
Baichuan-M3
Collection
Modeling Clinical Inquiry for Reliable Medical Decision-Making • 6 items • Updated • 17
![]()
From Inquiry to Decision: Building Trustworthy Medical AI
🏥 Experience AI-Powered Medical Inquiry: ying.ai
Baichuan-M3 is Baichuan AI's new-generation medical-enhanced large language model, a major milestone following Baichuan-M2.
In contrast to prior approaches that primarily focus on static question answering or superficial role-playing, Baichuan-M3 is trained to explicitly model the clinical decision-making process, aiming to improve usability and reliability in real-world medical practice. Rather than merely producing "plausible-sounding answers" or high-frequency vague recommendations like "you should see a doctor soon," the model is trained to proactively acquire critical clinical information, construct coherent medical reasoning pathways, and systematically constrain hallucination-prone behaviors.
HealthBench is OpenAI's authoritative medical benchmark, constructed by 262 practicing physicians from 60 countries, comprising 5,000 high-fidelity multi-turn clinical conversations.
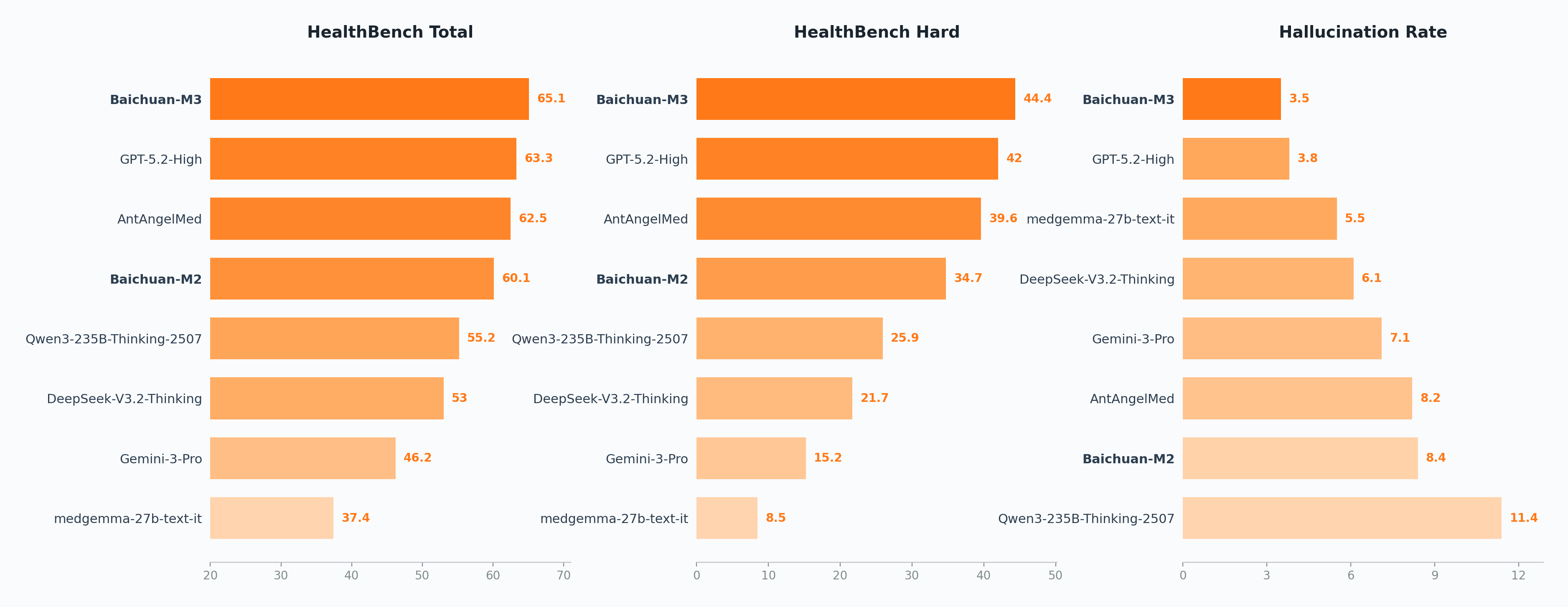
Compared to Baichuan-M2, Baichuan-M3 improves by 28 percentage points on HealthBench-Hard, reaching 44.4 and surpassing GPT-5.2. It also ranks first on the HealthBench Total leaderboard.
For hallucination evaluation, we decompose long-form responses into fine-grained, verifiable atomic medical claims and validate each against authoritative medical evidence. Even in a tool-free setting, Baichuan-M3 achieves lower hallucination rate than GPT-5.2.
SCAN-bench is our end-to-end clinical decision-making benchmark that simulates the complete clinical workflow from patient encounter to final diagnosis, evaluating models' high-fidelity clinical inquiry capabilities through three stations: History Taking, Ancillary Investigations, and Final Diagnosis.
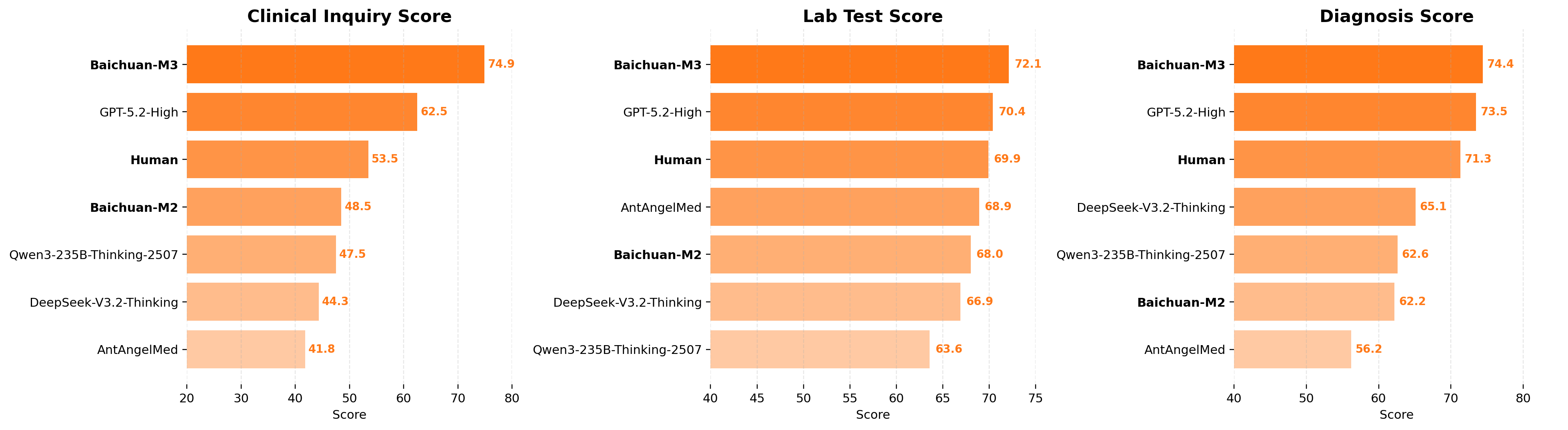
Baichuan-M3 ranks first across all three core dimensions, outperforming the second-best model by 12.4 points in Clinical Inquiry.
📢 The SCAN-bench will be open-sourced soon. Stay tuned.
📖 For detailed technical information, please refer to: Tech Blog
To address reward sparsity and credit assignment challenges in long clinical interactions, we propose SPAR (Step-Penalized Advantage with Relative baseline): it decomposes clinical workflows into four stages—history taking, differential diagnosis, laboratory testing, and final diagnosis—each with independent rewards, combined with process-level rewards for precise credit assignment, driving the model to construct auditable and complete decision logic.
By integrating factual verification directly into the RL loop, we build an online hallucination detection module that validates model-generated medical claims against authoritative medical evidence in real-time, supported by efficient caching mechanisms for online RL training. A dynamic reward aggregation strategy adaptively balances task learning and factual constraints based on the model's capability stage, significantly enhancing medical factual reliability without sacrificing reasoning depth.
Adopts a three-stage multi-expert fusion training paradigm (Domain-Specific RL → Offline Distillation → MOPD), combined with Gated Eagle3 speculative decoding (96% speedup) and W4 quantization (only 26% memory) for efficient deployment.
For deploying the Q4_K_M quantized model, you can use llama.cpp or ollama, please visit their website to get the specific operational steps for deploying the model.
Licensed under the Apache License 2.0. Research and commercial use permitted.
Thank you to the open-source community. We commit to continuous contribution and advancement of healthcare AI.
Advancing Medical AI from "Answering Correctly" to "Supporting Decisions"
@article{Baichuan-M3 Technical Report,
title={Baichuan-M3: Modeling Clinical Inquiry for Reliable Medical Decision-Making},
author={Baichuan-M3 Team: Chengfeng Dou, Fan Yang, Fei Li, Jiyuan Jia, Qiang Ju, Shuai Wang, Tianpeng Li, Xiangrong Zeng, Yijie Zhou, Hongda Zhang, Jinyang Tai, Linzhuang Sun, Peidong Guo, Yichuan Mo, Xiaochuan Wang, Hengfu Cui, Zhishou Zhang},
journal={arXiv preprint arXiv:2602.06570},
year={2026}
}
4-bit
Base model
Qwen/Qwen3-235B-A22B