ] = 0.3,
+ text_threshold: Annotated[
+ float,
+ typer.Option(
+ "--text_threshold",
+ "-t",
+ min=0.0,
+ max=1.0,
+ help="text_threshold",
+ rich_help_panel="create mask",
+ ),
+ ] = 0.25,
+ mask_padding: Annotated[
+ int,
+ typer.Option(
+ "--mask_padding",
+ "-mp",
+ min=-100,
+ max=100,
+ help="padding pixel value",
+ rich_help_panel="create mask",
+ ),
+ ] = 0,
+ use_rembg: Annotated[
+ bool,
+ typer.Option(
+ "--use_rembg",
+ "-rem",
+ is_flag=True,
+ help="use \[rembg] instead of \[Sam+GroundingDINO]",
+ rich_help_panel="create mask",
+ ),
+ ] = False,
+ use_animeseg: Annotated[
+ bool,
+ typer.Option(
+ "--use_animeseg",
+ "-anim",
+ is_flag=True,
+ help="use \[anime-segmentation] instead of \[Sam+GroundingDINO]",
+ rich_help_panel="create mask",
+ ),
+ ] = False,
+ low_vram: Annotated[
+ bool,
+ typer.Option(
+ "--low_vram",
+ "-lo",
+ is_flag=True,
+ help="low vram mode",
+ rich_help_panel="create mask/tag",
+ ),
+ ] = False,
+ is_simple_composite: Annotated[
+ bool,
+ typer.Option(
+ "--simple_composite",
+ "-si",
+ is_flag=True,
+ help="simple composite",
+ rich_help_panel="composite",
+ ),
+ ] = False,
+):
+ """composite FG and BG"""
+
+ from animatediff.utils.composite import composite, simple_composite
+ from animatediff.utils.mask import (create_fg, load_frame_list,
+ load_mask_list, restore_position)
+ from animatediff.utils.mask_animseg import animseg_create_fg
+ from animatediff.utils.mask_rembg import rembg_create_fg
+
+ if use_animeseg and use_rembg:
+ raise ValueError("use_animeseg and use_rembg cannot be enabled at the same time")
+
+ prepare_sam_hq(low_vram)
+ if use_animeseg:
+ prepare_anime_seg()
+
+ time_str = datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
+
+ config_org = stylize_dir.joinpath("prompt.json")
+
+ model_config: ModelConfig = get_model_config(config_org)
+
+
+ composite_config = {}
+ if "composite" in model_config.stylize_config:
+ composite_config = model_config.stylize_config["composite"]
+ else:
+ raise ValueError('model_config.stylize_config["composite"] not found')
+
+ save_dir = stylize_dir.joinpath(f"cp_{time_str}")
+ save_dir.mkdir(parents=True, exist_ok=True)
+
+ save_config_path = save_dir.joinpath("prompt.json")
+ save_config_path.write_text(model_config.json(indent=4), encoding="utf-8")
+
+
+ bg_dir = composite_config["bg_frame_dir"]
+ bg_dir = Path(bg_dir)
+ if not bg_dir.is_dir():
+ raise ValueError('model_config.stylize_config["composite"]["bg_frame_dir"] not valid')
+
+ frame_len = len(sorted(glob.glob( os.path.join(bg_dir, "[0-9]*.png"), recursive=False)))
+
+ fg_list = composite_config["fg_list"]
+
+ for i, fg_param in enumerate(fg_list):
+ mask_token = fg_param["mask_prompt"]
+ frame_dir = Path(fg_param["path"])
+ if not frame_dir.is_dir():
+ logger.warn(f"{frame_dir=} not valid -> skip")
+ continue
+
+ mask_dir = Path(fg_param["mask_path"])
+ if not mask_dir.is_dir():
+ logger.info(f"{mask_dir=} not valid -> create mask")
+
+ fg_tmp_dir = save_dir.joinpath(f"fg_{i:02d}_{time_str}")
+ fg_tmp_dir.mkdir(parents=True, exist_ok=True)
+
+ masked_area_list = [None for f in range(frame_len)]
+
+ if use_animeseg:
+ mask_list = animseg_create_fg(
+ frame_dir=frame_dir,
+ output_dir=fg_tmp_dir,
+ output_mask_dir=None,
+ masked_area_list=masked_area_list,
+ mask_padding=mask_padding,
+ )
+ elif use_rembg:
+ mask_list = rembg_create_fg(
+ frame_dir=frame_dir,
+ output_dir=fg_tmp_dir,
+ output_mask_dir=None,
+ masked_area_list=masked_area_list,
+ mask_padding=mask_padding,
+ )
+ else:
+ mask_list = create_fg(
+ mask_token=mask_token,
+ frame_dir=frame_dir,
+ output_dir=fg_tmp_dir,
+ output_mask_dir=None,
+ masked_area_list=masked_area_list,
+ box_threshold=box_threshold,
+ text_threshold=text_threshold,
+ mask_padding=mask_padding,
+ sam_checkpoint= "data/models/SAM/sam_hq_vit_h.pth" if not low_vram else "data/models/SAM/sam_hq_vit_b.pth",
+ )
+
+ else:
+ logger.info(f"use {mask_dir=} as mask")
+
+ masked_area_list = [None for f in range(frame_len)]
+
+ mask_list = load_mask_list(mask_dir, masked_area_list, mask_padding)
+
+ mask_list = [ m.transpose([1,2,0]) if m is not None else m for m in mask_list]
+
+ crop_info_path = frame_dir.parent.parent / "crop_info.json"
+ crop_info={}
+ if crop_info_path.is_file():
+ with open(crop_info_path, mode="rt", encoding="utf-8") as f:
+ crop_info = json.load(f)
+ mask_list = restore_position(mask_list, crop_info)
+
+
+ fg_list = [None for f in range(frame_len)]
+ fg_list = load_frame_list(frame_dir, fg_list, crop_info)
+
+ output_dir = save_dir.joinpath(f"bg_{i:02d}_{time_str}")
+ output_dir.mkdir(parents=True, exist_ok=True)
+
+ if is_simple_composite:
+ simple_composite(bg_dir, fg_list, output_dir, mask_list)
+ else:
+ composite(bg_dir, fg_list, output_dir, mask_list)
+
+ bg_dir = output_dir
+
+
+ from animatediff.generate import save_output
+
+ frames = sorted(glob.glob( os.path.join(bg_dir, "[0-9]*.png"), recursive=False))
+ out_images = []
+ for f in frames:
+ out_images.append(Image.open(f))
+
+ out_file = save_dir.joinpath(f"composite")
+ save_output(out_images,bg_dir,out_file,model_config.output,True,save_frames=None,save_video=None)
+
+ logger.info(f"output to {out_file}")
+
+
+
+
+@stylize.command(no_args_is_help=True)
+def create_region(
+ stylize_dir: Annotated[
+ Path,
+ typer.Argument(path_type=Path, file_okay=False, dir_okay=True, exists=True, help="Path to stylize dir"),
+ ] = ...,
+ frame_dir: Annotated[
+ Path,
+ typer.Option(
+ "--frame_dir",
+ "-f",
+ path_type=Path,
+ file_okay=False,
+ help="Path to source frames directory. default is 'STYLIZE_DIR/00_img2img'",
+ ),
+ ] = None,
+ box_threshold: Annotated[
+ float,
+ typer.Option(
+ "--box_threshold",
+ "-b",
+ min=0.0,
+ max=1.0,
+ help="box_threshold",
+ rich_help_panel="create mask",
+ ),
+ ] = 0.3,
+ text_threshold: Annotated[
+ float,
+ typer.Option(
+ "--text_threshold",
+ "-t",
+ min=0.0,
+ max=1.0,
+ help="text_threshold",
+ rich_help_panel="create mask",
+ ),
+ ] = 0.25,
+ mask_padding: Annotated[
+ int,
+ typer.Option(
+ "--mask_padding",
+ "-mp",
+ min=-100,
+ max=100,
+ help="padding pixel value",
+ rich_help_panel="create mask",
+ ),
+ ] = 0,
+ use_rembg: Annotated[
+ bool,
+ typer.Option(
+ "--use_rembg",
+ "-rem",
+ is_flag=True,
+ help="use [rembg] instead of [Sam+GroundingDINO]",
+ rich_help_panel="create mask",
+ ),
+ ] = False,
+ use_animeseg: Annotated[
+ bool,
+ typer.Option(
+ "--use_animeseg",
+ "-anim",
+ is_flag=True,
+ help="use [anime-segmentation] instead of [Sam+GroundingDINO]",
+ rich_help_panel="create mask",
+ ),
+ ] = False,
+ low_vram: Annotated[
+ bool,
+ typer.Option(
+ "--low_vram",
+ "-lo",
+ is_flag=True,
+ help="low vram mode",
+ rich_help_panel="create mask/tag",
+ ),
+ ] = False,
+ ignore_list: Annotated[
+ Path,
+ typer.Option(
+ "--ignore-list",
+ "-g",
+ path_type=Path,
+ dir_okay=False,
+ exists=True,
+ help="path to ignore token list file",
+ rich_help_panel="create tag",
+ ),
+ ] = Path("config/prompts/ignore_tokens.txt"),
+ predicte_interval: Annotated[
+ int,
+ typer.Option(
+ "--predicte-interval",
+ "-p",
+ min=1,
+ max=120,
+ help="Interval of frames to be predicted",
+ rich_help_panel="create tag",
+ ),
+ ] = 1,
+ general_threshold: Annotated[
+ float,
+ typer.Option(
+ "--threshold",
+ "-th",
+ min=0.0,
+ max=1.0,
+ help="threshold for general token confidence",
+ rich_help_panel="create tag",
+ ),
+ ] = 0.35,
+ character_threshold: Annotated[
+ float,
+ typer.Option(
+ "--threshold2",
+ "-th2",
+ min=0.0,
+ max=1.0,
+ help="threshold for character token confidence",
+ rich_help_panel="create tag",
+ ),
+ ] = 0.85,
+ without_confidence: Annotated[
+ bool,
+ typer.Option(
+ "--no-confidence-format",
+ "-ncf",
+ is_flag=True,
+ help="confidence token format or not. ex. '(close-up:0.57), (monochrome:1.1)' -> 'close-up, monochrome'",
+ rich_help_panel="create tag",
+ ),
+ ] = False,
+ is_no_danbooru_format: Annotated[
+ bool,
+ typer.Option(
+ "--no-danbooru-format",
+ "-ndf",
+ is_flag=True,
+ help="danbooru token format or not. ex. 'bandaid_on_leg, short_hair' -> 'bandaid on leg, short hair'",
+ rich_help_panel="create tag",
+ ),
+ ] = False,
+):
+ """Create region from prompt"""
+ from animatediff.utils.mask import create_bg, create_fg
+ from animatediff.utils.mask_animseg import animseg_create_fg
+ from animatediff.utils.mask_rembg import rembg_create_fg
+
+ is_danbooru_format = not is_no_danbooru_format
+ with_confidence = not without_confidence
+
+ if use_animeseg and use_rembg:
+ raise ValueError("use_animeseg and use_rembg cannot be enabled at the same time")
+
+ prepare_sam_hq(low_vram)
+ prepare_groundingDINO()
+ prepare_propainter()
+
+ if use_animeseg:
+ prepare_anime_seg()
+
+ time_str = datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
+
+ config_org = stylize_dir.joinpath("prompt.json")
+
+ model_config: ModelConfig = get_model_config(config_org)
+
+ if frame_dir is None:
+ frame_dir = stylize_dir / "00_img2img"
+
+ if not frame_dir.is_dir():
+ raise ValueError(f'{frame_dir=} does not exist.')
+
+
+ create_mask_list = []
+ if "create_mask" in model_config.stylize_config:
+ create_mask_list = model_config.stylize_config["create_mask"]
+ else:
+ raise ValueError('model_config.stylize_config["create_mask"] not found')
+
+ output_list = []
+
+ stylize_frame = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+ frame_len = len(stylize_frame)
+
+ masked_area = [None for f in range(frame_len)]
+
+ if use_rembg:
+ create_mask_list = ["rembg"]
+ elif use_animeseg:
+ create_mask_list = ["anime-segmentation"]
+
+
+ for i,mask_token in enumerate(create_mask_list):
+ fg_dir = stylize_dir.joinpath(f"r_fg_{i:02d}_{time_str}")
+ fg_dir.mkdir(parents=True, exist_ok=True)
+
+ fg_masked_dir = fg_dir / "00_tmp_masked"
+ fg_masked_dir.mkdir(parents=True, exist_ok=True)
+
+ fg_mask_dir = fg_dir / "00_mask"
+ fg_mask_dir.mkdir(parents=True, exist_ok=True)
+
+ if use_animeseg:
+ masked_area = animseg_create_fg(
+ frame_dir=frame_dir,
+ output_dir=fg_masked_dir,
+ output_mask_dir=fg_mask_dir,
+ masked_area_list=masked_area,
+ mask_padding=mask_padding,
+ bg_color=(0,255,0),
+ )
+ elif use_rembg:
+ masked_area = rembg_create_fg(
+ frame_dir=frame_dir,
+ output_dir=fg_masked_dir,
+ output_mask_dir=fg_mask_dir,
+ masked_area_list=masked_area,
+ mask_padding=mask_padding,
+ bg_color=(0,255,0),
+ )
+ else:
+ masked_area = create_fg(
+ mask_token=mask_token,
+ frame_dir=frame_dir,
+ output_dir=fg_masked_dir,
+ output_mask_dir=fg_mask_dir,
+ masked_area_list=masked_area,
+ box_threshold=box_threshold,
+ text_threshold=text_threshold,
+ mask_padding=mask_padding,
+ sam_checkpoint= "data/models/SAM/sam_hq_vit_h.pth" if not low_vram else "data/models/SAM/sam_hq_vit_b.pth",
+ bg_color=(0,255,0),
+ )
+
+ logger.info(f"mask from [{mask_token}] are output to {fg_dir}")
+
+ output_list.append((fg_dir, fg_masked_dir, fg_mask_dir))
+
+ torch.cuda.empty_cache()
+
+ bg_dir = stylize_dir.joinpath(f"r_bg_{time_str}")
+ bg_dir.mkdir(parents=True, exist_ok=True)
+
+ bg_inpaint_dir = bg_dir / "00_tmp_inpainted"
+ bg_inpaint_dir.mkdir(parents=True, exist_ok=True)
+
+
+ create_bg(frame_dir, bg_inpaint_dir, masked_area,
+ use_half = True,
+ raft_iter = 20,
+ subvideo_length=80 if not low_vram else 50,
+ neighbor_length=10 if not low_vram else 8,
+ ref_stride=10 if not low_vram else 8,
+ low_vram = low_vram,
+ )
+
+ logger.info(f"background are output to {bg_dir}")
+
+
+ output_list.append((bg_dir,bg_inpaint_dir,None))
+
+ torch.cuda.empty_cache()
+
+ black_list = []
+ if ignore_list.is_file():
+ with open(ignore_list) as f:
+ black_list = [s.strip() for s in f.readlines()]
+
+ black_list.append("simple_background")
+ black_list.append("green_background")
+
+ region_map = {}
+
+ for i, (output_root, masked_dir, mask_dir) in enumerate(output_list):
+
+ prompt_map = get_labels(
+ frame_dir= masked_dir,
+ interval=predicte_interval,
+ general_threshold=general_threshold,
+ character_threshold=character_threshold,
+ ignore_tokens=black_list,
+ with_confidence=with_confidence,
+ is_danbooru_format=is_danbooru_format,
+ is_cpu = False,
+ )
+
+ if mask_dir:
+
+ ipadapter_dir = output_root / "00_ipadapter"
+ ipadapter_dir.mkdir(parents=True, exist_ok=True)
+
+ region_map[str(i)]={
+ "enable": True,
+ "crop_generation_rate": 0.0,
+ "mask_dir" : os.path.relpath(mask_dir.absolute(), data_dir),
+ "save_mask": True,
+ "is_init_img" : False,
+ "condition" : {
+ "prompt_fixed_ratio": 0.5,
+ "head_prompt": "",
+ "prompt_map": prompt_map,
+ "tail_prompt": "",
+ "ip_adapter_map": {
+ "enable": True,
+ "input_image_dir": os.path.relpath(ipadapter_dir.absolute(), data_dir),
+ "prompt_fixed_ratio": 0.5,
+ "save_input_image": True,
+ "resized_to_square": False
+ }
+ }
+ }
+ else:
+ region_map["background"]={
+ "is_init_img" : False,
+ "hint" : "background's condition refers to the one in root"
+ }
+
+ model_config.prompt_map = prompt_map
+
+
+ model_config.region_map =region_map
+
+
+ config_org.write_text(model_config.json(indent=4), encoding="utf-8")
+
+
diff --git a/animate/src/animatediff/utils/__init__.py b/animate/src/animatediff/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/animate/src/animatediff/utils/civitai2config.py b/animate/src/animatediff/utils/civitai2config.py
new file mode 100644
index 0000000000000000000000000000000000000000..c1ee6a4a84a2068478c4654858856e2fa2339c08
--- /dev/null
+++ b/animate/src/animatediff/utils/civitai2config.py
@@ -0,0 +1,122 @@
+import glob
+import json
+import logging
+import os
+import re
+import shutil
+from pathlib import Path
+
+from animatediff import get_dir
+
+logger = logging.getLogger(__name__)
+
+data_dir = get_dir("data")
+
+extra_loading_regex = r'(<[^>]+?>)'
+
+def generate_config_from_civitai_info(
+ lora_dir:Path,
+ config_org:Path,
+ out_dir:Path,
+ lora_weight:float,
+):
+ lora_abs_dir = lora_dir.absolute()
+ config_org = config_org.absolute()
+ out_dir = out_dir.absolute()
+
+ civitais = sorted(glob.glob( os.path.join(lora_abs_dir, "*.civitai.info"), recursive=False))
+
+ with open(config_org, "r") as cf:
+ org_config = json.load(cf)
+
+ for civ in civitais:
+
+ logger.info(f"convert {civ}")
+
+ with open(civ, "r") as f:
+ # trim .civitai.info
+ name = os.path.splitext(os.path.splitext(os.path.basename(civ))[0])[0]
+
+ output_path = out_dir.joinpath(name + ".json")
+
+ if os.path.isfile(output_path):
+ logger.info("already converted -> skip")
+ continue
+
+ if os.path.isfile( lora_abs_dir.joinpath(name + ".safetensors")):
+ lora_path = os.path.relpath(lora_abs_dir.joinpath(name + ".safetensors"), data_dir)
+ elif os.path.isfile( lora_abs_dir.joinpath(name + ".ckpt")):
+ lora_path = os.path.relpath(lora_abs_dir.joinpath(name + ".ckpt"), data_dir)
+ else:
+ logger.info("lora file not found -> skip")
+ continue
+
+ info = json.load(f)
+
+ if not info:
+ logger.info(f"empty civitai info -> skip")
+ continue
+
+ if info["model"]["type"] not in ("LORA","lora"):
+ logger.info(f"unsupported type {info['model']['type']} -> skip")
+ continue
+
+ new_config = org_config.copy()
+
+ new_config["name"] = name
+
+ new_prompt_map = {}
+ new_n_prompt = ""
+ new_seed = -1
+
+
+ raw_prompt_map = {}
+
+ i = 0
+ for img_info in info["images"]:
+ if img_info["meta"]:
+ try:
+ raw_prompt = img_info["meta"]["prompt"]
+ except Exception as e:
+ logger.info("missing prompt")
+ continue
+
+ raw_prompt_map[str(10000 + i*32)] = raw_prompt
+
+ new_prompt_map[str(i*32)] = re.sub(extra_loading_regex, '', raw_prompt)
+
+ if not new_n_prompt:
+ try:
+ new_n_prompt = img_info["meta"]["negativePrompt"]
+ except Exception as e:
+ new_n_prompt = ""
+ if new_seed == -1:
+ try:
+ new_seed = img_info["meta"]["seed"]
+ except Exception as e:
+ new_seed = -1
+
+ i += 1
+
+ if not new_prompt_map:
+ new_prompt_map[str(0)] = ""
+
+ for k in raw_prompt_map:
+ # comment
+ new_prompt_map[k] = raw_prompt_map[k]
+
+ new_config["prompt_map"] = new_prompt_map
+ new_config["n_prompt"] = [new_n_prompt]
+ new_config["seed"] = [new_seed]
+
+ new_config["lora_map"] = {lora_path.replace(os.sep,'/'):lora_weight}
+
+ with open( out_dir.joinpath(name + ".json"), 'w') as wf:
+ json.dump(new_config, wf, indent=4)
+ logger.info("converted!")
+
+ preview = lora_abs_dir.joinpath(name + ".preview.png")
+ if preview.is_file():
+ shutil.copy(preview, out_dir.joinpath(name + ".preview.png"))
+
+
diff --git a/animate/src/animatediff/utils/composite.py b/animate/src/animatediff/utils/composite.py
new file mode 100644
index 0000000000000000000000000000000000000000..191a8553dcc9e512ecd4e2e5e5740e6622634475
--- /dev/null
+++ b/animate/src/animatediff/utils/composite.py
@@ -0,0 +1,202 @@
+import glob
+import logging
+import os
+import shutil
+from pathlib import Path
+
+import cv2
+import numpy as np
+import torch
+import torch.nn.functional as F
+from PIL import Image
+from tqdm.rich import tqdm
+
+logger = logging.getLogger(__name__)
+
+
+#https://github.com/jinwonkim93/laplacian-pyramid-blend
+#https://blog.shikoan.com/pytorch-laplacian-pyramid/
+class LaplacianPyramidBlender:
+
+ device = None
+
+ def get_gaussian_kernel(self):
+ kernel = np.array([
+ [1, 4, 6, 4, 1],
+ [4, 16, 24, 16, 4],
+ [6, 24, 36, 24, 6],
+ [4, 16, 24, 16, 4],
+ [1, 4, 6, 4, 1]], np.float32) / 256.0
+ gaussian_k = torch.as_tensor(kernel.reshape(1, 1, 5, 5),device=self.device)
+ return gaussian_k
+
+ def pyramid_down(self, image):
+ with torch.no_grad():
+ gaussian_k = self.get_gaussian_kernel()
+ multiband = [F.conv2d(image[:, i:i + 1,:,:], gaussian_k, padding=2, stride=2) for i in range(3)]
+ down_image = torch.cat(multiband, dim=1)
+ return down_image
+
+ def pyramid_up(self, image, size = None):
+ with torch.no_grad():
+ gaussian_k = self.get_gaussian_kernel()
+ if size is None:
+ upsample = F.interpolate(image, scale_factor=2)
+ else:
+ upsample = F.interpolate(image, size=size)
+ multiband = [F.conv2d(upsample[:, i:i + 1,:,:], gaussian_k, padding=2) for i in range(3)]
+ up_image = torch.cat(multiband, dim=1)
+ return up_image
+
+ def gaussian_pyramid(self, original, n_pyramids):
+ x = original
+ # pyramid down
+ pyramids = [original]
+ for i in range(n_pyramids):
+ x = self.pyramid_down(x)
+ pyramids.append(x)
+ return pyramids
+
+ def laplacian_pyramid(self, original, n_pyramids):
+ pyramids = self.gaussian_pyramid(original, n_pyramids)
+
+ # pyramid up - diff
+ laplacian = []
+ for i in range(len(pyramids) - 1):
+ diff = pyramids[i] - self.pyramid_up(pyramids[i + 1], pyramids[i].shape[2:])
+ laplacian.append(diff)
+
+ laplacian.append(pyramids[-1])
+ return laplacian
+
+ def laplacian_pyramid_blending_with_mask(self, src, target, mask, num_levels = 9):
+ # assume mask is float32 [0,1]
+
+ # generate Gaussian pyramid for src,target and mask
+
+ Gsrc = torch.as_tensor(np.expand_dims(src, axis=0), device=self.device)
+ Gtarget = torch.as_tensor(np.expand_dims(target, axis=0), device=self.device)
+ Gmask = torch.as_tensor(np.expand_dims(mask, axis=0), device=self.device)
+
+ lpA = self.laplacian_pyramid(Gsrc,num_levels)[::-1]
+ lpB = self.laplacian_pyramid(Gtarget,num_levels)[::-1]
+ gpMr = self.gaussian_pyramid(Gmask,num_levels)[::-1]
+
+ # Now blend images according to mask in each level
+ LS = []
+ for idx, (la,lb,Gmask) in enumerate(zip(lpA,lpB,gpMr)):
+ lo = lb * (1.0 - Gmask)
+ if idx <= 2:
+ lo += lb * Gmask
+ else:
+ lo += la * Gmask
+ LS.append(lo)
+
+ # now reconstruct
+ ls_ = LS.pop(0)
+ for lap in LS:
+ ls_ = self.pyramid_up(ls_, lap.shape[2:]) + lap
+
+ result = ls_.squeeze(dim=0).to('cpu').detach().numpy().copy()
+
+ return result
+
+ def __call__(self,
+ src_image: np.ndarray,
+ target_image: np.ndarray,
+ mask_image: np.ndarray,
+ device
+ ):
+
+ self.device = device
+
+ num_levels = int(np.log2(src_image.shape[0]))
+ #normalize image to 0, 1
+ mask_image = np.clip(mask_image, 0, 1).transpose([2, 0, 1])
+
+ src_image = src_image.transpose([2, 0, 1]).astype(np.float32) / 255.0
+ target_image = target_image.transpose([2, 0, 1]).astype(np.float32) / 255.0
+ composite_image = self.laplacian_pyramid_blending_with_mask(src_image, target_image, mask_image, num_levels)
+ composite_image = np.clip(composite_image*255, 0 , 255).astype(np.uint8)
+ composite_image=composite_image.transpose([1, 2, 0])
+ return composite_image
+
+
+def composite(bg_dir, fg_list, output_dir, masked_area_list, device="cuda"):
+ bg_list = sorted(glob.glob( os.path.join(bg_dir ,"[0-9]*.png"), recursive=False))
+
+ blender = LaplacianPyramidBlender()
+
+ for bg, fg_array, mask in tqdm(zip(bg_list, fg_list, masked_area_list),total=len(bg_list), desc="compositing"):
+ name = Path(bg).name
+ save_path = output_dir / name
+
+ if fg_array is None:
+ logger.info(f"composite fg_array is None -> skip")
+ shutil.copy(bg, save_path)
+ continue
+
+ if mask is None:
+ logger.info(f"mask is None -> skip")
+ shutil.copy(bg, save_path)
+ continue
+
+ bg = np.asarray(Image.open(bg)).copy()
+ fg = fg_array
+ mask = np.concatenate([mask, mask, mask], 2)
+
+ h, w, _ = bg.shape
+
+ fg = cv2.resize(fg, dsize=(w,h))
+ mask = cv2.resize(mask, dsize=(w,h))
+
+
+ mask = mask.astype(np.float32)
+# mask = mask * 255
+ mask = cv2.GaussianBlur(mask, (15, 15), 0)
+ mask = mask / 255
+
+ fg = fg * mask + bg * (1-mask)
+
+ img = blender(fg, bg, mask,device)
+
+
+ img = Image.fromarray(img)
+ img.save(save_path)
+
+def simple_composite(bg_dir, fg_list, output_dir, masked_area_list, device="cuda"):
+ bg_list = sorted(glob.glob( os.path.join(bg_dir ,"[0-9]*.png"), recursive=False))
+
+ for bg, fg_array, mask in tqdm(zip(bg_list, fg_list, masked_area_list),total=len(bg_list), desc="compositing"):
+ name = Path(bg).name
+ save_path = output_dir / name
+
+ if fg_array is None:
+ logger.info(f"composite fg_array is None -> skip")
+ shutil.copy(bg, save_path)
+ continue
+
+ if mask is None:
+ logger.info(f"mask is None -> skip")
+ shutil.copy(bg, save_path)
+ continue
+
+ bg = np.asarray(Image.open(bg)).copy()
+ fg = fg_array
+ mask = np.concatenate([mask, mask, mask], 2)
+
+ h, w, _ = bg.shape
+
+ fg = cv2.resize(fg, dsize=(w,h))
+ mask = cv2.resize(mask, dsize=(w,h))
+
+
+ mask = mask.astype(np.float32)
+ mask = cv2.GaussianBlur(mask, (15, 15), 0)
+ mask = mask / 255
+
+ img = fg * mask + bg * (1-mask)
+ img = img.clip(0 , 255).astype(np.uint8)
+
+ img = Image.fromarray(img)
+ img.save(save_path)
\ No newline at end of file
diff --git a/animate/src/animatediff/utils/control_net_lllite.py b/animate/src/animatediff/utils/control_net_lllite.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c83cd4d75b44a48ea8dfa7b20e7bf7fb95957cf
--- /dev/null
+++ b/animate/src/animatediff/utils/control_net_lllite.py
@@ -0,0 +1,526 @@
+# https://github.com/kohya-ss/sd-scripts/blob/main/networks/control_net_lllite.py
+
+import bisect
+import os
+from typing import Any, List, Mapping, Optional, Type
+
+import torch
+
+from animatediff.utils.util import show_bytes
+
+# input_blocksに適用するかどうか / if True, input_blocks are not applied
+SKIP_INPUT_BLOCKS = False
+
+# output_blocksに適用するかどうか / if True, output_blocks are not applied
+SKIP_OUTPUT_BLOCKS = True
+
+# conv2dに適用するかどうか / if True, conv2d are not applied
+SKIP_CONV2D = False
+
+# transformer_blocksのみに適用するかどうか。Trueの場合、ResBlockには適用されない
+# if True, only transformer_blocks are applied, and ResBlocks are not applied
+TRANSFORMER_ONLY = True # if True, SKIP_CONV2D is ignored because conv2d is not used in transformer_blocks
+
+# Trueならattn1とattn2にのみ適用し、ffなどには適用しない / if True, apply only to attn1 and attn2, not to ff etc.
+ATTN1_2_ONLY = True
+
+# Trueならattn1のQKV、attn2のQにのみ適用する、ATTN1_2_ONLY指定時のみ有効 / if True, apply only to attn1 QKV and attn2 Q, only valid when ATTN1_2_ONLY is specified
+ATTN_QKV_ONLY = True
+
+# Trueならattn1やffなどにのみ適用し、attn2などには適用しない / if True, apply only to attn1 and ff, not to attn2
+# ATTN1_2_ONLYと同時にTrueにできない / cannot be True at the same time as ATTN1_2_ONLY
+ATTN1_ETC_ONLY = False # True
+
+# transformer_blocksの最大インデックス。Noneなら全てのtransformer_blocksに適用
+# max index of transformer_blocks. if None, apply to all transformer_blocks
+TRANSFORMER_MAX_BLOCK_INDEX = None
+
+
+class LLLiteModule(torch.nn.Module):
+ def __init__(self, depth, cond_emb_dim, name, org_module, mlp_dim, dropout=None, multiplier=1.0):
+ super().__init__()
+ self.cond_cache ={}
+
+ self.is_conv2d = org_module.__class__.__name__ == "Conv2d" or org_module.__class__.__name__ == "LoRACompatibleConv"
+ self.lllite_name = name
+ self.cond_emb_dim = cond_emb_dim
+ self.org_module = [org_module]
+ self.dropout = dropout
+ self.multiplier = multiplier
+
+ if self.is_conv2d:
+ in_dim = org_module.in_channels
+ else:
+ in_dim = org_module.in_features
+
+ # conditioning1はconditioning imageを embedding する。timestepごとに呼ばれない
+ # conditioning1 embeds conditioning image. it is not called for each timestep
+ modules = []
+ modules.append(torch.nn.Conv2d(3, cond_emb_dim // 2, kernel_size=4, stride=4, padding=0)) # to latent (from VAE) size
+ if depth == 1:
+ modules.append(torch.nn.ReLU(inplace=True))
+ modules.append(torch.nn.Conv2d(cond_emb_dim // 2, cond_emb_dim, kernel_size=2, stride=2, padding=0))
+ elif depth == 2:
+ modules.append(torch.nn.ReLU(inplace=True))
+ modules.append(torch.nn.Conv2d(cond_emb_dim // 2, cond_emb_dim, kernel_size=4, stride=4, padding=0))
+ elif depth == 3:
+ # kernel size 8は大きすぎるので、4にする / kernel size 8 is too large, so set it to 4
+ modules.append(torch.nn.ReLU(inplace=True))
+ modules.append(torch.nn.Conv2d(cond_emb_dim // 2, cond_emb_dim // 2, kernel_size=4, stride=4, padding=0))
+ modules.append(torch.nn.ReLU(inplace=True))
+ modules.append(torch.nn.Conv2d(cond_emb_dim // 2, cond_emb_dim, kernel_size=2, stride=2, padding=0))
+
+ self.conditioning1 = torch.nn.Sequential(*modules)
+
+ # downで入力の次元数を削減する。LoRAにヒントを得ていることにする
+ # midでconditioning image embeddingと入力を結合する
+ # upで元の次元数に戻す
+ # これらはtimestepごとに呼ばれる
+ # reduce the number of input dimensions with down. inspired by LoRA
+ # combine conditioning image embedding and input with mid
+ # restore to the original dimension with up
+ # these are called for each timestep
+
+ if self.is_conv2d:
+ self.down = torch.nn.Sequential(
+ torch.nn.Conv2d(in_dim, mlp_dim, kernel_size=1, stride=1, padding=0),
+ torch.nn.ReLU(inplace=True),
+ )
+ self.mid = torch.nn.Sequential(
+ torch.nn.Conv2d(mlp_dim + cond_emb_dim, mlp_dim, kernel_size=1, stride=1, padding=0),
+ torch.nn.ReLU(inplace=True),
+ )
+ self.up = torch.nn.Sequential(
+ torch.nn.Conv2d(mlp_dim, in_dim, kernel_size=1, stride=1, padding=0),
+ )
+ else:
+ # midの前にconditioningをreshapeすること / reshape conditioning before mid
+ self.down = torch.nn.Sequential(
+ torch.nn.Linear(in_dim, mlp_dim),
+ torch.nn.ReLU(inplace=True),
+ )
+ self.mid = torch.nn.Sequential(
+ torch.nn.Linear(mlp_dim + cond_emb_dim, mlp_dim),
+ torch.nn.ReLU(inplace=True),
+ )
+ self.up = torch.nn.Sequential(
+ torch.nn.Linear(mlp_dim, in_dim),
+ )
+
+ # Zero-Convにする / set to Zero-Conv
+ torch.nn.init.zeros_(self.up[0].weight) # zero conv
+
+ self.depth = depth # 1~3
+ self.cond_emb = None
+ self.batch_cond_only = False # Trueなら推論時のcondにのみ適用する / if True, apply only to cond at inference
+ self.use_zeros_for_batch_uncond = False # Trueならuncondのconditioningを0にする / if True, set uncond conditioning to 0
+
+ # batch_cond_onlyとuse_zeros_for_batch_uncondはどちらも適用すると生成画像の色味がおかしくなるので実際には使えそうにない
+ # Controlの種類によっては使えるかも
+ # both batch_cond_only and use_zeros_for_batch_uncond make the color of the generated image strange, so it doesn't seem to be usable in practice
+ # it may be available depending on the type of Control
+
+ def _set_cond_image(self, cond_image):
+ r"""
+ 中でモデルを呼び出すので必要ならwith torch.no_grad()で囲む
+ / call the model inside, so if necessary, surround it with torch.no_grad()
+ """
+ if cond_image is None:
+ self.cond_emb = None
+ return
+
+ # timestepごとに呼ばれないので、あらかじめ計算しておく / it is not called for each timestep, so calculate it in advance
+ # print(f"C {self.lllite_name}, cond_image.shape={cond_image.shape}")
+ cx = self.conditioning1(cond_image)
+ if not self.is_conv2d:
+ # reshape / b,c,h,w -> b,h*w,c
+ n, c, h, w = cx.shape
+ cx = cx.view(n, c, h * w).permute(0, 2, 1)
+ self.cond_emb = cx
+
+ def set_cond_image(self, cond_image, cond_key):
+ self.cond_image = cond_image
+ self.cond_key = cond_key
+ #self.cond_emb = None
+ self.cond_emb = self.get_cond_emb(self.cond_key, "cuda", torch.float16)
+
+ def set_batch_cond_only(self, cond_only, zeros):
+ self.batch_cond_only = cond_only
+ self.use_zeros_for_batch_uncond = zeros
+
+ def apply_to(self):
+ self.org_forward = self.org_module[0].forward
+ self.org_module[0].forward = self.forward
+
+ def unapply_to(self):
+ self.org_module[0].forward = self.org_forward
+ self.cond_cache ={}
+
+ def get_cond_emb(self, key, device, dtype):
+ #if key in self.cond_cache:
+ # return self.cond_cache[key].to(device, dtype=dtype, non_blocking=True)
+ cx = self.conditioning1(self.cond_image.to(device, dtype=dtype))
+ if not self.is_conv2d:
+ # reshape / b,c,h,w -> b,h*w,c
+ n, c, h, w = cx.shape
+ cx = cx.view(n, c, h * w).permute(0, 2, 1)
+ #self.cond_cache[key] = cx.to("cpu", non_blocking=True)
+ return cx
+
+
+ def forward(self, x, scale=1.0):
+ r"""
+ 学習用の便利forward。元のモジュールのforwardを呼び出す
+ / convenient forward for training. call the forward of the original module
+ """
+# if self.multiplier == 0.0 or self.cond_emb is None:
+ if (type(self.multiplier) is int and self.multiplier == 0.0) or self.cond_emb is None:
+ return self.org_forward(x)
+
+ if self.cond_emb is None:
+ # print(f"cond_emb is None, {self.name}")
+ '''
+ cx = self.conditioning1(self.cond_image.to(x.device, dtype=x.dtype))
+ if not self.is_conv2d:
+ # reshape / b,c,h,w -> b,h*w,c
+ n, c, h, w = cx.shape
+ cx = cx.view(n, c, h * w).permute(0, 2, 1)
+ #show_bytes("self.conditioning1", self.conditioning1)
+ #show_bytes("cx", cx)
+ '''
+ self.cond_emb = self.get_cond_emb(self.cond_key, x.device, x.dtype)
+
+
+ cx = self.cond_emb
+
+ if not self.batch_cond_only and x.shape[0] // 2 == cx.shape[0]: # inference only
+ cx = cx.repeat(2, 1, 1, 1) if self.is_conv2d else cx.repeat(2, 1, 1)
+ if self.use_zeros_for_batch_uncond:
+ cx[0::2] = 0.0 # uncond is zero
+ # print(f"C {self.lllite_name}, x.shape={x.shape}, cx.shape={cx.shape}")
+
+ # downで入力の次元数を削減し、conditioning image embeddingと結合する
+ # 加算ではなくchannel方向に結合することで、うまいこと混ぜてくれることを期待している
+ # down reduces the number of input dimensions and combines it with conditioning image embedding
+ # we expect that it will mix well by combining in the channel direction instead of adding
+
+ cx = torch.cat([cx, self.down(x if not self.batch_cond_only else x[1::2])], dim=1 if self.is_conv2d else 2)
+ cx = self.mid(cx)
+
+ if self.dropout is not None and self.training:
+ cx = torch.nn.functional.dropout(cx, p=self.dropout)
+
+ cx = self.up(cx) * self.multiplier
+
+ #print(f"{self.multiplier=}")
+ #print(f"{cx.shape=}")
+
+ #mul = torch.tensor(self.multiplier).to(x.device, dtype=x.dtype)
+ #cx = cx * mul[:,None,None]
+
+ # residual (x) を加算して元のforwardを呼び出す / add residual (x) and call the original forward
+ if self.batch_cond_only:
+ zx = torch.zeros_like(x)
+ zx[1::2] += cx
+ cx = zx
+
+ x = self.org_forward(x + cx) # ここで元のモジュールを呼び出す / call the original module here
+ return x
+
+
+
+
+class ControlNetLLLite(torch.nn.Module):
+ UNET_TARGET_REPLACE_MODULE = ["Transformer2DModel"]
+ UNET_TARGET_REPLACE_MODULE_CONV2D_3X3 = ["ResnetBlock2D", "Downsample2D", "Upsample2D"]
+
+ def __init__(
+ self,
+ unet,
+ cond_emb_dim: int = 16,
+ mlp_dim: int = 16,
+ dropout: Optional[float] = None,
+ varbose: Optional[bool] = False,
+ multiplier: Optional[float] = 1.0,
+ ) -> None:
+ super().__init__()
+ # self.unets = [unet]
+
+ def create_modules(
+ root_module: torch.nn.Module,
+ target_replace_modules: List[torch.nn.Module],
+ module_class: Type[object],
+ ) -> List[torch.nn.Module]:
+ prefix = "lllite_unet"
+
+ modules = []
+ for name, module in root_module.named_modules():
+ if module.__class__.__name__ in target_replace_modules:
+ for child_name, child_module in module.named_modules():
+ is_linear = child_module.__class__.__name__ == "Linear" or child_module.__class__.__name__ == "LoRACompatibleLinear"
+ is_conv2d = child_module.__class__.__name__ == "Conv2d" or child_module.__class__.__name__ == "LoRACompatibleConv"
+
+ if is_linear or (is_conv2d and not SKIP_CONV2D):
+ # block indexからdepthを計算: depthはconditioningのサイズやチャネルを計算するのに使う
+ # block index to depth: depth is using to calculate conditioning size and channels
+ #print(f"{name=} {child_name=}")
+
+ #block_name, index1, index2 = (name + "." + child_name).split(".")[:3]
+ #index1 = int(index1)
+ block_name, num1, block_name2 ,num2 = (name + "." + child_name).split(".")[:4]
+
+ #if block_name == "input_blocks":
+ """
+ hf_down_res_prefix = f"down_blocks.{i}.resnets.{j}."
+ sd_down_res_prefix = f"input_blocks.{3*i + j + 1}.0."
+
+ hf_downsample_prefix = f"down_blocks.{i}.downsamplers.0.conv."
+ sd_downsample_prefix = f"input_blocks.{3*(i+1)}.0.op."
+ """
+ if block_name == "down_blocks" and block_name2=="downsamplers":
+ index1 = 3*(int(num1)+1)
+ if SKIP_INPUT_BLOCKS:
+ continue
+ depth = 1 if index1 <= 2 else (2 if index1 <= 5 else 3)
+ elif block_name == "down_blocks":
+ index1 = 3*int(num1)+int(num2)+1
+ if SKIP_INPUT_BLOCKS:
+ continue
+ depth = 1 if index1 <= 2 else (2 if index1 <= 5 else 3)
+
+ #elif block_name == "middle_block":
+ elif block_name == "mid_block":
+ depth = 3
+
+ #elif block_name == "output_blocks":
+ """
+ hf_up_res_prefix = f"up_blocks.{i}.resnets.{j}."
+ sd_up_res_prefix = f"output_blocks.{3*i + j}.0."
+
+ hf_upsample_prefix = f"up_blocks.{i}.upsamplers.0."
+ sd_upsample_prefix = f"output_blocks.{3*i + 2}.{2}." # change for sdxl
+ """
+ elif block_name == "up_blocks" and block_name2=="upsamplers":
+
+ index1 = 3*int(num1)+2
+ if SKIP_OUTPUT_BLOCKS:
+ continue
+ depth = 3 if index1 <= 2 else (2 if index1 <= 5 else 1)
+ #if int(index2) >= 2:
+ if block_name2 == "upsamplers":
+ depth -= 1
+ elif block_name == "up_blocks":
+ index1 = 3*int(num1)+int(num2)
+ if SKIP_OUTPUT_BLOCKS:
+ continue
+ depth = 3 if index1 <= 2 else (2 if index1 <= 5 else 1)
+ #if int(index2) >= 2:
+ if block_name2 == "upsamplers":
+ depth -= 1
+ else:
+ raise NotImplementedError()
+
+ lllite_name = prefix + "." + name + "." + child_name
+ lllite_name = lllite_name.replace(".", "_")
+
+ if TRANSFORMER_MAX_BLOCK_INDEX is not None:
+ p = lllite_name.find("transformer_blocks")
+ if p >= 0:
+ tf_index = int(lllite_name[p:].split("_")[2])
+ if tf_index > TRANSFORMER_MAX_BLOCK_INDEX:
+ continue
+
+ # time embは適用外とする
+ # attn2のconditioning (CLIPからの入力) はshapeが違うので適用できない
+ # time emb is not applied
+ # attn2 conditioning (input from CLIP) cannot be applied because the shape is different
+ '''
+ if "emb_layers" in lllite_name or (
+ "attn2" in lllite_name and ("to_k" in lllite_name or "to_v" in lllite_name)
+ ):
+ continue
+ '''
+ #("emb_layers.1.", "time_emb_proj."),
+ if "time_emb_proj" in lllite_name or (
+ "attn2" in lllite_name and ("to_k" in lllite_name or "to_v" in lllite_name)
+ ):
+ continue
+
+ if ATTN1_2_ONLY:
+ if not ("attn1" in lllite_name or "attn2" in lllite_name):
+ continue
+ if ATTN_QKV_ONLY:
+ if "to_out" in lllite_name:
+ continue
+
+ if ATTN1_ETC_ONLY:
+ if "proj_out" in lllite_name:
+ pass
+ elif "attn1" in lllite_name and (
+ "to_k" in lllite_name or "to_v" in lllite_name or "to_out" in lllite_name
+ ):
+ pass
+ elif "ff_net_2" in lllite_name:
+ pass
+ else:
+ continue
+
+ module = module_class(
+ depth,
+ cond_emb_dim,
+ lllite_name,
+ child_module,
+ mlp_dim,
+ dropout=dropout,
+ multiplier=multiplier,
+ )
+ modules.append(module)
+ return modules
+
+ target_modules = ControlNetLLLite.UNET_TARGET_REPLACE_MODULE
+ if not TRANSFORMER_ONLY:
+ target_modules = target_modules + ControlNetLLLite.UNET_TARGET_REPLACE_MODULE_CONV2D_3X3
+
+ # create module instances
+ self.unet_modules: List[LLLiteModule] = create_modules(unet, target_modules, LLLiteModule)
+ print(f"create ControlNet LLLite for U-Net: {len(self.unet_modules)} modules.")
+
+ def forward(self, x):
+ return x # dummy
+
+ def set_cond_image(self, cond_image, cond_key):
+ r"""
+ 中でモデルを呼び出すので必要ならwith torch.no_grad()で囲む
+ / call the model inside, so if necessary, surround it with torch.no_grad()
+ """
+ for module in self.unet_modules:
+ module.set_cond_image(cond_image,cond_key)
+
+ def set_batch_cond_only(self, cond_only, zeros):
+ for module in self.unet_modules:
+ module.set_batch_cond_only(cond_only, zeros)
+
+ def set_multiplier(self, multiplier):
+ if isinstance(multiplier, list):
+ multiplier = torch.tensor(multiplier).to("cuda", dtype=torch.float16, non_blocking=True)
+ multiplier = multiplier[:,None,None]
+
+ for module in self.unet_modules:
+ module.multiplier = multiplier
+
+ def load_weights(self, file):
+ if os.path.splitext(file)[1] == ".safetensors":
+ from safetensors.torch import load_file
+
+ weights_sd = load_file(file)
+ else:
+ weights_sd = torch.load(file, map_location="cpu")
+
+ info = self.load_state_dict(weights_sd, False)
+ return info
+
+ def apply_to(self):
+ print("applying LLLite for U-Net...")
+ for module in self.unet_modules:
+ module.apply_to()
+ self.add_module(module.lllite_name, module)
+
+ def unapply_to(self):
+ for module in self.unet_modules:
+ module.unapply_to()
+
+ # マージできるかどうかを返す
+ def is_mergeable(self):
+ return False
+
+ def merge_to(self, text_encoder, unet, weights_sd, dtype, device):
+ raise NotImplementedError()
+
+ def enable_gradient_checkpointing(self):
+ # not supported
+ pass
+
+ def prepare_optimizer_params(self):
+ self.requires_grad_(True)
+ return self.parameters()
+
+ def prepare_grad_etc(self):
+ self.requires_grad_(True)
+
+ def on_epoch_start(self):
+ self.train()
+
+ def get_trainable_params(self):
+ return self.parameters()
+
+ def save_weights(self, file, dtype, metadata):
+ if metadata is not None and len(metadata) == 0:
+ metadata = None
+
+ state_dict = self.state_dict()
+
+ if dtype is not None:
+ for key in list(state_dict.keys()):
+ v = state_dict[key]
+ v = v.detach().clone().to("cpu").to(dtype)
+ state_dict[key] = v
+
+ if os.path.splitext(file)[1] == ".safetensors":
+ from safetensors.torch import save_file
+
+ save_file(state_dict, file, metadata)
+ else:
+ torch.save(state_dict, file)
+
+ def load_state_dict(self, state_dict: Mapping[str, Any], strict: bool = True):
+ from animatediff.utils.lora_diffusers import UNET_CONVERSION_MAP
+
+ # convert SDXL Stability AI's state dict to Diffusers' based state dict
+ map_keys = list(UNET_CONVERSION_MAP.keys()) # prefix of U-Net modules
+ map_keys.sort()
+ for key in list(state_dict.keys()):
+ if key.startswith("lllite_unet" + "_"):
+ search_key = key.replace("lllite_unet" + "_", "")
+ position = bisect.bisect_right(map_keys, search_key)
+ map_key = map_keys[position - 1]
+ if search_key.startswith(map_key):
+ new_key = key.replace(map_key, UNET_CONVERSION_MAP[map_key])
+ state_dict[new_key] = state_dict[key]
+ del state_dict[key]
+
+ # in case of V2, some weights have different shape, so we need to convert them
+ # because V2 LoRA is based on U-Net created by use_linear_projection=False
+ my_state_dict = self.state_dict()
+ for key in state_dict.keys():
+ if state_dict[key].size() != my_state_dict[key].size():
+ # print(f"convert {key} from {state_dict[key].size()} to {my_state_dict[key].size()}")
+ state_dict[key] = state_dict[key].view(my_state_dict[key].size())
+
+ return super().load_state_dict(state_dict, strict)
+
+
+def load_controlnet_lllite(model_file, pipe, torch_dtype=torch.float16):
+ print(f"loading ControlNet-LLLite: {model_file}")
+
+ from safetensors.torch import load_file
+
+ state_dict = load_file(model_file)
+ mlp_dim = None
+ cond_emb_dim = None
+ for key, value in state_dict.items():
+ if mlp_dim is None and "down.0.weight" in key:
+ mlp_dim = value.shape[0]
+ elif cond_emb_dim is None and "conditioning1.0" in key:
+ cond_emb_dim = value.shape[0] * 2
+ if mlp_dim is not None and cond_emb_dim is not None:
+ break
+ assert mlp_dim is not None and cond_emb_dim is not None, f"invalid control net: {model_file}"
+
+ control_net = ControlNetLLLite(pipe.unet, cond_emb_dim, mlp_dim, multiplier=1.0)
+ control_net.apply_to()
+ info = control_net.load_state_dict(state_dict, False)
+ print(info)
+ #control_net.to(dtype).to(device)
+ control_net.to(torch_dtype)
+ control_net.set_batch_cond_only(False, False)
+ return control_net
diff --git a/animate/src/animatediff/utils/convert_from_ckpt.py b/animate/src/animatediff/utils/convert_from_ckpt.py
new file mode 100644
index 0000000000000000000000000000000000000000..84e21397639a911ea236b11754e55c1421b17609
--- /dev/null
+++ b/animate/src/animatediff/utils/convert_from_ckpt.py
@@ -0,0 +1,794 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Conversion script for the Stable Diffusion checkpoints."""
+
+import re
+from io import BytesIO
+from typing import Optional
+
+import requests
+import torch
+from diffusers.models import (AutoencoderKL, ControlNetModel, PriorTransformer,
+ UNet2DConditionModel)
+from diffusers.schedulers import DDIMScheduler
+from diffusers.utils import (is_accelerate_available,
+ logging)
+from transformers import CLIPTextConfig, CLIPTextModel
+
+if is_accelerate_available():
+ from accelerate import init_empty_weights
+ from accelerate.utils import set_module_tensor_to_device
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+def is_safetensors_available():
+ return True
+
+def shave_segments(path, n_shave_prefix_segments=1):
+ """
+ Removes segments. Positive values shave the first segments, negative shave the last segments.
+ """
+ if n_shave_prefix_segments >= 0:
+ return ".".join(path.split(".")[n_shave_prefix_segments:])
+ else:
+ return ".".join(path.split(".")[:n_shave_prefix_segments])
+
+
+def renew_resnet_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside resnets to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item.replace("in_layers.0", "norm1")
+ new_item = new_item.replace("in_layers.2", "conv1")
+
+ new_item = new_item.replace("out_layers.0", "norm2")
+ new_item = new_item.replace("out_layers.3", "conv2")
+
+ new_item = new_item.replace("emb_layers.1", "time_emb_proj")
+ new_item = new_item.replace("skip_connection", "conv_shortcut")
+
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def renew_vae_resnet_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside resnets to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ new_item = new_item.replace("nin_shortcut", "conv_shortcut")
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def renew_attention_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside attentions to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ # new_item = new_item.replace('norm.weight', 'group_norm.weight')
+ # new_item = new_item.replace('norm.bias', 'group_norm.bias')
+
+ # new_item = new_item.replace('proj_out.weight', 'proj_attn.weight')
+ # new_item = new_item.replace('proj_out.bias', 'proj_attn.bias')
+
+ # new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def renew_vae_attention_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside attentions to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ new_item = new_item.replace("norm.weight", "group_norm.weight")
+ new_item = new_item.replace("norm.bias", "group_norm.bias")
+
+ new_item = new_item.replace("q.weight", "to_q.weight")
+ new_item = new_item.replace("q.bias", "to_q.bias")
+
+ new_item = new_item.replace("k.weight", "to_k.weight")
+ new_item = new_item.replace("k.bias", "to_k.bias")
+
+ new_item = new_item.replace("v.weight", "to_v.weight")
+ new_item = new_item.replace("v.bias", "to_v.bias")
+
+ new_item = new_item.replace("proj_out.weight", "to_out.0.weight")
+ new_item = new_item.replace("proj_out.bias", "to_out.0.bias")
+
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def assign_to_checkpoint(
+ paths,
+ checkpoint,
+ old_checkpoint,
+ attention_paths_to_split=None,
+ additional_replacements=None,
+ config=None,
+):
+ """
+ This does the final conversion step: take locally converted weights and apply a global renaming to them. It splits
+ attention layers, and takes into account additional replacements that may arise.
+
+ Assigns the weights to the new checkpoint.
+ """
+ assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
+
+ # Splits the attention layers into three variables.
+ if attention_paths_to_split is not None:
+ for path, path_map in attention_paths_to_split.items():
+ old_tensor = old_checkpoint[path]
+ channels = old_tensor.shape[0] // 3
+
+ target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1)
+
+ num_heads = old_tensor.shape[0] // config["num_head_channels"] // 3
+
+ old_tensor = old_tensor.reshape((num_heads, 3 * channels // num_heads) + old_tensor.shape[1:])
+ query, key, value = old_tensor.split(channels // num_heads, dim=1)
+
+ checkpoint[path_map["query"]] = query.reshape(target_shape)
+ checkpoint[path_map["key"]] = key.reshape(target_shape)
+ checkpoint[path_map["value"]] = value.reshape(target_shape)
+
+ for path in paths:
+ new_path = path["new"]
+
+ # These have already been assigned
+ if attention_paths_to_split is not None and new_path in attention_paths_to_split:
+ continue
+
+ # Global renaming happens here
+ new_path = new_path.replace("middle_block.0", "mid_block.resnets.0")
+ new_path = new_path.replace("middle_block.1", "mid_block.attentions.0")
+ new_path = new_path.replace("middle_block.2", "mid_block.resnets.1")
+
+ if additional_replacements is not None:
+ for replacement in additional_replacements:
+ new_path = new_path.replace(replacement["old"], replacement["new"])
+
+ # proj_attn.weight has to be converted from conv 1D to linear
+ is_attn_weight = "proj_attn.weight" in new_path or ("attentions" in new_path and "to_" in new_path)
+ shape = old_checkpoint[path["old"]].shape
+ if is_attn_weight and len(shape) == 3:
+ checkpoint[new_path] = old_checkpoint[path["old"]][:, :, 0]
+ elif is_attn_weight and len(shape) == 4:
+ checkpoint[new_path] = old_checkpoint[path["old"]][:, :, 0, 0]
+ else:
+ checkpoint[new_path] = old_checkpoint[path["old"]]
+
+
+def conv_attn_to_linear(checkpoint):
+ keys = list(checkpoint.keys())
+ attn_keys = ["query.weight", "key.weight", "value.weight"]
+ for key in keys:
+ if ".".join(key.split(".")[-2:]) in attn_keys:
+ if checkpoint[key].ndim > 2:
+ checkpoint[key] = checkpoint[key][:, :, 0, 0]
+ elif "proj_attn.weight" in key:
+ if checkpoint[key].ndim > 2:
+ checkpoint[key] = checkpoint[key][:, :, 0]
+
+
+def create_unet_diffusers_config(original_config, image_size: int, controlnet=False):
+ """
+ Creates a config for the diffusers based on the config of the LDM model.
+ """
+ if controlnet:
+ unet_params = original_config.model.params.control_stage_config.params
+ else:
+ if (
+ "unet_config" in original_config.model.params
+ and original_config.model.params.unet_config is not None
+ ):
+ unet_params = original_config.model.params.unet_config.params
+ else:
+ unet_params = original_config.model.params.network_config.params
+
+ vae_params = original_config.model.params.first_stage_config.params.ddconfig
+
+ block_out_channels = [unet_params.model_channels * mult for mult in unet_params.channel_mult]
+
+ down_block_types = []
+ resolution = 1
+ for i in range(len(block_out_channels)):
+ block_type = (
+ "CrossAttnDownBlock2D" if resolution in unet_params.attention_resolutions else "DownBlock2D"
+ )
+ down_block_types.append(block_type)
+ if i != len(block_out_channels) - 1:
+ resolution *= 2
+
+ up_block_types = []
+ for i in range(len(block_out_channels)):
+ block_type = "CrossAttnUpBlock2D" if resolution in unet_params.attention_resolutions else "UpBlock2D"
+ up_block_types.append(block_type)
+ resolution //= 2
+
+ if unet_params.transformer_depth is not None:
+ transformer_layers_per_block = (
+ unet_params.transformer_depth
+ if isinstance(unet_params.transformer_depth, int)
+ else list(unet_params.transformer_depth)
+ )
+ else:
+ transformer_layers_per_block = 1
+
+ vae_scale_factor = 2 ** (len(vae_params.ch_mult) - 1)
+
+ head_dim = unet_params.num_heads if "num_heads" in unet_params else None
+ use_linear_projection = (
+ unet_params.use_linear_in_transformer if "use_linear_in_transformer" in unet_params else False
+ )
+ if use_linear_projection:
+ # stable diffusion 2-base-512 and 2-768
+ if head_dim is None:
+ head_dim_mult = unet_params.model_channels // unet_params.num_head_channels
+ head_dim = [head_dim_mult * c for c in list(unet_params.channel_mult)]
+
+ class_embed_type = None
+ addition_embed_type = None
+ addition_time_embed_dim = None
+ projection_class_embeddings_input_dim = None
+ context_dim = None
+
+ if unet_params.context_dim is not None:
+ context_dim = (
+ unet_params.context_dim
+ if isinstance(unet_params.context_dim, int)
+ else unet_params.context_dim[0]
+ )
+
+ if "num_classes" in unet_params:
+ if unet_params.num_classes == "sequential":
+ if context_dim in [2048, 1280]:
+ # SDXL
+ addition_embed_type = "text_time"
+ addition_time_embed_dim = 256
+ else:
+ class_embed_type = "projection"
+ assert "adm_in_channels" in unet_params
+ projection_class_embeddings_input_dim = unet_params.adm_in_channels
+ else:
+ raise NotImplementedError(
+ f"Unknown conditional unet num_classes config: {unet_params.num_classes}"
+ )
+
+ config = {
+ "sample_size": image_size // vae_scale_factor,
+ "in_channels": unet_params.in_channels,
+ "down_block_types": tuple(down_block_types),
+ "block_out_channels": tuple(block_out_channels),
+ "layers_per_block": unet_params.num_res_blocks,
+ "cross_attention_dim": context_dim,
+ "attention_head_dim": head_dim,
+ "use_linear_projection": use_linear_projection,
+ "class_embed_type": class_embed_type,
+ "addition_embed_type": addition_embed_type,
+ "addition_time_embed_dim": addition_time_embed_dim,
+ "projection_class_embeddings_input_dim": projection_class_embeddings_input_dim,
+ "transformer_layers_per_block": transformer_layers_per_block,
+ }
+
+ if controlnet:
+ config["conditioning_channels"] = unet_params.hint_channels
+ else:
+ config["out_channels"] = unet_params.out_channels
+ config["up_block_types"] = tuple(up_block_types)
+
+ return config
+
+
+def create_vae_diffusers_config(original_config, image_size: int):
+ """
+ Creates a config for the diffusers based on the config of the LDM model.
+ """
+ vae_params = original_config.model.params.first_stage_config.params.ddconfig
+ _ = original_config.model.params.first_stage_config.params.embed_dim
+
+ block_out_channels = [vae_params.ch * mult for mult in vae_params.ch_mult]
+ down_block_types = ["DownEncoderBlock2D"] * len(block_out_channels)
+ up_block_types = ["UpDecoderBlock2D"] * len(block_out_channels)
+
+ config = {
+ "sample_size": image_size,
+ "in_channels": vae_params.in_channels,
+ "out_channels": vae_params.out_ch,
+ "down_block_types": tuple(down_block_types),
+ "up_block_types": tuple(up_block_types),
+ "block_out_channels": tuple(block_out_channels),
+ "latent_channels": vae_params.z_channels,
+ "layers_per_block": vae_params.num_res_blocks,
+ }
+ return config
+
+
+def create_diffusers_schedular(original_config):
+ schedular = DDIMScheduler(
+ num_train_timesteps=original_config.model.params.timesteps,
+ beta_start=original_config.model.params.linear_start,
+ beta_end=original_config.model.params.linear_end,
+ beta_schedule="scaled_linear",
+ )
+ return schedular
+
+
+def convert_ldm_unet_checkpoint(
+ checkpoint, config, path=None, extract_ema=False, controlnet=False, skip_extract_state_dict=False
+):
+ """
+ Takes a state dict and a config, and returns a converted checkpoint.
+ """
+
+ if skip_extract_state_dict:
+ unet_state_dict = checkpoint
+ else:
+ # extract state_dict for UNet
+ unet_state_dict = {}
+ keys = list(checkpoint.keys())
+
+ if controlnet:
+ unet_key = "control_model."
+ else:
+ unet_key = "model.diffusion_model."
+
+ # at least a 100 parameters have to start with `model_ema` in order for the checkpoint to be EMA
+ if sum(k.startswith("model_ema") for k in keys) > 100 and extract_ema:
+ logger.warning(f"Checkpoint {path} has both EMA and non-EMA weights.")
+ logger.warning(
+ "In this conversion only the EMA weights are extracted. If you want to instead extract the non-EMA"
+ " weights (useful to continue fine-tuning), please make sure to remove the `--extract_ema` flag."
+ )
+ for key in keys:
+ if key.startswith("model.diffusion_model"):
+ flat_ema_key = "model_ema." + "".join(key.split(".")[1:])
+ unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(flat_ema_key)
+ else:
+ if sum(k.startswith("model_ema") for k in keys) > 100:
+ logger.warning(
+ "In this conversion only the non-EMA weights are extracted. If you want to instead extract the EMA"
+ " weights (usually better for inference), please make sure to add the `--extract_ema` flag."
+ )
+
+ for key in keys:
+ if key.startswith(unet_key):
+ unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(key)
+
+ new_checkpoint = {}
+
+ new_checkpoint["time_embedding.linear_1.weight"] = unet_state_dict["time_embed.0.weight"]
+ new_checkpoint["time_embedding.linear_1.bias"] = unet_state_dict["time_embed.0.bias"]
+ new_checkpoint["time_embedding.linear_2.weight"] = unet_state_dict["time_embed.2.weight"]
+ new_checkpoint["time_embedding.linear_2.bias"] = unet_state_dict["time_embed.2.bias"]
+
+ if config["class_embed_type"] is None:
+ # No parameters to port
+ ...
+ elif config["class_embed_type"] == "timestep" or config["class_embed_type"] == "projection":
+ new_checkpoint["class_embedding.linear_1.weight"] = unet_state_dict["label_emb.0.0.weight"]
+ new_checkpoint["class_embedding.linear_1.bias"] = unet_state_dict["label_emb.0.0.bias"]
+ new_checkpoint["class_embedding.linear_2.weight"] = unet_state_dict["label_emb.0.2.weight"]
+ new_checkpoint["class_embedding.linear_2.bias"] = unet_state_dict["label_emb.0.2.bias"]
+ else:
+ raise NotImplementedError(f"Not implemented `class_embed_type`: {config['class_embed_type']}")
+
+ if config["addition_embed_type"] == "text_time":
+ new_checkpoint["add_embedding.linear_1.weight"] = unet_state_dict["label_emb.0.0.weight"]
+ new_checkpoint["add_embedding.linear_1.bias"] = unet_state_dict["label_emb.0.0.bias"]
+ new_checkpoint["add_embedding.linear_2.weight"] = unet_state_dict["label_emb.0.2.weight"]
+ new_checkpoint["add_embedding.linear_2.bias"] = unet_state_dict["label_emb.0.2.bias"]
+
+ new_checkpoint["conv_in.weight"] = unet_state_dict["input_blocks.0.0.weight"]
+ new_checkpoint["conv_in.bias"] = unet_state_dict["input_blocks.0.0.bias"]
+
+ if not controlnet:
+ new_checkpoint["conv_norm_out.weight"] = unet_state_dict["out.0.weight"]
+ new_checkpoint["conv_norm_out.bias"] = unet_state_dict["out.0.bias"]
+ new_checkpoint["conv_out.weight"] = unet_state_dict["out.2.weight"]
+ new_checkpoint["conv_out.bias"] = unet_state_dict["out.2.bias"]
+
+ # Retrieves the keys for the input blocks only
+ num_input_blocks = len(
+ {".".join(layer.split(".")[:2]) for layer in unet_state_dict if "input_blocks" in layer}
+ )
+ input_blocks = {
+ layer_id: [key for key in unet_state_dict if f"input_blocks.{layer_id}" in key]
+ for layer_id in range(num_input_blocks)
+ }
+
+ # Retrieves the keys for the middle blocks only
+ num_middle_blocks = len(
+ {".".join(layer.split(".")[:2]) for layer in unet_state_dict if "middle_block" in layer}
+ )
+ middle_blocks = {
+ layer_id: [key for key in unet_state_dict if f"middle_block.{layer_id}" in key]
+ for layer_id in range(num_middle_blocks)
+ }
+
+ # Retrieves the keys for the output blocks only
+ num_output_blocks = len(
+ {".".join(layer.split(".")[:2]) for layer in unet_state_dict if "output_blocks" in layer}
+ )
+ output_blocks = {
+ layer_id: [key for key in unet_state_dict if f"output_blocks.{layer_id}" in key]
+ for layer_id in range(num_output_blocks)
+ }
+
+ for i in range(1, num_input_blocks):
+ block_id = (i - 1) // (config["layers_per_block"] + 1)
+ layer_in_block_id = (i - 1) % (config["layers_per_block"] + 1)
+
+ resnets = [
+ key
+ for key in input_blocks[i]
+ if f"input_blocks.{i}.0" in key and f"input_blocks.{i}.0.op" not in key
+ ]
+ attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key]
+
+ if f"input_blocks.{i}.0.op.weight" in unet_state_dict:
+ new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.weight"] = unet_state_dict.pop(
+ f"input_blocks.{i}.0.op.weight"
+ )
+ new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.bias"] = unet_state_dict.pop(
+ f"input_blocks.{i}.0.op.bias"
+ )
+
+ paths = renew_resnet_paths(resnets)
+ meta_path = {
+ "old": f"input_blocks.{i}.0",
+ "new": f"down_blocks.{block_id}.resnets.{layer_in_block_id}",
+ }
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ if len(attentions):
+ paths = renew_attention_paths(attentions)
+ meta_path = {
+ "old": f"input_blocks.{i}.1",
+ "new": f"down_blocks.{block_id}.attentions.{layer_in_block_id}",
+ }
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ resnet_0 = middle_blocks[0]
+ attentions = middle_blocks[1]
+ resnet_1 = middle_blocks[2]
+
+ resnet_0_paths = renew_resnet_paths(resnet_0)
+ assign_to_checkpoint(resnet_0_paths, new_checkpoint, unet_state_dict, config=config)
+
+ resnet_1_paths = renew_resnet_paths(resnet_1)
+ assign_to_checkpoint(resnet_1_paths, new_checkpoint, unet_state_dict, config=config)
+
+ attentions_paths = renew_attention_paths(attentions)
+ meta_path = {"old": "middle_block.1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(
+ attentions_paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ for i in range(num_output_blocks):
+ block_id = i // (config["layers_per_block"] + 1)
+ layer_in_block_id = i % (config["layers_per_block"] + 1)
+ output_block_layers = [shave_segments(name, 2) for name in output_blocks[i]]
+ output_block_list = {}
+
+ for layer in output_block_layers:
+ layer_id, layer_name = layer.split(".")[0], shave_segments(layer, 1)
+ if layer_id in output_block_list:
+ output_block_list[layer_id].append(layer_name)
+ else:
+ output_block_list[layer_id] = [layer_name]
+
+ if len(output_block_list) > 1:
+ resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.0" in key]
+ attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.1" in key]
+
+ resnet_0_paths = renew_resnet_paths(resnets)
+ paths = renew_resnet_paths(resnets)
+
+ meta_path = {
+ "old": f"output_blocks.{i}.0",
+ "new": f"up_blocks.{block_id}.resnets.{layer_in_block_id}",
+ }
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ output_block_list = {k: sorted(v) for k, v in output_block_list.items()}
+ if ["conv.bias", "conv.weight"] in output_block_list.values():
+ index = list(output_block_list.values()).index(["conv.bias", "conv.weight"])
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = unet_state_dict[
+ f"output_blocks.{i}.{index}.conv.weight"
+ ]
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = unet_state_dict[
+ f"output_blocks.{i}.{index}.conv.bias"
+ ]
+
+ # Clear attentions as they have been attributed above.
+ if len(attentions) == 2:
+ attentions = []
+
+ if len(attentions):
+ paths = renew_attention_paths(attentions)
+ meta_path = {
+ "old": f"output_blocks.{i}.1",
+ "new": f"up_blocks.{block_id}.attentions.{layer_in_block_id}",
+ }
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+ else:
+ resnet_0_paths = renew_resnet_paths(output_block_layers, n_shave_prefix_segments=1)
+ for path in resnet_0_paths:
+ old_path = ".".join(["output_blocks", str(i), path["old"]])
+ new_path = ".".join(
+ ["up_blocks", str(block_id), "resnets", str(layer_in_block_id), path["new"]]
+ )
+
+ new_checkpoint[new_path] = unet_state_dict[old_path]
+
+ if controlnet:
+ # conditioning embedding
+
+ orig_index = 0
+
+ new_checkpoint["controlnet_cond_embedding.conv_in.weight"] = unet_state_dict.pop(
+ f"input_hint_block.{orig_index}.weight"
+ )
+ new_checkpoint["controlnet_cond_embedding.conv_in.bias"] = unet_state_dict.pop(
+ f"input_hint_block.{orig_index}.bias"
+ )
+
+ orig_index += 2
+
+ diffusers_index = 0
+
+ while diffusers_index < 6:
+ new_checkpoint[
+ f"controlnet_cond_embedding.blocks.{diffusers_index}.weight"
+ ] = unet_state_dict.pop(f"input_hint_block.{orig_index}.weight")
+ new_checkpoint[f"controlnet_cond_embedding.blocks.{diffusers_index}.bias"] = unet_state_dict.pop(
+ f"input_hint_block.{orig_index}.bias"
+ )
+ diffusers_index += 1
+ orig_index += 2
+
+ new_checkpoint["controlnet_cond_embedding.conv_out.weight"] = unet_state_dict.pop(
+ f"input_hint_block.{orig_index}.weight"
+ )
+ new_checkpoint["controlnet_cond_embedding.conv_out.bias"] = unet_state_dict.pop(
+ f"input_hint_block.{orig_index}.bias"
+ )
+
+ # down blocks
+ for i in range(num_input_blocks):
+ new_checkpoint[f"controlnet_down_blocks.{i}.weight"] = unet_state_dict.pop(
+ f"zero_convs.{i}.0.weight"
+ )
+ new_checkpoint[f"controlnet_down_blocks.{i}.bias"] = unet_state_dict.pop(f"zero_convs.{i}.0.bias")
+
+ # mid block
+ new_checkpoint["controlnet_mid_block.weight"] = unet_state_dict.pop("middle_block_out.0.weight")
+ new_checkpoint["controlnet_mid_block.bias"] = unet_state_dict.pop("middle_block_out.0.bias")
+
+ return new_checkpoint
+
+
+def convert_ldm_vae_checkpoint(checkpoint, config, is_extract=False):
+ # extract state dict for VAE
+ vae_state_dict = {}
+ if is_extract:
+ vae_key = "first_stage_model."
+ keys = list(checkpoint.keys())
+ for key in keys:
+ if is_extract:
+ if key.startswith(vae_key):
+ vae_state_dict[key.replace(vae_key, "")] = checkpoint.get(key)
+ else:
+ vae_state_dict = checkpoint
+
+
+ new_checkpoint = {}
+
+ new_checkpoint["encoder.conv_in.weight"] = vae_state_dict["encoder.conv_in.weight"]
+ new_checkpoint["encoder.conv_in.bias"] = vae_state_dict["encoder.conv_in.bias"]
+ new_checkpoint["encoder.conv_out.weight"] = vae_state_dict["encoder.conv_out.weight"]
+ new_checkpoint["encoder.conv_out.bias"] = vae_state_dict["encoder.conv_out.bias"]
+ new_checkpoint["encoder.conv_norm_out.weight"] = vae_state_dict["encoder.norm_out.weight"]
+ new_checkpoint["encoder.conv_norm_out.bias"] = vae_state_dict["encoder.norm_out.bias"]
+
+ new_checkpoint["decoder.conv_in.weight"] = vae_state_dict["decoder.conv_in.weight"]
+ new_checkpoint["decoder.conv_in.bias"] = vae_state_dict["decoder.conv_in.bias"]
+ new_checkpoint["decoder.conv_out.weight"] = vae_state_dict["decoder.conv_out.weight"]
+ new_checkpoint["decoder.conv_out.bias"] = vae_state_dict["decoder.conv_out.bias"]
+ new_checkpoint["decoder.conv_norm_out.weight"] = vae_state_dict["decoder.norm_out.weight"]
+ new_checkpoint["decoder.conv_norm_out.bias"] = vae_state_dict["decoder.norm_out.bias"]
+
+ new_checkpoint["quant_conv.weight"] = vae_state_dict["quant_conv.weight"]
+ new_checkpoint["quant_conv.bias"] = vae_state_dict["quant_conv.bias"]
+ new_checkpoint["post_quant_conv.weight"] = vae_state_dict["post_quant_conv.weight"]
+ new_checkpoint["post_quant_conv.bias"] = vae_state_dict["post_quant_conv.bias"]
+
+ # Retrieves the keys for the encoder down blocks only
+ num_down_blocks = len(
+ {".".join(layer.split(".")[:3]) for layer in vae_state_dict if "encoder.down" in layer}
+ )
+ down_blocks = {
+ layer_id: [key for key in vae_state_dict if f"down.{layer_id}" in key]
+ for layer_id in range(num_down_blocks)
+ }
+
+ # Retrieves the keys for the decoder up blocks only
+ num_up_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "decoder.up" in layer})
+ up_blocks = {
+ layer_id: [key for key in vae_state_dict if f"up.{layer_id}" in key]
+ for layer_id in range(num_up_blocks)
+ }
+
+ for i in range(num_down_blocks):
+ resnets = [key for key in down_blocks[i] if f"down.{i}" in key and f"down.{i}.downsample" not in key]
+
+ if f"encoder.down.{i}.downsample.conv.weight" in vae_state_dict:
+ new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.weight"] = vae_state_dict.pop(
+ f"encoder.down.{i}.downsample.conv.weight"
+ )
+ new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.bias"] = vae_state_dict.pop(
+ f"encoder.down.{i}.downsample.conv.bias"
+ )
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"down.{i}.block", "new": f"down_blocks.{i}.resnets"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ mid_resnets = [key for key in vae_state_dict if "encoder.mid.block" in key]
+ num_mid_res_blocks = 2
+ for i in range(1, num_mid_res_blocks + 1):
+ resnets = [key for key in mid_resnets if f"encoder.mid.block_{i}" in key]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ mid_attentions = [key for key in vae_state_dict if "encoder.mid.attn" in key]
+ paths = renew_vae_attention_paths(mid_attentions)
+ meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config
+ )
+ conv_attn_to_linear(new_checkpoint)
+
+ for i in range(num_up_blocks):
+ block_id = num_up_blocks - 1 - i
+ resnets = [
+ key
+ for key in up_blocks[block_id]
+ if f"up.{block_id}" in key and f"up.{block_id}.upsample" not in key
+ ]
+
+ if f"decoder.up.{block_id}.upsample.conv.weight" in vae_state_dict:
+ new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.weight"] = vae_state_dict[
+ f"decoder.up.{block_id}.upsample.conv.weight"
+ ]
+ new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.bias"] = vae_state_dict[
+ f"decoder.up.{block_id}.upsample.conv.bias"
+ ]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"up.{block_id}.block", "new": f"up_blocks.{i}.resnets"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ mid_resnets = [key for key in vae_state_dict if "decoder.mid.block" in key]
+ num_mid_res_blocks = 2
+ for i in range(1, num_mid_res_blocks + 1):
+ resnets = [key for key in mid_resnets if f"decoder.mid.block_{i}" in key]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ mid_attentions = [key for key in vae_state_dict if "decoder.mid.attn" in key]
+ paths = renew_vae_attention_paths(mid_attentions)
+ meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config
+ )
+ conv_attn_to_linear(new_checkpoint)
+ return new_checkpoint
+
+
+def convert_ldm_clip_checkpoint(checkpoint, local_files_only=False, text_model=None):
+ if text_model is None:
+ config_name = "openai/clip-vit-large-patch14"
+ config = CLIPTextConfig.from_pretrained(config_name)
+
+ with init_empty_weights():
+ text_model = CLIPTextModel(config)
+
+ keys = list(checkpoint.keys())
+
+ text_model_dict = {}
+
+ remove_prefixes = ["cond_stage_model.transformer", "conditioner.embedders.0.transformer"]
+
+ for key in keys:
+ for prefix in remove_prefixes:
+ if key.startswith(prefix):
+ text_model_dict[key[len(prefix + ".") :]] = checkpoint[key]
+
+ for param_name, param in text_model_dict.items():
+ set_module_tensor_to_device(text_model, param_name, "cpu", value=param)
+
+ return text_model
+
+
+textenc_conversion_lst = [
+ ("positional_embedding", "text_model.embeddings.position_embedding.weight"),
+ ("token_embedding.weight", "text_model.embeddings.token_embedding.weight"),
+ ("ln_final.weight", "text_model.final_layer_norm.weight"),
+ ("ln_final.bias", "text_model.final_layer_norm.bias"),
+ ("text_projection", "text_projection.weight"),
+]
+textenc_conversion_map = {x[0]: x[1] for x in textenc_conversion_lst}
+
+textenc_transformer_conversion_lst = [
+ # (stable-diffusion, HF Diffusers)
+ ("resblocks.", "text_model.encoder.layers."),
+ ("ln_1", "layer_norm1"),
+ ("ln_2", "layer_norm2"),
+ (".c_fc.", ".fc1."),
+ (".c_proj.", ".fc2."),
+ (".attn", ".self_attn"),
+ ("ln_final.", "transformer.text_model.final_layer_norm."),
+ ("token_embedding.weight", "transformer.text_model.embeddings.token_embedding.weight"),
+ ("positional_embedding", "transformer.text_model.embeddings.position_embedding.weight"),
+]
+protected = {re.escape(x[0]): x[1] for x in textenc_transformer_conversion_lst}
+textenc_pattern = re.compile("|".join(protected.keys()))
diff --git a/animate/src/animatediff/utils/convert_lora_safetensor_to_diffusers.py b/animate/src/animatediff/utils/convert_lora_safetensor_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..cc38ed8a2c8d9f8ede894a9ff4149905f991d5da
--- /dev/null
+++ b/animate/src/animatediff/utils/convert_lora_safetensor_to_diffusers.py
@@ -0,0 +1,141 @@
+# coding=utf-8
+# Copyright 2023, Haofan Wang, Qixun Wang, All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+""" Conversion script for the LoRA's safetensors checkpoints. """
+
+import argparse
+
+import torch
+
+
+def convert_lora(
+ pipeline, state_dict, LORA_PREFIX_UNET="lora_unet", LORA_PREFIX_TEXT_ENCODER="lora_te", alpha=0.6
+):
+ # load base model
+ # pipeline = StableDiffusionPipeline.from_pretrained(base_model_path, torch_dtype=torch.float32)
+
+ # load LoRA weight from .safetensors
+ # state_dict = load_file(checkpoint_path)
+
+ visited = []
+
+ # directly update weight in diffusers model
+ for key in state_dict:
+ # it is suggested to print out the key, it usually will be something like below
+ # "lora_te_text_model_encoder_layers_0_self_attn_k_proj.lora_down.weight"
+
+ # as we have set the alpha beforehand, so just skip
+ if ".alpha" in key or key in visited:
+ continue
+
+ if "text" in key:
+ layer_infos = key.split(".")[0].split(LORA_PREFIX_TEXT_ENCODER + "_")[-1].split("_")
+ curr_layer = pipeline.text_encoder
+ else:
+ layer_infos = key.split(".")[0].split(LORA_PREFIX_UNET + "_")[-1].split("_")
+ curr_layer = pipeline.unet
+
+ # find the target layer
+ temp_name = layer_infos.pop(0)
+ while len(layer_infos) > -1:
+ try:
+ curr_layer = curr_layer.__getattr__(temp_name)
+ if len(layer_infos) > 0:
+ temp_name = layer_infos.pop(0)
+ elif len(layer_infos) == 0:
+ break
+ except Exception:
+ if len(temp_name) > 0:
+ temp_name += "_" + layer_infos.pop(0)
+ else:
+ temp_name = layer_infos.pop(0)
+
+ pair_keys = []
+ if "lora_down" in key:
+ pair_keys.append(key.replace("lora_down", "lora_up"))
+ pair_keys.append(key)
+ else:
+ pair_keys.append(key)
+ pair_keys.append(key.replace("lora_up", "lora_down"))
+
+ # update weight
+ if len(state_dict[pair_keys[0]].shape) == 4:
+ weight_up = state_dict[pair_keys[0]].squeeze(3).squeeze(2).to(torch.float32)
+ weight_down = state_dict[pair_keys[1]].squeeze(3).squeeze(2).to(torch.float32)
+ curr_layer.weight.data += alpha * torch.mm(weight_up, weight_down).unsqueeze(2).unsqueeze(3).to(
+ curr_layer.weight.data.device
+ )
+ else:
+ weight_up = state_dict[pair_keys[0]].to(torch.float32)
+ weight_down = state_dict[pair_keys[1]].to(torch.float32)
+ curr_layer.weight.data += alpha * torch.mm(weight_up, weight_down).to(
+ curr_layer.weight.data.device
+ )
+
+ # update visited list
+ for item in pair_keys:
+ visited.append(item)
+
+ return pipeline
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--base_model_path",
+ default=None,
+ type=str,
+ required=True,
+ help="Path to the base model in diffusers format.",
+ )
+ parser.add_argument(
+ "--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
+ )
+ parser.add_argument(
+ "--dump_path", default=None, type=str, required=True, help="Path to the output model."
+ )
+ parser.add_argument(
+ "--lora_prefix_unet", default="lora_unet", type=str, help="The prefix of UNet weight in safetensors"
+ )
+ parser.add_argument(
+ "--lora_prefix_text_encoder",
+ default="lora_te",
+ type=str,
+ help="The prefix of text encoder weight in safetensors",
+ )
+ parser.add_argument(
+ "--alpha", default=0.75, type=float, help="The merging ratio in W = W0 + alpha * deltaW"
+ )
+ parser.add_argument(
+ "--to_safetensors",
+ action="store_true",
+ help="Whether to store pipeline in safetensors format or not.",
+ )
+ parser.add_argument("--device", type=str, help="Device to use (e.g. cpu, cuda:0, cuda:1, etc.)")
+
+ args = parser.parse_args()
+
+ base_model_path = args.base_model_path
+ checkpoint_path = args.checkpoint_path
+ dump_path = args.dump_path
+ lora_prefix_unet = args.lora_prefix_unet
+ lora_prefix_text_encoder = args.lora_prefix_text_encoder
+ alpha = args.alpha
+
+ pipe = convert_lora(base_model_path, checkpoint_path, lora_prefix_unet, lora_prefix_text_encoder, alpha)
+
+ pipe = pipe.to(args.device)
+ pipe.save_pretrained(args.dump_path, safe_serialization=args.to_safetensors)
diff --git a/animate/src/animatediff/utils/device.py b/animate/src/animatediff/utils/device.py
new file mode 100644
index 0000000000000000000000000000000000000000..8a481521dd7c3dd1a4494638b8a59f2b830633c6
--- /dev/null
+++ b/animate/src/animatediff/utils/device.py
@@ -0,0 +1,112 @@
+import logging
+from functools import lru_cache
+from math import ceil
+from typing import Union
+
+import torch
+
+logger = logging.getLogger(__name__)
+
+
+def device_info_str(device: torch.device) -> str:
+ device_info = torch.cuda.get_device_properties(device)
+ return (
+ f"{device_info.name} {ceil(device_info.total_memory / 1024 ** 3)}GB, "
+ + f"CC {device_info.major}.{device_info.minor}, {device_info.multi_processor_count} SM(s)"
+ )
+
+
+@lru_cache(maxsize=4)
+def supports_bfloat16(device: Union[str, torch.device]) -> bool:
+ """A non-exhaustive check for bfloat16 support on a given device.
+ Weird that torch doesn't have a global function for this. If your device
+ does support bfloat16 and it's not listed here, go ahead and add it.
+ """
+ device = torch.device(device) # make sure device is a torch.device
+ match device.type:
+ case "cpu":
+ ret = False
+ case "cuda":
+ with device:
+ ret = torch.cuda.is_bf16_supported()
+ case "xla":
+ ret = True
+ case "mps":
+ ret = True
+ case _:
+ ret = False
+ return ret
+
+
+@lru_cache(maxsize=4)
+def maybe_bfloat16(
+ device: Union[str, torch.device],
+ fallback: torch.dtype = torch.float32,
+) -> torch.dtype:
+ """Returns torch.bfloat16 if available, otherwise the fallback dtype (default float32)"""
+ device = torch.device(device) # make sure device is a torch.device
+ return torch.bfloat16 if supports_bfloat16(device) else fallback
+
+
+def dtype_for_model(model: str, device: torch.device) -> torch.dtype:
+ match model:
+ case "unet":
+ return torch.float32 if device.type == "cpu" else torch.float16
+ case "tenc":
+ return torch.float32 if device.type == "cpu" else torch.float16
+ case "vae":
+ return maybe_bfloat16(device, fallback=torch.float32)
+ case unknown:
+ raise ValueError(f"Invalid model {unknown}")
+
+
+def get_model_dtypes(
+ device: Union[str, torch.device],
+ force_half_vae: bool = False,
+) -> tuple[torch.dtype, torch.dtype, torch.dtype]:
+ device = torch.device(device) # make sure device is a torch.device
+ unet_dtype = dtype_for_model("unet", device)
+ tenc_dtype = dtype_for_model("tenc", device)
+ vae_dtype = dtype_for_model("vae", device)
+
+ if device.type == "cpu":
+ logger.warn("Device explicitly set to CPU, will run everything in fp32")
+ logger.warn("This is likely to be *incredibly* slow, but I don't tell you how to live.")
+
+ if force_half_vae:
+ if device.type == "cpu":
+ logger.critical("Can't force VAE to fp16 mode on CPU! Exiting...")
+ raise RuntimeError("Can't force VAE to fp16 mode on CPU!")
+ if vae_dtype == torch.bfloat16:
+ logger.warn("Forcing VAE to use fp16 despite bfloat16 support! This is a bad idea!")
+ logger.warn("If you're not sure why you're doing this, you probably shouldn't be.")
+ vae_dtype = torch.float16
+ else:
+ logger.warn("Forcing VAE to use fp16 instead of fp32 on CUDA! This may result in black outputs!")
+ logger.warn("Running a VAE in fp16 can result in black images or poor output quality.")
+ logger.warn("I don't tell you how to live, but you probably shouldn't do this.")
+ vae_dtype = torch.float16
+
+ logger.info(f"Selected data types: {unet_dtype=}, {tenc_dtype=}, {vae_dtype=}")
+ return unet_dtype, tenc_dtype, vae_dtype
+
+
+def get_memory_format(device: Union[str, torch.device]) -> torch.memory_format:
+ device = torch.device(device) # make sure device is a torch.device
+ # if we have a cuda device
+ if device.type == "cuda":
+ device_info = torch.cuda.get_device_properties(device)
+ # Volta and newer seem to like channels_last. This will probably bite me on TU11x cards.
+ if device_info.major >= 7:
+ ret = torch.channels_last
+ else:
+ ret = torch.contiguous_format
+ elif device.type == "xpu":
+ # Intel ARC GPUs/XPUs like channels_last
+ ret = torch.channels_last
+ else:
+ # TODO: Does MPS like channels_last? do other devices?
+ ret = torch.contiguous_format
+ if ret == torch.channels_last:
+ logger.info("Using channels_last memory format for UNet and VAE")
+ return ret
\ No newline at end of file
diff --git a/animate/src/animatediff/utils/huggingface.py b/animate/src/animatediff/utils/huggingface.py
new file mode 100644
index 0000000000000000000000000000000000000000..c56171502a768194992ae32acb77ec9fc17f261e
--- /dev/null
+++ b/animate/src/animatediff/utils/huggingface.py
@@ -0,0 +1,149 @@
+import logging
+from os import PathLike
+from pathlib import Path
+from typing import Optional
+
+from diffusers import StableDiffusionPipeline, StableDiffusionXLPipeline
+from huggingface_hub import hf_hub_download, snapshot_download
+from tqdm.rich import tqdm
+
+from animatediff import HF_HUB_CACHE, HF_LIB_NAME, HF_LIB_VER, get_dir
+from animatediff.utils.util import path_from_cwd
+
+logger = logging.getLogger(__name__)
+
+data_dir = get_dir("data")
+checkpoint_dir = data_dir.joinpath("models/sd")
+pipeline_dir = data_dir.joinpath("models/huggingface")
+
+IGNORE_TF = ["*.git*", "*.h5", "tf_*"]
+IGNORE_FLAX = ["*.git*", "flax_*", "*.msgpack"]
+IGNORE_TF_FLAX = IGNORE_TF + IGNORE_FLAX
+
+
+class DownloadTqdm(tqdm):
+ def __init__(self, *args, **kwargs):
+ kwargs.update(
+ {
+ "ncols": 100,
+ "dynamic_ncols": False,
+ "disable": None,
+ }
+ )
+ super().__init__(*args, **kwargs)
+
+
+def get_hf_file(
+ repo_id: Path,
+ filename: str,
+ target_dir: Path,
+ subfolder: Optional[PathLike] = None,
+ revision: Optional[str] = None,
+ force: bool = False,
+) -> Path:
+ target_path = target_dir.joinpath(filename)
+ if target_path.exists() and force is not True:
+ raise FileExistsError(
+ f"File {path_from_cwd(target_path)} already exists! Pass force=True to overwrite"
+ )
+
+ target_dir.mkdir(exist_ok=True, parents=True)
+ save_path = hf_hub_download(
+ repo_id=str(repo_id),
+ filename=filename,
+ revision=revision or "main",
+ subfolder=subfolder,
+ local_dir=target_dir,
+ local_dir_use_symlinks=False,
+ cache_dir=HF_HUB_CACHE,
+ resume_download=True,
+ )
+ return Path(save_path)
+
+
+def get_hf_repo(
+ repo_id: Path,
+ target_dir: Path,
+ subfolder: Optional[PathLike] = None,
+ revision: Optional[str] = None,
+ force: bool = False,
+) -> Path:
+ if target_dir.exists() and force is not True:
+ raise FileExistsError(
+ f"Target dir {path_from_cwd(target_dir)} already exists! Pass force=True to overwrite"
+ )
+
+ target_dir.mkdir(exist_ok=True, parents=True)
+ save_path = snapshot_download(
+ repo_id=str(repo_id),
+ revision=revision or "main",
+ subfolder=subfolder,
+ library_name=HF_LIB_NAME,
+ library_version=HF_LIB_VER,
+ local_dir=target_dir,
+ local_dir_use_symlinks=False,
+ ignore_patterns=IGNORE_TF_FLAX,
+ cache_dir=HF_HUB_CACHE,
+ tqdm_class=DownloadTqdm,
+ max_workers=2,
+ resume_download=True,
+ )
+ return Path(save_path)
+
+
+def get_hf_pipeline(
+ repo_id: Path,
+ target_dir: Path,
+ save: bool = True,
+ force_download: bool = False,
+) -> StableDiffusionPipeline:
+ pipeline_exists = target_dir.joinpath("model_index.json").exists()
+ if pipeline_exists and force_download is not True:
+ pipeline = StableDiffusionPipeline.from_pretrained(
+ pretrained_model_name_or_path=target_dir,
+ local_files_only=True,
+ )
+ else:
+ target_dir.mkdir(exist_ok=True, parents=True)
+ pipeline = StableDiffusionPipeline.from_pretrained(
+ pretrained_model_name_or_path=str(repo_id).lstrip("./").replace("\\", "/"),
+ cache_dir=HF_HUB_CACHE,
+ resume_download=True,
+ )
+ if save and force_download:
+ logger.warning(f"Pipeline already exists at {path_from_cwd(target_dir)}. Overwriting!")
+ pipeline.save_pretrained(target_dir, safe_serialization=True)
+ elif save and not pipeline_exists:
+ #logger.info(f"Saving pipeline to {path_from_cwd(target_dir)}")
+ pipeline.save_pretrained(target_dir, safe_serialization=True)
+ return pipeline
+
+def get_hf_pipeline_sdxl(
+ repo_id: Path,
+ target_dir: Path,
+ save: bool = True,
+ force_download: bool = False,
+) -> StableDiffusionXLPipeline:
+ import torch
+ pipeline_exists = target_dir.joinpath("model_index.json").exists()
+ if pipeline_exists and force_download is not True:
+ pipeline = StableDiffusionXLPipeline.from_pretrained(
+ pretrained_model_name_or_path=target_dir,
+ local_files_only=True,
+ torch_dtype=torch.float16, use_safetensors=True, variant="fp16"
+ )
+ else:
+ target_dir.mkdir(exist_ok=True, parents=True)
+ pipeline = StableDiffusionXLPipeline.from_pretrained(
+ pretrained_model_name_or_path=str(repo_id).lstrip("./").replace("\\", "/"),
+ cache_dir=HF_HUB_CACHE,
+ resume_download=True,
+ torch_dtype=torch.float16, use_safetensors=True, variant="fp16"
+ )
+ if save and force_download:
+ logger.warning(f"Pipeline already exists at {path_from_cwd(target_dir)}. Overwriting!")
+ pipeline.save_pretrained(target_dir, safe_serialization=True)
+ elif save and not pipeline_exists:
+ #logger.info(f"Saving pipeline to {path_from_cwd(target_dir)}")
+ pipeline.save_pretrained(target_dir, safe_serialization=True)
+ return pipeline
diff --git a/animate/src/animatediff/utils/lora_diffusers.py b/animate/src/animatediff/utils/lora_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..2576fa78154e4461381b4514266076177e070f98
--- /dev/null
+++ b/animate/src/animatediff/utils/lora_diffusers.py
@@ -0,0 +1,649 @@
+# https://github.com/kohya-ss/sd-scripts/blob/dev/networks/lora_diffusers.py
+
+# Diffusersで動くLoRA。このファイル単独で完結する。
+# LoRA module for Diffusers. This file works independently.
+
+import bisect
+import math
+import random
+from typing import Any, Dict, List, Mapping, Optional, Union
+
+import numpy as np
+import torch
+from diffusers import UNet2DConditionModel
+from tqdm import tqdm
+from transformers import CLIPTextModel
+
+
+def make_unet_conversion_map() -> Dict[str, str]:
+ unet_conversion_map_layer = []
+
+ for i in range(3): # num_blocks is 3 in sdxl
+ # loop over downblocks/upblocks
+ for j in range(2):
+ # loop over resnets/attentions for downblocks
+ hf_down_res_prefix = f"down_blocks.{i}.resnets.{j}."
+ sd_down_res_prefix = f"input_blocks.{3*i + j + 1}.0."
+ unet_conversion_map_layer.append((sd_down_res_prefix, hf_down_res_prefix))
+
+ if i < 3:
+ # no attention layers in down_blocks.3
+ hf_down_atn_prefix = f"down_blocks.{i}.attentions.{j}."
+ sd_down_atn_prefix = f"input_blocks.{3*i + j + 1}.1."
+ unet_conversion_map_layer.append((sd_down_atn_prefix, hf_down_atn_prefix))
+
+ for j in range(3):
+ # loop over resnets/attentions for upblocks
+ hf_up_res_prefix = f"up_blocks.{i}.resnets.{j}."
+ sd_up_res_prefix = f"output_blocks.{3*i + j}.0."
+ unet_conversion_map_layer.append((sd_up_res_prefix, hf_up_res_prefix))
+
+ # if i > 0: commentout for sdxl
+ # no attention layers in up_blocks.0
+ hf_up_atn_prefix = f"up_blocks.{i}.attentions.{j}."
+ sd_up_atn_prefix = f"output_blocks.{3*i + j}.1."
+ unet_conversion_map_layer.append((sd_up_atn_prefix, hf_up_atn_prefix))
+
+ if i < 3:
+ # no downsample in down_blocks.3
+ hf_downsample_prefix = f"down_blocks.{i}.downsamplers.0.conv."
+ sd_downsample_prefix = f"input_blocks.{3*(i+1)}.0.op."
+ unet_conversion_map_layer.append((sd_downsample_prefix, hf_downsample_prefix))
+
+ # no upsample in up_blocks.3
+ hf_upsample_prefix = f"up_blocks.{i}.upsamplers.0."
+ sd_upsample_prefix = f"output_blocks.{3*i + 2}.{2}." # change for sdxl
+ unet_conversion_map_layer.append((sd_upsample_prefix, hf_upsample_prefix))
+
+ hf_mid_atn_prefix = "mid_block.attentions.0."
+ sd_mid_atn_prefix = "middle_block.1."
+ unet_conversion_map_layer.append((sd_mid_atn_prefix, hf_mid_atn_prefix))
+
+ for j in range(2):
+ hf_mid_res_prefix = f"mid_block.resnets.{j}."
+ sd_mid_res_prefix = f"middle_block.{2*j}."
+ unet_conversion_map_layer.append((sd_mid_res_prefix, hf_mid_res_prefix))
+
+ unet_conversion_map_resnet = [
+ # (stable-diffusion, HF Diffusers)
+ ("in_layers.0.", "norm1."),
+ ("in_layers.2.", "conv1."),
+ ("out_layers.0.", "norm2."),
+ ("out_layers.3.", "conv2."),
+ ("emb_layers.1.", "time_emb_proj."),
+ ("skip_connection.", "conv_shortcut."),
+ ]
+
+ unet_conversion_map = []
+ for sd, hf in unet_conversion_map_layer:
+ if "resnets" in hf:
+ for sd_res, hf_res in unet_conversion_map_resnet:
+ unet_conversion_map.append((sd + sd_res, hf + hf_res))
+ else:
+ unet_conversion_map.append((sd, hf))
+
+ for j in range(2):
+ hf_time_embed_prefix = f"time_embedding.linear_{j+1}."
+ sd_time_embed_prefix = f"time_embed.{j*2}."
+ unet_conversion_map.append((sd_time_embed_prefix, hf_time_embed_prefix))
+
+ for j in range(2):
+ hf_label_embed_prefix = f"add_embedding.linear_{j+1}."
+ sd_label_embed_prefix = f"label_emb.0.{j*2}."
+ unet_conversion_map.append((sd_label_embed_prefix, hf_label_embed_prefix))
+
+ unet_conversion_map.append(("input_blocks.0.0.", "conv_in."))
+ unet_conversion_map.append(("out.0.", "conv_norm_out."))
+ unet_conversion_map.append(("out.2.", "conv_out."))
+
+ sd_hf_conversion_map = {sd.replace(".", "_")[:-1]: hf.replace(".", "_")[:-1] for sd, hf in unet_conversion_map}
+ return sd_hf_conversion_map
+
+
+UNET_CONVERSION_MAP = make_unet_conversion_map()
+
+
+class LoRAModule(torch.nn.Module):
+ """
+ replaces forward method of the original Linear, instead of replacing the original Linear module.
+ """
+
+ def __init__(
+ self,
+ lora_name,
+ org_module: torch.nn.Module,
+ multiplier=1.0,
+ lora_dim=4,
+ alpha=1,
+ ):
+ """if alpha == 0 or None, alpha is rank (no scaling)."""
+ super().__init__()
+ self.lora_name = lora_name
+
+ if org_module.__class__.__name__ == "Conv2d" or org_module.__class__.__name__ == "LoRACompatibleConv" or org_module.__class__.__name__ == "InflatedConv3d":
+ in_dim = org_module.in_channels
+ out_dim = org_module.out_channels
+ else:
+ in_dim = org_module.in_features
+ out_dim = org_module.out_features
+
+ self.lora_dim = lora_dim
+
+ self.need_rearrange = False
+ if org_module.__class__.__name__ == "InflatedConv3d":
+ self.need_rearrange = True
+
+ if org_module.__class__.__name__ == "Conv2d" or org_module.__class__.__name__ == "LoRACompatibleConv" or org_module.__class__.__name__ == "InflatedConv3d":
+ kernel_size = org_module.kernel_size
+ stride = org_module.stride
+ padding = org_module.padding
+ self.lora_down = torch.nn.Conv2d(in_dim, self.lora_dim, kernel_size, stride, padding, bias=False)
+ self.lora_up = torch.nn.Conv2d(self.lora_dim, out_dim, (1, 1), (1, 1), bias=False)
+ else:
+ self.lora_down = torch.nn.Linear(in_dim, self.lora_dim, bias=False)
+ self.lora_up = torch.nn.Linear(self.lora_dim, out_dim, bias=False)
+
+ if type(alpha) == torch.Tensor:
+ alpha = alpha.detach().float().numpy() # without casting, bf16 causes error
+ alpha = self.lora_dim if alpha is None or alpha == 0 else alpha
+ self.scale = alpha / self.lora_dim
+ self.register_buffer("alpha", torch.tensor(alpha)) # 勾配計算に含めない / not included in gradient calculation
+
+ # same as microsoft's
+ torch.nn.init.kaiming_uniform_(self.lora_down.weight, a=math.sqrt(5))
+ torch.nn.init.zeros_(self.lora_up.weight)
+
+ self.multiplier = multiplier
+ self.org_module = [org_module]
+ self.enabled = True
+ self.network: LoRANetwork = None
+ self.org_forward = None
+
+ # override org_module's forward method
+ def apply_to(self, multiplier=None):
+ if multiplier is not None:
+ self.multiplier = multiplier
+ if self.org_forward is None:
+ self.org_forward = self.org_module[0].forward
+ self.org_module[0].forward = self.forward
+
+ # restore org_module's forward method
+ def unapply_to(self):
+ if self.org_forward is not None:
+ self.org_module[0].forward = self.org_forward
+
+ # forward with lora
+ # scale is used LoRACompatibleConv, but we ignore it because we have multiplier
+ def forward(self, x, scale=1.0):
+ from einops import rearrange
+ if not self.enabled:
+ return self.org_forward(x)
+
+ if self.need_rearrange:
+ org = self.org_forward(x)
+ frames = x.shape[2]
+ x = rearrange(x, "b c f h w -> (b f) c h w")
+ x = self.lora_up(self.lora_down(x)) * self.multiplier * self.scale
+ x = rearrange(x, "(b f) c h w -> b c f h w", f=frames)
+ return org + x
+ else:
+ return self.org_forward(x) + self.lora_up(self.lora_down(x)) * self.multiplier * self.scale
+
+ def set_network(self, network):
+ self.network = network
+
+ # merge lora weight to org weight
+ def merge_to(self, multiplier=1.0):
+ # get lora weight
+ lora_weight = self.get_weight(multiplier)
+
+ # get org weight
+ org_sd = self.org_module[0].state_dict()
+ org_weight = org_sd["weight"]
+ weight = org_weight + lora_weight.to(org_weight.device, dtype=org_weight.dtype)
+
+ # set weight to org_module
+ org_sd["weight"] = weight
+ self.org_module[0].load_state_dict(org_sd)
+
+ # restore org weight from lora weight
+ def restore_from(self, multiplier=1.0):
+ # get lora weight
+ lora_weight = self.get_weight(multiplier)
+
+ # get org weight
+ org_sd = self.org_module[0].state_dict()
+ org_weight = org_sd["weight"]
+ weight = org_weight - lora_weight.to(org_weight.device, dtype=org_weight.dtype)
+
+ # set weight to org_module
+ org_sd["weight"] = weight
+ self.org_module[0].load_state_dict(org_sd)
+
+ # return lora weight
+ def get_weight(self, multiplier=None):
+ if multiplier is None:
+ multiplier = self.multiplier
+
+ # get up/down weight from module
+ up_weight = self.lora_up.weight.to(torch.float)
+ down_weight = self.lora_down.weight.to(torch.float)
+
+ # pre-calculated weight
+ if len(down_weight.size()) == 2:
+ # linear
+ weight = self.multiplier * (up_weight @ down_weight) * self.scale
+ elif down_weight.size()[2:4] == (1, 1):
+ # conv2d 1x1
+ weight = (
+ self.multiplier
+ * (up_weight.squeeze(3).squeeze(2) @ down_weight.squeeze(3).squeeze(2)).unsqueeze(2).unsqueeze(3)
+ * self.scale
+ )
+ else:
+ # conv2d 3x3
+ conved = torch.nn.functional.conv2d(down_weight.permute(1, 0, 2, 3), up_weight).permute(1, 0, 2, 3)
+ weight = self.multiplier * conved * self.scale
+
+ return weight
+
+
+# Create network from weights for inference, weights are not loaded here
+def create_network_from_weights(
+ text_encoder: Union[CLIPTextModel, List[CLIPTextModel]], unet: UNet2DConditionModel, weights_sd: Dict, multiplier: float = 1.0, is_animatediff = True,
+):
+ # get dim/alpha mapping
+ modules_dim = {}
+ modules_alpha = {}
+
+ for key, value in weights_sd.items():
+ if "." not in key:
+ #print(f"skip {key}")
+ continue
+
+ lora_name = key.split(".")[0]
+ if "alpha" in key:
+ #print(f"{key} have alpha -> modules_alpha")
+ modules_alpha[lora_name] = value
+ elif "lora_down" in key:
+ #print(f"{key} have lora_down -> modules_dim")
+ dim = value.size()[0]
+ modules_dim[lora_name] = dim
+ #print(lora_name, value.size(), dim)
+
+ # support old LoRA without alpha
+ for key in modules_dim.keys():
+ if key not in modules_alpha:
+ modules_alpha[key] = modules_dim[key]
+
+ return LoRANetwork(text_encoder, unet, multiplier=multiplier, modules_dim=modules_dim, modules_alpha=modules_alpha, is_animatediff=is_animatediff)
+
+
+def merge_lora_weights(pipe, weights_sd: Dict, multiplier: float = 1.0):
+ text_encoders = [pipe.text_encoder, pipe.text_encoder_2] if hasattr(pipe, "text_encoder_2") else [pipe.text_encoder]
+ unet = pipe.unet
+
+ lora_network = create_network_from_weights(text_encoders, unet, weights_sd, multiplier=multiplier)
+ lora_network.load_state_dict(weights_sd)
+ lora_network.merge_to(multiplier=multiplier)
+
+
+# block weightや学習に対応しない簡易版 / simple version without block weight and training
+class LoRANetwork(torch.nn.Module):
+ UNET_TARGET_REPLACE_MODULE_TYPE1 = ["Transformer3DModel"]
+ UNET_TARGET_REPLACE_MODULE_CONV2D_3X3_TYPE1 = ["ResnetBlock3D", "Downsample3D", "Upsample3D"]
+ UNET_TARGET_REPLACE_MODULE_TYPE2 = ["Transformer2DModel"]
+ UNET_TARGET_REPLACE_MODULE_CONV2D_3X3_TYPE2 = ["ResnetBlock2D", "Downsample2D", "Upsample2D"]
+ TEXT_ENCODER_TARGET_REPLACE_MODULE = ["CLIPAttention", "CLIPMLP"]
+ LORA_PREFIX_UNET = "lora_unet"
+ LORA_PREFIX_TEXT_ENCODER = "lora_te"
+
+ # SDXL: must starts with LORA_PREFIX_TEXT_ENCODER
+ LORA_PREFIX_TEXT_ENCODER1 = "lora_te1"
+ LORA_PREFIX_TEXT_ENCODER2 = "lora_te2"
+
+ def __init__(
+ self,
+ text_encoder: Union[List[CLIPTextModel], CLIPTextModel],
+ unet: UNet2DConditionModel,
+ multiplier: float = 1.0,
+ modules_dim: Optional[Dict[str, int]] = None,
+ modules_alpha: Optional[Dict[str, int]] = None,
+ varbose: Optional[bool] = False,
+ is_animatediff: bool = True,
+ ) -> None:
+ super().__init__()
+ self.multiplier = multiplier
+
+ print(f"create LoRA network from weights")
+
+ # convert SDXL Stability AI's U-Net modules to Diffusers
+ converted = self.convert_unet_modules(modules_dim, modules_alpha)
+ if converted:
+ print(f"converted {converted} Stability AI's U-Net LoRA modules to Diffusers (SDXL)")
+
+ # create module instances
+ def create_modules(
+ is_unet: bool,
+ text_encoder_idx: Optional[int], # None, 1, 2
+ root_module: torch.nn.Module,
+ target_replace_modules: List[torch.nn.Module],
+ ) -> List[LoRAModule]:
+ prefix = (
+ self.LORA_PREFIX_UNET
+ if is_unet
+ else (
+ self.LORA_PREFIX_TEXT_ENCODER
+ if text_encoder_idx is None
+ else (self.LORA_PREFIX_TEXT_ENCODER1 if text_encoder_idx == 1 else self.LORA_PREFIX_TEXT_ENCODER2)
+ )
+ )
+ loras = []
+ skipped = []
+ for name, module in root_module.named_modules():
+ if module.__class__.__name__ in target_replace_modules:
+ for child_name, child_module in module.named_modules():
+ #print(f"{name=} / {child_name=} / {child_module.__class__.__name__}")
+ is_linear = (
+ child_module.__class__.__name__ == "Linear" or child_module.__class__.__name__ == "LoRACompatibleLinear"
+ )
+ is_conv2d = (
+ child_module.__class__.__name__ == "Conv2d" or child_module.__class__.__name__ == "LoRACompatibleConv" or child_module.__class__.__name__ == "InflatedConv3d"
+ )
+
+ if is_linear or is_conv2d:
+ lora_name = prefix + "." + name + "." + child_name
+ lora_name = lora_name.replace(".", "_")
+
+ if lora_name not in modules_dim:
+ print(f"skipped {lora_name} (not found in modules_dim)")
+ skipped.append(lora_name)
+ continue
+
+ dim = modules_dim[lora_name]
+ alpha = modules_alpha[lora_name]
+ lora = LoRAModule(
+ lora_name,
+ child_module,
+ self.multiplier,
+ dim,
+ alpha,
+ )
+ #print(f"{lora_name=}")
+ loras.append(lora)
+ return loras, skipped
+
+ text_encoders = text_encoder if type(text_encoder) == list else [text_encoder]
+
+ # create LoRA for text encoder
+ # 毎回すべてのモジュールを作るのは無駄なので要検討 / it is wasteful to create all modules every time, need to consider
+ self.text_encoder_loras: List[LoRAModule] = []
+ skipped_te = []
+ for i, text_encoder in enumerate(text_encoders):
+ if len(text_encoders) > 1:
+ index = i + 1
+ else:
+ index = None
+
+ text_encoder_loras, skipped = create_modules(False, index, text_encoder, LoRANetwork.TEXT_ENCODER_TARGET_REPLACE_MODULE)
+ self.text_encoder_loras.extend(text_encoder_loras)
+ skipped_te += skipped
+ print(f"create LoRA for Text Encoder: {len(self.text_encoder_loras)} modules.")
+ if len(skipped_te) > 0:
+ print(f"skipped {len(skipped_te)} modules because of missing weight for text encoder.")
+
+ # extend U-Net target modules to include Conv2d 3x3
+ if is_animatediff:
+ target_modules = LoRANetwork.UNET_TARGET_REPLACE_MODULE_TYPE1 + LoRANetwork.UNET_TARGET_REPLACE_MODULE_CONV2D_3X3_TYPE1
+ else:
+ target_modules = LoRANetwork.UNET_TARGET_REPLACE_MODULE_TYPE2 + LoRANetwork.UNET_TARGET_REPLACE_MODULE_CONV2D_3X3_TYPE2
+
+ self.unet_loras: List[LoRAModule]
+ self.unet_loras, skipped_un = create_modules(True, None, unet, target_modules)
+ print(f"create LoRA for U-Net: {len(self.unet_loras)} modules.")
+ if len(skipped_un) > 0:
+ print(f"skipped {len(skipped_un)} modules because of missing weight for U-Net.")
+
+ # assertion
+ names = set()
+ for lora in self.text_encoder_loras + self.unet_loras:
+ names.add(lora.lora_name)
+ for lora_name in modules_dim.keys():
+ assert lora_name in names, f"{lora_name} is not found in created LoRA modules."
+
+ # make to work load_state_dict
+ for lora in self.text_encoder_loras + self.unet_loras:
+ self.add_module(lora.lora_name, lora)
+
+ # SDXL: convert SDXL Stability AI's U-Net modules to Diffusers
+ def convert_unet_modules(self, modules_dim, modules_alpha):
+ converted_count = 0
+ not_converted_count = 0
+
+ map_keys = list(UNET_CONVERSION_MAP.keys())
+ map_keys.sort()
+
+ for key in list(modules_dim.keys()):
+ if key.startswith(LoRANetwork.LORA_PREFIX_UNET + "_"):
+ search_key = key.replace(LoRANetwork.LORA_PREFIX_UNET + "_", "")
+ position = bisect.bisect_right(map_keys, search_key)
+ map_key = map_keys[position - 1]
+ if search_key.startswith(map_key):
+ new_key = key.replace(map_key, UNET_CONVERSION_MAP[map_key])
+ modules_dim[new_key] = modules_dim[key]
+ modules_alpha[new_key] = modules_alpha[key]
+ del modules_dim[key]
+ del modules_alpha[key]
+ converted_count += 1
+ else:
+ not_converted_count += 1
+ assert (
+ converted_count == 0 or not_converted_count == 0
+ ), f"some modules are not converted: {converted_count} converted, {not_converted_count} not converted"
+ return converted_count
+
+ def set_multiplier(self, multiplier):
+ self.multiplier = multiplier
+ for lora in self.text_encoder_loras + self.unet_loras:
+ lora.multiplier = self.multiplier
+
+ def active(self, multiplier):
+ self.multiplier = multiplier
+ for lora in self.text_encoder_loras + self.unet_loras:
+ lora.multiplier = self.multiplier
+ lora.enabled = True
+
+ def deactive(self):
+ for lora in self.text_encoder_loras + self.unet_loras:
+ lora.enabled = False
+
+ def apply_to(self, multiplier=1.0, apply_text_encoder=True, apply_unet=True):
+ if apply_text_encoder:
+ print("enable LoRA for text encoder")
+ for lora in self.text_encoder_loras:
+ lora.apply_to(multiplier)
+ if apply_unet:
+ print("enable LoRA for U-Net")
+ for lora in self.unet_loras:
+ lora.apply_to(multiplier)
+
+ def unapply_to(self):
+ for lora in self.text_encoder_loras + self.unet_loras:
+ lora.unapply_to()
+
+ def merge_to(self, multiplier=1.0):
+ print("merge LoRA weights to original weights")
+ for lora in tqdm(self.text_encoder_loras + self.unet_loras):
+ lora.merge_to(multiplier)
+ print(f"weights are merged")
+
+ def restore_from(self, multiplier=1.0):
+ print("restore LoRA weights from original weights")
+ for lora in tqdm(self.text_encoder_loras + self.unet_loras):
+ lora.restore_from(multiplier)
+ print(f"weights are restored")
+
+ def load_state_dict(self, state_dict: Mapping[str, Any], strict: bool = True):
+ # convert SDXL Stability AI's state dict to Diffusers' based state dict
+ map_keys = list(UNET_CONVERSION_MAP.keys()) # prefix of U-Net modules
+ map_keys.sort()
+ for key in list(state_dict.keys()):
+ if key.startswith(LoRANetwork.LORA_PREFIX_UNET + "_"):
+ search_key = key.replace(LoRANetwork.LORA_PREFIX_UNET + "_", "")
+ position = bisect.bisect_right(map_keys, search_key)
+ map_key = map_keys[position - 1]
+ if search_key.startswith(map_key):
+ new_key = key.replace(map_key, UNET_CONVERSION_MAP[map_key])
+ state_dict[new_key] = state_dict[key]
+ del state_dict[key]
+
+ # in case of V2, some weights have different shape, so we need to convert them
+ # because V2 LoRA is based on U-Net created by use_linear_projection=False
+ my_state_dict = self.state_dict()
+ for key in state_dict.keys():
+ if state_dict[key].size() != my_state_dict[key].size():
+ # print(f"convert {key} from {state_dict[key].size()} to {my_state_dict[key].size()}")
+ state_dict[key] = state_dict[key].view(my_state_dict[key].size())
+
+ return super().load_state_dict(state_dict, strict)
+
+
+if __name__ == "__main__":
+ # sample code to use LoRANetwork
+ import argparse
+ import os
+
+ import torch
+ from diffusers import StableDiffusionPipeline, StableDiffusionXLPipeline
+
+ device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--model_id", type=str, default=None, help="model id for huggingface")
+ parser.add_argument("--lora_weights", type=str, default=None, help="path to LoRA weights")
+ parser.add_argument("--sdxl", action="store_true", help="use SDXL model")
+ parser.add_argument("--prompt", type=str, default="A photo of cat", help="prompt text")
+ parser.add_argument("--negative_prompt", type=str, default="", help="negative prompt text")
+ parser.add_argument("--seed", type=int, default=0, help="random seed")
+ args = parser.parse_args()
+
+ image_prefix = args.model_id.replace("/", "_") + "_"
+
+ # load Diffusers model
+ print(f"load model from {args.model_id}")
+ pipe: Union[StableDiffusionPipeline, StableDiffusionXLPipeline]
+ if args.sdxl:
+ # use_safetensors=True does not work with 0.18.2
+ pipe = StableDiffusionXLPipeline.from_pretrained(args.model_id, variant="fp16", torch_dtype=torch.float16)
+ else:
+ pipe = StableDiffusionPipeline.from_pretrained(args.model_id, variant="fp16", torch_dtype=torch.float16)
+ pipe.to(device)
+ pipe.set_use_memory_efficient_attention_xformers(True)
+
+ text_encoders = [pipe.text_encoder, pipe.text_encoder_2] if args.sdxl else [pipe.text_encoder]
+
+ # load LoRA weights
+ print(f"load LoRA weights from {args.lora_weights}")
+ if os.path.splitext(args.lora_weights)[1] == ".safetensors":
+ from safetensors.torch import load_file
+
+ lora_sd = load_file(args.lora_weights)
+ else:
+ lora_sd = torch.load(args.lora_weights)
+
+ # create by LoRA weights and load weights
+ print(f"create LoRA network")
+ lora_network: LoRANetwork = create_network_from_weights(text_encoders, pipe.unet, lora_sd, multiplier=1.0)
+
+ print(f"load LoRA network weights")
+ lora_network.load_state_dict(lora_sd)
+
+ lora_network.to(device, dtype=pipe.unet.dtype) # required to apply_to. merge_to works without this
+
+ # 必要があれば、元のモデルの重みをバックアップしておく
+ # back-up unet/text encoder weights if necessary
+ def detach_and_move_to_cpu(state_dict):
+ for k, v in state_dict.items():
+ state_dict[k] = v.detach().cpu()
+ return state_dict
+
+ org_unet_sd = pipe.unet.state_dict()
+ detach_and_move_to_cpu(org_unet_sd)
+
+ org_text_encoder_sd = pipe.text_encoder.state_dict()
+ detach_and_move_to_cpu(org_text_encoder_sd)
+
+ if args.sdxl:
+ org_text_encoder_2_sd = pipe.text_encoder_2.state_dict()
+ detach_and_move_to_cpu(org_text_encoder_2_sd)
+
+ def seed_everything(seed):
+ torch.manual_seed(seed)
+ torch.cuda.manual_seed_all(seed)
+ np.random.seed(seed)
+ random.seed(seed)
+
+ # create image with original weights
+ print(f"create image with original weights")
+ seed_everything(args.seed)
+ image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
+ image.save(image_prefix + "original.png")
+
+ # apply LoRA network to the model: slower than merge_to, but can be reverted easily
+ print(f"apply LoRA network to the model")
+ lora_network.apply_to(multiplier=1.0)
+
+ print(f"create image with applied LoRA")
+ seed_everything(args.seed)
+ image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
+ image.save(image_prefix + "applied_lora.png")
+
+ # unapply LoRA network to the model
+ print(f"unapply LoRA network to the model")
+ lora_network.unapply_to()
+
+ print(f"create image with unapplied LoRA")
+ seed_everything(args.seed)
+ image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
+ image.save(image_prefix + "unapplied_lora.png")
+
+ # merge LoRA network to the model: faster than apply_to, but requires back-up of original weights (or unmerge_to)
+ print(f"merge LoRA network to the model")
+ lora_network.merge_to(multiplier=1.0)
+
+ print(f"create image with LoRA")
+ seed_everything(args.seed)
+ image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
+ image.save(image_prefix + "merged_lora.png")
+
+ # restore (unmerge) LoRA weights: numerically unstable
+ # マージされた重みを元に戻す。計算誤差のため、元の重みと完全に一致しないことがあるかもしれない
+ # 保存したstate_dictから元の重みを復元するのが確実
+ print(f"restore (unmerge) LoRA weights")
+ lora_network.restore_from(multiplier=1.0)
+
+ print(f"create image without LoRA")
+ seed_everything(args.seed)
+ image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
+ image.save(image_prefix + "unmerged_lora.png")
+
+ # restore original weights
+ print(f"restore original weights")
+ pipe.unet.load_state_dict(org_unet_sd)
+ pipe.text_encoder.load_state_dict(org_text_encoder_sd)
+ if args.sdxl:
+ pipe.text_encoder_2.load_state_dict(org_text_encoder_2_sd)
+
+ print(f"create image with restored original weights")
+ seed_everything(args.seed)
+ image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
+ image.save(image_prefix + "restore_original.png")
+
+ # use convenience function to merge LoRA weights
+ print(f"merge LoRA weights with convenience function")
+ merge_lora_weights(pipe, lora_sd, multiplier=1.0)
+
+ print(f"create image with merged LoRA weights")
+ seed_everything(args.seed)
+ image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
+ image.save(image_prefix + "convenience_merged_lora.png")
diff --git a/animate/src/animatediff/utils/lpw_stable_diffusion.py b/animate/src/animatediff/utils/lpw_stable_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..2773170fe13f12c63f3bcc64587d6c32c5f91478
--- /dev/null
+++ b/animate/src/animatediff/utils/lpw_stable_diffusion.py
@@ -0,0 +1,1431 @@
+import inspect
+import re
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import numpy as np
+import PIL.Image
+import torch
+from packaging import version
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from diffusers import DiffusionPipeline
+from diffusers.configuration_utils import FrozenDict
+from diffusers.image_processor import VaeImageProcessor
+from diffusers.loaders import FromSingleFileMixin, StableDiffusionLoraLoaderMixin, TextualInversionLoaderMixin
+from diffusers.models import AutoencoderKL, UNet2DConditionModel
+from diffusers.models.lora import adjust_lora_scale_text_encoder
+from diffusers.pipelines.pipeline_utils import StableDiffusionMixin
+from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput, StableDiffusionSafetyChecker
+from diffusers.schedulers import KarrasDiffusionSchedulers
+from diffusers.utils import (
+ PIL_INTERPOLATION,
+ USE_PEFT_BACKEND,
+ deprecate,
+ logging,
+ scale_lora_layers,
+ unscale_lora_layers,
+)
+from diffusers.utils.torch_utils import randn_tensor
+
+
+# ------------------------------------------------------------------------------
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+re_attention = re.compile(
+ r"""
+\\\(|
+\\\)|
+\\\[|
+\\]|
+\\\\|
+\\|
+\(|
+\[|
+:([+-]?[.\d]+)\)|
+\)|
+]|
+[^\\()\[\]:]+|
+:
+""",
+ re.X,
+)
+
+
+def parse_prompt_attention(text):
+ """
+ Parses a string with attention tokens and returns a list of pairs: text and its associated weight.
+ Accepted tokens are:
+ (abc) - increases attention to abc by a multiplier of 1.1
+ (abc:3.12) - increases attention to abc by a multiplier of 3.12
+ [abc] - decreases attention to abc by a multiplier of 1.1
+ \\( - literal character '('
+ \\[ - literal character '['
+ \\) - literal character ')'
+ \\] - literal character ']'
+ \\ - literal character '\'
+ anything else - just text
+ >>> parse_prompt_attention('normal text')
+ [['normal text', 1.0]]
+ >>> parse_prompt_attention('an (important) word')
+ [['an ', 1.0], ['important', 1.1], [' word', 1.0]]
+ >>> parse_prompt_attention('(unbalanced')
+ [['unbalanced', 1.1]]
+ >>> parse_prompt_attention('\\(literal\\]')
+ [['(literal]', 1.0]]
+ >>> parse_prompt_attention('(unnecessary)(parens)')
+ [['unnecessaryparens', 1.1]]
+ >>> parse_prompt_attention('a (((house:1.3)) [on] a (hill:0.5), sun, (((sky))).')
+ [['a ', 1.0],
+ ['house', 1.5730000000000004],
+ [' ', 1.1],
+ ['on', 1.0],
+ [' a ', 1.1],
+ ['hill', 0.55],
+ [', sun, ', 1.1],
+ ['sky', 1.4641000000000006],
+ ['.', 1.1]]
+ """
+
+ res = []
+ round_brackets = []
+ square_brackets = []
+
+ round_bracket_multiplier = 1.1
+ square_bracket_multiplier = 1 / 1.1
+
+ def multiply_range(start_position, multiplier):
+ for p in range(start_position, len(res)):
+ res[p][1] *= multiplier
+
+ for m in re_attention.finditer(text):
+ text = m.group(0)
+ weight = m.group(1)
+
+ if text.startswith("\\"):
+ res.append([text[1:], 1.0])
+ elif text == "(":
+ round_brackets.append(len(res))
+ elif text == "[":
+ square_brackets.append(len(res))
+ elif weight is not None and len(round_brackets) > 0:
+ multiply_range(round_brackets.pop(), float(weight))
+ elif text == ")" and len(round_brackets) > 0:
+ multiply_range(round_brackets.pop(), round_bracket_multiplier)
+ elif text == "]" and len(square_brackets) > 0:
+ multiply_range(square_brackets.pop(), square_bracket_multiplier)
+ else:
+ res.append([text, 1.0])
+
+ for pos in round_brackets:
+ multiply_range(pos, round_bracket_multiplier)
+
+ for pos in square_brackets:
+ multiply_range(pos, square_bracket_multiplier)
+
+ if len(res) == 0:
+ res = [["", 1.0]]
+
+ # merge runs of identical weights
+ i = 0
+ while i + 1 < len(res):
+ if res[i][1] == res[i + 1][1]:
+ res[i][0] += res[i + 1][0]
+ res.pop(i + 1)
+ else:
+ i += 1
+
+ return res
+
+
+def get_prompts_with_weights(pipe: DiffusionPipeline, prompt: List[str], max_length: int):
+ r"""
+ Tokenize a list of prompts and return its tokens with weights of each token.
+
+ No padding, starting or ending token is included.
+ """
+ tokens = []
+ weights = []
+ truncated = False
+ for text in prompt:
+ texts_and_weights = parse_prompt_attention(text)
+ text_token = []
+ text_weight = []
+ for word, weight in texts_and_weights:
+ # tokenize and discard the starting and the ending token
+ token = pipe.tokenizer(word).input_ids[1:-1]
+ text_token += token
+ # copy the weight by length of token
+ text_weight += [weight] * len(token)
+ # stop if the text is too long (longer than truncation limit)
+ if len(text_token) > max_length:
+ truncated = True
+ break
+ # truncate
+ if len(text_token) > max_length:
+ truncated = True
+ text_token = text_token[:max_length]
+ text_weight = text_weight[:max_length]
+ tokens.append(text_token)
+ weights.append(text_weight)
+ if truncated:
+ logger.warning("Prompt was truncated. Try to shorten the prompt or increase max_embeddings_multiples")
+ return tokens, weights
+
+
+def pad_tokens_and_weights(tokens, weights, max_length, bos, eos, pad, no_boseos_middle=True, chunk_length=77):
+ r"""
+ Pad the tokens (with starting and ending tokens) and weights (with 1.0) to max_length.
+ """
+ max_embeddings_multiples = (max_length - 2) // (chunk_length - 2)
+ weights_length = max_length if no_boseos_middle else max_embeddings_multiples * chunk_length
+ for i in range(len(tokens)):
+ tokens[i] = [bos] + tokens[i] + [pad] * (max_length - 1 - len(tokens[i]) - 1) + [eos]
+ if no_boseos_middle:
+ weights[i] = [1.0] + weights[i] + [1.0] * (max_length - 1 - len(weights[i]))
+ else:
+ w = []
+ if len(weights[i]) == 0:
+ w = [1.0] * weights_length
+ else:
+ for j in range(max_embeddings_multiples):
+ w.append(1.0) # weight for starting token in this chunk
+ w += weights[i][j * (chunk_length - 2) : min(len(weights[i]), (j + 1) * (chunk_length - 2))]
+ w.append(1.0) # weight for ending token in this chunk
+ w += [1.0] * (weights_length - len(w))
+ weights[i] = w[:]
+
+ return tokens, weights
+
+
+def get_unweighted_text_embeddings(
+ pipe: DiffusionPipeline,
+ text_input: torch.Tensor,
+ chunk_length: int,
+ no_boseos_middle: Optional[bool] = True,
+ clip_skip: Optional[int] = None,
+):
+ """
+ When the length of tokens is a multiple of the capacity of the text encoder,
+ it should be split into chunks and sent to the text encoder individually.
+ """
+ max_embeddings_multiples = (text_input.shape[1] - 2) // (chunk_length - 2)
+ if max_embeddings_multiples > 1:
+ text_embeddings = []
+ for i in range(max_embeddings_multiples):
+ # extract the i-th chunk
+ text_input_chunk = text_input[:, i * (chunk_length - 2) : (i + 1) * (chunk_length - 2) + 2].clone()
+
+ # cover the head and the tail by the starting and the ending tokens
+ text_input_chunk[:, 0] = text_input[0, 0]
+ text_input_chunk[:, -1] = text_input[0, -1]
+ if clip_skip is None:
+ prompt_embeds = pipe.text_encoder(text_input_chunk.to(pipe.device))
+ text_embedding = prompt_embeds[0]
+ else:
+ prompt_embeds = pipe.text_encoder(text_input_chunk.to(pipe.device), output_hidden_states=True)
+ # Access the `hidden_states` first, that contains a tuple of
+ # all the hidden states from the encoder layers. Then index into
+ # the tuple to access the hidden states from the desired layer.
+ prompt_embeds = prompt_embeds[-1][-(clip_skip + 1)]
+ # We also need to apply the final LayerNorm here to not mess with the
+ # representations. The `last_hidden_states` that we typically use for
+ # obtaining the final prompt representations passes through the LayerNorm
+ # layer.
+ text_embedding = pipe.text_encoder.text_model.final_layer_norm(prompt_embeds)
+
+ if no_boseos_middle:
+ if i == 0:
+ # discard the ending token
+ text_embedding = text_embedding[:, :-1]
+ elif i == max_embeddings_multiples - 1:
+ # discard the starting token
+ text_embedding = text_embedding[:, 1:]
+ else:
+ # discard both starting and ending tokens
+ text_embedding = text_embedding[:, 1:-1]
+
+ text_embeddings.append(text_embedding)
+ text_embeddings = torch.concat(text_embeddings, axis=1)
+ else:
+ if clip_skip is None:
+ clip_skip = 0
+ prompt_embeds = pipe.text_encoder(text_input, output_hidden_states=True)[-1][-(clip_skip + 1)]
+ text_embeddings = pipe.text_encoder.text_model.final_layer_norm(prompt_embeds)
+ return text_embeddings
+
+
+def get_weighted_text_embeddings(
+ pipe: DiffusionPipeline,
+ prompt: Union[str, List[str]],
+ uncond_prompt: Optional[Union[str, List[str]]] = None,
+ max_embeddings_multiples: Optional[int] = 3,
+ no_boseos_middle: Optional[bool] = False,
+ skip_parsing: Optional[bool] = False,
+ skip_weighting: Optional[bool] = False,
+ clip_skip=None,
+ lora_scale=None,
+):
+ r"""
+ Prompts can be assigned with local weights using brackets. For example,
+ prompt 'A (very beautiful) masterpiece' highlights the words 'very beautiful',
+ and the embedding tokens corresponding to the words get multiplied by a constant, 1.1.
+
+ Also, to regularize of the embedding, the weighted embedding would be scaled to preserve the original mean.
+
+ Args:
+ pipe (`DiffusionPipeline`):
+ Pipe to provide access to the tokenizer and the text encoder.
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ uncond_prompt (`str` or `List[str]`):
+ The unconditional prompt or prompts for guide the image generation. If unconditional prompt
+ is provided, the embeddings of prompt and uncond_prompt are concatenated.
+ max_embeddings_multiples (`int`, *optional*, defaults to `3`):
+ The max multiple length of prompt embeddings compared to the max output length of text encoder.
+ no_boseos_middle (`bool`, *optional*, defaults to `False`):
+ If the length of text token is multiples of the capacity of text encoder, whether reserve the starting and
+ ending token in each of the chunk in the middle.
+ skip_parsing (`bool`, *optional*, defaults to `False`):
+ Skip the parsing of brackets.
+ skip_weighting (`bool`, *optional*, defaults to `False`):
+ Skip the weighting. When the parsing is skipped, it is forced True.
+ """
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(pipe, StableDiffusionLoraLoaderMixin):
+ pipe._lora_scale = lora_scale
+
+ # dynamically adjust the LoRA scale
+ if not USE_PEFT_BACKEND:
+ adjust_lora_scale_text_encoder(pipe.text_encoder, lora_scale)
+ else:
+ scale_lora_layers(pipe.text_encoder, lora_scale)
+ max_length = (pipe.tokenizer.model_max_length - 2) * max_embeddings_multiples + 2
+ if isinstance(prompt, str):
+ prompt = [prompt]
+
+ if not skip_parsing:
+ prompt_tokens, prompt_weights = get_prompts_with_weights(pipe, prompt, max_length - 2)
+ if uncond_prompt is not None:
+ if isinstance(uncond_prompt, str):
+ uncond_prompt = [uncond_prompt]
+ uncond_tokens, uncond_weights = get_prompts_with_weights(pipe, uncond_prompt, max_length - 2)
+ else:
+ prompt_tokens = [
+ token[1:-1] for token in pipe.tokenizer(prompt, max_length=max_length, truncation=True).input_ids
+ ]
+ prompt_weights = [[1.0] * len(token) for token in prompt_tokens]
+ if uncond_prompt is not None:
+ if isinstance(uncond_prompt, str):
+ uncond_prompt = [uncond_prompt]
+ uncond_tokens = [
+ token[1:-1]
+ for token in pipe.tokenizer(uncond_prompt, max_length=max_length, truncation=True).input_ids
+ ]
+ uncond_weights = [[1.0] * len(token) for token in uncond_tokens]
+
+ # round up the longest length of tokens to a multiple of (model_max_length - 2)
+ max_length = max([len(token) for token in prompt_tokens])
+ if uncond_prompt is not None:
+ max_length = max(max_length, max([len(token) for token in uncond_tokens]))
+
+ max_embeddings_multiples = min(
+ max_embeddings_multiples,
+ (max_length - 1) // (pipe.tokenizer.model_max_length - 2) + 1,
+ )
+ max_embeddings_multiples = max(1, max_embeddings_multiples)
+ max_length = (pipe.tokenizer.model_max_length - 2) * max_embeddings_multiples + 2
+
+ # pad the length of tokens and weights
+ bos = pipe.tokenizer.bos_token_id
+ eos = pipe.tokenizer.eos_token_id
+ pad = getattr(pipe.tokenizer, "pad_token_id", eos)
+ prompt_tokens, prompt_weights = pad_tokens_and_weights(
+ prompt_tokens,
+ prompt_weights,
+ max_length,
+ bos,
+ eos,
+ pad,
+ no_boseos_middle=no_boseos_middle,
+ chunk_length=pipe.tokenizer.model_max_length,
+ )
+ prompt_tokens = torch.tensor(prompt_tokens, dtype=torch.long, device=pipe.device)
+ if uncond_prompt is not None:
+ uncond_tokens, uncond_weights = pad_tokens_and_weights(
+ uncond_tokens,
+ uncond_weights,
+ max_length,
+ bos,
+ eos,
+ pad,
+ no_boseos_middle=no_boseos_middle,
+ chunk_length=pipe.tokenizer.model_max_length,
+ )
+ uncond_tokens = torch.tensor(uncond_tokens, dtype=torch.long, device=pipe.device)
+
+ # get the embeddings
+ text_embeddings = get_unweighted_text_embeddings(
+ pipe, prompt_tokens, pipe.tokenizer.model_max_length, no_boseos_middle=no_boseos_middle, clip_skip=clip_skip
+ )
+ prompt_weights = torch.tensor(prompt_weights, dtype=text_embeddings.dtype, device=text_embeddings.device)
+ if uncond_prompt is not None:
+ uncond_embeddings = get_unweighted_text_embeddings(
+ pipe,
+ uncond_tokens,
+ pipe.tokenizer.model_max_length,
+ no_boseos_middle=no_boseos_middle,
+ clip_skip=clip_skip,
+ )
+ uncond_weights = torch.tensor(uncond_weights, dtype=uncond_embeddings.dtype, device=uncond_embeddings.device)
+
+ # assign weights to the prompts and normalize in the sense of mean
+ # TODO: should we normalize by chunk or in a whole (current implementation)?
+ if (not skip_parsing) and (not skip_weighting):
+ previous_mean = text_embeddings.float().mean(axis=[-2, -1]).to(text_embeddings.dtype)
+ text_embeddings *= prompt_weights.unsqueeze(-1)
+ current_mean = text_embeddings.float().mean(axis=[-2, -1]).to(text_embeddings.dtype)
+ text_embeddings *= (previous_mean / current_mean).unsqueeze(-1).unsqueeze(-1)
+ if uncond_prompt is not None:
+ previous_mean = uncond_embeddings.float().mean(axis=[-2, -1]).to(uncond_embeddings.dtype)
+ uncond_embeddings *= uncond_weights.unsqueeze(-1)
+ current_mean = uncond_embeddings.float().mean(axis=[-2, -1]).to(uncond_embeddings.dtype)
+ uncond_embeddings *= (previous_mean / current_mean).unsqueeze(-1).unsqueeze(-1)
+
+ if pipe.text_encoder is not None:
+ if isinstance(pipe, StableDiffusionLoraLoaderMixin) and USE_PEFT_BACKEND:
+ # Retrieve the original scale by scaling back the LoRA layers
+ unscale_lora_layers(pipe.text_encoder, lora_scale)
+
+ if uncond_prompt is not None:
+ return text_embeddings, uncond_embeddings
+ return text_embeddings, None
+
+
+def preprocess_image(image, batch_size):
+ w, h = image.size
+ w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
+ image = image.resize((w, h), resample=PIL_INTERPOLATION["lanczos"])
+ image = np.array(image).astype(np.float32) / 255.0
+ image = np.vstack([image[None].transpose(0, 3, 1, 2)] * batch_size)
+ image = torch.from_numpy(image)
+ return 2.0 * image - 1.0
+
+
+def preprocess_mask(mask, batch_size, scale_factor=8):
+ if not isinstance(mask, torch.Tensor):
+ mask = mask.convert("L")
+ w, h = mask.size
+ w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
+ mask = mask.resize((w // scale_factor, h // scale_factor), resample=PIL_INTERPOLATION["nearest"])
+ mask = np.array(mask).astype(np.float32) / 255.0
+ mask = np.tile(mask, (4, 1, 1))
+ mask = np.vstack([mask[None]] * batch_size)
+ mask = 1 - mask # repaint white, keep black
+ mask = torch.from_numpy(mask)
+ return mask
+
+ else:
+ valid_mask_channel_sizes = [1, 3]
+ # if mask channel is fourth tensor dimension, permute dimensions to pytorch standard (B, C, H, W)
+ if mask.shape[3] in valid_mask_channel_sizes:
+ mask = mask.permute(0, 3, 1, 2)
+ elif mask.shape[1] not in valid_mask_channel_sizes:
+ raise ValueError(
+ f"Mask channel dimension of size in {valid_mask_channel_sizes} should be second or fourth dimension,"
+ f" but received mask of shape {tuple(mask.shape)}"
+ )
+ # (potentially) reduce mask channel dimension from 3 to 1 for broadcasting to latent shape
+ mask = mask.mean(dim=1, keepdim=True)
+ h, w = mask.shape[-2:]
+ h, w = (x - x % 8 for x in (h, w)) # resize to integer multiple of 8
+ mask = torch.nn.functional.interpolate(mask, (h // scale_factor, w // scale_factor))
+ return mask
+
+
+class StableDiffusionLongPromptWeightingPipeline(
+ DiffusionPipeline,
+ StableDiffusionMixin,
+ TextualInversionLoaderMixin,
+ StableDiffusionLoraLoaderMixin,
+ FromSingleFileMixin,
+):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion without tokens length limit, and support parsing
+ weighting in prompt.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/CompVis/stable-diffusion-v1-4) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+
+ model_cpu_offload_seq = "text_encoder-->unet->vae"
+ _optional_components = ["safety_checker", "feature_extractor"]
+ _exclude_from_cpu_offload = ["safety_checker"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if scheduler is not None and getattr(scheduler.config, "steps_offset", 1) != 1:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
+ f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
+ "to update the config accordingly as leaving `steps_offset` might led to incorrect results"
+ " in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
+ " it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
+ " file"
+ )
+ deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["steps_offset"] = 1
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if scheduler is not None and getattr(scheduler.config, "clip_sample", False) is True:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
+ " `clip_sample` should be set to False in the configuration file. Please make sure to update the"
+ " config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
+ " future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
+ " nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
+ )
+ deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["clip_sample"] = False
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ is_unet_version_less_0_9_0 = (
+ unet is not None
+ and hasattr(unet.config, "_diffusers_version")
+ and version.parse(version.parse(unet.config._diffusers_version).base_version) < version.parse("0.9.0.dev0")
+ )
+ is_unet_sample_size_less_64 = (
+ unet is not None and hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
+ )
+ if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
+ deprecation_message = (
+ "The configuration file of the unet has set the default `sample_size` to smaller than"
+ " 64 which seems highly unlikely. If your checkpoint is a fine-tuned version of any of the"
+ " following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
+ " CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
+ " \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
+ " configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
+ " in the config might lead to incorrect results in future versions. If you have downloaded this"
+ " checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
+ " the `unet/config.json` file"
+ )
+ deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(unet.config)
+ new_config["sample_size"] = 64
+ unet._internal_dict = FrozenDict(new_config)
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1) if getattr(self, "vae", None) else 8
+
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.register_to_config(
+ requires_safety_checker=requires_safety_checker,
+ )
+
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ max_embeddings_multiples=3,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ clip_skip: Optional[int] = None,
+ lora_scale: Optional[float] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `list(int)`):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ max_embeddings_multiples (`int`, *optional*, defaults to `3`):
+ The max multiple length of prompt embeddings compared to the max output length of text encoder.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if negative_prompt_embeds is None:
+ if negative_prompt is None:
+ negative_prompt = [""] * batch_size
+ elif isinstance(negative_prompt, str):
+ negative_prompt = [negative_prompt] * batch_size
+ if batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ if prompt_embeds is None or negative_prompt_embeds is None:
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ negative_prompt = self.maybe_convert_prompt(negative_prompt, self.tokenizer)
+
+ prompt_embeds1, negative_prompt_embeds1 = get_weighted_text_embeddings(
+ pipe=self,
+ prompt=prompt,
+ uncond_prompt=negative_prompt if do_classifier_free_guidance else None,
+ max_embeddings_multiples=max_embeddings_multiples,
+ clip_skip=clip_skip,
+ lora_scale=lora_scale,
+ )
+ if prompt_embeds is None:
+ prompt_embeds = prompt_embeds1
+ if negative_prompt_embeds is None:
+ negative_prompt_embeds = negative_prompt_embeds1
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ if do_classifier_free_guidance:
+ bs_embed, seq_len, _ = negative_prompt_embeds.shape
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ def check_inputs(
+ self,
+ prompt,
+ height,
+ width,
+ strength,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if strength < 0 or strength > 1:
+ raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ def get_timesteps(self, num_inference_steps, strength, device, is_text2img):
+ if is_text2img:
+ return self.scheduler.timesteps.to(device), num_inference_steps
+ else:
+ # get the original timestep using init_timestep
+ init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
+
+ t_start = max(num_inference_steps - init_timestep, 0)
+ timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
+
+ return timesteps, num_inference_steps - t_start
+
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def prepare_latents(
+ self,
+ image,
+ timestep,
+ num_images_per_prompt,
+ batch_size,
+ num_channels_latents,
+ height,
+ width,
+ dtype,
+ device,
+ generator,
+ latents=None,
+ ):
+ if image is None:
+ batch_size = batch_size * num_images_per_prompt
+ shape = (
+ batch_size,
+ num_channels_latents,
+ int(height) // self.vae_scale_factor,
+ int(width) // self.vae_scale_factor,
+ )
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents, None, None
+ else:
+ image = image.to(device=self.device, dtype=dtype)
+ init_latent_dist = self.vae.encode(image).latent_dist
+ init_latents = init_latent_dist.sample(generator=generator)
+ init_latents = self.vae.config.scaling_factor * init_latents
+
+ # Expand init_latents for batch_size and num_images_per_prompt
+ init_latents = torch.cat([init_latents] * num_images_per_prompt, dim=0)
+ init_latents_orig = init_latents
+
+ # add noise to latents using the timesteps
+ noise = randn_tensor(init_latents.shape, generator=generator, device=self.device, dtype=dtype)
+ init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
+ latents = init_latents
+ return latents, init_latents_orig, noise
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]],
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ image: Union[torch.Tensor, PIL.Image.Image] = None,
+ mask_image: Union[torch.Tensor, PIL.Image.Image] = None,
+ height: int = 512,
+ width: int = 512,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ strength: float = 0.8,
+ num_images_per_prompt: Optional[int] = 1,
+ add_predicted_noise: Optional[bool] = False,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.Tensor] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ max_embeddings_multiples: Optional[int] = 3,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.Tensor], None]] = None,
+ is_cancelled_callback: Optional[Callable[[], bool]] = None,
+ clip_skip: Optional[int] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ image (`torch.Tensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, that will be used as the starting point for the
+ process.
+ mask_image (`torch.Tensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
+ replaced by noise and therefore repainted, while black pixels will be preserved. If `mask_image` is a
+ PIL image, it will be converted to a single channel (luminance) before use. If it's a tensor, it should
+ contain one color channel (L) instead of 3, so the expected shape would be `(B, H, W, 1)`.
+ height (`int`, *optional*, defaults to 512):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to 512):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ strength (`float`, *optional*, defaults to 0.8):
+ Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1.
+ `image` will be used as a starting point, adding more noise to it the larger the `strength`. The
+ number of denoising steps depends on the amount of noise initially added. When `strength` is 1, added
+ noise will be maximum and the denoising process will run for the full number of iterations specified in
+ `num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ add_predicted_noise (`bool`, *optional*, defaults to True):
+ Use predicted noise instead of random noise when constructing noisy versions of the original image in
+ the reverse diffusion process
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.Tensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ max_embeddings_multiples (`int`, *optional*, defaults to `3`):
+ The max multiple length of prompt embeddings compared to the max output length of text encoder.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.Tensor)`.
+ is_cancelled_callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. If the function returns
+ `True`, the inference will be cancelled.
+ clip_skip (`int`, *optional*):
+ Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
+ the output of the pre-final layer will be used for computing the prompt embeddings.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+
+ Returns:
+ `None` if cancelled by `is_cancelled_callback`,
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt, height, width, strength, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+ lora_scale = cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ max_embeddings_multiples,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ clip_skip=clip_skip,
+ lora_scale=lora_scale,
+ )
+ dtype = prompt_embeds.dtype
+
+ # 4. Preprocess image and mask
+ if isinstance(image, PIL.Image.Image):
+ image = preprocess_image(image, batch_size)
+ if image is not None:
+ image = image.to(device=self.device, dtype=dtype)
+ if isinstance(mask_image, PIL.Image.Image):
+ mask_image = preprocess_mask(mask_image, batch_size, self.vae_scale_factor)
+ if mask_image is not None:
+ mask = mask_image.to(device=self.device, dtype=dtype)
+ mask = torch.cat([mask] * num_images_per_prompt)
+ else:
+ mask = None
+
+ # 5. set timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device, image is None)
+ latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
+
+ # 6. Prepare latent variables
+ latents, init_latents_orig, noise = self.prepare_latents(
+ image,
+ latent_timestep,
+ num_images_per_prompt,
+ batch_size,
+ self.unet.config.in_channels,
+ height,
+ width,
+ dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 8. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ if mask is not None:
+ # masking
+ if add_predicted_noise:
+ init_latents_proper = self.scheduler.add_noise(
+ init_latents_orig, noise_pred_uncond, torch.tensor([t])
+ )
+ else:
+ init_latents_proper = self.scheduler.add_noise(init_latents_orig, noise, torch.tensor([t]))
+ latents = (init_latents_proper * mask) + (latents * (1 - mask))
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if i % callback_steps == 0:
+ if callback is not None:
+ step_idx = i // getattr(self.scheduler, "order", 1)
+ callback(step_idx, t, latents)
+ if is_cancelled_callback is not None and is_cancelled_callback():
+ return None
+
+ if output_type == "latent":
+ image = latents
+ has_nsfw_concept = None
+ elif output_type == "pil":
+ # 9. Post-processing
+ image = self.decode_latents(latents)
+
+ # 10. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # 11. Convert to PIL
+ image = self.numpy_to_pil(image)
+ else:
+ # 9. Post-processing
+ image = self.decode_latents(latents)
+
+ # 10. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return image, has_nsfw_concept
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
+
+ def text2img(
+ self,
+ prompt: Union[str, List[str]],
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ height: int = 512,
+ width: int = 512,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.Tensor] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ max_embeddings_multiples: Optional[int] = 3,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.Tensor], None]] = None,
+ is_cancelled_callback: Optional[Callable[[], bool]] = None,
+ clip_skip=None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function for text-to-image generation.
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ height (`int`, *optional*, defaults to 512):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to 512):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.Tensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ max_embeddings_multiples (`int`, *optional*, defaults to `3`):
+ The max multiple length of prompt embeddings compared to the max output length of text encoder.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.Tensor)`.
+ is_cancelled_callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. If the function returns
+ `True`, the inference will be cancelled.
+ clip_skip (`int`, *optional*):
+ Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
+ the output of the pre-final layer will be used for computing the prompt embeddings.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+
+ Returns:
+ `None` if cancelled by `is_cancelled_callback`,
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ return self.__call__(
+ prompt=prompt,
+ negative_prompt=negative_prompt,
+ height=height,
+ width=width,
+ num_inference_steps=num_inference_steps,
+ guidance_scale=guidance_scale,
+ num_images_per_prompt=num_images_per_prompt,
+ eta=eta,
+ generator=generator,
+ latents=latents,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ max_embeddings_multiples=max_embeddings_multiples,
+ output_type=output_type,
+ return_dict=return_dict,
+ callback=callback,
+ is_cancelled_callback=is_cancelled_callback,
+ clip_skip=clip_skip,
+ callback_steps=callback_steps,
+ cross_attention_kwargs=cross_attention_kwargs,
+ )
+
+ def img2img(
+ self,
+ image: Union[torch.Tensor, PIL.Image.Image],
+ prompt: Union[str, List[str]],
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ strength: float = 0.8,
+ num_inference_steps: Optional[int] = 50,
+ guidance_scale: Optional[float] = 7.5,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: Optional[float] = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ max_embeddings_multiples: Optional[int] = 3,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.Tensor], None]] = None,
+ is_cancelled_callback: Optional[Callable[[], bool]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function for image-to-image generation.
+ Args:
+ image (`torch.Tensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, that will be used as the starting point for the
+ process.
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ strength (`float`, *optional*, defaults to 0.8):
+ Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1.
+ `image` will be used as a starting point, adding more noise to it the larger the `strength`. The
+ number of denoising steps depends on the amount of noise initially added. When `strength` is 1, added
+ noise will be maximum and the denoising process will run for the full number of iterations specified in
+ `num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference. This parameter will be modulated by `strength`.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ max_embeddings_multiples (`int`, *optional*, defaults to `3`):
+ The max multiple length of prompt embeddings compared to the max output length of text encoder.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.Tensor)`.
+ is_cancelled_callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. If the function returns
+ `True`, the inference will be cancelled.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+
+ Returns:
+ `None` if cancelled by `is_cancelled_callback`,
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ return self.__call__(
+ prompt=prompt,
+ negative_prompt=negative_prompt,
+ image=image,
+ num_inference_steps=num_inference_steps,
+ guidance_scale=guidance_scale,
+ strength=strength,
+ num_images_per_prompt=num_images_per_prompt,
+ eta=eta,
+ generator=generator,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ max_embeddings_multiples=max_embeddings_multiples,
+ output_type=output_type,
+ return_dict=return_dict,
+ callback=callback,
+ is_cancelled_callback=is_cancelled_callback,
+ callback_steps=callback_steps,
+ cross_attention_kwargs=cross_attention_kwargs,
+ )
+
+ def inpaint(
+ self,
+ image: Union[torch.Tensor, PIL.Image.Image],
+ mask_image: Union[torch.Tensor, PIL.Image.Image],
+ prompt: Union[str, List[str]],
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ strength: float = 0.8,
+ num_inference_steps: Optional[int] = 50,
+ guidance_scale: Optional[float] = 7.5,
+ num_images_per_prompt: Optional[int] = 1,
+ add_predicted_noise: Optional[bool] = False,
+ eta: Optional[float] = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ max_embeddings_multiples: Optional[int] = 3,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.Tensor], None]] = None,
+ is_cancelled_callback: Optional[Callable[[], bool]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function for inpaint.
+ Args:
+ image (`torch.Tensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, that will be used as the starting point for the
+ process. This is the image whose masked region will be inpainted.
+ mask_image (`torch.Tensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
+ replaced by noise and therefore repainted, while black pixels will be preserved. If `mask_image` is a
+ PIL image, it will be converted to a single channel (luminance) before use. If it's a tensor, it should
+ contain one color channel (L) instead of 3, so the expected shape would be `(B, H, W, 1)`.
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ strength (`float`, *optional*, defaults to 0.8):
+ Conceptually, indicates how much to inpaint the masked area. Must be between 0 and 1. When `strength`
+ is 1, the denoising process will be run on the masked area for the full number of iterations specified
+ in `num_inference_steps`. `image` will be used as a reference for the masked area, adding more
+ noise to that region the larger the `strength`. If `strength` is 0, no inpainting will occur.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The reference number of denoising steps. More denoising steps usually lead to a higher quality image at
+ the expense of slower inference. This parameter will be modulated by `strength`, as explained above.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ add_predicted_noise (`bool`, *optional*, defaults to True):
+ Use predicted noise instead of random noise when constructing noisy versions of the original image in
+ the reverse diffusion process
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ max_embeddings_multiples (`int`, *optional*, defaults to `3`):
+ The max multiple length of prompt embeddings compared to the max output length of text encoder.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.Tensor)`.
+ is_cancelled_callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. If the function returns
+ `True`, the inference will be cancelled.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+
+ Returns:
+ `None` if cancelled by `is_cancelled_callback`,
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ return self.__call__(
+ prompt=prompt,
+ negative_prompt=negative_prompt,
+ image=image,
+ mask_image=mask_image,
+ num_inference_steps=num_inference_steps,
+ guidance_scale=guidance_scale,
+ strength=strength,
+ num_images_per_prompt=num_images_per_prompt,
+ add_predicted_noise=add_predicted_noise,
+ eta=eta,
+ generator=generator,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ max_embeddings_multiples=max_embeddings_multiples,
+ output_type=output_type,
+ return_dict=return_dict,
+ callback=callback,
+ is_cancelled_callback=is_cancelled_callback,
+ callback_steps=callback_steps,
+ cross_attention_kwargs=cross_attention_kwargs,
+ )
\ No newline at end of file
diff --git a/animate/src/animatediff/utils/lpw_stable_diffusion_xl.py b/animate/src/animatediff/utils/lpw_stable_diffusion_xl.py
new file mode 100644
index 0000000000000000000000000000000000000000..ed071a6ec21ca2adb2907eee2e99b94880b1c0a2
--- /dev/null
+++ b/animate/src/animatediff/utils/lpw_stable_diffusion_xl.py
@@ -0,0 +1,2250 @@
+## ----------------------------------------------------------
+# A SDXL pipeline can take unlimited weighted prompt
+#
+# Author: Andrew Zhu
+# GitHub: https://github.com/xhinker
+# Medium: https://medium.com/@xhinker
+## -----------------------------------------------------------
+
+import inspect
+import os
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import torch
+from PIL import Image
+from transformers import (
+ CLIPImageProcessor,
+ CLIPTextModel,
+ CLIPTextModelWithProjection,
+ CLIPTokenizer,
+ CLIPVisionModelWithProjection,
+)
+
+from diffusers import DiffusionPipeline, StableDiffusionXLPipeline
+from diffusers.image_processor import PipelineImageInput, VaeImageProcessor
+from diffusers.loaders import (
+ FromSingleFileMixin,
+ IPAdapterMixin,
+ StableDiffusionXLLoraLoaderMixin,
+ TextualInversionLoaderMixin,
+)
+from diffusers.models import AutoencoderKL, ImageProjection, UNet2DConditionModel
+from diffusers.models.attention_processor import AttnProcessor2_0, XFormersAttnProcessor
+from diffusers.models.lora import adjust_lora_scale_text_encoder
+from diffusers.pipelines.pipeline_utils import StableDiffusionMixin
+from diffusers.pipelines.stable_diffusion_xl.pipeline_output import StableDiffusionXLPipelineOutput
+from diffusers.schedulers import KarrasDiffusionSchedulers
+from diffusers.utils import (
+ USE_PEFT_BACKEND,
+ deprecate,
+ is_accelerate_available,
+ is_accelerate_version,
+ is_invisible_watermark_available,
+ logging,
+ replace_example_docstring,
+ scale_lora_layers,
+ unscale_lora_layers,
+)
+from diffusers.utils.torch_utils import randn_tensor
+
+
+if is_invisible_watermark_available():
+ from diffusers.pipelines.stable_diffusion_xl.watermark import StableDiffusionXLWatermarker
+
+
+def parse_prompt_attention(text):
+ """
+ Parses a string with attention tokens and returns a list of pairs: text and its associated weight.
+ Accepted tokens are:
+ (abc) - increases attention to abc by a multiplier of 1.1
+ (abc:3.12) - increases attention to abc by a multiplier of 3.12
+ [abc] - decreases attention to abc by a multiplier of 1.1
+ \\( - literal character '('
+ \\[ - literal character '['
+ \\) - literal character ')'
+ \\] - literal character ']'
+ \\ - literal character '\'
+ anything else - just text
+
+ >>> parse_prompt_attention('normal text')
+ [['normal text', 1.0]]
+ >>> parse_prompt_attention('an (important) word')
+ [['an ', 1.0], ['important', 1.1], [' word', 1.0]]
+ >>> parse_prompt_attention('(unbalanced')
+ [['unbalanced', 1.1]]
+ >>> parse_prompt_attention('\\(literal\\]')
+ [['(literal]', 1.0]]
+ >>> parse_prompt_attention('(unnecessary)(parens)')
+ [['unnecessaryparens', 1.1]]
+ >>> parse_prompt_attention('a (((house:1.3)) [on] a (hill:0.5), sun, (((sky))).')
+ [['a ', 1.0],
+ ['house', 1.5730000000000004],
+ [' ', 1.1],
+ ['on', 1.0],
+ [' a ', 1.1],
+ ['hill', 0.55],
+ [', sun, ', 1.1],
+ ['sky', 1.4641000000000006],
+ ['.', 1.1]]
+ """
+ import re
+
+ re_attention = re.compile(
+ r"""
+ \\\(|\\\)|\\\[|\\]|\\\\|\\|\(|\[|:([+-]?[.\d]+)\)|
+ \)|]|[^\\()\[\]:]+|:
+ """,
+ re.X,
+ )
+
+ re_break = re.compile(r"\s*\bBREAK\b\s*", re.S)
+
+ res = []
+ round_brackets = []
+ square_brackets = []
+
+ round_bracket_multiplier = 1.1
+ square_bracket_multiplier = 1 / 1.1
+
+ def multiply_range(start_position, multiplier):
+ for p in range(start_position, len(res)):
+ res[p][1] *= multiplier
+
+ for m in re_attention.finditer(text):
+ text = m.group(0)
+ weight = m.group(1)
+
+ if text.startswith("\\"):
+ res.append([text[1:], 1.0])
+ elif text == "(":
+ round_brackets.append(len(res))
+ elif text == "[":
+ square_brackets.append(len(res))
+ elif weight is not None and len(round_brackets) > 0:
+ multiply_range(round_brackets.pop(), float(weight))
+ elif text == ")" and len(round_brackets) > 0:
+ multiply_range(round_brackets.pop(), round_bracket_multiplier)
+ elif text == "]" and len(square_brackets) > 0:
+ multiply_range(square_brackets.pop(), square_bracket_multiplier)
+ else:
+ parts = re.split(re_break, text)
+ for i, part in enumerate(parts):
+ if i > 0:
+ res.append(["BREAK", -1])
+ res.append([part, 1.0])
+
+ for pos in round_brackets:
+ multiply_range(pos, round_bracket_multiplier)
+
+ for pos in square_brackets:
+ multiply_range(pos, square_bracket_multiplier)
+
+ if len(res) == 0:
+ res = [["", 1.0]]
+
+ # merge runs of identical weights
+ i = 0
+ while i + 1 < len(res):
+ if res[i][1] == res[i + 1][1]:
+ res[i][0] += res[i + 1][0]
+ res.pop(i + 1)
+ else:
+ i += 1
+
+ return res
+
+
+def get_prompts_tokens_with_weights(clip_tokenizer: CLIPTokenizer, prompt: str):
+ """
+ Get prompt token ids and weights, this function works for both prompt and negative prompt
+
+ Args:
+ pipe (CLIPTokenizer)
+ A CLIPTokenizer
+ prompt (str)
+ A prompt string with weights
+
+ Returns:
+ text_tokens (list)
+ A list contains token ids
+ text_weight (list)
+ A list contains the correspondent weight of token ids
+
+ Example:
+ import torch
+ from transformers import CLIPTokenizer
+
+ clip_tokenizer = CLIPTokenizer.from_pretrained(
+ "stablediffusionapi/deliberate-v2"
+ , subfolder = "tokenizer"
+ , dtype = torch.float16
+ )
+
+ token_id_list, token_weight_list = get_prompts_tokens_with_weights(
+ clip_tokenizer = clip_tokenizer
+ ,prompt = "a (red:1.5) cat"*70
+ )
+ """
+ texts_and_weights = parse_prompt_attention(prompt)
+ text_tokens, text_weights = [], []
+ for word, weight in texts_and_weights:
+ # tokenize and discard the starting and the ending token
+ token = clip_tokenizer(word, truncation=False).input_ids[1:-1] # so that tokenize whatever length prompt
+ # the returned token is a 1d list: [320, 1125, 539, 320]
+
+ # merge the new tokens to the all tokens holder: text_tokens
+ text_tokens = [*text_tokens, *token]
+
+ # each token chunk will come with one weight, like ['red cat', 2.0]
+ # need to expand weight for each token.
+ chunk_weights = [weight] * len(token)
+
+ # append the weight back to the weight holder: text_weights
+ text_weights = [*text_weights, *chunk_weights]
+ return text_tokens, text_weights
+
+
+def group_tokens_and_weights(token_ids: list, weights: list, pad_last_block=False):
+ """
+ Produce tokens and weights in groups and pad the missing tokens
+
+ Args:
+ token_ids (list)
+ The token ids from tokenizer
+ weights (list)
+ The weights list from function get_prompts_tokens_with_weights
+ pad_last_block (bool)
+ Control if fill the last token list to 75 tokens with eos
+ Returns:
+ new_token_ids (2d list)
+ new_weights (2d list)
+
+ Example:
+ token_groups,weight_groups = group_tokens_and_weights(
+ token_ids = token_id_list
+ , weights = token_weight_list
+ )
+ """
+ bos, eos = 49406, 49407
+
+ # this will be a 2d list
+ new_token_ids = []
+ new_weights = []
+ while len(token_ids) >= 75:
+ # get the first 75 tokens
+ head_75_tokens = [token_ids.pop(0) for _ in range(75)]
+ head_75_weights = [weights.pop(0) for _ in range(75)]
+
+ # extract token ids and weights
+ temp_77_token_ids = [bos] + head_75_tokens + [eos]
+ temp_77_weights = [1.0] + head_75_weights + [1.0]
+
+ # add 77 token and weights chunk to the holder list
+ new_token_ids.append(temp_77_token_ids)
+ new_weights.append(temp_77_weights)
+
+ # padding the left
+ if len(token_ids) > 0:
+ padding_len = 75 - len(token_ids) if pad_last_block else 0
+
+ temp_77_token_ids = [bos] + token_ids + [eos] * padding_len + [eos]
+ new_token_ids.append(temp_77_token_ids)
+
+ temp_77_weights = [1.0] + weights + [1.0] * padding_len + [1.0]
+ new_weights.append(temp_77_weights)
+
+ return new_token_ids, new_weights
+
+
+def get_weighted_text_embeddings_sdxl(
+ pipe: StableDiffusionXLPipeline,
+ prompt: str = "",
+ prompt_2: str = None,
+ neg_prompt: str = "",
+ neg_prompt_2: str = None,
+ num_images_per_prompt: int = 1,
+ device: Optional[torch.device] = None,
+ clip_skip: Optional[int] = None,
+ lora_scale: Optional[int] = None,
+):
+ """
+ This function can process long prompt with weights, no length limitation
+ for Stable Diffusion XL
+
+ Args:
+ pipe (StableDiffusionPipeline)
+ prompt (str)
+ prompt_2 (str)
+ neg_prompt (str)
+ neg_prompt_2 (str)
+ num_images_per_prompt (int)
+ device (torch.device)
+ clip_skip (int)
+ Returns:
+ prompt_embeds (torch.Tensor)
+ neg_prompt_embeds (torch.Tensor)
+ """
+ device = device or pipe._execution_device
+
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(pipe, StableDiffusionXLLoraLoaderMixin):
+ pipe._lora_scale = lora_scale
+
+ # dynamically adjust the LoRA scale
+ if pipe.text_encoder is not None:
+ if not USE_PEFT_BACKEND:
+ adjust_lora_scale_text_encoder(pipe.text_encoder, lora_scale)
+ else:
+ scale_lora_layers(pipe.text_encoder, lora_scale)
+
+ if pipe.text_encoder_2 is not None:
+ if not USE_PEFT_BACKEND:
+ adjust_lora_scale_text_encoder(pipe.text_encoder_2, lora_scale)
+ else:
+ scale_lora_layers(pipe.text_encoder_2, lora_scale)
+
+ if prompt_2:
+ prompt = f"{prompt} {prompt_2}"
+
+ if neg_prompt_2:
+ neg_prompt = f"{neg_prompt} {neg_prompt_2}"
+
+ prompt_t1 = prompt_t2 = prompt
+ neg_prompt_t1 = neg_prompt_t2 = neg_prompt
+
+ if isinstance(pipe, TextualInversionLoaderMixin):
+ prompt_t1 = pipe.maybe_convert_prompt(prompt_t1, pipe.tokenizer)
+ neg_prompt_t1 = pipe.maybe_convert_prompt(neg_prompt_t1, pipe.tokenizer)
+ prompt_t2 = pipe.maybe_convert_prompt(prompt_t2, pipe.tokenizer_2)
+ neg_prompt_t2 = pipe.maybe_convert_prompt(neg_prompt_t2, pipe.tokenizer_2)
+
+ eos = pipe.tokenizer.eos_token_id
+
+ # tokenizer 1
+ prompt_tokens, prompt_weights = get_prompts_tokens_with_weights(pipe.tokenizer, prompt_t1)
+ neg_prompt_tokens, neg_prompt_weights = get_prompts_tokens_with_weights(pipe.tokenizer, neg_prompt_t1)
+
+ # tokenizer 2
+ prompt_tokens_2, prompt_weights_2 = get_prompts_tokens_with_weights(pipe.tokenizer_2, prompt_t2)
+ neg_prompt_tokens_2, neg_prompt_weights_2 = get_prompts_tokens_with_weights(pipe.tokenizer_2, neg_prompt_t2)
+
+ # padding the shorter one for prompt set 1
+ prompt_token_len = len(prompt_tokens)
+ neg_prompt_token_len = len(neg_prompt_tokens)
+
+ if prompt_token_len > neg_prompt_token_len:
+ # padding the neg_prompt with eos token
+ neg_prompt_tokens = neg_prompt_tokens + [eos] * abs(prompt_token_len - neg_prompt_token_len)
+ neg_prompt_weights = neg_prompt_weights + [1.0] * abs(prompt_token_len - neg_prompt_token_len)
+ else:
+ # padding the prompt
+ prompt_tokens = prompt_tokens + [eos] * abs(prompt_token_len - neg_prompt_token_len)
+ prompt_weights = prompt_weights + [1.0] * abs(prompt_token_len - neg_prompt_token_len)
+
+ # padding the shorter one for token set 2
+ prompt_token_len_2 = len(prompt_tokens_2)
+ neg_prompt_token_len_2 = len(neg_prompt_tokens_2)
+
+ if prompt_token_len_2 > neg_prompt_token_len_2:
+ # padding the neg_prompt with eos token
+ neg_prompt_tokens_2 = neg_prompt_tokens_2 + [eos] * abs(prompt_token_len_2 - neg_prompt_token_len_2)
+ neg_prompt_weights_2 = neg_prompt_weights_2 + [1.0] * abs(prompt_token_len_2 - neg_prompt_token_len_2)
+ else:
+ # padding the prompt
+ prompt_tokens_2 = prompt_tokens_2 + [eos] * abs(prompt_token_len_2 - neg_prompt_token_len_2)
+ prompt_weights_2 = prompt_weights + [1.0] * abs(prompt_token_len_2 - neg_prompt_token_len_2)
+
+ embeds = []
+ neg_embeds = []
+
+ prompt_token_groups, prompt_weight_groups = group_tokens_and_weights(prompt_tokens.copy(), prompt_weights.copy())
+
+ neg_prompt_token_groups, neg_prompt_weight_groups = group_tokens_and_weights(
+ neg_prompt_tokens.copy(), neg_prompt_weights.copy()
+ )
+
+ prompt_token_groups_2, prompt_weight_groups_2 = group_tokens_and_weights(
+ prompt_tokens_2.copy(), prompt_weights_2.copy()
+ )
+
+ neg_prompt_token_groups_2, neg_prompt_weight_groups_2 = group_tokens_and_weights(
+ neg_prompt_tokens_2.copy(), neg_prompt_weights_2.copy()
+ )
+
+ # get prompt embeddings one by one is not working.
+ for i in range(len(prompt_token_groups)):
+ # get positive prompt embeddings with weights
+ token_tensor = torch.tensor([prompt_token_groups[i]], dtype=torch.long, device=device)
+ weight_tensor = torch.tensor(prompt_weight_groups[i], dtype=torch.float16, device=device)
+
+ token_tensor_2 = torch.tensor([prompt_token_groups_2[i]], dtype=torch.long, device=device)
+
+ # use first text encoder
+ prompt_embeds_1 = pipe.text_encoder(token_tensor.to(device), output_hidden_states=True)
+
+ # use second text encoder
+ prompt_embeds_2 = pipe.text_encoder_2(token_tensor_2.to(device), output_hidden_states=True)
+ pooled_prompt_embeds = prompt_embeds_2[0]
+
+ if clip_skip is None:
+ prompt_embeds_1_hidden_states = prompt_embeds_1.hidden_states[-2]
+ prompt_embeds_2_hidden_states = prompt_embeds_2.hidden_states[-2]
+ else:
+ # "2" because SDXL always indexes from the penultimate layer.
+ prompt_embeds_1_hidden_states = prompt_embeds_1.hidden_states[-(clip_skip + 2)]
+ prompt_embeds_2_hidden_states = prompt_embeds_2.hidden_states[-(clip_skip + 2)]
+
+ prompt_embeds_list = [prompt_embeds_1_hidden_states, prompt_embeds_2_hidden_states]
+ token_embedding = torch.concat(prompt_embeds_list, dim=-1).squeeze(0)
+
+ for j in range(len(weight_tensor)):
+ if weight_tensor[j] != 1.0:
+ token_embedding[j] = (
+ token_embedding[-1] + (token_embedding[j] - token_embedding[-1]) * weight_tensor[j]
+ )
+
+ token_embedding = token_embedding.unsqueeze(0)
+ embeds.append(token_embedding)
+
+ # get negative prompt embeddings with weights
+ neg_token_tensor = torch.tensor([neg_prompt_token_groups[i]], dtype=torch.long, device=device)
+ neg_token_tensor_2 = torch.tensor([neg_prompt_token_groups_2[i]], dtype=torch.long, device=device)
+ neg_weight_tensor = torch.tensor(neg_prompt_weight_groups[i], dtype=torch.float16, device=device)
+
+ # use first text encoder
+ neg_prompt_embeds_1 = pipe.text_encoder(neg_token_tensor.to(device), output_hidden_states=True)
+ neg_prompt_embeds_1_hidden_states = neg_prompt_embeds_1.hidden_states[-2]
+
+ # use second text encoder
+ neg_prompt_embeds_2 = pipe.text_encoder_2(neg_token_tensor_2.to(device), output_hidden_states=True)
+ neg_prompt_embeds_2_hidden_states = neg_prompt_embeds_2.hidden_states[-2]
+ negative_pooled_prompt_embeds = neg_prompt_embeds_2[0]
+
+ neg_prompt_embeds_list = [neg_prompt_embeds_1_hidden_states, neg_prompt_embeds_2_hidden_states]
+ neg_token_embedding = torch.concat(neg_prompt_embeds_list, dim=-1).squeeze(0)
+
+ for z in range(len(neg_weight_tensor)):
+ if neg_weight_tensor[z] != 1.0:
+ neg_token_embedding[z] = (
+ neg_token_embedding[-1] + (neg_token_embedding[z] - neg_token_embedding[-1]) * neg_weight_tensor[z]
+ )
+
+ neg_token_embedding = neg_token_embedding.unsqueeze(0)
+ neg_embeds.append(neg_token_embedding)
+
+ prompt_embeds = torch.cat(embeds, dim=1)
+ negative_prompt_embeds = torch.cat(neg_embeds, dim=1)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt, 1).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+ negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt, 1).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+
+ if pipe.text_encoder is not None:
+ if isinstance(pipe, StableDiffusionXLLoraLoaderMixin) and USE_PEFT_BACKEND:
+ # Retrieve the original scale by scaling back the LoRA layers
+ unscale_lora_layers(pipe.text_encoder, lora_scale)
+
+ if pipe.text_encoder_2 is not None:
+ if isinstance(pipe, StableDiffusionXLLoraLoaderMixin) and USE_PEFT_BACKEND:
+ # Retrieve the original scale by scaling back the LoRA layers
+ unscale_lora_layers(pipe.text_encoder_2, lora_scale)
+
+ return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
+
+
+# -------------------------------------------------------------------------------------------------------------------------------
+# reuse the backbone code from StableDiffusionXLPipeline
+# -------------------------------------------------------------------------------------------------------------------------------
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ from diffusers import DiffusionPipeline
+ import torch
+
+ pipe = DiffusionPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-xl-base-1.0"
+ , torch_dtype = torch.float16
+ , use_safetensors = True
+ , variant = "fp16"
+ , custom_pipeline = "lpw_stable_diffusion_xl",
+ )
+
+ prompt = "a white cat running on the grass"*20
+ prompt2 = "play a football"*20
+ prompt = f"{prompt},{prompt2}"
+ neg_prompt = "blur, low quality"
+
+ pipe.to("cuda")
+ images = pipe(
+ prompt = prompt
+ , negative_prompt = neg_prompt
+ ).images[0]
+
+ pipe.to("cpu")
+ torch.cuda.empty_cache()
+ images
+ ```
+"""
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg
+def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
+ """
+ Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
+ Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ """
+ std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
+ std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
+ # rescale the results from guidance (fixes overexposure)
+ noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
+ # mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
+ noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
+ return noise_cfg
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.retrieve_latents
+def retrieve_latents(
+ encoder_output: torch.Tensor, generator: Optional[torch.Generator] = None, sample_mode: str = "sample"
+):
+ if hasattr(encoder_output, "latent_dist") and sample_mode == "sample":
+ return encoder_output.latent_dist.sample(generator)
+ elif hasattr(encoder_output, "latent_dist") and sample_mode == "argmax":
+ return encoder_output.latent_dist.mode()
+ elif hasattr(encoder_output, "latents"):
+ return encoder_output.latents
+ else:
+ raise AttributeError("Could not access latents of provided encoder_output")
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.retrieve_timesteps
+def retrieve_timesteps(
+ scheduler,
+ num_inference_steps: Optional[int] = None,
+ device: Optional[Union[str, torch.device]] = None,
+ timesteps: Optional[List[int]] = None,
+ **kwargs,
+):
+ """
+ Calls the scheduler's `set_timesteps` method and retrieves timesteps from the scheduler after the call. Handles
+ custom timesteps. Any kwargs will be supplied to `scheduler.set_timesteps`.
+
+ Args:
+ scheduler (`SchedulerMixin`):
+ The scheduler to get timesteps from.
+ num_inference_steps (`int`):
+ The number of diffusion steps used when generating samples with a pre-trained model. If used,
+ `timesteps` must be `None`.
+ device (`str` or `torch.device`, *optional*):
+ The device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
+ timesteps (`List[int]`, *optional*):
+ Custom timesteps used to support arbitrary spacing between timesteps. If `None`, then the default
+ timestep spacing strategy of the scheduler is used. If `timesteps` is passed, `num_inference_steps`
+ must be `None`.
+
+ Returns:
+ `Tuple[torch.Tensor, int]`: A tuple where the first element is the timestep schedule from the scheduler and the
+ second element is the number of inference steps.
+ """
+ if timesteps is not None:
+ accepts_timesteps = "timesteps" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())
+ if not accepts_timesteps:
+ raise ValueError(
+ f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"
+ f" timestep schedules. Please check whether you are using the correct scheduler."
+ )
+ scheduler.set_timesteps(timesteps=timesteps, device=device, **kwargs)
+ timesteps = scheduler.timesteps
+ num_inference_steps = len(timesteps)
+ else:
+ scheduler.set_timesteps(num_inference_steps, device=device, **kwargs)
+ timesteps = scheduler.timesteps
+ return timesteps, num_inference_steps
+
+
+class SDXLLongPromptWeightingPipeline(
+ DiffusionPipeline,
+ StableDiffusionMixin,
+ FromSingleFileMixin,
+ IPAdapterMixin,
+ StableDiffusionXLLoraLoaderMixin,
+ TextualInversionLoaderMixin,
+):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion XL.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
+ implemented for all pipelines (downloading, saving, running on a particular device, etc.).
+
+ The pipeline also inherits the following loading methods:
+ - [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
+ - [`~loaders.IPAdapterMixin.load_ip_adapter`] for loading IP Adapters
+ - [`~loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`] for loading LoRA weights
+ - [`~loaders.StableDiffusionXLLoraLoaderMixin.save_lora_weights`] for saving LoRA weights
+ - [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion XL uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ text_encoder_2 ([` CLIPTextModelWithProjection`]):
+ Second frozen text-encoder. Stable Diffusion XL uses the text and pool portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModelWithProjection),
+ specifically the
+ [laion/CLIP-ViT-bigG-14-laion2B-39B-b160k](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k)
+ variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ tokenizer_2 (`CLIPTokenizer`):
+ Second Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]):
+ Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ feature_extractor ([`~transformers.CLIPImageProcessor`]):
+ A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
+ """
+
+ model_cpu_offload_seq = "text_encoder->text_encoder_2->image_encoder->unet->vae"
+ _optional_components = [
+ "tokenizer",
+ "tokenizer_2",
+ "text_encoder",
+ "text_encoder_2",
+ "image_encoder",
+ "feature_extractor",
+ ]
+ _callback_tensor_inputs = [
+ "latents",
+ "prompt_embeds",
+ "negative_prompt_embeds",
+ "add_text_embeds",
+ "add_time_ids",
+ "negative_pooled_prompt_embeds",
+ "negative_add_time_ids",
+ ]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ text_encoder_2: CLIPTextModelWithProjection,
+ tokenizer: CLIPTokenizer,
+ tokenizer_2: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ feature_extractor: Optional[CLIPImageProcessor] = None,
+ image_encoder: Optional[CLIPVisionModelWithProjection] = None,
+ force_zeros_for_empty_prompt: bool = True,
+ add_watermarker: Optional[bool] = None,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ tokenizer=tokenizer,
+ tokenizer_2=tokenizer_2,
+ unet=unet,
+ scheduler=scheduler,
+ feature_extractor=feature_extractor,
+ image_encoder=image_encoder,
+ )
+ self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt)
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1) if getattr(self, "vae", None) else 8
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.mask_processor = VaeImageProcessor(
+ vae_scale_factor=self.vae_scale_factor, do_normalize=False, do_binarize=True, do_convert_grayscale=True
+ )
+ self.default_sample_size = (
+ self.unet.config.sample_size
+ if hasattr(self, "unet") and self.unet is not None and hasattr(self.unet.config, "sample_size")
+ else 128
+ )
+
+ add_watermarker = add_watermarker if add_watermarker is not None else is_invisible_watermark_available()
+
+ if add_watermarker:
+ self.watermark = StableDiffusionXLWatermarker()
+ else:
+ self.watermark = None
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ model_sequence = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+ model_sequence.extend([self.unet, self.vae])
+
+ hook = None
+ for cpu_offloaded_model in model_sequence:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ # Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.encode_prompt
+ def encode_prompt(
+ self,
+ prompt: str,
+ prompt_2: Optional[str] = None,
+ device: Optional[torch.device] = None,
+ num_images_per_prompt: int = 1,
+ do_classifier_free_guidance: bool = True,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ lora_scale: Optional[float] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ negative_prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
+ `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ pooled_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
+ input argument.
+ lora_scale (`float`, *optional*):
+ A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
+ """
+ device = device or self._execution_device
+
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(self, StableDiffusionXLLoraLoaderMixin):
+ self._lora_scale = lora_scale
+
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ # Define tokenizers and text encoders
+ tokenizers = [self.tokenizer, self.tokenizer_2] if self.tokenizer is not None else [self.tokenizer_2]
+ text_encoders = (
+ [self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
+ )
+
+ if prompt_embeds is None:
+ prompt_2 = prompt_2 or prompt
+ # textual inversion: process multi-vector tokens if necessary
+ prompt_embeds_list = []
+ prompts = [prompt, prompt_2]
+ for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, tokenizer)
+
+ text_inputs = tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = text_encoder(
+ text_input_ids.to(device),
+ output_hidden_states=True,
+ )
+
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ if pooled_prompt_embeds is None and prompt_embeds[0].ndim == 2:
+ pooled_prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.hidden_states[-2]
+
+ prompt_embeds_list.append(prompt_embeds)
+
+ prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
+
+ # get unconditional embeddings for classifier free guidance
+ zero_out_negative_prompt = negative_prompt is None and self.config.force_zeros_for_empty_prompt
+ if do_classifier_free_guidance and negative_prompt_embeds is None and zero_out_negative_prompt:
+ negative_prompt_embeds = torch.zeros_like(prompt_embeds)
+ negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
+ elif do_classifier_free_guidance and negative_prompt_embeds is None:
+ negative_prompt = negative_prompt or ""
+ negative_prompt_2 = negative_prompt_2 or negative_prompt
+
+ uncond_tokens: List[str]
+ if prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = [negative_prompt, negative_prompt_2]
+
+ negative_prompt_embeds_list = []
+ for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders):
+ if isinstance(self, TextualInversionLoaderMixin):
+ negative_prompt = self.maybe_convert_prompt(negative_prompt, tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = tokenizer(
+ negative_prompt,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ negative_prompt_embeds = text_encoder(
+ uncond_input.input_ids.to(device),
+ output_hidden_states=True,
+ )
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ if negative_pooled_prompt_embeds is None and negative_prompt_embeds[0].ndim == 2:
+ negative_pooled_prompt_embeds = negative_prompt_embeds[0]
+ negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2]
+
+ negative_prompt_embeds_list.append(negative_prompt_embeds)
+
+ negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1)
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+ if do_classifier_free_guidance:
+ negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
+ bs_embed * num_images_per_prompt, -1
+ )
+
+ return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.encode_image
+ def encode_image(self, image, device, num_images_per_prompt, output_hidden_states=None):
+ dtype = next(self.image_encoder.parameters()).dtype
+
+ if not isinstance(image, torch.Tensor):
+ image = self.feature_extractor(image, return_tensors="pt").pixel_values
+
+ image = image.to(device=device, dtype=dtype)
+ if output_hidden_states:
+ image_enc_hidden_states = self.image_encoder(image, output_hidden_states=True).hidden_states[-2]
+ image_enc_hidden_states = image_enc_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
+ uncond_image_enc_hidden_states = self.image_encoder(
+ torch.zeros_like(image), output_hidden_states=True
+ ).hidden_states[-2]
+ uncond_image_enc_hidden_states = uncond_image_enc_hidden_states.repeat_interleave(
+ num_images_per_prompt, dim=0
+ )
+ return image_enc_hidden_states, uncond_image_enc_hidden_states
+ else:
+ image_embeds = self.image_encoder(image).image_embeds
+ image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
+ uncond_image_embeds = torch.zeros_like(image_embeds)
+
+ return image_embeds, uncond_image_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ prompt_2,
+ height,
+ width,
+ strength,
+ callback_steps,
+ negative_prompt=None,
+ negative_prompt_2=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ pooled_prompt_embeds=None,
+ negative_pooled_prompt_embeds=None,
+ callback_on_step_end_tensor_inputs=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if strength < 0 or strength > 1:
+ raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
+
+ if callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if callback_on_step_end_tensor_inputs is not None and not all(
+ k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
+ ):
+ raise ValueError(
+ f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt_2 is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+ elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)):
+ raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+ elif negative_prompt_2 is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt_2`: {negative_prompt_2} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ if prompt_embeds is not None and pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
+ )
+
+ if negative_prompt_embeds is not None and negative_pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `negative_prompt_embeds` are provided, `negative_pooled_prompt_embeds` also have to be passed. Make sure to generate `negative_pooled_prompt_embeds` from the same text encoder that was used to generate `negative_prompt_embeds`."
+ )
+
+ def get_timesteps(self, num_inference_steps, strength, device, denoising_start=None):
+ # get the original timestep using init_timestep
+ if denoising_start is None:
+ init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
+ t_start = max(num_inference_steps - init_timestep, 0)
+ else:
+ t_start = 0
+
+ timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
+
+ # Strength is irrelevant if we directly request a timestep to start at;
+ # that is, strength is determined by the denoising_start instead.
+ if denoising_start is not None:
+ discrete_timestep_cutoff = int(
+ round(
+ self.scheduler.config.num_train_timesteps
+ - (denoising_start * self.scheduler.config.num_train_timesteps)
+ )
+ )
+
+ num_inference_steps = (timesteps < discrete_timestep_cutoff).sum().item()
+ if self.scheduler.order == 2 and num_inference_steps % 2 == 0:
+ # if the scheduler is a 2nd order scheduler we might have to do +1
+ # because `num_inference_steps` might be even given that every timestep
+ # (except the highest one) is duplicated. If `num_inference_steps` is even it would
+ # mean that we cut the timesteps in the middle of the denoising step
+ # (between 1st and 2nd derivative) which leads to incorrect results. By adding 1
+ # we ensure that the denoising process always ends after the 2nd derivate step of the scheduler
+ num_inference_steps = num_inference_steps + 1
+
+ # because t_n+1 >= t_n, we slice the timesteps starting from the end
+ timesteps = timesteps[-num_inference_steps:]
+ return timesteps, num_inference_steps
+
+ return timesteps, num_inference_steps - t_start
+
+ def prepare_latents(
+ self,
+ image,
+ mask,
+ width,
+ height,
+ num_channels_latents,
+ timestep,
+ batch_size,
+ num_images_per_prompt,
+ dtype,
+ device,
+ generator=None,
+ add_noise=True,
+ latents=None,
+ is_strength_max=True,
+ return_noise=False,
+ return_image_latents=False,
+ ):
+ batch_size *= num_images_per_prompt
+
+ if image is None:
+ shape = (
+ batch_size,
+ num_channels_latents,
+ int(height) // self.vae_scale_factor,
+ int(width) // self.vae_scale_factor,
+ )
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ elif mask is None:
+ if not isinstance(image, (torch.Tensor, Image.Image, list)):
+ raise ValueError(
+ f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
+ )
+
+ # Offload text encoder if `enable_model_cpu_offload` was enabled
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.text_encoder_2.to("cpu")
+ torch.cuda.empty_cache()
+
+ image = image.to(device=device, dtype=dtype)
+
+ if image.shape[1] == 4:
+ init_latents = image
+
+ else:
+ # make sure the VAE is in float32 mode, as it overflows in float16
+ if self.vae.config.force_upcast:
+ image = image.float()
+ self.vae.to(dtype=torch.float32)
+
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ elif isinstance(generator, list):
+ init_latents = [
+ retrieve_latents(self.vae.encode(image[i : i + 1]), generator=generator[i])
+ for i in range(batch_size)
+ ]
+ init_latents = torch.cat(init_latents, dim=0)
+ else:
+ init_latents = retrieve_latents(self.vae.encode(image), generator=generator)
+
+ if self.vae.config.force_upcast:
+ self.vae.to(dtype)
+
+ init_latents = init_latents.to(dtype)
+ init_latents = self.vae.config.scaling_factor * init_latents
+
+ if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
+ # expand init_latents for batch_size
+ additional_image_per_prompt = batch_size // init_latents.shape[0]
+ init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0)
+ elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
+ raise ValueError(
+ f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
+ )
+ else:
+ init_latents = torch.cat([init_latents], dim=0)
+
+ if add_noise:
+ shape = init_latents.shape
+ noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ # get latents
+ init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
+
+ latents = init_latents
+ return latents
+
+ else:
+ shape = (
+ batch_size,
+ num_channels_latents,
+ int(height) // self.vae_scale_factor,
+ int(width) // self.vae_scale_factor,
+ )
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if (image is None or timestep is None) and not is_strength_max:
+ raise ValueError(
+ "Since strength < 1. initial latents are to be initialised as a combination of Image + Noise."
+ "However, either the image or the noise timestep has not been provided."
+ )
+
+ if image.shape[1] == 4:
+ image_latents = image.to(device=device, dtype=dtype)
+ image_latents = image_latents.repeat(batch_size // image_latents.shape[0], 1, 1, 1)
+ elif return_image_latents or (latents is None and not is_strength_max):
+ image = image.to(device=device, dtype=dtype)
+ image_latents = self._encode_vae_image(image=image, generator=generator)
+ image_latents = image_latents.repeat(batch_size // image_latents.shape[0], 1, 1, 1)
+
+ if latents is None and add_noise:
+ noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ # if strength is 1. then initialise the latents to noise, else initial to image + noise
+ latents = noise if is_strength_max else self.scheduler.add_noise(image_latents, noise, timestep)
+ # if pure noise then scale the initial latents by the Scheduler's init sigma
+ latents = latents * self.scheduler.init_noise_sigma if is_strength_max else latents
+ elif add_noise:
+ noise = latents.to(device)
+ latents = noise * self.scheduler.init_noise_sigma
+ else:
+ noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ latents = image_latents.to(device)
+
+ outputs = (latents,)
+
+ if return_noise:
+ outputs += (noise,)
+
+ if return_image_latents:
+ outputs += (image_latents,)
+
+ return outputs
+
+ def _encode_vae_image(self, image: torch.Tensor, generator: torch.Generator):
+ dtype = image.dtype
+ if self.vae.config.force_upcast:
+ image = image.float()
+ self.vae.to(dtype=torch.float32)
+
+ if isinstance(generator, list):
+ image_latents = [
+ retrieve_latents(self.vae.encode(image[i : i + 1]), generator=generator[i])
+ for i in range(image.shape[0])
+ ]
+ image_latents = torch.cat(image_latents, dim=0)
+ else:
+ image_latents = retrieve_latents(self.vae.encode(image), generator=generator)
+
+ if self.vae.config.force_upcast:
+ self.vae.to(dtype)
+
+ image_latents = image_latents.to(dtype)
+ image_latents = self.vae.config.scaling_factor * image_latents
+
+ return image_latents
+
+ def prepare_mask_latents(
+ self, mask, masked_image, batch_size, height, width, dtype, device, generator, do_classifier_free_guidance
+ ):
+ # resize the mask to latents shape as we concatenate the mask to the latents
+ # we do that before converting to dtype to avoid breaking in case we're using cpu_offload
+ # and half precision
+ mask = torch.nn.functional.interpolate(
+ mask, size=(height // self.vae_scale_factor, width // self.vae_scale_factor)
+ )
+ mask = mask.to(device=device, dtype=dtype)
+
+ # duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
+ if mask.shape[0] < batch_size:
+ if not batch_size % mask.shape[0] == 0:
+ raise ValueError(
+ "The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
+ f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
+ " of masks that you pass is divisible by the total requested batch size."
+ )
+ mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
+
+ mask = torch.cat([mask] * 2) if do_classifier_free_guidance else mask
+
+ if masked_image is not None and masked_image.shape[1] == 4:
+ masked_image_latents = masked_image
+ else:
+ masked_image_latents = None
+
+ if masked_image is not None:
+ if masked_image_latents is None:
+ masked_image = masked_image.to(device=device, dtype=dtype)
+ masked_image_latents = self._encode_vae_image(masked_image, generator=generator)
+
+ if masked_image_latents.shape[0] < batch_size:
+ if not batch_size % masked_image_latents.shape[0] == 0:
+ raise ValueError(
+ "The passed images and the required batch size don't match. Images are supposed to be duplicated"
+ f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
+ " Make sure the number of images that you pass is divisible by the total requested batch size."
+ )
+ masked_image_latents = masked_image_latents.repeat(
+ batch_size // masked_image_latents.shape[0], 1, 1, 1
+ )
+
+ masked_image_latents = (
+ torch.cat([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
+ )
+
+ # aligning device to prevent device errors when concating it with the latent model input
+ masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
+
+ return mask, masked_image_latents
+
+ def _get_add_time_ids(self, original_size, crops_coords_top_left, target_size, dtype):
+ add_time_ids = list(original_size + crops_coords_top_left + target_size)
+
+ passed_add_embed_dim = (
+ self.unet.config.addition_time_embed_dim * len(add_time_ids) + self.text_encoder_2.config.projection_dim
+ )
+ expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
+
+ if expected_add_embed_dim != passed_add_embed_dim:
+ raise ValueError(
+ f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
+ )
+
+ add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
+ return add_time_ids
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae
+ def upcast_vae(self):
+ dtype = self.vae.dtype
+ self.vae.to(dtype=torch.float32)
+ use_torch_2_0_or_xformers = isinstance(
+ self.vae.decoder.mid_block.attentions[0].processor,
+ (AttnProcessor2_0, XFormersAttnProcessor),
+ )
+ # if xformers or torch_2_0 is used attention block does not need
+ # to be in float32 which can save lots of memory
+ if use_torch_2_0_or_xformers:
+ self.vae.post_quant_conv.to(dtype)
+ self.vae.decoder.conv_in.to(dtype)
+ self.vae.decoder.mid_block.to(dtype)
+
+ # Copied from diffusers.pipelines.latent_consistency_models.pipeline_latent_consistency_text2img.LatentConsistencyModelPipeline.get_guidance_scale_embedding
+ def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
+ """
+ See https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
+
+ Args:
+ timesteps (`torch.Tensor`):
+ generate embedding vectors at these timesteps
+ embedding_dim (`int`, *optional*, defaults to 512):
+ dimension of the embeddings to generate
+ dtype:
+ data type of the generated embeddings
+
+ Returns:
+ `torch.Tensor`: Embedding vectors with shape `(len(timesteps), embedding_dim)`
+ """
+ assert len(w.shape) == 1
+ w = w * 1000.0
+
+ half_dim = embedding_dim // 2
+ emb = torch.log(torch.tensor(10000.0)) / (half_dim - 1)
+ emb = torch.exp(torch.arange(half_dim, dtype=dtype) * -emb)
+ emb = w.to(dtype)[:, None] * emb[None, :]
+ emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
+ if embedding_dim % 2 == 1: # zero pad
+ emb = torch.nn.functional.pad(emb, (0, 1))
+ assert emb.shape == (w.shape[0], embedding_dim)
+ return emb
+
+ @property
+ def guidance_scale(self):
+ return self._guidance_scale
+
+ @property
+ def guidance_rescale(self):
+ return self._guidance_rescale
+
+ @property
+ def clip_skip(self):
+ return self._clip_skip
+
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ @property
+ def do_classifier_free_guidance(self):
+ return self._guidance_scale > 1 and self.unet.config.time_cond_proj_dim is None
+
+ @property
+ def cross_attention_kwargs(self):
+ return self._cross_attention_kwargs
+
+ @property
+ def denoising_end(self):
+ return self._denoising_end
+
+ @property
+ def denoising_start(self):
+ return self._denoising_start
+
+ @property
+ def num_timesteps(self):
+ return self._num_timesteps
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: str = None,
+ prompt_2: Optional[str] = None,
+ image: Optional[PipelineImageInput] = None,
+ mask_image: Optional[PipelineImageInput] = None,
+ masked_image_latents: Optional[torch.Tensor] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ strength: float = 0.8,
+ num_inference_steps: int = 50,
+ timesteps: List[int] = None,
+ denoising_start: Optional[float] = None,
+ denoising_end: Optional[float] = None,
+ guidance_scale: float = 5.0,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.Tensor] = None,
+ ip_adapter_image: Optional[PipelineImageInput] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ original_size: Optional[Tuple[int, int]] = None,
+ crops_coords_top_left: Tuple[int, int] = (0, 0),
+ target_size: Optional[Tuple[int, int]] = None,
+ clip_skip: Optional[int] = None,
+ callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
+ callback_on_step_end_tensor_inputs: List[str] = ["latents"],
+ **kwargs,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str`):
+ The prompt to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ prompt_2 (`str`):
+ The prompt to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in both text-encoders
+ image (`PipelineImageInput`, *optional*):
+ `Image`, or tensor representing an image batch, that will be used as the starting point for the
+ process.
+ mask_image (`PipelineImageInput`, *optional*):
+ `Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
+ replaced by noise and therefore repainted, while black pixels will be preserved. If `mask_image` is a
+ PIL image, it will be converted to a single channel (luminance) before use. If it's a tensor, it should
+ contain one color channel (L) instead of 3, so the expected shape would be `(B, H, W, 1)`.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ strength (`float`, *optional*, defaults to 0.8):
+ Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1.
+ `image` will be used as a starting point, adding more noise to it the larger the `strength`. The
+ number of denoising steps depends on the amount of noise initially added. When `strength` is 1, added
+ noise will be maximum and the denoising process will run for the full number of iterations specified in
+ `num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ timesteps (`List[int]`, *optional*):
+ Custom timesteps to use for the denoising process with schedulers which support a `timesteps` argument
+ in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
+ passed will be used. Must be in descending order.
+ denoising_start (`float`, *optional*):
+ When specified, indicates the fraction (between 0.0 and 1.0) of the total denoising process to be
+ bypassed before it is initiated. Consequently, the initial part of the denoising process is skipped and
+ it is assumed that the passed `image` is a partly denoised image. Note that when this is specified,
+ strength will be ignored. The `denoising_start` parameter is particularly beneficial when this pipeline
+ is integrated into a "Mixture of Denoisers" multi-pipeline setup, as detailed in [**Refine Image
+ Quality**](https://huggingface.co/docs/diffusers/using-diffusers/sdxl#refine-image-quality).
+ denoising_end (`float`, *optional*):
+ When specified, determines the fraction (between 0.0 and 1.0) of the total denoising process to be
+ completed before it is intentionally prematurely terminated. As a result, the returned sample will
+ still retain a substantial amount of noise (ca. final 20% of timesteps still needed) and should be
+ denoised by a successor pipeline that has `denoising_start` set to 0.8 so that it only denoises the
+ final 20% of the scheduler. The denoising_end parameter should ideally be utilized when this pipeline
+ forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refine Image
+ Quality**](https://huggingface.co/docs/diffusers/using-diffusers/sdxl#refine-image-quality).
+ guidance_scale (`float`, *optional*, defaults to 5.0):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str`):
+ The prompt not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ negative_prompt_2 (`str`):
+ The prompt not to guide the image generation to be sent to `tokenizer_2` and
+ `text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.Tensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ ip_adapter_image: (`PipelineImageInput`, *optional*):
+ Optional image input to work with IP Adapters.
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ pooled_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ negative_pooled_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
+ input argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] instead
+ of a plain tuple.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+ guidance_rescale (`float`, *optional*, defaults to 0.0):
+ Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Guidance rescale factor should fix overexposure when using zero terminal SNR.
+ original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
+ `original_size` defaults to `(height, width)` if not specified. Part of SDXL's micro-conditioning as
+ explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
+ `crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
+ `crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
+ `crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
+ [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
+ For most cases, `target_size` should be set to the desired height and width of the generated image. If
+ not specified it will default to `(height, width)`. Part of SDXL's micro-conditioning as explained in
+ section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
+ clip_skip (`int`, *optional*):
+ Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
+ the output of the pre-final layer will be used for computing the prompt embeddings.
+ callback_on_step_end (`Callable`, *optional*):
+ A function that calls at the end of each denoising steps during the inference. The function is called
+ with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
+ callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
+ `callback_on_step_end_tensor_inputs`.
+ callback_on_step_end_tensor_inputs (`List`, *optional*):
+ The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
+ will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
+ `._callback_tensor_inputs` attribute of your pipeline class.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] if `return_dict` is True, otherwise a
+ `tuple`. When returning a tuple, the first element is a list with the generated images.
+ """
+
+ callback = kwargs.pop("callback", None)
+ callback_steps = kwargs.pop("callback_steps", None)
+
+ if callback is not None:
+ deprecate(
+ "callback",
+ "1.0.0",
+ "Passing `callback` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
+ )
+ if callback_steps is not None:
+ deprecate(
+ "callback_steps",
+ "1.0.0",
+ "Passing `callback_steps` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
+ )
+
+ # 0. Default height and width to unet
+ height = height or self.default_sample_size * self.vae_scale_factor
+ width = width or self.default_sample_size * self.vae_scale_factor
+
+ original_size = original_size or (height, width)
+ target_size = target_size or (height, width)
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ prompt_2,
+ height,
+ width,
+ strength,
+ callback_steps,
+ negative_prompt,
+ negative_prompt_2,
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ callback_on_step_end_tensor_inputs,
+ )
+
+ self._guidance_scale = guidance_scale
+ self._guidance_rescale = guidance_rescale
+ self._clip_skip = clip_skip
+ self._cross_attention_kwargs = cross_attention_kwargs
+ self._denoising_end = denoising_end
+ self._denoising_start = denoising_start
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+
+ if ip_adapter_image is not None:
+ output_hidden_state = False if isinstance(self.unet.encoder_hid_proj, ImageProjection) else True
+ image_embeds, negative_image_embeds = self.encode_image(
+ ip_adapter_image, device, num_images_per_prompt, output_hidden_state
+ )
+ if self.do_classifier_free_guidance:
+ image_embeds = torch.cat([negative_image_embeds, image_embeds])
+
+ # 3. Encode input prompt
+ lora_scale = (
+ self._cross_attention_kwargs.get("scale", None) if self._cross_attention_kwargs is not None else None
+ )
+
+ negative_prompt = negative_prompt if negative_prompt is not None else ""
+
+ (
+ prompt_embeds,
+ negative_prompt_embeds,
+ pooled_prompt_embeds,
+ negative_pooled_prompt_embeds,
+ ) = get_weighted_text_embeddings_sdxl(
+ pipe=self,
+ prompt=prompt,
+ neg_prompt=negative_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ clip_skip=clip_skip,
+ lora_scale=lora_scale,
+ )
+ dtype = prompt_embeds.dtype
+
+ if isinstance(image, Image.Image):
+ image = self.image_processor.preprocess(image, height=height, width=width)
+ if image is not None:
+ image = image.to(device=self.device, dtype=dtype)
+
+ if isinstance(mask_image, Image.Image):
+ mask = self.mask_processor.preprocess(mask_image, height=height, width=width)
+ else:
+ mask = mask_image
+ if mask_image is not None:
+ mask = mask.to(device=self.device, dtype=dtype)
+
+ if masked_image_latents is not None:
+ masked_image = masked_image_latents
+ elif image.shape[1] == 4:
+ # if image is in latent space, we can't mask it
+ masked_image = None
+ else:
+ masked_image = image * (mask < 0.5)
+ else:
+ mask = None
+
+ # 4. Prepare timesteps
+ def denoising_value_valid(dnv):
+ return isinstance(dnv, float) and 0 < dnv < 1
+
+ timesteps, num_inference_steps = retrieve_timesteps(self.scheduler, num_inference_steps, device, timesteps)
+ if image is not None:
+ timesteps, num_inference_steps = self.get_timesteps(
+ num_inference_steps,
+ strength,
+ device,
+ denoising_start=self.denoising_start if denoising_value_valid(self.denoising_start) else None,
+ )
+
+ # check that number of inference steps is not < 1 - as this doesn't make sense
+ if num_inference_steps < 1:
+ raise ValueError(
+ f"After adjusting the num_inference_steps by strength parameter: {strength}, the number of pipeline"
+ f"steps is {num_inference_steps} which is < 1 and not appropriate for this pipeline."
+ )
+
+ latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
+ is_strength_max = strength == 1.0
+ add_noise = True if self.denoising_start is None else False
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.vae.config.latent_channels
+ num_channels_unet = self.unet.config.in_channels
+ return_image_latents = num_channels_unet == 4
+
+ latents = self.prepare_latents(
+ image=image,
+ mask=mask,
+ width=width,
+ height=height,
+ num_channels_latents=num_channels_unet,
+ timestep=latent_timestep,
+ batch_size=batch_size,
+ num_images_per_prompt=num_images_per_prompt,
+ dtype=prompt_embeds.dtype,
+ device=device,
+ generator=generator,
+ add_noise=add_noise,
+ latents=latents,
+ is_strength_max=is_strength_max,
+ return_noise=True,
+ return_image_latents=return_image_latents,
+ )
+
+ if mask is not None:
+ if return_image_latents:
+ latents, noise, image_latents = latents
+ else:
+ latents, noise = latents
+
+ # 5.1 Prepare mask latent variables
+ if mask is not None:
+ mask, masked_image_latents = self.prepare_mask_latents(
+ mask=mask,
+ masked_image=masked_image,
+ batch_size=batch_size * num_images_per_prompt,
+ height=height,
+ width=width,
+ dtype=prompt_embeds.dtype,
+ device=device,
+ generator=generator,
+ do_classifier_free_guidance=self.do_classifier_free_guidance,
+ )
+
+ # Check that sizes of mask, masked image and latents match
+ if num_channels_unet == 9:
+ # default case for runwayml/stable-diffusion-inpainting
+ num_channels_mask = mask.shape[1]
+ num_channels_masked_image = masked_image_latents.shape[1]
+ if num_channels_latents + num_channels_mask + num_channels_masked_image != num_channels_unet:
+ raise ValueError(
+ f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
+ f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
+ f" `num_channels_mask`: {num_channels_mask} + `num_channels_masked_image`: {num_channels_masked_image}"
+ f" = {num_channels_latents+num_channels_masked_image+num_channels_mask}. Please verify the config of"
+ " `pipeline.unet` or your `mask_image` or `image` input."
+ )
+ elif num_channels_unet != 4:
+ raise ValueError(
+ f"The unet {self.unet.__class__} should have either 4 or 9 input channels, not {self.unet.config.in_channels}."
+ )
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 6.1 Add image embeds for IP-Adapter
+ added_cond_kwargs = {"image_embeds": image_embeds} if ip_adapter_image is not None else {}
+
+ height, width = latents.shape[-2:]
+ height = height * self.vae_scale_factor
+ width = width * self.vae_scale_factor
+
+ original_size = original_size or (height, width)
+ target_size = target_size or (height, width)
+
+ # 7. Prepare added time ids & embeddings
+ add_text_embeds = pooled_prompt_embeds
+ add_time_ids = self._get_add_time_ids(
+ original_size, crops_coords_top_left, target_size, dtype=prompt_embeds.dtype
+ )
+
+ if self.do_classifier_free_guidance:
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
+ add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
+ add_time_ids = torch.cat([add_time_ids, add_time_ids], dim=0)
+
+ prompt_embeds = prompt_embeds.to(device)
+ add_text_embeds = add_text_embeds.to(device)
+ add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
+
+ num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
+
+ # 7.1 Apply denoising_end
+ if (
+ self.denoising_end is not None
+ and self.denoising_start is not None
+ and denoising_value_valid(self.denoising_end)
+ and denoising_value_valid(self.denoising_start)
+ and self.denoising_start >= self.denoising_end
+ ):
+ raise ValueError(
+ f"`denoising_start`: {self.denoising_start} cannot be larger than or equal to `denoising_end`: "
+ + f" {self.denoising_end} when using type float."
+ )
+ elif self.denoising_end is not None and denoising_value_valid(self.denoising_end):
+ discrete_timestep_cutoff = int(
+ round(
+ self.scheduler.config.num_train_timesteps
+ - (self.denoising_end * self.scheduler.config.num_train_timesteps)
+ )
+ )
+ num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps)))
+ timesteps = timesteps[:num_inference_steps]
+
+ # 8. Optionally get Guidance Scale Embedding
+ timestep_cond = None
+ if self.unet.config.time_cond_proj_dim is not None:
+ guidance_scale_tensor = torch.tensor(self.guidance_scale - 1).repeat(batch_size * num_images_per_prompt)
+ timestep_cond = self.get_guidance_scale_embedding(
+ guidance_scale_tensor, embedding_dim=self.unet.config.time_cond_proj_dim
+ ).to(device=device, dtype=latents.dtype)
+
+ self._num_timesteps = len(timesteps)
+
+ # 9. Denoising loop
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
+
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ if mask is not None and num_channels_unet == 9:
+ latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
+
+ # predict the noise residual
+ added_cond_kwargs.update({"text_embeds": add_text_embeds, "time_ids": add_time_ids})
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ timestep_cond=timestep_cond,
+ cross_attention_kwargs=self.cross_attention_kwargs,
+ added_cond_kwargs=added_cond_kwargs,
+ return_dict=False,
+ )[0]
+
+ # perform guidance
+ if self.do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ if self.do_classifier_free_guidance and guidance_rescale > 0.0:
+ # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ if mask is not None and num_channels_unet == 4:
+ init_latents_proper = image_latents
+
+ if self.do_classifier_free_guidance:
+ init_mask, _ = mask.chunk(2)
+ else:
+ init_mask = mask
+
+ if i < len(timesteps) - 1:
+ noise_timestep = timesteps[i + 1]
+ init_latents_proper = self.scheduler.add_noise(
+ init_latents_proper, noise, torch.tensor([noise_timestep])
+ )
+
+ latents = (1 - init_mask) * init_latents_proper + init_mask * latents
+
+ if callback_on_step_end is not None:
+ callback_kwargs = {}
+ for k in callback_on_step_end_tensor_inputs:
+ callback_kwargs[k] = locals()[k]
+ callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
+
+ latents = callback_outputs.pop("latents", latents)
+ prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
+ negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)
+ add_text_embeds = callback_outputs.pop("add_text_embeds", add_text_embeds)
+ negative_pooled_prompt_embeds = callback_outputs.pop(
+ "negative_pooled_prompt_embeds", negative_pooled_prompt_embeds
+ )
+ add_time_ids = callback_outputs.pop("add_time_ids", add_time_ids)
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ step_idx = i // getattr(self.scheduler, "order", 1)
+ callback(step_idx, t, latents)
+
+ if not output_type == "latent":
+ # make sure the VAE is in float32 mode, as it overflows in float16
+ needs_upcasting = self.vae.dtype == torch.float16 and self.vae.config.force_upcast
+
+ if needs_upcasting:
+ self.upcast_vae()
+ latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
+
+ image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
+
+ # cast back to fp16 if needed
+ if needs_upcasting:
+ self.vae.to(dtype=torch.float16)
+ else:
+ image = latents
+ return StableDiffusionXLPipelineOutput(images=image)
+
+ # apply watermark if available
+ if self.watermark is not None:
+ image = self.watermark.apply_watermark(image)
+
+ image = self.image_processor.postprocess(image, output_type=output_type)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image,)
+
+ return StableDiffusionXLPipelineOutput(images=image)
+
+ def text2img(
+ self,
+ prompt: str = None,
+ prompt_2: Optional[str] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ timesteps: List[int] = None,
+ denoising_start: Optional[float] = None,
+ denoising_end: Optional[float] = None,
+ guidance_scale: float = 5.0,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.Tensor] = None,
+ ip_adapter_image: Optional[PipelineImageInput] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ original_size: Optional[Tuple[int, int]] = None,
+ crops_coords_top_left: Tuple[int, int] = (0, 0),
+ target_size: Optional[Tuple[int, int]] = None,
+ clip_skip: Optional[int] = None,
+ callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
+ callback_on_step_end_tensor_inputs: List[str] = ["latents"],
+ **kwargs,
+ ):
+ r"""
+ Function invoked when calling pipeline for text-to-image.
+
+ Refer to the documentation of the `__call__` method for parameter descriptions.
+ """
+ return self.__call__(
+ prompt=prompt,
+ prompt_2=prompt_2,
+ height=height,
+ width=width,
+ num_inference_steps=num_inference_steps,
+ timesteps=timesteps,
+ denoising_start=denoising_start,
+ denoising_end=denoising_end,
+ guidance_scale=guidance_scale,
+ negative_prompt=negative_prompt,
+ negative_prompt_2=negative_prompt_2,
+ num_images_per_prompt=num_images_per_prompt,
+ eta=eta,
+ generator=generator,
+ latents=latents,
+ ip_adapter_image=ip_adapter_image,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
+ output_type=output_type,
+ return_dict=return_dict,
+ cross_attention_kwargs=cross_attention_kwargs,
+ guidance_rescale=guidance_rescale,
+ original_size=original_size,
+ crops_coords_top_left=crops_coords_top_left,
+ target_size=target_size,
+ clip_skip=clip_skip,
+ callback_on_step_end=callback_on_step_end,
+ callback_on_step_end_tensor_inputs=callback_on_step_end_tensor_inputs,
+ **kwargs,
+ )
+
+ def img2img(
+ self,
+ prompt: str = None,
+ prompt_2: Optional[str] = None,
+ image: Optional[PipelineImageInput] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ strength: float = 0.8,
+ num_inference_steps: int = 50,
+ timesteps: List[int] = None,
+ denoising_start: Optional[float] = None,
+ denoising_end: Optional[float] = None,
+ guidance_scale: float = 5.0,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.Tensor] = None,
+ ip_adapter_image: Optional[PipelineImageInput] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ original_size: Optional[Tuple[int, int]] = None,
+ crops_coords_top_left: Tuple[int, int] = (0, 0),
+ target_size: Optional[Tuple[int, int]] = None,
+ clip_skip: Optional[int] = None,
+ callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
+ callback_on_step_end_tensor_inputs: List[str] = ["latents"],
+ **kwargs,
+ ):
+ r"""
+ Function invoked when calling pipeline for image-to-image.
+
+ Refer to the documentation of the `__call__` method for parameter descriptions.
+ """
+ return self.__call__(
+ prompt=prompt,
+ prompt_2=prompt_2,
+ image=image,
+ height=height,
+ width=width,
+ strength=strength,
+ num_inference_steps=num_inference_steps,
+ timesteps=timesteps,
+ denoising_start=denoising_start,
+ denoising_end=denoising_end,
+ guidance_scale=guidance_scale,
+ negative_prompt=negative_prompt,
+ negative_prompt_2=negative_prompt_2,
+ num_images_per_prompt=num_images_per_prompt,
+ eta=eta,
+ generator=generator,
+ latents=latents,
+ ip_adapter_image=ip_adapter_image,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
+ output_type=output_type,
+ return_dict=return_dict,
+ cross_attention_kwargs=cross_attention_kwargs,
+ guidance_rescale=guidance_rescale,
+ original_size=original_size,
+ crops_coords_top_left=crops_coords_top_left,
+ target_size=target_size,
+ clip_skip=clip_skip,
+ callback_on_step_end=callback_on_step_end,
+ callback_on_step_end_tensor_inputs=callback_on_step_end_tensor_inputs,
+ **kwargs,
+ )
+
+ def inpaint(
+ self,
+ prompt: str = None,
+ prompt_2: Optional[str] = None,
+ image: Optional[PipelineImageInput] = None,
+ mask_image: Optional[PipelineImageInput] = None,
+ masked_image_latents: Optional[torch.Tensor] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ strength: float = 0.8,
+ num_inference_steps: int = 50,
+ timesteps: List[int] = None,
+ denoising_start: Optional[float] = None,
+ denoising_end: Optional[float] = None,
+ guidance_scale: float = 5.0,
+ negative_prompt: Optional[str] = None,
+ negative_prompt_2: Optional[str] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.Tensor] = None,
+ ip_adapter_image: Optional[PipelineImageInput] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ negative_pooled_prompt_embeds: Optional[torch.Tensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ original_size: Optional[Tuple[int, int]] = None,
+ crops_coords_top_left: Tuple[int, int] = (0, 0),
+ target_size: Optional[Tuple[int, int]] = None,
+ clip_skip: Optional[int] = None,
+ callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
+ callback_on_step_end_tensor_inputs: List[str] = ["latents"],
+ **kwargs,
+ ):
+ r"""
+ Function invoked when calling pipeline for inpainting.
+
+ Refer to the documentation of the `__call__` method for parameter descriptions.
+ """
+ return self.__call__(
+ prompt=prompt,
+ prompt_2=prompt_2,
+ image=image,
+ mask_image=mask_image,
+ masked_image_latents=masked_image_latents,
+ height=height,
+ width=width,
+ strength=strength,
+ num_inference_steps=num_inference_steps,
+ timesteps=timesteps,
+ denoising_start=denoising_start,
+ denoising_end=denoising_end,
+ guidance_scale=guidance_scale,
+ negative_prompt=negative_prompt,
+ negative_prompt_2=negative_prompt_2,
+ num_images_per_prompt=num_images_per_prompt,
+ eta=eta,
+ generator=generator,
+ latents=latents,
+ ip_adapter_image=ip_adapter_image,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
+ output_type=output_type,
+ return_dict=return_dict,
+ cross_attention_kwargs=cross_attention_kwargs,
+ guidance_rescale=guidance_rescale,
+ original_size=original_size,
+ crops_coords_top_left=crops_coords_top_left,
+ target_size=target_size,
+ clip_skip=clip_skip,
+ callback_on_step_end=callback_on_step_end,
+ callback_on_step_end_tensor_inputs=callback_on_step_end_tensor_inputs,
+ **kwargs,
+ )
+
+ # Override to properly handle the loading and unloading of the additional text encoder.
+ def load_lora_weights(self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], **kwargs):
+ # We could have accessed the unet config from `lora_state_dict()` too. We pass
+ # it here explicitly to be able to tell that it's coming from an SDXL
+ # pipeline.
+ state_dict, network_alphas = self.lora_state_dict(
+ pretrained_model_name_or_path_or_dict,
+ unet_config=self.unet.config,
+ **kwargs,
+ )
+ self.load_lora_into_unet(state_dict, network_alphas=network_alphas, unet=self.unet)
+
+ text_encoder_state_dict = {k: v for k, v in state_dict.items() if "text_encoder." in k}
+ if len(text_encoder_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder,
+ prefix="text_encoder",
+ lora_scale=self.lora_scale,
+ )
+
+ text_encoder_2_state_dict = {k: v for k, v in state_dict.items() if "text_encoder_2." in k}
+ if len(text_encoder_2_state_dict) > 0:
+ self.load_lora_into_text_encoder(
+ text_encoder_2_state_dict,
+ network_alphas=network_alphas,
+ text_encoder=self.text_encoder_2,
+ prefix="text_encoder_2",
+ lora_scale=self.lora_scale,
+ )
+
+ @classmethod
+ def save_lora_weights(
+ cls,
+ save_directory: Union[str, os.PathLike],
+ unet_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ text_encoder_2_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
+ is_main_process: bool = True,
+ weight_name: str = None,
+ save_function: Callable = None,
+ safe_serialization: bool = False,
+ ):
+ state_dict = {}
+
+ def pack_weights(layers, prefix):
+ layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers
+ layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()}
+ return layers_state_dict
+
+ state_dict.update(pack_weights(unet_lora_layers, "unet"))
+
+ if text_encoder_lora_layers and text_encoder_2_lora_layers:
+ state_dict.update(pack_weights(text_encoder_lora_layers, "text_encoder"))
+ state_dict.update(pack_weights(text_encoder_2_lora_layers, "text_encoder_2"))
+
+ cls.write_lora_layers(
+ state_dict=state_dict,
+ save_directory=save_directory,
+ is_main_process=is_main_process,
+ weight_name=weight_name,
+ save_function=save_function,
+ safe_serialization=safe_serialization,
+ )
+
+ def _remove_text_encoder_monkey_patch(self):
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder)
+ self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder_2)
\ No newline at end of file
diff --git a/animate/src/animatediff/utils/mask.py b/animate/src/animatediff/utils/mask.py
new file mode 100644
index 0000000000000000000000000000000000000000..4f4359ac1063187a60cb651159b7359a06045a91
--- /dev/null
+++ b/animate/src/animatediff/utils/mask.py
@@ -0,0 +1,721 @@
+import glob
+import logging
+import os
+from pathlib import Path
+
+import cv2
+import numpy as np
+import torch
+from groundingdino.models import build_model
+from groundingdino.util.slconfig import SLConfig
+from groundingdino.util.utils import clean_state_dict, get_phrases_from_posmap
+from PIL import Image
+from segment_anything_hq import (SamPredictor, build_sam_vit_b,
+ build_sam_vit_h, build_sam_vit_l)
+from segment_anything_hq.build_sam import build_sam_vit_t
+from tqdm.rich import tqdm
+
+logger = logging.getLogger(__name__)
+
+build_sam_table={
+ "sam_hq_vit_l":build_sam_vit_l,
+ "sam_hq_vit_h":build_sam_vit_h,
+ "sam_hq_vit_b":build_sam_vit_b,
+ "sam_hq_vit_tiny":build_sam_vit_t,
+}
+
+# adapted from https://github.com/IDEA-Research/Grounded-Segment-Anything/blob/main/grounded_sam_demo.py
+class MaskPredictor:
+ def __init__(self,model_config_path, model_checkpoint_path,device, sam_checkpoint, box_threshold=0.3, text_threshold=0.25 ):
+ self.groundingdino_model = None
+ self.sam_predictor = None
+
+ self.model_config_path = model_config_path
+ self.model_checkpoint_path = model_checkpoint_path
+ self.device = device
+ self.sam_checkpoint = sam_checkpoint
+
+ self.box_threshold = box_threshold
+ self.text_threshold = text_threshold
+
+ def load_groundingdino_model(self):
+ args = SLConfig.fromfile(self.model_config_path)
+ args.device = self.device
+ model = build_model(args)
+ checkpoint = torch.load(self.model_checkpoint_path, map_location="cpu")
+ load_res = model.load_state_dict(clean_state_dict(checkpoint["model"]), strict=False)
+ #print(load_res)
+ _ = model.eval()
+ self.groundingdino_model = model
+
+ def load_sam_predictor(self):
+ s = Path(self.sam_checkpoint)
+ self.sam_predictor = SamPredictor(build_sam_table[ s.stem ](checkpoint=self.sam_checkpoint).to(self.device))
+
+ def transform_image(self,image_pil):
+ import groundingdino.datasets.transforms as T
+ transform = T.Compose(
+ [
+ T.RandomResize([800], max_size=1333),
+ T.ToTensor(),
+ T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
+ ]
+ )
+ image, _ = transform(image_pil, None) # 3, h, w
+ return image
+
+ def get_grounding_output(self, image, caption, with_logits=True):
+ model = self.groundingdino_model
+ device = self.device
+
+ caption = caption.lower()
+ caption = caption.strip()
+ if not caption.endswith("."):
+ caption = caption + "."
+ model = model.to(device)
+ image = image.to(device)
+ with torch.no_grad():
+ outputs = model(image[None], captions=[caption])
+ logits = outputs["pred_logits"].cpu().sigmoid()[0] # (nq, 256)
+ boxes = outputs["pred_boxes"].cpu()[0] # (nq, 4)
+ logits.shape[0]
+
+ # filter output
+ logits_filt = logits.clone()
+ boxes_filt = boxes.clone()
+ filt_mask = logits_filt.max(dim=1)[0] > self.box_threshold
+ logits_filt = logits_filt[filt_mask] # num_filt, 256
+ boxes_filt = boxes_filt[filt_mask] # num_filt, 4
+ logits_filt.shape[0]
+
+ # get phrase
+ tokenlizer = model.tokenizer
+ tokenized = tokenlizer(caption)
+ # build pred
+ pred_phrases = []
+ for logit, box in zip(logits_filt, boxes_filt):
+ pred_phrase = get_phrases_from_posmap(logit > self.text_threshold, tokenized, tokenlizer)
+ if with_logits:
+ pred_phrases.append(pred_phrase + f"({str(logit.max().item())[:4]})")
+ else:
+ pred_phrases.append(pred_phrase)
+
+ return boxes_filt, pred_phrases
+
+
+ def __call__(self, image_pil:Image, text_prompt):
+ if self.groundingdino_model is None:
+ self.load_groundingdino_model()
+ self.load_sam_predictor()
+
+ transformed_img = self.transform_image(image_pil)
+
+ # run grounding dino model
+ boxes_filt, pred_phrases = self.get_grounding_output(
+ transformed_img, text_prompt
+ )
+
+ if boxes_filt.shape[0] == 0:
+ logger.info(f"object not found")
+ w, h = image_pil.size
+ return np.zeros(shape=(1,h,w), dtype=bool)
+
+ img_array = np.array(image_pil)
+ self.sam_predictor.set_image(img_array)
+
+ size = image_pil.size
+ H, W = size[1], size[0]
+ for i in range(boxes_filt.size(0)):
+ boxes_filt[i] = boxes_filt[i] * torch.Tensor([W, H, W, H])
+ boxes_filt[i][:2] -= boxes_filt[i][2:] / 2
+ boxes_filt[i][2:] += boxes_filt[i][:2]
+
+ boxes_filt = boxes_filt.cpu()
+ transformed_boxes = self.sam_predictor.transform.apply_boxes_torch(boxes_filt, img_array.shape[:2]).to(self.device)
+
+ masks, _, _ = self.sam_predictor.predict_torch(
+ point_coords = None,
+ point_labels = None,
+ boxes = transformed_boxes.to(self.device),
+ multimask_output = False,
+ )
+
+ result = None
+ for m in masks:
+ if result is None:
+ result = m
+ else:
+ result |= m
+
+ result = result.cpu().detach().numpy().copy()
+
+ return result
+
+def load_mask_list(mask_dir, masked_area_list, mask_padding):
+
+ mask_frame_list = sorted(glob.glob( os.path.join(mask_dir, "[0-9]*.png"), recursive=False))
+
+ kernel = np.ones((abs(mask_padding),abs(mask_padding)),np.uint8)
+
+ for m in mask_frame_list:
+ cur = int(Path(m).stem)
+ tmp = np.asarray(Image.open(m))
+
+ if mask_padding < 0:
+ tmp = cv2.erode(tmp, kernel,iterations = 1)
+ elif mask_padding > 0:
+ tmp = cv2.dilate(tmp, kernel,iterations = 1)
+
+ masked_area_list[cur] = tmp[None,...]
+
+ return masked_area_list
+
+def crop_mask_list(mask_list):
+ area_list = []
+
+ max_h = 0
+ max_w = 0
+
+ for m in mask_list:
+ if m is None:
+ area_list.append(None)
+ continue
+ m = m > 127
+ area = np.where(m[0] == True)
+ if area[0].size == 0:
+ area_list.append(None)
+ continue
+
+ ymin = min(area[0])
+ ymax = max(area[0])
+ xmin = min(area[1])
+ xmax = max(area[1])
+ h = ymax+1 - ymin
+ w = xmax+1 - xmin
+ max_h = max(max_h, h)
+ max_w = max(max_w, w)
+ area_list.append( (ymin, ymax, xmin, xmax) )
+ #crop = m[ymin:ymax+1,xmin:xmax+1]
+
+ logger.info(f"{max_h=}")
+ logger.info(f"{max_w=}")
+
+ border_h = mask_list[0].shape[1]
+ border_w = mask_list[0].shape[2]
+
+ mask_pos_list=[]
+ cropped_mask_list=[]
+
+ for a, m in zip(area_list, mask_list):
+ if m is None or a is None:
+ mask_pos_list.append(None)
+ cropped_mask_list.append(None)
+ continue
+
+ ymin,ymax,xmin,xmax = a
+ h = ymax+1 - ymin
+ w = xmax+1 - xmin
+
+ # H
+ diff_h = max_h - h
+ dh1 = diff_h//2
+ dh2 = diff_h - dh1
+ y1 = ymin - dh1
+ y2 = ymax + dh2
+ if y1 < 0:
+ y1 = 0
+ y2 = max_h-1
+ elif y2 >= border_h:
+ y1 = (border_h-1) - (max_h - 1)
+ y2 = (border_h-1)
+
+ # W
+ diff_w = max_w - w
+ dw1 = diff_w//2
+ dw2 = diff_w - dw1
+ x1 = xmin - dw1
+ x2 = xmax + dw2
+ if x1 < 0:
+ x1 = 0
+ x2 = max_w-1
+ elif x2 >= border_w:
+ x1 = (border_w-1) - (max_w - 1)
+ x2 = (border_w-1)
+
+ mask_pos_list.append( (int(x1),int(y1)) )
+ m = m[0][y1:y2+1,x1:x2+1]
+ cropped_mask_list.append( m[None,...] )
+
+
+ return cropped_mask_list, mask_pos_list, (max_h,max_w)
+
+def crop_frames(pos_list, crop_size_hw, frame_dir):
+ h,w = crop_size_hw
+
+ for i,pos in tqdm(enumerate(pos_list),total=len(pos_list)):
+ filename = f"{i:08d}.png"
+ frame_path = frame_dir / filename
+ if not frame_path.is_file():
+ logger.info(f"{frame_path=} not found. skip")
+ continue
+ if pos is None:
+ continue
+
+ x, y = pos
+
+ tmp = np.asarray(Image.open(frame_path))
+ tmp = tmp[y:y+h,x:x+w,...]
+ Image.fromarray(tmp).save(frame_path)
+
+def save_crop_info(mask_pos_list, crop_size_hw, frame_size_hw, save_path):
+ import json
+
+ pos_map = {}
+
+ for i, pos in enumerate(mask_pos_list):
+ if pos is not None:
+ pos_map[str(i)]=pos
+
+ info = {
+ "frame_height" : int(frame_size_hw[0]),
+ "frame_width" : int(frame_size_hw[1]),
+ "height": int(crop_size_hw[0]),
+ "width": int(crop_size_hw[1]),
+ "pos_map" : pos_map,
+ }
+
+ with open(save_path, mode="wt", encoding="utf-8") as f:
+ json.dump(info, f, ensure_ascii=False, indent=4)
+
+def restore_position(mask_list, crop_info):
+
+ f_h = crop_info["frame_height"]
+ f_w = crop_info["frame_width"]
+
+ h = crop_info["height"]
+ w = crop_info["width"]
+ pos_map = crop_info["pos_map"]
+
+ for i in pos_map:
+ x,y = pos_map[i]
+ i = int(i)
+
+ m = mask_list[i]
+
+ if m is None:
+ continue
+
+ m = cv2.resize( m, (w,h) )
+ if len(m.shape) == 2:
+ m = m[...,None]
+
+ frame = np.zeros(shape=(f_h,f_w,m.shape[2]), dtype=np.uint8)
+
+ frame[y:y+h,x:x+w,...] = m
+ mask_list[i] = frame
+
+
+ return mask_list
+
+def load_frame_list(frame_dir, frame_array_list, crop_info):
+ frame_list = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+
+ for f in frame_list:
+ cur = int(Path(f).stem)
+ frame_array_list[cur] = np.asarray(Image.open(f))
+
+ if not crop_info:
+ logger.info(f"crop_info is not exists -> skip restore")
+ return frame_array_list
+
+ for i,f in enumerate(frame_array_list):
+ if f is None:
+ continue
+ frame_array_list[i] = f
+
+ frame_array_list = restore_position(frame_array_list, crop_info)
+
+ return frame_array_list
+
+
+def create_fg(mask_token, frame_dir, output_dir, output_mask_dir, masked_area_list,
+ box_threshold=0.3,
+ text_threshold=0.25,
+ bg_color=(0,255,0),
+ mask_padding=0,
+ groundingdino_config="config/GroundingDINO/GroundingDINO_SwinB_cfg.py",
+ groundingdino_checkpoint="data/models/GroundingDINO/groundingdino_swinb_cogcoor.pth",
+ sam_checkpoint="data/models/SAM/sam_hq_vit_l.pth",
+ device="cuda",
+ ):
+
+ frame_list = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+
+ with torch.no_grad():
+ predictor = MaskPredictor(
+ model_config_path=groundingdino_config,
+ model_checkpoint_path=groundingdino_checkpoint,
+ device=device,
+ sam_checkpoint=sam_checkpoint,
+ box_threshold=box_threshold,
+ text_threshold=text_threshold,
+ )
+
+
+ if mask_padding != 0:
+ kernel = np.ones((abs(mask_padding),abs(mask_padding)),np.uint8)
+ kernel2 = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
+
+ for i, frame in tqdm(enumerate(frame_list),total=len(frame_list), desc=f"creating mask from {mask_token=}"):
+ frame = Path(frame)
+ file_name = frame.name
+
+ cur_frame_no = int(frame.stem)
+
+ img = Image.open(frame)
+
+ mask_array = predictor(img, mask_token)
+ mask_array = mask_array[0].astype(np.uint8) * 255
+
+
+ if mask_padding < 0:
+ mask_array = cv2.erode(mask_array.astype(np.uint8),kernel,iterations = 1)
+ elif mask_padding > 0:
+ mask_array = cv2.dilate(mask_array.astype(np.uint8),kernel,iterations = 1)
+
+ mask_array = cv2.morphologyEx(mask_array.astype(np.uint8), cv2.MORPH_OPEN, kernel2)
+ mask_array = cv2.GaussianBlur(mask_array, (7, 7), sigmaX=3, sigmaY=3, borderType=cv2.BORDER_DEFAULT)
+
+ if masked_area_list[cur_frame_no] is not None:
+ masked_area_list[cur_frame_no] = np.where(masked_area_list[cur_frame_no] > mask_array[None,...], masked_area_list[cur_frame_no], mask_array[None,...])
+ #masked_area_list[cur_frame_no] = masked_area_list[cur_frame_no] | mask_array[None,...]
+ else:
+ masked_area_list[cur_frame_no] = mask_array[None,...]
+
+
+ if output_mask_dir:
+ #mask_array2 = mask_array.astype(np.uint8).clip(0,1)
+ #mask_array2 *= 255
+ Image.fromarray(mask_array).save( output_mask_dir / file_name )
+
+ img_array = np.asarray(img).copy()
+ if bg_color is not None:
+ img_array[mask_array == 0] = bg_color
+
+ img = Image.fromarray(img_array)
+
+ img.save( output_dir / file_name )
+
+ return masked_area_list
+
+
+def dilate_mask(masked_area_list, flow_mask_dilates=8, mask_dilates=5):
+ kernel = np.ones((flow_mask_dilates,flow_mask_dilates),np.uint8)
+ flow_masks = [ cv2.dilate(mask[0].astype(np.uint8),kernel,iterations = 1) for mask in masked_area_list ]
+ flow_masks = [ Image.fromarray(mask * 255) for mask in flow_masks ]
+
+ kernel = np.ones((mask_dilates,mask_dilates),np.uint8)
+ dilated_masks = [ cv2.dilate(mask[0].astype(np.uint8),kernel,iterations = 1) for mask in masked_area_list ]
+ dilated_masks = [ Image.fromarray(mask * 255) for mask in dilated_masks ]
+
+ return flow_masks, dilated_masks
+
+
+# adapted from https://github.com/sczhou/ProPainter/blob/main/inference_propainter.py
+def resize_frames(frames, size=None):
+ if size is not None:
+ out_size = size
+ process_size = (out_size[0]-out_size[0]%8, out_size[1]-out_size[1]%8)
+ frames = [f.resize(process_size) for f in frames]
+ else:
+ out_size = frames[0].size
+ process_size = (out_size[0]-out_size[0]%8, out_size[1]-out_size[1]%8)
+ if not out_size == process_size:
+ frames = [f.resize(process_size) for f in frames]
+
+ return frames, process_size, out_size
+
+def get_ref_index(mid_neighbor_id, neighbor_ids, length, ref_stride=10, ref_num=-1):
+ ref_index = []
+ if ref_num == -1:
+ for i in range(0, length, ref_stride):
+ if i not in neighbor_ids:
+ ref_index.append(i)
+ else:
+ start_idx = max(0, mid_neighbor_id - ref_stride * (ref_num // 2))
+ end_idx = min(length, mid_neighbor_id + ref_stride * (ref_num // 2))
+ for i in range(start_idx, end_idx, ref_stride):
+ if i not in neighbor_ids:
+ if len(ref_index) > ref_num:
+ break
+ ref_index.append(i)
+ return ref_index
+
+def create_bg(frame_dir, output_dir, masked_area_list,
+ use_half = True,
+ raft_iter = 20,
+ subvideo_length=80,
+ neighbor_length=10,
+ ref_stride=10,
+ device="cuda",
+ low_vram = False,
+ ):
+ import sys
+ repo_path = Path("src/animatediff/repo/ProPainter").absolute()
+ repo_path = str(repo_path)
+ sys.path.append(repo_path)
+
+ from animatediff.repo.ProPainter.core.utils import to_tensors
+ from animatediff.repo.ProPainter.model.modules.flow_comp_raft import \
+ RAFT_bi
+ from animatediff.repo.ProPainter.model.propainter import InpaintGenerator
+ from animatediff.repo.ProPainter.model.recurrent_flow_completion import \
+ RecurrentFlowCompleteNet
+ from animatediff.repo.ProPainter.utils.download_util import \
+ load_file_from_url
+
+ pretrain_model_url = 'https://github.com/sczhou/ProPainter/releases/download/v0.1.0/'
+ model_dir = Path("data/models/ProPainter")
+ model_dir.mkdir(parents=True, exist_ok=True)
+
+ frame_list = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+
+ frames = [Image.open(f) for f in frame_list]
+
+ if low_vram:
+ org_size = frames[0].size
+ _w, _h = frames[0].size
+ if max(_w, _h) > 512:
+ _w = int(_w * 0.75)
+ _h = int(_h * 0.75)
+
+ frames, size, out_size = resize_frames(frames, (_w, _h))
+ out_size = org_size
+
+ masked_area_list = [m[0] for m in masked_area_list]
+ masked_area_list = [cv2.resize(m.astype(np.uint8), dsize=size) for m in masked_area_list]
+ masked_area_list = [ m>127 for m in masked_area_list]
+ masked_area_list = [m[None,...] for m in masked_area_list]
+
+ else:
+ frames, size, out_size = resize_frames(frames, None)
+ masked_area_list = [ m>127 for m in masked_area_list]
+
+ w, h = size
+
+ flow_masks,masks_dilated = dilate_mask(masked_area_list)
+
+ frames_inp = [np.array(f).astype(np.uint8) for f in frames]
+ frames = to_tensors()(frames).unsqueeze(0) * 2 - 1
+ flow_masks = to_tensors()(flow_masks).unsqueeze(0)
+ masks_dilated = to_tensors()(masks_dilated).unsqueeze(0)
+ frames, flow_masks, masks_dilated = frames.to(device), flow_masks.to(device), masks_dilated.to(device)
+
+
+ ##############################################
+ # set up RAFT and flow competition model
+ ##############################################
+ ckpt_path = load_file_from_url(url=os.path.join(pretrain_model_url, 'raft-things.pth'),
+ model_dir=model_dir, progress=True, file_name=None)
+ fix_raft = RAFT_bi(ckpt_path, device)
+
+ ckpt_path = load_file_from_url(url=os.path.join(pretrain_model_url, 'recurrent_flow_completion.pth'),
+ model_dir=model_dir, progress=True, file_name=None)
+ fix_flow_complete = RecurrentFlowCompleteNet(ckpt_path)
+ for p in fix_flow_complete.parameters():
+ p.requires_grad = False
+ fix_flow_complete.to(device)
+ fix_flow_complete.eval()
+
+ ##############################################
+ # set up ProPainter model
+ ##############################################
+ ckpt_path = load_file_from_url(url=os.path.join(pretrain_model_url, 'ProPainter.pth'),
+ model_dir=model_dir, progress=True, file_name=None)
+ model = InpaintGenerator(model_path=ckpt_path).to(device)
+ model.eval()
+
+
+
+ ##############################################
+ # ProPainter inference
+ ##############################################
+ video_length = frames.size(1)
+ logger.info(f'\nProcessing: [{video_length} frames]...')
+ with torch.no_grad():
+ # ---- compute flow ----
+ if max(w,h) <= 640:
+ short_clip_len = 12
+ elif max(w,h) <= 720:
+ short_clip_len = 8
+ elif max(w,h) <= 1280:
+ short_clip_len = 4
+ else:
+ short_clip_len = 2
+
+ # use fp32 for RAFT
+ if frames.size(1) > short_clip_len:
+ gt_flows_f_list, gt_flows_b_list = [], []
+ for f in range(0, video_length, short_clip_len):
+ end_f = min(video_length, f + short_clip_len)
+ if f == 0:
+ flows_f, flows_b = fix_raft(frames[:,f:end_f], iters=raft_iter)
+ else:
+ flows_f, flows_b = fix_raft(frames[:,f-1:end_f], iters=raft_iter)
+
+ gt_flows_f_list.append(flows_f)
+ gt_flows_b_list.append(flows_b)
+ torch.cuda.empty_cache()
+
+ gt_flows_f = torch.cat(gt_flows_f_list, dim=1)
+ gt_flows_b = torch.cat(gt_flows_b_list, dim=1)
+ gt_flows_bi = (gt_flows_f, gt_flows_b)
+ else:
+ gt_flows_bi = fix_raft(frames, iters=raft_iter)
+ torch.cuda.empty_cache()
+
+
+ if use_half:
+ frames, flow_masks, masks_dilated = frames.half(), flow_masks.half(), masks_dilated.half()
+ gt_flows_bi = (gt_flows_bi[0].half(), gt_flows_bi[1].half())
+ fix_flow_complete = fix_flow_complete.half()
+ model = model.half()
+
+
+ # ---- complete flow ----
+ flow_length = gt_flows_bi[0].size(1)
+ if flow_length > subvideo_length:
+ pred_flows_f, pred_flows_b = [], []
+ pad_len = 5
+ for f in range(0, flow_length, subvideo_length):
+ s_f = max(0, f - pad_len)
+ e_f = min(flow_length, f + subvideo_length + pad_len)
+ pad_len_s = max(0, f) - s_f
+ pad_len_e = e_f - min(flow_length, f + subvideo_length)
+ pred_flows_bi_sub, _ = fix_flow_complete.forward_bidirect_flow(
+ (gt_flows_bi[0][:, s_f:e_f], gt_flows_bi[1][:, s_f:e_f]),
+ flow_masks[:, s_f:e_f+1])
+ pred_flows_bi_sub = fix_flow_complete.combine_flow(
+ (gt_flows_bi[0][:, s_f:e_f], gt_flows_bi[1][:, s_f:e_f]),
+ pred_flows_bi_sub,
+ flow_masks[:, s_f:e_f+1])
+
+ pred_flows_f.append(pred_flows_bi_sub[0][:, pad_len_s:e_f-s_f-pad_len_e])
+ pred_flows_b.append(pred_flows_bi_sub[1][:, pad_len_s:e_f-s_f-pad_len_e])
+ torch.cuda.empty_cache()
+
+ pred_flows_f = torch.cat(pred_flows_f, dim=1)
+ pred_flows_b = torch.cat(pred_flows_b, dim=1)
+ pred_flows_bi = (pred_flows_f, pred_flows_b)
+ else:
+ pred_flows_bi, _ = fix_flow_complete.forward_bidirect_flow(gt_flows_bi, flow_masks)
+ pred_flows_bi = fix_flow_complete.combine_flow(gt_flows_bi, pred_flows_bi, flow_masks)
+ torch.cuda.empty_cache()
+
+
+ # ---- image propagation ----
+ masked_frames = frames * (1 - masks_dilated)
+ subvideo_length_img_prop = min(100, subvideo_length) # ensure a minimum of 100 frames for image propagation
+ if video_length > subvideo_length_img_prop:
+ updated_frames, updated_masks = [], []
+ pad_len = 10
+ for f in range(0, video_length, subvideo_length_img_prop):
+ s_f = max(0, f - pad_len)
+ e_f = min(video_length, f + subvideo_length_img_prop + pad_len)
+ pad_len_s = max(0, f) - s_f
+ pad_len_e = e_f - min(video_length, f + subvideo_length_img_prop)
+
+ b, t, _, _, _ = masks_dilated[:, s_f:e_f].size()
+ pred_flows_bi_sub = (pred_flows_bi[0][:, s_f:e_f-1], pred_flows_bi[1][:, s_f:e_f-1])
+ prop_imgs_sub, updated_local_masks_sub = model.img_propagation(masked_frames[:, s_f:e_f],
+ pred_flows_bi_sub,
+ masks_dilated[:, s_f:e_f],
+ 'nearest')
+ updated_frames_sub = frames[:, s_f:e_f] * (1 - masks_dilated[:, s_f:e_f]) + \
+ prop_imgs_sub.view(b, t, 3, h, w) * masks_dilated[:, s_f:e_f]
+ updated_masks_sub = updated_local_masks_sub.view(b, t, 1, h, w)
+
+ updated_frames.append(updated_frames_sub[:, pad_len_s:e_f-s_f-pad_len_e])
+ updated_masks.append(updated_masks_sub[:, pad_len_s:e_f-s_f-pad_len_e])
+ torch.cuda.empty_cache()
+
+ updated_frames = torch.cat(updated_frames, dim=1)
+ updated_masks = torch.cat(updated_masks, dim=1)
+ else:
+ b, t, _, _, _ = masks_dilated.size()
+ prop_imgs, updated_local_masks = model.img_propagation(masked_frames, pred_flows_bi, masks_dilated, 'nearest')
+ updated_frames = frames * (1 - masks_dilated) + prop_imgs.view(b, t, 3, h, w) * masks_dilated
+ updated_masks = updated_local_masks.view(b, t, 1, h, w)
+ torch.cuda.empty_cache()
+
+ ori_frames = frames_inp
+ comp_frames = [None] * video_length
+
+ neighbor_stride = neighbor_length // 2
+ if video_length > subvideo_length:
+ ref_num = subvideo_length // ref_stride
+ else:
+ ref_num = -1
+
+ # ---- feature propagation + transformer ----
+ for f in tqdm(range(0, video_length, neighbor_stride)):
+ neighbor_ids = [
+ i for i in range(max(0, f - neighbor_stride),
+ min(video_length, f + neighbor_stride + 1))
+ ]
+ ref_ids = get_ref_index(f, neighbor_ids, video_length, ref_stride, ref_num)
+ selected_imgs = updated_frames[:, neighbor_ids + ref_ids, :, :, :]
+ selected_masks = masks_dilated[:, neighbor_ids + ref_ids, :, :, :]
+ selected_update_masks = updated_masks[:, neighbor_ids + ref_ids, :, :, :]
+ selected_pred_flows_bi = (pred_flows_bi[0][:, neighbor_ids[:-1], :, :, :], pred_flows_bi[1][:, neighbor_ids[:-1], :, :, :])
+
+ with torch.no_grad():
+ # 1.0 indicates mask
+ l_t = len(neighbor_ids)
+
+ # pred_img = selected_imgs # results of image propagation
+ pred_img = model(selected_imgs, selected_pred_flows_bi, selected_masks, selected_update_masks, l_t)
+
+ pred_img = pred_img.view(-1, 3, h, w)
+
+ pred_img = (pred_img + 1) / 2
+ pred_img = pred_img.cpu().permute(0, 2, 3, 1).numpy() * 255
+ binary_masks = masks_dilated[0, neighbor_ids, :, :, :].cpu().permute(
+ 0, 2, 3, 1).numpy().astype(np.uint8)
+ for i in range(len(neighbor_ids)):
+ idx = neighbor_ids[i]
+ img = np.array(pred_img[i]).astype(np.uint8) * binary_masks[i] \
+ + ori_frames[idx] * (1 - binary_masks[i])
+ if comp_frames[idx] is None:
+ comp_frames[idx] = img
+ else:
+ comp_frames[idx] = comp_frames[idx].astype(np.float32) * 0.5 + img.astype(np.float32) * 0.5
+
+ comp_frames[idx] = comp_frames[idx].astype(np.uint8)
+
+ torch.cuda.empty_cache()
+
+ # save each frame
+ for idx in range(video_length):
+ f = comp_frames[idx]
+ f = cv2.resize(f, out_size, interpolation = cv2.INTER_CUBIC)
+ f = cv2.cvtColor(f, cv2.COLOR_BGR2RGB)
+ dst_img_path = output_dir.joinpath( f"{idx:08d}.png" )
+ cv2.imwrite(str(dst_img_path), f)
+
+ sys.path.remove(repo_path)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/animate/src/animatediff/utils/mask_animseg.py b/animate/src/animatediff/utils/mask_animseg.py
new file mode 100644
index 0000000000000000000000000000000000000000..299c8ca0d836d8b2e3a0926276972708435392da
--- /dev/null
+++ b/animate/src/animatediff/utils/mask_animseg.py
@@ -0,0 +1,88 @@
+import glob
+import logging
+import os
+from pathlib import Path
+
+import cv2
+import numpy as np
+import onnxruntime as rt
+import torch
+from PIL import Image
+from rembg import new_session, remove
+from tqdm.rich import tqdm
+
+logger = logging.getLogger(__name__)
+
+def animseg_create_fg(frame_dir, output_dir, output_mask_dir, masked_area_list,
+ bg_color=(0,255,0),
+ mask_padding=0,
+ ):
+
+ frame_list = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+
+ if mask_padding != 0:
+ kernel = np.ones((abs(mask_padding),abs(mask_padding)),np.uint8)
+ kernel2 = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
+
+
+ providers = ['CUDAExecutionProvider', 'CPUExecutionProvider']
+ rmbg_model = rt.InferenceSession("data/models/anime_seg/isnetis.onnx", providers=providers)
+
+ def get_mask(img, s=1024):
+ img = (img / 255).astype(np.float32)
+ h, w = h0, w0 = img.shape[:-1]
+ h, w = (s, int(s * w / h)) if h > w else (int(s * h / w), s)
+ ph, pw = s - h, s - w
+ img_input = np.zeros([s, s, 3], dtype=np.float32)
+ img_input[ph // 2:ph // 2 + h, pw // 2:pw // 2 + w] = cv2.resize(img, (w, h))
+ img_input = np.transpose(img_input, (2, 0, 1))
+ img_input = img_input[np.newaxis, :]
+ mask = rmbg_model.run(None, {'img': img_input})[0][0]
+ mask = np.transpose(mask, (1, 2, 0))
+ mask = mask[ph // 2:ph // 2 + h, pw // 2:pw // 2 + w]
+ mask = cv2.resize(mask, (w0, h0))
+ mask = (mask * 255).astype(np.uint8)
+ return mask
+
+
+ for i, frame in tqdm(enumerate(frame_list),total=len(frame_list), desc=f"creating mask"):
+ frame = Path(frame)
+ file_name = frame.name
+
+ cur_frame_no = int(frame.stem)
+
+ img = Image.open(frame)
+ img_array = np.asarray(img)
+
+ mask_array = get_mask(img_array)
+
+# Image.fromarray(mask_array).save( output_dir / Path("raw_" + file_name))
+
+ if mask_padding < 0:
+ mask_array = cv2.erode(mask_array.astype(np.uint8),kernel,iterations = 1)
+ elif mask_padding > 0:
+ mask_array = cv2.dilate(mask_array.astype(np.uint8),kernel,iterations = 1)
+
+ mask_array = cv2.morphologyEx(mask_array, cv2.MORPH_OPEN, kernel2)
+ mask_array = cv2.GaussianBlur(mask_array, (7, 7), sigmaX=3, sigmaY=3, borderType=cv2.BORDER_DEFAULT)
+
+ if masked_area_list[cur_frame_no] is not None:
+ masked_area_list[cur_frame_no] = np.where(masked_area_list[cur_frame_no] > mask_array[None,...], masked_area_list[cur_frame_no], mask_array[None,...])
+ else:
+ masked_area_list[cur_frame_no] = mask_array[None,...]
+
+ if output_mask_dir:
+ Image.fromarray(mask_array).save( output_mask_dir / file_name )
+
+ img_array = np.asarray(img).copy()
+ if bg_color is not None:
+ img_array[mask_array == 0] = bg_color
+
+ img = Image.fromarray(img_array)
+
+ img.save( output_dir / file_name )
+
+ return masked_area_list
+
+
+
diff --git a/animate/src/animatediff/utils/mask_rembg.py b/animate/src/animatediff/utils/mask_rembg.py
new file mode 100644
index 0000000000000000000000000000000000000000..78514a28dca01dc67fc07881ec98b50e247cec8d
--- /dev/null
+++ b/animate/src/animatediff/utils/mask_rembg.py
@@ -0,0 +1,68 @@
+import glob
+import logging
+import os
+from pathlib import Path
+
+import cv2
+import numpy as np
+import torch
+from PIL import Image
+from rembg import new_session, remove
+from tqdm.rich import tqdm
+
+logger = logging.getLogger(__name__)
+
+def rembg_create_fg(frame_dir, output_dir, output_mask_dir, masked_area_list,
+ bg_color=(0,255,0),
+ mask_padding=0,
+ ):
+
+ frame_list = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+
+ if mask_padding != 0:
+ kernel = np.ones((abs(mask_padding),abs(mask_padding)),np.uint8)
+ kernel2 = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
+
+ session = new_session(providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
+
+ for i, frame in tqdm(enumerate(frame_list),total=len(frame_list), desc=f"creating mask"):
+ frame = Path(frame)
+ file_name = frame.name
+
+ cur_frame_no = int(frame.stem)
+
+ img = Image.open(frame)
+ img_array = np.asarray(img)
+
+ mask_array = remove(img_array, only_mask=True, session=session)
+
+ #mask_array = mask_array[None,...]
+
+ if mask_padding < 0:
+ mask_array = cv2.erode(mask_array.astype(np.uint8),kernel,iterations = 1)
+ elif mask_padding > 0:
+ mask_array = cv2.dilate(mask_array.astype(np.uint8),kernel,iterations = 1)
+
+ mask_array = cv2.morphologyEx(mask_array, cv2.MORPH_OPEN, kernel2)
+ mask_array = cv2.GaussianBlur(mask_array, (7, 7), sigmaX=3, sigmaY=3, borderType=cv2.BORDER_DEFAULT)
+
+ if masked_area_list[cur_frame_no] is not None:
+ masked_area_list[cur_frame_no] = np.where(masked_area_list[cur_frame_no] > mask_array[None,...], masked_area_list[cur_frame_no], mask_array[None,...])
+ else:
+ masked_area_list[cur_frame_no] = mask_array[None,...]
+
+ if output_mask_dir:
+ Image.fromarray(mask_array).save( output_mask_dir / file_name )
+
+ img_array = np.asarray(img).copy()
+ if bg_color is not None:
+ img_array[mask_array == 0] = bg_color
+
+ img = Image.fromarray(img_array)
+
+ img.save( output_dir / file_name )
+
+ return masked_area_list
+
+
+
diff --git a/animate/src/animatediff/utils/model.py b/animate/src/animatediff/utils/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..6ac0f7a6220e24250f1c077e5acbcf6408649801
--- /dev/null
+++ b/animate/src/animatediff/utils/model.py
@@ -0,0 +1,201 @@
+import logging
+from functools import wraps
+from pathlib import Path
+from typing import Optional, TypeVar
+
+from diffusers import StableDiffusionPipeline, StableDiffusionXLPipeline
+from huggingface_hub import hf_hub_download
+from torch import nn
+
+from animatediff import HF_HUB_CACHE, HF_MODULE_REPO, get_dir
+from animatediff.settings import CKPT_EXTENSIONS
+from animatediff.utils.huggingface import get_hf_pipeline, get_hf_pipeline_sdxl
+from animatediff.utils.util import path_from_cwd
+
+logger = logging.getLogger(__name__)
+
+data_dir = get_dir("data")
+checkpoint_dir = data_dir.joinpath("models/sd")
+pipeline_dir = data_dir.joinpath("models/huggingface")
+
+# for the nop_train() monkeypatch
+T = TypeVar("T", bound=nn.Module)
+
+
+def nop_train(self: T, mode: bool = True) -> T:
+ """No-op for monkeypatching train() call to prevent unfreezing module"""
+ return self
+
+
+def get_base_model(model_name_or_path: str, local_dir: Path, force: bool = False, is_sdxl:bool=False) -> Path:
+ model_name_or_path = Path(model_name_or_path)
+
+ model_save_dir = local_dir.joinpath(str(model_name_or_path).split("/")[-1]).resolve()
+ model_is_repo_id = False if model_name_or_path.joinpath("model_index.json").exists() else True
+
+ # if we have a HF repo ID, download it
+ if model_is_repo_id:
+ logger.debug("Base model is a HuggingFace repo ID")
+ if model_save_dir.joinpath("model_index.json").exists():
+ logger.debug(f"Base model already downloaded to: {path_from_cwd(model_save_dir)}")
+ else:
+ logger.info(f"Downloading base model from {model_name_or_path}...")
+ if is_sdxl:
+ _ = get_hf_pipeline_sdxl(model_name_or_path, model_save_dir, save=True, force_download=force)
+ else:
+ _ = get_hf_pipeline(model_name_or_path, model_save_dir, save=True, force_download=force)
+ model_name_or_path = model_save_dir
+
+ return Path(model_name_or_path)
+
+
+def fix_checkpoint_if_needed(checkpoint: Path, debug:bool):
+ def dump(loaded):
+ for a in loaded:
+ logger.info(f"{a} {loaded[a].shape}")
+
+ if debug:
+ from safetensors.torch import load_file, save_file
+ loaded = load_file(checkpoint, "cpu")
+
+ dump(loaded)
+
+ return
+
+ try:
+ pipeline = StableDiffusionPipeline.from_single_file(
+ pretrained_model_link_or_path=str(checkpoint.absolute()),
+ local_files_only=False,
+ load_safety_checker=False,
+ )
+ logger.info("This file works fine.")
+ return
+ except:
+ from safetensors.torch import load_file, save_file
+
+ loaded = load_file(checkpoint, "cpu")
+
+ convert_table_bias={
+ "first_stage_model.decoder.mid.attn_1.to_k.bias":"first_stage_model.decoder.mid.attn_1.k.bias",
+ "first_stage_model.decoder.mid.attn_1.to_out.0.bias":"first_stage_model.decoder.mid.attn_1.proj_out.bias",
+ "first_stage_model.decoder.mid.attn_1.to_q.bias":"first_stage_model.decoder.mid.attn_1.q.bias",
+ "first_stage_model.decoder.mid.attn_1.to_v.bias":"first_stage_model.decoder.mid.attn_1.v.bias",
+ "first_stage_model.encoder.mid.attn_1.to_k.bias":"first_stage_model.encoder.mid.attn_1.k.bias",
+ "first_stage_model.encoder.mid.attn_1.to_out.0.bias":"first_stage_model.encoder.mid.attn_1.proj_out.bias",
+ "first_stage_model.encoder.mid.attn_1.to_q.bias":"first_stage_model.encoder.mid.attn_1.q.bias",
+ "first_stage_model.encoder.mid.attn_1.to_v.bias":"first_stage_model.encoder.mid.attn_1.v.bias",
+ }
+
+ convert_table_weight={
+ "first_stage_model.decoder.mid.attn_1.to_k.weight":"first_stage_model.decoder.mid.attn_1.k.weight",
+ "first_stage_model.decoder.mid.attn_1.to_out.0.weight":"first_stage_model.decoder.mid.attn_1.proj_out.weight",
+ "first_stage_model.decoder.mid.attn_1.to_q.weight":"first_stage_model.decoder.mid.attn_1.q.weight",
+ "first_stage_model.decoder.mid.attn_1.to_v.weight":"first_stage_model.decoder.mid.attn_1.v.weight",
+ "first_stage_model.encoder.mid.attn_1.to_k.weight":"first_stage_model.encoder.mid.attn_1.k.weight",
+ "first_stage_model.encoder.mid.attn_1.to_out.0.weight":"first_stage_model.encoder.mid.attn_1.proj_out.weight",
+ "first_stage_model.encoder.mid.attn_1.to_q.weight":"first_stage_model.encoder.mid.attn_1.q.weight",
+ "first_stage_model.encoder.mid.attn_1.to_v.weight":"first_stage_model.encoder.mid.attn_1.v.weight",
+ }
+
+ for a in list(loaded.keys()):
+ if a in convert_table_bias:
+ new_key = convert_table_bias[a]
+ loaded[new_key] = loaded.pop(a)
+ elif a in convert_table_weight:
+ new_key = convert_table_weight[a]
+ item = loaded.pop(a)
+ if len(item.shape) == 2:
+ item = item.unsqueeze(dim=-1).unsqueeze(dim=-1)
+ loaded[new_key] = item
+
+ new_path = str(checkpoint.parent / checkpoint.stem) + "_fixed"+checkpoint.suffix
+
+ logger.info(f"Saving file to {new_path}")
+ save_file(loaded, Path(new_path))
+
+
+
+def checkpoint_to_pipeline(
+ checkpoint: Path,
+ target_dir: Optional[Path] = None,
+ save: bool = True,
+) -> StableDiffusionPipeline:
+ logger.debug(f"Converting checkpoint {path_from_cwd(checkpoint)}")
+ if target_dir is None:
+ target_dir = pipeline_dir.joinpath(checkpoint.stem)
+
+ pipeline = StableDiffusionPipeline.from_single_file(
+ pretrained_model_link_or_path=str(checkpoint.absolute()),
+ local_files_only=False,
+ safety_checker=None,
+ )
+
+ if save:
+ target_dir.mkdir(parents=True, exist_ok=True)
+ logger.info(f"Saving pipeline to {path_from_cwd(target_dir)}")
+ pipeline.save_pretrained(target_dir, safe_serialization=True)
+ return pipeline, target_dir
+
+def checkpoint_to_pipeline_sdxl(
+ checkpoint: Path,
+ target_dir: Optional[Path] = None,
+ save: bool = True,
+) -> StableDiffusionXLPipeline:
+ logger.debug(f"Converting checkpoint {path_from_cwd(checkpoint)}")
+ if target_dir is None:
+ target_dir = pipeline_dir.joinpath(checkpoint.stem)
+
+ pipeline = StableDiffusionXLPipeline.from_single_file(
+ pretrained_model_link_or_path=str(checkpoint.absolute()),
+ local_files_only=False,
+ safety_checker=None,
+ )
+
+ if save:
+ target_dir.mkdir(parents=True, exist_ok=True)
+ logger.info(f"Saving pipeline to {path_from_cwd(target_dir)}")
+ pipeline.save_pretrained(target_dir, safe_serialization=True)
+ return pipeline, target_dir
+
+def get_checkpoint_weights(checkpoint: Path):
+ temp_pipeline: StableDiffusionPipeline
+ temp_pipeline, _ = checkpoint_to_pipeline(checkpoint, save=False)
+ unet_state_dict = temp_pipeline.unet.state_dict()
+ tenc_state_dict = temp_pipeline.text_encoder.state_dict()
+ vae_state_dict = temp_pipeline.vae.state_dict()
+ return unet_state_dict, tenc_state_dict, vae_state_dict
+
+def get_checkpoint_weights_sdxl(checkpoint: Path):
+ temp_pipeline: StableDiffusionXLPipeline
+ temp_pipeline, _ = checkpoint_to_pipeline_sdxl(checkpoint, save=False)
+ unet_state_dict = temp_pipeline.unet.state_dict()
+ tenc_state_dict = temp_pipeline.text_encoder.state_dict()
+ tenc2_state_dict = temp_pipeline.text_encoder_2.state_dict()
+ vae_state_dict = temp_pipeline.vae.state_dict()
+ return unet_state_dict, tenc_state_dict, tenc2_state_dict, vae_state_dict
+
+
+def ensure_motion_modules(
+ repo_id: str = HF_MODULE_REPO,
+ fp16: bool = False,
+ force: bool = False,
+):
+ """Retrieve the motion modules from HuggingFace Hub."""
+ module_files = ["mm_sd_v14.safetensors", "mm_sd_v15.safetensors"]
+ module_dir = get_dir("data/models/motion-module")
+ for file in module_files:
+ target_path = module_dir.joinpath(file)
+ if fp16:
+ target_path = target_path.with_suffix(".fp16.safetensors")
+ if target_path.exists() and force is not True:
+ logger.debug(f"File {path_from_cwd(target_path)} already exists, skipping download")
+ else:
+ result = hf_hub_download(
+ repo_id=repo_id,
+ filename=target_path.name,
+ cache_dir=HF_HUB_CACHE,
+ local_dir=module_dir,
+ local_dir_use_symlinks=False,
+ resume_download=True,
+ )
+ logger.debug(f"Downloaded {path_from_cwd(result)}")
diff --git a/animate/src/animatediff/utils/pipeline.py b/animate/src/animatediff/utils/pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..f24c2d445acfaf263862f4e5737134eab8cfda40
--- /dev/null
+++ b/animate/src/animatediff/utils/pipeline.py
@@ -0,0 +1,123 @@
+import logging
+from typing import Optional
+
+import torch
+import torch._dynamo as dynamo
+from diffusers import (DiffusionPipeline, StableDiffusionPipeline,
+ StableDiffusionXLPipeline)
+from einops._torch_specific import allow_ops_in_compiled_graph
+
+from animatediff.utils.device import get_memory_format, get_model_dtypes
+from animatediff.utils.model import nop_train
+
+logger = logging.getLogger(__name__)
+
+
+def send_to_device(
+ pipeline: DiffusionPipeline,
+ device: torch.device,
+ freeze: bool = True,
+ force_half: bool = False,
+ compile: bool = False,
+ is_sdxl: bool = False,
+) -> DiffusionPipeline:
+ if is_sdxl:
+ return send_to_device_sdxl(
+ pipeline=pipeline,
+ device=device,
+ freeze=freeze,
+ force_half=force_half,
+ compile=compile,
+ )
+
+ logger.info(f"Sending pipeline to device \"{device.type}{device.index if device.index else ''}\"")
+
+ unet_dtype, tenc_dtype, vae_dtype = get_model_dtypes(device, force_half)
+ model_memory_format = get_memory_format(device)
+
+ if hasattr(pipeline, 'controlnet'):
+ unet_dtype = tenc_dtype = vae_dtype
+
+ logger.info(f"-> Selected data types: {unet_dtype=},{tenc_dtype=},{vae_dtype=}")
+
+ if hasattr(pipeline.controlnet, 'nets'):
+ for i in range(len(pipeline.controlnet.nets)):
+ pipeline.controlnet.nets[i] = pipeline.controlnet.nets[i].to(device=device, dtype=vae_dtype, memory_format=model_memory_format)
+ else:
+ if pipeline.controlnet:
+ pipeline.controlnet = pipeline.controlnet.to(device=device, dtype=vae_dtype, memory_format=model_memory_format)
+
+ if hasattr(pipeline, 'controlnet_map'):
+ if pipeline.controlnet_map:
+ for c in pipeline.controlnet_map:
+ #pipeline.controlnet_map[c] = pipeline.controlnet_map[c].to(device=device, dtype=unet_dtype, memory_format=model_memory_format)
+ pipeline.controlnet_map[c] = pipeline.controlnet_map[c].to(dtype=unet_dtype, memory_format=model_memory_format)
+
+ if hasattr(pipeline, 'lora_map'):
+ if pipeline.lora_map:
+ pipeline.lora_map.to(device=device, dtype=unet_dtype)
+
+ if hasattr(pipeline, 'lcm'):
+ if pipeline.lcm:
+ pipeline.lcm.to(device=device, dtype=unet_dtype)
+
+ pipeline.unet = pipeline.unet.to(device=device, dtype=unet_dtype, memory_format=model_memory_format)
+ pipeline.text_encoder = pipeline.text_encoder.to(device=device, dtype=tenc_dtype)
+ pipeline.vae = pipeline.vae.to(device=device, dtype=vae_dtype, memory_format=model_memory_format)
+
+ # Compile model if enabled
+ if compile:
+ if not isinstance(pipeline.unet, dynamo.OptimizedModule):
+ allow_ops_in_compiled_graph() # make einops behave
+ logger.warn("Enabling model compilation with TorchDynamo, this may take a while...")
+ logger.warn("Model compilation is experimental and may not work as expected!")
+ pipeline.unet = torch.compile(
+ pipeline.unet,
+ backend="inductor",
+ mode="reduce-overhead",
+ )
+ else:
+ logger.debug("Skipping model compilation, already compiled!")
+
+ return pipeline
+
+
+def send_to_device_sdxl(
+ pipeline: StableDiffusionXLPipeline,
+ device: torch.device,
+ freeze: bool = True,
+ force_half: bool = False,
+ compile: bool = False,
+) -> StableDiffusionXLPipeline:
+ logger.info(f"Sending pipeline to device \"{device.type}{device.index if device.index else ''}\"")
+
+ pipeline.unet = pipeline.unet.half()
+ pipeline.text_encoder = pipeline.text_encoder.half()
+ pipeline.text_encoder_2 = pipeline.text_encoder_2.half()
+
+ if False:
+ pipeline.to(device)
+ else:
+ pipeline.enable_model_cpu_offload()
+
+ pipeline.enable_xformers_memory_efficient_attention()
+ pipeline.enable_vae_slicing()
+ pipeline.enable_vae_tiling()
+
+ return pipeline
+
+
+
+def get_context_params(
+ length: int,
+ context: Optional[int] = None,
+ overlap: Optional[int] = None,
+ stride: Optional[int] = None,
+):
+ if context is None:
+ context = min(length, 16)
+ if overlap is None:
+ overlap = context // 4
+ if stride is None:
+ stride = 0
+ return context, overlap, stride
diff --git a/animate/src/animatediff/utils/tagger.py b/animate/src/animatediff/utils/tagger.py
new file mode 100644
index 0000000000000000000000000000000000000000..3e63c42312aedbc9e852ca319bc5b7ca10abe4c0
--- /dev/null
+++ b/animate/src/animatediff/utils/tagger.py
@@ -0,0 +1,161 @@
+# https://huggingface.co/spaces/SmilingWolf/wd-v1-4-tags/blob/main/app.py
+
+import glob
+import logging
+import os
+
+import cv2
+import numpy as np
+import onnxruntime
+import pandas as pd
+from PIL import Image
+from tqdm.rich import tqdm
+
+from animatediff.utils.util import prepare_wd14tagger
+
+logger = logging.getLogger(__name__)
+
+
+def make_square(img, target_size):
+ old_size = img.shape[:2]
+ desired_size = max(old_size)
+ desired_size = max(desired_size, target_size)
+
+ delta_w = desired_size - old_size[1]
+ delta_h = desired_size - old_size[0]
+ top, bottom = delta_h // 2, delta_h - (delta_h // 2)
+ left, right = delta_w // 2, delta_w - (delta_w // 2)
+
+ color = [255, 255, 255]
+ new_im = cv2.copyMakeBorder(
+ img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color
+ )
+ return new_im
+
+def smart_resize(img, size):
+ # Assumes the image has already gone through make_square
+ if img.shape[0] > size:
+ img = cv2.resize(img, (size, size), interpolation=cv2.INTER_AREA)
+ elif img.shape[0] < size:
+ img = cv2.resize(img, (size, size), interpolation=cv2.INTER_CUBIC)
+ return img
+
+
+class Tagger:
+ def __init__(self, general_threshold, character_threshold, ignore_tokens, with_confidence, is_danbooru_format,is_cpu):
+ prepare_wd14tagger()
+# self.model = onnxruntime.InferenceSession("data/models/WD14tagger/model.onnx", providers=['CUDAExecutionProvider','CPUExecutionProvider'])
+ if is_cpu:
+ self.model = onnxruntime.InferenceSession("data/models/WD14tagger/model.onnx", providers=['CPUExecutionProvider'])
+ else:
+ self.model = onnxruntime.InferenceSession("data/models/WD14tagger/model.onnx", providers=['CUDAExecutionProvider'])
+ df = pd.read_csv("data/models/WD14tagger/selected_tags.csv")
+ self.tag_names = df["name"].tolist()
+ self.rating_indexes = list(np.where(df["category"] == 9)[0])
+ self.general_indexes = list(np.where(df["category"] == 0)[0])
+ self.character_indexes = list(np.where(df["category"] == 4)[0])
+
+ self.general_threshold = general_threshold
+ self.character_threshold = character_threshold
+ self.ignore_tokens = ignore_tokens
+ self.with_confidence = with_confidence
+ self.is_danbooru_format = is_danbooru_format
+
+ def __call__(
+ self,
+ image: Image,
+ ):
+
+ _, height, width, _ = self.model.get_inputs()[0].shape
+
+ # Alpha to white
+ image = image.convert("RGBA")
+ new_image = Image.new("RGBA", image.size, "WHITE")
+ new_image.paste(image, mask=image)
+ image = new_image.convert("RGB")
+ image = np.asarray(image)
+
+ # PIL RGB to OpenCV BGR
+ image = image[:, :, ::-1]
+
+ image = make_square(image, height)
+ image = smart_resize(image, height)
+ image = image.astype(np.float32)
+ image = np.expand_dims(image, 0)
+
+ input_name = self.model.get_inputs()[0].name
+ label_name = self.model.get_outputs()[0].name
+ probs = self.model.run([label_name], {input_name: image})[0]
+
+ labels = list(zip(self.tag_names, probs[0].astype(float)))
+
+ # First 4 labels are actually ratings: pick one with argmax
+ ratings_names = [labels[i] for i in self.rating_indexes]
+ rating = dict(ratings_names)
+
+ # Then we have general tags: pick any where prediction confidence > threshold
+ general_names = [labels[i] for i in self.general_indexes]
+ general_res = [x for x in general_names if x[1] > self.general_threshold]
+ general_res = dict(general_res)
+
+ # Everything else is characters: pick any where prediction confidence > threshold
+ character_names = [labels[i] for i in self.character_indexes]
+ character_res = [x for x in character_names if x[1] > self.character_threshold]
+ character_res = dict(character_res)
+
+ #logger.info(f"{rating=}")
+ #logger.info(f"{general_res=}")
+ #logger.info(f"{character_res=}")
+
+ general_res = {k:general_res[k] for k in (general_res.keys() - set(self.ignore_tokens)) }
+ character_res = {k:character_res[k] for k in (character_res.keys() - set(self.ignore_tokens)) }
+
+ prompt = ""
+
+ if self.with_confidence:
+ prompt = [ f"({i}:{character_res[i]:.2f})" for i in (character_res.keys()) ]
+ prompt += [ f"({i}:{general_res[i]:.2f})" for i in (general_res.keys()) ]
+ else:
+ prompt = [ i for i in (character_res.keys()) ]
+ prompt += [ i for i in (general_res.keys()) ]
+
+ prompt = ",".join(prompt)
+
+ if not self.is_danbooru_format:
+ prompt = prompt.replace("_", " ")
+
+ #logger.info(f"{prompt=}")
+ return prompt
+
+
+def get_labels(frame_dir, interval, general_threshold, character_threshold, ignore_tokens, with_confidence, is_danbooru_format, is_cpu =False):
+
+ import torch
+
+ result = {}
+ if os.path.isdir(frame_dir):
+ png_list = sorted(glob.glob( os.path.join(frame_dir, "[0-9]*.png"), recursive=False))
+
+ png_map ={}
+ for png_path in png_list:
+ basename_without_ext = os.path.splitext(os.path.basename(png_path))[0]
+ png_map[int(basename_without_ext)] = png_path
+
+ with torch.no_grad():
+ tagger = Tagger(general_threshold, character_threshold, ignore_tokens, with_confidence, is_danbooru_format, is_cpu)
+
+ for i in tqdm(range(0, len(png_list), interval ), desc=f"WD14tagger"):
+ path = png_map[i]
+
+ #logger.info(f"{path=}")
+
+ result[str(i)] = tagger(
+ image= Image.open(path)
+ )
+
+ tagger = None
+
+ torch.cuda.empty_cache()
+
+ return result
+
diff --git a/animate/src/animatediff/utils/util.py b/animate/src/animatediff/utils/util.py
new file mode 100644
index 0000000000000000000000000000000000000000..70475b7babc53dfcd8c2da23e2c507e6660bf814
--- /dev/null
+++ b/animate/src/animatediff/utils/util.py
@@ -0,0 +1,666 @@
+import logging
+from os import PathLike
+from pathlib import Path
+from typing import List
+
+import torch
+import torch.distributed as dist
+from einops import rearrange
+from PIL import Image
+from torch import Tensor
+from torchvision.utils import save_image
+from tqdm.rich import tqdm
+
+logger = logging.getLogger(__name__)
+
+def zero_rank_print(s):
+ if not isinstance(s, str): s = repr(s)
+ if (not dist.is_initialized()) or (dist.is_initialized() and dist.get_rank() == 0): print("### " + s)
+
+
+def save_frames(video: Tensor, frames_dir: PathLike, show_progress:bool=True):
+ frames_dir = Path(frames_dir)
+ frames_dir.mkdir(parents=True, exist_ok=True)
+ frames = rearrange(video, "b c t h w -> t b c h w")
+ if show_progress:
+ for idx, frame in enumerate(tqdm(frames, desc=f"Saving frames to {frames_dir.stem}")):
+ save_image(frame, frames_dir.joinpath(f"{idx:08d}.png"))
+ else:
+ for idx, frame in enumerate(frames):
+ save_image(frame, frames_dir.joinpath(f"{idx:08d}.png"))
+
+
+def save_imgs(imgs:List[Image.Image], frames_dir: PathLike):
+ frames_dir = Path(frames_dir)
+ frames_dir.mkdir(parents=True, exist_ok=True)
+ for idx, img in enumerate(tqdm(imgs, desc=f"Saving frames to {frames_dir.stem}")):
+ img.save( frames_dir.joinpath(f"{idx:08d}.png") )
+
+def save_video(video: Tensor, save_path: PathLike, fps: int = 8):
+ save_path = Path(save_path)
+ save_path.parent.mkdir(parents=True, exist_ok=True)
+
+ if video.ndim == 5:
+ # batch, channels, frame, width, height -> frame, channels, width, height
+ frames = video.permute(0, 2, 1, 3, 4).squeeze(0)
+ elif video.ndim == 4:
+ # channels, frame, width, height -> frame, channels, width, height
+ frames = video.permute(1, 0, 2, 3)
+ else:
+ raise ValueError(f"video must be 4 or 5 dimensional, got {video.ndim}")
+
+ # Add 0.5 after unnormalizing to [0, 255] to round to the nearest integer
+ frames = frames.mul(255).add_(0.5).clamp_(0, 255).permute(0, 2, 3, 1).to("cpu", torch.uint8).numpy()
+
+ images = [Image.fromarray(frame) for frame in frames]
+ images[0].save(
+ fp=save_path, format="GIF", append_images=images[1:], save_all=True, duration=(1 / fps * 1000), loop=0
+ )
+
+
+def path_from_cwd(path: PathLike) -> str:
+ path = Path(path)
+ return str(path.absolute().relative_to(Path.cwd()))
+
+
+def resize_for_condition_image(input_image: Image, us_width: int, us_height: int):
+ input_image = input_image.convert("RGB")
+ H = int(round(us_height / 8.0)) * 8
+ W = int(round(us_width / 8.0)) * 8
+ img = input_image.resize((W, H), resample=Image.LANCZOS)
+ return img
+
+def get_resized_images(org_images_path: List[str], us_width: int, us_height: int):
+
+ images = [Image.open( p ) for p in org_images_path]
+
+ W, H = images[0].size
+
+ if us_width == -1:
+ us_width = W/H * us_height
+ elif us_height == -1:
+ us_height = H/W * us_width
+
+ return [resize_for_condition_image(img, us_width, us_height) for img in images]
+
+def get_resized_image(org_image_path: str, us_width: int, us_height: int):
+
+ image = Image.open( org_image_path )
+
+ W, H = image.size
+
+ if us_width == -1:
+ us_width = W/H * us_height
+ elif us_height == -1:
+ us_height = H/W * us_width
+
+ return resize_for_condition_image(image, us_width, us_height)
+
+def get_resized_image2(org_image_path: str, size: int):
+
+ image = Image.open( org_image_path )
+
+ W, H = image.size
+
+ if size < 0:
+ return resize_for_condition_image(image, W, H)
+
+ if W < H:
+ us_width = size
+ us_height = int(size * H/W)
+ else:
+ us_width = int(size * W/H)
+ us_height = size
+
+ return resize_for_condition_image(image, us_width, us_height)
+
+
+def show_bytes(comment, obj):
+
+ import sys
+# memory_size = sys.getsizeof(tensor) + torch.numel(tensor)*tensor.element_size()
+
+ if torch.is_tensor(obj):
+ logger.info(f"{comment} : {obj.dtype=}")
+
+ cpu_mem = sys.getsizeof(obj)/1024/1024
+ cpu_mem = 0 if cpu_mem < 1 else cpu_mem
+ logger.info(f"{comment} : CPU {cpu_mem} MB")
+
+ gpu_mem = torch.numel(obj)*obj.element_size()/1024/1024
+ gpu_mem = 0 if gpu_mem < 1 else gpu_mem
+ logger.info(f"{comment} : GPU {gpu_mem} MB")
+ elif type(obj) is tuple:
+ logger.info(f"{comment} : {type(obj)}")
+ cpu_mem = 0
+ gpu_mem = 0
+
+ for o in obj:
+ cpu_mem += sys.getsizeof(o)/1024/1024
+ gpu_mem += torch.numel(o)*o.element_size()/1024/1024
+
+ cpu_mem = 0 if cpu_mem < 1 else cpu_mem
+ logger.info(f"{comment} : CPU {cpu_mem} MB")
+
+ gpu_mem = 0 if gpu_mem < 1 else gpu_mem
+ logger.info(f"{comment} : GPU {gpu_mem} MB")
+
+ else:
+ logger.info(f"{comment} : unknown type")
+
+
+
+def show_gpu(comment=""):
+ return
+ import inspect
+ callerframerecord = inspect.stack()[1]
+ frame = callerframerecord[0]
+ info = inspect.getframeinfo(frame)
+
+ import time
+
+ import GPUtil
+ torch.cuda.synchronize()
+
+# time.sleep(1.5)
+
+ #logger.info(comment)
+ logger.info(f"{info.filename}/{info.lineno}/{comment}")
+ GPUtil.showUtilization()
+
+
+PROFILE_ON = False
+
+def start_profile():
+ if PROFILE_ON:
+ import cProfile
+
+ pr = cProfile.Profile()
+ pr.enable()
+ return pr
+ else:
+ return None
+
+def end_profile(pr, file_name):
+ if PROFILE_ON:
+ import io
+ import pstats
+
+ pr.disable()
+ s = io.StringIO()
+ ps = pstats.Stats(pr, stream=s).sort_stats('cumtime')
+ ps.print_stats()
+
+ with open(file_name, 'w+') as f:
+ f.write(s.getvalue())
+
+STOPWATCH_ON = False
+
+time_record = []
+start_time = 0
+
+def stopwatch_start():
+ global start_time,time_record
+ import time
+
+ if STOPWATCH_ON:
+ time_record = []
+ torch.cuda.synchronize()
+ start_time = time.time()
+
+def stopwatch_record(comment):
+ import time
+
+ if STOPWATCH_ON:
+ torch.cuda.synchronize()
+ time_record.append(((time.time() - start_time) , comment))
+
+def stopwatch_stop(comment):
+
+ if STOPWATCH_ON:
+ stopwatch_record(comment)
+
+ for rec in time_record:
+ logger.info(rec)
+
+
+def prepare_ip_adapter():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/ip_adapter/models/image_encoder", exist_ok=True)
+ for hub_file in [
+ "models/image_encoder/config.json",
+ "models/image_encoder/pytorch_model.bin",
+ "models/ip-adapter-plus_sd15.bin",
+ "models/ip-adapter_sd15.bin",
+ "models/ip-adapter_sd15_light.bin",
+ "models/ip-adapter-plus-face_sd15.bin",
+ "models/ip-adapter-full-face_sd15.bin",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/ip_adapter" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="h94/IP-Adapter", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/ip_adapter"
+ )
+
+def prepare_ip_adapter_sdxl():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/ip_adapter/sdxl_models/image_encoder", exist_ok=True)
+ for hub_file in [
+ "models/image_encoder/config.json",
+ "models/image_encoder/pytorch_model.bin",
+ "sdxl_models/ip-adapter-plus_sdxl_vit-h.bin",
+ "sdxl_models/ip-adapter-plus-face_sdxl_vit-h.bin",
+ "sdxl_models/ip-adapter_sdxl_vit-h.bin",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/ip_adapter" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="h94/IP-Adapter", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/ip_adapter"
+ )
+
+
+def prepare_lcm_lora():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/lcm_lora/sdxl", exist_ok=True)
+ for hub_file in [
+ "pytorch_lora_weights.safetensors",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/lcm_lora/sdxl" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="latent-consistency/lcm-lora-sdxl", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/lcm_lora/sdxl"
+ )
+
+ os.makedirs("data/models/lcm_lora/sd15", exist_ok=True)
+ for hub_file in [
+ "AnimateLCM_sd15_t2v_lora.safetensors",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/lcm_lora/sd15" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="chaowenguo/AnimateLCM", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/lcm_lora/sd15"
+ )
+
+def prepare_lllite():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/lllite", exist_ok=True)
+ for hub_file in [
+ "bdsqlsz_controlllite_xl_canny.safetensors",
+ "bdsqlsz_controlllite_xl_depth.safetensors",
+ "bdsqlsz_controlllite_xl_dw_openpose.safetensors",
+ "bdsqlsz_controlllite_xl_lineart_anime_denoise.safetensors",
+ "bdsqlsz_controlllite_xl_mlsd_V2.safetensors",
+ "bdsqlsz_controlllite_xl_normal.safetensors",
+ "bdsqlsz_controlllite_xl_recolor_luminance.safetensors",
+ "bdsqlsz_controlllite_xl_segment_animeface_V2.safetensors",
+ "bdsqlsz_controlllite_xl_sketch.safetensors",
+ "bdsqlsz_controlllite_xl_softedge.safetensors",
+ "bdsqlsz_controlllite_xl_t2i-adapter_color_shuffle.safetensors",
+ "bdsqlsz_controlllite_xl_tile_anime_alpha.safetensors", # alpha
+ "bdsqlsz_controlllite_xl_tile_anime_beta.safetensors", # beta
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/lllite" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="bdsqlsz/qinglong_controlnet-lllite", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/lllite"
+ )
+
+
+def prepare_extra_controlnet():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/controlnet/animatediff_controlnet", exist_ok=True)
+ for hub_file in [
+ "controlnet_checkpoint.ckpt"
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/controlnet/animatediff_controlnet" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="crishhh/animatediff_controlnet", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/controlnet/animatediff_controlnet"
+ )
+
+
+def prepare_motion_module():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/motion-module", exist_ok=True)
+ for hub_file in [
+ "AnimateLCM_sd15_t2v.ckpt"
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/motion-module" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="chaowenguo/AnimateLCM", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/motion-module"
+ )
+
+def prepare_wd14tagger():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/WD14tagger", exist_ok=True)
+ for hub_file in [
+ "model.onnx",
+ "selected_tags.csv",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/WD14tagger" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="SmilingWolf/wd-v1-4-moat-tagger-v2", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/WD14tagger"
+ )
+
+def prepare_dwpose():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/DWPose", exist_ok=True)
+ for hub_file in [
+ "dw-ll_ucoco_384.onnx",
+ "yolox_l.onnx",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/DWPose" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="yzd-v/DWPose", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/DWPose"
+ )
+
+
+
+def prepare_softsplat():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/softsplat", exist_ok=True)
+ for hub_file in [
+ "softsplat-lf",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/softsplat" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="s9roll74/softsplat_mirror", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/softsplat"
+ )
+
+
+def extract_frames(movie_file_path, fps, out_dir, aspect_ratio, duration, offset, size_of_short_edge=-1, low_vram_mode=False):
+ import ffmpeg
+
+ probe = ffmpeg.probe(movie_file_path)
+ video = next((stream for stream in probe['streams'] if stream['codec_type'] == 'video'), None)
+ width = int(video['width'])
+ height = int(video['height'])
+
+ node = ffmpeg.input( str(movie_file_path.resolve()) )
+
+ node = node.filter( "fps", fps=fps )
+
+
+ if duration > 0:
+ node = node.trim(start=offset,end=offset+duration).setpts('PTS-STARTPTS')
+ elif offset > 0:
+ node = node.trim(start=offset).setpts('PTS-STARTPTS')
+
+ if size_of_short_edge != -1:
+ if width < height:
+ r = height / width
+ width = size_of_short_edge
+ height = int( (size_of_short_edge * r)//8 * 8)
+ node = node.filter('scale', size_of_short_edge, height)
+ else:
+ r = width / height
+ height = size_of_short_edge
+ width = int( (size_of_short_edge * r)//8 * 8)
+ node = node.filter('scale', width, size_of_short_edge)
+
+ if low_vram_mode:
+ if aspect_ratio == -1:
+ aspect_ratio = width/height
+ logger.info(f"low {aspect_ratio=}")
+ aspect_ratio = max(min( aspect_ratio, 1.5 ), 0.6666)
+ logger.info(f"low {aspect_ratio=}")
+
+ if aspect_ratio > 0:
+ # aspect ratio (width / height)
+ ww = round(height * aspect_ratio)
+ if ww < width:
+ x= (width - ww)//2
+ y= 0
+ w = ww
+ h = height
+ else:
+ hh = round(width/aspect_ratio)
+ x = 0
+ y = (height - hh)//2
+ w = width
+ h = hh
+ w = int(w // 8 * 8)
+ h = int(h // 8 * 8)
+ logger.info(f"crop to {w=},{h=}")
+ node = node.crop(x, y, w, h)
+
+ node = node.output( str(out_dir.resolve().joinpath("%08d.png")), start_number=0 )
+
+ node.run(quiet=True, overwrite_output=True)
+
+
+
+
+
+
+def is_v2_motion_module(motion_module_path:Path):
+ if motion_module_path.suffix == ".safetensors":
+ from safetensors.torch import load_file
+ loaded = load_file(motion_module_path, "cpu")
+ else:
+ from torch import load
+ loaded = load(motion_module_path, "cpu")
+
+ is_v2 = "mid_block.motion_modules.0.temporal_transformer.norm.bias" in loaded
+
+ loaded = None
+ torch.cuda.empty_cache()
+
+ logger.info(f"{is_v2=}")
+
+ return is_v2
+
+def is_sdxl_checkpoint(checkpoint_path:Path):
+ if checkpoint_path.suffix == ".safetensors":
+ from safetensors.torch import load_file
+ loaded = load_file(checkpoint_path, "cpu")
+ else:
+ from torch import load
+ loaded = load(checkpoint_path, "cpu")
+
+ is_sdxl = False
+
+ if "conditioner.embedders.1.model.ln_final.weight" in loaded:
+ is_sdxl = True
+ if "conditioner.embedders.0.model.ln_final.weight" in loaded:
+ is_sdxl = True
+
+ loaded = None
+ torch.cuda.empty_cache()
+
+ logger.info(f"{is_sdxl=}")
+ return is_sdxl
+
+
+tensor_interpolation = None
+
+def get_tensor_interpolation_method():
+ return tensor_interpolation
+
+def set_tensor_interpolation_method(is_slerp):
+ global tensor_interpolation
+ tensor_interpolation = slerp if is_slerp else linear
+
+def linear(v1, v2, t):
+ return (1.0 - t) * v1 + t * v2
+
+def slerp(
+ v0: torch.Tensor, v1: torch.Tensor, t: float, DOT_THRESHOLD: float = 0.9995
+) -> torch.Tensor:
+ u0 = v0 / v0.norm()
+ u1 = v1 / v1.norm()
+ dot = (u0 * u1).sum()
+ if dot.abs() > DOT_THRESHOLD:
+ #logger.info(f'warning: v0 and v1 close to parallel, using linear interpolation instead.')
+ return (1.0 - t) * v0 + t * v1
+ omega = dot.acos()
+ return (((1.0 - t) * omega).sin() * v0 + (t * omega).sin() * v1) / omega.sin()
+
+
+
+def prepare_sam_hq(low_vram):
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/SAM", exist_ok=True)
+ for hub_file in [
+ "sam_hq_vit_h.pth" if not low_vram else "sam_hq_vit_b.pth"
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/SAM" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="lkeab/hq-sam", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/SAM"
+ )
+
+def prepare_groundingDINO():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/GroundingDINO", exist_ok=True)
+ for hub_file in [
+ "groundingdino_swinb_cogcoor.pth",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/GroundingDINO" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="ShilongLiu/GroundingDINO", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/GroundingDINO"
+ )
+
+
+def prepare_propainter():
+ import os
+
+ import git
+
+ if os.path.isdir("src/animatediff/repo/ProPainter"):
+ if os.listdir("src/animatediff/repo/ProPainter"):
+ return
+
+ repo = git.Repo.clone_from(url="https://github.com/sczhou/ProPainter", to_path="src/animatediff/repo/ProPainter", no_checkout=True )
+ repo.git.checkout("a8a5827ca5e7e8c1b4c360ea77cbb2adb3c18370")
+
+
+def prepare_anime_seg():
+ import os
+ from pathlib import PurePosixPath
+
+ from huggingface_hub import hf_hub_download
+
+ os.makedirs("data/models/anime_seg", exist_ok=True)
+ for hub_file in [
+ "isnetis.onnx",
+ ]:
+ path = Path(hub_file)
+
+ saved_path = "data/models/anime_seg" / path
+
+ if os.path.exists(saved_path):
+ continue
+
+ hf_hub_download(
+ repo_id="skytnt/anime-seg", subfolder=PurePosixPath(path.parent), filename=PurePosixPath(path.name), local_dir="data/models/anime_seg"
+ )
diff --git a/animate/src/animatediff/utils/wild_card.py b/animate/src/animatediff/utils/wild_card.py
new file mode 100644
index 0000000000000000000000000000000000000000..6e4ef1a75a8741437674409ebff80a60565e6ab4
--- /dev/null
+++ b/animate/src/animatediff/utils/wild_card.py
@@ -0,0 +1,39 @@
+import glob
+import os
+import random
+import re
+
+wild_card_regex = r'(\A|\W)__([\w-]+)__(\W|\Z)'
+
+
+def create_wild_card_map(wild_card_dir):
+ result = {}
+ if os.path.isdir(wild_card_dir):
+ txt_list = glob.glob( os.path.join(wild_card_dir ,"**/*.txt"), recursive=True)
+ for txt in txt_list:
+ basename_without_ext = os.path.splitext(os.path.basename(txt))[0]
+ with open(txt, encoding='utf-8') as f:
+ try:
+ result[basename_without_ext] = [s.rstrip() for s in f.readlines()]
+ except Exception as e:
+ print(e)
+ print("can not read ", txt)
+ return result
+
+def replace_wild_card_token(match_obj, wild_card_map):
+ m1 = match_obj.group(1)
+ m3 = match_obj.group(3)
+
+ dict_name = match_obj.group(2)
+
+ if dict_name in wild_card_map:
+ token_list = wild_card_map[dict_name]
+ token = token_list[random.randint(0,len(token_list)-1)]
+ return m1+token+m3
+ else:
+ return match_obj.group(0)
+
+def replace_wild_card(prompt, wild_card_dir):
+ wild_card_map = create_wild_card_map(wild_card_dir)
+ prompt = re.sub(wild_card_regex, lambda x: replace_wild_card_token(x, wild_card_map ), prompt)
+ return prompt
diff --git a/animate/stylize/.gitignore b/animate/stylize/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d
--- /dev/null
+++ b/animate/stylize/.gitignore
@@ -0,0 +1,2 @@
+*
+!.gitignore
diff --git a/animate/upscaled/.gitignore b/animate/upscaled/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d
--- /dev/null
+++ b/animate/upscaled/.gitignore
@@ -0,0 +1,2 @@
+*
+!.gitignore
diff --git a/animate/wildcards/.gitignore b/animate/wildcards/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d
--- /dev/null
+++ b/animate/wildcards/.gitignore
@@ -0,0 +1,2 @@
+*
+!.gitignore